Seminar Nasional Telekomunikasi dan Informatika (SELISIK 2016)
Bandung, 28 Mei 2016 ISSN : 2503-2844
Feri Sulianta
Seminar Nasional Telekomunikasi dan Informatika 2016
MEMBANGUN ATURAN ASOSIASI MENGGUNAKAN
ALGORITMA APRIORI UNTUK MENGETAHUI HUBUNGAN
KRIMINALITAS DENGAN FAKTOR DEMOGRAFI SEBAGAI
PERTIMBANGAN MEMBUAT ATURAN KEPENDUDUKAN
Feri Sulianta
Fakultas Teknis, Jurusan Teknik Informatika Universitas Widyatama
Jalan Cikutra No. 204A, Bandung, Indonesia [email protected]
Abstrak
Pendekatan penambangan data digunakan sebagai teknik untuk mendapatkan informasi-informasi penting yang dapat dijadikan bahan penunjang dalam suatu pengambilan keputusan. Pada penelitian ini, metode asosiasi diimplementasikan untuk mendapatkan hubungan sebab akibat yang ada pada data kependudukan, terutama untuk mendapatkan pola hubungan kejadian kriminalitas dengan karakteristik penduduk. Dalam kasus ini, didapati data-data dengan nilai yang tidak valid dan kendala ketidaklengkapan data, yang harus ditangani dengan seksama sehingga layak untuk dibangunkan aturan asosiasi. Algoritma apriori diterapkan pada metode ini, karena algoritma ini terbukti mampu menghasilkan aturan dengan tingkat akurasi tinggi dalam membangun pola keterhubungan antar atribut. Aturan asosiasi akan dijadikan dasar dalam membuat kebijakan sehubungan masalah kependudukan. Kata kunci :
apriori, aturan asosiasi, menambang data, demografi, kriminalitas, kependudukan
Abstract
Data mining approach is used as a technique to obtain important information that can be used as supporting material in a decision . in this study, the association method is implemented to obtain relationship existing on population data , especially to get the relationship patterns of crime events related to characteristics of the population. In this case , invalid data and missing values must be handled carefully before building association rules.
Apriori algorithm is applied to this method, since the algorithm is proven to generate rules with high degree of accuracy in establishing the pattern of connectivity between attributes . Association rules will be used as a basis for making policy related to the population problem .
Keywords :
apriori, association rule, data mining, , demographics, crime, populations
I.
P
ENDAHULUANData Mining saat ini menjadi suatu metode yang mulai banyak digunakan untuk menemukan berbagai informasi yang signifikan dari kumpulan data historis dan digunakan sebagai dasar untuk membuat berbagai kebijakan. (Tan, Steinbach & Kumar, 2006)
Untuk memberikan hasil maksimal, secara umum diperlukan beberapa tahapan dalam proses penambangan data dengan metode asosiasi, antara lain: pemahaman masalah, pengenalan data, penanganan data, proses menambang dan kesimpulan hasil serta evaluasi dan analisa.
Seminar Nasional Telekomunikasi dan Informatika (SELISIK 2016)
Bandung, 28 Mei 2016 ISSN : 2503-2844
Feri Sulianta
Seminar Nasional Telekomunikasi dan Informatika 2016 usulan atau masukan bagi pemerintah dalam
penanggulangan kriminalitas.
II.
K
AJIANL
ITERATURPenambangan data menarik banyak perhatian dalam industri informasi dan bisnis dalam dekade terakhir, hal ini dikarenakan karena ketersediaan data dalam jumlah besar. Umumnya data didapat dari kegiatan transaksional dan arsip yang tersimpan dalam sistem komputer. Teknik penambangan data tersebut dapat menghasilkan informasi yang berharga yang dipandang sebagai pengetahuan. Pengetahuan dari pertambangan dapat digunakan untuk aplikasi mulai dari analisis bisnis, deteksi pola penyakit, industri periklanan, prediksi bencana, pertanian dan banyak lagi (Sulianta, 2013).
Banyak istilah penambangan data lainnya dikembangkan, seperti pertambangan pengetahuan dari data, ekstraksi pengetahuan, analisis pola, arkeologi data, dan data pengerukan. Kebanyakan orang memperlakukan data mining sebagai Knowledge Discovery Database (Witten & Frank, 2005).
Gambar 1. Menambang data sebagai proses dalam mendapatan pengetahuan
Sebelum menambang data dan mendapatkan aturan asosiasi, data mentah harus proses terlebih dahulu, yang mencakup transformassi data, agregasi, normalisasi terhadap redudansi data serta mengkonstruksi atribut.
Gambar 2. Proses transformasi data dan reduksi data sebelum tahap menambang data
Algoritma Apriori digunakan sebagai prosedur untuk menghasilkan aturan asosiasi. Secara teknis, algoritma akan mencari berbagai kombinasi item
pada kumpulan data dengan yang telah ditentukan dukungan minimal, disebut frequent item (frekunsi kemunculan item data) yang ditetapkan. Jika kombinasi kurang dari minimum support yang telah ditentukan maka kombinasi tersebut layak untuk dihilangkan. Kumpulan atribut yang diidentifikasi sering muncul digunakan untuk membangun aturan yang diinginkan untuk mencocokkan pola untuk dikumpulkan sebagai frequent (Han, Kamber & Micheline, 2006)
Algoritma apriori mampu menghasilkan hubungan dan aturan tentang transaksi kumpulan data yang akan mengungkapkan pola pilihan pelanggan terhadap suatu produk, yang mampu mengungkapkan hal yang awalnya tak teralamati dan sulit untuk diukur (Agrawal & Srikant, 1994).
Perhitungan dalam algoritma Apriori diukur berdasarkan dukungan persentase kejadian atau suatu aksi yang dihitung dengan rumus seperti yang dijelaskan di bawah ini:
Confidence (A B) = (semua data yang terdiri dari komponen A dan B) dibandingkan dengan (semua data yang terdiri atau mengandung komponen A)
Support (A B) = (semua data yang terdiri dari komponen A dan B) dibandingkan dengan (keseluruhan data)
Seminar Nasional Telekomunikasi dan Informatika (SELISIK 2016)
Bandung, 28 Mei 2016 ISSN : 2503-2844
Feri Sulianta
Seminar Nasional Telekomunikasi dan Informatika 2016 Aturan asosiasi mengungkapkan pengetahuan
sehubungan dengan data transaksional menggunakan algoritma Apriori dengan tingkat support lebih dari 50% dan confident sama atau lebih tinggi dari 70% (Witten & Frank, 2005).
III.
A
NALISIS DANP
ERANCANGAN Data demografi yang tersedia sangat beraneka ragam, mulai dari populasi, ekonomi, kriminalitas, dan sebagainya. Dari data-data yang tersedia begitu banyak, dapat dibuat beberapa asumsi, antara lain:1. Hubungan antara kriminalitas dengan persoalan perumahan.
2. Hubungan antara jenis-jenis kriminalitas 3. Hubungan antara tingkat pendapatan dengan
kriminalitas.
4. Hubungan antara rasisme dengan kriminalitas.
Beberapa asumsi tersebut dibuat untuk menghindari adanya aturan yang kurang relevan dengan faktor-faktor yang mempengaruhinya.
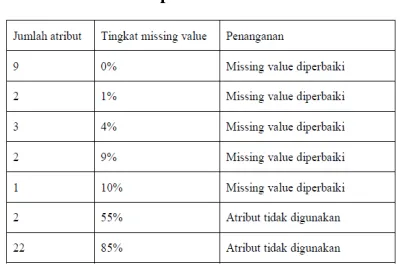
Tabel 1. Penanganan missing value pada data kependudukan
Terkait data kependudukan, kondisi yakni data disimpan dalam format flat filedan memiliki komposisi 147 atribut dengan 2215 baris data. Kendala pada data dikarenakan banyaknya missing value dan nilai yang tidak valid masuk kedalam sistem, kondisitersebut ditangani pada proses praposes data. Dengan adanya pengurangan atribut, maka atribut yang bisa digunakan adalah sebanyak 123 atribut, dimana nilai missing value sudah diperbaiki.
Dari data tersebut diatas, diputuskan untuk atribut yang memiliki tingkat missing value 55% dan 85% tidak digunakan. Selanjutnya untuk tingkat missing value <= 10% maka data akan diperbaiki dengan menggantinya dengan nilai modus dan median. Hal ini berdasarkan dari studi literatur yang menyatakan bahwa data dengan tingkat missing va lue 15% dapat menyebabkan penurunan nilai confident hingga 85% (Tan, Steinbach, & Kumar, 2006).
Pada tahapan ini, metode asosiasi menggunakan algoritma Apriori, akan diimplementasikan dengan membuat batasan dengan tingkat confident-nya yakni lebih dari 70%.
Berdasarkan asumsi-asumsi yang telah dibuat, diambil atribut-atribut yang diperkirakan terkait dengan aturan yang ingin dihasilkan. Menambang keterhubungan data dengan algoritma Apriori menghasilkan aturan asosiasi sebagai berikut:
1. BX=3 CS=0 DZ=0 601 ==> CT=0 574 conf: (0.96)
2. CS=0 DZ=0 750 ==> CT=0 705 conf:(0.94)
3. BX=3 DZ=0 783 ==> CT=0 735 conf:(0.94)
4. BX=3 CS=0 898 ==> CT=0 842 conf:(0.94)
5. Q=100 BX=3 DZ=0 403 ==> CT=0 373 conf:(0.93)
6. Q=100 BX=3 CS=0 491 ==> CT=0 453 conf:(0.92)
7. Q=100 CS=0 DZ=0 402 ==> CT=0 370 conf:(0.92)
8. DZ=0 1026 ==> CT=0 931 conf:(0.91) 9. CS=0 1234 ==> CT=0 1118 conf:(0.91) 10. Q=0 BX=3 369 ==> CT=0 333 conf:(0.9)
Keterangan nama atribut: BX : jumlah kamar tidur
CS : jumlah orang di tempat penampungan DZ : jumlah pembunuhan (pada tahun 1995) Q : jumlah orang yang tinggal di perkotaan CT : jumlah orag tunawisma di jalanan Dari sepuluh aturan yang memiliki tingkat confident lebih dari 90%, dapat diambil kesimpulan yakni:
Seminar Nasional Telekomunikasi dan Informatika (SELISIK 2016)
Bandung, 28 Mei 2016 ISSN : 2503-2844
Feri Sulianta
Seminar Nasional Telekomunikasi dan Informatika 2016 meminimalisir tingkat kejahatan domestik
dan konflik-konflik sosial.
Kebanyakan orang kulit hitam teridentifikasi sebagai pelaku tindak kejahatan, tapi tidak ada korelasi lain yang dapat diungkapkan terkait tercetusnya perilaku tersebut, maka dari itu perlu adanya pemeriksaan lebih lanjut pada orang berkulit hitam
Perampokan bukan hanya disebabkan oleh masalah ekonomi, tapi juga karena faktor lain, dalam hal ini adalah rasisme, maka perlu dipertimbangkan adanya undang-undang tentang larangan rasisme.
Orang Asia biasanya lemah dan mudah ditindas, maka perlu dipertimbangkan adanya undang-undang tentang perlindungan warga negara lokal dan warga negara asing.
Terjadinya berbagai jenis kriminalitas biasanya dibarengin dengan jenis perampokan, sedangkan perampokan dipicu dari tingkat kemiskinan yang tinggi. Dalam kasus ini, guna mengurangi kriminalitas dan meningkatkan kesejahteraan masyarakat, perlu dipertimbangkan adanya pembinaan kewira usahaan dan penyediaan lapangan pekerjaan.
IV.
K
ESIMPULAN DANS
ARANDari data yang tersedia, dapat diungkapkan lebih banyak keterhubungan antara elemen data, misalkan hubungan antara tingkat pendidikan dengan jumlah pekerja, hubungan antara jenis pekerjaan dengan pendapatan, dan sebagainya dengan batasan tingkat confident yang berdampak pada akurasi dari aturan asosiasi sebagai dasar dalam membuat kebijakan sehubungan kependudukan.
Dengan menambah atribut yang lebih banyak, diharapkan akan bertambah pula usulan yang bisa diajukan kepada pemerintahan.
R
EFERENSIAgrawal, R., Srikant, R., Fast Algorithms for Mining Association Rules. IBM Almaden Research Center 650 Harry Road, San Jose, CA 95120. Proceedings of the 20th VLDB Conference Santiago, Chile. 1994.
Campos, Marcos., Stengard,Peter.,
Milenova,Boriana., Data Centric Automated
data Mining. Proceedings of the Fourth International Conference on Machine Learning and Applications (ICMLA’05). IEEE. 2005.
D.N, Goswami., Anshu, Chaturvedi., C.S,
Raghuvanshi., D.N, Goswami. et. al. An
Algorithm for Frequent Pattern Mining Based On Apriori. (IJCSE) International Journal on Computer Science and Engineering Vol. 02, No. 04, 2010, 942-947.
Farajian, Mohammad Ali., Mohammadi, Shahriar.,
Mining the Banking Customer Behaviour Using
Clustering and Association Rules Methods,
International Journal of Industrial Engineering and Production Research.Vol 21, Number 4 pp. 239-245.2010.
Haery, A., Salmasi,N., Modarres Yazdi,M.,
Iranmanesh,H., Application of Association Rule
Mining in Supplier Selection Criteria. World
Academy of Science, Engineering and
Technology 40 2008.
Han,Jiawei., Kamber, Micheline., Data Mining:Concepts and Techniques. Morgan Kaufmann Publishers 2006 page.: 4-37 , page : 227-260.
Sulianta, Feri. Mining Food Industry’s
Multidimensional Data to Produce Association Rules using Apriori Algorithm as a basis of Business Strategy. IEEE. Issue 28, March 2013.
Tan, P.-N., Steinbach, M., & Kumar, V. Introduction to Data Mining. Boston: Pea rson Education,Inc. (2006).