Artikel Berita Berbahasa Indonesia
Yan PuspitaraniJurusan Teknik Informatika, Universitas Widyatama Jl. Cikutra 204A Bandung
yan.puspitarani@widyatama.ac.id
Abstract — With the technology development, a large amount of information such as news articles are available over the internet. Hence, text categorization, such as applying classification as one of data mining task, is needed. The major issue in text categorization is the high dimensionality of data. Therefore, we need to select some representative attributes to improve the performance of text categorization. One of techniques to complete this task is feature selection. Feature selection can reduce high dimensionality. Thus, the classifier effectiveness can improve. Among many method, is a filter-based feature selection. This research examined and compared some feature selection techniques toward Indonesian news articles by applying filter model. These models are discussed:
Gini Index for text categorization, CHI, Information Gain, Expected Cross Entropy, Weight Of Evidence and Orthogonal Centroid Feature Selection (OCFS).
Keywords — filter-based feature selection, measurement function.
I. PENDAHULUAN
Jumlah informasi pada artikel berbahasa Indonesia berbasiskan web saat ini semakin besar. Besarnya jumlah ini menyebabkan diperlukannya suatu kategorisasi terhadap artikel tersebut untuk memudahkan pembaca dalam mencari topik berita yang mereka inginkan. Salah satu cara yang dapat dilakukan sebagai solusi untuk masalah ini adalah dengan menggunakan proses kategorisasi teks dalam data
mining yang dapat menggali informasi yang tersembunyi
dari informasi-informasi mentah yang ada.
Akan tetapi, tingginya dimensi dari feature space data dan adanya data noise menjadi masalah utama dalam kategorisasi teks. Hal ini dapat mengganggu efektifitas dari hasil kategorisasinya itu sendiri. Oleh karena itu, harus dilakukan pemilihan terhadap beberapa atribut yang dapat berpengaruh besar terhadap hasil kategorisasi, yaitu feature
selection, untuk mengurangi tingginya dimensi data berupa
manipulasi feature sehingga dapat meningkatkan efektifitas dari classifier.
Saat ini, ada banyak measurement function dalam proses
feature selection yang dapat digunakan untuk kategorisasi
teks. Beberapa diantaranya yaitu CHI, Information Gain,
Expected Cross Entropy, dan Weight of evidence. Selain itu,
ada pula modifikasi dari Gini Index agar dapat digunakan langsung sebagai fungsi pada text feature selection.
Gini index merupakan salah satu measurement function
pada proses feature selection yang sudah sering digunakan
pada decision tree untuk splitting atribut dan memiliki efektifitas yang cukup baik. Selain itu, Gini Index juga dapat bekerja lebih baik mengatasi data noise. Akan tetapi, hal ini jarang digunakan untuk feature selection pada kategorisasi teks.
Dari segi implementasi feature selection, ada beberapa pendekatan yang dapat digunakan. Salah satunya adalah
filter-based feature selection. Ini merupakan teknik
pemilihan atribut yang tidak bergantung terhadap classifier sehingga hasilnya dapat digunakan oleh algoritma classifier manapun bahkan oleh algoritma classifier yang kompleks seperti Neural Network. Selain itu, komputasi dari pendekatan ini relatif rendah sehingga tidak memakan cost yang banyak.
Berdasarkan pertimbangan di atas, penelitian dilakukan terhadap beberapa measurement function pada proses
feature selection terhadap artikel berbahasa Indonesia yang
didapat dari suatu web dengan menerapkan filter model, yaitu Gini Index, CHI, Information Gain, Expected Cross
Entropy, dan Weight of evidence dan Orthogonal Centroid Feature Selection (OCFS). Serta, dilakukan pula analisis
perbandingan terhadap measurement function yang telah disebutkan sebelumnya.
II. FILTER-BASED FEATURE SELECTION
Salah satu pendekatan Feature Selection dalam pemilihan feature adalah filter-based Feature Selection.
Input Features Feature Selection Induction Algorithm
Gambar 1 Filter Based Feature Selection [7]
Berdasarkan gambar, feature yang tidak relevan di-filter dari data sebelum proses induksi dilakukan. Hal ini berarti, pendekatan filter independent terhadap classifier[6]. Dengan begitu, pemilihan atribut tidak bergantung terhadap
classifier sehingga hasilnya dapat digunakan oleh algoritma classifier manapun bahkan oleh algoritma classifier yang
kompleks seperti Neural Network.[5]
A. Ranking
Feature Selection dengan Ranking berarti pemilihan feature berdasarkan relevancy score yang paling baik. Score
dihitung menggunakan measurement function untuk setiap
Algoritma dasar filter Feature Selection secara ranking[1]
Setiap measurement function akan menghitung nilai relevansi suatu term dengan class yang berarti perhitungan kontribusi term tersebut dengan class tertentu. Perhitungan itu, memerlukan komponen sebagai berikut:
) (W
P = Kemungkinan kata W muncul
) (W
P = Kemungkinan kata W tidak
muncul
) (Ci
P = Kemungkinan Class ke-i
) |
(C W
P i = Conditional Probability Class
ke-i jke-ika kata W muncul
)
|
(
C
W
P
i= Conditional Probability Class ke-i jke-ika kata W tke-idak muncul
) | (W Ci
P = Conditional Probability kata W
jika Class ke-i muncul
dimana: ) ( ) , ( ) | ( C P C A P C A P (1)
Beberapa komponen di atas, digunakan dalam
measurement function sebagai berikut: B. Gini Index
Pada awalnya, algoritma Klasik Gini Index merupakan metode split yang non-purity dan biasa digunakan pada algoritma decision tree seperti CART, SLIQ, SPRINT dan
Intelligent Miner.[10]
m i iP
S
Gini
1 21
)
(
Dimana S adalah kumpulan sample s dan kumpulan
sample tersebut memiliki m class yang berbeda. Sedangkan Pi merupakan kemungkinan beberapa sample yang termasuk
kategori Ci.[10]
Wenqian Shang [10] mengembangkan metode gini index
tersebut untuk text categorization yang selanjutnya akan
mengukur jumlah bagian informasi yang diperoleh untuk prediksi kategori dengan mengetahui kemunculan atau tidaknya sebuah term dalam sebuah dokumen.[2] Hal ini terlihat dari persamaan Information Gain di bawah:
m i i i i m i i i i C P W C P W C P W P C P W C P W C P W P W InfGain 1 2 1 2 ) ( ) | ( log ) | ( ) ( ) ( ) | ( log ) | ( ) ( ) (
C. Expected Cross Entropy
m i i i i C P W C P W C P W P W py CrossEntro 1 2 ) ( ) | ( log ) | ( ) ( ) ( (5)Expected Cross Entropy digunakan dalam eksperimen
klasifikasi teks yang mirip dengan Information Gain. Perbedaannya yaitu pada perhitungan rata-rata dari semua atribut, hanya nilai kemunculan term yang dipertimbangkan. Hal ini berarti sebuah perbedaan penting dalam menghasilkan performansi.[2] D. Weight of Evidence
m i i i i i i W C P C P C P W C P C P W P W id WeightofEv 1 ( )(1 ( | )) )) ( 1 )( | ( log ) ( ) ( ) ( (6)Weight of Evidence for text merupakan perhitungan relevancy score suatu term berdasarkan rata-rata bobot
absolut dari evidence yang digunakan dalam mesin
learning.[2] Weight of Evidence ini juga digunakan sebagai
pendekatan untuk mengkombinasikan suatu informasi untuk memutuskan informasi mana yang paling berpengaruh. Dalam arti, pendekatan ini memeriksa seberapa banyak suatu feature yang diperiksa tersebut pada data dapat ditambahkan atau dikurangi dari nilai pengaruhnya. [3]
E. CHI
m i i A A A A A A A A A A A A N C P W 1 1 3 2 4 1 2 3 4 2 3 2 4 1 2 ) )( )( )( ( ) ( ) ( ) ( (7) Di mana:W = term atau kata C = class atau kategori N = total jumlah dokumen
A1 = jumlah kemunculan term dan kategori
A2 = jumlah kemunculan term tanpa kategori
A3 = jumlah kemunculan kategori tanpa term
A4 = jumlah ketidakmunculan term dan kategori F. Orthogonal Centroid Feature Selection (OCFS)
SelectFeatures(D, c, k) V ← ExtractVocabulary(D) L ← [] For each t Є V Do A(t,c) ← ComputeFeatureUtility(D, t, c) Append(L,(A(t, c), t)) Return FeaturesWithLargestValues(L, k)
3. hitung feature score s(i) untuk semua feature
c j i i j j m m n n i s() 1 ( )24. pilih feature yang memiliki score s(i) lebih besar dari
threshold yang ditentukan
III. PENELITIAN
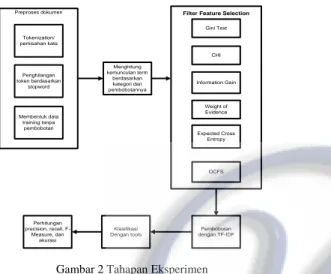
Eksperimen dilakukan melalui beberapa tahapan yang dilakukan seperti pada gambar di bawah ini.
Pembobotan dengan TF-IDF Klasifikasi Dengan tools Perhitungan precision, recall, F-Measure, dan akurasi
Filter Feature Selection
Weight of Evidence Gini Text Information Gain CHI Expected Cross Entropy Menghitung kemunculan term berdasarkan kategori dan pembobotannya Preproses dokumen Tokenization/ pemisahan kata Penghilangan token berdasarkan stopword Membentuk data training tanpa pembobotan OCFS
Gambar 2 Tahapan Eksperimen
Sebelum proses Feature Selection dilakukan, dilakukan preproses dokumen untuk mengubah struktur dokumen menjadi data dengan struktur yang sesuai dengan cara melakukan tokenization untuk memisahkan kata dari dokumen dan menghasilkan token. Setelah token terbentuk, maka token-token yang dianggap kurang penting sesuai daftar stopword seperti di, ke, dari, saya, kamu, dan lain-lain akan dihilangkan. Setelah itu, dilakukan perhitungan jumlah kemunculan kata untuk setiap dokumen yang hasilnya berupa data training yang belum diberi bobot yang akan dimasukkan ke dalam database.
Setelah preproses berakhir, dilakukan proses Feature
Selection. Akan tetapi sebelum proses Feature Selection
dilakukan, perlu dilakukan perhitungan kemunculan term dalam dokumen dan pembobotannya untuk setiap kategori untuk dihitung nilai kontribusinya terhadap kategori. Hasil perhitungan inilah yang akan menjadi inputan bagi proses
Feature Selection.
Hasil dari Feature Selection akan diberi bobot menggunakan TF-IDF. Kemudian dilakukan klasifikasi menggunakan tools. Tools yang digunakan pada eksperimen ini adalah WEKA dengan Naïve Bayes sebagai classifier-nya. Kemudian proses klasifikasi pun berakhir dengan perhitungan precision, recall, F1-Measure, dan akurasi sebagai pengukuran performansi yang dihasilkan.
A. Dataset
Dataset yang digunakan pada penelitian ini adalah
sekumpulan artikel Bahasa Indonesia pada
www.okezone.com di bulan Maret 2008. Sementara itu, kategori dokumen diambil berdasarkan kategori asli pada harian tersebut, yaitu: Ekonomi, Internasional, Techno dan Olahraga dengan asumsi pengkategorian yang dilakukan www.okezone.com benar.
Jumlah dokumen yang digunakan sebanyak 500 dokumen dengan jumlah masing-masing kategori adalah 125 dokumen teks.
B. Pengujian
Pengujian dilakukan terhadap proses training dan testing. 1) Training: Dilakukan klasifikasi terhadap dataset tanpa Feature Selection, yaitu 500 dokumen, 4 kategori, dan 10075 term. Selain itu, klasifikasi pun dilakukan terhadap
dataset yang telah dilakukan Feature Selection dengan threshold berupa jumlah term yang dihasilkan: 10, 100, 500,
dan 1000 serta dilakukan pula perhitungan waktu proses
perhitungan score feature untuk masing-masing
measurement function dengan dataset berskala kecil yaitu
16 dokumen (4 kategori dan masing-masing kategori terdiri dari 4 dokumen) dan dilakukan 10 kali percobaan.
2) Testing: Testing terhadap datatest tanpa Feature
Selection dan setelah Feature Selection dilakukan
menggunakan 100 dokumen yang diambil secara acak dari data training. Percobaan testing dilakukan sebanyak 5 kali percobaan.
Selain itu, dilakukan pula perhitungan waktu eksekusi untuk masing-masing measurement function sebanyak 10 kali percobaan.
Berikut ini merupakan hasil pengujian terhadap testing data:
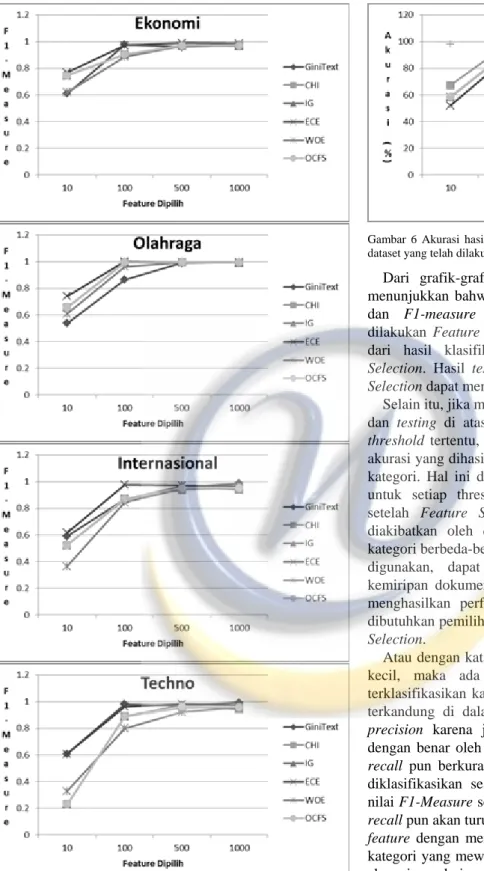
Gambar 5 Grafik F1-measure testing pada setiap kategori hasil klasifikasi dengan Naïve Bayes terhadap dataset setelah Feature Selection disertai tanpa Feature Selection
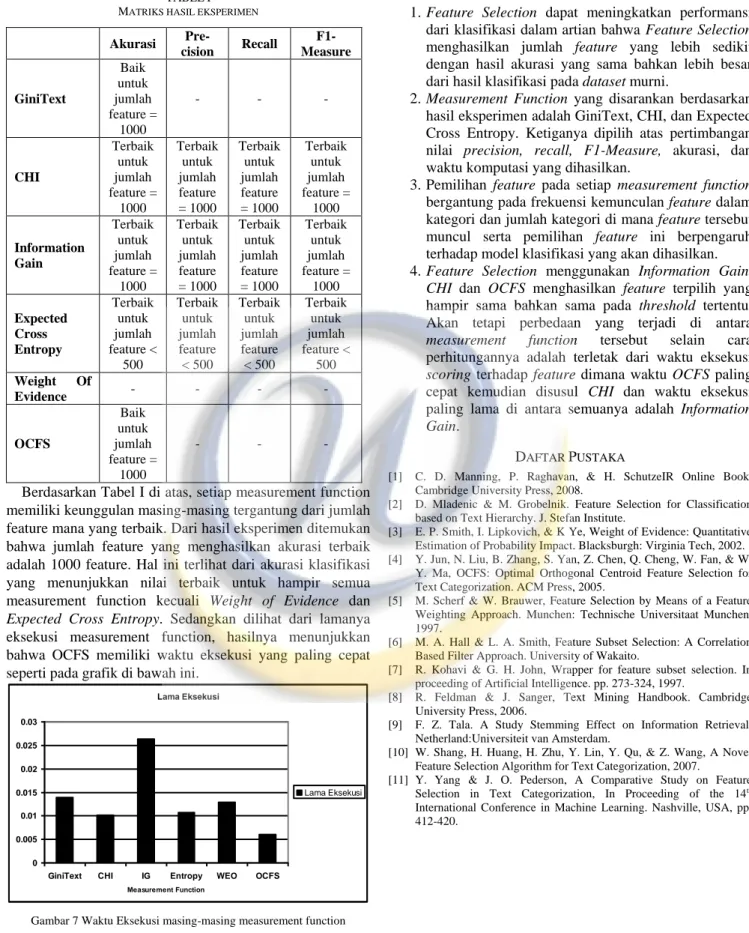
Gambar 6 Akurasi hasil testing klasifikasi dengan Naïve Bayes terhadap dataset yang telah dilakukan Feature Selection
Dari grafik-grafik perbandingan hasil testing di atas menunjukkan bahwa sebagian besar nilai precision, recall, dan F1-measure klasifikasi terhadap dataset setelah dilakukan Feature Selection menyamai bahkan lebih besar dari hasil klasifikasi terhadap dataset tanpa Feature
Selection. Hasil testing pun membuktikan bahwa Feature Selection dapat meningkatkan performansi dari klasifikasi.
Selain itu, jika memperhatikan grafik-grafik hasil training dan testing di atas. Terlihat jelas bahwa pada
threshold-threshold tertentu, nilai precision, recall, F1-measure, dan
akurasi yang dihasilkan kadang naik dan turun untuk semua kategori. Hal ini dapat diakibatkan oleh pemilihan feature untuk setiap threshold mengakibatkan panjang kategori setelah Feature Selection berbeda-beda. Hal ini dapat diakibatkan oleh distribusi feature yang muncul dalam kategori berbeda-beda. Jika dikaitkan dengan dokumen yang digunakan, dapat diketahui bahwa karakteristik atau kemiripan dokumen berbeda-beda. Oleh karena itu, untuk menghasilkan performansi yang terbaik bagi klasifikasi, dibutuhkan pemilihan threshold yang terbaik dalam Feature
Selection.
Atau dengan kata lain, jika threshold yang dipilih terlalu kecil, maka ada kemungkinan suatu dokumen tidak terklasifikasikan karena sama sekali tidak ada feature yang terkandung di dalamnya. Hal ini akan menurunkan nilai
precision karena jumlah dokumen yang diklasifikasikan
dengan benar oleh sistem akan berkurang. Selain itu, nilai
recall pun berkurang karena jumlah dokumen yang benar
diklasifikasikan sesuai aslinya akan berkurang. Sehingga nilai F1-Measure sebagai nilai tengah antara precisison dan
recall pun akan turun. Oleh karena itu, diperlukan pemilihan feature dengan mengusahakan jumlah feature untuk setiap
kategori yang mewakilinya seimbang. Berikut matriks hasil eksperimen dari masing-masing measurement function.
TABELI MATRIKS HASIL EKSPERIMEN Akurasi Pre-cision Recall F1-Measure GiniText Baik untuk jumlah feature = 1000 - - - CHI Terbaik untuk jumlah feature = 1000 Terbaik untuk jumlah feature = 1000 Terbaik untuk jumlah feature = 1000 Terbaik untuk jumlah feature = 1000 Information Gain Terbaik untuk jumlah feature = 1000 Terbaik untuk jumlah feature = 1000 Terbaik untuk jumlah feature = 1000 Terbaik untuk jumlah feature = 1000 Expected Cross Entropy Terbaik untuk jumlah feature < 500 Terbaik untuk jumlah feature < 500 Terbaik untuk jumlah feature < 500 Terbaik untuk jumlah feature < 500 Weight Of Evidence - - - - OCFS Baik untuk jumlah feature = 1000 - - -
Berdasarkan Tabel I di atas, setiap measurement function memiliki keunggulan masing-masing tergantung dari jumlah feature mana yang terbaik. Dari hasil eksperimen ditemukan bahwa jumlah feature yang menghasilkan akurasi terbaik adalah 1000 feature. Hal ini terlihat dari akurasi klasifikasi yang menunjukkan nilai terbaik untuk hampir semua measurement function kecuali Weight of Evidence dan
Expected Cross Entropy. Sedangkan dilihat dari lamanya
eksekusi measurement function, hasilnya menunjukkan bahwa OCFS memiliki waktu eksekusi yang paling cepat seperti pada grafik di bawah ini.
IV. SIMPULAN
1. Feature Selection dapat meningkatkan performansi dari klasifikasi dalam artian bahwa Feature Selection menghasilkan jumlah feature yang lebih sedikit dengan hasil akurasi yang sama bahkan lebih besar dari hasil klasifikasi pada dataset murni.
2. Measurement Function yang disarankan berdasarkan hasil eksperimen adalah GiniText, CHI, dan Expected Cross Entropy. Ketiganya dipilih atas pertimbangan nilai precision, recall, F1-Measure, akurasi, dan waktu komputasi yang dihasilkan.
3. Pemilihan feature pada setiap measurement function bergantung pada frekuensi kemunculan feature dalam kategori dan jumlah kategori di mana feature tersebut muncul serta pemilihan feature ini berpengaruh terhadap model klasifikasi yang akan dihasilkan. 4. Feature Selection menggunakan Information Gain,
CHI dan OCFS menghasilkan feature terpilih yang
hampir sama bahkan sama pada threshold tertentu. Akan tetapi perbedaan yang terjadi di antara
measurement function tersebut selain cara perhitungannya adalah terletak dari waktu eksekusi
scoring terhadap feature dimana waktu OCFS paling
cepat kemudian disusul CHI dan waktu eksekusi paling lama di antara semuanya adalah Information
Gain.
DAFTAR PUSTAKA
[1] C. D. Manning, P. Raghavan, & H. SchutzeIR Online Book. Cambridge University Press, 2008.
[2] D. Mladenic & M. Grobelnik. Feature Selection for Classification based on Text Hierarchy. J. Stefan Institute.
[3] E. P. Smith, I. Lipkovich, & K Ye, Weight of Evidence: Quantitative Estimation of Probability Impact. Blacksburgh: Virginia Tech, 2002. [4] Y. Jun, N. Liu, B. Zhang, S. Yan, Z. Chen, Q. Cheng, W. Fan, & W.
Y. Ma, OCFS: Optimal Orthogonal Centroid Feature Selection for Text Categorization. ACM Press, 2005.
[5] M. Scherf & W. Brauwer, Feature Selection by Means of a Feature Weighting Approach. Munchen: Technische Universitaat Munchen, 1997.
[6] M. A. Hall & L. A. Smith, Feature Subset Selection: A Correlation Based Filter Approach. University of Wakaito.
[7] R. Kohavi & G. H. John, Wrapper for feature subset selection. In proceeding of Artificial Intelligence. pp. 273-324, 1997.
[8] R. Feldman & J. Sanger, Text Mining Handbook. Cambridge University Press, 2006.
[9] F. Z. Tala. A Study Stemming Effect on Information Retrieval. Netherland:Universiteit van Amsterdam.
[10] W. Shang, H. Huang, H. Zhu, Y. Lin, Y. Qu, & Z. Wang, A Novel Feature Selection Algorithm for Text Categorization, 2007.
[11] Y. Yang & J. O. Pederson, A Comparative Study on Feature Selection in Text Categorization, In Proceeding of the 14th
Lama Eksekusi 0.015 0.02 0.025 0.03 Lama Eksekusi
![Gambar 1 Filter Based Feature Selection [7]](https://thumb-ap.123doks.com/thumbv2/123dok/4465306.2982375/1.892.470.829.789.854/gambar-filter-based-feature-selection.webp)