Fakultas Ilmu Komputer
Universitas Brawijaya
2487
Analisis Segmentasi Pelanggan Kartu Prabayar Kabupaten Malang
dengan RFM Model Menggunakan Metode Fuzzy C-Means Clustering
(Studi Kasus : PT. XYZ)
Akbar Ilham1, Nanang Yudi Setiawan2, Tri Afirianto3
Program Studi Sistem Informasi, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2 [email protected], 3[email protected]
Abstrak
PT.XYZ merupakan salah satu perusahaan operator telekomunikasi yang ada di Indonesia yang menyediakan jasa GSM (global system for mobile communication) prabayar. PT.XYZ berkomitmen untuk melayani seluruh kota hingga pelosok Indonesia tidak terkecuali Kabupaten Malang dengan terus berupaya mempertahankan dan meningkatkan jumlah pelanggan sekaligus pemakaian layanan yang disediakan. Perusahaan yang memberikan pelayanan yang berbeda berdasarkan karakteristik atau perilaku setiap pelanggan dalam mengonsumsi suatu produk dapat membangun dan memperkuat hubungan pelanggan yang loyal dan tahan lama. Data yang digunakan dalam penelitian ini adalah data transaksi pelanggan PT.XYZ daerah operasional Kabupaten Malang dengan periode waktu 01 Januari 2019 – 31 Maret 2019 yang berjumlah 35.868 transaksi. Segmentasi pelanggan merupakan strategi untuk membagi pelanggan menjadi subkelompok yang berbeda, bermakna, dan homogen sesuai dengan karakteristiknya.
Tujuan utama segmentasi pelanggan adalah untuk memahami basis pelanggan
dan mendapatkan wawasan pelanggan yang akan memungkinkan desain dan pengembangan
strategi pemasaran yang berbeda
. Karakteristik pelanggan dapat dilihat melalui pemodelan data transaksi pelanggan menggunakan model RFM (recency, frequency, dan monetary) yaitu rentang waktu transaksi terakhir (recency), jumlah transaksi (frequency), dan uang yang dikeluarkan (monetary). Fuzzy C-Means Clustering dapat menjadi salah satu pilihan dalam menyelesaikan masalah segmentasi pelanggan. Metode Elbow digunakan untuk menunjang proses clustering dengan menentukan jumlah cluster dalam penerapan Fuzzy C-Means Clustering. Modified Partition Coefficient (MPC) dan Euclidean Distance (EU) adalah metode validasi yang digunakan untuk menilai ketepatan hasil cluster berdasarkan letak data ke titik pusat terdekat. Pada penelitian ini clustering dengan 2 cluster adalah hasil terbaik. Hasil segmentasi pelanggan divisualisasikan menjadi halaman dashboard yang terdiri dari gabungan tabel, diagram, dan grafik yang saling berintegrasi dan memuat informasi yang dibutuhkan perusahaan. Hasil visualisasi dashboard diuji oleh pengguna untuk memperoleh tingkat keberterimaan pengguna terhadap dengan menggunakan analisis System Usability Scale (SUS). Hasil pengujian dashboard menujukan nilai rata-rata yaitu 80 yang termasuk dalam kategori acceptable.Kata kunci: segmentasi pelanggan, RFM, Fuzzy C-Means Clustering, Elbow, MPC, dashboard, SUS Abstract
PT. XYZ is a telecommunications operator company in Indonesia that provides prepaid GSM (global system for cellular communication) services. PT. XYZ support to serve the whole city until remote areas of Indonesia are no exception Malang Regency by continuing to increase the number and increase the number of customers when providing the services provided. Companies that provide different services based on the characteristics or each customer in the form that provides services and build loyal and long-lasting relationships. The data used in this study is the transaction data of PT. XYZ customers in Malang Regency operational area with a period of time January 1 2019 - March 31 2019 that made 35,868 transactions. Customer segmentation is a strategy to divide customers into different, different, and homogeneous subgroups according to their characteristics. The main purpose of customer segmentation is to determine the customer base and gain customer insights that will enable the design and development of different marketing strategies. Customer characteristics can be seen through customer transaction data modeling using RFM (recency, frequency, and monetary) models, namely the
Fakultas Ilmu Komputer, Universitas Brawijaya
time span of the last transaction (recency), number of transactions (frequency), and money spent (monetary). Fuzzy C-Means Clustering can be an option in solving customer segmentation problems. The Elbow method is used to support the clustering process by determining the number of clusters in the application of Fuzzy C-Means Clustering. Modification of Partition Coefficients (MPC) and Euclidean Distance (EU) is a validation method used to obtain the accuracy of cluster results using data to the nearest central point. In this study clustering with 2 clusters is the best result. The results of customer segmentation are visualized into a dashboard page consisting of a combination of integrated tables, diagrams and graphs and information needed by the company. The results of dashboard visualization are sponsored by users to obtain the level of user acceptance of using the System Usage Scale (SUS) analysis. Dashboard test results show an average value of 80 which is included in the acceptable category.
Keywords: customer segmentation, RFM, Fuzzy C-Means Clustering, Elbow, MPC, dashboard, SUS
1. PENDAHULUAN
PT.XYZ merupakan salah satu perusahaan operator telekomunikasi yang ada di Indonesia. Tercatat PT.XYZ sudah menyediakan jasa GSM (global system for mobile communication) prabayar sejak tahun 1995. Ada dua jenis kartu yang diproduksi yaitu kartu prepaid (prabayar) dan kartu postpaid (pascabayar). Di indonesia penggunaan kartu prabayar lebih diminati karena kemudahan dan harganya yang murah. PT.XYZ berkomitmen untuk melayani seluruh kota hingga pelosok Indonesia tidak terkecuali Kabupaten Malang dengan terus berupaya mempertahankan dan meningkatkan jumlah pelanggan yang memakai telepon genggam sekaligus meningkatkan pemakaian layanan yang disediakan.
Kepuasan pelanggan akan berujung pada kesetiaan pelanggan untuk menjaga hubungan yang baik dengan perusahaan (Tsiptsis & Chorianopoulos, 2010). Dalam kondisi seperti ini perusahaan operator telekomunikasi perlu melakukan pendekatan secara personal terhadap pelanggan dalam menyusun dan mengembangkan kebijakan strategis yang lebih efektif dan dapat bersaing secara unggul. Salah satu caranya adalah dengan menerapkan strategi Customer Relationship Management (CRM).
CRM adalah filosofi bisnis dan strategi yang berorientasi kepada pelanggannya (customercentric). Hal ini dapat di tinjau dari perilaku pelanggan dalam mengonsumsi suatu produk atau jasa untuk membangun, mengelola, dan memperkuat hubungan pelanggan yang loyal dan tahan lama. Untuk berhasil dengan penerapan CRM maka perlu dilakukan suatu strategi yang disebut segmentasi pelanggan. Segmentasi pelanggan adalah strategi untuk membagi pelanggan menjadi subkelompok yang berbeda, bermakna, dan homogen berdasarkan
berbagai atribut dan karakteristik. Segmentasi pelanggan memungkinkan organisasi untuk memahami pelanggan mereka dan membangun strategi yang berbeda (Tsiptsis & Chorianopoulos, 2010).
Customer profiling merupakan hasil analisis data dengan menggunakan teknik pemodelan. Salah satu teknik pemodelan data adalah model RFM (recency, frequency, monetary). Model RFM merupakan salah satu metode pengelompokan pelanggan dan analisis nilai pelanggan berdasarkan recency, frequency dan monetary (Cheng & Chen, 2009).
Metode clustering yang dipakai untuk segmentasi pelanggan pada penelitian ini adalah Fuzzy C-Means (FCM). Metode ini merupakan metode non-hirarki dimana jumlah kelompoknya ditentukan terlebih dahulu berdasarkan kriteria yang diberikan. FCM menggunakan model pengelompokan fuzzy sehingga data dapat menjadi anggota dari semua kelas atau cluster terbentuk dengan derajat atau tingkat keanggotaan yang berbeda antara 0 hingga 1. Menurut (Sausen, Tomczak, & Herrmann, 2005) kemampuan untuk menempatkan pelanggan dalam sejumlah kelompok dapat membantu perusahaan untuk menentukan berbagai strategi pemasaran sesuai dengan keanggotaan pelanggan untuk berbagai kelompok. Serta untuk dapat menghasilkan cluster yang tepat, maka perlu dilakukan uji performa cluster dalam proses clustering tersebut.
Penyampaian informasi dalam bentuk visual atau dashboard lebih mudah dimengerti dan lebih mudah memetakan informasi karena hal tersebut mampu menggantikan penjelasan yang terlalu panjang, serta menggantikan tabel yang rumit dan penuh angka. Namun tidak semua dashboard efektif dan mampu menyajikan informasi yang dibutuhkan perusahaan,
sehingga perlu adanya penilaian tingkat keberterimaan perusahaan pada proses pembangunan dashboard.
2. LANDASAN KEPUSTAKAAN 2.1 Penelitian Terdahulu
Penelitian yang dilakukan oleh Yuliari, Putra, dan Rusjayanti (2015) dengan judul “Customer Segmentation Through Fuzzy C-Means and Fuzzy RFM Method”. Penelitian ini menggunakan Fuzzy RFM dan Fuzy C-Means untuk segmentasi pelanggan potensial menggunakan data transaksi perusahaan mebel. Pada penelitian ini arsitektur data untuk segmentasi pelanggan dibagi menjadi 3 bagian yaitu pemilihan data, preprocessing dan transformasi. Pemilihan data menggunakan data transaksi perusahaan mebel. Percobaan dilakukan dengan mencoba dua hingga lima cluster iterasi maksimal, dan kemudian menerapkan FCM untuk mengklasifikasikan pelanggan. Sebelum itu pada penelitian ini mengimplementasikan metode MPC (Modified Partition Coefficient) untuk cluster validasi untuk memastikan hasil dari clustering benar dan hasil terbaik yaitu dua cluster dengan nilai uji validasi mendekati satu. Hasil penelitian ini menghasilkan 2 cluster yang paling optimal. Cluster 1 untuk pelanggan superstar dengan kesetiaan yang tinggi dan cluster 2 pelanggan occasional dengan frequency yang rendah tetapi monetary tinggi.
Selanjutnya terdapat penelitian yang telah dilakukaniSavitri (2016), yaitu penelitian yang bertujuan untuk mengetahuiMloyalitas dari pelanggan suatu perusahaan dengan cara melakukan segmentasimmpelanggan guna membantu perusahaan dalam mengambil keputusan. Padaipenelitian ini dilakukan analisis terlebih dahulu menggunakan RFM sebelum dilakukan segmentasi menggunakanimetode K-Means Clustering. Penelitian ini juga menggunakanimetode Elbow untuk menujang proses clustering dengan menentukan jumlah segmen yang diterapkan. Hasilnya terbentuk pengelompokanipelanggan dengan duaesegmen dan tigaisegmen. Kemudian berdasarkan analisis RFM, peringkat pertama yang memiliki nilai RFMnyang paling besarsdari kelompokilainnya merupakan kelompokspelanggan yangspaling baik atau bersifattprofitable. Kemudian dalam penelitian ini hasilssegmentasi dimuat dalam bentuksvisual dashboard.
2.2 Data Mining
Data mining adalah bidang multidisiplin, menggambar pekerjaan dari berbagai bidang termasuk basis data teknologi, pembelajaran mesin, statistik, pengenalan pola, pengambilan informasi, jaringan saraf, sistem berbasis pengetahuan, kecerdasan buatan, kinerja tinggi komputasi, dan visualisasi data. Dengan data mining memungkinkan seseorang untuk penemuan pola tersembunyi dalam kumpulan data besar, berfokus pada masalah yang berkaitan dengan kelayakan, kegunaan, efektivitas, dan skalabilitasnya (Agarwal, 2014). Selain itu data mining adalah turunan dari Knowledge Dicovery in Database (KDD) yang merupakan semua proses mengubah data mentah menjadi informasi yang berguna (Pang-Ning, Steinbach dan Kumar, 2006). Mengubah data menjadi informasi pada proses Knowledge Dicovery in Database (KDD) terdiri dari 3 tahapan, yaitu :
1. Data Preprocessing
Pada tahap ini, dilakukan beberapa proses seperti penggabungan data dari beberapa sumber, pembersihan data untuk menghilangkan noise atau outlier, serta memilih atribut data untuk proses data mining.
2. Data mining
Dalam tahapan Data mining, didapatkan pola-pola serta informasi yang tidak terlihat dalam basis data. Dalam data mining terdapat beberapa teknik yang dapat digunakan yaitu Association Rules, Classification, OLAP (Online Analytical Processing), Neural Network, Decision Tree, Clustering, dan Genetic Algorithm.
3. Postprocessing
Tahap Postprocessing untuk memastikan hanya hasil yang valid dan berguna yang digunakan oleh perusahaan. Setelah itu dilakukan proses integrasi hasil data mining. Salah satu contoh yaitu proses visualisasi untuk menganalisa dan mengeksplorasi data dan hasil dari proses data mining dari berbagai sudut pandang.
Fakultas Ilmu Komputer, Universitas Brawijaya Menurut (Dibb, 1998) Segmentasi pelanggan adalah salah satu metode yang efisien untuk mengelola berbagai pelanggan dengan preferensi yang berbeda. Ini adalah proses membagi kelompok pelanggan yang heterogen menjadi kelompok yang homogen berdasarkan karakteristik dan atribut yang sama . Segmentasi pelanggan meningkatkan tidak hanya kepuasan tetapi juga keuntungan yang diharapkan untuk suatu perusahaan. Di antara metode segmentasi, clustering adalah salah satu metode yang paling berguna untuk mengenali kelompok pelanggan yang homogen dan untuk mengembangkan strategi pemasaran yang disesuaikan untuk setiap perusahaan (Shin & Sohn, 2004). Identifikasi segmen harus diikuti dengan membuat profil pengelompokan pelanggan yang terungkap. Profiling diperlukan untuk memahami dan memberi label segmen berdasarkan karakteristik umum anggota. 2.4 Analisis Recency, Frequency, Monetary
(RFM)
Analisis Recency, Frequency, Monetary (RFM) merupakan proses pendekatan yang biasa digunakan untuk memahami di perusahaan operator telekomunikasi untuk perilaku pembelian pelanggan. Dalam menentukan segmentasi pelanggan, model RFM digunakan yang berdasar kepada tiga variabel yaitu recency yang digunakan untuk mencari selisih waktu sejak terakhir melakukan transaksi dan waktu penelitian, frequency untuk mencari jumlah transaksi pembelian, dan monetary untuk mengetahui jumlah uang yang dikeluarkan seluruh pembelian setiap pelanggan.
2.5
Normalisasi Min-Max
Normalisasi digunakan pada penelitian ini agar data yang akan dilakukan proses clustering memiliki range yang jelas tiap variabelnya. Berdasarkan penelitian (Monalisa, 2018) normalisasi dengan metode Min-Max diperlukan untuk menyederhanakan data pada tiap variabel recency, fequency, dan monetary yang memiliki range yang berbeda menjadi nilai 0 hingga 1. Persamaan (1) adalah persamaan normalisasi Min-Max.
𝑥′ = 𝑥−𝑚𝑖𝑛𝑎
𝑚𝑎𝑥𝑎−𝑚𝑖𝑛𝑎 (𝑚𝑎𝑥 − 𝑚𝑖𝑛) + 𝑚𝑖𝑛
(1)
Dengan:
𝑥′ = nilai setelah dinormalisasi
𝑥 = nilai yang akan dinormalisasi 𝑚𝑖𝑛𝑎 = nilai minimal tiap variabel
𝑚𝑎𝑥𝑎 = nilai maximal tiap variabel
𝑚𝑖𝑛𝑎 = nilai minimal tiap variabel
𝑚𝑖𝑛 = rentang minimal x dengan nilai 0 𝑚𝑎𝑥 = rentang maximal x dengan nilai 1
2.6 Metode Elbow
Metode Elbow adalah metode yang digunakan untuk menentukan jumlah cluster yang tepat dengan melihat penurunan dramatis grafik nilai SSE (Sum Square of Error) jumlah cluster yang diujikan dan membentuk sebuah lekukan yang disebut kriteria siku, penurunan secara dramatis pada titik tertentu juga diikuti dengan mulai stabilnya nilai SSE pada titik-titik selanjutnya. Nilai titik tersebut adalah nilai yang dijadikan nilai k atau jumlah cluster yang terbaik (Purnima & Arvind, 2014).
2.7 Fuzzy C-Means
Fuzzy C-means (FCM) pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981. Metode ini merupakan pengembangan dari K-Means dengan menggabungkan prinsip fuzzy dengan metode K-Means. Berdasarkan (Wijaya, 2014) berbeda halnya dengan K-Means, data yang di-cluster menggunakan FCM akan menjadi aggota dari setiap cluster yang ada, ikatan data dengan cluster ditentukan oleh nilai keanggotannya yang berada pada rentang 0 hingga 1. Konsep dasar Fuzzy C-Means Clustering yaitu menentukan pusat cluster, tahap ini berfungsi untuk menandai lokasi rata-rata untuk setiap cluster. Pada kondisi awal, pusat cluster belum memiliki keakuratan yang baik. Setiap titik data pada setiap cluster memiliki derajat keanggotaan yang berbeda. Untuk membuat pusat cluster bergerak menuju lokasi yang tepat, pusat cluster serta derajat keanggotaan setiap titik data harus diperbaiki secara berulang.
2.8 Modified Partition Coefficient (MPC) Untuk pengujian hasil cluster digunakan metode Modified Partition Coefficient (MPC). MPC merupakan pengembangan dari metode Partition Cofficient (PC). Partition Coefficient (PC) merupakan metode yang mengukur jumlah cluster yang mengalami overlap. Nilai PC berada dalam batas 0 ≤ PC (c) ≤ 1. Pada umumnya jumlah cluster yang paling optimal
ditentukan dari nilai PC yang paling besar (𝑚𝑎𝑥2 ≤ 𝑐 ≤𝑛−1 PC(𝑐)). Persamaan (2) adalah algoritme metode PC : 𝑃𝐶(𝑐) =𝑁1∑𝑐𝑖=1∑𝑁𝑗=1(𝜇𝑖𝑗2) (2) Dimana : C = jumlah cluster N = jumlah data
𝜇𝑖𝑗= derajat keanggotaan data k-j pada cluster
ke-i
𝑃𝐶(𝑐) = nilai indeks PC pada cluster ke-c Partition coefficient cenderung mengalami perubahan yang monoton terhadap beragam nilai 𝑐 (jumlah cluster). Modified Partition Coefficient dapat mengurangi perubahan yang monoton tersebut. Nilai MPC berada dalam batas 0 ≤ PC(𝑐) ≤ 1 dan jumlah cluster yang paling optimal ditentukan dari nilai MPC yang paling besar. Persamaan (3) adalah algoritme metode MPC (Ramadhan et al., 2015):
𝑀𝑃𝐶(𝑐) = 1 − 𝑐
𝑐−1 (1 − 𝑃𝐶(𝑐)) (3)
Dimana :
c = jumlah cluster
𝑀𝑃𝐶(𝑐) = nilai indeks MPC pada cluster ke-c 2.9 Euclidean Distance (ED)
Euclidiean Distance (ED) merupakan metode yang sering digunakan dalam melakukan analisis cluster. Perhitungan ED dilakukan untuk mencari jarak data yang paling dekat dengan titik pusat cluster dan jarak tersebut digunakan untuk menentukan cluster dari anggota pada proses Clustering (Haviluddin, Fanany, & Gafar, 2018). Pada penelitian ini ED digunakan untuk melakukan validasi bahwa data hasil clustering sesuai dengan jarak terdekat data ke pusat cluster yang terbentuk. Persamaan 2.7 merupakan formula Euclidean Distance :
𝑇(𝑥, 𝑦) = √(𝑇1𝑥− 𝑇1𝑦)2+ (𝑇2𝑥− 𝑇2𝑦)2+. . . . +(𝑇𝑘𝑥− 𝑇𝑘𝑦)2 (4)
Dimana :
𝑇(𝑥, 𝑦) = jarak data 𝑥 ke pusat cluster 𝑦 𝑇𝑘𝑥 = data pada atribut 𝑘
𝑇𝑘𝑦 = titik pusat 𝑗 pada atribut 𝑘
2.10 Dashboard
Dashboard adalah antarmuka komputer yang kaya akan elemen di dalamnya termasuk grafik, laporan, indikator visual, dan mekanisme
peringatan yang digabungkan ke dalam platform informasi yang dinamis dan relevan (Malik, 2005). Dashboard muncul untuk memudahkan perusahaan dalam mengambil keputusan dari hasil ekstraksi data secara cepat sehingga mampu mengetahui kondisi terkini dan posisi strategi bisnis.Kelebihan dan kegunaan dashboard pada organisasi, di antaranya :
1. Berbagi informasi
2. Sebagai alat komunikasi strategi 3. Mengawasi penerapan strategi 2.11 Usability Testing
Pengembangan dashboard tidak hanya berfokus pada selesainya dashboard tersebut melainkan ada hal lain yang perlu dilakukan, yaitu pengukuran antarmuka yang dilihat dari sisi pengguna akhir, hal tersebut dilakukan untuk mengetahui penilaian pengguna terhadap dashboard yang telah dibuat. System Usability Scale (SUS) adalah salah satu metode yang dapat digunakan untuk melakukan pengujian antarmuka yang dilakukan langsung oleh pengguna akhir (end user). Adapun beberapa kelebihan yang dimiliki System Usability Scale menurut (Bangor, Kortum, & Miller, 2008), di antaranya :
1. Fleksibel 3. Hemat
2. Cepat 4. Mudah
dipahami
3. METODOLOGI PENELITIAN
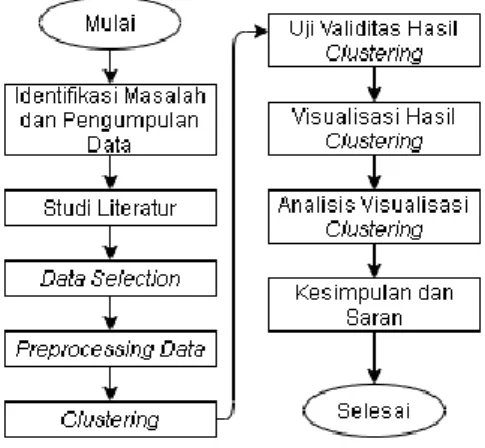
Alur penelitian analisis segmentasi pelanggan dengan metode Fuzzy C-Means Clustering berdasarkan RFM model pada PT.XYZ digambarkan dalam diagram alir seperti pada gambar 1.
Fakultas Ilmu Komputer, Universitas Brawijaya
Gambar 1. Diagram Alir Penelitian
Tahap pertama penulis melakukan identifikasi masalahan terkait objek penelitian PT. XYZ sekaligus pengumpulan data. Data diextraksi dan dianalisis untuk mengidentifikasi atribut yang digunakan. Tahapan kedua adalah studi literatur untuk mencari teori yang tepat dan relevan serta mencari penelitian yang memiliki masalah yang sejenis dengan permasalahan yang sedang diteliti. Tahapan berikutnya adalah data selection, tahapan ini dilakukan untuk memilihan variabel yang berkaitan dengan segmentasi pelanggan dalam proses clustering. Dalam penelitian ini variabel RFM (Recency, Frequency, Monetary) digunakan untuk mengidentifikasi perilaku belanja pelanggan.
Selanjutnya Preprocessing data, terdiri dari beberapa tahap seperti transformasi data, pembersihan data (data cleansing) dari noise atau outlier seperti data yang tidak lengkap, data yang tidak valid ataupun salah ketik, serta normalisasi. Transformasi data(data transformation) memiliki beberapa kegunaan yaitu menyeragamkan data menjadi nilai yang lebih kecil dan sesuai untuk diproses dalam data mining, untuk mengatasi data yang terdistribusi tidak normal dan juga identifikasi outlier dengan lebih baik (Shofiani, 2017). Normalisasi dengan Metode Min-Max agar data R, F dan M tidak terlalu jauh.
Tahapan ke lima adalah Clustering, Pada tahap ini, dilakukan metode clustering dengan metode Fuzzy C-Means dengan inputan berupa data dari hasil seleksi berdasarkan RFM model dan telah melewati tahap preprocessing data. Sebelum melakukan clustering terlebih dahulu menentukan jumlah cluster yang digunakan dengan menggunakan metode Elbow. Selanjutnya hasil clustering yang didapatkan harus diuji agar dapat mengetahui validitas dari hasil clustering tersebut. Uji validitas cluster
dilakukan dengan menggunakan metode Modified Partition Coefficient (MPC) dan Euclidean Distance (EU).
Tahapan berikutnya adalah visualisasi. Visualisasi dalam bentuk dashboard dibuat dari hasil clustering yang telah diuji validitasnya. Dilanjutkan dengan tahapan analisis visualisasi clustering untuk mengetahui tingkat efektifitas dari visualisasi yang dibuat. Analisis visualisasi clustering dilakukan menggunakan System Usability Scale (SUS). Tahap terakhir yaitu penarikan kesimpulan berdasarkan analisis dan pembahasan yang dilakukan untuk menjawab rumusan masalah terkait segmentasi pelanggan serta pemberian saran untuk perkembangan penelitian di masa mendatang.
4. HASIL DAN PEMBAHASAN
Pada bagian ini akan membahas mulai dari pemilihan data, preprocessing data, analisis hasil clustering hingga visualisasi dengan dashboard.
4.1 Data Selection
Pemilihan data dilakukan berdasarkan data transaksi pelanggan kartu pra bayar PT. XYZ dengan daerah operasional Kabupaten Malang yang terdiri dari lima variabel yaitu period, msisdn, result_code, Kabupaten dan recharge_amount. Variabel ini telah terbentuk dari hasil transaksi 9.379 pelanggan selama bulan Januari hingga Maret 2019 sebanyak 35.868 transaksi. Namun pada penelitian ini tidak semua variabel digunakan, untuk itu dilakukan pemilihan dari lima variabel tersebut menjadi tiga variabel saja yaitu period, msisdn dan recharge_amount. Hal ini disebabkan karena ketiga variabel tersebut merupakan variabel yang diperlukan untuk mendapatkan nilai RFM. Selanjutnya dilakukan pergantian nama variabel guna mempermudah proses penelitian seperti tercantum pada Tabel 1.
Tabel 1. Perubahan Nama Variabel Variabel lama
terpilih
Variabel baru terpilih
period Tanggal_transaksi
msisdn Id_pelanggan
4.2 Ekstraksi RFM
Ekstraksi nilai RFM dilakukan berdasarkan variabel yang telah dipilih pada proses pemilihan data. Ekstraksi nilai recency tiap pelanggan didapatkan berdasarkan selisih tanggal pemrosesan data dan tanggal transaksi terakhir, nilai frequency didapatkan dari banyaknya transaksi dalam satu periode, sedangkan nilai monetary didapatkan dari hasil penjumlahan seluruh uang yang dikeluarkan tiap pelanggan dalam melakukan transaksi. potongan Hasil ekstraksi nilai recency, frequency dan monetary tiap pelanggan dapat dilihat pada Tabel 2.
Tabel 2. Potongan Hasil Ekstraksi RFM Id_pelanggan Recency Frequency Monetary
0000 330 3 150.000 0001 277 6 231.000 0002 324 2 20.000 0003 292 6 135.000 0004 285 6 176.000 4.3 Preprocessing Data
Dalam tahap preprocessing data pada penelitian ini adalah transformasi data ,cleansing data, serta normalisasi min-max. Pada tahapan transformasi data dilakukan proses Logarithmic pada data hasil ekstraksi RFM untuk mengatasi data terdistribusi tidak normal yang memiliki nilai yang tidak konsisten dan cenderung berkumpul pada suatu area, untuk itu maka diubah nilainya menggunakan fungsi log10. Hasil dari data transformasi dapat diliat pada Tabel 3.
Tabel 3. Potongan Data Hasil Transformasi Id_pelanggan Recency Frequency Monetary
0000 2,51851 0,47712 5,17609
0001 2,44247 0,77815 5,32837
0002 2,51054 0,30102 4,30102
0003 2,46538 0,77815 5,13033
0004 2,45484 0,77815 5,24551
Setelah melalui tahap transformasi terdapat data yang mengandung outlier. Outlier merupakan data yang muncul dan memiliki karakteristik yang jauh berbeda dengan data lainnya, biasanya muncul dalam bentuk nilai extream dari sebuah variabel ataupun gabungan variabel. Data dengan kandungan outlier dapat
merusak hasil dari clustering yang akan dilakukan sehingga perlu dilakukannya data cleansing atau penghapusan baris. Pada variabel recency memiliki proporsi 4,094 persen outlier atau sebanyak 384 data yang mengandung outlier, Pada variabel monetary memiliki persentase proporsi outlier sebesar 1,844 atau sebanyak 173 data dari 9.379 data sedangkan variabel frequency tidak memiliki outlier. Hasil identifikasi outlier terdapat pada Tabel 4.
Tabel 4. Hasil Identifikasi Outlier
Recency Frequency Monetary
Jumlah oulier 385 0 173 Proporsi outlier (%) 4,09425 0 1,84454 Rata-rata outlier 2,53485 0 3,70648 Rata-rata data dengan outlier 2,45622 0,50435 4,86537 Rata-rata data tanpa outlier 2,45286 0,50435 4,88714
Setelah data bebas dari outlier, kemudian dilakukan penyeragaman range data menggunakan normalisasi dengan metode Min-Max. Semakin banyak jumlah transaksi dan besaran uang yang dikeluarkan akan menghasilkan nilai frequency dan monetary besar pula, namun berbanding terbalik dengan nilai recency sehingga perlu dibalik dengan proses pengurangan 1 terhadap hasil normalisasi pada variabel recency (Annisa, 2017). Hasil dari normalisasi terdapat pada Tabel 5.
Tabel 5. Potongan Data Hasil Normalisasi Id_pelanggan Recency Dibalik Frequency Monetary 0000 0,0593 0,3962 0,6576 0001 0,7501 0,6462 0,7362 0002 0,1317 0,25 0,2055 0003 0,5420 0,6462 0,6339 0004 0,6377 0,6462 0,6934 4.4 Clustering
Data yang telah melalui tahapan preprocessing siap untuk dilakukan segmentasi menggunakan teknik clustering dengan tujuan
mengenali
kelompok
pelanggan
yang
homogen dan mengembangkan strategi
pemasaran yang disesuaikan
. LangkahFakultas Ilmu Komputer, Universitas Brawijaya pertama dalam melakukan clustering adalah dengan menentukan jumlah cluster yang digunakan. Metode yang digunakan dalam menentukan jumlah cluster adalah metode Elbow. Garafik dari Metode Elbow pada Gambar 2 memperlihatkan titik 1 yang memiliki nilai SSE 1.253,7974 mengalami penurunan drastis pada titik 2 dengan nilai SSE 630,3939 dan titik 3 yaitu 473,6384. Penurunan tidak lagi terjadi secara signifikan pada titik 4 hingga titik 10 sehingga penentuan jumlah cluster menggunakan metode Elbow adalah sebanyak 2 atau 3 cluster.
Gambar 2. Grafik Metode Elbow
Setelah mendapatkan nilai k berdasarkan metode Elbow yang telah dilakukan. Proses selanjutnya adalah melakukan clustering dengan metode Fuzzy C-Means. Pada proses clustering menggunakan metode Fuzzy C-Means dengan 2 cluster, anggota pada cluster pertama dan kedua berturut-turut adalah 5.438 dan 3.443. Pada segmentasi pelanggan PT.XYZ dengan 2 cluster membedakan pelanggan berdasarkan urutan prioritas penilaian pelanggan terbaik menjadi kelompok pelanggan gold atau yang bersifat loyal dan kelompok pelanggan bronze atau kurang loyal. Pada proses clustering menggunakan Fuzzy C-Means dengan 2 cluster menghasilkan bahwa cluster 1 dengan rentang recency 260-318 hari memiliki rata-rata nilai recency yang rendah dibanding cluster 2. Sementara itu cluster 1 dengan rentang frequency 1-16 memiliki nilai rata-rata frequency yang lebih tinggi dari cluster 2. Fuzzy C-Means dengan 2 cluster juga menghasilkan bahwa cluster 1 dengan rentang monetary 15.000-690.000 memiliki rata-rata nilai monetary yang lebih tinggi dibandingkan dengan cluster 2Tabel 6 merupakan hasil clustering dengan 2 cluster.
Tabel 6. Potongan Data Hasil Fuzzy C-Means 2
Cluster Id_pelanggan R F M Cluster 0000 0,0593 0,3962 0,6576 2 0001 0,7501 0,6462 0,7362 1 0002 0,1317 0,25 0,2055 2 0003 0,5420 0,6462 0,6339 1 0004 0,6377 0,6462 0,6934 1
Custering yang dilakukan menggunakan metode Fuzzy C-Means dengan 3 Cluster menghasilkan jumlah anggota yang berbeda. Pada cluster pertama memiliki jumlah anggota sebanyak 3.427, cluster kedua memiliki jumlah anggota 1.885 sedangkan cluster ketiga memiliki jumlah anggota sebanyak 3.569. Fuzzy C-Means dengan 3 cluster membedakan pelanggan berdasarkan urutan prioritas penilaian pelanggan terbaik menjadi kelompok pelanggan gold atau yang bersifat loyal, kelompok pelanggan silver atau kurang loyal namun memiliki prospek yang lebih baik untuk menjadi pelanggan yang loyal serta kelompok pelanggan bronze atau yang bersifat tidak loyal. Nilai rata-rata recency terendah terdapat pada cluster 3 dengan rentang recency 260-309 hari diikuti dengan cluster 1 yang memiliki rentang recency 260-319 hari, kemudian rata-rata recency yang paling tinggi adalah cluster 2 dengan rentang recency 276-355 hari. . Sementara itu cluster 3 dengan rentang frequency 2-16 kali transaksi memiliki nilai rata-rata frequency yang paling tinggi diikuti dengan cluster 1 yang memiliki rentang frequency 1-8 kali transaksi, kemudian rata-rata frequency yang paling rendah adalah cluster 2 dengan rentang frequency 1-5 kali transaksi. Pada proses clustering menggunakan Fuzzy C-Means dengan 3 cluster menghasilkan bahwa cluster 3 dengan rentang monetary 30.000-690.000 memiliki rata-rata nilai monetary yang paling tinggi diikuti dengan cluster 1 yang memiliki rentang monetary 8.000-335.000, kemudian rata-rata monetary yang paling rendah adalah cluster 2 dengan rentang monetary 10.000-400.000. Tabel 7 merupakan hasil clustering dengan 3 cluster.
Tabel 7. Potongan Data Hasil Fuzzy C-Means 3
Cluster Id_pelanggan R F M Cluster 0000 0,0593 0,3962 0,6576 2 0001 0,7501 0,6462 0,7362 3 0002 0,1317 0,25 0,2055 2 0003 0,5420 0,6462 0,6339 3 0004 0,6377 0,6462 0,6934 3
Untuk melakukan pengujian hasil cluster digunakan metode Modified Partition Coefficient (MPC) dan Euclidean Distance (EU). Penentuan cluster terbaik diambil dari jumlah cluster yang memiliki nilai Modified Partition Coefficient paling tinggi. Jika dibandingkan nilai Modified Partition Coefficient 2 cluster dan 3 cluster berturut-turut adalah 0,4844421 dan 0,4132718, sehingga 2 cluster adalah jumlah yang paling baik. Sedangkan untuk uji validitas cluster dilakukan dengan pengukuran jarak terdekat data ke titik pusat cluster menggunakan Euclidean Distance. Seluruh data pada 2 cluster maupun 3 cluster menunjukkan nilai true yang berarti cluster yang terbentuk berdasarkan derajat keanggotaan sama dengan jarak terdekat data dengan titik pusat. 4.6 Visualisasi Hasil Cluster
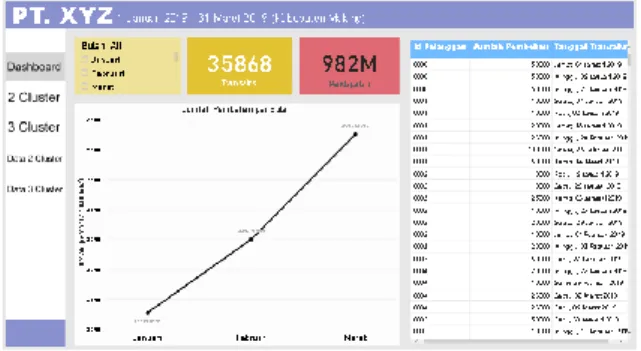
Visualisasi hasil Cluster diimplementasikan ke dalam halaman-halaman dashboard yang informatif dan mudah dipahami guna membantu perusahaan dalam mengambil keputusan. Pada halaman depan visualisasi dashboard menampilkan informasi seperti jumlah pembelian dalam bentuk diagram garis, daftar transaksi pelanggan dalam bentuk tabel yang memuat ID pelanggan, jumlah pembelian dan tanggal transaksi. Halaman depan juga memuat informasi jumlah transaksi dan total pendapatan yang ditampilkan dalam bentuk card serta disediakan slicer agar pengguna dapat mengatur informasi halaman depan dashboard berdasarkan bulan. Gambar 3 adalah tampilan halaman depan dashboard.
Gambar 3. Halaman Depan Dashboard
Pada visualisasi cluster jumlah anggota divisualisasi menggunakan diagram donat untuk menampilkan persentase jumlah anggota tiap cluster seperti pada Gambar 4. Kemudian Gambar 5 merupakan visualisasi dalam bentuk card yang dibuat untuk menampilkan rata-rata nilai recency, frequency, dan monetary pada tiap cluster, Berdasarkan prioritas penilaian
pelanggan PT. XYZ dimana nilai frequency pelanggan merupakan indikator pertama maka visualisasi jumlah pelanggan berdasarkan frequency pada tiap cluster ditampilkan menggunakan dengan bar chart. Visualisasi Bar chart yang ditunjukan Gambar 6 juga memungkinkan pengguna untuk melihat rincian data pada halaman Cluster dengan melakukan drillthrough menggunakan click kanan.
Gambar 4. Persentase Jumlah Anggota Cluster
Gambar 5. Nilai Rata-rata Ketiga Variabel
Gambar 6. Jumlah Pelanggan Berdasarkan
Frequency
Pada visualisasi cluster juga menampilkan 15 pelanggan terbaik dan 15 pelanggan terburuk berdasarkan nilai frequency, monetary dan recency dalam bentuk tabel seperti yang terlihat pada Gambar 7. Rincian visualisasi cluster seperti persebaran pelanggan berdasarkan hubungan variabel dan persebaran pelanggan secara keseluruhan berturut-turut
Fakultas Ilmu Komputer, Universitas Brawijaya divisualisasi menggunakan grafik dan scatter plot 3D seperti pada Gambar 8 dan Gambar 9.
Gambar 7. 15 Pelanggan Terbaik
Gambar 8. Persebaran Pelanggan Berdasarkan Hubungan Variabel
Gambar 9. Scatter Plot 3D Persebaran Pelanggan
4.7 Analisis Hasil Usability Testing
Hasil visualisasi dashboard di uji menggunakan analisis System Usability Testing (SUS) untuk menilai tingkat keberterimaan pengguna. Dalam penggunan SUS terdiri dari 10 pernyataan yang disajikan dalam kuisioner dimana setiap pertanyaan disediakan skala penilaian 1 yang mewakilkan tanggapan “sangat tidak setuju” hingga 5 yang mewakilkan tanggapan “sangat setuju”. Nomer ganjil merupakan pernyataan yang bersifat positif dan pernyataan dengan nomer genap adalah pernyataan yang sifatnya negatif. Skor SUS berkisar dari 0 hingga 100 yang didapatkan dari akumulasi bobot pada setiap pertanyaan dan telah dikalikan 2,5. Bobot setiap pernyataan didapatkan berdasarkan skala yag diberikan responden yang memiliki ketentuan yaitu nilai skala yang diberikan kepada pernyataan dengan nomor ganjil akan dikurangi 1 (posisi skala – 1) sedangkan nilai skala yang diberikan kepada pernyataan dengan nomor genap akan menjadi pengurang nilai 5 (5 - posisi skala). Hasil pengujian menggunakan SUS menunjukkan skor akhir 80, artinya dashboard yang terbentuk masuk ke dalam kategori Acceptable atau diterima dengan baik dan dapat digunakan dengan mudah oleh perusahaan sebagai media penyampaian informasi dalam proses pengambilan keputusan.
5. KESIMPULAN
1. Hasil pemodelan data menggunakan model RFM berdasarkan data transaksi pelanggan PT.XYZ daerah operasional Kabupaten Malang dapat menggambarkan profil pelanggan. Nilai pada variabel recency menunjukkan rentang waktu terakhir kali pelanggan melakukan transaksi. Nilai pada variabel frequency menunjukkan seberapa sering pelanggan melakukan transaksi dalam satu periode waktu. Nilai pada variabel monetary menunjukkan total uang yang dikeluarkan setiap pelanggan dalam mengkonsumsi layanan kartu prabayar PT.XYZ dalam satu periode waktu.
2. Metode Fuzzy C-Means Clustering dapat menjadi pilihan dalam menyelesaikan masalah segmentasi pelanggan. Data yang terbentuk berdasarkan model RFM dilakukan preprocessing data sehingga menjadi data yang sesuai dan bisa digunakan pada metode Fuzzy C-Means clustering. Jumlah cluster ditentukan menggunakan metode Elbow dan hasilnya ditemukan
jumlah cluster yang digunakan dalam Fuzzy C-Means clustering adalah sebanyak 2 dan 3 cluster. Pada Fuzzy C-Means clustering dengan 2 cluster menunjukkan cluster 1 berada di peringkat pertama atau termasuk kelompok pelanggan gold atau yang bersifat loyal diikuti dengan cluster 2 kelompok pelanggan bronze atau kurang loyal. Hal tersebut dikarenakan cluster 1 memiliki nilai rata-rata recency yang lebih rendah, selain itu cluster 1 juga memiliki nilai rata-rata frequency dan monetary yang lebih tinggi dibandingkan dengan cluster 2. Pada Fuzzy C-Means clustering dengan 3 cluster menunjukkan peringkat cluster terbaik atau termasuk kelompok pelanggan gold atau yang bersifat loyal yaitu cluster 3 kemudian diikuti dengan cluster 1 yang termasuk kelompok pelanggan silver atau kurang loyal namun memiliki prospek yang lebih baik untuk menjadi pelanggan yang loyal serta cluster 2 yang merupakan kelompok pelanggan bronze atau yang bersifat tidak loyal. Hal ini disebabkan karena nilai rata-rata recency paling rendah dimiliki oleh cluster 3 dan diikuti dengan cluster 1 kemudian cluster 2, selain itu cluster 3 juga memiliki nilai rata-rata frequency dan monetary yang paling tinggi yang diikuti dengan cluster 1 kemudian cluster 2. 3. Hasil uji performa menggunakan metode
penilaian indeks MPC menunjukkan Fuzzy C-Means clustering dengan 2 cluster adalah jumlah cluster terbaik. Kemudian pengujian menggunakan Euclidean Distance (EU) yang dilakukan untuk mengetahui kesamaan hasil cluster yang didapatkan berdasarkan derajat keanggotaan dengan jarak terdekat tiap data ke titik pusat pada Fuzzy C-Means clustering menghasilkan nilai true yang artinya semua data berada di cluster yang tepat.
4. Visualisasi dashboard dibuat dalam bentuk halaman-halaman informatif yang terdiri dari tabel, diagram, dan grafik yang disusun dan diintegrasikan sehingga memuat informasi yang berguna dan mudah dipahami. Hasil perhitungan responden dengan System Usability Testing (SUS) menunjukkan nilai rata-rata yang tinggi yaitu 80 yang termasuk dalam kategori dashboard acceptable, sehingga dapat disimpulkan bahwa dashboard yang dibuat mampu menyajikan informasi yang
dibutuhkan perusahaan dalam menyusun kebijakan.
6. SARAN
Berikut merupakan beberapa saran yang dapat diberikan untuk penelitian selanjutnya diantaranya, penelitian dapat dikembangkan menggunakan objek penelitian dengan jumlah data pelanggan yang lebih banyak. Kemudian Metode clustering atau metode ekstraksi dapat dikembangkan menggunkan metode lain agar hasil yang didapatkan lebih detail. Rentang waktu transaksi juga dapat ditambah untuk memperluas analisis terhadap variabel Frequency dan Monetary. Hasil dari penelitian ini dapat digunakan sebagai acuan pembuatan sistem informasi pelanggan yang dapat membantu perusahaan.
7. DAFTAR PUSTAKA
Agarwal, S. (2014). Data mining: Data mining concepts and techniques. In Proceedings - 2013 International Conference on
Machine Intelligence Research and Advancement, ICMIRA 2013.
Annisa, A. Veronica. 2017. Segmentasi
Pelanggan Menggunakan Clustering
KMeans Dan Model RFM (Studi
Kasus: Pt. Bina Adidaya Surabaya).
Skripsi. Institut Teknologi Sepuluh
Nopember.
Bangor, A., Kortum, P. T., & Miller, J. T. (2008). An empirical evaluation of the system usability scale. International Journal of Human-Computer Interaction, 24(6), 574–594.
Cheng, C. H., & Chen, Y. S. (2009).
Classifying the segmentation of customer value via RFM model and RS theory. Expert Systems with Applications, 36(3 PART 1), 4176–4184.
Dibb, S. (1998). Market segmentation: Strategies for success. Marketing
Intelligence & Planning, 16(7), 394–406. Haviluddin, B., Fanany, A., & Gafar, O. (2018).
Proceedings of the Eleventh International Conference on Management Science and Engineering Management. Proceedings of the Eleventh International Conference on Management Science and Engineering Management, 2.
Fakultas Ilmu Komputer, Universitas Brawijaya
John Wiley and Sons Inc (Vol. 1). Monalisa, S. (2018). Segmentasi Perilaku
Pembelian Pelanggan Berdasarkan Model RFM dengan Metode K-Means.
5341(April), 9–15.
Purnima, B., & Arvind, K. (2014). EBK-Means: A Clustering Technique based on Elbow Method and K-Means in WSN. International Journal of Computer Applications, 105(9), 17–24.
Ramadhan, R., Djauhari, Z., Kurniawandy, A., Jurusan, M., Sipil, T., Jurusan, D., & Sipil, T. (2015). Analisis perbandingan metode. 2(2), 1–15.
Sausen, K., Tomczak, T., & Herrmann, A. (2005). Development of a taxonomy of strategic market segmentation: A framework for bridging the
implementation gap between normative segmentation and business practice. Journal of Strategic Marketing, 13(3), 151–173.
Shin, H. W., & Sohn, S. Y. (2004).
Segmentation of stock trading customers according to potential value. Expert Systems with Applications, 27(1), 27–33. Shofiani, N. (2017). Segmentasi Supplier
Menggunakan Metode K- Means Clustering ( Studi Kasus : Ptpn X Pg Meritjan ).
Tsiptsis, K., & Chorianopoulos, A. (2010). Data Mining Techniques in CRM: Inside Customer Segmentation. In Data Mining Techniques in CRM: Inside Customer Segmentation.