PENERAPAN ALGORITMA NAÏVE BAYESIAN UNTUK
SELEKSI PEGAWAI
(Studi Kasus Pada PT. Mega Andalan Kalasan Yogyakarta)
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Valentina Dian Indriani NIM : 085314047
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
IMPLEMENTATION OF NAÏVE BAYESIAN ALGORITM FOR
EMPLOYEE SELECTION
(Case Study At PT. Mega Andalan Kalasan Yogyakarta)
A Thesis
Presented as Partial Fullfillment of the Requirements To Obtain the Sarjana Komputer Degree In Study Program of Informatics Engineering
By:
Valentina Dian Indriani NIM : 085314047
INFORMATICS ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
“Berbahagialah orang yang bertahan dalam pencobaan. Sebab apabila ia sudah tahan uji, ia akan menerima mahkota kehidupan yang dijanjikan Allah pada
barang siapa yang percaya kepada-Nya.” (Yakobus 1 : 12)
“Pencobaan-pencobaan yang kamu alami ialah pencobaan- pencobaan biasa, yang tidak melebihi kekuatan manusia. Sebab Allah setia dan karena itu Ia tidak akan membiarkan kamu dicobai melampaui kekuatanmu. Pada waktu kamu dicobai Ia akan memberikan kepadamu jalan keluar, sehingga kamu
dapat menanggungnya.” ( 1 Korintus 10 :
13)
“Mintalah, maka akan diberikan kepadamu; Carilah, maka kamu akan mendapat; Ketoklah, maka pintu akan dibukakan bagimu. Karena setiap orang yang meminta, menerima, dan setiap orang yang mencari, mendapat, dan setiap
orang yang mengetok, baginya pintu dibukakan.” ( Lukas 11 :9-10)
“Kita meminta apa yang kita inginkan, dan Allah memberikan yang paling kita perlukan. Itulah yang diberikan-Nya dengan berlimpah!”
“Jika kesusahan adalah hujan, dan kemudahan adalah mentari, maka kita membutuhkan keduanya untuk melihat indahnya Pelangi”
“Karena itu AKU berkata kepadamu
: Apa saja yang kamu minta dan
doakan, percayalah bahwa kamu
telah menerimanya, maka hal itu
akan diberikannya kepadamu.”
( Markus 11 : 24)
Ku Persembahkan karya kecilku untuk:
Orangtua Tercinta, Adik Tersayang, Dosen, dan Teman-Teman
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian dari karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 27 Mei 2013 Penulis
PENERAPAN ALGORITMA NAÏVE BAYESIAN UNTUK
SELEKSI PEGAWAI
(Studi Kasus PT. Mega Andalan Kalasan Yogyakarta)
ABSTRAK
Dalam lingkup perusahaan sumber daya manusia yaitu pegawai mempunyai peranan yang sangat penting dalam kemajuan suatu perusahaan. Seleksi pegawai mempunyai peran yang strategis, sehingga dapat ditentukan orang yang layak dan berkemampuan untuk diterima dalam perusahaan sesuai dengan penilaian yang sudah dilakukan dalam seleksi penerimaan pegawai.
Dari data kepegawaian tersebut bisa dimanfaatkan untuk diolah menggunakan teknik penambangan data dengan menggunakan algoritma naïve Bayesian. Algoritma
naïve Bayesian akan menghitung probabilitas posterior untuk setiap nilai kejadian
dari atribut target pada setiap kasus (sampel data). Selanjutnya, naïve Bayesian akan mengklasifikasikan sampel data tersebut ke kelas yang mempunyai nilai probabilitas posterior tertinggi.
Keluaran sistem adalah rekomendasi seorang pelamar yang akan lolos ke tahap training calon pegawai. Pengujian dilakukan pada 325 record data menggunakan
5-fold cross-validation dengan tingkat rata-rata akurasi yang dihasilkan dari data
pengujian sebesar 50%.
IMPLEMENTATION OF NAÏVE BAYESIAN ALGORITM FOR
EMPLOYEE SELECTION
(Case Study At PT. Mega Andalan Kalasan Yogyakarta)
ABSTRACT
In the scope of human resource company, employees have an important role in the progress of the company. The employee selection has a strategic role that can determine the individuals who are worthy and capable of being accepted in the company in accordance with the employee selection which has been done.
The employment data can be used to process the data by using data mining tehnic of naive Bayesian algorithm. Naive Bayesian Algorithm will count the posterior probability for each value of event from the target attribute in each case (data sample). After that, naive Bayesian will clarify the data sample to the class which has the highest posterior probability score.
System output is a recommendation that an applicant will qualify for the training phase of the prospective employee. Tests performed on 325 data records using a 5-fold cross-validation with an average accuracy rate resulting from the test data by 50%.
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama : Valentina Dian Indriani NIM : 08 5314 047
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
PENERAPAN ALGORITMA NAÏVE BAYESIAN UNTUK SELEKSI PEGAWAI
(Studi Kasus PT. Mega Andalan Kalasan Yogyakarta)
Dengan demikian saya memberikan kepada Universitas Sanata Dharma hak untuk menyiapkan, mengalihkan dalam bentuk media lain, mengelola dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikan di internet atau media lain untuk kepentingan akademis tanpa perlu meminta izin dari saya maupun memberi royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada Tanggal: 27 Mei 2013 Yang menyatakan,
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa, karena hanya dengan berkat dan karunia-Nya, serta campur tangan-Nya, penulis dapat menyelesaikan skripsi yang berjudul “PENERAPAN ALGORITMA NAÏVE BAYESIAN UNTUK SELEKSI PEGAWAI (Studi Kasus PT. Mega Andalan
Kalasan Yogyakarta)” dengan baik.
Pada kesempatan ini penulis juga ingin mengucapkan rasa terima kasih kepada:
1. Tuhan Yesus Kristus dan Bunda Maria untuk semua berkat yang sangat melimpah yang penulis terima.
2. Bapak Puspaningtyas Sanjoyo Adi S.T., M.T., selaku dosen pembimbing yang sudah meluangkan waktu dan dengan sabar membimbing penulis, sehingga skripsi ini dapat diselesaikan dengan baik.
3. Ibu P. H. Prima Rosa, S.Si., M.Sc. dan Ibu Ridowati Gunawan S.Kom., M.T. selaku dosen penguji.
4. Pihak sekretariat dan laboran Fakultas Sains dan Teknologi yang turut membantu penulis dalam studi dan menyelesaikan tugas akhir ini.
5. Kepada kedua orang tua tercinta, Bapak Petrus Mariyanto dan Ibu Elizabeth Eni Ristiyanti, yang selalu memberikan kasih sayang, semangat, dukungan serta doa yang melimpah kepada penulis.
6. Adik tersayang Yustina Nila Herdiani yang selalu memberikan hiburan, semangat, serta kasih sayang kepada penulis.
7. Sahabat hati tersayang, Leo Sukoto, S.T., terimakasih atas semangat, motivasi, bantuan, dan hiburan yang selalu diberikan kepada penulis. 8. Sahabat dan teman-teman : teman- teman TI tersayang Maria Roswita
V.A, S.Kom, Gadis Pujiningtyas R, S.Kom, Putri Nastiti, S.Kom, Laurina Silvianti D, S.Kom, Christina Rusma A, S.Kom, Petra Valentin W, S.Kom, Aristawati C, S.Kom, Ilana F yang bangun pagi untuk saling menyemangati. Untuk kakak Daditya Nugroho, S.T., Atanasius Tendy, S.Kom, Kevin, S.Kom, Linardi, S.Kom terima kasih unutuk bantuan dan
dukungannya kepada penulis dan seluruh teman-teman TI 2008 terima kasih untuk dukungan dan perjuangannya selama ini.
9. Untuk teman kost „Pak Kuat‟, kost Kartika Dewi, dan teman-teman kost PATRIA yang spartan terima kasih untuk menjadi saudara di jogja. Adik kost tersayang Adven dan Erni terima kasih sudah saling berbagi suka dan duka dengan penulis.
10. Tante Rini Veronica, om Kingkin Teja Angkasa, dek Benedictus Elang P terima kasih karena menjadi saudara di jogja yang memberikan semangat, dukungan, dan doa.
Penulis menyadari bahwa penelitian tugas akhir ini masih memiliki banyak kekurangan. Untuk itu, penulis sangat membutuhkan saran dan kritik untuk perbaikan di masa yang akan datang. Semoga penelitian tugas akhir ini dapat membawa manfaat bagi semua pihak.
Yogyakarta, 27 Mei 2013
DAFTAR ISI
HALAMAN JUDUL... ii
HALAMAN PERSETUJUAN... iii
HALAMAN PENGESAHAN... iv
MOTTO... v
HALAMAN PERSEMBAHAN... vi
PERNYATAAN KEASLIAN KARYA... vii
ABSTRAK... viii
ABSTRACT... ix
LEMBAR PERSETUJUAN PUBLIKASI... x
KATA PENGANTAR... xi
DAFTAR ISI... xiii
DAFTAR TABEL... xv
DAFTAR GAMBAR... xvi
BAB I PENDAHULUAN... 1
1.1 Latar Belakang Masalah... 1
1.2 Perumusan Masalah... 4 1.3 Tujuan... 4 1.4 Batasan Masalah... 4 1.5 Luaran... 5 1.6 Metodologi Penelitian... 5 1.7 Sistematika Penulisan... 6 BAB II LANDASANTEORI... 8 2.1 Penambangan Data... 8
2.1.1 Pengertian Penambangan Data... 11
2.1.2 Pengelompokan Penambangan Data... 13
2.1.3 Klasifikasi... 14
2.2 Teorema Bayesian... 14
2.2.1 Pengertian Teorema Bayesian... 14
2.2.2 Klasifikasi Naive Bayesian... 16
2.3 K-Fold Cross Valodation... 21
BAB III ANALISA DAN PERANCANGAN SISTEM... 23
3.1 Analisis Sistem... 23
3.1.1 Identifikasi Permasalahan... 23
3.1.2 Analisa Kebutuhan Pengguna... 26
3.2 Masukan Sistem... 26
3.4 Arsitektur Sistem... 33
3.5 Perancangan Umum Sistem... 36
3.5.1 Diagram Model Use Case... 36
3.5.2 Narasi Use Case... 36
3.5.3 Diagram Aktivitas... 37
3.5.4 Model Analisis... 37
3.5.5 Diagram Kelas... 38
3.5.6 Perancangan Basis Data... 39
3.6 Model Desain... 43
BAB IV IMPLEMENTASI DAN ANALISI SISTEM... 44
4.1 Tahap Implementasi... 44
4.1.1 Spesifikasi Software dan Hardware... 44
4.2 Implementasi Use Case... 45
4.3 Implementasi Diagram Kelas... 45
4.4 Pengujian Hasil Sistem... 46
4.4.1 Pengujian 5-fold cross validation... 46
4.4.2 Analisis Struktur Algoritma Naive Bayesian... 51
BAB V KESIMPULAN DAN SARAN... 57
5.1 Kesimpulan... 57
5.2 Saran... 58
5.2.1 Untuk Pengembangan Program... 58
DAFTAR PUSTAKA... 59 LAMPIRAN... 60 LAMPIRAN I... 61 LAMPIRAN II... 75 LAMPIRAN III... 82 LAMPIRAN IV... 95 LAMPIRAN V... 111 LAMPIRAN VI... 125
DAFTAR TABEL
Tabel 2.1 Data Mobil Tercuri... 18
Tabel 3.1 Tabel Pelamar... 40
Tabel 3.2 Tabel Calon Pegawai... 41
Tabel 3.3 Tabel Pegawai Tetap... 43
Tabel 4.1 Tabel Hasil Perhitungan Akurasi... 48
Tabel 4.2 Tabel Data Anomali... 50
Tabel 4.3 Tabel nilai likelihood STTB dengan status diterima... 52
Tabel 4.4 Tabel nilai likelihood STTB dengan status tidak diterima... 52
Tabel 4.5 Tabel nilai likelihood test tertulis dengan status diterima... 53
Tabel 4.6 Tabel nilai likelihood test tertulis dengan status tidak diterima... 54
Tabel 4.7 Tabel nilai likelihood test psikologi dengan status diterima... 54
Tabel 4.8 Tabel nilai likelihood test psikologi dengan status tidak diterima.... 55
Tabel 4.9 Tabel nilai likelihood test wawancara dengan status diterima... 55
Tabel 4.10 Tabel nilai likelihood test wawancara status tidak diterima... 56
Tabel 4.11 Tabel nilai likelihood test kesehatan dengan status diterima... 56
DAFTAR GAMBAR
Gambar 2.1 Langkah Penambangan Data... 8
Gambar 3.1 Alur Pengangkatan Pegawai Tetap... 19
Gambar 3.3 Arsitektur Sistem... 29
Gambar 3.4 Arsitektur Aplikasi untuk Admin... 30
Gambar 3.4 Arsitektur Aplikasi untuk Manager... 31
Gambar 3.5 Diagram Model Use Case Sistem... 32
BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Dalam waktu tertentu manusia dihadapkan pada kewajiban mengambil keputusan. Pada umumnya dapat dilihat bahwa tidak semua keputusan yang diambil membawa hasil seperti yang diinginkan. Berhasil atau tidaknya suatu keputusan tergantung dari berbagai faktor. Semakin banyak faktor yang harus dipertimbangkan, maka semakin relatif sulit untuk mengambil keputusan dari suatu permasalahan. Apalagi jika upaya pengambilan keputusan dari suatu permasalahan tertentu, selain mempertimbangkan faktor/kriteria yang beragam, juga melibatkan beberapa orang pengambil keputusan.
Dalam lingkup perusahaan sumber daya manusia dalam hal ini pegawai mempunyai peranan yang sangat penting dalam kemajuan suatu perusahaan. Hanya pegawai berkemampuan dan penempatan pada bagian yang tepat akan membuat tujuan dari perusahaan tercapai. Seleksi pegawai tetap mempunyai peran yang strategis, sehingga dapat ditentukan orang yang layak dan berkemampuan untuk diterima dalam perusahaan sesuai dengan penilaian yang sudah dilakukan dalam seleksi penerimaan pegawai.
PT. Mega Andalan Kalasan (MAK) adalah perusahaan manufaktur yang memproduksi peralatan rumah sakit (hospital equipment). Perusahaan tersebut memiliki pegawai yang cukup banyak dan hampir setiap tahun merekrut pegawai sesuai bidang-bidang yang dibutuhkan. Proses seleksi ditangani oleh Panitia
Rekrutasi Trainee dan semua hasil penilaian diserahkan yang kemudian diproses oleh bagian Human Resource Department (HRD). Beberapa hambatan dalam proses seleksi adalah banyaknya alternatif pegawai serta tahap seleksi manual yang sudah ditentukan. Berikut ini adalah tahap seleksi pegawai tetap PT. Mega Andalan Kalasan :
1. Rekrutmen
Pada tahap ini pelamar mengikuti 5 tahap seleksi yaitu seleksi administrasi, test tertulis, test psikologi, test wawancara teknik dan non teknik, dan test kesehatan.
2. Pelatihan keahlian / training
Pada tahun 2008 jumlah lamaran yang masuk ke Panitia Rekrutasi Trainee sejumlah 2010 lamaran. HRD dan Wakil Direktur berkonsultasi dengan pihak manajemen menyangkut rencana jumlah pegawai yang akan diterima. Arahan penerima training dari manajemen pada tahun 2008 yaitu 100 pegawai. Setiap tahun nya kapasitas pegawai yang diterima berbeda-beda, hal ini menurut strategi bisnis perusahaan. Sebanyak 966 pelamar lolos dalam seleksi Administrasi, dimana penilaian dilihat dari kualifikasi kelengkapan dokumen lamaran. Sebelum memasuki tahap seleksi Psikologi terdapat tahap seleksi internal psikologi, namun seleksi ini hnaya digunakan untuk untuk meminimalkan jumlah peserta test Psikologi. Pada seleksi Internal Psikologi penilaian diambil dari nilai eksak mata pelajaran matematika dan fisika dengan jumlah pelamar yang lolos yaitu 456 pelamar. Dalam seleksi Internal Psikologi ini proses seleksi masih dilakukan secara manual dengan menyeleksi kembali ijasah pelamar misalnya, nilai matematika dan fisika > 7 maka lolos ke tahap seleksi Psikologi.
Pencarian keputusan pegawai yang masih dilakukan secara manual memiliki kelemahan karena membutuhkan waktu yang relatif lama, serta faktor
human error seperti pengolahan, penyajian laporan hasil seleksi, penyimpanan
dan perawatan dokumen berbentuk kertas masih belum dapat ditangani dengan baik. Selain itu pencarian keputusan pegawai juga hanya mempertimbangkan nilai calon pegawai dalam masa training. Data rekrutmen belum dimanfaatkan mempertimbangkan keputusan pengangkatan pegawai tetap.
Dari data kepegawaian tersebut bisa dimanfaatkan untuk diolah menggunakan teknik penambangan data dengan menggunakan algoritma naïve
Bayesian. Naïve Bayesian merupakan salah satu metode penambangan data yang
digunakan pada persoalan klasifikasi. Algoritma naïve Bayesian akan menghitung probabilitas posterior untuk setiap nilai kejadian dari atribut target pada setiap kasus (sampel data). Selanjutnya, naïve Bayesian akan mengklasifikasikan sampel data tersebut ke kelas yang mempunyai nilai probabilitas posterior tertinggi [5].
Dengan perkembangan dan diterapkannya teknologi komputer atau teknologi informatika pengolahan data maupun penyajian informasi secara cepat dan akurat akan sangat membantu untuk meningkatkan kinerja agar lebih efektif dan efisien. Sistem ini diharapkan membantu dalam menentukan pegawai yang terpilih dan berkompeten menjadi pegawai sesuai bidang yang sudah ditentukan.
1.2 Perumusan Masalah
Perumusan masalah yang akan diselesaikan dalam penelitian Tugas Akhir ini sebagai berikut :
1. Bagaimana memilih calon pegawai yang memiliki potensi lolos dalam masa training menggunakan algoritma Naive Bayesian dengan atribut test rekrutmen yaitu nilai STTB, test psikologi, test tertulis, test wawancara, dan test kesehatan ?
1.3 Tujuan
Tujuan dari penelitian Tugas Akhir ini adalah :
1. Menerapkan algoritma Naïve Bayesian sebagai salah satu algoritma dalam penambangan data untuk membantu memberikan rekomendasi dalam seleksi pegawai di PT. Mega Andalan Kalasan.
1.4 Batasan Masalah
Dalam tugas akhir ini batasan masalah yang akan diambil dalam pembahasan adalah sebagai berikut:
1. Obyek yang diteliti adalah data pegawai PT. Mega Andalan kalasan Yogyakarta.
2. Data yang diteliti adalah data pegawai dari jenjang pendidikan Sekolah Menengah Kejuruan (SMK).
3. Data yang digunakan sebagai atribut adalah data pegawai yang sudah melalui seleksi yang ditetapkan oleh PT. Mega Andalan Kalasan berkisar dari tahun 2006-2011. Pemilihan rentang tahun 2006-2011 dikarenakan
rentang tahun ini, masih relevan untuk menggambarkan situasi perekrutan pegawai.
4. Penelitian ini menerapkan algoritma Naïve Bayesian dan dilakukan pengujian tingkat akurasi algoritma dalam memprediksi seleksi pegawai pada PT. Mega Andalan Kalasan.
5. Pengguna sistem adalah Human Resource Department (HRD).
1.5 Luaran
Sebuah hasil prediksi dari algoritma Naïve Bayesian. Hasil prediksi tersebut dapat digunakan Human Resource Department (HRD) sebagai alat bantu dalam seleksi pegawai tetap.
1.6 Metodologi Penelitian
Langkah-langkah yang dilakukan untuk menyelesaikan masalah pada tugas akhir ini adalah :
1. Studi literatur
Penulis melakukan studi pustaka dengan mempelajari teori-teori serta serta referensi yang mendukung penelitian ini terutama yang berhubungan dengan algoritma Naïve Bayesian. Selain itu penulis juga mengumpulkan data mengenai sistem seleksi pegawai untuk mengumpulkan informasi yang digunakan untuk penelitian ini. Dalam penelitian ini penulis melakukan studi kasus di PT. Mega Andalan Kalasan.
Pembuatan sistem dilakukan berdasarkan ide kebutuhan sistem seleksi pegawai. Metode yang dipakai untuk mengembangkan sistem yang dipakai adalah pendekatan algoritma Naïve Bayesian.
3. Implementasi
Mengimplementasikan hasil perancangan sistem seleksi pegawai. 4. Evaluasi sistem
Melakukan pengujian atau evaluasi terhadap system yang telah dibangun. Evaluasi dilakukan dengan menguji sistem berdasar beberapa masukan (inputan).
1.7 Sistematika Penulisan
Adapun sistematika penulisan tugas akhir ini adalah sebagai berikut :
Halaman Judul
Abstrak, berisi tentang rangkuman Tugas Akhir. Daftar Isi
Bab I Pendahuluan
Bab ini berisi tentang pembahasan latar belakang, perumusan masalah, tujuan penelitian, batasan masalah, luaran, kegunaan, metodologi penelitian, serta sistematika penulisan.
Bab II Landasan Teori
Bab ini berisi tentang teori yang dapat menunjang penelitian, berupa pengertian penambangan data, proses penambangan data, klasifikasi, dan algoritma Naïve Bayesian.
Dalam bab ini akan diidentifikasikan masalah yang akan diselesaikan serta tahap-tahap penyelesaian masalah tersebut dengan menggunakan algoritma Naïve Bayesian.
Bab IV Analisa Hasil dan Pembahasan
Bab ini memuat implementasi program dan hasil implementasi dari algoritma yang digunakan, yaitu algoritma Naïve Bayesian serta pembahasan dari program yang telah dibangun.
Bab V Kesimpulan dan Saran
Bab ini berisi kesimpulan dari sistem yang telah dibuat serta saran untuk pengembangan dan penyempurnaan tugas akhir ini.
BAB II
LANDASAN TEORI
2.1. Penambangan Data
2.1.1. Pengertian Penambangan Data
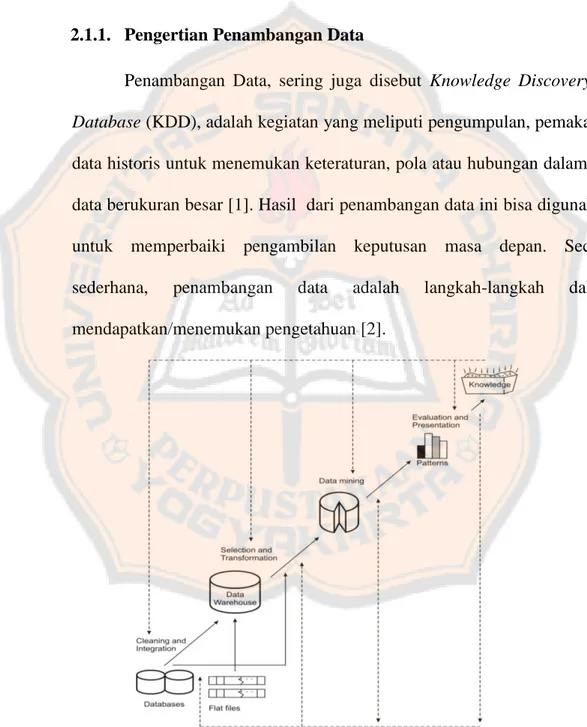
Penambangan Data, sering juga disebut Knowledge Discovery in
Database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian
data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar [1]. Hasil dari penambangan data ini bisa digunakan untuk memperbaiki pengambilan keputusan masa depan. Secara sederhana, penambangan data adalah langkah-langkah dalam mendapatkan/menemukan pengetahuan [2].
Gambar 2.1 Langkah Penambangan Data
Penemuan pengetahuan ini merupakan sebuah proses seperti ditunjukkan pada gambar 2.1 dan terdiri dari urutan-urutan sebagai berikut [2] :
1. Pembersihan data (data cleaning)
Pada langkah ini noice dan data yang tidak konsisten akan dihapus. Langkah pertama yang dilakukan dalam proses pembersihan data (data cleaning atau disebut juga data cleansing) adalah deteksi ketidakcocokan. Ketidakcocokan tersebut dapat disebabkan oleh beberapa faktor antara lain desain form masukan data yang kurang baik sehingga menyebabkan munculnya banyak field, adanya kesalahan petugas ketika memasukkan data, adanya kesalahan yang disengaja dan adanya data yang rusak.
2. Integrasi data (data integration)
Pada langkah ini akan dilakukan penggabungan data. Data dari bermacam-macam tempat penyimpanan data akan digabungkan ke dalam satu tempat penyimpanan data yang koheren. Macam-macam tempat penyimpanan data tersebut termasuk multiple database, data
cube, atau file flat. Pada langkah ini, ada beberapa hal yang perlu
diperhatikan yaitu integrasi skema dan pencocokan objek, redundansi data, deteksi dan resolusi konflik nilai data. Selama melakukan integrasi data, hal yang perlu dipertimbangkan secara khusus adalah masalah struktur data. Struktur data perlu diperhatikan ketika mencocokkan atribut dari satu basis data ke basis data lain.
3. Seleksi data (data selection)
Data yang relevan akan diambil dari basis data untuk dianalisis. Pada langkah ini akan dilakukan analisis korelasi untuk analisi fitur. Atribut-atribut data akan dicek apakah relevan untuk dilakukan penambangan data. Atribut yang tidak relevan ataupun atribut yang mengalami redundansi tidak akan digunakan. Atribut yang diharapkan adalah atribut yang bersifat independen. Artinya, antara atribut satu dengan atribut yang lain tidak saling mempengaruhi. 4. Transformasi data (data transformation)
Data ditransformasikan ke dalam bentuk yang tepat untuk ditambang. Yang termasuk dalam langkah transformasi data adalah penghalusan (smooting) yaitu menghilangkan noise yang ada pada data, pengumpulan (aggregation) yaitu mengaplikasikan kesimpulan pada data, generalisasi (generalization) yaitu mengganti data primitif/data level rendah menjadi data level tinggi), normalisasi
(normalization) yaitu mengemas data atribut ke dalam skala yang
kecil, sebagai contoh -1.0 sampai 1.0, dan konstruksi atribut/fitur
(attribute construction/feature construction) yaitu mengkonstruksi
dan menambahkan atribut baru untuk membantu proses penambangan.
5. Penambangan data (data mining)
Langkah ini adalah langkah yang penting di mana akan diaplikasikan metode yang tepat untuk mengekstrak pola data.
Langkah ini berguna untuk mengidentifikasi pola yang benar dan menarik. Pola tersebut akan direpresentasikan dalam bentuk pengetahuan berdasarkan beberapa pengukuran yang penting.
7. Presentasi pengetahuan (knowledge presentation)
Pada langkah ini informasi yang sudah ditambang akan divisualisasikan dan direpresentasikan kepada pengguna. Langkah 1 sampai dengan langkah 4 merupakan langkah praproses data di mana data akan disiapkan terlebih dahulu selanjutnya dilakukan penambangan.
Pada langkah penambangan data, pengguna atau basis pengetahuan bisa dilibatkan. Kemudian pola yang menarik akan direpresentasikan kepada pengguna dan akan disimpan sebagai pengetahuan yang baru.
2.1.2. Pengelompokan Penambangan Data
Penambangan data dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose,2005):
a. Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup professional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
b. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali atribut target lebih kearah numerik daripada kearah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari atribut target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi niali dari atribut target dibuat berdasarkan atribut prediksi.
c. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil aka nada di masa mendatang.
d. Klasifikasi
Dalam klasifikasi, terdapat target atribut kategori. Sebagai contoh, menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
e. Pengklusteran
Pengklusteran merupakan pengelompokkan record¸pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain.
Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya atribut target dalam pengklusteran.Algoritma ini mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogeny), yang mana kemiripan record
dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
f. Asosiasi
Tugas asosiasi dalam penambangan data adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut market basket analisis.
2.1.3. Klasifikasi
Klasifikasi merupakan model atau classfier yang dikonstruksikan untuk memprediksi kategori label (categorical labels). Misalnya : aman atau berbahaya untuk sebuah data aplikasi, ya dan tidak untuk data penjualan. Klasifikasi dan prediksi numerik adalah dua tipe utama dari masalah-masalah prediksi (prediction problems) [2]. Cara klasifikasi bekerja, di mana klasifikasi data (data classification) terdiri dari dua langkah proses, yaitu :
1. Langkah pertama, penggolong (classifier) mendiskripsikan
pembangunan himpunan dari kelas-kelas data atau konsep-konsep yang telah ditetapkan. Bagian ini merupakan langkah pembelajaran atau fase pelatihan (learning step atau training phase), di mana algoritma klasifikasi yang dibangun digolongkan melalui menganalisa atau dari mana pembelajaran itu berasal “ learning from”, sebuah training set akan dibuat dari database tuples dan label-label kelas yang berhubungan satu dan lainnya. Sebuah tuple, X, dinyatakan sebagai sebuah
n-dimensional attribute vector, di mana X = (x1, x2,…,xn),
menggambarkan ukuran n tuple dari n atribut-atribut basisdata, A1,A2, …., An. Setiap tuple , X, diasumsikan termasuk dalam
kelas predefined yang ditentukan oleh atribut basis data lainnya yang disebut class label attribute. Karena label kelas dari setiap tuple pelatihan sudah tersedia maka fase ini juga dikenal dengan sebutan fase supervised learning.
2. Langkah kedua, mengenai akurasi dari klasifikasi. Model
langsung akan langsung digunakan untuk diklasifikasi. Pertama, akan ditaksir seberapa akurat prediksi yang dibuat oleh classifier. Jika kekuatan classifier diukur dengan menggunakan data pelatihan, maka taksiran ini akan baik karena classifier cenderung overfit data. Maka dari itu, perlu digunakan sekumpulan data uji. Data tersebut dipilih secara acak dari sekumpulan data umum. Data yang diuji ini bersifat independen/ berdiri sendiri dari data pelatihan, artinya data yang diuji tersebut tidak lagi digunakan untuk membuat classifier.
2.2. Teorema Bayesian
2.2.1 Pengertian Teorema Bayesian
Teori keputusan Bayes atau sering disebut Teorema bayes adalah pendekatan statistic yang fundamental dalam pengenalan pola (pattern
recognition) [1]. Pendekatan Teorema Bayes ini didasarkan pada
menggunakan probabilitas dan nilai yang muncul dalam keputusan-keputusan tersebut.
Jika X adalah bukti atau kumpulan data pelatihan dan 𝑌 adalah hipotesis. Jika class variable memiliki hubungan tidak deterministic dengan atribut, maka dapat diperlukan X dan 𝑌 sebagai atribut acak dan menangkap hubungan peluang menggunakan 𝑃 𝑌 𝑋 . Peluang bersyarat ini juga dikenal dengan probabilitas posterior untuk 𝑌, dan 𝑃(𝑌) adalah probabilitas prior. Untuk mengestimasi peluang posterior secara akurat untuk setiap kombinasi label kelas yang mungkin dan nilai atribut adalah masalah sulit karena membutuhkan training set sangat besar, meski untuk jumlah moderate atribut. Penggunaan teorema Bayes untuk melakukan klasifikasi sangat bermanfaat karena menyediakan pernyataan istilah peluang posterior dari peluang prior 𝑃(𝑌), peluang kelas bersyarat 𝑃 𝑋 𝑌 dan bukti 𝑃(𝑋) seperti pada Rumus 2.1 berikut [3] :
( Rumus 2.1)
Dalam hal ini :
X = himpunan data training Y = hipotesis.
𝑃 (𝑌|𝑋) = probabilitas posterior, yaitu probabilitas bersyarat dari hipotesis Y berdasarkan kondisi X.
𝑃(𝑌) = probabilitas prior dari hipotesis Y, yaitu probabilitas bahwa hipotesis Y bernilai benar sebelum data X muncul.
𝑃 (𝑋|𝑌) = probabilitas bersyarat dari X berdasarkan kondisi pada hipotesis Y, dan biasa disebut dengan likelihood. Likelihood ini mudah untuk dihitung ketika memberikan nilai 1 saat X dan Y konsisten, dan memberikan nilai 0 saat X dan Y tidak konsisten.
2.2.2 Klasifikasi Naïve Bayesian
Klasifikasi Naïve Bayesian merupakan salah satu metode pengklasifikasi yang berdasarkan pada penerapan Teorema Bayes dengan asumsi antar atribut penjelas saling bebas (independen). Algoritma ini memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman dimasa sebelumnya.
Klasifikasi Naïve Bayes diasumsikan dimana nilai atribut dari sebuah kelas dianggap terpisah dan independen dengan nilai atribut lainnya. [3]:
( Rumus 2.2 ) Keterangan :
X = himpunan data training Y = hipotesis.
𝑃(𝑌|𝑋) = probabilitas posterior, yaitu probabilitas bersyarat dari hipotesis Y berdasarkan kondisi X.
𝑃(𝑌) = probabilitas prior dari hipotesis Y, yaitu probabilitas bahwa hipotesis Y bernilai benar sebelum data X muncul.
𝑃(𝑋1|𝑌) , 𝑃(𝑋2|𝑌) , 𝑃(𝑋𝑛|𝑌) = probabilitas dari X1, X2, Xn untuk hipotesis Y, biasa disebut dengan likelihood.
Karena P(X) irrelevant maka untuk mencari peluang hanya menggunakan rumus berikut ini :
( Rumus 2.3 )
Jika ada P(Xn|Y) yang memiliki nilai 0, maka P(Y|X) = 0. Maka klasifikasi Naïve Bayesian tidak bisa memprediksi record yang salah satu atributnya memiliki probabilitas bersyarat (likelihood) = 0. Untuk mengatasi hal itu maka dilakukan penambahan nilai 1 ke setiap evidence dalam perhitungan sehingga probabilitas tidak akan bernilai 0. Langkah ini sering disebut Laplace Estimator dengan rumus sebagai berikut [1] :
( Rumus 2.4 ) Dimana :
𝑛 = total jumlah instances dari kelas 𝑌𝑗
𝑛𝑐 = jumlah contoh training dari 𝑌𝑗 yang menerima nilai 𝑋𝑖 𝑚 = parameter yang dikenal sebagai ukuran sampel ekivalen
Pada tabel 2.1 adalah contoh kasus yang akan diselesaikan dengan algoritma naïve bayes.
Tabel 2.1 Data Mobil Tercuri
Warna Tipe Asal Kelas : Tercuri ?
Merah Sport Domestik Tidak Merah Sport Domestik Tidak Merah Sport Domestik Tidak Kuning Sport Domestik Tidak
Kuning Sport Import Ya
Kuning SUV Import Ya
Kuning SUV Import Ya
Kuning SUV Domestik Tidak
Merah SUV Import Ya
Merah Sport Import Ya
Tabel 2.1 memperlihatkan data training dengan atribut : warna, tipe, asal. Sedangkan atribut label kelas adalah tercuri. Berikut ini adalah penyelesaian contoh kasus mengguakan algoritma naïve bayes :
Terdapat dua class dari klasifikasi yang dibentuk, yaitu : 𝑦1 = tercuri= “ya”
𝑦2 = tercuri = “tidak”
Data yang akan diklasifikasikan adalah 𝑥=(warna=merah, tipe=SUV,
Penyelesaian :
𝑃(𝑦𝑖) merupakan probabilitas prior (untuk setiap class) yang dapat dihitung berdasarkan data training pada Tabel 2.1.
P(tercuri = ya) = 5/10 = 0.5 P(tercuri = tidak) = 5/10 = 0.5
Untuk menghitung
𝑃 𝑥 𝑦
𝑖,
untuk i=1,2 akan dihitung probabilitas bersyarat (likelihood) sebagai berikut :Likelihood atribut warna :
P(warna=merah | tercuri = ya) = 2/5 = 0.4 P(warna=merah | tercuri = tidak) = 3/5 = 0.6 P(warna=kuning | tercuri = ya) = 3/5 = 0.6 P(warna=kuning | tercuri = tidak) = 2/5 = 0.4
Likelihood atribut tipe :
P(tipe=SUV | tercuri = ya) = 3/5 = 0.6 P(tipe=SUV | tercuri = tidak) = 1/5 = 0.2 P(tipe=sport | tercuri = ya) = 2/5 = 0.4 P(tipe=sport | tercuri = tidak) = 4/5 = 0.8
Likelihood atribut asal :
P(asal=domestik | tercuri = ya) = 0/5 = 0 P(asal=domestik | tercuri = tidak) = 5/5 = 1 P(asal=import | tercuri = ya) = 5/5 = 1 P(asal=import | tercuri = tidak) = 0/5 = 0
Laplace Estimator
Bila ditemukan salah satu atribut yang memiliki probabilitas bersyarat (likelihood)=0, maka dilakukan penambahan nilai satu ke setiap evidence sehingga tidak ada probabilitas yang akan bernilai 0. Berikut ialah nilai
likelihood untuk atribut asal setelah dilakukan laplace estimator. Likelihood atribut asal :
P(asal=domestik | tercuri = ya) = 1/7 = 0.14 P(asal=domestik | tercuri = tidak) = 6/7 = 0.86 P(asal=import | tercuri = ya) = 6/7 = 0.86 P(asal=import | tercuri = tidak) = 1/7 = 0.14
Dari probabilitas-probabilitas tersebut, maka diperoleh
P(𝑋|tercuri=ya) = P(warna=merah | tercuri = ya) x P(tipe=SUV | tercuri
= ya) x P(asal=domestik | tercuri = ya)
= 0.4 x 0.6 x 0.14 = 0.0336
P(𝑋|tercuri=tidak) = P(warna=merah | tercuri = tidak) x P(tipe=SUV |
tercuri = tidak) x P(asal=domestik | tercuri = tidak)
= 0.6 x 0.2 x 0.86 = 0.1032
Untuk menemukan kelas 𝑃(𝑦𝑖), maksimalkan 𝑃 𝑥 𝑦𝑖 𝑃(𝑦𝑖) dengan menghitung P(𝑋|tercuri=ya)P(tercuri=ya) = 0.0336 x 0.5 = 0.0168
P(𝑋| tercuri=tidak) P(tercuri=tidak) = 0.1032 x 0.5 = 0.0516
Persentasi prediksi untuk tercuri =”ya” adalah : 0. 0168/(0. 0168+0. 0516) x 100% = 24.6%
Persentasi prediksi untuk tercuri =“tidak” adalah : 0. 0516/(0. 0168+0. 0516) x 100% = 75.4%
Kesimpulan :
Jika mobil warna=merah, tipe=SUV, asal=domestik maka klasifikasi
naïve bayes memprediksi “tidak tercuri”, dengan presentase 75,4%.
3. K-Fold Cross Validation
Cross Validation adalah salah satu metode yang bisa digunakan untuk
mengukur kinerja dari sebuah model prediktif. Dalam k-fold Cross Validation, data akan dipartisi secara acak ke dalam k partisi, D1, D2, …Dk, masing-masing D mempunyai jumlah yang sama. Pada iterasi ke – i partisi Di digunakan sebagai data uji, sedangkan sisa partisi digunakan sebagai data pelatihan. Maka dari itu pada iterasi pertama, D1 digunakan sebagai data uji dan D2, D3, ….Dk digunakan sebagai data pelatihan. Pada iterasi kedua, D2 digunakan sebagai data uji, sedangakan D1, D3, ….Dk digunakan sebagai data pelatihan. Pada iterasi ketiga, D3 digunakan sebagai data uji, sedangkan D1, D2, …Dk digunakan sebagai data pelatihan dan seterusnya. Setiap sample D, hanya digunakan sekali sebagai data
uji dan berkali-kali sebagai data pelatihan. Untuk pengklasifikasian, pengukuran keakurasian dapat dihitung dengan rumus sebagai berikut :
BAB III
ANALISA DAN PERANCANGAN SISTEM
3.1. Analisis Sistem
3.1.1. Identifikasi Permasalahan
Dalam proses rekrutmen pelamar mengikuti 5 rangkaian test, yaitu test administrasi, test tertulis, test psikologi, test wawancara, dan yang terakhir test kesehatan. Proses rekrutmen ditangani oleh Panitia Rekrutasi Trainee dan semua hasil penilaian diserahkan yang kemudian diproses oleh bagian HRD. Pelamar yang lolos dalam rekrutmen menjadi calon pegawai dan diterima di Unit Training Center PT.Mega Andalan Kalasan untuk menempuh pelatihan dan pendidikan sebelum resmi di angkat sebagai pegawai tetap. Dibawah ini adalah alur yang dilakukan HRD untuk dari pelamar sampai menjadi pegawai tetap.
Gambar 3.1 Alur Pengangkatan Pegawai Tetap
Seleksi dan pengambilan keputusan penerimaan pegawai baru di PT. Mega Andalan Kalasan masih dilakukan secara manual, belum menggunakan sistem yang terkomputerisasi dengan baik untuk membatu seleksi penerimaan pegawai baru. Langkah-langkah yang dilakukan dalam proses seleksi sebagai berikut :
1. Panitia Rekrutasi Trainee menerima semua berkas lamaran yang masuk, kemudian di seleksi dalam seleksi administrasi.
2. Apabila jumlah pelamar yang memenuhi standar dalam jumlah yang banyak maka panitia akan menerapkan seleksi internal psikologi. Seleksi internal psikologi adalah langkah alternatif sebelum dilakukan test psikologi. Panitia menyeleksi secara manual ijasah pelamar dengan menyeleksi nilai eksak mata pelajaran matematika dan fisika.
3. Panitia Rekrutasi Trainee membuat surat panggilan test psikologi kepada pelamar.
4. Karena PT. Mega Andalan Kalasan tidak memiliki panitia dan fasilitas untuk test psikologi, maka test dilaksanakan oleh Lembaga Psikologi. Kemudian hasil test diserahkan kembali ke Panitia Rekrutasi Trainee.
5. Panitia Rekrutasi Trainee kembali membuat surat panggilan test kesehatan kepada pelamar.
6. Dalam Test Kesehatan PT. Mega Andalan Kalasan menggunakan jasa Balai Hiperkes dan KK DISNAKERTRANS Propinsi DI.Yoykakarta. Test kesehatan meliputi : test mata, jantung, paru-paru, darah urine, dan cek kesehatan secara umum.
7. Panitia Rekrutasi Trainee kembali membuat surat panggilan test wawancara kepada pelamar yang lolos test kesehatan.
8. Test wawancara teknik dan non teknik dilakukan oleh pihak HRD dengan skor penilaian antara 0-100. Diterima atau tidaknya pelamar sesuai ranking penilaian akhir.
9. Pengumuman akhir perekrutan pegawai
10. Penyerahan pegawai baru ke Unit Training Center.
11. Laporan akhir hasil rekrutmen dan seleksi.
Dalam Tugas Akhir ini data rekrutmen pegawai akan diteliti apakah hasil rekrutmen mempengaruhi hasil akhir seleksi pegawai. Keberhasil training calon pegawai dapat direpresentasikan dengan berbagai aspek penilaian dan indeks prestasi kumulatif. Data kepegawaian tersebut bisa dimanfaatkan untuk diolah menggunakan teknik penambangan data dengan menggunakan algoritma Naïve Bayesian.
Data yang digunakan untuk penelitian ini adalah data hasil rekrutmen dan data hasil training pegawai PT. Mega Andalan Kalasan yang di dapat dari Human Resource Department (HRD). Data diberikan dalam format ekstensi xls yang terdiri dari tahun 2000, 2002, 2003, 2006, 2008, dan 2010. Data pegawai tersebut terdiri dari atribut nomor, nama, tempat lahir, tanggal lahir, alamat, agama, nama sekolah, jurusan, nilai STTB, hasil rekomendasi psikotest, hasil test tertulis, hasil test wawancara, hasil test kesehatan, ipk training, dan nilai Evaluasi Kinerja Karyawan (EKK).
3.1.2. Analisis Kebutuhan Pengguna
Manager dan Administrator adalah pelaku (user) dalam sistem ini. Selama menjalani proses taining calon pegawai mendapatkan pelatihan dan penilaian. Manager adalah user yang memiliki wewenang dalam memberikan keputusan seorang pelamar diterima atau tidak. Manager juga memiliki wewenang dalam memberikan penilaian bagi calon pegawai, serta memutuskan calon pegawai diangkat menjadi pegawai tetap atau tidak. Manager juga memiliki wewenang untuk mengakses sistem, serta dapat melakukan seleksi calon pegawai dan seleksi pegawai tetap. Sedangkan administrator memiliki wewenang untuk melakukan kegiatan menambah, mengubah, menampilkan data calon pegawai dan pegawai tetap.
3.2. Masukan Sistem
Pada bagian ini, data yang menjadi masukkan sistem dibagi menjadi 2 bagian yaitu : data pelatihan dan data uji. Pada data pelatihan terdapat 5 variabel, meliputi: nilai sttb, test psikologi, test tertulis, test wawancara, dan test kesehatan. Sedangkan data uji, semua variabel tetap digunakan hanya variabel hasil sistem (Diterima/Tidak Diterima) tidak dimasukkan.
3.3. Proses Sistem
Proses sistem menggunakan algoritma Naive Bayesian sebagai berikut:
a.) Dalam sistem ini kelas-kelas yang muncul dari atribut target. X1 untuk kelas dengan status penerimaan = Diterima, dan X2 untuk kelas dengan status penerimaan = Tidak Diterima.
b.) Menghitung nilai Probabilitas Prior untuk masing-masing kelas X1 dan X2 yaitu sebagai berikut :
P(X1 = Diterima) =
P(X2 = Tidak Diterima) =
c.) Menghitung Probabilitas Bersyarat atau yang disebut Likelihood untuk setiap kelas X1 dan X2 sesuai dengan atribut :
d.) Melakukan proses prediksi dengan menghitung Probabilitas Posterior dari data yang akan diprediksi. Misalnya dari model data dibawah ini akan diprediksi dengan menggunakan algoritma Naive Bayesian dengan menghitung nilai probabilitas posterior sebagai berikut:
nilai_sttb test_psikologi test_tertulis test_wawancara test_kesehatan
8.5 Masih
Disarankan
75 3.8 A
Probabilitas posterior status penerimaan = Diterima : P (status_penerimaan=diterima | K)
= (K|status_penerimaan=diterima) . (status_penerimaan=diterima)
={P(nilai_sttb=8.5|status_penerimaan=diterima).P(test_psikologi=masihdi sarankan | status_penerimaan = diterima) . P(test_tertulis = 75 | status_penerimaan = diterima) . P(test_wawancara =3.8 | status_penerimaan = diterima) . P(test_kesehatan =A | status_penerimaan = diterima) }. P(Status = diterima)
Probabilitas posterior status penerimaan = Tidak Diterima : P (status_penerimaan=tidak diterima | K)
= (K|status_penerimaan= tidak diterima) . (status_penerimaan= tidak diterima)
={P(nilai_sttb=8.5|status_penerimaan= tidak diterima) . P(test_psikologi= masihdisarankan | status_penerimaan = tidakditerima) . P(test_tertulis=75 | status_penerimaan = tidak diterima) . P(test_wawancara = 3.8 |
status_penerimaan = tidak diterima) . P(test_kesehatan = A | status_penerimaan = tidak diterima) }. P (Status = tidak diterima)
e.) Setelah probabilitas posterior sudah didapatkan, nilai probabilitas akan dibandingkan dan nilai yang paling besar diambil unutuk menjadi nilai hasil prediksi.
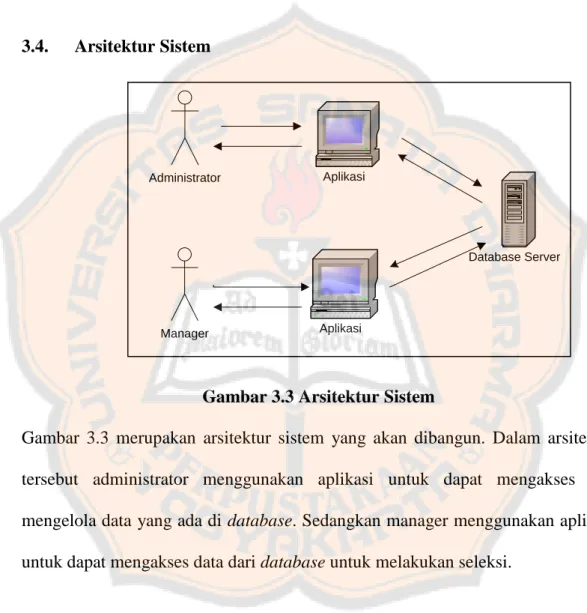
3.4. Arsitektur Sistem
Gambar 3.3 Arsitektur Sistem
Gambar 3.3 merupakan arsitektur sistem yang akan dibangun. Dalam arsitektur tersebut administrator menggunakan aplikasi untuk dapat mengakses dan mengelola data yang ada di database. Sedangkan manager menggunakan aplikasi untuk dapat mengakses data dari database untuk melakukan seleksi.
Administrator Aplikasi
Database Server
Gambar 3.4 Arsitektur Aplikasi untuk Admin
Gambar 3.4 merupakan arsitektur aplikasi untuk Administrator yang akan dibangun. Dalam Arsitektur tersebut administrator akan memasukan data pelamar berupa ID pelamar, nama, tempat lahir, tanggal lahir, alamat, agama, nama pendidikan, jurusan, nilai test , tanggal rekrutmen. Sedangkan untuk data calon pegawai yaitu nilai training dan evaluasi kinerja pegawai. Saat ada perubahan yang dilakukan oleh administrator maka data yang baru akan disimpan di
database.
Perubahan Database Kepegawaian User
Data kepegawaian telah berubah
Input data pelamar (ID pelamar, nama, tempat lahir, tanggal lahir, alamat, agama, nama pendidikan, jurusan, nilai test , tanggal rekrutmen, nilai training, evaluasi kinerja
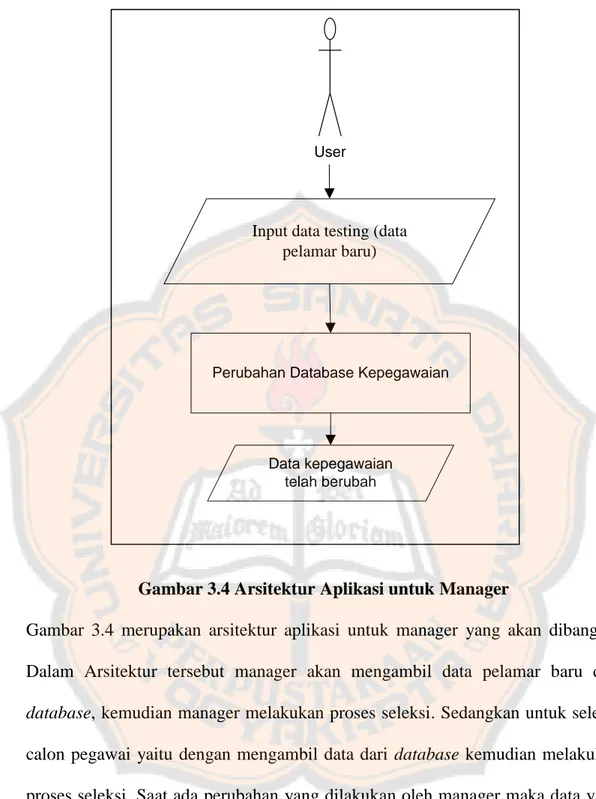
Gambar 3.4 Arsitektur Aplikasi untuk Manager
Gambar 3.4 merupakan arsitektur aplikasi untuk manager yang akan dibangun. Dalam Arsitektur tersebut manager akan mengambil data pelamar baru dari
database, kemudian manager melakukan proses seleksi. Sedangkan untuk seleksi
calon pegawai yaitu dengan mengambil data dari database kemudian melakukan proses seleksi. Saat ada perubahan yang dilakukan oleh manager maka data yang baru akan disimpan di database.
Perubahan Database Kepegawaian User
Data kepegawaian telah berubah
Input data testing (data pelamar baru)
3.5. Perancangan Umum Sistem
Pada subbab ini akan dijelaskan gambaran umum dari sistem yang akan dibangun berupa diagram use case, narasi use case, diagram aktivitas, model analisis, diagram kelas, dan desain basis data.
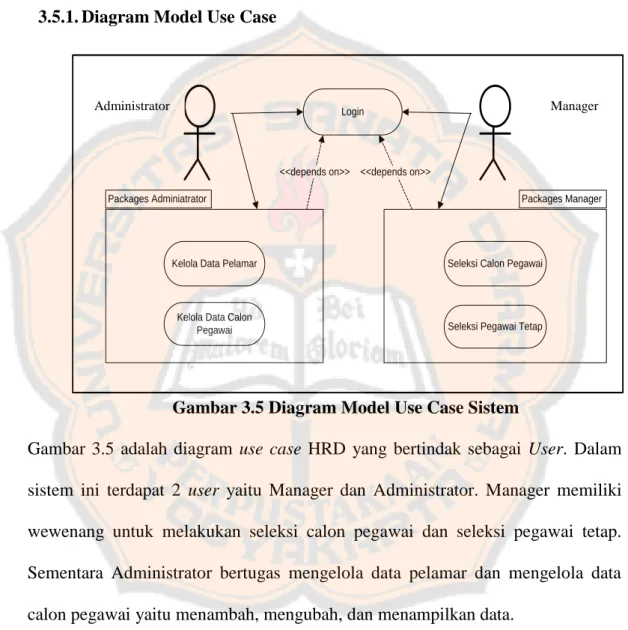
3.5.1. Diagram Model Use Case
Login
Seleksi Calon Pegawai
Seleksi Pegawai Tetap Kelola Data Pelamar
Kelola Data Calon Pegawai
<<depends on>> <<depends on>>
Packages Adminiatrator Packages Manager
Gambar 3.5 Diagram Model Use Case Sistem
Gambar 3.5 adalah diagram use case HRD yang bertindak sebagai User. Dalam sistem ini terdapat 2 user yaitu Manager dan Administrator. Manager memiliki wewenang untuk melakukan seleksi calon pegawai dan seleksi pegawai tetap. Sementara Administrator bertugas mengelola data pelamar dan mengelola data calon pegawai yaitu menambah, mengubah, dan menampilkan data.
3.5.2. Narasi Use Case
Aktivitas usecase akan di deskripsikan secara tertulis dalam narasi usecase. Skenario dari diagram usecase pada Gambar 3.4 terdapat pada lampiran I pada halaman 61.
3.5.3. Diagram Aktivitas
Diagram Aktivitas merupakan diagram yang menjelaskan aktivitas user dengan sistem. Secara lebih terperinci tahap diagram aktivitas dapat dilihat di lampiran II pada halaman 75.
3.5.4. Model Analisis
Diagram Aktivitas merupakan diagram yang menjelaskan aktivitas user dengan sistem. Secara lebih terperinci tahap diagram aktivitas dapat dilihat di lampiran III pada halaman 82.
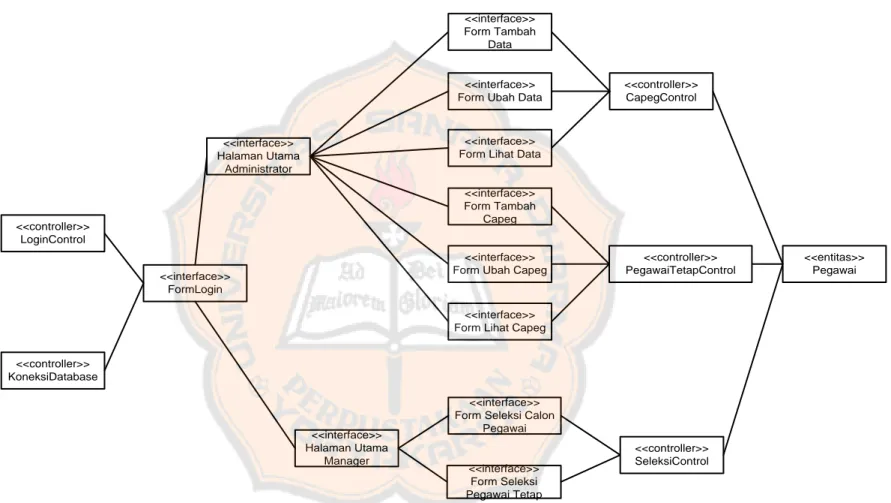
3.5.5. Diagram Kelas <<controller>> LoginControl <<controller>> KoneksiDatabase <<interface>> Form Ubah Capeg
<<interface>> Form Tambah Capeg <<interface>> Form Seleksi Pegawai Tetap <<interface>> Form Seleksi Calon
Pegawai <<interface>> Form Lihat Data
<<interface>> Form Ubah Data
<<interface>> Form Tambah Data <<interface>> Halaman Utama Manager <<interface>> Halaman Utama Administrator <<interface>> FormLogin <<interface>> Form Lihat Capeg
<<controller>> CapegControl <<controller>> PegawaiTetapControl <<controller>> SeleksiControl <<entitas>> Pegawai
3.5.6. Perancangan Basis Data
Berikut ini adalah desain konseptual dan desain basis data fisikal yang terbentuk dalam sistem.
a.) Desain Konseptual
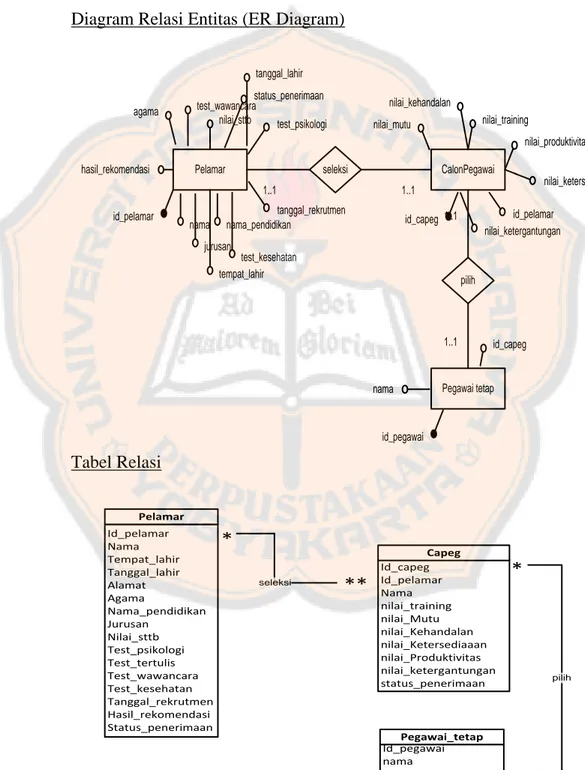
Diagram Relasi Entitas (ER Diagram)
Pelamar id_pelamar nama jurusan nama_pendidikan nilai_sttb tanggal_rekrutmen CalonPegawai test_wawancara hasil_rekomendasi test_kesehatan test_psikologi agama id_capeg id_pelamar nilai_kehandalan Pegawai tetap nilai_training id_capeg id_pegawai status_penerimaan nilai_mutu 1..1 1..1 seleksi 1..1 1..1 pilih nilai_produktivitas nilai_ketersediaan nilai_ketergantungan tempat_lahir tanggal_lahir nama Tabel Relasi Pegawai_tetap Id_pegawai nama Id_capeg Id_capeg Id_pelamar Nama nilai_training nilai_Mutu nilai_Kehandalan nilai_Ketersediaaan nilai_Produktivitas nilai_ketergantungan status_penerimaan Capeg ** * Id_pelamar Nama Tempat_lahir Tanggal_lahir Alamat Agama Nama_pendidikan Jurusan Nilai_sttb Test_psikologi Test_tertulis Test_wawancara Test_kesehatan Tanggal_rekrutmen Hasil_rekomendasi Status_penerimaan Pelamar ** seleksi * pilih
b.) Desain Basis Data Fisikal Tabel Pelamar
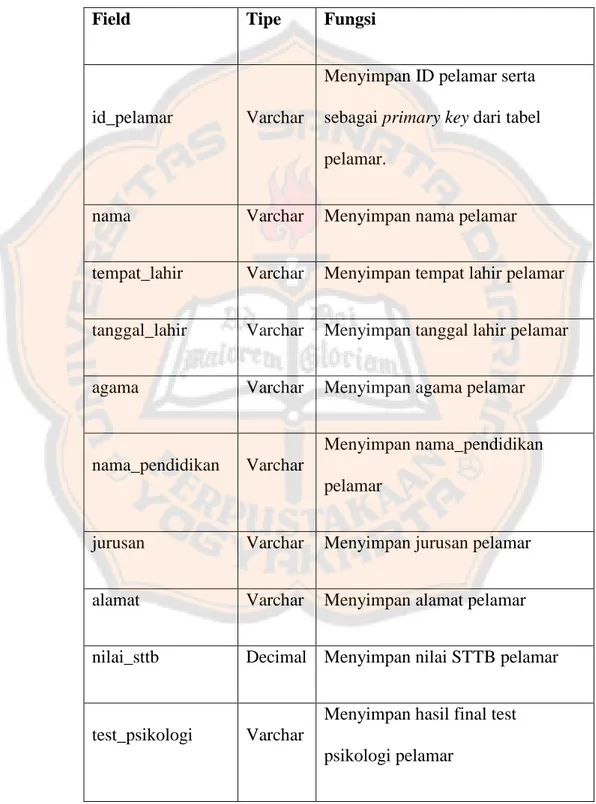
Tabel Pelamar digunakan untuk menyimpan semua informasi pelamar.
Tabel 3.1 Tabel Pelamar
Field Tipe Fungsi
id_pelamar Varchar
Menyimpan ID pelamar serta sebagai primary key dari tabel pelamar.
nama Varchar Menyimpan nama pelamar
tempat_lahir Varchar Menyimpan tempat lahir pelamar
tanggal_lahir Varchar Menyimpan tanggal lahir pelamar
agama Varchar Menyimpan agama pelamar
nama_pendidikan Varchar
Menyimpan nama_pendidikan pelamar
jurusan Varchar Menyimpan jurusan pelamar
alamat Varchar Menyimpan alamat pelamar
nilai_sttb Decimal Menyimpan nilai STTB pelamar
test_psikologi Varchar
Menyimpan hasil final test psikologi pelamar
test_tertulis Int
Menyimpan hasil final test tertulis pelamar
test_wawancara Decimal
Menyimpan hasil final test wawancara pelamar
test_kesehatan Varchar
Menyimpan hasil final test kesehatan pelamar
tanggal_rekrutmen Date
Menyimpan tanggal
diselenggarakannya rekrutmen
hasil_rekomendasi Int
Menyimpan hasil prediksi dari klasifikasi Naive Bayesian
status_penerimaan Int
Menyimpan status penerimaan calon pegawai
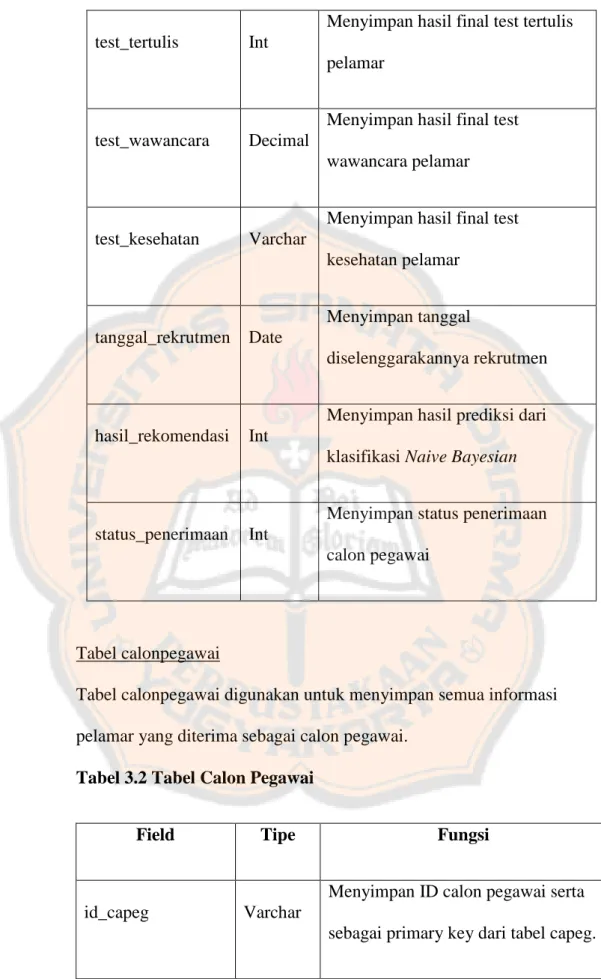
Tabel calonpegawai
Tabel calonpegawai digunakan untuk menyimpan semua informasi pelamar yang diterima sebagai calon pegawai.
Tabel 3.2 Tabel Calon Pegawai
Field Tipe Fungsi
id_capeg Varchar
Menyimpan ID calon pegawai serta sebagai primary key dari tabel capeg.
nilai_training Decimal
Menyimpan nilai akhir calon pegawai melakukan training
mutu Int
Menyimpan nilai mutu dalam evaluasi kinerja calon pegawai
kehandalan Int
Menyimpan nilai kehandalam dalam evaluasi kinerja calon pegawai
ketersediaan Int
Menyimpan nilai ketersediaan dalam evaluasi kinerja calon pegawai
produktivitas Int
Menyimpan nilai produktivitas dalam evaluasi kinerja calon pegawai
ketergantungan Int
Menyimpan nilai ketergantungan dalam evaluasi kinerja calon pegawai
status_penerimaan Varchar
Menyimpan status calon pegawai apakah diterima menjadi pegawai tetap atau tidak.
Tabel Pegawai Tetap
Tabel Pegawai Tetap digunakan untuk menyimpan semua informasi calon pegawai yang diterima menjadi pegawai tetap.
Tabel 3.3 Tabel Pegawai Tetap
Field Tipe Fungsi
id_pegawai Varchar
Menyimpan ID pegawai tetap serta sebagai
primary key dari tabel pegawai tetap.
Nama Varchar Menyimpan nama pegawai tetap
3.6. Model Desain
Pada model desain akan ditampilkan perancangan dari tiap use case yang akan diimplementasikan. Perancangan antarmuka pengguna secara lebih lengkap akan dijelaskan di lampiran IV halaman 95.
BAB IV
IMPLEMENTASI DAN ANALISIS SISTEM
Pada bab ini berisi tentang implementasi dan analisis sistem. Implementasi sistem berdasarkan pada analisis dan perancangan sistem pada bab sebelumnya untuk memprediksi nilai rekrutmen calon pegawai. Implementasi yang dijelaskan berupa implementasi software dan hardware yang digunakan dalam implementasi sistem, implementasi file, serta implementasi use case yang terbentuk dari pembuatan sistem.
4.1. Tahap Implementasi
4.1.1. Spesifikasi Software dan Hardware
Spesifikasi software yang digunakan dalam implementasi sistem ini adalah:
Bahasa pemrograman : Java Netbeans IDE 6.8
DBMS : SQLyog814Enterprise
Spesifikasi hardware yang digunakan dalam implementasi sistem ini adalah :
Processor : Intel corei3 2.53 GHz
Memori : 2 GB
4.2. Implementasi Use Case
Use case yang telah dirancang pada Bab III, telah diimplementasikan ke
dalam sebuah tampilan antarmuka. Antarmuka atau biasa dikenal dengan GUI (Graphical User Interface) merupakan tampilan yang langsung berinteraksi dengan pengguna (user). Antar muka dari program yang telah dibangun dapat dilihat di lampiran V pada halaman 111.
4.3. Implementasi Diagram Kelas
Pada bab III sebelumnya sudah dibuat rancangan untuk kelas-kelas yang nantinya akan digunakan oleh sistem. Berikut ini adalah bentuk implementasi dari desain kelas menjadi implementasi file yang digunakan sistem yang telah dibuat :
Use Case Kelas Desain Implementasi Jenis
Login Login LoginJFrame.java Interface
Login LoginControl.java Controller
koneksiDatabase koneksiDatabase.java Controller
Account Account.java Entity
Kelola Data Pelamar
TambahDataPelamar TambahDataPelamar Interface EditDataPelamar EditDataPelamar Interface LihatDataPelamar LihatDataPelamar Interface
CapegControl CapegControl Controller
Pelamar Pelamar Entity
Kelola Data Calon
TambahDataCapeg TambahDataCapeg Interface EditDataCapeg EditDataCapeg Interface LihatDataCapeg LihatDataCapeg Interface
Pegawai PegawaiTetapControl PegawaiTetapControl Controller
CalonPegawai CalonPegawai Entity
Seleksi Calon Pegawai
SeleksiCalonPegawai SeleksiCalonPegawai Interface SeleksiControl SeleksiControl Controller
PegawaiTetap PegawaiTetap Entity
Seleksi Pegawai Tetap
SeleksiPegawaiTetap SeleksiPegawaiTetap Interface SeleksiControl SeleksiControl Controller
PegawaiTetap PegawaiTetap Entity
Implementasi file secara lebih lengkap akan dijelaskan di lampiran VI pada halaman 125.
Berikut ini adalah tabel file yang digunakan sebagai tools :
No Nama File Fungsi
1. mysql-connector-java-5.0.5-bin.jar Koneksi ke database
2. jcalendar-1.3.2.jar Library untuk pallete Calendar
4.4. Pengujian Hasil Sistem
4.4.1. Pengujian 5-fold cross validation
Setelah semua usecase berhasil diimplementasikan dan dapat diakses langsung oleh user, tahap akhir dari penelitian ini adalah pengujian sistem yang telah dibangun. Sistem seleksi pegawai yang dibangun menggunakan algoritma Naive Bayesian. Dalam pengujian ini
penulis menggunakan teknik k-fold cross validation dengan 5-fold. Tahap pengujian sistem sebagai berikut:
1. Penentuan 5 kelompok data
Dalam penelitian ini terdapat data sebanyak 325 data. Data dibagi menjadi 5 kelompok atau bagian yang hampir sama, seperti yang terlihat pada gambar dibawah ini:
2. Pengujian dan Perhitungan Akurasi
Setelah data dikelompokan menjadi 5 bagian, maka langkah selanjutnya adalah pengujian dan perhitungan akurasi. Proses pengujian dilakukan dengan 5-fold cross validation. Sedangkan proses perhitungan menggunakan rumus :
Hasil pengujian dan perhitungan akurasi dengan menggunakan 5-fold sebagai berikut :
Tabel 4.1 Tabel Hasil Perhitungan Akurasi
Pengujian Data Training Data Testing Total Data Training Total Data Testing Data Tidak Sesuai Data Sesuai AKURASI I B,C, D, E A 259 66 29 37 56% II A,C,D,E B 259 66 32 34 52% III A,B,D,E C 259 66 38 28 42% IV A,B,C,E D 259 66 37 29 44% V A,B,C,D E 264 61 32 34 56% Rata-rata 50 %
Dari hasil pengujian akurasi seperti terlihat pada tabel diatas, dapat disimpulkan bahwa :
1. Menggunakan teknik 5-fold cross validation, pengujian dengan presentase akurasi yang paling jelek terdapat pada pengujian III dengan akurasi data sebesar 42%. Sedangkan yang paling bagus terdapat pada pengujian I dengan tingkat akurasi sebesar 56%.
2. Pada pengujian III dan penhujian IV masih memiliki nilai akurasi di bawah 50%. Hal ini dapat disebabkan karena variasi data untuk tiap atribut data test rekrutmen berbeda-beda tetapi metode untuk pengelompokkan datanya sama. Oleh karena itu, jumlah variasi klasifikasi yang dihasilkan pun berbeda-beda.
Asumsi lain yang dimiliki adalah dengan adanya data-data anomali pada data training dapat memengaruhi nilai akurasi sistem. Dari data training sebanyak 325 data terdapat 7 record yang memiliki pola data seperti pada tabel 4.2
Tabel 4.2 Tabel Data Anomali
ID Nama nilai_
STTB
test_ psikologi test_ tertulis test_
wawancara
test_
kesehatan
status_
penerimaan
TRN-02039 Mustangin 7,88 Kurang Disarankan 76 3,1 A Diterima
TRN-03024 Susanto 6,80 Kurang Disarankan 81 2,7 A Diterima
TRN-03040 Muh. Puji Astoko 6,92 Kurang Disarankan 75 3,4 A Diterima
TRN-03050 Wibowo Rokhmadi 7,88 Kurang Disarankan 78 3,2 A Diterima
TRN-08047 Andreas Tommy Guntoro 7,07 Kurang Disarankan 80 3,1 A Diterima
TRN-10037 Sayat 8,22 Kurang Disarankan 81 3,0 A Diterima
TRN-10055 Slamet Yunianto 7,45 Kurang Disarankan 84 3,3 A Diterima
Data pada tabel 4.2 dianggap bersifat anomali karena status penerimaan= diterima yang didapat seorang pelamar ketika menjadi pegawai tidak merepresentasikan kemampuan akademis pelamar yang dilihat dari nilai test rekrutmen yaitu nilai STTB, test psikologi, test tertulis, test wawancara, dan test kesehatan.
4.4.2. Analisis Struktur Algoritma Naive Bayesian
Dalam analisis struktur algoritma naive bayesian ini data yang digunakan sebagai sampel data adalah pengujian I dengan jumlah data sebanyak 256 record. Data pengujian I terdiri dari 5 atribut yaitu nilai STTB, test tertulis, test psikologi, test wawancara, test kesehatan. Dari data tersebut terbentuk klasifikasi algoritma naive bayesian untuk setiap atribut sebagai berikut :
1. Nilai STTB
Tabel 4.3 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai STTB dengan status penerimaan diterima.
Tabel 4.3 Tabel nilai likelihood STTB dengan status diterima
Keterangan Nilai Likelihood
Nilai STTB = A 0.08796
Nilai STTB = B 0.4352
Nilai STTB = C 0.3333
Nilai STTB = D 0.3333
Nilai STTB = E 0.0092
Tabel 4.4 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai STTB dengan status penerimaan tidak diterima.
Tabel 4.4 Tabel nilai likelihood STTB dengan status tidak diterima
Keterangan Nilai Likelihood
Nilai STTB = B 0.05
Nilai STTB = C 0.025
Nilai STTB = D 0.06
Nilai STTB = E 0.35
Dari data pengujian I dengan variabel nilai STTB urutan probabilitas status penerimaan diterima terbesar sampai terkecil yaitu nilai STTB = B, nilai STTB = C, nilai STTB = D, nilai STTB = A, nilai STTB = E. Sedangkan status penerimaan tidak diterima nilai STTB = E mempunyai probabilitas paling kecil. Sehingga dari data diatas dapat disimpulkan bahwa calon pegawai yang memiliki peluang terbesar untuk diterima dengan nilai STTB = B dan yang memiliki peluang terbesar untuk tidak diterima dengan nilai STTB = E.
2. Test Tertulis
Tabel 4.5 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test tertulis dengan status penerimaan diterima.
Tabel 4.5 Tabel nilai likelihood test tertulis dengan status diterima
Keterangan Nilai Likelihood
Nilai Test Tertulis = A 0.0045
Nilai Test Tertulis = B 0.0045
Nilai Test Tertulis = C 0.009
Nilai Test Tertulis = D 0.1409
Tabel 4.6 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test tertulis dengan status penerimaan tidak diterima.
Tabel 4.6 Tabel nilai likelihood test tertulis dengan status tidak diterima
Keterangan Nilai Likelihood
Nilai Test Tertulis = A 0.0227
Nilai Test Tertulis = B 0.0227
Nilai Test Tertulis = C 0.0454
Nilai Test Tertulis = D 0.659
Nilai Test Tertulis = E 0.2272
Dari data diatas dapat dilihat bahwa probabilitas status penerimaan diterima terbesar adalah test tertulis = D. Sedangkan probabilitas status penerimaan tidak diterima terbesar adalah test tertulis = D.
3. Test Psikologi
Tabel 4.7 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test psikologi dengan status penerimaan diterima.
Tabel 4.7 Tabel nilai likelihood test psikologi dengan status diterima
Keterangan Nilai Likelihood
Nilai Psikologi = Disarankan 0.367
Nilai Psikologi = Masih Disarankan 0.6147
Nilai Psikologi = Kurang Disarankan 0.0092
Tabel 4.8 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test psikologi dengan status penerimaan tidak diterima.
Tabel 4.8 Tabel nilai likelihood test psikologi dengan status tidak diterima
Keterangan Nilai Likelihood
Nilai Psikologi = Disarankan 0.0238
Nilai Psikologi = Masih Disarankan 0.1428
Nilai Psikologi = Kurang Disarankan 0.5238
Nilai Psikologi = Tidak Disarankan 0.5238
Dari data diatas dapat dilihat bahwa calon pegawai yang memiliki peluang diterima yaitu dengan nilai test psikologi = Masih Disarankan. Dan yang memiliki peluang paling besar untuk tidak diterima yaitu dengan nilai test psikologi = Kurang Disarankan dan Tidak Disarankan.
4. Test Wawancara
Tabel 4.9 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test wawancara dengan status penerimaan diterima.
Tabel 4.9 Tabel nilai likelihood test wawancara dengan status diterima
Keterangan Nilai Likelihood
Nilai Wawancara = A 0.054
Nilai Wawancara = B 0.0045
Nilai Wawancara = C 0.3513
Nilai Wawancara = D 0.1982
Tabel 4.10 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test wawancara dengan status penerimaan tidak diterima.
Tabel 4.10 Tabel nilai likelihood test wawancara status tidak diterima
Keterangan Nilai Likelihood
Nilai Wawancara = A 0.0217
Nilai Wawancara = B 0.0217
Nilai Wawancara = C 0.0435
Nilai Wawancara = D 0.413
Nilai Wawancara = E 0.4348
Dari data diatas dapat dilihat bahwa probabilitas status penerimaan diterima terbesar adalah test wawancara = C. Sedangkan probabilitas status penerimaan tidak diterima terbesar adalah test wawancara = E. 5. Test Kesehatan
Tabel 4.11 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test kesehatan dengan status penerimaan diterima.
Tabel 4.11 Tabel nilai likelihood test kesehatan dengan status diterima
Keterangan Nilai Likelihood
Nilai Kesehatan = A 0.0045
Nilai Kesehatan = B 0.0946
Nilai Kesehatan = C 0.360
Tabel 4.12 menampilkan hasil klasifikasi algoritma naive bayesian untuk nilai test kesehatan dengan status penerimaan tidak diterima.