II-1
BAB II
STUDI LITERATUR
Secara garis besar, bab dua berisi berbagai studi literatur mengenai teori graf, social network dan text classification. Pembahasan mengenai teori graf mencakup definisi graf, jenis-jenis graf, dan representasi graf. Teori graf ini diperlukan karena social network biasanya dimodelkan dalam bentuk graf. Pembahasan mengenai social network mencakup definisi social network, data social network, konsep SNA, teknik SNE, serta perangkat lunak social network. Sedangkan pembahasan mengenai text classification mencakup definisi permasalahan klasifikasi, pemilihan atribut klasifikasi, dan algoritma klasifikasi. Studi literatur ini akan memberikan pemahaman yang lebih detil mengenai topik-topik tersebut sehingga akan memudahkan proses pembangunan social network dari dokumen web pada bab selanjutnya.
2.1 Teori Graf
2.1.1 Definisi Graf
Secara matematis, graf G didefinisikan sebagai pasangan himpunan (V,E), dimana: V = himpunan tidak-kosong dari simpul-simpul (vertices)
= { v1 , v2 , ... , vn }
E = himpunan sisi (edges) yang menghubungkan sepasang simpul = {e1 , e2 , ... , en }
atau dapat ditulis dengan notasi G = (V,E).
II-2
Sebagai contoh, pada Gambar II-1, G merupakan graf dengan himpunan simpul V dan himpunan sisi E sebagai berikut:
V = { 1, 2, 3, 4 }
E = { (1, 2), (2, 3), (1, 3), (1, 3), (2, 4), (3, 4), (3, 4) } = { e1, e2, e3, e4, e5, e6, e7}
Terdapat beberapa terminologi dasar di dalam teori graf, yaitu:
1. Derajat
Derajat suatu simpul pada graf tak-berarah merupakan jumlah sisi yang bersisian dengan simpul tersebut. Pada graf berarah, terdapat derajat-masuk (in-degree) dan derajat keluar (out-degree). Derajat-masuk pada suatu simpul merupakan banyaknya busur yang masuk ke simpul tersebut. Sedangkan derajat-keluar dari suatu simpul merupakan banyaknya busur yang keluar dari simpul tersebut.
2. Lintasan (Path)
Lintasan yang panjangnya n dari simpul awal v0 ke simpul tujuan vn di dalam graf
G ialah barisan berselang-seling simpul-simpul dan sisi-sisi yang berbentuk v0, e1,
v1, e2, v2,... , vn –1, en, vn sedemikian sehingga e1 = (v0, v1), e2 = (v1, v2), ... , en = (v n-1, vn) adalah sisi-sisi dari graf G. Panjang lintasan merupakan jumlah sisi (en)
dalam lintasan tersebut.
3. Graf berbobot (weighted graph)
Graf berbobot adalah graf yang setiap sisinya diberi sebuah harga (bobot).
2.1.2 Jenis-Jenis Graf
Graf dapat dibedakan berdasarkan tiga hal, yaitu ada tidaknya gelang atau sisi ganda, jumlah simpul, dan orientasi arah pada sisi. Berdasarkan ada tidaknya gelang atau sisi ganda pada suatu graf, maka graf digolongkan menjadi dua jenis, yaitu:
1. Graf sederhana (simple graph)
Graf sederhana merupakan graf yang tidak mengandung gelang maupun sisi-ganda.
2. Graf tak-sederhana (unsimple-graph)
Graf yang mengandung sisi ganda atau gelang dinamakan graf tak-sederhana (unsimple graph). Graf G pada Gambar II-1 merupakan contoh graf tak-sederhana.
II-3
Berdasarkan jumlah simpul pada suatu graf, maka secara umum graf dapat digolongkan menjadi dua jenis, yaitu:
1. Graf berhingga (limited graph)
Graf berhingga adalah graf yang jumlah simpulnya, n, berhingga. Graf G pada Gambar II-1 merupakan graf berhingga.
2. Graf tak-berhingga (unlimited graph)
Graf yang jumlah simpulnya, n, tidak berhingga banyaknya disebut graf tak-berhingga.
Berdasarkan orientasi arah pada sisi, maka secara umum graf dibedakan atas dua jenis, yaitu:
1. Graf tak-berarah (undirected graph)
Graf yang sisinya tidak mempunyai orientasi arah disebut graf tak-berarah. Graf G pada Gambar II-1 merupakan graf tak-berarah.
2. Graf berarah (directed graph atau digraph)
Graf yang setiap sisinya diberikan orientasi arah disebut sebagai graf berarah.
2.1.3 Representasi Graf
Untuk maksud pemrosesan pada graf dengan program komputer, maka graf harus direpresentasikan di dalam memori. Karena itu, terdapat beberapa representasi yang mungkin untuk graf. Representasi yang biasa digunakan adalah matriks ketetanggaan, matriks bersisian, dan senarai ketetanggaan.
1. Matriks ketetanggaan (adjacency matrix)
Matriks ketetanggaan merupakan representasi graf yang paling umum. Misalkan G=(V,E) adalah graf dengan n simpul, n ≥ 1. Matriks ketetanggaan G adalah matriks berukuran n x n. Bila matriks tersebut dinamakan A = [aij], maka
{
1, jika simpul i dan j bertetanggaaij
II-4
Karena matriks ketetanggaan hanya berisi 0 dan 1, maka matriks ini dinamakan juga matriks nol-satu. Namun, pada perkembangan selanjutnya, matriks ketetanggaan dapat juga digunakan untuk merepresentasikan graf tak-sederhana dan graf berbobot. Jika digunakan untuk merepresentasikan graf tak-sederhana, maka elemen aij pada matriks ketetanggaan sama dengan jumlah sisi yang
berasosiasi dengan (vi, vj). Jika digunakan untuk merepresentasikan graf
berbobot, maka elemen aij pada matriks ketetanggaan sama dengan bobot sisi
yang menghubungkan simpul i dan simpul j. Pada graf berbobot ini, jika tidak terdapat sisi yang menghubungkan simpul i dan simpul j, maka elemen aij pada
matriks ketetanggaannya diberi simbol tak berhingga (∞).Keuntungan representasi dengan matriks ketetanggaan adalah elemen matriksnya dapat diakses langsung melalui indeks.
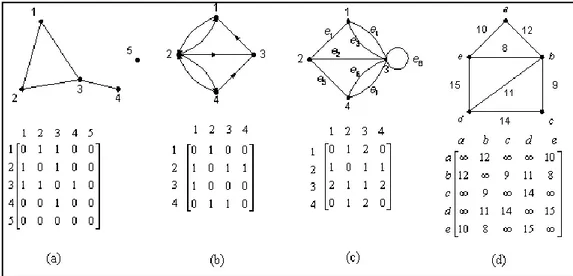
Gambar II-2 Graf (atas) dan Matriks Ketetanggaannya (bawah)
Gambar II-2 menunjukkan matriks ketetanggaan untuk empat buah jenis graf yang berbeda. Gambar II-2(a) menunjukkan matriks ketetanggan untuk graf sederhana dan tak-berarah. Gambar II-2(b) menunjukkan matriks ketetanggan untuk graf sederhana dan berarah. Gambar II-2(c) menunjukkan matriks ketetanggan untuk graf tak-sederhana. Gambar II-2(d) menunjukkan matriks ketetanggan untuk graf berbobot.
II-5
2. Matriks bersisian (incidency matrix
Matriks bersisisan menyatakan kebersisian simpul dengan sisi. Misalkan G=(V,E) adalah graf dengan n simpul dan m buah sisi. Matriks bersisian G adalah matriks berukuran n x m. Baris menunjukkan label simpul, sedangkan kolom menunjukkan label sisi. Bila matriks tersebut dinamakan A = [aij], maka
{
1, jika simpul i berisisian dengan sisi jaij
0, jika simpul i tidak bersisian dengan sisi j
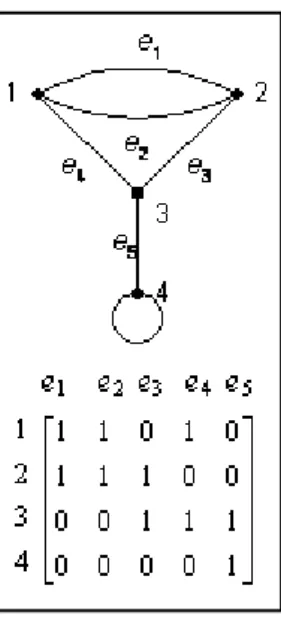
Matriks bersisian ini dapat diterapkan pada berbagai jenis graf, seperti halnya pada matriks ketetanggaan. Gambar II-3 menunjukkan matriks bersisian untuk graf yang direpresentasikannya.
Gambar II-3 Graf (atas) dan Matriks Bersisiannya (bawah)
3. Senarai ketetanggaan (adjacency list)
Senarai ketetanggaan mengenumerasi simpul-simpul yang bertetangga dengan setiap simpul di dalam graf. Sebagai contoh, senarai ketetanggaan untuk graf pada Gambar II-2 (a) adalah:
II-6 1: 2, 3 2: 1, 3 3: 1, 2, 4 4: 3 5: -
2.2 Social Network
Social network merupakan suatu kajian di bidang sosiologi yang dikembangkan pertama kali oleh Jacob L. Moreno, seorang psikiater dan ilmuwan di bidang sosial dari Universitas Harvard, pada tahun 1934. Beliau memperkenalkan istilah sociometry dan sociogram. Sociometry merupakan studi mengenai social network sedangkan sociogram merupakan graf yang merepresentasikan social network [KAD04].
Perkembangan kajian social network selanjutnya dilatarbelakangi oleh percobaan yang dilakukan oleh Stanley Milgram, seorang profesor di bidang sosiologi dari Universitas Harvard. Pada percobaan tersebut, Milgram mengirimkan seuntaian surat secara acak kepada 160 orang yang tinggal di daerah pedesaan Wichita dan Omaha, Amerika Serikat. Orang-orang tersebut diminta untuk meneruskan surat tadi kepada seorang pialang saham yang tinggal di Boston, yang alamatnya tidak diberitahukan. Penerima surat hanya diberitahu bahwa jika mereka tidak mengenal pialang saham tersebut, maka mereka harus meneruskan surat itu kepada orang lain yang menurut mereka mengenal si pialang saham tadi. Tujuan percobaan ini adalah untuk mengetahui berapa langkah yang dibutuhkan agar surat tersebut sampai ke tempat tujuan. Hasilnya, pialang saham tersebut ternyata menerima 42 surat dari 160 surat pada batas waktu yang telah ditentukan. Secara rata-rata, setiap surat diteruskan sebanyak enam kali sebelum sampai ke tangan pialang saham tadi. Percobaan yang dilakukan oleh Milgram dan para mahasiswanya pada tahun 1960 tersebut menghasilkan suatu teori yang disebut Teori Six Degrees Of Separation. Teori ini menyatakan menyatakan bahwa jika hubungan setiap orang di dunia dipetakan ke dalam graf, maka secara rata-rata setiap orang akan saling terhubung dengan panjang lintasan sebesar enam [HAM04]. Panjang lintasan merupakan banyaknya sisi yang dilalui dalam lintasan tersebut.
II-7
2.2.1 Definisi Social Network
Social network merupakan pola-pola interaksi sosial yang terjadi antar individu di dalam suatu komunitas tertentu [EHR05]. Social network biasanya digambarkan dalam bentuk graf, dimana simpul merepresentasikan aktor dan sisi merepresentasikan relasi sosial antara aktor-aktor tersebut. Aktor dapat berupa individual maupun kolektif. Contoh aktor individual adalah manusia dan hewan. Sedangkan contoh aktor kolektif adalah kelompok, organisasi, departemen, kota, dan negara. Aktor memiliki atribut-atribut yang melekat pada dirinya. Contoh atribut adalah jenis kelamin dan bidang keahlian. Selanjutnya, pada Tugas Akhir ini, penyebutan individu akan merujuk pada aktor.
Relasi sosial yang terjadi dapat bermacam-macam, antara lain [BOR92]:
1. Relasi komunikasi, misalnya siapa yang menasihati atau memberikan informasi kepada siapa.
2. Relasi resmi atau official, siapa yang “melapor” kepada siapa, atau siapa yang memimpin siapa.
3. Relasi afektif, siapa yang menyukai siapa, siapa yang mempercayai siapa, siapa yang melakukan hubungan seksual dengan siapa, atau relasi pertemanan.
4. Relasi aliran materi atau aliran kerja, misalnya siapa yang “memberikan” uang atau materi lainnya kepada siapa.
5. Relasi kognitif, misalnya siapa yang mengenal siapa.
6. Relasi afiliasi, misalnya relasi antara individu-individu yang berada dalam klub atau organisasi yang sama.
7. Relasi kekeluargaan, misalnya relasi suami-istri, ibu-anak, ayah-anak, atau kakak-adik.
Relasi sosial yang terjalin antar individu dapat lebih dari satu. Hal ini disebut sebagai multiple relationship. Sebagai contoh, dua orang individu dapat memiliki relasi resmi atau official, relasi kekeluargaan, dan relasi afektif.
Selain itu, relasi sosial dapat dikategorikan berdasarkan dua hal, yaitu bobot relasi dan arah relasi [KIL00]. Berdasarkan bobot relasi, terdapat dua jenis relasi sosial, yaitu:
1. Relasi tak-berbobot (dichotomous relation)
Relasi tak-berbobot hanya mengandung nilai 0 dan 1, sehingga sering disebut juga relasi boolean atau dichotomous relation. Nilai 0 menyatakan tidak adanya
II-8
relasi antara dua buah individu, sedangkan nilai 1 menyatakan adanya relasi antara dua buah individu. Dengan demikian penggunaan relasi tak-berbobot hanya ditujukan untuk menyatakan ada tidaknya relasi antara dua buah individu.
2. Relasi berbobot (valued relation)
Pada relasi berbobot, terdapat nilai yang menjadi bobot relasi, sehingga disebut juga valued relation. Nilai tersebut dapat merepresentasikan beberapa hal, yaitu kapasitas materi (misalnya informasi, uang, dan lain-lain) yang dialirkan, jarak antar individu, dan intensitas serta frekuensi hubungan yang terjadi [BOR92]. Berdasarkan arah relasi, terdapat dua jenis relasi sosial, yaitu:
1. Relasi berarah (directed relation)
Relasi berarah memperhatikan asal dan tujuan relasi. Contoh relasi berarah adalah relasi “menyukai”. Pada relasi menyukai, jika terdapat relasi berarah dari individu A ke individu B maka A menyukai B tetapi tidak sebaliknya.
2. Relasi tak-berarah (undirected relation)
Relasi tak-berarah tidak memperhatikan asal dan tujuan relasi. Relasi ini digunakan untuk menyatakan hubungan resiprokal, misalnya saling menyukai atau saling mengenal.
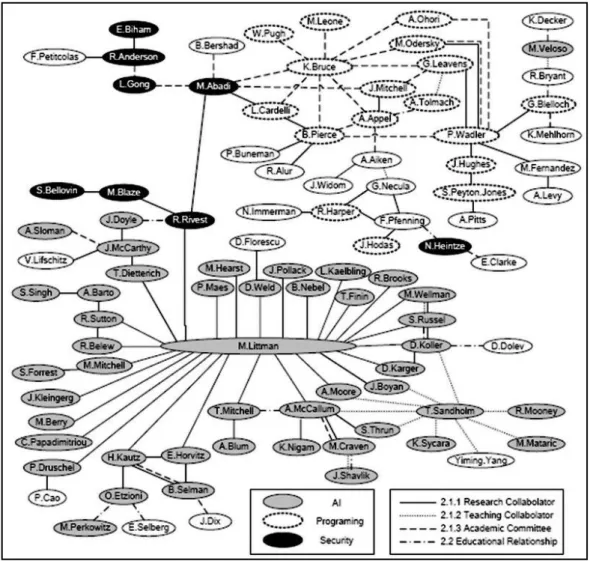
Gambar II-4 menunjukkan social network pada komunitas peneliti di bidang ilmu komputer. Gambar tersebut diambil dari [MIK04]. Dari Gambar II-4 dapat dilihat deskripsi mengenai aktor dan relasi yang telah dijelaskan sebelumnya. Aktor-aktor merupakan para peneliti yang dikelompokkan berdasarkan bidang penelitian mereka. Sedangkan relasi sosial yang terjadi meliputi relasi research collaborator, teaching collaborator, academic committee, dan educational relationship. Relasi sosial tersebut merupakan relasi tak-berbobot dan tak-berarah. Pada sociogram tersebut dapat dilihat bahwa terjadi multiple relationship.
Beberapa terminologi dasar yang sering digunakan dalam social network, antara lain:
1. Sociogram
Sociogram merupakan graf yang merepresentasikan social network. Simpul pada sociogram merepresentasikan individu sedangkan sisi pada sociogram merepresentasikan relasi sosial antar individu.
II-9
Gambar II-4 Social Network pada Komunitas Ilmu Komputer
2. Sociomatrix
Sociomatrix merupakan matriks yang merepresentasikan social network. Baris dan kolom pada matriks merupakan individu sedangkan isi sel merupakan bobot relasi, baik untuk relasi tak-berbobot maupun relasi berbobot.
3. Path
Path merupakan lintasan dalam sociogram tanpa ada simpul (individu) yang berulang.
4. Geodesic
Geodesic merupakan path terpendek antara dua buah simpul.
5. Geodesic distance
Geodesic distance merupakan jarak geodesic atau nilai lintasan terpendek antara dua buah individu.
II-10
2.2.2 Data Social Network
Sumber data yang digunakan untuk membangun social network dapat berupa dokumen terstruktur maupun dokumen yang tidak terstruktur. Contoh dokumen yang terstruktur adalah dokumen XML. Sedangkan contoh dokumen tidak terstruktur adalah dokumen web dan email. Data social network yang dihasilkan dari dokumen terstruktur dan dokumen tidak terstruktur biasanya direpresentasikan dalam sociomatrix. Sociomatrix kemudian digunakan sebagai masukan untuk membangun sociogram dan melakukan berbagai pengukuran dalam SNA.
Kelebihan dari dokumen terstruktur adalah kemudahan dalam proses ekstraksi sumber datanya. Sedangkan kelemahan dari dokumen terstruktur adalah kurangnya informasi, terbatasnya jenis relasi yang dapat diungkapkan, serta perlunya usaha tersendiri untuk menghasilkan dokumen terstruktur tersebut. Contoh usaha yang biasa dilakukan untuk mengumpulkan data masukan bagi sociogram adalah kuesioner, wawancara, maupun observasi langsung terhadap komunitas target. Pada kuesioner atau wawancara, para responden yang merupakan anggota dari suatu komunitas biasanya diberikan daftar nama seluruh anggota komunitas tersebut. Kemudian, responden diminta untuk memberikan tanda pada nama-nama dalam daftar yang memiliki hubungan dengannya. Responden juga dapat diminta untuk memberikan informasi mengenai seberapa sering mereka mengadakan kontak atau mengenai substansi interaksi sosial yang terjadi. Proyek FOAF (www.foaf-project.org) merupakan contoh usaha yang dilakukan untuk menghasilkan dokumen terstruktur. Kebanyakan perangkat lunak social network yang ada di pasaran saat ini menggunakan dokumen terstruktur sebagai sumber data untuk melakukan SNA. Perangkat lunak ini akan dibahas pada bagian 2.2.5.
Berlawanan dengan dokumen terstruktur, dokumen yang tidak terstruktur sangat kaya akan informasi sehingga dapat menghasilkan sociogram yang lebih lengkap dari segi banyaknya individu dan jenis relasi yang dapat diungkapkan. Namun, diperlukan usaha yang lebih rumit untuk mengekstrak sumber datanya. Contoh perangkat lunak social network yang menggunakan masukan berupa dokumen tidak terstruktur adalah Polyphonet [MAT06]. Polyphonet inilah yang digunakan sebagai acuan utama dalam pembangunan perangkat lunak dalam Tugas Akhir ini.
II-11
2.2.3 SNA
SNA merupakan metode-metode yang melibatkan perhitungan matematis yang menggunakan graf dan dilengkapi dengan statistik serta model aljabar [PAP06]. Teori SNA melibatkan berbagai disiplin ilmu, antara lain sosiologi, psikologi sosial, matematika, ilmu politik, komunikasi, antropologi, dan ekonomi.
2.2.3.1 Ukuran-Ukuran pada SNA
SNA memiliki beberapa ukuran dasar yang sering digunakan, yaitu centrality, betweenness, closeness, dan density. Centrality, betweenness, dan closeness merupakan pengukuran jaringan secara individual. Sedangkan density merupakan pengukuran jaringan secara kelompok. Selain ukuran-ukuran dasar di atas, masih terdapat banyak ukuran kompleks lainnya yang digunakan untuk menganalisis struktur social network lebih lanjut, misalnya centrality eigenvector, clustering coefficient, radiality, connectivity, cohesion, eigen decomposition, structural equivalence, QAP correlation, dan transitivity [BOR05a] [BOR05b]. Ukuran-ukuran tersebut sudah disediakan oleh berbagai perangkat lunak social network, misalnya UCINET. Karena itu, perangkat lunak yang dihasilkan pada Tugas Akhir ini hanya menangani ukuran-ukuran dasar SNA.
1. Centrality
Nilai centrality suatu individu merupakan banyaknya relasi langsung yang dimiliki oleh individu tersebut. Semakin tinggi nilai centrality suatu individu, semakin sentral posisinya dalam keseluruhan jaringan. Individu yang menjadi pusat dalam jaringan biasanya mudah mempengaruhi dan dipengaruhi oleh individu-individu di sekitarnya [BOR92]. Secara formal, centrality suatu individu ( ) di dalam sociomatrix X dinyatakan pada persamaan II.1.
= = (II.1)
yang dalam hal ini, ni = individu ke i
N = jumlah individu
xji = isi sel sociomatrix X baris ke i kolom ke j; sociomatrix tersebut
merupakan matriks boolean dengan nilai 0 menyatakan tidak adanya relasi dan nilai 1 menyatakan adanya relasi.
II-12
Persamaan II.1 merupakan absolute centrality. Absolute centrality tidak dapat dibandingkan dengan social network lain yang berbeda jumlah individunya. Untuk itu, persamaan II.1 harus dinormalisasi dengan cara membandingkan absolute centrality dari setiap individu dengan maksimum jumlah relasi yang mungkin dimiliki oleh seorang individu. Jika banyak individu dalam komunitas adalah N, maka maksimum jumlah relasi yang mungkin dimiliki oleh seorang individu adalah N-1. Dengan demikian, nilai centrality akan berkisar antara 0 dan 1. Centrality yang telah dinormalisasi ini disebut dengan relative centrality. Jika absolute centrality individu n adalah d(n) dan total individu adalah N maka relative centrality individu n dinyatakan pada persamaan II.2.
(II.2)
Pada sociogram yang mengandung relasi berarah, terdapat dua macam centrality, yaitu in-degree centrality dan out-degree centrality. In-degree centrality merupakan banyaknya relasi langsung yang menuju ke sebuah individu. Out-degree centrality merupakan banyaknya relasi langsung dari sebuah individu.
2. Betweenness
Betweenness bertujuan untuk mengetahui seberapa besar kemungkinan seorang individu menjadi perantara dalam hubungan setiap pasangan individu dalam jaringan. Nilai betweenness suatu individu merupakan banyaknya kehadiran individu tersebut dalam lintasan terpendek setiap pasangan individu dibandingkan dengan banyaknya lintasan terpendek setiap pasangan individu tersebut dalam jaringan. Berbeda dengan centrality, betweennes merujuk pada banyaknya relasi tidak langsung yang dimiliki oleh sebuah individu. Individu dengan nilai betweenness tertinggi biasanya merupakan individu yang sering bertindak sebagai perantara dalam jaringan. Secara formal, betweenness suatu individu ( ) dalam sociogram X dinyatakan pada persamaan II.3.
II-13
yang dalam hal ini,
ni = individu ke i; i ≠ j dan i ≠ k
gjk = jumlah geodesic dari individu j ke individu k
gjk (ni) = jumlah geodesic dari individu j ke individu k yang mengandung
individu i.
Persamaan II.3 merupakan absolute betweenness. Normalisasi terhadap persamaan II.3 dilakukan dengan cara membandingkan absolute betweenness suatu individu n dengan jumlah pasangan individu dalam komunitas tanpa kehadiran individu n tersebut. Jika banyak individu dalam komunitas adalah N, maka banyaknya pasangan individu yang mungkin tanpa kehadiran individu n adalah C(N-1, 2). Dengan demikian, nilai betweenness
akan berkisar antara 0 dan 1. Betweenness yang telah dinormalisasi ini disebut dengan relative betweenness. Jika absolute betweenness individu n adalah cB(n) dan jumlah total
individu adalah N, maka relative betweenness individu n dinyatakan pada persamaan II.4. Persamaan II.4 ini hanya berlaku bagi relasi tak-berarah.
(II.4)
3. Closeness
Closeness bertujuan untuk mengetahui seberapa dekat seorang individu dengan semua individu lainnya dalam jaringan. Nilai closeness suatu individu merupakan total geodesic distance yang menghubungkan individu tersebut dengan setiap individu dalam jaringan. Individu yang memiliki nilai closeness yang tinggi biasanya merupakan individu yang paling cepat mengetahui informasi atau isu yang sedang berkembang di komunitasnya. Selain itu, individu yang memiliki nilai closeness dan centrality yang tinggi umumnya memegang peranan sebagai pemimpin komunitas [BOR92]. Closeness merupakan invers dari centrality sehingga secara formal, closeness suatu individu ( ) dalam sociomatrix dinyatakan pada persamaan II.5.
II-14
yang dalam hal ini,
ni = individu ke i; i ≠ j
N = jumlah individu
d(ni,nj) = geodesic distance antara individu ke i dan individu ke j
Persamaan II.5 merupakan absolute closeness. Normalisasi terhadap persamaan II.5 dilakukan dengan mengalikan absolute closeness suatu individu n dengan jumlah maksimal relasi sosial yang mungkin dimiliki oleh individu n tersebut. Jika banyak individu dalam komunitas adalah N, maka jumlah maksimal relasi sosial yang mungkin dimiliki oleh individu n adalah N-1. Dengan demikian, nilai closeness akan berkisar antara 0 dan 1. Closeness yang telah dinormalisasi ini disebut dengan relative closeness. Jika absolute closeness individu n adalah cc(n) dan jumlah total individu adalah N, maka
relative closeness individu n dinyatakan pada persamaan II.6.
(II.6)
4. Density
Density menyatakan kerapatan suatu jaringan. Nilai density suatu jaringan merupakan perbandingan antara banyaknya relasi sosial yang ada dengan banyaknya relasi sosial yang mungkin dalam jaringan tersebut. Semakin terhubung suatu jaringan, semakin besar kerapatannya. Jaringan yang rapat adalah jaringan dimana terdapat banyak relasi sosial yang kuat antara anggotanya [PAP06]. Secara formal, density (∆) suatu sociomatrix X dengan jumlah individu sebanyak N dinyatakan pada persamaan II.7. Persamaan II.7 hanya berlaku untuk relasi tak-berarah.
(II.7)
yang dalam hal ini, N = jumlah individu
II-15
merupakan matriks boolean dengan nilai 0 menyatakan tidak adanya relasi dan nilai 1 menyatakan adanya relasi.
2.2.3.2 Aplikasi SNA
Seiring dengan berkembangnya bidang kajian social network, maka terdapat beberapa penelitian untuk menerapkan SNA di berbagai bidang, antara lain:
1. Pada bidang medis, Corner (2003) menerapkan teori social network untuk memodelkan penyebaran penyakit TBC melalui udara pada hewan-hewan di New Zealand. Hasilnya, penyebaran penyakit TBC tersebut dapat diprediksi melalui interaksi antara hewan-hewan tersebut [CON06].
2.
Pada bidang sosiologi, Liljeros (2001) menganalisis kelakuan seksual manusia dengan menggunakan teori social network. Hasilnya individu dalam social network yang berperan sebagai penghubung antar kelompok, cenderung tidak memilih-milih pasangannya dan cenderung menjadi tersangka utama dalam penyebaran penyakit menular seksual [CON05]. Selain itu, terdapat juga penerapan SNA untuk menganalisis kelakuan atau behavior para anggota gang di New York. Penelitian ini dilakukan oleh [PAP06]. Selanjutnya, Shaw dan McKay (1942) menerapkan SNA untuk meneliti behaviour para pelaku kejahatan. Hasil penelitiannya menunjukkan bahwa, para pelaku kejahatan biasanya bergantung pada jaringan teman-temannya untuk membantu mereka melakukan kejahatan. Para kriminal pada derah-daerah tertentu di Amerika ternyata tidak hanya berhubungan dengan para kriminal sebayanya tetapi juga dengan para kriminal yang lebih tua, yang ternyata juga memiliki hubungan dengan para kriminal yang lebih tua lagi dan seterusnya. Dari hasil penelitian ini dapat disimpulkan bahwa tradisi kejahatan diwariskan melalui generasi yang lebih tua dan generasi sebaya [ZEN06].3. Pada bidang manajemen personalia, [TAN07] menggunakan konsep SNA untuk mengatasi masalah pembentukan tim evaluasi proyek yang independen. Masalah ini terutama muncul pada proyek-proyek berskala besar yang menyerap banyak tenaga kerja, sehingga sulit untuk membentuk tim evaluasi yang benar-benar objektif dan independen dari tim proyek.
4. Pada bidang pengembangan proyek perangkat lunak, [HAH06] menerapkan SNA untuk mengamati pola pembentukan tim pengembang perangkat lunak. Penelitiannya menggunakan data proyek perangkat lunak dari SourceForge.net.
II-16
Selanjutnya, [BIR06] menerapkan SNA untuk mengetahui kaitan kelakuan para peserta proyek Open Source Software (OSS) terhadap pekerjaan pengembangan proyek perangkat lunak. Penelitiannya menggunakan aliran email dan arsip Concurrent Versioning System untuk mendeteksi pola-pola interaksi yang terjadi. Proyek OSS yang dijadikan objek penelitian adalah proyek Apache HTTP Server dan Postgres.
5. Pada bidang knowledge management, [ANK03] menerapkan SNA untuk menganalisis pola-pola relasi, aliran kerja, dan aliran informasi yang terjadi dalam suatu perusahaan. Hasil analisisnya digunakan sebagai masukan untuk pengembangan Knowledge Management System (KMS) di perusahaan. Selanjutnya, [CRO01] melakukan evaluasi efektivitas penggunaan KMS suatu perusahaan. Hasilnya, ternyata sebagian besar karyawan lebih suka mendapatkan pengetahuan langsung dari karyawan lain meskipun sudah tersedia arsip-arsip perusahaan dalam KMS tersebut. Hal ini membuktikan pentingnya integrasi SNA dalam KMS.
6. Pada bidang keamanan, [ODO06] dan [HOL01] menerapkan SNA pada sumber data yang berupa aliran pengiriman email untuk mendeteksi keberadaan akun email yang tidak sah.
7. Pada bidang pemasaran, [DOM05] membangun social network dari situs-situs knowledge-sharing. Social network yang dihasilkan digunakan sebagai masukan untuk mendesain strategi pemasaran yang memaksimumkan potensi word-of-mouth diantara para pelanggan. Berdasarkan hasil penelitian yang dilakukan, strategi pemasaran yang melibatkan interaksi antar pelanggan ini ternyata mampu menghasilkan keuntungan yang lebih banyak dibandingkan strategi pemasaran tradisional.
2.2.4 SNE dari Dokumen Web
SNE merupakan proses ekstraksi sumber data social network untuk mendapatkan sociogram maupun sociomatrix. Pada bagian ini hanya akan dibahas teknik SNE dari dokumen web karena sumber data yang digunakan pada Tugas Akhir ini adalah dokumen web.
II-17
2.2.4.1 Teknik SNE dari Dokumen Web
Secara garis besar, proses SNE meliputi penentuan daftar aktor, penentuan keterhubungan antar aktor, dan penentuan jenis relasi sosial.
1. Menentukan Daftar Aktor
Daftar nama aktor atau individu pada suatu komunitas yang akan diekstrak social network-nya dapat dikumpulkan melalui dua cara, yaitu secara manual dan secara otomatis dengan bantuan search engine. Secara manual, nama-nama individu suatu komunitas didaftarkan terlebih dahulu. Secara otomatis, hanya diperlukan minimal sebuah nama. Dari sebuah nama tersebut, kemudian dikumpulkan nama-nama lainnya dengan menggunakan search engine.
ExpandPerson(X,k)
/*mengekstrak nama individu dari halaman web yang terambil oleh
search engine*/
D GoogleTop(“X”,k)
E ExtractEntities (D)
return (E)
Algoritma II-1 Algoritma Ekstraksi Nama Individu dari Dokumen Web
Algoritma untuk mengekstrak nama individu secara otomatis ini dinyatakan dalam Algoritma II-1. GoogleTop(“X”, k) mengembalikan k dokumen teratas berdasarkan query untuk nama individu X. ExtractEntities merupakan algoritma yang digunakan untuk mengekstrak nama orang dari dokumen web. Algoritma ini tidak dijelaskan pada Tugas Akhir ini karena nama-nama individu pada Tugas Akhir ini dikumpulkan secara manual. Hal ini dapat dilihat pada bagian 1.4 nomor 4.
2. Menentukan Keterhubungan antar Aktor
Kebanyakan sistem SNE menggunakan bantuan search engine dan prinsip co-occurrence setiap pasang nama pada dokumen web untuk menentukan keterhubungan antar individu. Hal ini berdasarkan hipotesis bahwa segala informasi mengenai seseorang yang terdapat pada suatu situs merefleksikan interaksi sosial yang dimiliki orang tersebut di dalam dunia nyata [ADA03]. Demikian juga segala informasi mengenai sepasang individu pada suatu situs merefleksikan interaksi sosial yang dimiliki oleh sepasang individu tersebut.
II-18
Karena itu, prinsip co-occurrence dapat digunakan untuk menentukan ada tidaknya relasi sosial antara sepasang individu berdasarkan ”kedekatan” sepasang individu tersebut pada dokumen web.
Search engine yang digunakan bisa bermacam-macam, namun yang paling sering digunakan adalah Google. Properti Google yang digunakan dalam SNE adalah Google hit dan Google top. Google hit merupakan banyaknya dokumen yang terambil oleh Google berdasarkan query yang diberikan [ZEN04]. Google top merujuk pada dokumen-dokumen yang menempati posisi teratas atau paling relevan dengan query yang diberikan. Proses perankingan dokumen tersebut menggunakan algoritma Google page-rank yang dapat dilihat pada [BRI98].
Terkait prinsip co-occurrence, terdapat beberapa koefisien dalam bidang Information Retrieval (IR) yang dapat digunakan untuk mengukur co-occurrence antara dua buah entitas. Koefisien-koefisien tersebut adalah Matching Coefficient, Mutual Information, Dice Coefficient, Overlap Coefficient, Jaccard Coefficient, dan Cosine Coefficient. Masukan untuk setiap koefisien ini didapatkan dari hasil query ke search engine. Sistem SNE akan menggunakan salah satu dari koefisien ini untuk mengukur co-occurrence dari setiap pasang nama individu. Apabila nilai co-occurrence dari setiap pasang nama individu melebihi threshold tertentu, maka kedua individu tersebut dideteksi memiliki relasi sosial.
Rumusan koefisien-koefisien untuk mengukur co-occurrence dua buah entitas x dan y dinyatakan pada persamaan II.8, II.9, II.10, II.11, II.12, dan II.13 [MAT06].
a. Matching Coefficient
(II.8)
b. Mutual Information
II-19 c. Dice Coefficient (II.10) d. Overlap Coefficient (II.11) e. Jaccard coefficient (II.12) f. Cosine coefficient (II.13) Keterangan:
nx = banyaknya kemunculan entitas x
ny = banyaknya kemunculan entitas y
nx^y = banyaknya kemunculan entitas x dan entitas y bersama-sama
nxvy = banyaknya kemunculan entitas x atau entitas y bersama-sama
N = banyaknya dokumen dalam koleksi dokumen
Rumusan koefisien co-occurrence di atas ditujukan untuk penentuan relasi tak-berarah. Namun, beberapa dari rumusan koefiesien co-occurrence tersebut, yakni persamaan II.9, II.10, dan II.12 dapat dimodifikasi untuk penentuan relasi berarah. Menurut [TOM03], untuk menentukan relasi berarah dari simpul asal x, maka penyebut dari persamaan II.9, II.10, dan II.12 harus diganti dengan nx, dan sebaliknya.
Terdapat dua jenis parameter hasil pencarian Google yang digunakan sebagai masukan bagi koefisien co-occurrence, yaitu Google hit dan Google top document. Umumnya, sistem SNE menggunakan salah satu dari kedua parameter tersebut. Secara ringkas,
II-20
teknik SNE yang menggunakan parameter Google hit dinyatakan dalam Algoritma II-2. GoogleHit(“X”) mengembalikan banyaknya dokumen yang terambil oleh Google berdasarkan query untuk nama individu X. Sedangkan GoogleHit(“X Y”) mengembalikan banyaknya dokumen yang terambil oleh Google berdasarkan query untuk nama individu X dan Y. CoocFunction(nx, ny, nx^y) merupakan rumusan koefisien co-occurrence yang
digunakan.
GoogleCoocHit(X,Y)
/*masukan berupa nama individu X dan Y, mengembalikan co
occurrence X dan Y*/ nx GoogleHit(“X”) ny GoogleHit(“Y”) nx^y GoogleHit(“X Y”)
rx,y CoocFunction(nx, ny, nx^y) return (rx,y)
Algoritma II-2 Algoritma Co-occurrence Menggunakan Google Hit
GoogleCoocTop(X,Y,k)
/*masukan berupa nama individu X dan Y, mengembalikan
co-occurrence X dan Y */ Dx GoogleTop(“X”,k) Dy GoogleTop(“Y”,k) nx NumEntity(Dx U Dy,X) ny NumEntity(Dx U Dy,Y) nx^y NumCooc(Dx U Dy,X,Y) rx,y CoocFunction(nx, ny, nx^y) return (rx,y)
Algoritma II-3 Algoritma Co-occurrence Menggunakan Google Top.
Teknik SNE yang menggunakan parameter Google top dinyatakan dalam Algoritma II-3. GoogleTop(“X”, k) mengembalikan k dokumen teratas berdasarkan query untuk nama individu X. NumEntity(Dx U Dy, X) mengembalikan banyaknya nama individu X yang
terdapat dalam himpunan dokumen Dx U Dy. NumCooc(Dx U Dy, X,Y) mengembalikan
banyaknya kemunculan nama individu X dan individu Y secara bersama-sama di setiap dokumen dalam himpunan dokumen Dx U Dy. CoocFunction(nx, ny, nx^y) merupakan
II-21
perhitungan co-occurrence, maka dapat dibangun social network dengan menggunakan Algoritma II-4. GoogleCoocHit yang digunakan pada algoritma ini dapat diganti dengan GoogleCoocTop.
GetSocialNet(L)
/*masukan berupa daftar nama individu L, mengembalikan social
network G*/ for each X Є L
do set a node in G for each X Є L and Y Є L
do rx,y GoogleCoocHit(X,Y)
for each X Є L and Y Є L and rx,y > threshold do set an edge in G
return (G)
Algoritma II-4 Algoritma SNE Menggunakan GoogleCoocHit
3. Menentukan Jenis Relasi Sosial
Terdapat dua cara untuk menentukan jenis relasi sosial antar individu. Cara pertama adalah membuat daftar jenis relasi sosial secara manual berdasarkan domain komunitas. Cara yang kedua adalah menentukan jenis relasi sosial secara otomatis berdasarkan isi dokumen web.
a. Membuat daftar jenis relasi sosial secara manual berdasarkan domain komunitas
Pada cara yang pertama ini, ditentukan jenis relasi apa saja yang mungkin terjadi berdasarkan domain komunitas. Kemudian dibangun aturan klasifikasi bagi setiap jenis relasi sosial. Aturan klasifikasi ini lalu diterapkan pada setiap pasang individu untuk mendapatkan jenis relasi sosialnya. Dengan demikian, cara pertama ini dapat diselesaikan dengan pendekatan text classification pada dokumen web hasil query sepasang nama individu. Yang menjadi kelas target dari permasalahan text classification adalah jenis-jenis relasi sosial yang telah ditentukan sebelumnya. Algoritma penentuan relasi ini dapat dilihat pada Algoritma II-5. Classifier pada algoritma tersebut merupakan berbagai algoritma klasifikasi yang dapat digunakan, misalnya Naïve Bayes, ID3, dan SVM.
II-22
ClassifyRelation(X,Y,k)
/*masukan berupa nama sepasang individu X dan Y,
mengembalikan kelas relasi sosial */
Dx^y GoogleTop(“X Y”,k) for each d Є Dx^y
do cd Classifier(d,X,Y)
class determine on cd Є Dx^y return (class)
Algoritma II-5 Algoritma Klasifikasi Relasi Sosial
b. Menentukan jenis relasi sosial secara otomatis berdasarkan isi dokumen web
Pada cara yang kedua ini, jenis relasi sosial yang terjadi ditentukan berdasarkan banyaknya kata yang muncul pada dokumen web hasil query yang memuat dua buah nama individu. Misalnya kata yang paling banyak muncul adalah ”course”, maka disimpulkan bahwa sepasang individu tersebut memiliki relasi sosial terlibat dalam suatu mata kuliah yang sama. Pendekatan Term Frequency (TF) dan Index Document Frequency (IDF) merupakan salah satu pendekatan yang sering dilakukan pada cara kedua ini. Terkait dengan batasan masalah nomor tiga pada bagian 1.4, maka cara ini tidak dijelaskan lebih lanjut.
2.2.4.2 Sistem SNE dari Dokumen Web
Sehubungan dengan teknik SNE dari dokumen tidak terstruktur, terdapat tiga sistem SNE yang telah dikembangkan sejauh ini. Ketiga sistem tersebut membangun social network pada komunitas akademis. Tinjauan umum mengenai sistem-sistem tersebut dapat dilihat pada Tabel II-1.
Tabel II-1 Sistem Software Network Extraction dari Dokumen Web
No. Nama
Program
Penentuan Nama Individu
Penentuan Keterhubungan antar Individu
Penentuan Jenis Relasi Karakteristik Relasi Sosial Parameter search
engine (Google)
Koefisien
Co-ocurrence
1 Referral Web Otomatis Google hit dan Google top
Jaccard Coefficient
Tidak ditentukan jenis relasi sosial
Tak-berarah, berbobot 2 Flink Manual Google hit Jaccard
Coefficient Manual dengan menggunakan proyek FOAF Tak-berarah, tak-berbobot
3 Polyphonet Manual Google hit Overlap Coefficient Manual dengan pendekatan text classification Tak-berarah, tak-berbobot
II-23
2.2.5 Perangkat Lunak Social Network
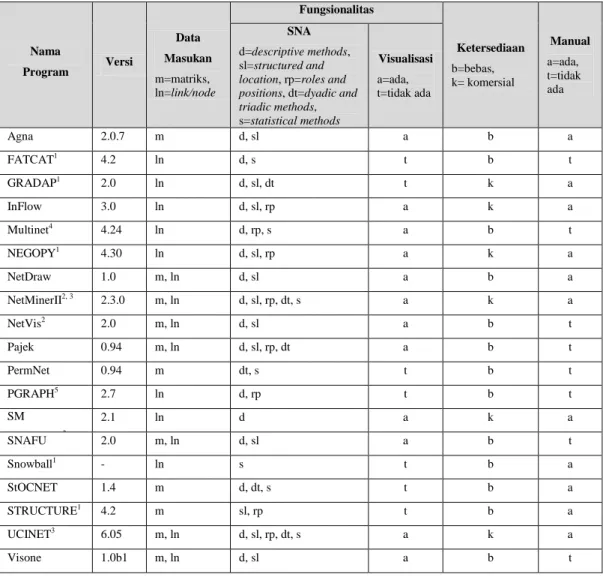
Perangkat lunak social network (social network software) merupakan aplikasi yang mampu melakukan SNE, SNA, dan visualisasinya. Secara ringkas, beberapa contoh perangkat lunak social network tersebut dapat dilihat pada Tabel II-2 [HUI03]. Perangkat lunak social network yang terdapat pada Tabel II-2 merupakan perangkat lunak yang sudah relatif stabil. Perangkat lunak tersebut menggunakan dokumen terstruktur sebagai data masukannya. Perangkat lunak-perangkat lunak tersebut umumnya telah mampu menangani berbagai ukuran SNA yang kompleks. Sebaliknya, perangkat lunak social network yang menggunakan dokumen tidak terstruktur sebagai masukannya umumnya lebih fokus pada teknik SNE daripada ukuran-ukuran SNA.
Pada Tabel II-2, setiap perangkat lunak dideskripsikan berdasarkan versi terakhir perangkat lunak, data masukan, fungsionalitas, serta ketersediaannya. Data masukan terdiri dari dua jenis, yaitu matriks, serta simpul dan sisi. Fungsionalitas perangkat lunak terdiri dari ukuran-ukuran SNA dan kemampuan visualisasi sociogram. Ukuran-ukuran SNA dibedakan menjadi empat jenis, yaitu descriptive methods, structure and location, roles and positions, dyadic and triadic methods, serta statistical methods. Contoh descriptive methods adalah centrality dan transitivity. Contoh structure and location adalah centrality, betweenness, closeness, dan cohesive subgroup. Contoh ukuran roles and positions adalah structural equivalence dan eigen decompositions. Contoh dyadid dan triadic methods adalah dyad census, mutuality, dan triad census. Sedangkan contoh statistical methods adalah QAP correlation [HUI03]. Beberapa ukuran tersebut tidak dijelaskan pada Tugas Akhir ini karena sangat kompleks dan merupakan istilah-istilah di bidang sosiologi. Berdasarkan sifat ketersediaannya, terdapat perangkat lunak yang tersedia dengan bebas dan perangkat lunak yang bersifat komersial. Dari Tabel II-2 dapat dilihat bahwa hampir semua perangkat lunak komersial menyediakan manual. Sebaliknya, tidak semua perangkat lunak bebas menyediakan manual.
Dari berbagai perangkat lunak pada Tabel II-2, UCINET (www.analytictech.com) merupakan perangkat lunak social network yang paling komprehensif dari segi fungsionalitas. UCINET juga merupakan perangkat lunak social network yang paling banyak digunakan saat ini [HUI03]. Sayangnya UCINET merupakan perangkat lunak komersial sehingga pengguna harus membayar untuk mendapatkannya. Sebagai
II-24
alternatif, Pajek (vlado.fmf.uni-lj.si/pub/networks/pajek/default.htm) merupakan perangkat lunak social network yang tersedia secara bebas dan memiliki fungsionalitas yang relatif lengkap. Akan tetapi, Pajek tidak dilengkapi dengan manual.
Tabel II-2 Perangkat Lunak Social Network
Nama Program Versi Data Masukan m=matriks, ln=link/node Fungsionalitas Ketersediaan b=bebas, k= komersial Manual a=ada, t=tidak ada SNA d=descriptive methods, sl=structured and location, rp=roles and positions, dt=dyadic and triadic methods, s=statistical methods Visualisasi a=ada, t=tidak ada Agna 2.0.7 m d, sl a b a FATCAT1 4.2 ln d, s t b t GRADAP1 2.0 ln d, sl, dt t k a InFlow 3.0 ln d, sl, rp a k a Multinet4 4.24 ln d, rp, s a b t NEGOPY1 4.30 ln d, sl, rp a k a NetDraw 1.0 m, ln d, sl a b a NetMinerII2, 3 2.3.0 m, ln d, sl, rp, dt, s a k a NetVis2 2.0 m, ln d, sl a b t Pajek 0.94 m, ln d, sl, rp, dt a b t PermNet 0.94 m dt, s t b t PGRAPH5 2.7 ln d, rp t b t SM LinkAlyzer3 2.1 ln d a k a SNAFU 2.0 m, ln d, sl a b t Snowball1 - ln s t b a StOCNET 1.4 m d, dt, s t b a STRUCTURE1 4.2 m sl, rp t b a UCINET3 6.05 m, ln d, sl, rp, dt, s a k a Visone 1.0b1 m, ln d, sl a b t Keterangan:
1 = Aplikasi berbasis DOS yang tidak dikembangkan lagi 2 = Aplikasi dapat diakses langsung dari internet secara bebas 3 = Tersedia versi demo
4 = Aplikasi hanya menyediakan manual untuk beberapa modul tertentu
5 = Aplikasi menyediakan manual setelah melalui proses registrasi manual setelah melalui proses registrasi.
II-25
Selain perangkat lunak social network, terdapat layanan social network (social network service). Layanan social network merupakan aplikasi yang berfungsi untuk memperluas social network para penggunanya. Contoh layanan social network adalah friendster (www.friendster.com), orkut (www.orkut.com), Imeem (www.imeem.com), Yahoo!360 (www.yahoo.com), dan myspace (www.myspace.com). Agar dapat menggunakan layanan tersebut, pengguna harus mendaftar terlebih dahulu. Layanan social network ini memungkinkan pengguna untuk saling membagikan informasi pribadi, foto, maupun arsip pribadi. Pengguna juga dapat mencari seorang individu tertentu dan mengetahui radius keterhubungannya dengan individu tersebut. Namun, individu yang dicari haruslah terdaftar pada aplikasi yang bersangkutan. Selain itu, layanan-layanan social network yang ada pun belum menyediakan fasilitas untuk melakukan SNA. Hal ini dikarenakan tujuan layanan social network adalah untuk memudahkan perluasan pergaulan dan sharing informasi di antara para penggunanya, bukan untuk menganalisis struktur social network yang terjadi.
2.3 Text Classification
2.3.1 Klasifikasi
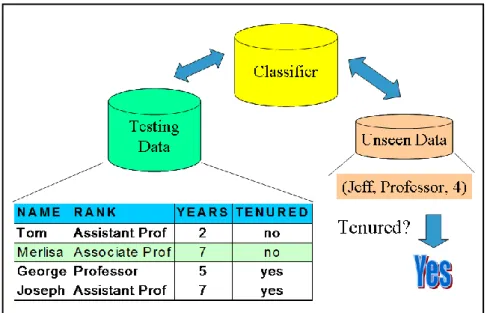
Klasifikasi merupakan proses untuk mengelompokkan sejumlah objek atau instans ke dalam kelas-kelas target yang sudah ditentukan sebelumnya. Objek atau instans dapat berupa dokumen, data relasional, dan lain-lain. Terdapat sejumlah algoritma yang dapat digunakan pada proses klasifikasi, yaitu Naïve Bayes, ID3, k-Nearest Neighbour, dan SVM.
Proses klasifikasi terdiri dari dua tahap, yaitu tahap pembelajaran dan tahap klasifikasi itu sendiri [HAN01]. Proses klasifikasi memerlukan dua jenis data, yaitu training set dan test set. Baik training set dan test set direpresentasikan dalam tupple-tupple yang memiliki pasangan atribut dan nilai. Setiap tupple pada training set dan test set telah diberikan kelas target masing-masing. Karena itu, klasifikasi tergolong dalam supervised learning [HAN01].
Tahap pembelajaran menghasilkan model klasifikasi dengan menerapkan algoritma klasifikasi tertentu pada training set. Hal ini diilustrasikan pada Gambar II-5 [HAN01].
II-26
Model klasifikasi dapat berupa aturan klasifikasi (classification rule), pohon keputusan, atau formula matematika.
Gambar II-5 Tahap Pembelajaran pada Proses Klasifikasi
Gambar II-6 Tahap Klasifikasi pada Proses Klasifikasi
Pada tahap klasifikasi, dilakukan pengujian terhadap akurasi model klasifikasi yang didapatkan dari tahap pembelajaran. Pengujian tersebut melibatkan test set. Akurasi model klasifikasi merupakan persentase data pada test set yang diklasifikasi dengan benar
II-27
oleh model klasifikasi [HAN01]. Jika nilai akurasi dapat diterima atau melebihi threshold tertentu, maka model klasifikasi tersebut dapat digunakan untuk mengklasifikasikan data yang baru, yaitu data yang kelas targetnya belum diketahui. Hal ini diilustrasikan pada Gambar II-6 [HAN01].
2.3.2 Pemilihan Atribut Klasifikasi pada Text Classification
Permasalahan yang dijumpai pada text classification adalah penentuan atribut klasifikasi (feature selection). Objek yang sering dijadikan atribut adalah kata-kata yang terdapat dalam training set. Namun, seberapa valid suatu kata dapat dijadikan atribut klasifikasi merupakan inti permasalahan feature selection. Beberapa penelitian di bidang text classification menggunakan pendekatan Mutual Information untuk menentukan atribut klasifikasi [JOA96].
Mutual Information (MI). MI merupakan pendekatan yang paling sering digunakan
untuk menentukan atribut klasifikasi dalam text classification. MI tergolong pendekatan bags-of-words, yaitu dokumen direpresentasikan sebagai vektor kata. MI menentukan kata-kata apa saja yang paling mendeskripsikan suatu kelas target tertentu. Jika terdapat sebuah kata t dan sebuah kelas target c, maka MI kata t dan kelas target c, yaitu I(t,c) dinyatakan dalam persamaan II.14. I(t,c) akan bernilai 0 jika kata t dan target kelas c bersifat independen.
(II.14)
yang dalam hal ini,
A : jumlah kemunculan kata t dalam kelas target c B : jumlah kemunculan kata t di luar kelas target c
C : jumlah kemunculan kelas target c yang tidak mengandung kata t N : jumlah total koleksi dokumen
Selain pendekatan bags-of-words, terdapat pendekatan bersifat subjektif, sesuai dengan tujuan klasifikasi. Pada Tugas Akhir ini, akan dikaji penentuan atribut klasifikasi dengan pendekatan subjektif pada Polyphonet. Atribut klasifikasi pada Polyphonet ini dikaji
II-28
karena tujuan klasifikasinya sama dengan tujuan klasifikasi pada Tugas Akhir ini, yaitu untuk menentukan jenis relasi sosial antar individu.
Tabel II-3 Kelompok Kata pada Polyphonet
Kelas
Target Kata-Kata
A Publication, paper, presentation, activity, theme, award, authors, etc
B Member, lab, group, laboratory, institute, team, etc
C Project, committee
D Workshop, conference, seminar, meeting, sponsor, symposium, etc
E Association, program, national, journal, session, etc
F Professor, major, graduate student, lecturer, etc
Pada Polyphonet, terlebih dahulu dilakukan pengelompokkan kata-kata yang paling sering muncul di setiap kelas target. Pengelompokkan tersebut berdasarkan pengukuran TF-IDF. Hasilnya berupa kelompok kata pada Tabel II-3. Pada Tabel II-3, kelas target merupakan jenis relasi sosial. Polyphonet mendeteksi empat jenis relasi sosial dari beberapa jenis relasi sosial yang diidentifikasi. Empat jenis relasi sosial yang dianggap paling dominan tersebut adalah relasi co-author, lab, proj, dan conf. Keempat jenis relasi sosial tersebut direpresentasikan berturut-turut oleh abjad A, B, C, dan D pada Tabel II-3. Sedangkan abjad E dan F merepresentasikan jenis relasi sosial lainnya yang kurang dominan [MAT06]. Selanjutnya, atribut klasifikasi pada Polyphonet didapatkan secara eksperimental hingga dicapai akurasi yang cukup tinggi. Atribut klasifikasi tersebut dapat dilihat pada Tabel II-4. Kemudian, dengan menerapkan algoritma ID3, didapatkan aturan klasifikasi pada Tabel II-5. Dengan menggunakan atribut klasifikasi pada Tabel II-4 dan aturan klasifikasi pada Tabel II-5, didapatkan rata precision sebesar 81,7% dan rata-rata recall sebesar 85,98%. Precision dan recall tersebut menunjukkan tingkat akurasi klasifikasi yang tinggi.
II-29
Tabel II-4 Atribut Klasifikasi dan Nilainya pada Polyphonet
Atribut Keterangan Nilai
NumberCo Jumlah kemunculan nama individu X dan Y zero, one, more_than_one
SameLine Apakah nama individu X dan Y muncul pada baris yang
sama pada dokumen yes, no
FreqX Frekuensi kemunculan nama individu X zero, one, more_than_two FreqY Frekuensi kemunculan nama individu Y zero, one, more_than_two
GroTitle Apakah minimal sebuah kata pada kelompok kata (A-F)
muncul pada judul dokumen
yes, no (untuk setiap
kelompok)
GroFFive Apakah minimal sebuah kata pada kelompok kata (A-F)
muncul pada lima baris pertama dokumen
yes, no (untuk setiap
kelompok)
Tabel II-5 Aturan Klasifikasi pada Polyphonet
Kelas Target
Aturan
Co-author SameLine=yes
Lab
(NumCo=more_than_one & GroTitle(D)=no & GroFFive(A)=yes & GroFFive(E)=yes) | (FreqX=more_than_two & FreqY=more_than_two & GroFFive(A)=yes & GroFFive(D)=no
Proj (SameLine=no & GroTitle(A)=no & GroFFive(F)=yes
Conf (GroTitle(A)=no & GroFFive(B)=no & GroFFive(D)=yes) | (GroFFive(A)=no & GroFFive(D)=no & GroFFive(E)=yes)
2.3.3 Algoritma Klasifikasi
2.3.3.1 Naïve Bayes
Naive Bayes diterapkan untuk tugas pembelajaran di mana setiap instans x direpresentasikan dalam bentuk konjungsi dari pasangan-pasangan atribut-nilai {a1,a2,...,an} dan terdapat fungsi target f(x) untuk mengklasifikasikan setiap instans ke
dalam kelas target tertentu. Himpunan kelas target merupakan suatu himpunan terbatas V. Pendekatan Bayesian untuk mengklasifikasikan suatu instans yang baru didapatkan dengan mencari nilai probabilitas tertinggi vMAPuntuk setiap kelas target, jika diberikan
II-30
pasangan atribut-nilai {a1,a2,...,an} yang merepresentasikan instans tersebut. Hal ini
dinyatakan dalam persamaan II.15.
(II.15)
Naive Bayes menggunakan asumsi bahwa setiap pasangan atribut-nilai tidak memiliki ketergantungan agar dapat diklasifikasikan ke dalam kelas target tertentu. Dengan demikian, probabilitas suatu instans diklasifikasikan ke dalam suatu kelas target merupakan perkalian dari probabilitas setiap pasangan atribut-nilai untuk kelas target tersebut. Berdasarkan asumsi ini, maka P(a1,a2,...,an |vj) = i P(ai|vj) [MIT97]. Dengan
mensubstitusikan P(a1,a2,...,an |vj) = i P(ai|vj) ke dalam persamaan II.15, didapatkan
rumusan Naive Bayes yang dinyatakan pada persamaan II.16. Secara ringkas, algoritma Naive Bayes dinyatakan pada Algoritma II-6.
(II.16)
yang dalam hal ini,
vNB : nilai kelas target yang dihasilkan oleh rumusan Naive Bayes
P(vj) : probabilitas suatu instans memiliki kelas target vj
P(ai| vj) : probabilitas atribut-nilai ai berada dalam kelas target vj
Naive_Bayes_Learn (examples)
/* examples merupakan training set*/ for each target value vj
P(vj) estimate P(vj)
for each attribute value ai of each attribute a P(ai|vj) estimate P(ai|vj)
Classify_New_Instance (x)
II-31
2.3.3.2 SVM
SVM merupakan teknik pembelajaran yang relatif baru dibandingkan dengan teknik lain, tetapi memiliki performansi yang lebih baik di berbagai bidang aplikasi seperti bioinformatics, pengenalan tulisan tangan, klasifikasi teks dan lain sebagainya [JOA04]. SVM merupakan teknik pembelajaran yang berdasarkan prinsip Structural Risk Minimization (SRM) [JOA04]. Prinsip SRM adalah menemukan sebuah hipotesis h dari suatu ruang hipotesis H dimana hipotesis h tersebut memiliki probabilitas kesalahan minimum pada training set S. Hipotesis-hipotesis pada H direpresentasikan dalam bentuk bidang pemisah. Implementasi SRM pada SVM menggunakan fungsi linier yang akan dibahas pada bagian 2.3.3.2.1.
2.3.3.2.1 SVM pada Linearly Separable Data
Linearly separable data merupakan data yang dapat dipisahkan secara linier. Misalkan
x ,...,1 xn
adalah data set dan yi
1,1
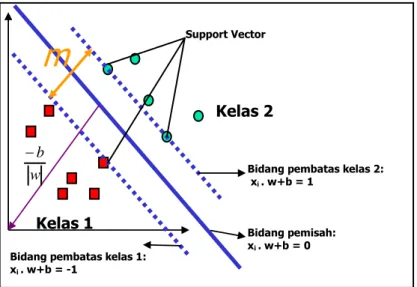
adalah kelas target dari data xi.. PadaGambar II-7 dapat dilihat berbagai alternatif bidang pemisah yang dapat memisahkan semua data set sesuai dengan kelasnya. Dari berbagai alternatif bidang pemisah tersebut, akan dicari bidang pemisah yang memiliki margin paling besar, seperti ditunjukkan pada Gambar II-8. Gambar II-7 dan Gambar II-8 diambil dari [SEM07].
Data yang berada pada bidang pembatas ini disebut support vector. Pada contoh di Gambar II-7 dan Gambar II-8, dua kelas dapat dipisahkan oleh sepasang bidang pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama sedangkan bidang pembatas kedua membatasi kelas kedua, sehingga diperoleh:
1
1
.
1
1
.
i i i iy
for
b
w
x
y
for
b
w
x
(II.17)yang dalam hal ini, w adalah normal bidang dan b adalah posisi bidang relatif terhadap pusat koordinat.
II-32
Gambar II-7 Alternatif Bidang Pemisah
Gambar II-8 Bidang Pemisah Terbaik dengan Margin m Terbesar
Dengan menggunakan lagrange multiplier, maka persoalan pencarian bidang pemisah terbaik dapat dirumuskan pada persamaan II.18.
0
,
0
.
.
.
2
1
1 1 , 1 1max
i i n i i j i j i n j i j i n i i Dy
t
s
x
x
y
y
L
(II.18)Dengan demikian, dapat diperoleh nilai
i yang nantinya digunakan untuk menemukanw. Terdapat nilai
i untuk setiap data pelatihan. Data pelatihan yang memiliki nilaiClass 1
Class 2
Class 1
Class 2
Bidang pembatas kelas 2: xi . w+b = 1 Kelas 1 Kelas 2
m
Support Vector Bidang pemisah: xi . w+b = 0 Bidang pembatas kelas 1:xi . w+b = -1 w
b
II-33
0
i
adalah support vector sedangkan sisanya memiliki nilai
i 0. Dengandemikian fungsi keputusan yang dihasilkan hanya dipengaruhi oleh support vector. Fungsi keputusan untuk mengklasifikasikan suatu data x dinyatakan pada persamaan II.19. b x x y x f i i ns i i
. ) ( 1
, (xi= support vector) (II.19)2.3.3.2.2 Multi Class SVM
Pada dasarnya, SVM hanya dapat digunakan untuk mengklasifikasi koleksi data ke dalam dua buah kelas target. Namun, terdapat penelitian lebih lanjut untuk mengembangkan SVM sehingga bisa mengklasifikasikan koleksi data yang memiliki lebih dari dua kelas target atau multi class. Multi class SVM dapat dilakukan dengan menggabungkan beberapa SVM biner.
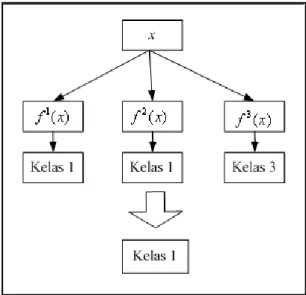
Terdapat beberapa teknik yang sering digunakan untuk mengimplementasikan multi class SVM dengan pendekatan SVM biner. Berdasarkan penelitian yang dilakukan oleh [HSU02], teknik one-against-one merupakan teknik multi class SVM yang memberikan performansi maksimum dari segi akurasi klasifikasi pada linearly separable data, waktu pelatihan dan pengujian, serta jumlah support vector. Karena itu, pada bagian ini akan dibahas mengenai teknik one-against-one.
Teknik One-against-one. Pada teknik ini, dibangun
2
1
k
k
buah model klasifikasi biner (k adalah jumlah kelas target). Setiap model klasifikasi dilatih pada data yang berasal dari dua kelas target. Setiap fungsi keputusan yang dihasilkan oleh setiap model klasifikasi tersebut digunakan untuk menentukan kelas target data yang baru dengan menggunakan metode pemungutan suara (voting) [HSU02]. Sebagai contoh, terdapat masalah klasifikasi dengan tiga buah kelas target, maka dibangun tiga buah model klasifikasi SVM biner seperti pada Tabel II-6. Contoh penggunaanya untuk memprediksi kelas target data baru dapat dilihat pada Gambar II-9.
II-34
Gambar II-9 Contoh Klasifikasi dengan Teknik One-against-one
Tabel II-6 Contoh 3 SVM Biner dengan Teknik One-against-one