PENERAPAN
FUZZY C-MEANS
UNTUK PENGELOMPOKKAN PENYAKIT
BERDASARKAN FAKTOR USIA DAN NILAI
BODY MASS
INDEX
PADA RUMAH SAKIT SARI MULIA BANJARMASIN
OLEH :
BAGUS WINDHYA KUSUMA WARDANA
3101 0701 1033
PROGRAM STUDI SISTEM INFORMASI
SEKOLAH TINGGI MANAJEMEN INFORMATIKA
DAN KOMPUTER BANJARBARU
(STMIK BANJARBARU)
PROGRAM STUDI SISTEM INFORMASI
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER BANJARBARU(STMIK BANJARBARU)
PERSETUJUAN PROPOSAL SKRIPSI
Nama : BAGUS WINDHYA KUSUMA WARDANA
NIM : 310107011033
Program Studi : SISTEM INFORMASI
Judul Skripsi : PENERAPAN FUZZY C-MEANS UNTUK
PENGELOMPOKKAN PENYAKIT BERDASARKAN FAKTOR USIA DAN NILAI BODY MASS INDEX PADA RUMAH SAKIT SARI MULIA BANJARMASIN
Banjarbaru (STMIK BANJARBARU).
Banjarmasin, 22 April 2011 Pembimbing Utama,
Budi Rahmani, S.Pd., M.Kom.
Mengetahui : Ketua Jurusan Sistem Informasi,
Bahar A. Rahman, M.Kom.
DAFTAR ISI
1.2.2. Ruang Lingkup Masalah...3
1.2.3. Rumusan Masalah...4
1.3. Tujuan dan Manfaat Penelitian...4
1.3.1. Tujuan Penelitian...4
1.3.2. Manfaat Penelitian...4
BAB II LANDASAN TEORI...5
2.1. Tinjauan Pustaka...5
2.2. Landasan Teori...6
2.2.1. Penyakit...6
2.2.2. Body Mass Index (BMI)...6
2.2.3. Data Mining...8
2.2.4. Fuzzy C-Means...11
2.2.5. Unified Modelling Language...13
2.3. Kerangka Pemikiran...14
BAB III METODE PENELITIAN...15
3.1. Analisa Kebutuhan...15
3.1.1. Metode Pengumpulan Data...16
3.2. Perancangan Penelitian...16
3.2.1. Sumber Data dan Variabel Penelitian...16
3.2.2. Diagram Konteks...17
3.2.3. Use Case Diagram...18
3.2.4. Sequence Diagram...19
3.4. Jadwal Penelitian...30
DAFTAR PUSTAKA...31
LAMPIRAN
DAFTAR TABEL
Ha
Tabel 2. 1 Rumus BMI...7
Tabel 2. 2 kategori BMI untuk orang dewasa...7
Tabel 2. 3 Tabel Body Mass Index dan resiko kesehatan...8
YTabel 3. 1. Data penyakit pasien laki-laki...21
Tabel 3. 2 Data penyakit pasien perempuan...23
Tabel 3. 3. Hasil perhitungan nilai BMI pasien laki-laki...25
Tabel 3. 4 Hasil perhitungan BMI pasien perempuan...27
Tabel 3. 5. Tabel Estimasi Jadwal...30
Hal
Gambar 3. 1. Diagram Konteks...17
Gambar 3. 2. Use Case Diagram...18
Gambar 3. 3. Sequence Diagram Clustering Penyakit...19
Gambar 3. 4. Activity Diagram...20
BAB I PENDAHULUAN
1.1. Latar Belakang
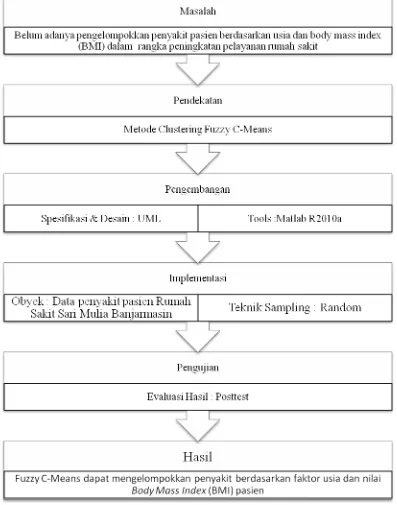
Rekam medis adalah catatan yang berisikan informasi tentang identitas pasien, anamnesa, penentuan fisik laboratorium, diagnosa segala pelayanan dan tindakan medik yang diberikan kepada pasien dan pengobatan baik yang dirawat inap, rawat jalan maupun yang mendapatkan pelayanan gawat darurat. Salah satunya berisikan informasi mengenai penyakit-penyakit yang pernah/sedang di derita oleh pasien. Penyakit merupakan suatu keadaan abnormal dari tubuh atau pikiran yang menyebabkan ketidaknyamanan, disfungsi atau kesukaran terhadap orang yang dipengaruhinya. Suatu penyakit biasanya dipengaruhi oleh beberapa faktor, diantaranya ialah usia pasien dan BMI (Body Mass Index).
bidang spesialisasi tertentu, penambahan stok obat, dan melakukan penyuluhan atau sosialisasi kepada masyarakat terhadap penyakit tertentu.
Melihat kondisi tersebut pihak rumah sakit tentunya perlu mengetahui jenis penyakit yang paling banyak dijumpai di rumah sakit tersebut, dan jenis penyakit apa yang paling banyak diidap oleh pasien yang berusia sekian. Dengan mengetahui kondisi ini, pihak rumah sakit dapat mengambil tindakan kebijakan dalam antisipasi pengobatan dan pencegahan penyakit. Untuk dapat membantu pihak rumah sakit Sari Mulia Banjarmasin dalam memberikan informasi mengenai data penyakit pasien berdasarkan faktor usia dan nilai BMI tentunya diperlukan suatu metode pendukung sebagai landasan dalam pengambilan keputusan.
Metode Clustering adalah salah satu metode dalam data mining yang dapat diterapkan untuk membantu membangun suatu sistem sebagai penyelesaian permasalahan tersebut. Metode ini telah banyak diterapkan untuk berbagai keperluan dalam mengatasi masalah yang sedang dihadapi. Beberapa penelitian diantaranya yang menerapkan metode ini adalah “Klasifikasi Kandungan Nutrisi Bahan Pangan Menggunakan Fuzzy C-Means”, dan “Aplikasi K-Means Untuk Pengelompokkan Mahasiswa Berdasarkan Nilai Body Mass Index (BMI) & Ukuran Kerangka”.
Fuzzy C-Means adalah suatu teknik pengclusteran data yang mana
3
pasien yang berusia sekian tahun, dan berada pada kategori kurus, normal, atau gemuk dilihat dari nilai BMI pasien.
Penelitian ini akan menganalisis penerapan Fuzzy C-Means untuk pengelompokkan penyakit berdasarkan faktor usia dan nilai Body Mass Index pada Rumah Sakit Sari Mulia Banjarmasin.
1.2. Permasalahan Penelitian
1.2.1. Identifikasi Masalah
Berdasarkan uraian latar balakang di atas, maka identifikasi permasalahan dalam penelitian ini yaitu belum ada penerapan algoritma fuzzy c-means dalam kasus pengelompokkan penyakit di Rumah Sakit Sari Mulia berdasarkan faktor usia dan nilai body mass index.
1.2.2. Ruang Lingkup Masalah
Ruang lingkup masalah dalam penelitian ini adalah sebagai berikut : 1. Data yang digunakan pada penelitian ini adalah data penyakit yang berada
dalam rangking 5 besar terbanyak yang meliputi data nama penyakit pasien, usia pasien, berat badan pasien dan tinggi badan pasien yang didapat pada berkas rekam medis pasien Rumah Sakit Sari Mulia Banjarmasin dari bulan Maret 2011 sampai bulan Mei 2011.
2. Penelitian ini hanya mengelompokkan penyakit pasien yang di rawat nginap. 3. Penelitian ini hanya membahas pasien yang berusia diatas 18 tahun.
1.2.3. Rumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana menerapkan metode fuzzy c-means dalam kasus pengelompokkan penyakit di Rumah Sakit Sari Mulia Banjarmasin berdasarkan faktor usia dan nilai body mass index?
1.3. Tujuan dan Manfaat Penelitian
1.3.1. Tujuan Penelitian
Sesuai dengan latar belakang di atas, maka penelitian yang dilakukan ini memiliki tujuan menerapkan metode fuzzy c-means dalam kasus pengelompokkan penyakit di Rumah Sakit Sari Mulia Banjarmasin berdasarkan faktor usia dan nilai body mass index.
1.3.2. Manfaat Penelitian
1. Bagi Penulis, penelitian ini berguna untuk menambah wawasan mengenai metode fuzzy c-means beserta penerapannya dan sebagai sarana penerapan ilmu pengetahuan yang diperoleh selama kuliah dalam realita permasalahan yang ditemukan di lapangan.
BAB II LANDASAN TEORI
2.1. Tinjauan Pustaka
Penelitian mengenai pengclusteran penyakit berdasarkan usia dan body mass index (BMI) dengan metode fuzzy c-means clustering bukanlah baru pertama
kali ini dilakukan, sudah ada penelitian terdahulu tentang penerapan metode clustering tersebut. Penelitian terdahulu yang relevan dengan penelitian ini adalah
sebagai berikut.
Sri Kusumadewi (2007) dengan judul “Klasifikasi Kandungan Nutrisi Bahan Pangan Menggunakan Fuzzy C-Means” meneliti tentang klasifikasi bahan pangan berdasarkan kandungan nutrisinya. Penelitian tersebut menghasilkan 4 buah cluster : golongan hijau, golongan kuning, golongan jingga, golongan merah.
Tedy Rismawan (2007) dengan judulnya “Aplikasi K-Means Untuk Pengelompokkan Mahasiswa Berdasarkan Nilai Body Mass Index (BMI) & Ukuran Kerangka” meneliti tentang pengelompokkan mahasiswa berdasarkan status gizi dan ukuran kerangka. Hasil penelitian tersebut diperoleh 3 kelompok : BMI normal dan kerangka besar, BMI obesitas sedang, kerangka sedang, dan BMI obesitas berat dan kerangka kecil.
Hasil penelitian sebelumnya dapat menjadi informasi dan acuan bagi peneliti saat ini yang menerapkan metode yang sama. Penelitian-penelitian diatas berbeda dengan penelitian kali ini, dimana penelitian ini menerapkan metode fuzzy c-means untuk pengelompokkan penyakit pasien berdasarkan usia dan
2.2. Landasan Teori
2.2.1. Penyakit
Penyakit merupakan suatu kondisi abnormal yang mempengaruhi organisme tubuh. Hal ini sering ditafsirkan sebagai kondisi medis yang terkait dengan spesifik gejala dan tanda-tanda. Ini mungkin disebabkan oleh faktor eksternal, seperti penyakit menular, atau mungkin disebabkan oleh disfungsi internal. Pada manusia, penyakit sering digunakan secara lebih luas untuk mengacu pada setiap kondisi yang menyebabkan rasa sakit, disfungsi, penderitaan, masalah sosial, dan/atau kematian kepada penderita, atau masalah serupa bagi mereka yang melakukan kontak dengan orang tersebut. Dalam arti yang lebih luas, penyakit termasuk cedera, cacat, gangguan, sindrom, dan infeksi. Penyakit biasanya tidak hanya mempengaruhi orang-orang secara fisik, tetapi juga secara emosional, hidup dengan menderita banyak penyakit dapat mengubah sudut pandang seseorang terhadap kehidupan, dan kepribadian mereka.
2.2.2. Body Mass Index (BMI)
Body Mass Index (BMI) merupakan suatu pengukuran yang menunjukkan
7
Tabel 2. 1 Rumus BMI
Satuan Internasional
Satuan Imperial/wilayah United States
Dengan batas pengelompokkan :
Tabel 2. 2 kategori BMI untuk orang dewasa
Kategori Untuk Laki-Laki Untuk Perempuan
Kurus (underweight) < 17 kg/m2 < 18 kg/m2
Normal 17 – 23 kg/m2 18 – 25 kg/m2
Kegemukan (overweight) 23 – 27 kg/m2 25 – 27 kg/m2
Obesitas > 27 kg/m2 > 27 kg/m2
Sumber : Pedoman praktis terapi gizi medis Departemen Kesehatan RI 2003
BMI dapat digunakan untuk menentukan seberapa besar seseorang dapat terkena resiko penyakit tertentu yang disebabkan karena berat badannya. Seseorang dikatakan obese dan membutuhkan pengobatan bila mempunyai BMI di atas 27. Resiko penyakit yang berhubungan dengan derajat kegemukan seperti penyakit jantung, kencing manis bahkan stroke dapat dilihat dari nilai BMI.
Berikut tabel BMI (Body Mass Index) atau indeks massa tubuh jika dihubungkan dengan resiko kesehatan.
2.2.3. Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan
penemuan di dalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengestraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar.
Menurut Gartner Group data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti statistik dasn matematika.
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor, antara lain :
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang andal.
9
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang
dapat dilakukan, yaitu : 1. Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel dibuat berdasarkan nilai variabel prediksi.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan untuk (untuk keadaan yang tepat) prediksi.
Dalam klasifikasi, terdapat yang variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, pendapatan rendah.
5. Pengklusteran
Pengklusteran merupakan pengelompokkan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain.
Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
2.2.4. Fuzzy C-Means
11
keberadaan tiap-tiap titik data dalam suatu cluster ditentukan oleh derajat keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981.
Konsep dasar FCM, pertama kali adalah menentukan pusat cluster, yang akan menandai lokasi rata-rata untuk tiap-tiap cluster. Pada kondisi awal, pusat cluster ini masih belum akurat. Tiap-tiap titik data memiliki derajat keanggotaan
untuk tiap-tiap cluster. Dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik data secara berulang, maka akan dapat dilihat bahwa pusat klaster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimisasi fungsi objektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut.
Keluaran dari FCM bukan merupakan fuzzy inference system, namun merupakan deretan pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data. Informasi ini dapat digunakan untuk membangun suatu fuzzy inference system.
Algoritma Fuzzy C-Means (FCM) adalah sebagai berikut :
1. Input data yang akan dicluster X, berupa matriks berukuran n x m (n=jumlah sampel data, m=atribut setiap data). Xij = data sampel ke-i (i=1,2,…,n), atribut ke-j (j=1,2,…,m).
2. Tentukan :
Jumlah cluster = c;
Pangkat = w;
Error terkecil yang diharapkan = ξ;
Fungsi obektif awal = P0 = 0;
Iterasi awal = t = 1;
3. Bangkitkan bilangan random µik, i=1,2,…,n; k=1,2,…,c; sebagai elemen-elemen matriks partisi awal U. Hitung jumlah setiap kolom :
(2.1)
Dengan j=1,2,…,n. Hitung :
(2.2) 4. Hitung pusat cluster ke-k: Vkj, dengan k=1,2,…c; dan j=1,2,…,m.
(2.3)
5. Hitung fungsi objektif pada iterasi ke-t, Pt :
(2.4)
6. Hitung perubahan matriks partisi :
(2.5)
7. Cek kondisi berhenti :
Jika : (|Pt – Pt-1|<ξ) atau (t>MaxIter) maka berhenti;
Jika tidak: t=t+1, ulangi langkah ke-4.
2.2.5. Unified Modelling Language
Unified Modelling Language (UML) adalah bahasa standar yang
13
dan desain berorientasi obyek. UML menyediakan standar notasi dan diagram yang bisa digunakan memodelkan suatu sistem. UML dikembangkan oleh Grady Booch, Jim Rumbaugh dan Ivar Jacobson. UML menjadi bahasa yang bisa digunakan untuk berkomunikasi dalam perspektif obyek antara user, developer dan project manajer.
UML memungkinkan developer melakukan pemodelan secara visual, yaitu penekanan pada penggambaran, bukan didominasi pada narasi. Pemodelan visual membantu untuk menangkap struktur dan kelakuan (behavior) suatu objek, mempermudah penggambaran interaksi antara elemen dalam system dan mempertahankan konsistensi antara design dan implementasi dalam pemrograman.
Namun karena UML hanya merupakan bahasa pemodelan, maka UML bukanlah rujukan bagaimana melakukan analisis dan desain berorientasi objek. Untuk mengetahui bagaimana melakukan analisis desain berorientasi obyek, sudah terdapat beberapa metodologi yang bisa diikuti. Didalam UML terdapat 8 diagram, antara lain Use Case Diagram, Class Diagram, Sequence Diagram, Collaboration Diagram, Statechart Diagram, Activity Diagram, Component
Diagram, dan Deployment Diagram.
BAB III METODE PENELITIAN
3.1. Analisa Kebutuhan
Analisa kebutuhan merupakan suatu penjelasan tentang kebutuhan dalam penyelesaian kasus clustering dan apa saja kebutuhan sistem dalam penerapan algoritma fuzzy c-means yang melingkupi kebutuhan perangkat keras dan perangkat lunak, dan analisa kebutuhan data .
Rumah Sakit Sari Mulia Banjarmasin memiliki jumlah pasien dalam skala besar dan keaneka ragaman jenis penyakit. Banyak kasus pasien yang menderita penyakit yang sama berdasarkan faktor usia dan nilai bmi. Sebagai upaya dalam antisipasi pengobatan dan pencegahan penyakit tentu pihak rumah sakit perlu mengetahui penyakit apa-apa saja yang banyak dijumpai di rumah sakit tersebut.
Hal ini dapat di lakukan salah satunya dengan menerapkan Algoritma fuzzy c-means yang bertujuan untuk membuat kelompok/cluster terhadap
informasi penyakit di Rumah Sakit Sari Mulia. Dengan adanya pengelompokkan penyakit diharapkan pihak rumah sakit dapat mengetahui kelompok penyakit yg paling banyak dijumpai di rumah sakit tersebut berdasarkan pada usia dan nilai bmi pasien. Sehingga dapat membantu pihak rumah sakit dalam pengambilan keputusan dalam hal pengobatan dan pencegahan penyakit.
Dalam penerapannya pada kasus pengelompokkan penyakit, algoritma fuzzy c-means membutuhkan beberapa informasi yang ada di dalam database
3.1.1. Metode Pengumpulan Data
1. Metode Kepustakaan
Metode ini digunakan untuk mengumpulkan data-data dan rumus-rumus yang diperlukan dalam kaitannya untuk menerapkan algoritma fuzzy c-means. Hal ini dapat diperoleh dari buku-buku dan literatur lainnya.
2. Wawancara
Metode ini dilakukan dengan mangadakan tanya jawab (wawancara) secara langsung dengan pihak-pihak yang berkaitan dengan informasi.
3. Metode observasi
Metode ini dilaksanakan dengan melakukan peninjauan langsung pada objek penelitian serta melakukan pencatatan mengenai hal-hal dan semua kejadian yang berhubungan dengan masalah yang diteliti. Observasi dilakukan di Rumah Sakit Sari Mulia Banjarmasin.
3.2. Perancangan Penelitian
3.2.1. Sumber Data dan Variabel Penelitian
Data penelitian yang digunakan adalah data sekunder yang diambil dari Rumah Sakit Sari Mulia Banjarmasin. Variabel penelitian yang digunakan dalam pengelompkkan dua variabel yang telah didefinisikan pada bab landasan teori. Kedua variabel tersebut adalah sebagai berikut :
17
3.2.2. Diagram Konteks
Diagram konteks merupakan gambaran umum mengenai interaksi yang terjadi antara sistem dengan admin. Diagram konteks dari sistem ini ditunjukkan pada gambar.
Pada diagram konteks digambarkan proses umum yang terjadi di dalam sistem. Terdapat komponen proses cluster dan external entity admin sebagai yang memasukkan input dan menerima output. Admin memasukkan jumlah cluster yang diminta untuk selanjutnya di proses. Setelah melakukan proses, sistem akan menghasilkan output berupa hasil cluster penyakit berdasarkan usia dan nilai bmi pasien.
Gambar 3. 1. Diagram Konteks
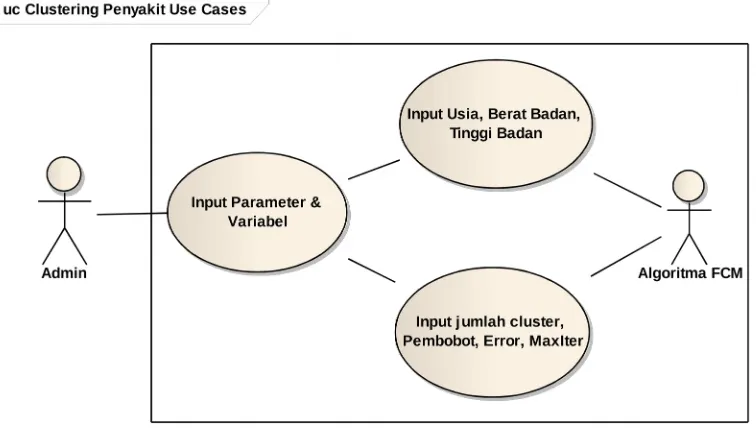
Use case adalah konstruksi untuk mendeskripsikan bagaimana sistem
terlihat di mata pengguna. Sasaran pemodelan use case diantaranya adalah mendefinisikan kebutuhan fungsional dan operasional sistem dengan mendefinisikan skenario penggunaan yang disepakati antara pemakai dan pengembang (developer). Use case diagram untuk pengelompokkan penyakit dapat dilihat pada Gambar 3.2 .
Gambar 3. 2. Use Case Diagram
19
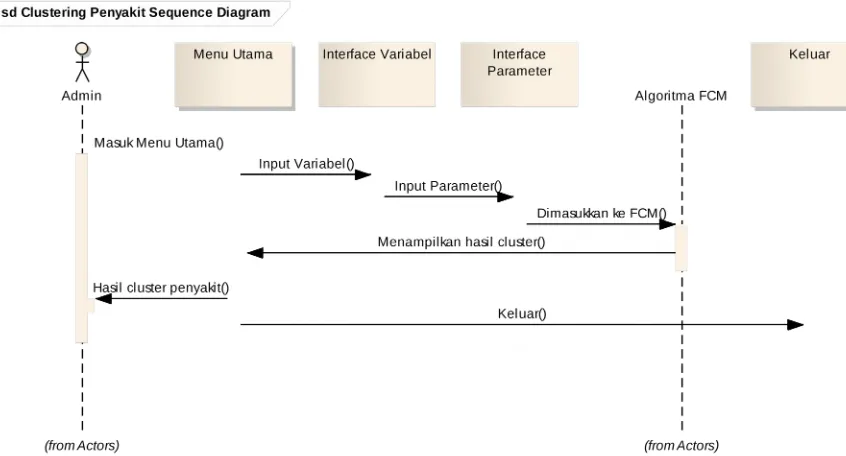
Gambar 3. 3. Sequence Diagram Clustering Penyakit
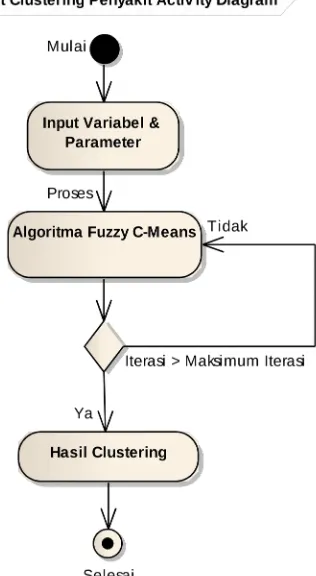
Diagram aktifitas (Activity diagram) memodelkan urutan aktifitas dalam suatu proses. Berikut gambaran diagram aktifitas dalam pengelompokkan penyakit.
Gambar 3. 4. Activity Diagram
21
Teknik analisis yang dipakai pada penelitian ini adalah analisis cluster dengan metode fuzzy c-means. Analisis cluster merupakan teknik multivarian yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Dalam hal ini ialah pengelompokkan penyakit berdasarkan usia dan nilai bmi. Analisis cluster mengklasifikasi objek sehingga setiap objek yang paling dekat kesamaannya dengan objek lain berada dalam cluster yang sama. Cluster-cluster yang terbentuk memiliki homogenitas internal yang tinggi dan heterogenitas eksternal yang tinggi. Fokus dari analisis cluster adalah membandingkan objek berdasarkan set variabel, set variabel cluster adalah suatu set variabel yang merepresentasikan karakteristik yang dipakai objek-objek.
Berikut data penyakit pasien laki-laki dan pasien perempuan beserta atribut sebelum dilakukan perhitungan untuk mencari nilai BMI dari masing-masing data dapat dilihat pada tabel 3.1. dan tabel
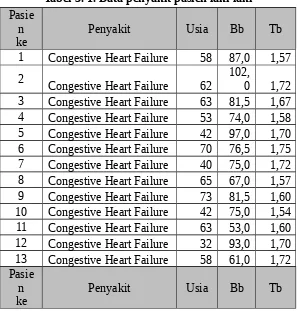
Tabel 3. 1. Data penyakit pasien laki-laki Pasie
n ke
Penyakit Usia Bb Tb
1 Congestive Heart Failure 58 87,0 1,57 2
Congestive Heart Failure 62
102,
0 1,72 3 Congestive Heart Failure 63 81,5 1,67 4 Congestive Heart Failure 53 74,0 1,58 5 Congestive Heart Failure 42 97,0 1,70 6 Congestive Heart Failure 70 76,5 1,75 7 Congestive Heart Failure 40 75,0 1,72 8 Congestive Heart Failure 65 67,0 1,57 9 Congestive Heart Failure 73 81,5 1,60 10 Congestive Heart Failure 42 75,0 1,54 11 Congestive Heart Failure 63 53,0 1,60 12 Congestive Heart Failure 32 93,0 1,70 13 Congestive Heart Failure 58 61,0 1,72 Pasie
n ke
14 Dyspepsia 46 58,0 1,78
15 Dyspepsia 36 49,0 1,88
16 Dyspepsia 27 63,0 1,70
17 Dyspepsia 26 62,0 1,70
18 Dyspepsia 50 65,0 1,78
19 Dyspepsia 50 37,0 1,61
20 Dyspepsia 44 43,0 1,58
21 Dyspepsia 50 50,0 1,62
22 Dyspepsia 53 50,5 1,70
23 Dyspepsia 22 45,0 1,70
24 Dyspepsia 42 50,0 1,68
25 Dyspepsia 36 56,0 1,73
26 Dyspepsia 92 45,0 1,63
27 Dyspepsia 60 60,0 1,77
28 Dyspepsia 65 52,0 1,68
29 Dyspepsia 56 55,0 1,70
30 Dyspepsia 19 54,0 1,73
31 Hipertensi 81 73,0 1,68
32 Hipertensi 51 75,0 1,67
33 Hipertensi 39 72,0 1,70
34 Hipertensi 61 61,5 1,67
35 Hipertensi 66 73,0 1,65
36 Hipertensi 44 79,0 1,69
37 Hipertensi 25 69,0 1,76
38 Hipertensi 46 80,0 1,67
39 Hipertensi 59 58,0 1,52
40 Hipertensi 25 73,0 1,72
41 Hipertensi 23 95,0 1,76
42 Hipertensi 70 82,5 1,57
43 Hipertensi 51 47,0 1,70
44 Hipertensi 59 50,0 1,72
45 Stroke Hemoragik 55 63,5 1,65
46 Stroke Hemoragik 50 65,0 1,60
47 Stroke Hemoragik 75 68,0 1,57
48 Stroke Hemoragik 29 62,0 1,64
49 Stroke Hemoragik 45 51,0 1,72
50 Stroke Hemoragik 55 46,0 1,64
51 Stroke Hemoragik 70 73,5 1,58
Pasie n ke
Penyakit Usia Bb Tb
52 Stroke Hemoragik 54 69,5 1,66
23
54 Stroke Hemoragik 37 86,0 1,70
55 Stroke Hemoragik 49 39,0 1,47
56 Stroke Hemoragik 60 73,5 1,63
57 Stroke Hemoragik 55 77,0 1,63
58 Stroke Hemoragik 65 89,0 1,65
59 Stroke Non Hemoragik 62 62,0 1,49 60 Stroke Non Hemoragik 62 56,0 1,79 61 Stroke Non Hemoragik 57 61,0 1,67 62 Stroke Non Hemoragik 70 63,0 1,79 63 Stroke Non Hemoragik 58 78,0 1,56 64 Stroke Non Hemoragik 35 59,0 1,58 65 Stroke Non Hemoragik 64 93,0 1,68 66 Stroke Non Hemoragik 68 64,0 1,56 67 Stroke Non Hemoragik 30 60,5 1,58 68 Stroke Non Hemoragik 56 63,0 1,52 69 Stroke Non Hemoragik 63 84,0 1,69 70 Stroke Non Hemoragik 56 67,0 1,61 71 Stroke Non Hemoragik 70 49,0 1,67 72 Stroke Non Hemoragik 60 88,5 1,51 73 Stroke Non Hemoragik 52 69,5 1,64
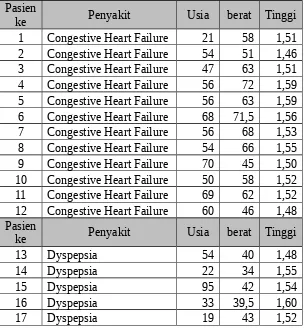
Tabel 3. 2 Data penyakit pasien perempuan
Pasien
ke Penyakit Usia berat Tinggi
1 Congestive Heart Failure 21 58 1,51 2 Congestive Heart Failure 54 51 1,46 3 Congestive Heart Failure 47 63 1,51 4 Congestive Heart Failure 56 72 1,59 5 Congestive Heart Failure 56 63 1,59 6 Congestive Heart Failure 68 71,5 1,56 7 Congestive Heart Failure 56 68 1,53 8 Congestive Heart Failure 54 66 1,55 9 Congestive Heart Failure 70 45 1,50 10 Congestive Heart Failure 50 58 1,52 11 Congestive Heart Failure 69 62 1,52 12 Congestive Heart Failure 60 46 1,48 Pasien
ke Penyakit Usia berat Tinggi
13 Dyspepsia 54 40 1,48
14 Dyspepsia 22 34 1,55
15 Dyspepsia 95 42 1,54
16 Dyspepsia 33 39,5 1,60
18 Dyspepsia 18 48 1,62
19 Dyspepsia 35 40 1,60
20 Dyspepsia 60 40 1,48
21 Dyspepsia 30 37,5 1,48
22 Dyspepsia 36 39 1,62
23 Dyspepsia 20 45 1,60
24 Dyspepsia 64 40 1,55
25 Dyspepsia 22 38 1,55
26 Dyspepsia 38 41 1,63
27 Dyspepsia 31 50 1,70
28 Dyspepsia 51 53 1,64
29 Dyspepsia 55 41 1,66
30 Dyspepsia 21 50 1,67
31 Dyspepsia 58 50 1,68
32 Dyspepsia 43 51 1,73
33 Hipertensi 56 73 1,68
34 Hipertensi 65 60 1,52
35 Hipertensi 52 82 1,68
36 Hipertensi 86 74 1,59
37 Hipertensi 45 83 1,66
38 Hipertensi 63 75 1,67
39 Hipertensi 45 72 1,65
40 Hipertensi 100 59 1,63
41 Hipertensi 33 72 1,64
42 Hipertensi 73 73 1,68
43 Hipertensi 40 85 1,73
44 Hipertensi 70 75 1,67
45 Hipertensi 24 65 1,61
46 Hipertensi 51 71 1,58
47 Hipertensi 44 73 1,53
48 Hipertensi 60 67 1,44
49 Hipertensi 44 123 1,72
50 Hipertensi 83 75 1,67
Pasien
ke Penyakit Usia berat Tinggi
51 Hipertensi 70 81 1,56
52 Hipertensi 52 73 1,64
53 Hipertensi 65 59 1,46
54 Hipertensi 45 75 1,59
55 Hipertensi 46 69 1,60
56 Stroke Hemoragik 56 47 1,59
57 Stroke Hemoragik 50 49 1,65
25
59 Stroke Hemoragik 68 57 1,86
60 Stroke Hemoragik 40 64 1,50
61 Stroke Non Hemoragik 50 63 1,47
62 Stroke Non Hemoragik 76 53 1,86
63 Stroke Non Hemoragik 75 83 1,57
64 Stroke Non Hemoragik 49 77 1,66
65 Stroke Non Hemoragik 90 55 1,57
66 Stroke Non Hemoragik 53 58 1,61
67 Stroke Non Hemoragik 45 79 1,55
68 Stroke Non Hemoragik 42 48 1,56
Ket :
Bb : Berat badan (kg) Tb : Tinggi badan (m)
Data pada tabel 3.1. dan tabel 3.2. kemudian digunakan untuk menghitung nilai BMI. Hasil dari perhitungan dapat di lihat pada tabel 3.3. dan tabel 3.4.
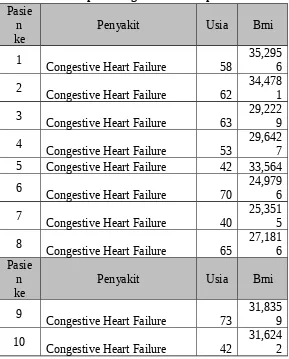
Tabel 3. 3. Hasil perhitungan nilai BMI pasien laki-laki Pasie
n
ke Penyakit Usia Bmi
11 Congestive Heart Failure 63 20,7031 12 Congestive Heart Failure 32 32,1799 13
15 Dyspepsia 36 13,8637
16 Dyspepsia 27 21,7993
17 Dyspepsia 26 21,4533
18 Dyspepsia 50 20,5151
19
27 Dyspepsia 60 19,1516
28 Dyspepsia 65 18,424
29 Dyspepsia 56 19,1435
30 Dyspepsia 19 18,0427
31 Hipertensi 81 25,8645
32 Hipertensi 51 26,8923
27
1
37 Hipertensi 25 22,2753
38 Hipertensi 46 28,6851
39 Hipertensi 59 25,1039
40 Hipertensi 25 24,6755
41
45 Stroke Hemoragik 55 23,3242
46 Stroke Hemoragik 50 25,3906
Pasie n ke
Penyakit Usia Bmi
47 Stroke Hemoragik 75 27,5873
48 Stroke Hemoragik 29 23,0518
49
51 Stroke Hemoragik 70 29,4424
52 Stroke Hemoragik 54 25,2214
53 Stroke Hemoragik 73 28,8044
54 Stroke Hemoragik 37 29,7578
55
57 Stroke Hemoragik 55 28,9811
58 Stroke Hemoragik 65 32,6905
59
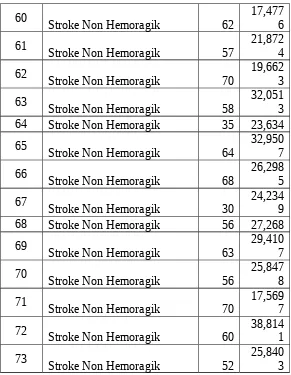
Stroke Non Hemoragik 62
60 Stroke Non Hemoragik 62 17,4776 61 Stroke Non Hemoragik 57 21,8724 62
64 Stroke Non Hemoragik 35 23,634
65 67 Stroke Non Hemoragik 30 24,2349
68 Stroke Non Hemoragik 56 27,268
69 71 Stroke Non Hemoragik 70 17,5697 72 Stroke Non Hemoragik 60 38,8141 73 Stroke Non Hemoragik 52 25,8403
Tabel 3. 4 Hasil perhitungan BMI pasien perempuan
Pasie n ke
Penyakit Usia Bmi
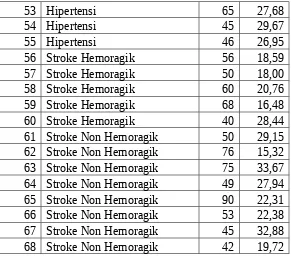
1 Congestive Heart Failure 21 25,44 2 Congestive Heart Failure 54 23,93 3 Congestive Heart Failure 47 27,63 4 Congestive Heart Failure 56 28,48 5 Congestive Heart Failure 56 24,92 6 Congestive Heart Failure 68 29,38 7 Congestive Heart Failure 56 29,05 Pasie
n ke
Penyakit Usia Bmi
53 Hipertensi 65 27,68
54 Hipertensi 45 29,67
55 Hipertensi 46 26,95
56 Stroke Hemoragik 56 18,59
57 Stroke Hemoragik 50 18,00
58 Stroke Hemoragik 60 20,76
59 Stroke Hemoragik 68 16,48
60 Stroke Hemoragik 40 28,44
61 Stroke Non Hemoragik 50 29,15
62 Stroke Non Hemoragik 76 15,32
63 Stroke Non Hemoragik 75 33,67
64 Stroke Non Hemoragik 49 27,94
65 Stroke Non Hemoragik 90 22,31
66 Stroke Non Hemoragik 53 22,38
67 Stroke Non Hemoragik 45 32,88
68 Stroke Non Hemoragik 42 19,72
Selanjutnya data pada Tabel 3.2. dianalisa menggunakan algoritma fuzzy c-means yang mana tahapan algoritmanya telah disebutkan pada bab landasan
teori.
3.4. Jadwal Penelitian
Penelitian ini akan dilaksanakan dengan mengikuti estimasi jadwal yang telah disusun seperti pada Tabel 3.3. berikut :
Tabel 3. 5. Tabel Estimasi Jadwal
No Kegiatan Bulan 1 Bulan 2 Bulan 3 Bulan 4
31
1. Pengumpulan Data 2. Analisa Permasalahan 3. Penerapan Algoritma 4. Uji Algoritma dan
Implementasi 5. Pembuatan Laporan
Keterangan :
: Pelaksanaan Kegiatan
DAFTAR PUSTAKA
Andaka, D. (2008, Agustus 1). Normalkah Body Mass Index Anda? Retrieved April 6, 2011, from Andaka.com: www.andaka.com/normalkah-body-mass-index-bmi-anda.php
Anonim. (2011, Maret 27). Disease. Retrieved Maret 31, 2011, from http://en.wikipeia.org/wiki/Disease
Kusumadewi, S. (2010). Aplikasi Logika Fuzzy untuk Pendukung Keputusan. Yogyakarta: Graha Ilmu.
Kusumadewi, S. (2008). Klasifikasi Kandungan Nutrisi Bahan Pangan Menggunakan Fuzzy C-Means. Seminar Nasional Aplikasi Teknologi Informasi (SNATI) 2008 .
Luthfi, E. T. (2007, November 24). Fuzzy C-Means Untuk Clustering Data (Studi Kasus: Data Performance Mengajar Dosen). Seminar Nasional Teknologi (SNT 2007) .
Rismawan, T., & Kusumadewi, S. (2008). Aplikasi K-Means Untuk Pengelompokkan Mahasiswa Berdasarkan Nilai Body Mass Index (BMI) & Ukuran Kerangka. Seminar Nasional Aplikasi Teknologi Informasi (SNATI) 2008 .