LAPORAN RESMI
PRAKTIKUM DATA MINING
CLUSTERING
DISUSUN OLEH: KELOMPOK C.23
ARIF RAKHMANTO (08 522 200) CATUR HERMAWANTO (08 522 210)
LABORATORIUM DATA MINING
JURUSAN TEKNIK INDUSTRI
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS ISLAM INDONESIA
2010
ABSTRAKS
Analisis cluster merupakan salah satu teknik multivariat dalam data mining yang bertujuan untuk mengidentifikasi sekelompok obyek dengan kemiripan karakteristik tertentu yang dapat dipisahkan dengan kelompok obyek lainnya, sehingga obyek yang berada dalam kelompok yang sama relatif lebih homogen (sama) daripada obyek yang berada pada kelompok yang berbeda. Metode yang digunakan dalam peneliatian ini adalah metode hirarki. Dan dari hasil penelitian yang dilakukan terbentuk 3 cluster dan 1 outlier.
BAB I
PENDAHULUAN
1.1 Latar Belakang masalah
Laboratorium Data Mining merupakan salah satu lab. yang dibuat oleh UII yang ditujukan kepada mahasiswa jurusan teknik industri. Namun mahasiswa biasanya datang ke laboratorium hanya untuk melaksanakan praktikum saja. Padahal laboratorium tersebut dibuat tidak hanya untuk keperluan praktikum. Maka dengan penelitian yang dilakukan akan diketahui profilisasi mahasiswa yang berkunjung ke laboratorium data mining. Profilisasi tersebut berisi jenis kelamin, usia, angkatan, intensitas, dan durasi atau berapa lama biasanya responden tersebut berada di laboratorium.
1.2 Rumusan Masalah
1. Berapa cluster yang terbentuk dari penelitian yang dilakukan ? 2. Bagaimana hasil profilisasi customer berdasarkan penelitian ?
1.3 Batasan Masalah
1. Penelitian dikhususkan pada mahasiswa Teknik Industri. 2. Obyek lokasi penelitian adalah Laboratorium Data Mining.
1.4 Tujuan penelitian
1. Untuk mengetahui berapa banyak cluster yang akan terbentuk dari penelitian yang dilakukan.
2. Untuk mengetahui hasil profilisasi customer berdasarkan penelitian.
1.5 Manfaat Penelitian
Penelitian ini bermafaat untuk mengetahui apakah laboratorium data mining perlu meningkatkan pelayanan, mengatur ulang tata letak dan menambah fasilitas atau tidak. Manfaat lainnya adalah untuk mengetahui presentase angkatan berapa yang rata – rata mengambil praktikum data mining.
BAB II
LANDASAN TEORI
Analisis cluster merupakan salah satu teknik multivariat yang digunakan dalam data mining yang bertujuan untuk mengidentifikasi sekelompok obyek yang mempunyai kemiripan karakteristik tertentu yang dapat dipisahkan dengan kelompok obyek lainnya, sehingga obyek yang berada dalam kelompok yang sama relatif lebih homogen (sama) daripada obyek yang berada pada kelompok yang berbeda.
Jumlah kelompok yang dapat diidentifikasi tergantung pada banyak dan variasi data obyek. Tujuan dari pembentukan cluster ini adalah untuk analisis dan interpretasi lebih lanjut sesuai dengan tujuan penelitian yang dilakukan. Solusi cluster secara keseluruhan bergantung pada variabel-variabel yang digunakan sebagai dasar untuk menilai kesamaan. Penambahan atau pengurangan variabel-variabel yang relevan dapat mempengaruhi substansi hasil analisis cluster.
Analisis cluster dapat diterapkan pada bidang apa saja. Namun pemakaian teknik ini lebih familiar pada bidang pemasaran karena memang salah satu kegiatan yang dilakukan dalam pemasaran adalah pengelompokan, yang disebut segmentasi pasar. Penerapan analisis cluster di dalam pemasaran adalah sebagai berikut :
1. Membuat segmen pasar (segmenting the market)
Pelanggan atau pembeli sering diklasterkan berdasarkan manfaat atau keuntungan yang diperoleh dari pembelian barang. Setiap cluster akan terdiri dari pelanggan/pembeli yang relatif homogen, dinyatakan dalam manfaat yang dicari. 2. Memahami perilaku pembeli
Analisis cluster digunakan untuk mengenali/mengidentifikasi kelompok pembeli yang homogen/relatif homogen. Kemudian perilaku dalam untuk setiap kelompok perlu dikaji secara terpisah. Responden (pembeli) dikelompokkan didasarkan pada self-reported importance yang terkait pada setiap faktor pilihan yang digunakan untuk memilih toko atau mall di mana para pembeli membeli barang yang dibutuhkan.
3. Mengenali peluang produk baru
Dengan mengklasterkan merk dan produk, competitive set di dalam pasar bisa ditentukan. Merek di dalam klaster yang sama bersaing sengit satu sama lain, daripada merek dari klaster lain.
BAB III
METODOLOGI PENELITIAN
3.1 Lokasi Penelitian
Laboratorium Data Mining Teknik Industri FTI UII
3.2 Objek Penelitian
Mahasiswa teknik industri UII
3.3 Metode Pengumpulan Data
1. Data Primer
Data primer merupakan data yang didapatkan oleh peneliti langsung dari objeknya. Yang menjadi data primer dalam penelitian ini adalah data yang berasal dari kuisioner yang diisi langsung oleh para responden.
2. Data Sekunder
Data sekunder adalah data yang didapatkan setelah dilakukan proses analisa dan interpretasi terhadap data – data primer atau data – data yang telah ada sebelumnya sesuai dengan tujuan penelitian.. Yang merupakan data sekunder pada penelitian ini adalah data – data yang telah diclustering menggunakan metode hirarki dan memakai software SPSS.
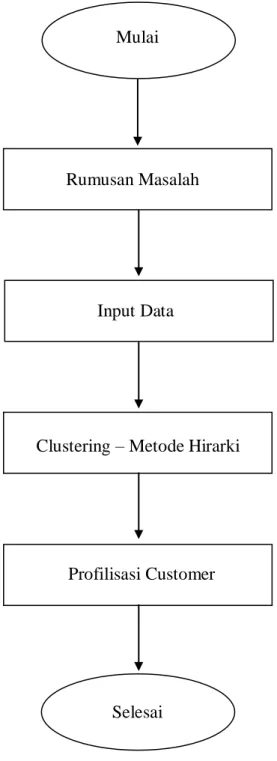
3.4. Flowchart Penelitian
Mulai
Rumusan Masalah
Input Data
Clustering – Metode Hirarki
Profilisasi Customer
Selesai
3.5. Langkah Software
Kuisioner Tingkat Kepuasan
1. Input data yang diperoleh ke software
2. Pilih analyze klik Clasify lalu pilih Hirarchical Cluster 3. Variabel : Letakkan semua Variabel X yang valid 4. Label case by : Letakkan nama responden
5. Cluster : Case
6. Display : statistic, plot
7. Statistik : agglomeration schedule 8. Plots : klik Dendogram
9. I ccicle : none
10. Method : Cluster Method Pilih nearest neighbor measure Interval pilih Squared Euqliden Distance
11. Klik save
Cluster membership : none
Kuisioner Profilisasi Customer
1. Input data yang diperoleh ke software
2. Pilih analyze klik Descriptive Statistics lalu pilih Crosstabs 3. Row : Letakkan semua variable Y yang valid
4. Column : Letakkan Cluster Member 5. Exact : Asymptotic only
6. Statistics : Correlations
7. Cells : Counts klik observed, Noninteger Weights klik Round Cells Counts
8. Format : Row Order klik Ascending 9. Klik OK
BAB IV
PENGUMPULAN DAN PENGOLAHAN DATA
4.1. Pengumpulan Data
Hasil Rekapitulasi Kuesioner Profilisasi Customer
Tabel 4.1 Rekapitulasi Kuesioner Profilisasi Customer
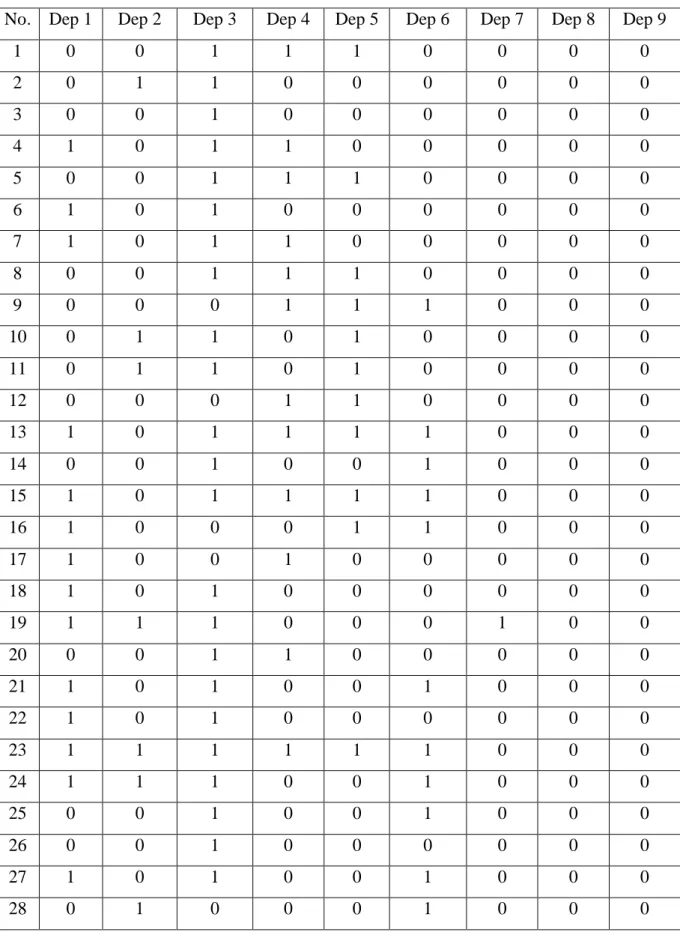
No. Nama Jenis
Kelamin Usia Angkatan Intensitas Durasi
1 Sekar 2 3 2 3 4 2 Hendia V. R 2 3 2 2 3 3 Huda 1 2 2 4 3 4 Annisa 2 3 2 4 2 5 Fitra 1 3 2 4 2 6 Fandi 1 2 2 3 2 7 Maro 2 2 2 3 2 8 Ikhsan 1 3 2 3 3 9 Aya' 2 3 2 4 1 10 Mabok 1 3 2 3 4 11 Richo 1 3 3 4 1 12 Atlit 2 3 2 3 3 13 Digdoyo 1 2 3 4 1 14 Sigit 1 3 2 2 4 15 Anestia 2 3 2 2 4 16 Ayu 2 3 2 1 4 17 Ryan 1 3 2 1 4 18 Fauzi 1 3 2 1 4 19 Dika Oki 1 3 1 2 1 20 Hendi 1 3 2 2 1 21 Kristin 2 3 2 1 4 22 Farikh 1 2 3 4 1 23 Adit 1 3 1 1 4 24 Nunuk 1 3 1 4 1
No. Nama Jenis
Kelamin Usia Angkatan Intensitas Durasi
25 Wanda 1 3 1 4 1 26 Trisno 1 3 2 4 1 27 Rizki D.K. 1 3 1 1 3 28 Himawan 1 3 1 2 4 29 Omiyabi 1 3 1 2 3 30 Laskar Kesatria 1 3 1 2 3 31 Ibnu Herlino 1 3 2 3 4 32 Chanifa Yunani 2 2 3 4 3 33 Tomy 1 3 2 2 2 34 Safri Halimi 1 3 2 4 1 35 Rozaq 1 3 2 1 4 36 Lenny Octaviani 2 2 2 3 3 37 Nurul Luklu 2 3 2 3 4 38 Abdul Hafith 1 3 2 1 4 39 Syarif 1 3 2 2 3 40 Novi 2 2 2 3 3 41 Kidhut 1 3 2 1 4 42 Vivialita 2 3 2 3 3 43 Arfiana 2 3 2 4 3 44 Maya 2 3 2 2 2 45 Karen 2 3 2 4 1 46 Didit 1 3 2 3 3 47 Tasya 2 3 2 3 1 48 Tyas 2 3 2 4 2 49 Jusman Bieber 1 3 1 2 4 50 Galih 1 3 2 3 2
Hasil Rekapitulasi Kuesioner Tingkat Kepuasan
Tabel 4.2 Rekapitulasi Kuesioner Tingkat Kepuasan
No Nama Fasilitas Pelayanan Tata Letak Kenyamanan
1 Sekar 3 3 4 3 2 Hendia V. R 3 2 3 4 3 Huda 3 3 4 4 4 Annisa 2 3 3 3 5 Fitra 3 3 3 2 6 Fandi 2 2 2 1 7 Maro 2 2 2 2 8 Ikhsan 2 2 3 2 9 Aya' 2 3 3 2 10 Mabok 2 2 2 2 11 Richo 2 3 2 2 12 Atlit 3 3 4 4 13 Digdoyo 2 3 2 2 14 Sigit 2 2 3 3 15 Anestia 2 3 3 2 16 Ayu 1 2 1 3 17 Ryan 2 2 3 3 18 Fauzi 2 2 1 3 19 Dika Oki 1 2 2 3 20 Hendi 2 2 3 3 21 Kristin 1 2 1 3 22 Farikh 2 1 2 3 23 Adit 2 2 2 1 24 Nunuk 2 2 3 2 25 Wanda 2 3 3 3 26 Trisno 1 2 2 1 27 Rizki D.K. 2 3 2 3 28 Himawan 2 3 2 2 29 Omiyabi 2 3 2 1
No Nama Fasilitas Pelayanan Tata Letak Kenyamanan 30 Laskar Kesatria 2 3 2 2 31 Ibnu Herlino 2 2 2 2 32 Chanifa Yunani 2 2 2 2 33 Tomy 2 2 3 2 34 Safri Halimi 2 2 2 2 35 Rozaq 1 2 3 1 36 Lenny Octaviani 3 2 3 2 37 Nurul Luklu 2 2 2 2 38 Abdul Hafith 2 3 1 1 39 Syarif 2 2 2 2 40 Novi 2 2 2 2 41 Kidhut 1 1 1 1 42 Vivialita 3 4 3 3 43 Arfiana 3 3 3 3 44 Maya 3 2 3 2 45 Karen 3 3 3 3 46 Didit 3 3 3 2 47 Tasya 2 2 4 4 48 Tyas 3 2 2 2 49 Jusman Bieber 2 3 3 3 50 Galih 2 2 2 1
4.2. Pengolahan Data
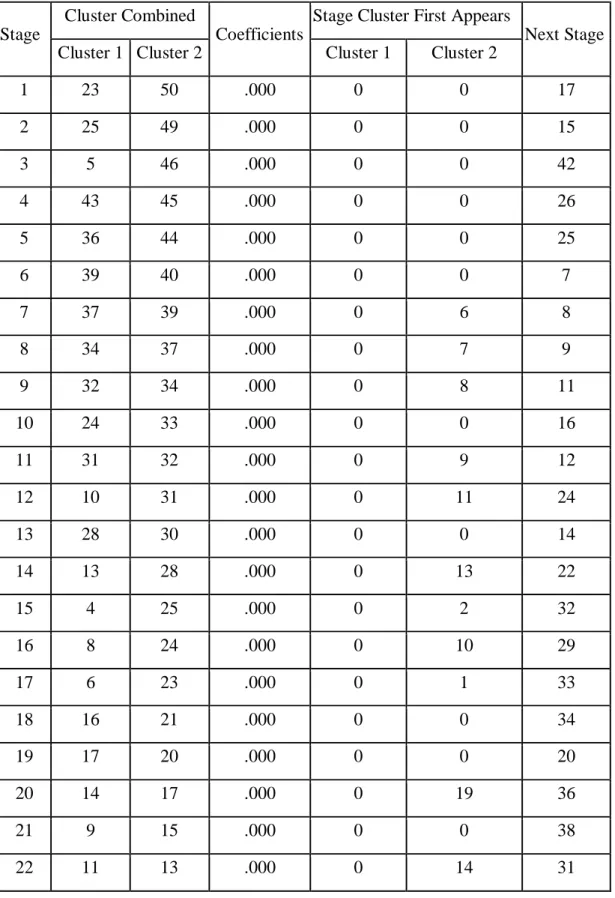
4.2.1. Metode Hirarki a. Stage
Tabel 4.3 Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 23 50 .000 0 0 17 2 25 49 .000 0 0 15 3 5 46 .000 0 0 42 4 43 45 .000 0 0 26 5 36 44 .000 0 0 25 6 39 40 .000 0 0 7 7 37 39 .000 0 6 8 8 34 37 .000 0 7 9 9 32 34 .000 0 8 11 10 24 33 .000 0 0 16 11 31 32 .000 0 9 12 12 10 31 .000 0 11 24 13 28 30 .000 0 0 14 14 13 28 .000 0 13 22 15 4 25 .000 0 2 32 16 8 24 .000 0 10 29 17 6 23 .000 0 1 33 18 16 21 .000 0 0 34 19 17 20 .000 0 0 20 20 14 17 .000 0 19 36 21 9 15 .000 0 0 38 22 11 13 .000 0 14 31
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
23 3 12 .000 0 0 44 24 7 10 .000 0 12 37 25 36 48 1.000 5 0 29 26 42 43 1.000 0 4 27 27 1 42 1.000 0 26 42 28 29 38 1.000 0 0 31 29 8 36 1.000 16 25 36 30 26 35 1.000 0 0 33 31 11 29 1.000 22 28 37 32 4 27 1.000 15 0 41 33 6 26 1.000 17 30 40 34 16 19 1.000 18 0 35 35 16 18 1.000 34 0 48 36 8 14 1.000 29 20 38 37 7 11 1.000 24 31 39 38 8 9 1.000 36 21 39 39 7 8 1.000 37 38 40 40 6 7 1.000 33 39 41 41 4 6 1.000 32 40 43 42 1 5 1.000 27 3 43 43 1 4 1.000 42 41 44 44 1 3 1.000 43 23 45 45 1 47 2.000 44 0 46 46 1 41 2.000 45 0 47 47 1 22 2.000 46 0 48
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
48 1 16 2.000 47 35 49
b. Dendogram
Dendrogram using Single Linkage
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25 Label Num +---+---+---+---+---+ Adit 23 ─┐ Galih 50 ─┼───────────────────────┐ Fandi 6 ─┘ │ Trisno 26 ─────────────────────────┤ Rozaq 35 ─────────────────────────┤ Syarif 39 ─┐ │ Novi 40 ─┤ │ Nurul Lu 37 ─┤ │ Safri Ha 34 ─┤ │ Chanifa 32 ─┤ │ Ibnu Her 31 ─┤ │ Mabok 10 ─┼───────────────────────┤ Maro 7 ─┘ │ Himawan 28 ─┐ │ Laskar K 30 ─┤ │ Digdoyo 13 ─┼───────────────────────┤ Richo 11 ─┘ │ Omiyabi 29 ─────────────────────────┤ Abdul Ha 38 ─────────────────────────┤ Aya' 9 ─┬───────────────────────┤ Anestia 15 ─┘ │ Ryan 17 ─┐ │ Hendi 20 ─┼───────────────────────┤ Sigit 14 ─┘ │ Nunuk 24 ─┐ │ Tomy 33 ─┼───────────────────────┤ Ikhsan 8 ─┘ │ Lenny Oc 36 ─┬───────────────────────┤ Maya 44 ─┘ │ Tyas 48 ─────────────────────────┤ Wanda 25 ─┐ │ Jusman B 49 ─┼───────────────────────┤ Annisa 4 ─┘ │ Rizki D. 27 ─────────────────────────┤ Fitra 5 ─┬───────────────────────┼───────────────────────┐ Didit 46 ─┘ │ │ Arfiana 43 ─┬───────────────────────┤ │ Karen 45 ─┘ │ │ Vivialit 42 ─────────────────────────┤ │ Sekar 1 ─────────────────────────┤ │ Huda 3 ─┬───────────────────────┘ │ Atlit 12 ─┘ │ Tasya 47 ─────────────────────────────────────────────────┤ Kidhut 41 ─────────────────────────────────────────────────┤ Farikh 22 ─────────────────────────────────────────────────┤ Ayu 16 ─┬───────────────────────┐ │ Kristin 21 ─┘ │ │ Dika Oki 19 ─────────────────────────┼───────────────────────┤ Fauzi 18 ─────────────────────────┘ │ Hendia V 2 ─────────────────────────────────────────────────┘ Gambar 4.1 Dendogram
c. Cluster
Tabel 4.4 Cluster
Cluster 1 Cluster 2 Cluster 3 Cluster 4 (outlier)
Adit Tasya Ayu Hendia V.
Galih Kidhut Kristin Fandi Farikh Dika Oki
Trisno Fauzi Rozaq Syarif Novi Nurul Luklu Safri Halimi Chanifa Ibnu Herlino Mabok Maro Himawan Laskar Kesatria Digdiyo Richo Omiyabi Abdul Hafit Aya’ Anestia Ryan Hendi Sigit Nunuk Tomy Ikhsan Lenny Oktaviani Maya
Cluster 1 Cluster 2 Cluster 3 Cluster 4 (outlier) Tyas Wanda Jusman Beiber Annisa Rizki D Didit Arfiana Karen Vivialita Sekar Huda Atlit
4.2.2. Profilisasi Customer
Tabel 4.5 Jenis Kelamin * Cluster Member Cluster Member
Total
1 2 3 4
Jenis Kelamin Laki - laki Count 27 2 2 0 31
% of Total 54.0% 4.0% 4.0% .0% 62.0%
Perempuan Count 15 1 2 1 19
% of Total 30.0% 2.0% 4.0% 2.0% 38.0%
Total Count 42 3 4 1 50
% of Total 84.0% 6.0% 8.0% 2.0% 100.0%
Tabel 4.6 Usia * Cluster Member Cluster Member
Total
1 2 3 4
Usia 17 - 19 tahun Count 7 1 0 0 8
% of Total 14.0% 2.0% .0% .0% 16.0%
20 -22 tahun Count 35 2 4 1 42
% of Total 70.0% 4.0% 8.0% 2.0% 84.0%
Total Count 42 3 4 1 50
% of Total 84.0% 6.0% 8.0% 2.0% 100.0%
Tabel 4.7 Angkatan * Cluster Member Cluster Member Total 1 2 3 4 Angkatan <= 2007 Count 8 0 1 0 9 % of Total 16.0% .0% 2.0% .0% 18.0% 2008 Count 31 2 3 1 37 % of Total 62.0% 4.0% 6.0% 2.0% 74.0% 2009 Count 3 1 0 0 4 % of Total 6.0% 2.0% .0% .0% 8.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0%
Tabel 4.8 Intensitas * Cluster Member Cluster Member
Total
1 2 3 4
Intensitas Sangat Sering Count 5 1 3 0 9
% of Total 10.0% 2.0% 6.0% .0% 18.0% Sering Count 10 0 1 1 12 % of Total 20.0% .0% 2.0% 2.0% 24.0% Sedang Count 13 1 0 0 14 % of Total 26.0% 2.0% .0% .0% 28.0% Jarang Count 14 1 0 0 15 % of Total 28.0% 2.0% .0% .0% 30.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0%
Tabel 4.9 Durasi * Cluster Member Cluster Member
Total
1 2 3 4
Durasi <= 15 menit Count 9 2 1 0 12
% of Total 18.0% 4.0% 2.0% .0% 24.0% 16 - 30 menit Count 8 0 0 0 8 % of Total 16.0% .0% .0% .0% 16.0% 30 - 60 menit Count 13 0 0 1 14 % of Total 26.0% .0% .0% 2.0% 28.0% >= 60 menit Count 12 1 3 0 16 % of Total 24.0% 2.0% 6.0% .0% 32.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0%
BAB V
PEMBAHASAN
5.1. Clustering
Teknik yang digunakan dalam penelitian in adalah Teknik hirarki (hierarchical methods) adalah teknik clustering membentuk kontruksi hirarki atau berdasarkan tingkatan tertentu seperti struktur pohon (struktur pertandingan).
Dengan demikian proses pengelompokkannya dilakukan secara bertingkat atau bertahap. Hasil dari pengelompokan ini dapat disajikan dalam bentuk dendogram. Metode dalam teknik hirarki yang digunakan dalam penelitian ini adalah Agglomerative Methods.
Dari pengolahan data dengan menggunakan metode herarki maka terbentuklah 4 cluster yang dimana cluster 1 terdiri dari 42 responden, cluster 2 terdiri dari 3 responden, dan cluster 3 terdiri dari 4 responden. Cluster 4 tidak memiliki kelompok yang relative homogen, sehingga cluster 4 dikatakan outlier. Cluster 4 terdiri dari 1 responden.
5.2. Profilisasi Customer
Kuisioner 1 merupakan profilisasi dari customer. Ada 5 variabel yang terdapat pada kuisioner 1, yaitu Jenis Kelamin, Usia, Angkatan, Intensitas, dan Durasi. Berikut penjabaran dari crosstab masing – masing variable.
Jenis Kelamin Cluster 1 Laki – laki : 27 Perempuan : 15 Total : 42 Cluster 2 Laki – laki : 2 Perempuan : 1 Total : 3 Cluster 3 Laki – laki : 2 Perempuan : 2 Total : 4 Cluster 4 Laki – laki : 0 Perempuan : 1 Total : 1
Usia Cluster 1 17 – 19 tahun : 7 20 – 22 tahun : 35 Total : 42 Cluster 2 17 – 19 tahun : 1 20 – 22 tahun : 2 Total : 3 Cluster 3 17 – 19 tahun : 0 20 – 22 tahun : 4 Total : 4 Cluster 4 17 – 19 tahun : 0 20 – 22 tahun : 1 Total : 1 Angkatan Cluster 1 ≤ 2007 : 8 2008 : 31 2009 : 3 Total : 42 Cluster 2 ≤ 2007 : 0 2008 : 2 2009 : 1 Total : 3 Cluster 3 ≤ 2007 : 1 2008 : 3 2009 : 0 Total : 4 Cluster 4 ≤ 2007 : 0 2008 : 1 2009 : 0 Total : 1 Intensitas Cluster 1 Sangat Sering : 5 Sering : 10 Sedang : 13 Jarang : 14 Total : 42 Cluster 2 Sangat Sering : 1 Sering : 0 Sedang : 1 Jarang : 1 Total : 3 Cluster 3 Sangat Sering : 3 Sering : 1 Sedang : 0 Jarang : 0 Total : 4
Cluster 4 Sangat Sering : 0 Sering : 1 Sedang : 0 Jarang : 0 Total : 1 Durasi Cluster 1 ≤ 15 menit : 9 16 – 30 menit : 8 30 – 60 menit : 13 ≥ 60 menit : 12 Total : 42 Cluster 2 ≤ 15 menit : 2 16 – 30 menit : 0 30 – 60 menit : 0 ≥ 60 menit : 1 Total : 3 Cluster 3 ≤ 15 menit : 1 16 – 30 menit : 0 30 – 60 menit : 0 ≥ 60 menit : 3 Total : 4 Cluster 4 ≤ 15 menit : 0 16 – 30 menit : 0 30 – 60 menit : 1 ≥ 60 menit : 0 Total : 1
BAB VI
KESIMPULAN DAN SARAN
6.1. Kesimpulan
Berdasarkan hasil dari pembahasan pada bab V, maka didapatkan beberapa kesimpulan :
1. Cluster yang terbentuk sebanyak 3 cluster dan 1 outlier. Cluster 1 terdiri dari 42 responden, cluster 2 terdiri dari 3 responden, dan cluster 3 terdiri dari 4 responden. Cluster 4 tidak memiliki kelompok yang relative homogen, sehingga cluster 4 dikatakan outlier. Cluster 4 terdiri dari 1 responden.
2. Mahasiswa Teknik Industri yang berkunjung ke laboratorium Data Mining dominan berjenis kelamin laki-laki dengan rata-rata usia 20 – 22 tahun dan merupakan angkatan 2008 dengan intensitas kunjungan yang jarang dan durasi atau lama berkunjung responden ≥ 60 menit.
6.2. Saran
Berdasarkan kesimpulan diatas maka disarankan kepada Laboratorium Data Mining agar lebih gencar dalam mempromosikan kepada mahasiswa Teknik Industri dan mengadakan kegiatan yang bersifat rutin selain praktikum agar intensitas kunjungan mahasiswa ke Laboratorium dapat bertambah.
DAFTAR PUSTAKA
Modul II Analisis Cluster Praktikum Data MiningHan, Jiawei. ”Data Mining Concept and Technique”. Presentation. http://www.cse.msu.edu/~cse980
Bertalya, ”Konsep Data Mining”. Universitas Gunadarma, 2009.
LAMPIRAN
Cluster
Case Processing Summarya,b Cases
Valid Missing Total
N Percent N Percent N Percent
50 100.0 0 .0 50 100.0
a. Squared Euclidean Distance used
b. Single Linkage Single Linkage Agglomeration Schedule Stage Cluster Combined Coefficients
Stage Cluster First Appears
Next Stage
Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 23 50 .000 0 0 17 2 25 49 .000 0 0 15 3 5 46 .000 0 0 42 4 43 45 .000 0 0 26 5 36 44 .000 0 0 25 6 39 40 .000 0 0 7 7 37 39 .000 0 6 8 8 34 37 .000 0 7 9 9 32 34 .000 0 8 11 10 24 33 .000 0 0 16 11 31 32 .000 0 9 12 12 10 31 .000 0 11 24 13 28 30 .000 0 0 14 14 13 28 .000 0 13 22 15 4 25 .000 0 2 32 16 8 24 .000 0 10 29
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage
Cluster 1 Cluster 2 Cluster 1 Cluster 2
17 6 23 .000 0 1 33 18 16 21 .000 0 0 34 19 17 20 .000 0 0 20 20 14 17 .000 0 19 36 21 9 15 .000 0 0 38 22 11 13 .000 0 14 31 23 3 12 .000 0 0 44 24 7 10 .000 0 12 37 25 36 48 1.000 5 0 29 26 42 43 1.000 0 4 27 27 1 42 1.000 0 26 42 28 29 38 1.000 0 0 31 29 8 36 1.000 16 25 36 30 26 35 1.000 0 0 33 31 11 29 1.000 22 28 37 32 4 27 1.000 15 0 41 33 6 26 1.000 17 30 40 34 16 19 1.000 18 0 35 35 16 18 1.000 34 0 48 36 8 14 1.000 29 20 38 37 7 11 1.000 24 31 39 38 8 9 1.000 36 21 39 39 7 8 1.000 37 38 40 40 6 7 1.000 33 39 41 41 4 6 1.000 32 40 43 42 1 5 1.000 27 3 43 43 1 4 1.000 42 41 44 44 1 3 1.000 43 23 45 45 1 47 2.000 44 0 46 46 1 41 2.000 45 0 47 47 1 22 2.000 46 0 48 48 1 16 2.000 47 35 49 49 1 2 2.000 48 0 0
Dendrogram
* * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * Dendrogram using Single Linkage
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25 Label Num +---+---+---+---+---+ Adit 23 ─┐ Galih 50 ─┼───────────────────────┐ Fandi 6 ─┘ │ Trisno 26 ─────────────────────────┤ Rozaq 35 ─────────────────────────┤ Syarif 39 ─┐ │ Novi 40 ─┤ │ Nurul Lu 37 ─┤ │ Safri Ha 34 ─┤ │ Chanifa 32 ─┤ │ Ibnu Her 31 ─┤ │ Mabok 10 ─┼───────────────────────┤ Maro 7 ─┘ │ Himawan 28 ─┐ │ Laskar K 30 ─┤ │ Digdoyo 13 ─┼───────────────────────┤ Richo 11 ─┘ │ Omiyabi 29 ─────────────────────────┤ Abdul Ha 38 ─────────────────────────┤ Aya' 9 ─┬───────────────────────┤ Anestia 15 ─┘ │ Ryan 17 ─┐ │ Hendi 20 ─┼───────────────────────┤ Sigit 14 ─┘ │ Nunuk 24 ─┐ │ Tomy 33 ─┼───────────────────────┤ Ikhsan 8 ─┘ │ Lenny Oc 36 ─┬───────────────────────┤ Maya 44 ─┘ │ Tyas 48 ─────────────────────────┤ Wanda 25 ─┐ │ Jusman B 49 ─┼───────────────────────┤ Annisa 4 ─┘ │ Rizki D. 27 ─────────────────────────┤ Fitra 5 ─┬───────────────────────┼───────────────────────┐ Didit 46 ─┘ │ │ Arfiana 43 ─┬───────────────────────┤ │ Karen 45 ─┘ │ │ Vivialit 42 ─────────────────────────┤ │ Sekar 1 ─────────────────────────┤ │ Huda 3 ─┬───────────────────────┘ │ Atlit 12 ─┘ │ Tasya 47 ─────────────────────────────────────────────────┤ Kidhut 41 ─────────────────────────────────────────────────┤ Farikh 22 ─────────────────────────────────────────────────┤ Ayu 16 ─┬───────────────────────┐ │ Kristin 21 ─┘ │ │ Dika Oki 19 ─────────────────────────┼───────────────────────┤ Fauzi 18 ─────────────────────────┘ │ Hendia V 2 ─────────────────────────────────────────────────┘
Crosstabs
Case Processing Summary Cases
Valid Missing Total
N Percent N Percent N Percent
Jenis Kelamin * Cluster
Member 50 100.0% 0 .0% 50 100.0%
Usia * Cluster Member 50 100.0% 0 .0% 50 100.0%
Angkatan * Cluster Member 50 100.0% 0 .0% 50 100.0%
Intensitas * Cluster Member 50 100.0% 0 .0% 50 100.0%
Durasi * Cluster Member 50 100.0% 0 .0% 50 100.0%
Jenis Kelamin * Cluster Member
Crosstab
Cluster Member
Total
1 2 3 4
Jenis Kelamin Laki - laki Count 27 2 2 0 31
% of Total 54.0% 4.0% 4.0% .0% 62.0% Perempuan Count 15 1 2 1 19 % of Total 30.0% 2.0% 4.0% 2.0% 38.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0% Symmetric Measures Value Asymp. Std.
Errora Approx. Tb Approx. Sig.
Interval by Interval Pearson's R .159 .141 1.117 .270c
Ordinal by Ordinal Spearman Correlation .121 .146 .844 .403c
N of Valid Cases 50
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
Usia * Cluster Member
Crosstab
Cluster Member
Total
1 2 3 4
Usia 17 - 19 tahun Count 7 1 0 0 8
% of Total 14.0% 2.0% .0% .0% 16.0% 20 -22 tahun Count 35 2 4 1 42 % of Total 70.0% 4.0% 8.0% 2.0% 84.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0% Symmetric Measures Value Asymp. Std. Errora Approx. Tb Approx. Sig.
Interval by Interval Pearson's R .097 .078 .679 .501c
Ordinal by Ordinal Spearman Correlation .056 .119 .391 .698c
N of Valid Cases 50
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
c. Based on normal approximation.
Angkatan * Cluster Member
Crosstab Cluster Member Total 1 2 3 4 Angkatan <= 2007 Count 8 0 1 0 9 % of Total 16.0% .0% 2.0% .0% 18.0% 2008 Count 31 2 3 1 37 % of Total 62.0% 4.0% 6.0% 2.0% 74.0% 2009 Count 3 1 0 0 4 % of Total 6.0% 2.0% .0% .0% 8.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0%
Symmetric Measures
Value
Asymp. Std.
Errora Approx. Tb Approx. Sig.
Interval by Interval Pearson's R .023 .116 .160 .874c
Ordinal by Ordinal Spearman Correlation .071 .135 .495 .623c
N of Valid Cases 50
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
c. Based on normal approximation.
Intensitas * Cluster Member
Crosstab
Cluster Member
Total
1 2 3 4
Intensitas Sangat Sering Count 5 1 3 0 9
% of Total 10.0% 2.0% 6.0% .0% 18.0% Sering Count 10 0 1 1 12 % of Total 20.0% .0% 2.0% 2.0% 24.0% Sedang Count 13 1 0 0 14 % of Total 26.0% 2.0% .0% .0% 28.0% Jarang Count 14 1 0 0 15 % of Total 28.0% 2.0% .0% .0% 30.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0% Symmetric Measures Value Asymp. Std.
Errora Approx. Tb Approx. Sig.
Interval by Interval Pearson's R -.368 .107 -2.739 .009c
Ordinal by Ordinal Spearman Correlation -.334 .129 -2.459 .018c
N of Valid Cases 50
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
Durasi * Cluster Member
Crosstab
Cluster Member
Total
1 2 3 4
Durasi <= 15 menit Count 9 2 1 0 12
% of Total 18.0% 4.0% 2.0% .0% 24.0% 16 - 30 menit Count 8 0 0 0 8 % of Total 16.0% .0% .0% .0% 16.0% 30 - 60 menit Count 13 0 0 1 14 % of Total 26.0% .0% .0% 2.0% 28.0% >= 60 menit Count 12 1 3 0 16 % of Total 24.0% 2.0% 6.0% .0% 32.0% Total Count 42 3 4 1 50 % of Total 84.0% 6.0% 8.0% 2.0% 100.0% Symmetric Measures Value Asymp. Std. Errora Approx. Tb Approx. Sig.
Interval by Interval Pearson's R .087 .137 .603 .549c
Ordinal by Ordinal Spearman Correlation .065 .162 .452 .653c
N of Valid Cases 50
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
LAPORAN RESMI
PRAKTIKUM DATA MINING
REGRESI
DISUSUN OLEH: KELOMPOK C.23
ARIF RAKHMANTO (08 522 200) CATUR HERMAWANTO (08 522 210)
LABORATORIUM DATA MINING
JURUSAN TEKNIK INDUSTRI
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS ISLAM INDONESIA
2010
ABSTRAKS
Regresi merupakan salah satu metode yang dapat digunakan untuk memprediksi penjualan pada suatu perusahaan. Dalam penelitian ini, analisis regresi berganda digunakan untuk memprediksi total penjualan dari butik THE UNIQUE CULTURE. Metode yang digunakan dalam penelitian ini adalah Analisis Linier Berganda yang merupakan suatu metode statistik umum yang digunakan untuk meneliti hubungan antara sebuah variable dependent dengan beberapa variable independent. Tujuan analisis regresi linier berganda adalah menggunakan variable independent yang diketahui, untuk meramalkan variable dependent.
BAB I
PENDAHULUAN
1.4 Latar Belakang masalah
THE UNIQUE CULTURE merupakan sebuah butik Batik dengan etnik modern yang sedang berkembang di kalangan menengah atas masyarakat Indonesia. Dalam beberapa bulan terakhir, THE UNIQUE CULTURE gencar mempromosikan batik dengan segala jenis varian barunya yang dijualnya dengan membuka outlet-outlet di 50 daerah. Dalam rangka memperluas jaringan pasar, THE UNIQUE CULTURE menambah 5 kota untuk membuka outletnya, yakni Purworejo, Purwodadi, Waykambas, Musi dan Tarakan. Oleh sebab itu, THE UNIQUE CULTURE membutuhkan prediksi penjualan pada lima kota tersebut.
1.5 Rumusan Masalah
1. Bagaimana hasil uji normalitas?
2. Bagaimana hasil uji signifikansi persamaan regresi? 3. Bagaimana persamaan regresi yang terbentuk? 4. Bagaimana hasil uji multikolineritas?
5. Bagaimana korelasi antara variable dependent dengan variabel independentnya?
6. Bagaimana hasil prediksi penjualan pada lima kota?
1.6 Tujuan penelitian
3. Untuk mengetahui hasil uji normalitas.
4. Untuk mengetahui hasil uji signifikansi persamaan regresi. 5. Untuk mengetahui persamaan regresi yang terbentuk. 6. Untuk mengetahui uji multikolineritas.
7. Untuk mengetahui hubungan antara variable dependent dengan variable independentnya.
1.7 Manfaat Penelitian
Penelitian ini bermafaat untuk mengetahui persamaan regresi yang didapatkan dari data historis butik THE UNIQUE CULTURE untuk memprediksi total penjualan yang didapatkan pada 5 kota.
1.5 Flowchart Gambar 1.1 Flowchart Mulai Pengumpulan Data MasaPengumpulal ah
Menentukan Persamaan Regresi
Selesai Uji Normalitas
Uji Linearitas Sig ≤ 0.05 atau Fhitung > Ftabel
ya
ya
Uji MultiKolinearitas VIF < 2 ya
Menentukan Nilai R Square
Menentukan Koefisien Korelasi TIDAK
TIDAK TIDAK
3.5. Langkah Software
12. Input data yang diperoleh ke software
13. Pilih analyze klik Regression lalu pilih Linear
14. Dependent : Letakkan
Variabel dependent (Y) yang valid
15. Independent(s) : Letakkan semua Variabel
independent(X) yang valid
16. Case labels : Letakkan nama daerah
17. Statistik : Regression
Coefficient lalu klik estimates, model fit, descriptives,
collinearity diagnostics lalu klik continue
18. Plots : Y = dependent, X = *adjpred, klik histogram dan probability plot, klik continue
19. Save : predicted values, klik unstandardized, include the convariance matrix, continue.
20. Option : klik Probability of F, include constant in equation, exclude cases listwise, continue.
BAB II
LANDASAN TEORI
Banyak penelitian yang bertujuan mencari dasar-dasar untuk mengadakan prediksi suatu variabel dari informasi-informasi yang diperoleh dari variabel tersebut. Misalnya, apakah keadaan cuaca dapat diramalkan dari suhu, tekanan udara, kelembaban udara, dan kecepatan angin; Apakah prestasi belajar anak dapat diprediksikan dari angka kecerdasan dan perbendaharaan bahasa (kosa kata); Apakah prestasi pemain sepak bola dapat dipresiksi dari keahliannya dan umur pemain tersebut; dan sebagainya. Maka diperlukan metoda untuk dapat memecahkan semua masalah yang ada untuk memudahkan dalam pengambilan keputusan. Salah satu tool atau metoda untuk memprediksi adalah Regresi.
Dalam kehidupan sehari-hari kita sering melihat suatu peristiwa atau keadaan yang terjadi akibat peristiwa yang lain. Untuk mengetahui hubungan antara kejadian tersebut, terutama untuk menelusuri pola hubungan yang modelnya belum diketahui maka analisis regresi dapat dijadikan alat untuk membantu menganalisis hubungan tersebut. Analisis regresi memiliki 3 kegunaan yaitu, deskripsi, kendali, dan prediksi (peramalan). Tetapi manfaat utama dari kebanyakan penyelidikan statistik dalam dunia bisnis dan ekonomi adalah mengadakan prediksi atau peramalan.
Dalam analisis regresi dikenal dua macam variabel atau peubah yaitu variabel bebas (independent variabel) adalah dan variabel tidak bebas (dependent variabel). Variabel bebas (independent variabel) adalah suatau variabel yang nilainya telah diketahui, sedangkan variabel tidak bebas (dependent variabel) adalah variabel yang nialainya belum diketahui dan yang akan diramalkan. Suatu variabel dapat diramalkan dari variabel lain apabila antara variabel yang diramalakan (dependent variabel) dengan variabel yang nilainya diketahui (independent variabel) terdapat hubungan atau korelasi yang signifikan. Misalnya, jika antara tinggi badan dan berat badan pada umur-umur tertentu terdapat korelasi yang signifikan, maka berat badan orang pada umur tersebut akan dapat diramalkan dari tinggi badannya. Korelasi antara independent variable dengan dependent variabel dapat dilukiskan dalam suatu garis. Garis ini disebut garis regresi. Garis regresi mungkin merupakan garis lurus (linier) disebut regresi linier, mungkin juga merupakan garis lengkung (parabolik, hiperbolik,
Ŷ = a + b1X1 + b2X2 + b3X3 + … + bnXn
dan sebagainya) yang disebut regresi non linier. Namun berdasarkan dari data yang ada, maka analisis yang akan digunakan adalah analisis regresi linear berganda.
Regresi linier berganda mengamati pengaruh lebih dari satu variabel bebas (independent variable) terhadap variabel tidak bebas (dependent variable), minimal ada dua buah variabel bebas (independent variable).
Analisis Linier Berganda adalah suatu metode statistik umum yang digunakan untuk meneliti hubungan antara sebuah variable dependent dengan beberapa variable independent. Tujuan analisis regresi linier berganda adalah menggunakan variable independent yang diketahui, untuk meramalkan variable dependent. Misalnya : penjualan sebuah produk dapat dipengaruhi oleh biaya promosi, biaya produksi, biaya transportasi, gaji karyawan dan lain-lain. Jumlah pengeluaran rumah tangga dipengaruhi oleh pendapatan, jumlah keluarga.
Secara matematis regresi linier berganda dapat dituliskan dalam persamaan berikut :
dimana :
Y = variabel yang diramalkan (dependent variable)
X1, X2, X3, …, Xn = variabel yang diketahui (independent variable) b1, b2, b3,…, bn = koefisien regresi
BAB III
PENGUMPULAN DAN PENGOLAHAN DATA
3.1 Pengumpulan Data
3.1.1 Data Historis butik THE UNIQUE CULTURE
Tabel 3.1 Data historis butik THE UNIQUE CULTURE
No. Daerah Penjualan Biaya Periklanan Laju Pertumbuhan Penduduk Luas Outlet Jumlah Pesaing 1 Jakarta Pusat 231 50 2.55 55 35 2 Jakarta Barat 135 17 2.15 46 30 3 Jakarta Selatan 187 18 1.99 53 25 4 Bandung 276 25 1.76 45 33 5 Bogor 233 15 2.3 64 14 6 Cirebon 345 35 2.69 54 5 7 Aceh 267 21 2.56 76 10 8 Medan 163 40 3 56 7 9 Riau 321 34 1.65 67 12 10 Batam 337 44 1.9 68 9 11 Bengkulu 333 24 1.46 40 5 12 Jambi 235 26 1.57 61 4 13 Banten 234 15 1.87 65 7 14 Cilegon 169 26 1.76 55 9 15 Purwakarta 179 11 1.98 41 12 16 Yogyakarta 245 44 1.28 59 53 17 Semarang 100 29 1.76 41 27 18 Pekalongan 256 23 2.23 65 40 19 Solo 139 29 2.21 52 25 20 Bekasi 157 35 2.66 53 12 21 Tangerang 212 23 1.69 54 11 22 Denpasar 365 45 2.56 65 9
No. Daerah Penjualan Biaya Periklanan Laju Pertumbuhan Penduduk Luas Outlet Jumlah Pesaing 23 Dumai 250 24 2.39 61 17 24 Bontang 198 19 1.54 51 19 25 Surabaya 284 24 2.88 75 7 26 Kediri 247 29 1.99 58 6 27 Malang 210 22 1.79 64 19 28 Banjarmasin 290 23 2.89 68 6 29 Padang 342 33 2.68 60 8 30 Pekanbaru 214 13 1.79 78 7 31 Manado 320 31 1.78 45 3 32 Jayapura 300 26 1.46 51 5 33 Martapura 349 32 2.7 49 2 34 Sorong 209 21 1.65 54 4 35 Makasar 217 18 1.9 65 9 36 Ambon 89 21 1 40 4 37 Bukit Tinggi 225 22 2.76 50 9 38 Purwokerto 135 21 2.14 47 8 39 Tuban 218 21 2.01 87 6 40 Jombang 175 23 1.87 43 9 41 Bangka 211 15 1.67 53 5 42 Belitung 374 40 2.24 74 4 43 Lampung 256 19 2.58 64 8 44 Mataram 234 27 1.65 70 8 45 Depok 223 18 2.34 45 9 46 Gorontalo 264 39 2.21 88 8 47 Metro 319 39 2.24 65 9 48 Madiun 126 16 1.98 43 5 49 Magelang 110 9 1.22 46 7 50 Palangka Raya 390 39 2.54 90 9
3.1.2 Data yang Akan Diprediksi
Tabel 3.2 Data yang akan diprediksi dari butik THE UNIQUE CULTURE
NO Daerah Biaya Periklanan (juta) Laju pertumbuhan penduduk (%) Luas outlet (m2) Jumlah pesaing 1 Purworejo 22 2.12 39 5 2 Purwodadi 27 1.91 78 3 3 Waykambas 17 1.88 37 6 4 Musi 19 1.69 49 3 5 Tarakan 23 2.23 72 4
3.2 Pengolahan Data 3.2.1 Uji Normalitas
Gambar 3.1
3.2.2 Tabel Model Summary
Tabel 3.3 Model Summaryb Model R R Square Adjusted R
Square Std. Error of the Estimate 1 .663a .440 .390 58.90304 3.2.3 Uji Linearitas Tabel 3.4 ANOVAb
Model Sum of Squares df Mean Square F Sig. 1 Regression 122477.380 4 30619.345 8.825 .000a
Residual 156130.540 45 3469.568
Total 278607.920 49
3.2.4 Uji Multikolinieritas dan Persamaan Regresi
Tabel 3.5 Coefficientsa Model Unstandardized Coefficients Standardized Coefficients t Sig. Collinearity Statistics B Std.
Error Beta Tolerance VIF
1 (Constant) 36.481 50.393 .724 .473 Biaya Periklanan 3.520 .959 .451 3.670 .001 .826 1.211 Laju Pertumbuhan Penduduk 12.587 19.314 .079 .652 .518 .844 1.185 Luas Outlet 1.765 .718 .296 2.458 .018 .858 1.165 Jumlah Pesaing -1.631 .824 -.230 -1.979 .054 .925 1.081
3.2.5 Nilai Korelasi antara Variable Dependent dengan Variable Independent Tabel 3.6 Correlations Penjualan Biaya Periklanan Laju Pertumbuhan Penduduk Luas Outlet Jumlah Pesaing Pearson Correlation Penjualan 1.000 .513 .326 .467 -.193 Biaya Periklanan .513 1.000 .299 .266 .176 Laju Pertumbuhan Penduduk .326 .299 1.000 .301 -.101 Luas Outlet .467 .266 .301 1.000 -.118 Jumlah Pesaing -.193 .176 -.101 -.118 1.000
Sig. (1-tailed) Penjualan . .000 .010 .000 .089
Biaya Periklanan .000 . .017 .031 .111 Laju Pertumbuhan Penduduk .010 .017 . .017 .242 Luas Outlet .000 .031 .017 . .208 Jumlah Pesaing .089 .111 .242 .208 . N Penjualan 50 50 50 50 50 Biaya Periklanan 50 50 50 50 50 Laju Pertumbuhan Penduduk 50 50 50 50 50 Luas Outlet 50 50 50 50 50 Jumlah Pesaing 50 50 50 50 50
3.2.6 Prediksi
Berdasarkan table koefisien, maka dapat diperoleh informasi bahwa nilai : a = 36,481
b1 = 3,52 b2 = 12,587 b3 = 1,765 b4 = -1,631
sehingga dapat diperoleh persamaan regresi sebagai berikut :
Y = 36,481 + 3,52 X1 + 12,587 X2 + 1,765 X3 - 1,631 X4
Maka prediksi penjualan pada lima kota adalah sebagai berikut :
YPurworejo = 36,481 + 3,52 (22) + 12,587 (2,12) + 1,765 (39) - 1,631 (5) = 201,29 YPurwodadi = 36,481 + 3,52 (27) + 12,587 (1,91) + 1,765 (78) - 1,631 (3) = 288,34 YWaykambas = 36,481 + 3,52 (17) + 12,587 (1,88) + 1,765 (37) - 1,631 (6) = 175,5 YMusi = 36,481 + 3,52 (19) + 12,587 (1,69) + 1,765 (49) - 1,631 (3) = 206,23 YTarakan = 36,481 + 3,52 (23) + 12,587 (2,23) + 1,765 (72) - 1,631 (4) = 266,07
BAB IV
PEMBAHASAN
4.1 Uji Normalitas
Berdasarkan histogram yang diperoleh dari output SPSS, maka dapat dilihat bahwa pola histogram relatif membentuk lonceng terbalik. Hal tersebut menunjukkan bahwa data bersifat normal. Selain itu, berdasarkan scater plot juga dapa terlihat bahwa pola distribusi data relatif membentuk linier.
4.2 Tabel Model Summary
Dari hasil pengolahan data diperoleh nilai R-square yaitu sebesar 0.440, yang artinya besarnya keragaman antara variabel dependent dengan variabel independent yang terdapat pada persamaan regresi sebesar 0.440, semakin besar nilai R-square semakin baik persamaan regresi tersebut dalam menjelaskan keragaman data.
4.3 Uji Linearitas
Hipotesis:
Ho: Biaya periklanan, laju pertumbuhan penduduk, luas outlet, dan jumlah pesaing tidak berpengaruh pada penjualan.
H1: Biaya periklanan, laju pertumbuhan penduduk, luas outlet, dan jumlah pesaing berpengaruh pada penjualan.
Tingkat signifikansi
Level signifikansi = 0.000 df1 = k = 4 df2 = n – k – 1 = 45 Ftabel = 5,56
Fhitung = 8,825 Daerah kritis
Jika Fhitung ≥ Ftabel maka Ho ditolak Jika Fhitung ≤ Ftabel maka Ho diterima
F hitung > F table maka H0 ditolak sehingga persamaan signifikan (ada pengauh yang signifikan antara variable independent terhadap variable dependent.
4.4 Uji Multikolinieritas dan Persamaan Regresi 4.4.1 Uji Multikolinieritas
Dengan uji multikolinieritas maka didapat hasil VIF sebagai berikut: VIF Nilai biaya periklanan = 1.211
VIF Nilai laju pertumbuhan penduduk = 1.185
VIF Nilai luas outlet = 1.165
VIF Nilai jumlah pesaing = 1.081
Karena 4 nilai VIF < 2, maka artinya variabel biaya periklanan, laju pertumbuhan penduduk, luas outlet dan jumlah pesaing tidak saling berkorelasi atau tidak terjadi multikolinieritas.
4.4.2 Persamaan Regresi
Dari hasil pengolahan data didapat hasil sebagai berikut; a = 36,481 b1 = 3,52 b2 = 12,587 b3 = 1,765 b4 = -1,631 dengan; Y1 = penjualan X1 = biaya periklanan
X2 = laju pertumbuhan penduduk X3 = luas outlet
X4 = jumlah pesaing
sehingga dapat diperoleh persamaan regresi sebagai berikut : Y = 36,481 + 3,52 X1 + 12,587 X2 + 1,765 X3 - 1,631 X4
4.5 Nilai Korelasi antara Variable Dependent dengan Variable Independent
Dari hasil pengolahan data diperoleh hubungan korelasi sebagai berikut: 1. Hubungan korelasi antara Y – X1 = 0.513 berarti positif kuat. 2. Hubungan korelasi antara Y – X2 = 0.326 berarti positif lemah 3. Hubungan korelasi antara Y – X3 = 0.467 berarti positif lemah. 4. Hubungan korelasi antara Y – X4 = - 0.193 berarti negatif lemah. 5. Hubungan korelasi antara X1 – X2 = 0.299 berarti positif lemah. 6. Hubungan korelasi antara X1 – X3 = 0.266 berarti positif lemah. 7. Hubungan korelasi antara X1 – X4 = 0.176 berarti positif lemah. 8. Hubungan korelasi antara X2 – X3 = 0.301 berarti positif lemah. 9. Hubungan korelasi antara X2 – X4 = - 0.101 berarti negatif lemah. 10. Hubungan korelasi antara X3 – X4 = - 0.118 berarti negatif lemah.
4.6 Prediksi
Dari hasil penghitungan dengan menggunakan persamaaan regeresi dapat diketahui prediksi besar insentif karyawan yang akan diterima sebagai berikut:
1. Di kota Purworejo besar penjualan adalah 201.29 2. Di kota Purwodadi besar penjualan adalah 288.34 3. Di kota Waykambas besar penjualan adalah 175.5 4. Di kota Musi besar penjualan adalah 206.23 5. Di kota Tarakan besar penjualan adalah 266.07
BAB V
KESIMPULAN DAN SARAN
6.1. Kesimpulan
1. Berdasarkan hasil uji normalitas diketahui bahwa data bersifat normal 2. Berdasarkan hasil uji signifikansi persamaan regresi, maka :
Ftabel = 5,56 Fhitung = 8,825
F hitung > F table maka H0 ditolak sehingga persamaan signifikan (ada pengauh yang signifikan antara variable independent terhadap variable dependent.
3. Persamaan regresi yang terbentuk adalah sebagai berikut : Y = 36,481 + 3,52 X1 + 12,587 X2 + 1,765 X3 - 1,631 X4
4. Berdasarkan uji multikolineritas, maka dapat disimpulkan bahwa variabel biaya periklanan, laju pertumbuhan penduduk, luas outlet dan jumlah pesaing tidak saling berkorelasi atau tidak terjadi multikolinieritas karena 4 nilai VIF < 2.
5. Yang memiliki hubungan positif kuat adalah : Y – X1
Yang memiliki hubungan positif lemah adalah : Y – X2, Y – X3, X1 – X2, X1 – X3, X1 – X4, X2 – X3
Yang memiliki hubungan negatif lemah : Y – X4, X2 – X4, X3 – X4 6. Hasil prediksi penjualan pada lima kota :
1. Di kota Purworejo besar penjualan adalah 201.29 2. Di kota Purwodadi besar penjualan adalah 288.34 3. Di kota Waykambas besar penjualan adalah 175.5 4. Di kota Musi besar penjualan adalah 206.23 5. Di kota Tarakan besar penjualan adalah 266.07
6.2. Saran
1. Jumlah variabel independent hendaknya lebih banyak lagi untuk mendapatkan hasil prediksi yang lebih akurat.
2. Berdasarkan dari hasil prediksi, maka disarankan pada Butik THE UNIQUE CULTURE agar membuka outlet baru dengan prioritas sebagai berikut : Di kota Purwodadi besar penjualan adalah 288.34
Di kota Tarakan besar penjualan adalah 266.07 Di kota Musi besar penjualan adalah 206.23 Di kota Purworejo besar penjualan adalah 201.29 Di kota Waykambas besar penjualan adalah 175.5
DAFTAR PUSTAKA
Modul III PREDIKSI Praktikum Data Mining1. Han, Jiawei. ”Data Mining Concept and Technique”. Presentation. http://www.cse.msu.edu/~cse980
2. Bertalya, ”Konsep Data Mining”. Universitas Gunadarma, 2009.
3. Walpole, Ronald E. Probability and Statistics for Engineers and Scientists.
LAMPIRAN
Regression
Descriptive Statistics Mean Std. Deviation N Penjualan 237,9600 75,40475 50 Biaya Periklanan 26,2600 9,65488 50 Laju Pertumbuhan Penduduk 2,0694 ,47433 50 Luas Outlet 58,3800 12,65216 50 Jumlah Pesaing 12,2800 10,61966 50 Correlations Penjualan Biaya Periklanan Laju PertumbuhanPenduduk Luas Outlet
Jumlah Pesaing Pearson Correlation Penjualan 1,000 ,513 ,326 ,467 -,193 Biaya Periklanan ,513 1,000 ,299 ,266 ,176 Laju Pertumbuhan Penduduk ,326 ,299 1,000 ,301 -,101 Luas Outlet ,467 ,266 ,301 1,000 -,118 Jumlah Pesaing -,193 ,176 -,101 -,118 1,000
Sig. (1-tailed) Penjualan . ,000 ,010 ,000 ,089
Biaya Periklanan ,000 . ,017 ,031 ,111 Laju Pertumbuhan Penduduk ,010 ,017 . ,017 ,242 Luas Outlet ,000 ,031 ,017 . ,208 Jumlah Pesaing ,089 ,111 ,242 ,208 . N Penjualan 50 50 50 50 50 Biaya Periklanan 50 50 50 50 50 Laju Pertumbuhan Penduduk 50 50 50 50 50 Luas Outlet 50 50 50 50 50 Jumlah Pesaing 50 50 50 50 50
Variables Entered/Removed(b) Model Variables Entered Variables Removed Method 1 Jumlah Pesaing, Laju Pertumbuha n Penduduk, Luas Outlet, Biaya Periklanan( a) . Enter
a All requested variables entered.
b Dependent Variable: Penjualan
Model Summary(b) Model R R Square Adjusted R Square Std. Error of the Estimate 1 ,663(a) ,440 ,390 58,90304
a Predictors: (Constant), Jumlah Pesaing, Laju Pertumbuhan Penduduk, Luas Outlet, Biaya Periklanan
b Dependent Variable: Penjualan
ANOVA(b)
Model
Sum of
Squares df Mean Square F Sig.
1 Regression 122477,38 0 4 30619,345 8,825 ,000(a) Residual 156130,54 0 45 3469,568 Total 278607,92 0 49
a Predictors: (Constant), Jumlah Pesaing, Laju Pertumbuhan Penduduk, Luas Outlet, Biaya Periklanan
Coefficients(a) Model Unstandardized Coefficients Standardized Coefficients t Sig. Collinearity Statistics B Std.
Error Beta Tolerance VIF B
Std. Error 1 (Constant) 36,481 50,393 ,724 ,473 Biaya Periklanan 3,520 ,959 ,451 3,670 ,001 ,826 1,211 Laju Pertumbuhan Penduduk 12,587 19,314 ,079 ,652 ,518 ,844 1,185 Luas Outlet 1,765 ,718 ,296 2,458 ,018 ,858 1,165 Jumlah Pesaing -1,631 ,824 -,230 -1,979 ,054 ,925 1,081
a Dependent Variable: Penjualan
Collinearity Diagnostics(a)
Model Dimension
Eigenvalue
Condition
Index Variance Proportions-
(Constant) Biaya Periklanan Laju Pertumbuhan Penduduk Luas Outlet Jumlah Pesaing (Constant) Biaya Periklan an 1 1 4,497 1,000 ,00 ,00 ,00 ,00 ,01 2 ,375 3,464 ,00 ,00 ,01 ,01 ,88 3 ,077 7,664 ,04 ,98 ,03 ,04 ,02 4 ,033 11,745 ,00 ,00 ,72 ,50 ,00 5 ,019 15,522 ,96 ,01 ,25 ,46 ,09
Residuals Statistics(a)
Minimum Maximum Mean Std. Deviation N
Predicted Value 152,9086 349,8795 237,9600 49,99538 50
Std. Predicted Value -1,701 2,239 ,000 1,000 50
Standard Error of
Predicted Value 10,798 38,091 17,972 4,947 50
Adjusted Predicted Value 150,0846 358,2657 237,9812 51,31624 50
Residual -139,44339 131,23038 ,00000 56,44765 50 Std. Residual -2,367 2,228 ,000 ,958 50 Stud. Residual -2,558 2,354 ,000 1,018 50 Deleted Residual -162,80220 146,55676 -,02123 63,74182 50
Stud. Deleted Residual -2,736 2,486 -,004 1,043 50
Mahal. Distance ,667 19,511 3,920 3,089 50
Cook's Distance ,000 ,219 ,027 ,043 50
Centered Leverage Value ,014 ,398 ,080 ,063 50
a Dependent Variable: Penjualan
Regression Standardized Residual
3 2 1 0 -1 -2 -3 Frequency 20 15 10 5 0 Histogram
Dependent Variable: Penjualan
Mean =-1.63E-16 Std. Dev. =0.958
Observed Cum Prob 1.0 0.8 0.6 0.4 0.2 0.0 Ex pecte d C um Prob 1.0 0.8 0.6 0.4 0.2 0.0 Bengkulu Bandung Martapura Manado Jayapura Cirebon Padang Pekalongan Riau Belitung Palangka Raya Denpasar Depok Purwakarta Banjarmasin Bogor Lampung Yogyakarta Dumai Banten MetroBatam Bontang Bangka Jakarta Selatan Aceh Surabaya Bukit Tinggi Tangerang Makasar Malang Kediri Sorong Jambi Pekanbaru Jakarta Barat Jombang Mataram Magelang Jakarta Pusat Madiun Tuban CilegonPurwokerto Solo GorontaloSemarang Ambon Bekasi Medan
Normal P-P Plot of Regression Standardized Residual
Dependent Variable: Penjualan
Regression Adjusted (Press) Predicted Value
400 350 300 250 200 150 Regre ssi on D el ete d ( Pre ss) R esi dual 200 100 0 -100 -200 Palangka Raya Magelang Madiun Metro Gorontalo Depok Mataram Lampung Belitung Bangka Jombang Tuban Purwokerto Ambon Makasar Sorong Martapura Jayapura Manado Pekanbaru Padang Banjarmasin Malang Kediri Surabaya Bontang Dumai Denpasar Tangerang Bekasi Solo Pekalongan Semarang Yogyakarta Purwakarta Cilegon Banten Jambi Bengkulu Batam Riau Medan Aceh Cirebon Bogor Bandung Jakarta Selatan Jakarta Barat Jakarta Pusat Scatterplot
LAPORAN RESMI
PRAKTIKUM DATA MINING
ASSOCIATION RULE - MARKET BASKET ANALYSIS
DISUSUN OLEH: KELOMPOK C.23
ARIF RAKHMANTO (08 522 200)
CATUR HERMAWANTO (08 522 210)
LABORATORIUM DATA MINING
JURUSAN TEKNIK INDUSTRI
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS ISLAM INDONESIA
2010
ABSTRAK
Association Rule merupakan salah satu metode dalam Market Basket Analysis yang dapat digunakan untuk mengetahui aturan asosiasi antara himpunan item dalam suatu basisdata transaksi. Aturan asosiasi tersebut sangat bermanfaat bagi perencanaan promosi dan penjualan, strategi pemasaran serta tata letak toko. Dalam penelitian ini, studi Market Basket Analysis dilakukan terhadap toko Indomart Cabang Nogotirto/ 004 untuk menganalisa Association Rule yang terbentuk sehingga dapat diperoleh usulan tata letak toko yang lebih baik. Hasil penelitian menunjukkan bahwa departemen satu memiliki hubungan yang sangat kuat dengan departemen tiga. Sedangkan departemen 2, 4, 5, 6 memiliki hubungan yang sedang dengan departemen 3.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Indomart merupakan salah satu toko retail di Indonesia yang berkembang dengan cara franchise, sehingga banyak investor yang membuka cabang di berbagai daerah, salah satunya adalah di daerah Nogotirto, Kecamatan Gamping, Kabupaten Sleman, DIY. Dalam mencatat setiap transaksi pembelian, Indomart menggunakan sistem basis data transaksi yang dapat mencatat setiap transaksi penjualan yang nantinya dapat digunakan untuk kepentingan perencanaan promosi, penjualan, strategi pemasaran dan perencanaan tata letak toko. Transaksi yang tercatat tersebut dapat dipelajari melalui sebuah studi Market Basket Analysis dengan metode Association Rule untuk mengetahui aturan asosiasi diantara himpunan besar data item dalam basisdata transaksi.
Tingkat kedatangan dan transaksi konsumen yang relatif tinggi merupakan salah satu faktor pendorong untuk melakukan analisa kelayakan tata letak toko terkait efektifitas dan efisiensi. Oleh sebab itu maka dilakukan analisa terkait perencanaan tata letak toko menggunakan studi Market Basket Analysis dengan metode Association Rule.
1.2 Rumusan Masalah
1. Bagaimanakah Association Rule yang terbentuk berdasarkan hasil penelitian? 2. Bagaimanakah Activity Relationship Chart (ARC) yang diperoleh?
3. Bagaimanakah usulan alternatif tata letak toko yang baru?
1.3 Batasan Masalah
1. Jumlah struk yang digunakan sebagai bahan penelitian dibatasi sejumlah 50 buah struk.
2. Association Rule dan ARC yang diperoleh dari penelitian sebatas dipergunakan untuk merencanakan usulan tata letak toko yang lebih baik.
1.4 Tujuan Penelitian
1. Untuk mengetahui Association Rule yang terbentuk.
2. Untuk mengetahui Activity Relationship Chart (ARC) yang terbentuk.
3. Untuk mendapatkan alternatif tata letak toko yang lebih menunjang proses transaksi.
1.5 Manfaat Penelitian
Penelitian ini bermanfaat untuk mengetahui tingkat efektifitas tata letak toko dalam mengakomodir aktivitas belanja konsumen melalui analisa Association Rule yang nantinya akan digunakan sebagai pertimbangan dalam merencanakan tata letak toko yang lebih baik.
BAB II
LANDASAN TEORI
Asociation dalam data mining adalah pekerjaan untuk menentukan mana atribut yang akan didapatkan bersamaan. Dalam dunia bisnis lazim dikenal istilah affinity analysis. Tugas dari asociation rule adalah mencari aturan yang tidak mengcover untuk mengukur hubungan antara dua atau lebih atribut.
Association Rule adalah bentuk jika “kejadian sebelumnya” kemudian “konsekuensinya”. (IF antecedent, THEN consequent). Bersamaan dengan perhitungan aturan support dan confidence. Pola asosiasi menjadi salah satu fungsionalitas yang paling menarik dalam penggalian data (Kumar dan Wahidabanu, 2007). Association Rule adalah teknik data mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Contoh dari Association Rule dari analisa pembelian di suatu pasar swalayan adalah bisa diketahui berapa besar kemungkinan seorang pembeli membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut Pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang kampanye pemasaran dengan memakai kupon diskon untuk kombinasi barang tertentu (Wiwin, 2008).
Menurut Leo Susanto (2003) penggalian kaidah asosiasi mempunyai peranan penting dalam proses pengambilan keputusan. Salah satu contoh penerapan Association Rule adalah Market Basket Analysis. Association Rule menjadi terkenal karena aplikasinya untuk menganalisa isi keranjang belanja di pasar swalayan, sehingga Association Rule juga sering disebut dengan istilah Market Basket Analysis. Association Rule juga dikenal sebagai salah satu teknik data mining yang menjadi dasar dari berbagai teknik data mining lainnya.
Market Basket Analysis merupakan salah satu contoh penerapan Association Rule. Untuk menyampaikan ide mendasar dari Market Basket Analysis, dimulai dengan melihat gambar keranjangan belanjaan pada gambar 3.1 yang berisi bermacam-macam barang-barang yang dibeli oleh seseorang disebuah supermarket. Keranjang ini berisi bermacam-macam barang-barang seperti roti, susu, sereal, telur, mentega, gula, dan sebagainya. Sebuah keranjang memberitahukan kepada kita tentang apa saja yang dibeli oleh seorang konsumen dalam satu waktu. Sebuah daftar
belanjaan yang lengkap yang diperoleh dari semua konsumen memberikan kita informasi yang sangat banyak, dan ini dapat menjelaskan barang-barang apa saja yang paling penting dari bisnis penjualan yaitu ”apa barang yang dibeli oleh konsumen dan kapan”.
Setiap konsumen membeli seperangkat barang-barang yang berbeda, dalam jumlah yang berbeda, dan dalam waktu yang berbeda. Market Basket Analysis menggunakan informasi apa yang dibeli oleh konsumen-konsumen untuk menyediakan tanda/informasi yaitu siapa mereka dan mengapa mereka melakukan pembelian tersebut?. Market Basket Analysis menyediakan pengertian tentang barang dagangan dengan memberitahukan kepada kita produk-produk mana yang memungkinkan untuk dibeli secara bersamaan dan produk mana yang lebih disetujui untuk di promosikan. Karena dalam Market Basket Analysis tidak hanya memahami kuantitas dari item yang dibeli dalam keranjang itu, tapi bagaimana item yang dibeli dalam hubungannya satu dengan yang lain.
BAB III
METODOLOGI PENELITIAN
3.1 Lokasi Penelitian
Indomart Cabang Nogotirto/ 004 Jalan Godean km. 4
Nogotirto, Gamping, Sleman, Daerah Istimewa Yogyakarta
3.2 Objek Penelitian
Outlet Indomart Cabang Nogotirto/ 004 beserta pelanggan dan struk transaksi pembeliannya.
3.3 Metode Pengumpulan Data
3.3.1 Data Primer
Data primer dalam penelitian ini berupa struk belanja konsumen yang dikumpulkan melalui proses kolektif di lapangan.
3.3.2 Data Sekunder
Data sekunder dalam penelitian ini merupakan data yang telah diproses dari data primer menjadi data yang siap untuk diolah lebih lanjut. Data sekunder dalam penelitian ini meliputi data pembelian, data transformasi, dan data tabulasi yang selanjutnya siap diolah menggunakan software.
1.4 Flow Chart Penelitian
Mulai
Input Data
Pre processing data 1. Data integrasi 2. Data transformasi Data Tabulasi Association Rule Activity Relationship Chart Selesai Gambar 1.1 Flowchart
1.6 Langkah Software 1.6.1 Input Data
1. Pre Processing Data a. Data Integrasi
a.1 Edit click Find
a.2 Find click name of item
a.3 Replace click Name of department
b. Data Transformasi
Change data department to matrix binary 1 = item dibeli, 0 = item tidak dibeli
1.6.2 Association Rule
a. Open sheet binary
c. Data Range: Block matrix binary click enter (name of department enclosed).
d. Check list: first row contains header
f. Parameter:
Min support ……….(in total) Min Confidence ……(in %)
BAB IV
PENGUMPULAN DAN PENGOLAHAN DATA
4.1 Pengumpulan Data
a. Data Transaksi
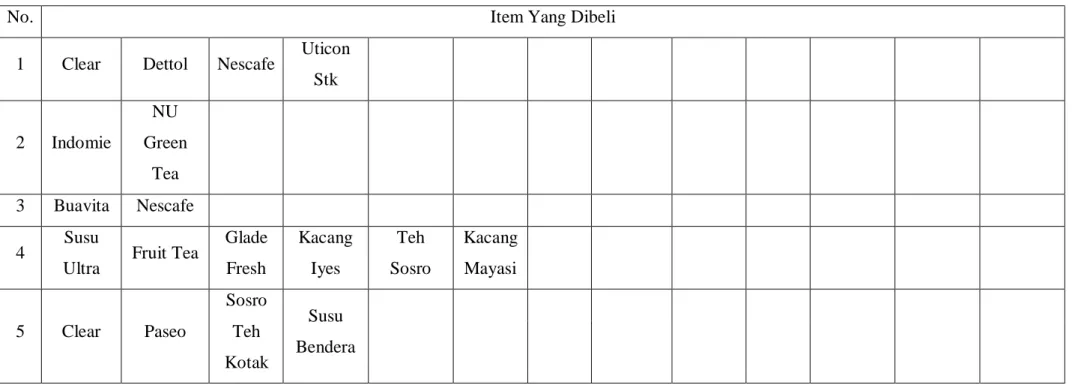
Tabel 4.1 Data Transaksi
No. Item Yang Dibeli
1 Clear Dettol Nescafe Uticon
Stk 2 Indomie NU Green Tea 3 Buavita Nescafe 4 Susu
Ultra Fruit Tea
Glade Fresh Kacang Iyes Teh Sosro Kacang Mayasi 5 Clear Paseo Sosro Teh Kotak Susu Bendera
No. Item Yang Dibeli 6 Keripik Jagung Tong Tji Jasmine Aneka Sagon 7 Paseo Susu Ultra Koko Crunch 8 Sunlight Spons Sabut Lem ALL Sikat Gigi Susu Ultra Susu Ultra 9 Kiwi Black Vitalis
Blossom Attack Paramex
Enervon C 10 Attack Enzim Pasta Gigi
Buavita Indomie Indomie
11 Indomie Indomie Buavita Yakult
NU Green Tea Susu Ultra Susu Ultra Shampo o Dove 12 Shampo
No Item Yang Dibeli
13 Paseo Sunlight Dettol Vaseline
Enzim Pasta Gigi Cap Lang Kayu Putih Pon ds Whit e Kacang Garuda Walls Magnu m 14 Sensitif Strip Nice Yoghurt Indomil k Coklat 15 Susu Bendera NU Green
Tea Paseo Aqua
Roti Lumbu ng Straw Roti Lumbun g Nanas Stre psil Vit C Gilette Razor Neozep Forte Sikat Gigi Clear Walls Almond Walls Royal
16 Attack Hemaviton Gery
Salute
17 Philips
Tornado Pop Corn
Sabut Stainles s Sabut Spons 18 Koko Crunch Indomilk Vanilla