APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 353
APLIKASI
K-MEANS
UNTUK PENGELOMPOKAN RUMAH TANGGA
DI SALATIGA BERDASARKAN DATA SUSENAS 2011
1Tinus Septioko1, Hanna Arini Parhusip2, Tundjung Mahatma3 1
Mahasiswa Program Studi Matematika FSM UKSW
2,3
Dosen Program Studi Matematika FSM UKSW
e-mail : [email protected],[email protected], [email protected]
Ucapan Terimakasih
Penulis ucapkan terimakasih kepada pihak-pihak yang telah membantu dan
membimbing dalam penyusunan makalah yang berjudul “ Aplikasi K-Means untuk
Pengelompokan Rumah Tangga di Salatiga Berdasarkan Data Susenas 2011” sehingga dapat terselesaikan dengan lancar. Semoga Tuhan membalas kebaikan yang telah diberikan kepada penulis dengan berkat yang melimpah.
1
354 | Proceeding for Call Paper PEKAN ILMIAH DOSEN FEB – UKSW, 14 DESEMBER 2012
APLIKASI
K-MEANS
UNTUK PENGELOMPOKAN RUMAH TANGGA
DI SALATIGA BERDASARKAN DATA SUSENAS 2011
Tinus Septioko1, Hanna Arini Parhusip2, Tundjung Mahatma3 1
Mahasiswa Program Studi Matematika FSM UKSW
2,3
Dosen Program Studi Matematika FSM UKSW
e-mail : [email protected],[email protected], [email protected]
Abstrak
Survei sosial ekonomi nasional atau yang disebut Susenas adalah survei yang dilaksanakan badan pusat statistik empat kali dalam setahun. Susenas merupakan salah satu sumber data yang diperlukan khususnya untuk perencanaan di bidang sosial ekonomi masyarakat. Susenas mengumpulkan data yang menyangkut bidang pendidikan, kesehatan, perumahan, dan sosial ekonomi lainnya. Keadaan ekonomi masyarakat dapat diketahui melalui hasil Susenas, jika tingkat ekonomi masyarakat rendah tentunya pemerintah tidak boleh tinggal diam. Dari data Susenas dapat diketahui rumah tangga ekonomi bawah, menengah, maupun ekonomi atas. Hasil ini dapat digunakan untuk patokan pemberian bantuan kepada rumah tangga ekonomi bawah.
Pengelompokan ekonomi masyarakat dapat dilakukan dengan metode clustering, dimana rumah tangga yang memiliki karakteristik yang mirip akan dikelompokkan ke dalam kelompok yang sama. Untuk mendapatkan hasil cluster yang lebih cepat dan efisien maka pada penelitian ini, dikembangkan aplikasi untuk mengelompokkan rumah tangga dari data Susenas di Salatiga tahun 2011 triwulan satu dan dua berdasarkan tingkat ekonomi, yaitu rumah tangga ekonomi atas, rumah tangga ekonomi menengah, dan rumah tangga ekonomi bawah. Pengelompokan data dilakukan menggunakan metode k-means, yaitu dengan mengelompokkan n-buah objek dengan p-dimensi ke dalam k-cluster berdasarkan jarak minimal masing-masing data ke pusat cluster. Aplikasi yang dibangun diharapkan dapat membantu untuk tujuan pengelompokan data bagi pihak-pihak yang membutuhkan.
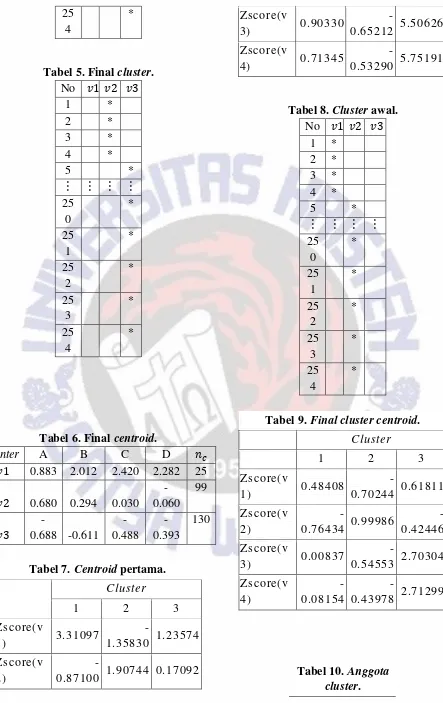
Dari hasil penelitian terhadap 254 data sampel, diperoleh tiga kelompok rumah tangga berdasarkan tingkat ekonomi, yaitu 25 rumah tangga ekonomi atas, 99 rumah tangga ekonomi menengah, dan 130 rumah tangga ekonomi bawah. Rata-rata pendapatan rumah tangga yang masuk dalam kategori rumah tangga ekonomi bawah berkisar antara 2 juta rupiah sampai 2.25 juta rupiah per bulan, sedangkan untuk pendapatan dua kategori yang lain tentunya berada diatas 2.25 juta rupiah per bulan.
Kata kunci: Susenas, cluster, K-means, ekonomi.
Abstract
APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 355 Community economic grouping to do with the method of clustering, where by households with similar characteristics will be grouped into the same group. To get the cluster more quickly and efficiently so in this study, the application was developed to classify the data Susenas households in Salatiga in 2011 quarter one and two based on an economic level, ie the upper economy household, middle class household, and the bottom economy household. Grouping of data is done using k-means clustering method, by classifying n-pieces with a p-dimensional objects into k-clusters based on a minimum distance of each data to a cluster center. Applications built is expected to help for the purpose of grouping the data for private need.
From the results of a study of 254 samples of the data, obtained by the three groups of households based on an economic level, ie 25 upper economy households, 99 middle class households, and 130 down economy household. The average household income in the lower economic category of households ranged up 2 million to 2.25 million per month, while for the other two categories of income must be above 2.25 million per month.
Kata kunci: Susenas, cluster, K-means, economy.
1. Pendahuluan
Pemberian bantuan untuk masyarakat miskin sudah banyak dilakukan, seperti raskin, BLT, dan bantuan yang lainnya. Melalui survei yang dilakukan BPS, yaitu Susenas dapat diketahui perekonomian masyarakat. Mencegah terjadinya salah sasaran pemberian bantuan, maka dari data perekonomian masyarakat, harus dikelompokkan terlebih dahulu ke dalam kelompok-kelompok ekonomi. Untuk melakukan pengolahan data dapat dilakukan dengan metode cluster. Metode
cluster adalah metode yang digunakan untuk mengelompokkan data ke dalam satu atau lebih kelompok yang mempunyai karakteristik yang mirip. Penghitungan manual akan sulit dilakukan mengingat data yang diolah tidaklah sedikit. Penghitungan manual yang lama dan rumit dapat diatasi dengan adanya program komputer. Peran komputer sebagai alat bantu pengelompokan data sangat menunjang dalam kecepatan dan ketepatan hasil. Dalam berbagai bidang, pengelompokan data banyak digunakan dengan berbagai tujuan. Dalam bidang ekonomi, clustering atau pengelompokan data digunakan untuk membuat segmen
pasar, memahami perilaku pembeli, mengenali peluang produk baru (Supranto 2004), digunakan untuk mengelompokkan saham-saham perusahaan (Mahadwartha 2002), dalam bidang pendidikan digunakan untuk memprediksi kualitas akademik siswa (Oyelade et al. 2010), Program komputer untuk pengelompokan data banyak dijumpai, namun program-program tersebut relatif memiliki memori yang besar dan susah dalam penggunaannya.
358 | Proceeding for Call Paper PEKAN ILMIAH DOSEN FEB – UKSW, 14 DESEMBER 2012
ekonomi bawah. Pada penelitian ini data yang digunakan terbatas pada data Susenas dan pebuatan program dilakukan dengan program matlab R2009a.
Program ini berdasarkan pada metode k-means clustering. K-means
merupakan salah satu metode clustering
non hirarki yang berusaha mempartisi data ke dalam satu atau lebih cluster / kelompok berdasarkan jarak minimal data ke
centroid. Metode ini mempartisi data, dimana data yang memiliki karakteristik yang mirip dikelompokkan ke dalam
cluster yang sama (Agusta 2007; Santoso 2007).
2. Analisis Cluster
Analisis cluster merupakan metode pengolahan data yang bertujuan untuk mengelompokkan data kedalam kelompok-kelompok dimana data-data yang berada dalam kelompok yang sama akan mempunyai sifat yang mirip (Agusta 2007; Santoso 2007).
2.1. K-means
K-means merupakan metode cluster
berbasis jarak yang membagi data ke dalam k-cluster, dan algoritma ini hanya bekerja pada data numerik. Pada awalnya algoritma ini mengambil sebanyak k-centroid secara random dari data, namun dalam penelitian ini penentuan centroid pertama kali diambil dari mean data sebanyak k-centroid. Hitung jarak setiap data terhadap masing-masing centroid, dalam hal ini penghitungan jarak digunakan rumus euclidean. Alokasikan data ke cluster yang memiliki jarak minimum ke centroid. Lakukan langkah tersebut hingga cluster stabil / tidak berubah.
2.2. Euclidean Distance
Untuk menghitung jarak antara data dengan centroid digunakan euclidean disatnce. Jarak dihitung menggunakan persamaan satu (Santoso 2007; Supranto 2004) :
‖ ‖
√∑ ( ) (1)
dimana
: dimensi data
2.3. Menilai Kualitas Cluster
Metode yang digunakan untuk menilai kualitas cluster dianggap ideal adalah batasan variance, yaitu dengan menghitung kepadatan cluster berupa
variance withincluster dan variance between cluster Cluster yang ideal memiliki minimum yang mempresentasikan internal homogenity
dan maksimum yang mempresentasikan external homogenity
(Saepulloh 2010).
(2) Menghitung nilai variance tiap cluster
dapat dilakukan menggunakan persamaan tiga :
∑ ( ̅̅̅) (3) dimana
: variance pada cluster ke- ,
,
: banyaknya cluster
: banyaknya data pada cluster ke-
: data ke- pada cluster ke-
̅̅̅ : rata-rata dari data pada cluster ke- Selanjutnya untuk menghitung variance within cluster (Vw) dapat dihitung dengan persamaan empat :
∑ (4)
dimana
APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 359
: banyaknya data
Variance between cluster (Vb) dihitung menggunakan persamaan lima :
∑ ( ̅̅̅ ̅) (5) dimana
̅ : rata-rata ̅̅̅ .
3. Metode Penelitian
3.1. Data
Data yang digunakan adalah data Susenas di Salatiga tahun 2011 triwulan satu dan dua, dengan 254 pengamatan dan empat variabel yang meliputi variabel banyak anggota rumah tangga (orang), pengeluaran makanan (Rp), pendapatan rumah tangga (Rp), dan pengeluaran non makanan (Rp).
3.2. Rancangan Program
Rancangan program untuk metode k-means clustering menggunakan diagram alir seperti pada gambar satu.
3.3. Uji Program
Dengan data dan metode yang sama pengujian program dilakukan dengan cara membandingkan hasil output program dengan hasil output program SPSS. Pengujian ini bertujuan untuk mengetahui apakah hasil yang didapat dengan program
k-means sudah setara dengan program-program yang lain.
4. Hasil dan Pembahasan
4.1. Implementasi Program
Uji coba dilakukan dengan menggunakan data Susenas di Salatiga tahun 2011 triwulan satu dan dua dengan 254 pengamatan dan empat variabel yang meliputi variabel banyak ART (A), konsumsi makanan (B), pendapatan (C), dan konsumsi non-makanan (D). Dari ke-4
variabel ini memiliki satuan yang berbeda sehingga tahap pertama yang dilakukan adalah standarisasi data. Data yang sudah distandarisasi kemudian digunakan untuk proses pengelompokan. Setelah didapatkan hasil cluster, sebagai pengecekan, dengan metode yang sama hasil ini dibandingkan dengan hasil penghitungan dengan program SPSS. Pengelompokan data dengan program k-means adalah sebagai berikut :
a. Menjalankan program k-means dengan Matlab, maka akan terlihat tampilan awal program, yang terlihat pada gambar dua.
>> cover_program % merupakan perintah untuk memanggil program
k-means
b. Tampilan program utama terlihat pada gambar tiga, digunakan untuk menginputkan parameter-parameter program dan prosedur program yang meliputi :
1. Banyak cluster yang dibentuk 3. 2. Buka data yang akan diproses,
dalam hal ini data Susenas Salatiga tahun 2011.
3. Lakukan proses standarisasi data. 4. Proses pengelompokan k-means. 5. Hasil pengelompokan data ke
dalam tiga kelompok dengan 254 pengamatan dapat dilihat dalam tabel hasil cluster.
360 | Proceeding for Call Paper PEKAN ILMIAH DOSEN FEB – UKSW, 14 DESEMBER 2012
pengelompokan data dengan k-means
adalah sebagai berikut :
1. Menentukan pusat cluster pertama atau
centroid awal.
Centroid pertama didekati dengan
mean dari data sebanyak k-cluster. Karena akan dibentuk tiga cluster maka
centroid yang dibentuk juga sebanyak tiga. Berikut merupakan centroid yang dibentuk :
2. Hitung jarak setiap data terhadap setiap pusat cluster.
Dengan persamaan satu dihitung jarak setiap data ke setiap centroid. Hasil penghitungan jarak ditampilkan dalam tabel tiga.
3. Data akan menjadi anggota dari cluster
yang memiliki nilai jarak terkecil dari pusat clusternya, hal ini ditampilkan dalam tabel empat.
Hitung setia centroid yang baru dari
mean data yang menjadi anggota cluster, hitung jarak setiap data ke centroid yang baru. Alokasikan setiap data ke cluster
yang memiliki jarak minimal. Ulangi langkah satu sampai tiga hingga cluster
stabil / tidak ada perubahan. Hasil akhir dari program k-means ditampilkan dalam tabel lima dan centroid akhir ditampilkan dalam tabel enam, dengan nilai sebesar 0.011655 persen, hal ini menunjukkan tingkat homogenitas hasil cluster. Hasil yang diperoleh dengan program k-means
adalah sebagai berikut :
a. Rumah tangga ekonomi atas sebanyak 25 rumah tangga, terdapat dalam
cluster satu. Terlihat dari nilai variabel
C / pendapatan 2.420 merupakan nilai paling besar dintara cluster yang lain. b. Rumah tangga ekonomi menengah
sebanyak 99 rumah tangga, terdapat dalam cluster dua, dengan nilai variabel pendapatan 0.030.
c. Rumah tangga ekonomi bawah sebanyak 130 rumah tangga, terdapat dalam cluster tiga dengan nilai variabel pendapatan terkecil yaitu -0.488.
4.2. Output SPSS
Dengan data dan metode yang sama, dengan alat bantu SPSS dilakukan proses
clustering. Centroid pertama, hasil cluster, dan centroid akhir secara berturut-turut ditampilkan dalam tabel tujuh, delapan, dan sembilan. Dalam tabel sepuluh menunjukkan banyak data yang menjadi anggota cluster yang terbentuk. Hasil
cluster akhir yang diperoleh dengan program SPSS adalah :
a. Rumah tangga ekonomi atas sebanyak 21 rumah tangga, terdapat dalam
cluster tiga, yang berdasar pada nilai Zscore(v3) 2.70304 yang merupakan nilai tertinggi dibanding dengan nilai pada cluster yang lain.
b. Rumah tangga ekonomi menengah sebanyak 127 rumah tangga, terdapat dalam cluster satu, dengan nilai Zscore(v3) sebesar 0.00837.
c. Rumah tangga ekonomi bawah sebanyak 106 rumah tangga, terdapat dalam cluster dua, dengan nilai Zscore(v3) sebesar -0.54553.
4.3. Perbandingan Hasil
APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 361
tingkat ekonomi atas ditunjukkan dalam
cluster satu. Dari hasil program k-means, sebanyak 25 rumah tangga menjadi anggota cluster satu, dan hasil SPSS sebanyak 21 rumah tangga menjadi anggota cluster satu. Rumah tangga yang menjadi anggota cluster satu ditampilkan dalam tabel 11. Dari tabel 11 terlihat bahwa rumah tangga 165, 190, 210, 230 yang menjadi anggota cluster satu dari hasil program k-means tidak menjadi anggota cluster satu dari hasil SPSS. Empat data ini menjadi anggota cluster
lain dalam hasil program k-means. Dengan cara yang sama cluster dua dan tiga dapat diketahui.
5. Kesimpulan
Berdasarkan hasil penelitian, diperoleh kesimpulan sebagai berikut : 1) Program yang telah dibangun dapat
digunakan untuk mengelompokkan rumah tangga berdasarkan tingkat perekonomian (ekonomi atas, menengah, dan bawah). Program hanya dapat digunakan untuk data numerik.
2) Dari program k-means didapat 25 rumah tangga ekonomi atas, 99 rumah tangga ekonomi menengah, dan 130 rumah tangga ekonomi bawah.
3) Dari SPSS didapat 21 rumah tangga ekonomi atas, 127 rumah tangga ekonomi menengah, dan 106 rumah tangga ekonomi bawah.
4) Perbedaan hasil program k-means dan SPSS terjadi karena perbedaan inisialisasi centroid pertama. Metode
k-means sangat sensitif terhadap inisialisasi centroid awal, sehingga hasil cluster yang dihasilkan berbeda. 5) Berdasarkan data, sebagian besar
penduduk Salatiga berekonomi menengah ke bawah.
6)
6. Daftar Pustaka
Agusta, Yudi. 2007. K-means -Penerapan, Permasalahan dan Metode Terkait. Jurnal Sistem dan Informatika Vol.3 : 47 - 60.
Bandan Pusat Statistik. 2010. Survei Sosial Ekonomi Nasional [SUSENAS Juli 2010] (Pedoman Pencacahan KOR). Jakarta : Badan Pusat Statistik.
Mahadwartha, P.A. 2002. Analisis
Cluster Saham-Saham
Berdasarkan Nisbah Profitabilitas Di Masa Kritis. Jurnal Ekonomi dan Bisnis Dian Ekonomi VIII/2.
O.J.Oyelade, O.O.Oladipupo, dan I.C.Obagbuwa. 2010. Aplication of K-meansClustering Algorithm
for Prediction of Students’
Academic Performance. International Journal of Computer Science and Information Security, Vol. 7, No. 1.
Saepulloh, D. 2010. Analisis Data Mining K-means cluster analysis Untuk Menentukan Data Berjenis
Biner (Studi Kasus
Pengelompokan Rumah Tangga Sasaran (RTS) Bantuan Langsung Tunai (BLT))(Tesis).
Bandung : Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Padjadjaran.
Santoso, B. 2007. DATA MINING : Teknik Pemanfaatan Data untuk Keperluan Bisnis, Edisi Pertama. Yogyakarta : Graha Ilmu.
362 | Proceeding for Call Paper PEKAN ILMIAH DOSEN FEB – UKSW, 14 DESEMBER 2012 LAMPIRAN GAMBAR
1. Gambar 1. Diagram alir program k-means. 2. Gambar 2. Tampilan awal program k-means. 3. Gambar 3. Tampilan program k-means.
4. Gambar 4. Hasil cluster program k-means dan SPSS.
LAMPIRAN TABEL
1. Tabel 1. Data asli.
2. Tabel 2. Data standarisasi. 3. Tabel 3. Jarak data ke centroid. 4. Tabel 4. Hasil cluster.
5. Tabel 5. Final cluster. 6. Tabel 6. Final centroid. 7. Tabel 7. Centroid pertama. 8. Tabel 8. Cluster awal.
9. Tabel 9. Final cluster centroid. 10. Anggota cluster.
11. Anggota cluster 1.
Tentukan banyak cluster k
Tentukan
Centroid
Hitung jarak objek dengan
Centroid
Alokasikan objek (minimum
jarak)
konvergen Buka file data
Standarisasi data Start
End Ya Tidak
Gambar 1. Diagram alir program k-means.
APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 363 Gambar 3. Tampilan program k-means.
Gambar 4. Hasil cluster k-means dan SPSS.
Tabel 1. Data asli.
No. A B C D 1 5 1759864 2705000 824383 2 5 1783285 3364333 1418616 3 3 1346142 6040000 4297650 4 4 1118571 3353000 1936733 5 3 774857 1426333 773483
250 3 572785 4266667 3440916 251 1 867857 4674000 3587168 252 2 525642 3566667 2613668 253 1 460714 1571933 1342584 254 1 1075714 1766667 689000
Tabel 2. Data standarisasi.
No A B C D 1 0.717 0.499 -0.356 -0.548
2 0.717 0.527 -0.197 -0.373 3 -0.321 0.0189 0.448 0.473 4 0.198 -0.246 -0.200 -0.221 5 -0.321 -0.645 -0.664 -0.563
250 0.198 -0.704 -0.502 -0.424 251 -0.321 -0.880 0.020 0.221 252 -1.358 -0.537 0.119 0.264 253 -0.840 -0.935 -0.148 -0.022
254
-1.3583 -1.011 -0.629 -0.396
Tabel 3. Jarak data ke centroid.
No
1 1.078 0.920 1.380 2 0.919 0.788 1.336 3 0.663 0.842 0.879 4 0.631 0.450 0.552 5 1.403 1.257 0.791
250 1.138 1.132 0.739 251 1.652 1.712 1.155 252 1.496 1.475 0.856 253 2.110 2.054 1.389 254 1.863 1.809 1.203
Tabel 4. Hasil cluster.
No 1 * 2 * 3 * 4 *
5 *
25 0
*
25 1
*
25 2
*
25 3
*
25
99 130
21 127
106
0 50 100 150
1 2 3
B
an
y
ak
ru
m
ah
tan
g
g
a
Cluster
Hasil Cluster
364 | Proceeding for Call Paper PEKAN ILMIAH DOSEN FEB – UKSW, 14 DESEMBER 2012
25 4
*
Tabel 5. Final cluster.
No 1 * 2 * 3 * 4 *
5 *
25 0
*
25 1
*
25 2
*
25 3
*
25 4
*
Tabel 6. Final centroid.
Center A B C D
0.883 2.012 2.420 2.282 25
0.680 0.294 0.030 -0.060
99
-0.688 -0.611 -0.488
-0.393
130
Tabel 7. Centroid pertama.
Cluster
1 2 3
Zscore(v
1) 3.31097
-1.35830 1.23574
Zscore(v 2)
-0.87100 1.90744 0.17092
Zscore(v
3) 0.90330
-0.65212 5.50626
Zscore(v
4) 0.71345
-0.53290 5.75191
Tabel 8. Cluster awal.
No 1 *
2 * 3 * 4 * 5 *
25 0
*
25 1
*
25 2
*
25 3
*
25 4
*
Tabel 9. Final cluster centroid.
Cluster
1 2 3
Zscore(v
1) 0.48408
-0.70244 0.61811
Zscore(v 2)
-0.76434 0.99986
-0.42446
Zscore(v
3) 0.00837
-0.54553 2.70304
Zscore(v 4)
-0.08154
-0.43978 2.71299
APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 365
Tabel 11. Anggota cluster 1. Cluster 1
LAMPIRAN DATA SUSENAS SALATIGA 2011
APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 367 89 6 1,786,28 3,399,00 1,419,03
368 | Proceeding for Call Paper PEKAN ILMIAH DOSEN FEB – UKSW, 14 DESEMBER 2012 13 3 1,327,07 2,191,66 1,022,86
370 | Proceeding for Call Paper PEKAN ILMIAH DOSEN FEB – UKSW, 14 DESEMBER 2012 21 2 1,759,71 11,566,6 8,887,23
APLIKASI K-MEANS...( Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma) 371
24
0 1 637,714
6,500,00 0
5,312,26 7 24
1 1 377,142
1,150,00
0 851,366 24
2 1 642,857
3,056,66 7
2,318,63 3 24
3 1 811,714
1,677,33
3 861,333 24
4 1
1,422,85 7
4,670,33 3
3,172,73 3 24
5 4
1,191,42 8
4,936,00 0
3,152,33 6 24
6 4
1,681,71 4
12,466,6 67
10,403,6 83 24 4 1,168,71 2,341,66 1,093,17
7 4 7 3
24
8 5
1,305,21 4
3,900,00 0
2,078,15 3 24
9 4 724,285
2,100,00 0
1,246,42 0 25
0 3 572,785
4,266,66 7
3,440,91 6 25
1 1 867,857
4,674,00 0
3,587,16 8 25
2 2 525,642
3,566,66 7
2,613,66 8 25
3 1 460,714
1,571,93 3
1,342,58 4 25
4 1
1,075,71 4
1,766,66