BAB 2
LANDASAN TEORI
2.1 Perpustakaan Digital
Beberapa literatur yang terkait dengan perpustakaan digital diberikan sebagai berikut.
2.1.1 Definisi Perpustakaan Digital
Ada banyak definisi perpustakaan digital berdasarkan pendapat para ahli atau beberapa lembaga. Beberapa definisi tersebut adalah:
1. Digital Library Federation di Amerika Serikat memberikan definisi perpustakaan digital sebagai organisasi-organisasi yang menyediakan sumber-sumber informasi, termasuk staf dengan keahlian khusus untuk menyeleksi, menyusun, menginterpretasikan, memberikan akses intelektual, mendistribusikan, melestarikan, dan menjamin keberadaan koleksi karya-karya digital sepanjang waktu sehingga koleksi tersebut dapat digunakan oleh komunitas masyarakat tertentu atau masyarakat terpilih secara ekonomis dan mudah (Purtini, 2005).
2. Berdasarkan International Conference of Digital Library 2004, konsep perpustakaan digital adalah sebagai perpustakaan elektronik yang informasinya didapat, disimpan, dan diperoleh kembali melalui format digital. Perpustakaan digital merupakan kelompok workstations yang saling berkaitan dan terhubung dengan jaringan (networks) berkecepatan tinggi. Pustakawan menghadapi tantangan yang lebih besar dalam mendapatkan, menyimpan, memformat, menelusuri atau mendapatkan kembali, dan memproduksi informasi non teks. Sistem informasi modern kini dapat menyajikan informasi
secara elektronik dan memanipulasi secara otomatis dalam kecepatan tinggi (Purtini, 2005).
3. Romi Satria Wahono mendefinisikan perpustakaan digital sebagai suatu perpustakaan yang menyimpan data baik itu buku (tulisan), gambar, suara dalam bentuk file elektronik dan mendistribusikannya dengan menggunakan protokol elektronik melalui jaringan komputer (Wahono, 1998).
Berdasarkan beberapa definisi tentang perpustakaan digital di atas, yang perlu digaris bawahi adalah perpustakaan digital berbeda dengan virtual library dan library automation. Library automation (otomatisasi perpustakaan) adalah suatu sistem yang menggunakan teknologi informasi untuk mengelola suatu perpustakaan termasuk pendaftaran anggota, peminjaman buku dan pengembaliannya serta analisa profil pemakaian perpustakaan oleh anggotanya. Sistem otomatisasi perpustakaan dapat saja mempunyai komponen perpustakaan digital.
Perpustakaan digital menandakan bahwa koleksinya berbentuk digital dan dapat saja tidak mempunyai koleksi cetakannya. Perpustakaan digital dapat merupakan bagian dari perpustakaan secara umum atau berdiri sendiri. Perpustakaan digital mungkin dapat diakses melalui internet (menjadi virtual library) atau hanya tersedia di jaringa n lokal.
Virtual library dikonotasikan sebagai perpustakaan digital, namun pada dasarnya tidak harus berupa koleksi digital. Virtual library adalah konsep yang dipandang dari sisi pengakses informasi yang dimana informasi diperoleh dari perpustakaan yang seolah-olah ada dalam satu tempat (padahal tidak). Internet pada dasarnya adalah virtual library yang sangat besar dan suatu virtual library pada dasarnya harus dapat diakses dari jarak jauh.
Salah satu tanda perpustakaan digital yang sesungguhnya adalah selain kontennya berbentuk digital, juga klasifikasinya menggunakan sistem digital. Disini umumnya digunakan MARC (Machine Readable Cataloging) yang kompleks atau Dublin Core yang minimalis. Dengan demikian beberapa perpustakaan yang
mendigitalisi dokumennya (umumnya terbatas pada disertasi, tesis dan skripsi) sudah dapat dikatakan mendekati karakter suatu perpustakaan digital.
2.2 Semantic Search
Tujuan dari suatu sistem temu kembali informasi (information retrieval) adalah untuk memetakan kueri dalam bentuk bahasa alami Q (yang menspesifikasikan informasi yang dibutuhkan pengguna) ke suatu set dokumen (yang memenuhi kebutuhan pengguna) dalam koleksi dokumen D serta secara optional mengurutkan (ranking) dokumen tersebut berdasarkan tingkat relevansinya berdasarkan pendekatan tertentu misalnya statistik. Search engine S secara umum dapat direpresentasikan sebagai suatu fungsi pemetaan:
S:QD
Untuk mengimplementasikan suatu sistem temu kembali informasi dibutuhkan penentuan:
1. Elemen atomic (term) apa yang digunakan dalam representasi dokumen dan kueri.
2. Teknik maching (match) apa yang digunakan untuk mencocokkan dokumen dan term kueri.
3. Model apa yang digunakan untuk representasi dokumen dan kueri.
4. Struktur data mana yang digunakan untuk pengindeksan dan pengembalian. Sehingga sistem temu kembali informasi dapat didefinisikan sebagai:
Sistem temu kembali infomasi = < Model, Data_Struktur, Term, Match >
Secara umum terdapat dua pendekatan utama dalam sistem temu kembali informasi yaitu temu kembali informasi berdasarkan sintaksis dan sistem temu kembali informasi berdasarkan semantik. Dalam temu kembali informasi berdasarkan sintaksis, search engine menggunakan kata atau frase yang terdapat dalam dokumen dan kueri sebagai elemen atomik dalam merepresentasikan dokumen dan kueri. Prosedur pencarian yang digunakan search engine ini pada prinsipnya berdasarkan pada sintaksis matching dari representasi dokumen dan kueri. Search engine ini
mempunyai nilai precision yang rendah sementara menjadi baik dalam hal recall (Wei et al, 2008).
Dalam sistem temu kembali informasi berbasis sintaksis, term direpresentasikan oleh kata atau frase dan match adalah pencocokan berdasarkan kesamaan sintaks. Dalam implementasi sederhana, sintaksis maching dilakukan melalui pencarian kata yang ekuivalen.
Dalam pendekatan semantic search, elemen term dideskripsikan sebagai atomic concept atau complex concept dan match dideskripsikan sebagai maching semantik dari concept dan bukan kata seperti pada pendekatan sintaksis. Ide utama dari pendekatan semantic search berasal dari pandangan kognitif terhadap dunia dimana terdapat asumsi bahwa arti dari suatu teks (kata) bergantung kepada relasi konseptual terhadap obyek dalam dunia nyata dari pada relasi linguistik yang terdapat dalam teks atau kamus. Komponen penting dalam model ini adalah keberadaan struktur concept untuk memetakan deskripsi objek informasi dengan concept yang terdapat dalam kueri. Struktur concept dapat bersifat umum atau domain spesifik dan dapat dibuat dengan pendekatan manual atau otomatis. Tipe utama dari struktur concept yang digunakan dalam pendekatan semantic search antara lain struktur taxonomy, thesauri dan ontologi.
Sebagai contoh sederhana, makna dari kueri “orang dalam kampus Ilmu Komputer” akan diinterpretasikan oleh semantic search sebagai individual (misalnya staf akademik) yang mempunyai relasi (misalnya bekerja untuk atau anggota dari) kampus Ilmu Komputer. Berlawanan dengan sistem temu kembali tradisional yang menginterpretasikan kueri berdasarkan bentuk leksikalnya. Sehingga sumber daya yang berisikan kata “orang” dan “Ilmu Komputer”, mungkin akan dikembalikan.
2.3 Ontologi
Beberapa teori tentang ontologi dipaparkan sebagai berikut.
2.3.1 Pengertian Ontologi
Pada dasarnya ada dua bidang ilmu yang menggunakan istilah ontologi, yakni filsafat dan ilmu komputer. Berawal dari filsafat, kemudian istilah ontologi diadaptasi oleh ilmu komputer setelah melewati perdebatan mengenai apa yang dimaksud dengan ontologi hingga akhirnya ada definisi yang banyak dirujuk dalam literatur ilmu komputer (Fensel et al, 2003).
Untuk membedakan istilah ontologi pada dua bidang ini, digunakan istilah philosophical ontology yang mengarah pada filsafat, dan computational ontology yang mengacu pada ontologi di ilmu komputer atau ada pula menyebutkannya sebagai information systems ontology. Sebagian berpendapat bahwa computational ontology merupakan applied philosophy. Pembahasan ontologi yang dimaksud dalam tugas akhir ini ialah mengenai computational ontology (Gruber, 2007).
Untuk meringkas pengertian ontologi pada filsafat, dapat diberikan satu buah kata yaitu eksistensi. Dengan kata lain, philosophical ontology merupakan theory of existence, studi tentang sesuatu yang ada. Dalam kamus Oxford, ontologi diberikan arti sebagai cabang ilmu metafisika yang mempelajari nature of being. Aristoteles membuat 10 kategori tentang “what exist in the world” antara lain matter, quantity, quality, relation, location, time dan sebagainya.
Selanjutnya, definisi ontologi dalam ilmu komputer yang sering dirujuk berasal dari Tom Gruber (2007) yang menyatakan ”An ontology is an explicit and formal spesification of a conceptualization of domain of interest”.
Dalam memahami definisi tersebut digunakan istilah semantic, logic, controlled vocabulary, taxonomy dan thesauri sebagai sudut pandang untuk memulai
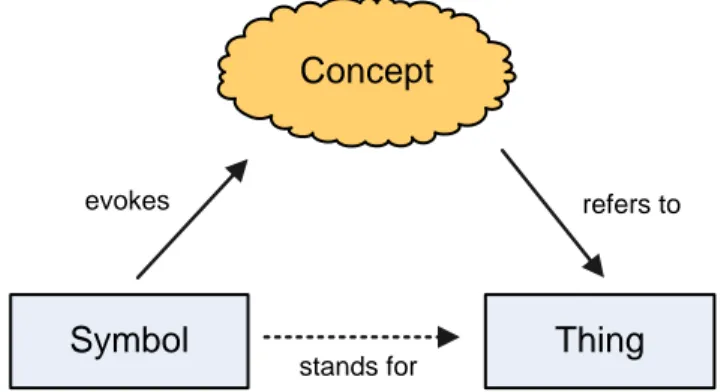
pembahasan tentang pengertian ontologi. Untuk memberikan pengertian semantik, dirujuk permasalahan dalam konteks komunikasi. Dalam konteks komunikasi dengan ataupun tanpa ontologi dikenal suatu penggambaran yang disebut meaning triangle yang dapat dilihat pada Gambar 2.1 berikut.
Symbol Thing
Concept
evokes refers to
stands for
Gambar 2.1 The Meaning Triangle
Ada tiga komponen pada meaning triangle yang berupa symbol, concept dan thing. Symbol merupakan kata atau istilah yang digunakan dalam bahasa (syntax). Thing (referent) adalah sesuatu yang diwakilkan oleh symbol, namun tidak terdapat relasi langsung dari symbol menuju thing. Untuk memahami thing yang dimaksud, diperlukan concept yang memberikan meaning (semantic) sehingga terdapat reference menuju thing tersebut.
Sebagai contoh, kata ”kijang” dalam kalimat ”Saya melihat kijang” dapat dimengerti sebagai hewan kijang atau ”kijang” yang merupakan merk mobil. ”Kijang” merupakan simbol yang menggambarkan sesuatu berupa mobil dan hewan. Mobil dan hewan sebagai sesuatu yang dapat dimengerti karena sudah ada konsep tentang mobil (kenderaan beroda empat) dan juga hewan makhluk hidup. Bandingkan jika kata yang diberikan ”AIRKJT340” yang mungkin tidak akan memberikan makna apapun. Atau dengan kata lain tidak ada konsep yang dapat diasosiasikan dengan sesuatu. Disini dapat dilihat bahwa konsep merupakan pemahaman kognitif tentang yang ada di dunia nyata dan konsep akan memberikan makna (semantik) pada suatu kata (sintaks).
Suatu kosakata terkontrol (controlled vocabulary) adalah suatu daftar istilah (term) atau konsep yang dinyatakan secara eksplisit. Semua istilah dalam kosakata terkontrol memiliki definisi yang jelas dan tidak redudansi.
Taxonomy adalah koleksi dari kosakata terkontrol yang diorganisasikan secara hierarki berdasarkan hubungan generalisasi. Setiap istilah dalam taxonomy memiliki satu atau lebih relasi induk-anak (parent-child) dengan istilah lain dalam taxonomy. Ada mungkin beberapa variasi relasi induk-anak dengan istilah lain dalam taxonomy, misalnya whole-part, genus-spesies, type-instance. Beberapa taxonomy membolehkan poly-hierarchy yang berarti bahwa suatu istilah dapat memiliki lebih dari satu induk.
Thesauri adalah jaringan koleksi dari kata atau frase dengan satu set relasi linguistik. Thesauri juga menggunakan relasi asosiatif selain menggunakan relasi induk-anak sehingga thesauri lebih kuat dalam memberikan semantik bila dibandingkan dengan taxonomy. Relasi asosiatif dalam thesauri misalnya “related- to”, ”broader”, ”narrower” dan sebagainya.
Ontologi lebih dikenal sebagai logical theory yang merupakan ekstensi dari taxonomy dan thesauri. Dalam ontologi terdapat taxonomy, karena konsep-konsep dari domain diorganisasikan secara hierarki. Ontologi juga menggunakan relasi asosiatif seperti pada thesauri, namun yang membedakan antara ontologi dan kedua pemodelan semantik pendahulunya adalah karena ontologi melibatkan unsur logika. Dalam ontologi dikenal disjoint concept, transitive property, inverse property, symmetry property, multiple inheritance dan property inheritance sehingga ontologi lebih kaya akan semantik dan jauh lebih kompleks dari taxonomy dan thesauri. Selain itu, unsur logika dalam ontologi diinterpretasikan dalam bahasa representasi sehingga semantik bersifat formal dan dapat digunakan oleh mesin misalnya untuk inferensi (penarikan kesimpulan baru).
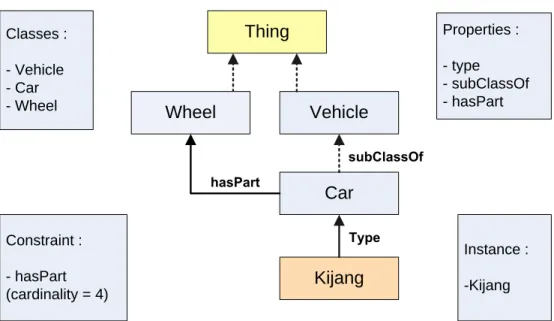
Gambar 2.2 merupakan contoh ontologi yang memodelkan konsep sederhana tentang mobil. Pada gambar tersebut terdapat konsep Thing, Vehicle, Car, dan Wheel. Dari contoh sederhana ini dapat dilihat bahwa Thing pada domain yang dimaksud terdiri Vehicle, Car, dan Wheel. Konsep Car sebagai suatu Vehicle,
hierarki ini dikenal sebagai relasi is-a (Car is-a Vehicle). Selain itu, Car memiliki properti hasPart yang menghubungkannya dengan Wheel (Car hasPart Wheel), jumlah Wheel yang dimiliki sebanyak 4. Kijang adalah contoh instance (individu) dari konsep Car.
Thing Classes : - Vehicle - Car - Wheel Properties : - type - subClassOf - hasPart Wheel Vehicle Car hasPart subClassOf Kijang Type Constraint : - hasPart (cardinality = 4) Instance : -Kijang
Gambar 2.2 Contoh Ontologi
2.3.2 Latar Belakang Historis
Ontologi pada ilmu komputer (computational ontology) berakar pada penelitian di bidang Artificial Intelligence (AI) sejak tahun 1980. Namun ada pula yang berpendapat bahwa isu ontologi sudah diangkat oleh para peneliti di bidang database management system pada tahun 1960 untuk menjawab pertanyaan bagaimana data diasosiasikan dengan dunia nyata. Dengan mengadaptasi istilah ontologi yang digunakan pada filsafat, ”what exist” pada suatu AI sistem adalah sesuatu yang dapat direpresentasikan. Representasi yang digunakan bersifat formal dan merupakan bahasan pada knowledge representation (Barry Smith, 2001).
Dengan menggunakan ontologi, selain merepresentasikan knowledge dengan bahasa yang dapat dimengerti oleh mesin (machine-understandable), dapat terjadi komunikasi antar software agent seperti yang terjadi pada manusia karena memiliki
unsur semantik yang dapat dipahami oleh agent tersebut. Sekarang, pembahasan ontologi sangat berkembang terkait dengan aplikasinya pada web, yaitu visi semantic web yang akan dijelaskan pada subbab 2.2.
2.3.3 Tipe Ontologi
Ontologi dapat dibedakan menjadi beberapa tipe sebagai berikut:
1. Upper-level ontology
Upper-level Ontology merupakan ontologi yang berupa suatu model umum untuk merepresentasikan apa yang ada di dunia, sangat serupa dengan apa yang diteliti dalam philosofical theory. Saat ini ada SUO (Standard Upper Ontology) yang dikembangkan oleh IEEE. Namun sangat sulit untuk mencapai kesepakatan dalam menetapkan ontologi yang demikian umum. Beberapa kandidat untuk SUO adalah SUMO (Suggested Upper Merged Ontology) dan Cys upper Ontology (OpenCys). NASA juga mengembankan upper level ontology yang disebut SWEET (Sementic Web for Earth and Environmental Terminology).
2. Domain ontology
Domain ontology merupakan ontologi yang merepresentasikan suatu domain tertentu saja. Banyak penelitian yang mengembangkan ontologi di bidang kesehatan atau biologi, seperti Gene Ontology, Cancer Ontology, dan Medical Ontology.
3. Application dan Task Ontology
Application dan Task Ontology merupakan ontologi yang khusus menyatakan application dan task yang indipenden terhadap domain. Contoh ontologi tipe ini adalah PROTON yang digunakan untuk knowledge management system dan selanjutnya dikembangkan pula untuk automatic entity recognition dan information extraction dari teks.
2.3.4 Kegunaan
Setelah mendapatkan pengertian tentang ontologi, sekarang dapat disebutkan apa saja kegunaan ontologi secara umum. Ada beberapa peran ontologi (bergantung pula dari tipe ontologi yang dimaksud).
1. Komunikasi
Masalah komunikasi seperti yang dijelaskan pada tahap awal pengertian, perlu adanya representasi semantik agar informasi dapat disampaikan secara tepat. Ontologi berguna untuk memfasilitasi komunikasi antar manusia dalam suatu organisasi dengan menyediakan model konsep sehingga memungkinkan shared understanding. Model dapat dibuat dengan menyusun definisi, kosakata, dan terminologi yang secara informal merepresentasikan semantik. Selain itu penggunaan diagram yang sudah dikenal seperti ER dan UML sangat efektif dalam komunikasi antar manusia untuk memahami suatu sistem. Komunikasi antar software agent dan intelligent agent juga dapat memanfaatkan ontologi sesuai dengan format message yang digunakan. Standard komunikasi antar intelligent agent seperti yang telah di tetapkan oleh FIPA (Foundation for Intelligent Physical Agent).
2. Interoperability
Ontologi juga sangat bermanfaat untuk integrasi sistem yang sudah ada, terlebih lagi dalam aplikasi sistem terdistribusi. Hal ini memungkinkan jika ontologi yang sama digunakan sehingga dapat terjadi pertukaran informasi antar sistem dengan mudah. Keragaman informasi di tingkat sintaks dan struktur dapat diatasi dengan ontologi yang berada di level semantik sebagai format standard data.
3. System Engineering
Ontologi juga berguna dalam perancangan dan pengembangan sistem, misalnya dapat membuat spesifikasi sistem yang terdiri atas komponen dan relasinya. Selain itu, ontologi juga dapat meningkatkan reliability sistem dengan menjadi standard untuk memeriksa konsistensi software dengan
spesifikasi yang telah dibuat. Reuse pemodelan untuk permasalahan dan domain juga dapat dilakukan dengan menggunakan ontologi.
2.3.5 Pengembangan
Setelah melihat pengertian dan kegunaan ontologi, berikut akan dijelaskan sedikit mengenai pembuatan dan manajemen ontologi. Kedua hal ini tidak akan dibahas secara mendalam karena merupakan topik lanjut yang berada di luar lingkup penelitian ini.
2.3.5.1 Pembuatan
Pembuatan ontologi sering dikenal juga sebagai ontology engineering atau ontology development. Pada dasarnya kegiatan ini melibatkan tiga hal, yaitu metode, bahasa dan tool. Ada beberapa metode pengembangan ontologi, salah satunya ialah dengan langkah-langkah seperti pada Gambar 2.3.
Gambar 2.3 Ontology Development Process
Bahasa ontologi dapat dibedakan menjadi dua, yaitu tradisional dan web-based. Tradisional disini maksudnya ialah yang tidak digunakan secara langsung pada web. Bahasa yang tradisional tersebuat antara lain Ontolingua, OKBC, LOOM, F-Logic. Sedangkan bahasa ontologi untuk web yang pernah dibuat antara lain SHOE (Simple HTML Ontology Extention), OML (Ontology Markup Language) dan XOL (XML-based Ontology Language) dan bahasa ontologi sekarang yang banyak digunakan adalah untuk semantic web, yaitu RDF(S) dan OWL.
Tool pengembangan ontologi juga ada bermacam-macam, seperti OntoEdit, WebODE, Altova, dan Protege. Yang terakhir merupakan tool yang powerful dan banyak digunakan baik dalam penelitian maupun untuk pengembangan aplikasi.
Proses pembuatan ontologi dapat memakan waktu yang cukup lama. Karena itu, banyak juga usaha penelitian yang melakukan pembuatan ontologi secara semi-automatic dengan metoda machine-learning dan knowledge discovery. Tidak hanya pembuatan ontologi di level konsep, namun juga pembuatan instances dapat memakan waktu yang lebih lama lagi. Teknik information extranction banyak diaplikasikan untuk pembuatan instances dari teks, berdasarkan natural language analysis. Proses menghasilkan instances disebut juga sebagai annotation text yang bertujuan untuk memberi deskripsi suatu data atau metadata (data tentang data).
2.3.5.2 Manajemen
Ontologi membutuhkan perubahan seiring perubahan pengetahuan juga perubahan penggunaannya. Selain itu, berdasarkan nature ontologi yang reusable dan sharable, diperlukan suatu manajemen ontologi untuk mengatur pemanfaatan ontologi tersebut, termasuk menambah ataupun mengubah ontologi yang sudah ada. Isu ini juga menyangkut hal-hal seperti ontology versioning, alignment, mapping, dan merging.
2.4 Semantic Web
Terkadang penggunaan istilah teknologi semantic web sulit dibedakan dengan teknologi berbasis ontologi (bahkan kedua hal tersebut seolah-olah bisa disamakan). Mungkin hal ini disebabkan karena tidak ada batasan yang jelas antar keduanya. Namun memang inti (backbone technology) dari semantic web adalah ontologi sehingga dapat disimpulkan teknologi semantic web merupakan aplikasi terkini dari ontologi. Bahasan tentang semantic web pasti akan menyertakan ontologi sebagai salah satu layer penerapannya, sedangkan bahasan ontologi belum tentu menyertakan semantic web karena aplikasi ontologi dapat diterapkan bukan dalam bentuk web-based. Semantic web sendiri masih merupakan visi jangka panjang dan penerapannya pun sampai saat ini belum sampai tahap akhir.
2.4.1 Visi
Berdasarkan visi dari penemu World Wide Web (WWW), Tim Berners-Lee, web yang sekarang ini belum sesuai seperti yang diharapkannya pada pertama kali pada tahun 1989. Meskipun sejak tahun 1994 sampai sekarang perkembangan internet telah cukup pesat, namun web page saat ini belum dapat diproses secara otomatis oleh komputer. Artinya, web page yang sekarang sifatnya baru human-readable, sehingga informasi yang ditampilkannya hanya dapat dimengerti manusia.
Semantic web pada intinya ialah menjadikan informasi pada web bersifat machine-readable. Pengertian semantic web menurut Berners-Lee ialah ”The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation” (Daconta et al, 2003).
Dilihat dari penjelasan tersebut, jelas bahwa semantic web tidak menggantikan web yang sudah ada sekarang, namun memperkaya dalam hal informasi yang diberikan menjadi lebih baik dalam pendefinisiannya, sehingga memungkinkan komputer dapat memahami informasi yang diberikan. Motivasi utama dari penerapan semantic web ialah kemampuan komputer untuk melakukan proses secara otomatis, misalnya dalam melakukan pencarian informasi yang lebih efektif dan efisien. Maksudnya, di tengah banyaknya jumlah informasi yang terdapat pada web, pengguna dapat dibantu oleh software agent yang dapat memahami informasi tersebut seperti manusia sehingga software agent tersebut dapat menemukan informasi yang tepat dan berguna untuk ditampilkan, tidak hanya informasi berdasarkan pencocokan kata kunci (keyword match). Bahkan bila semantic web telah mencapai tahap final, pengguna bukan saja dapat mencari informasi yang tepat namun juga dapat mempercayai informasi tersebut. Dengan kata lain, ada level of trust yang dapat disajikan oleh web (Fensel et al, 2003).
Perubahan web yang sekarang menuju semantic web merupakan suatu pergeseran paradigma dari prinsip web sebagai dokumen menjadi data. Informasi pada web dapat diproses karena memiliki representasi yang lebih ”cerdas” (smart data).
Jadi keunggulan software ditentukan bukan dari proses yang dilakukan, namun dari kualitas datanya. Web bukan lagi hanya menampilkan informasi tetapi juga melakukan proses terhadap informasi yang ada. Karena demikian pentingya, data dapat dipandang sebagai raja (data as the king) atau sebagai warga kelas satu (first class citizen) dalam semantic web (Daconta et al, 2003).
Dalam beberapa artikel disebutkan semantic web akan menjadi next generation web atau dengan sebutan Web 3.0. Versi web yang pertama (Web 1.0) ditandai dengan adanya garis batas yang jelas antara producer dan consumer dari suatu web content. Producer adalah organisasi yang membuat website dan consumer adalah pengguna yang melukan browsing website tersebut. Sedangkan web 2.0 menghapus pemisahan tersebut dan menekankan kolaborasi dalam pembuatan web content sehingga terjadi social networking melalui media sharing yang dilakukan. Pengguna tidak hanya sekedar browsing tetapi juga menjadi content provider. Contohnya ialah Wikipedia dan blog. Generasi web berikutnya, seperti yang diharapkan oleh Tim Berners-Lee, dapat menganalisa dan memproses data pada web serta menemukan link diantara data tersebut. Salah satu penerapan semantic web yang sangat bermanfaat ialah untuk integrasi data dari berbagai sumber dan format yang berbeda.
Terkait dengan visi tersebut, semantic web dapat pula dilihat dari sudut pandang berbeda, yaitu semantic web sebagai program dan sebagai teknologi. Sebagai program, saat ini semantic web merupakan aktivitas W3C terkait dengan penelitian dan implementasi semantic web yang melibatkan peneliti dan partner industri. W3C telah membuat beberapa rekomendasi terkait dengan semantic web antara lain RDF, OWL, dan SPARQL. Sedangkan beberapa semantic web framework yang sedang dalam proses rekomendasi yaitu SWRL, SKOS dan RDF.
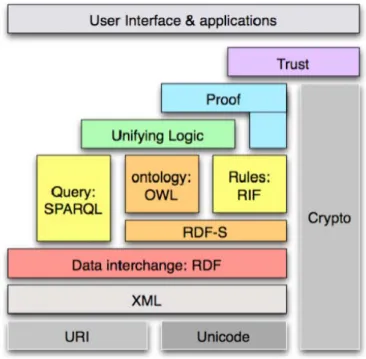
Gambar 2.4 Semantic Web Layer
Teknologi semantic web terbagi dalam beberapa layer arsitektur seperti yang terlihat pada Gambar 2.4. Teknologi yang sering disebut pula sebagai layer cake technology terdiri atas:
1. Unicode dan URI
Unicode adalah standard representasi karakter komputer. URI (Uniform Resources
Identifier) merupakan standard untuk lokasi dan identitas suatu resource (misalnya web page).
2. XML, NS dan XML(S)
XML (Extensible Markup Language) dan Namespace serta Schema, merupakan aturan sintaks yang berfungsi untuk menyajikan struktrur data pada web.
3. RDF + RDF(S)
RDF (Resources Description Framework) merupakan model berbentuk graph untuk merepresentasikan resource dan relasinya. Sedangkan RDF Schema adalah definisi kosakata yang digunakan pada RDF.
4. Ontology Vocabulary
bahasa ontologi yang direkomendasikan oleh W3C pada 10 Februari 2004 adalah OWL Web Ontology Language, merupakan bahasa yang lebih kaya dan kompleks untuk mendeskripsikan resource.
5. Logic dan Proof
layer ini berupa rule dan sistem untuk melakukan reasoning pada ontologi sehingga dapat disimpulkan apakah suatu resource memenuhi syarat tertentu.
6. Trust
Layer dari semantic web yang memungkinkan pengguna web untuk mempercayai suatu informasi pada web.
2.5 RDF (Resource Description Framework)
RDF merupakan standard untuk mendeskripsikan resource. Secara umum, resource adalah sesuatu yang ingin dibicarakan, sesuatu yang dapat diidentifikasi, misalnya website, homepage, orang, benda dan sebagainya. Tidak seperti HMTL (Hypertext Markup Language) yang fungsi utamanya untuk menampilkan informasi dan XML (Extensible Markup Language) yang berfungsi dalam pertukaran informasi, RDF adalah suatu model data yang digunakan untuk menjelaskan informasi (meta informasi).
Selama ini, metadata sudah banyak dikenal dan digunakan, terutama menggunakan XML. Meskipun XML sudah menyajikan bentuk data yang terstruktur, namun dalam konteks semantic web hal tersebut tidaklah cukup. Karena XML hanya menyediakan syntactic interoperability. Contohnya apabila label yang digunakan untuk suatu harga barang adalah
<price> Rp 125.000 </price> sedangkan pada dokumen tagihan diberi label
<cost> Rp 125.000 </cost>
maka kedua data tersebut bisa dianggap berbeda padahal menjelaskan barang yang sama sehingga data tidak bisa diproses lebih lanjut. RDF menyediakan suatu fondasi dasar dalam menemukan relasi antar resources.
RDF merupakan suatu model data yang berbentuk graph, yaitu dengan representasi node dan edge (disebut juga directed graph karena ada arah yang dituju oleh edge). Statement RDF berupa triple, yaitu subject, predicate, object (Manola et al, 2004).
Jhon Smith Http://purl.org/dc/elements/1.1/creator Http://www.example.org/index.html : Resource : Property : Value Gambar 2.5 RDF Statement
Subject ialah resource yang ingin dijelaskan melalui property dan value of property. Pada Gambar 2.5, subject berupa node yang menjadi titik awal edge. Predicate berupa property yang menghubungkan subject dan object, direpresentasikan dengan tanda panah (edge). Sedangkan object dapat berupa resource atau literal value, yang menjadi titik akhir edge. Sedangkan object dapat berupa resource atau literal value, yang menjadi titik akhir edge. Contoh kalimat yang berisi pernyataan seperti pada Gambar 2.5 adalah
http://www.example.org/index.html has a creator whose value is Jhon Smith
Subject Predicate Object Setelah melihat konsep RDF, berikut beberapa hal mengenai RDF yang kan dibahas yaitu naming, syntax, vocabulary (RDF Schema), dan kueri pada RDF.
2.5.1 RDF Naming
Resource diidentifikasi dengan menggunakan URI (Uniform Resource Identifier), seperti http://example.org/index.html. URL (Uniform Resource Locator)
merupakan salah satu jenis URI yang khusus digunakan untuk mengakses resources (web document) melalui jaringan komputer. URI penggunaanya lebih umum, tidak
hanya untuk mengakses resources tetapi lebih untuk merujuk (refer) sesuatu. RDF menggunakan URI sebagai mekanisme dasar untuk identifikasi resource. Jadi dalam konteks ini http://example.org/index.html bukan menyatakan suatu alamat yang
dapat diakses melalui web browser melaikan untuk mengidentifikasi resource. Dalam penamaan RDF statement, subject dan property harus berupa URI, tetapai object dapat berupa URI atau literal (Constant value).
URI dapat diikuti dengan fragment identifier, yaitu setelah tanda ”#”, misalnya
http://example.org/index.html#section2. Bentuk URI seperti ini dinamakan dengan URI reference (URIref) dan digunakan untuk penamaan sesuatu yang dinyatakan dalam RDF, yaitu sebagai resource ID. Karena RDF tidak menggunakan URI untuk mengakses resources sebagai suatu web document, maka
http://example.org/index.html dianggap tidak memiliki relasi atau kaitan langsung dengan http://example.org/index.html#section2, sebab relasi antar resource pada RDF dinyatakan secara explisit melalui property.
Untuk menyederhanakan penulisan URI, RDF menggunakan qualified names (QNames) yang terdiri atas prefix untuk suatu namespace, diikut i oleh tanda”:”, dan local name (ID). Contohnya ialah ”dc:creator”. QNames merupakan penamaan yang digunakan untuk XML content, tetapi dalam konteks RDF tidak terbatas hanya untuk penulisan yang berbasis XML (pada bagian berikutnya akan dilihat tipe syntax RDF yang lain). Penggunaan namespace dimaksudkan untuk menghindari konflik penamaan pada tag XML dengan memakai URI.
Jadi, jika RDF statement dalam bentuk awalnya seperti ini:
http://www.example.org/index.html
http://purl.org/dc/elements/1.1/creator ”John Smith”.
dengan menggunakan
Prefix ex: untuk namespace URI:http://www.example.org/
Prefix dc: untuk namespace URI:http://purl.org/dc/elements/1.1/creator
maka RDF statement tersebut menjadi lebih singkat seperti ini: ex:index.html dc:creator ”Jhon Smith”
2.5.2 RDF Syntax
Cara penulisan RDF ada beberapa, misalnya RDF/XML, N-Triple, N3, Turtle dan lain-lain. Format RDF/XML atau disebut juga serialization format memiliki syntax yang lebih rumit untuk ditulis maupun dibaca oleh manusia. Contoh format RDF/XML sebagai berikut. <?xml version="1.0"?> <rdf:RDF xmlns:rdf=http://www.w3.org/1999/02/22-rdf-syntax-ns# xmlsns:dc:”http://purl.org/dc/elements/1.1/”> <rdf:Description rdf:about=”http://www.example.org/index.html”> <dc:creator>John Smith</dc:creator> </rdf:Description> </rdf:RDF>
Syntax yang lebih sederhana dan mudah dipahami ialah notation 3 (N3). Statement RDF dengan jelas dinyatakan dalam bentuk triples. Salah satu contoh konvensi penulisan property ialah ”rdf:type” menjadi ”a”. Berikut contoh penulisannya yang equivalent dengan RDF/XML di atas.
@prefix rdf:< http://www.w3.org/1999/02/22-rdf-syntax-ns#> @prefix dc: http://purl.org/dc/elements/1.1/
@prefix ex: http://www.example.org/index.htmle x:index.html dc:creator ”John Smith”.
2.5.3 RDF Schema
RDF Schema (RDFS) digunakan untuk mendefinisikan kosakata yang dipakai pada RDF. RDFS merupakan bahasa yang dapat dipakai untuk membuat ontologi yang sederhana (lightweight). Seperti yang telah diuraikan sebalumnya, model RDF berbentuk triples. Hal ini dapat dimanfaatkan untuk menyatakan class, property, value dan akan dapat membahas class hierarchies untuk mengklasifikasikan dan mendeskripsikan objek. Tujuan dari RDFS menyatakan data model seperti yang digunakan pada object-oriented programming (OOP). Namun ada beberapa perbedaan misalnya RDFS memungkinkan multiple inheritance. Tabel 2.1 dan 2.2 berisi
beberapa data kosakata utama berupa class dan property yang didefeniskan dalam RDFS (Brickley et al, 2004).
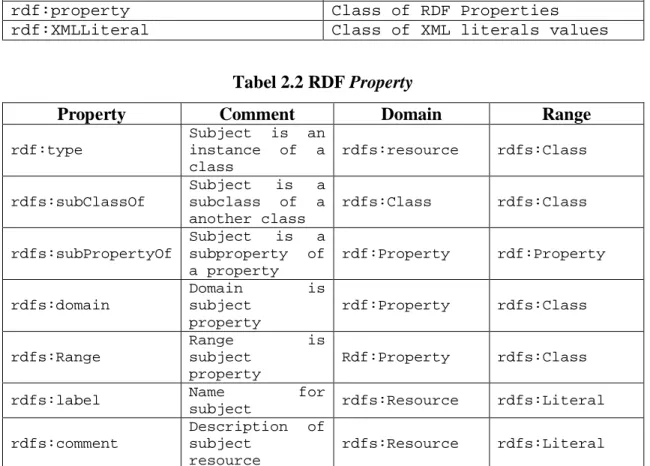
Tabel 2.1 RDF Classes
Class Name Comment
rdfs:Resource Class resource, everything
rdfs:Class Class of classes
rdfs:Literal Class of literal value
(strings, integers)
rdfs:Datatype Class of RDF Datatypes
rdf:property Class of RDF Properties
rdf:XMLLiteral Class of XML literals values
Tabel 2.2 RDF Property
Property Comment Domain Range
rdf:type Subject is an instance of a class rdfs:resource rdfs:Class rdfs:subClassOf Subject is a subclass of a another class rdfs:Class rdfs:Class rdfs:subPropertyOf Subject is a subproperty of a property rdf:Property rdf:Property rdfs:domain Domain is subject property rdf:Property rdfs:Class rdfs:Range Range is subject property Rdf:Property rdfs:Class
rdfs:label Name for
subject rdfs:Resource rdfs:Literal
rdfs:comment
Description of subject
resource
rdfs:Resource rdfs:Literal
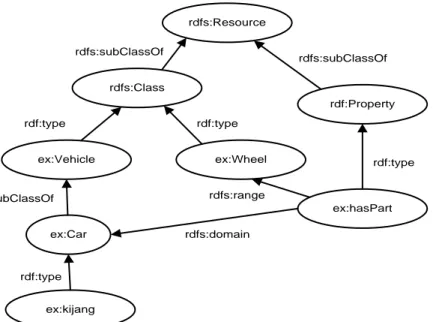
Hal yang paling mendasar dalam penggunaan RDFS ialah mendeskripsikan class, property, dan value dan relasi antar class serta instance. Gambar 2.6 adalah contoh RDF Graph yang merepresentasikan ontologi tentang mobil.
rdfs:Resource rdfs:Class rdf:Property ex:Vehicle ex:Wheel ex:Car ex:hasPart ex:kijang rdfs:subClassOf rdfs:subClassOf rdf:type rdfs:range rdfs:subClassOf rdfs:domain rdf:type rdf:type rdf:type
Gambar 2.6 Contoh RDF Schema
2.5.4 RDF Query
Untuk mendapatkan data yang disimpan dalam model RDF, diperlukan bahasa kueri. Ada beberapa macam bahasa kueri RDF, salah satunya adalah SPARQL yang direkomendasikan W3C pada tanggal 15 januari 2008. SPARQL query terdiri atas triple pattern yang disebut basic graph pattern. Triple pattern sama seperti RDF triple kecuali masing-masing subject, predicate, dan object dapat berupa variabel. Contoh kueri 1 menggunakan triple pattern dengan variabel yang ditanyakan adalah object. Sedangkan kueri 2 menunjukkan variabel yang ditanyakan adalah subject dan object. Data:
<http://www.example.org/index.html>
<http://purl.org/dc/elements/1.1/creator> ”Jhon Smith”
Kueri 1: SELECT ?x WHERE { <http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/creator> ?X. }
Hasil 1: x ”Jhon Smith” Kueri 2: SELECT ?X ?Y WHERE { ?X <http://purl.org/dc/elements/1.1/creator> ?Y. } Hasil 2: x y
<http://www.example.org/index.html> ”Jhon Smith”
2.6 OWL (Ontology Web Language)
OWL adalah bahasa ontologi untuk web yang merupakan ekstensi dari RDF Schema. Sama seperti RDF, OWL juga direkomendasikan oleh W3C pada tanggal 10 Februari 2004 sebagai bagian dari aktivitas pengembangan semantic web. OWL merupakan successor dari bahasa sebelumnya dikembangkan, yaitu Defense Advance Research Projects Agency (DARPA), Agent Markup Language (DAML) dan Ontology Inference Layer (OIL). Saat ini OWL adalah bahasa ontologi paling ekspresif yang digunakan untuk aplikasi semantic web. Karena visi semantic web untuk memberikan informasi yang bermakna secara eksplisit sehingga mesin dapat memproses secara otomatis dan mengintegrasikan informasi pada web, maka diperlukan bahasa yang tepat untuk merepresentasikan informasi tersebut. OWL digunakan untuk merepresentasikan makna dari kosakata dan relasi antar kata sehingga makna suatu informasi menjadi eksplisit (McGuinness et al, 2004).
OWL dapat dilihat sebagai RDF triples dan juga berbentuk graph model seperti RDF. Pemodelan OWL secara grafik dapat menggunakan UML (Unified Modeling Language) agar lebih mudah karena notasinya telah banyak digunakan oleh developer untuk menggambar class diagram.
2.6.1 Sub Bahasa OWL
OWL menyediakan tiga level bahasa (species) yang penggunaannya disesuaikan dengan kebutuhan, yaitu OWL Lite, OWL DL, dan OWL Full. OWL DL dapat dipandang sebagai ekstensi dari OWL Lite dan OWL Full sebagai ekstensi dari OWL DL. Berikut penjelasan masing-masing sub bahasa OWL.
1. OWL Lite
Sub bahasa ini adalah yang paling sederhana dibanding sub bahasa lainnya. Memiliki formalitas bahasa yang rendah (secara logic) tetapi lebih ekspresif dibanding RDF(S). OWL Lite digunakan untuk memenuhi kebutuhan klasifikasi secara hierarkis dan batasan (constraint) yang sederhana. Cardinality constraint yang diperbolehkan pada level ini hanya 0 atau 1. Level ini memberikan kemudahan dalam migrasi dari bentuk taxonomy biasa.
2. OWL DL (Description Logic)
OWL DL berdasarkan description logic (subset dari first order predicate logic) yang berkembang dari semantic network dan memiliki definisi formal untuk knowledge representation. Sub bahasa ini menambahkan beberapa features selain dari yang dimiliki oleh OWL Lite, antara lain membuat class dengan operasi himpunan (boolean combination) seperti unionOf, intersectionOf, complementOf. Selain tidak membatasi cardinality hanya 0 atau 1, OWL DL juga memungkinkan untuk mendefinisikan suatu nilai property yang berasal dari instance suatu class dengan feature hasValue. Ada pula tambahan feature untuk class yaitu disjointWith dan oneOf (enumerated classes).
3. OWL Full
Level ini merupakan subbahasa yang paling kompleks dan digunakan oleh pengguna yang menginginkan ekspresi maksimum tanpa adanya jaminan computational (pada saat reasoning mungkin tidak lengkap atau selesai dalam waktu yang berhingga). Hal ini berbeda dengan OWL DL yang memberikan jaminan tersebut sehingga bisa dilakukan automated reasoning pada subbahasa
tersebut. Pada OWL Full, suatu class dapat diperlakukan sebagai collection of instances dan instance itu sendiri. Selain itu, datatypeProperty dapat dispesifikasikan sebagai inverseFunctionalProperty.
Pemilihan subbahasa yang akan digunakan harus melihat pada kebutuhan. Pilihan antara OWL Lite dan OWL DL bergantung pada cukup tidaknya konstruksi dengan OWL Lite (apakah perlu menggunakan yang lebih ekspresif dengan OWL DL). Sedangkan pilihan antara OWL DL dan OWL Full bergantung pada apakah lebih penting melakukan automated reasoning atau memberikan ekspresi yang lebih tinggi pada model seperti memberikan metaclasses (classes of classes).
2.6.2 Elemen OWL
Elemen pada OWL terdiri atas clasess, properties, instance of clasess dan relasi antar instance. Berikut akan dijelaskan secara singkat elemen dasar OWL untuk memberikan gambaran lebih jelas tentang penggunaan OWL berikut dengan penggunaan sintaksisnya yang berbasis RDF/XML. Untuk pengembangan ontologi (dengan OWL) sebaiknya menggunakan ontologi editor seperti protege agar lebih fokus pada representasi yang akan dilakukan, sedangkan sintaksnya dapat dihasilkan (generated) oleh tool secara otomatis. Sintaks yang dijelaskan disini hanya sebagai gambaran agar dapat memahami elemen atau komponen yang dinyatakan melalui OWL.
1. Classes
OWL mendefinisikan root dari semua yang ada dengan owl:Thing. Jadi semua class yang dibuat secara implisit merupakan subclass owl:Thing. Pembuatan Class menggunakan owl:Class dan menyatakan subclass dengan
rdfs:subClassOf. Contoh pendefinisian class Vehicle dan Car yang menjadi subclass Vehicle.
<owl:Class rdf:ID=”Vehicle”> <owl:Class rdf:ID=”Wheel”>
<owl:Class rdf:ID=”Car”>
<rdfs:subClassOf rdf:resource=”#Vehicle” /> </owl:Class>
Penggunaan rdf:ID dapat diganti dengan rdf:about=”#Car” yang menjadi reference untuk mendefinisikan resource, dalam hal ini ialah class Car. Definisi class dapat dibedakan menjadi dua bagian, yaitu pemberian nama atau reference, dan daftar keterangan atau restriction yang berlaku untuk class tersebut, misalnya subClassOf.
2. Individuals
Individuals atau disebut juga instance adalah anggota (members) dari classes. Instance ini dapat dipandang sebagai objek yang ada pada domain yang dibahas. Sama seperti owl:Class yang menjadi metal level untuk class, begitu pula class yang telah didefinisikan menjadi meta level untuk instance. Contoh pendefinisian instance dari class Car:
<Car rdf:ID=”kijang” />
Sintaks di atas sama artinya dengan pendefinisian berikut:
<owl:Thing rdf:ID=”kijang” /> <owl:Thing rdf:about=”#kijang”> <rdf:type rdf:resource=”#Car”/> </owl:Thing>
Dalam format RDF, hal serupa dapat direpresentasikan dengan makna yang sama
<rdf:Description rdf:about=”kijang”> <rdf:type rdf:resource=”#Car” /> </rdf:Description >
3. Properties
Property merupakan binary relation. Ada dua jenis property pada OWL, yaitu ObjectProperty (relasi antara instance dari dua classes) dan DatatypeProperty (relasi antara instance dengan RDF literal dan XML Schema datatypes). Sama
halnya seperti class yang dapat dinyatakan secara hierarkis, begitu pulsa property dapat dinyatakan sebagai subPropertyOf dengan
rdfs:subPropertyOf. Untuk memberikan batasan pada suatu property, dapat digunakan rdfs:domain dan rdfs:range yang disebut juga sebagai global restriction karena berlaku untuk umum, tidak terbatas pada class tertentu. <owl:ObjectProperty rdf:ID=”hasPart”>
<rdfs:domain rdf:resource=”#Car”/> <rdfs:range rdf:resource=”Wheel”/> </owl:ObjectProperty>
Jadi setalah property hasPart didefinisikan, dapat ditambahkan restriction pada class Car yang memiliki cardinality = 4 untuk property tersebut.
<owl:Class rdf:ID=”Car”>
<rdfs:subClassOf rdf:resource =”#Vehicle” /> <rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource =”#hasPart”/> <owl:cardinality rdf:datatype
=”&xsd;int”>4</owl:cardinality> </owl:Restriction>
</rdfs:subClassOf> </owl:Class>
Ada dua hal terkait dengan property, yaitu:
a. Characteristic memberikan tambahan keterangan untuk property yaitu
inverseOf, TransitiveProperty, SymmetricProperty, FunctionalProperty, dan InverseFunctionalProperty.
b. Restriction disebut juga sebagai local restriction karena memberikan batasan pada definisi suatu class, seperti pada contoh yang diberikan sebelumnya tentang cardinality dengan Restriction dan onProperty. Ada tiga macam restriction, yaitu quantifier, cardinality dan hasValue. Untuk menentukan quantifier digunakan allValuesFrom dan someValuesFrom.
2.6.3 Rule dan Reasoning
Reasoning pada OWL DL berdasarkan open world assumption, artinya tidak dapat diasumsikan sesuatu tidak ada sampai hal tersebut dinyatakan secara eksplisit tidak ada. Dengan kata lain, karena sesuatu tidak dinyatakan true, tidak dapat diasumsikan sesuatu itu false. Proses reasoning atau inference pada OWL DL menggunakan reasoner DIG (Description Logic Implementers Group) seperti Pellet, Racer atau FaCT. Reasoner ini digunakan untuk memeriksa konsistensi pada ontologi, melakukan klasifikasi secara otomatis berdasarkan relasi hierarki (subsumption reasoning), dan mendapatkan data atau fakta baru berdasarkan axioms dan rules (Gruber, 2007).
Berikut contoh inference yang dilakukan untuk memperoleh data baru berdasarkan rule mengenai relasi ”paman” (uncleOf) jika diketahui relasi anak (childOf) dan relasi ”saudara laki-laki (brotherOf). Contoh menggunakan sintaks N3. Data awal: John adalah saudara laki-laki Bill, Dave adalah anak John
@prefix eg: http://www.example.org/eg#.
Eg:Person a rdfs:Class . Eg:chileOf a rdf:Property . Eg:brotherOf a rdf:Property . Eg: uncle Of a rdf:Property . Eg: Bill a eg:Person .
Eg:John a eg:Person ; eg:brohterOf eg:Bill . Eg:Dave a eg:Person ;eg:chileOf eg:John .
Didefinisikan rule ”jika x anak dari y, dan y memiliki saudara laki-laki z, maka z adalah paman x”:
(?x eg:chileOf ?y) (?y eg:brotherOf ?z) (?z eg:uncleOf ?x) .
Maka dengan melakukan inference dapat diperoleh triple berikut (Bill adalah paman Dave)
2.7 Inverted Index
Inverted index banyak digunakan dalam sistem temu kembali informasi untuk manajemen indeks. Pengembangan semantic search dalam penelitian ini juga menggunakan inverted index sebagai metode penyimpanan dan pencarian index semantik. Pada dasarnya, inverted index adalah struktur data yang memotong tiap kata (term) yang berbeda dari suatu daftar term dokumen. Sekumpulan dokumen, D = {d1,
d2, ..., dN}, dan tiap dokumen memiliki ID yang unik. Inverted index mempunyai
vocabulary V, yang berisi seluruh term yang berbeda pada masing-masing dokumennya, dan tiap-tiap term ti yang berbeda ditempatkan pada daftar inverted (inverted list) (Manning et al, 2008).
Setiap penempatan akan menyimpan ID dokumen idj, term ti yang terdapat pada tiap dokumen dan informasi lainnya menyangkut term ti pada dokumen tersebut. Sehingga pada setiap penempatan term akan diperoleh notasi sebagai berikut (Manning et al, 2008).
< idj, fij, [o1,o2, ..., ok| fij|]> (2.1) idj adalah ID dokumen dj yang mengandung term ti, fij adalah frekuensi kemunculan term ti didokumen dj, dan ok adalah posisi term ti di dokumen dj. Sebagai contoh, Terdapat tiga dokumen, id1, id2, dan id3,
id1: Web mining is useful 1 2 3 4 id2: Usage mining applications 1 2 3
id3: Web structure mining studies the Web hyperlink structure 1 2 3 4 5 6 7 8
Nomor yang terdapat di bawah kalimat menunjukkan posisi dari setiap term. Dari ketiga dokumen tersebut didapatkan satu set vocabulary, yaitu:
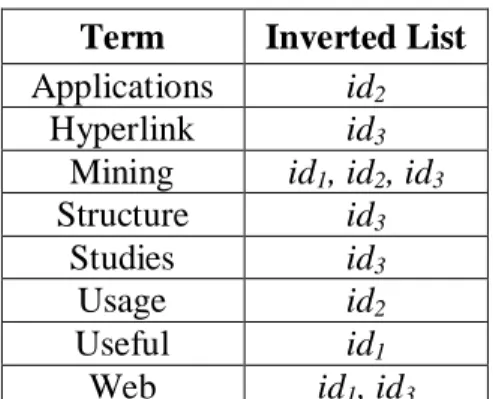
{Web, mining, useful, applications, usage, structure, studies, hyperlink}. Dari vocabulary ini kemudian didapatkan inverted index nya.
Tabel 2.3 Inverted Indeks Sederhana Term Inverted List Applications id2 Hyperlink id3 Mining id1, id2, id3 Structure id3 Studies id3 Usage id2 Useful id1 Web id1, id3
Tabel 2.4 Inverted Indeks Kompleks
Term Inverted List
Applications <id2, 1, [3]> Hyperlink <id3, 1, [7]>
Mining <id1, 1, [2]>, <id2,1, [2]>,< id3 1, [3]> Structure <id3, 2, [2, 8]>
Studies <id3, 1, [4]> Usage <id2, 1, [1]> Useful <id1, 1, [4]
Web <id1,1, [1]>, <id3, 2, [1, 6]>
2.7.2 Pencarian Term
Pencarian dokumen yang relevan pada inverted index terdiri atas tiga langkah: (Manning et at, 2008).
1. Pencarian Vocabulary
Proses ini bertujuan untuk menemukan kueri pencarian pada vocabulary yang sudah ditempatkan pada daftar inverted (inverted list). Jika kueri terdiri dari term tunggal, maka proses akan dilanjutkan ke langkah ketiga. Jika kueri terdiri lebih dari satu term, maka proses dilanjutkan ke langkah ke dua.
2. Penggabungan
Setelah term ditemukan pada daftar invertex, kemudian dilakukan proses penggabungan. Secara sederhana penggabungan adalah proses penyilangan semua daftar inverted untuk mendapatkan perpotongan (intersection) diantara term tersebut. Tujuannya adalah untuk mendapatkan dokumen yang
mengandung keseluruhan term sebagai dokumen yang paling relevan. Jika tidak terdapat dokumen yang mengandung keseluruhan term, maka akan didapatkan dokumen yang mengandung masing-masing term tersebut.
3. Penghitungan Nilai Rangking
Langkah ini menghitung rangking atau skor relevansi untuk tiap dokumen terhadap kueri pencarian, berdasarkan fungsi yang terdapat pada langkah ini (contoh:okapi, persamaan kosinus, pagerank)
Sebagai contoh, dengan menggunakan inverted index pada Tabel 2.2, akan dilakukan pencarian kueri “web mining”. Pada langkah pertama, ditemukan dua daftar inverted yaitu:
Web: <id1,1, [1]>, <id3, 2, [1, 6]>
Mining: <id1, 1, [2]>, <id2,1, [2]>,< id3 1, [3]>
Pada langkah kedua, kedua daftar yang diperoleh kemudian disilangkan untuk mendapatkan perpotangan term tersebut. Posisi term pada dokumen juga berperan penting untuk proses kedua ini. Pada langkah ketiga, penghitungan skor dilakukan. Dengan pertimbangan kedekatan dan urutan kata, maka id1 memiliki skor yang lebih tinggi dibandingkan id3, dalam memberikan informasi yang relevan terhadap term “web mining”.