Fakultas Ilmu Komputer
1856
Klasifikasi Keminatan Menggunakan Algoritme Extreme Learning Machine
dan Particle Swarm Optimization untuk Seleksi Fitur
(Studi Kasus: Program Studi Teknik Informatika FILKOM UB)
Nur Afifah Sugianto1, Imam Cholissodin2, Agus Wahyu Widodo3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Program keminatan pada Program Studi Teknik Informatika Fakultas Ilmu Komputer (FILKOM) Universitas Brawijaya merupakan suatu program pemantapan untuk profil lulusan mahasiswa Teknik Informatika agar setiap mahasiswa memiliki kemampuan khusus sesuai dengan profil lulusan yang ingin dicapai. Untuk dapat membantu mahasiswa dalam memilih keminatan, dibutuhkan suatu sistem cerdas yang dapat menentukan keminatan mahasiswa sesuai dengan minat dan kemampuan mahasiwa. Salah satu metode klasifikasi yang dapat digunakan adalah algoritme Extreme Learning Machine (ELM). Namun metode tersebut tidak memiliki kemampuan untuk menyeleksi fitur sehingga perlu dikombinasi dengan algoritme Particle Swarm Optimization yang dapat digunakan untuk melakukan seleksi fitur secara otomatis dan optimal. Penelitian ini menggunakan 90 data hasil studi mahasiswa dengan 25 fitur dan 3 kelas. Berdasarkan penelitian yang telah dilakukan, didapatkan parameter optimal yaitu jumlah node pada hidden node 20, perbandingan data training dan data testing sebesar 80% : 20% (72 data training dan 18 data testing), jumlah partikel 120, maksimum iterasi 600 dan bobot inersia 1. Dari parameter tersebut didapatkan tingkat akurasi sistem menggunakan algoritme ELM&PSO sebesar 94,44% dengan 11 fitur terpilih. Sedangkan akurasi yang didapatkan dari algoritme ELM biasa hanya mencapai 66,67%. Dari hasil akurasi yang didapatkan, menunjukkan bahwa penambahan algoritme PSO pada ELM mampu meningkatkan akurasi algoritme ELM biasa.
Kata kunci: Klasifikasi, Seleksi Fitur, Extreme Learning Machine, Particle Swarm Optimization.
Abstract
Majoring program in Informatics Engineering Program Faculty of Computer Science (FILKOM) Brawijaya University is a stabilization program for the profile of graduates of Informatics Engineering students so that each student has a special ability in accordance with the profile of graduates to be achieved. To be able to help the student in selecting the major program then a smart system is needed to determine the major program of each student that accordance with the interests and abilities of students. One methods of classification that can be used is Extreme Learning Machine (ELM) algorithm. However, the method does not have the ability to select features so it needs to be combined with Particle Swarm Optimization algorithm that can be used to perform feature selection automatically and optimally. This research uses 90 data of student study result with 25 features and 3 classes. Based on the research that has been done, the optimal parameters are the number of nodes in the hidden node is 20, the comparison of training data and testing data is 80%:20% (72 training data and 18 testing data), the number of particles is 120, the maximum iteration is 600 and the weight of inertia is 1. From these parameters, the system accuracy using ELM&PSO algorithm is 94.44% with 11 selected features. While the accuracy obtained from the ordinary ELM algorithm is only 66.67%. from the results of accuracy obtained, shows that the addition of PSO algorithm on ELM can improve the accuracy of common ELM algorithm.
1. PENDAHULUAN
Penyelenggaraan kurikulum pada Program Studi Teknik Informatika Fakultas Ilmu Komputer (FILKOM) Universitas Brawijaya, terdapat program keminatan. Program tersebut merupakan suatu program yang bertujuan untuk memantapkan dan menguatkan profil lulusan bagi mahasiswa Teknik Informatika sehingga setiap mahasiswa memiliki kemampuan yang khusus sesuai dengan profil lulusan yang ingin dicapai. Kelompok keminatan yang dapat dipilih mahasiswa Teknik Informatika dibagi menjadi 4 kelompok, yaitu Keminatan Rekayasa Perangkat Lunak (RPL), Komputasi Cerdas (KC), Komputasi Berbasis Jaringan (KBJ) serta Multimedia, Game dan Mobile (MGM). Selain itu, pemilihan keminatan juga menjadi syarat bagi mahasiswa Teknik Informatika untuk mengajukan skripsi karena berdasarkan buku pedoman kurikulum setiap mahasiswa diwajibkan mengambil 10 mata kuliah pilihan. Dari 10 mata kuliah pilihan yang diambil, setiap mahasiswa diwajibkan mengambil 6 mata kuliah pilihan dari 1 keminatan yang sama sedangkan 4 mata kuliah sisanya boleh diambil dari keminatan lainnya atau non keminatan (Laporan Kurikulum Berbasis Standar Nasional Pendidikan Tinggi Program Studi Teknik Informatika, 2016).
Permasalahan yang sering terjadi pada mahasiswa yang akan memilih keminatan adalah kebebasan dalam memilih keminatan tanpa adanya syarat-syarat, kriteria–kriteria atau informasi–informasi yang spesifik terkait keminatan tersebut serta kurangnya wawasan mahasiswa terkait keminatan–keminatan yang ditawarkan. Hal tersebut membuat mayoritas mahasiswa menjadi bingung dalam memilih keminatan. Selain itu, ketidaktahuan mahasiswa akan minat dan kemampuan yang dimiliki membuat sebagian besar mahasiswa memilih keminatan hanya karena mengikuti teman. Hal itu semua dapat menyebabkan terjadinya perubahan pemikiran mahasiswa terhadap keminatan yang seharusnya diambil. Selain itu, hal ini tentunya juga akan berdampak pada proses pengerjaan skripsi yang akan terhambat jika sampai terjadi perubahan keminatan karena mahasiswa harus mengambil mata kuliah pilihan lagi untuk memenuhi syarat 6 mata kuliah pada keminatan yang sama.
Berdasarkan banyaknya kendala yang dihadapi mahasiswa Teknik Informatika dalam
milih keminatan, maka diperlukan suatu sistem cerdas yang mampu membantu mahasiswa dalam memilih keminatan sesuai dengan minat dan kemampuan mahasiwa.
Seiring dengan perkembangan dan kemajuan teknologi saat ini, banyak sekali metode–metode yang dapat digunakan untuk melakukan proses klasifikasi pemilihan keminatan. Salah satu metode klasifikasi yang dapat digunakan adalah agoritme Extreme Learning Machine (ELM). Kelebihan dari metode ini terletak pada learning speed serta memiliki tingkat akurasi yang lebih baik di bandingkan dengan metode konvensional lainnya (Siwi, et al., 2016). Penelitian terkait metode Extreme Learning Machine (ELM) telah banyak dilakukan oleh peneliti–peneliti sebelumnya, salah satunya dilakukan oleh Prakoso, Wisesty & Jondri (2016) dengan judul Klasifikasi Keadaan Mata Berdasarkan Sinyal EEG Menggunakan Extreme Learning Machine. Penelitian tersebut mampu menghasilkan nilai akurasi sebesar 97,95%.
Tahap yang perlu dilakukan sebelum melakukan proses klasifikasi adalah proses pengolahan fitur atau seleksi fitur untuk menghasilkan hasil klasifikasi yang lebih baik. Hal ini perlu dilakukan karena proses klasifikasi atau pemilihan keminatan akan menghasilkan hasil yang kurang baik karena adanya fitur–fitur yang tidak relevan dalam kumpulan data. Salah satu solusi yang dapat digunakan untuk memecahkan permasalahan tersebut adalah dengan menggunakan metode Particle Swarm Optimization (PSO). Penggunaan metode PSO dalam meningkatkan akurasi telah dibuktikan oleh Shahsavari, Bakhsh & Rashidi (2016) untuk melakukan klasifikasi penyakit Parkinson menggunakan metode ELM dan Hybrid PSO. Hasil dari penelitian tersebut menunjukkan bahwa penggunaan Hybrid PSO mampu memberikan akurasi yang lebih tinggi dari pada metode-metode seleksi fitur lainnya yaitu mencapai 88,72%.
Berdasarkan permasalahan yang sering dihadapi mahasiswa Teknik Informatika dalam pemilihan keminatan, maka penulis mengusulkan penelitian dengan menggabungkan kedua metode tersebut untuk menyelesaikan permasalahan di atas dengan
judul “Klasifikasi Keminatan Menggunakan
Algoritme Extreme Learning Machine dan Particle Swarm Optimization Untuk Seleksi
Fitur”. Metode ELM diharapkan mampu
berdasarkan kemampuan mahasiswa melalui nilai hasil studi mahasiswa. Sedangkan penggunaan PSO untuk seleksi fitur diharapkan mampu meningkatkan akurasi pada metode ELM.
2. DASAR TEORI
2.1 Penjelasan Dataset
Data yang digunakan pada penelitian ini adalah data nilai hasil studi mahasiswa Teknik Informatika Universitas Brawijaya angkatan 2013 dan jenis kelamin. Data terdiri dari 25 fitur dan 3 kelas yaitu, kelas keminatan KC, RPL dan KBJ. Data yang digunakan dibagi menjadi dua bagian yaitu data training dan data testing yang kemudian akan digunakan untuk proses klasifikasi.
2.2 Klasifikasi
Klasifikasi merupakan proses identifikasi obyek ke dalam sebuah kelas, kelompok, atau kategori berdasarkan prosedur, karakteristik dan definisi yang telah ditentukan sebelumnya. Klasifikasi ini bertujuan untuk membagi objek yang ditugaskan hanya ke salah satu nomor kategori yang disebut kelas. Selain bertujuan untuk membagi objek atau data, klasifikasi juga sering digunakan untuk melakukan prediksi. Klasifikasi bekerja dengan cara menemukan model dari data pelatihan (training) yang label kelasnya telah diketahui.
2.3 Seleksi Fitur
Seleksi fitur merupakan salah satu tahapan praproses pada machine learning yang bertujuan untuk mengurangi dimensi data dan menghilangkan data yang tidak relevan untuk meningkatkan efisiensi, performa sistem dan meningkatkan hasil akurasi (Yu & Liu, 2003). Banyaknya jumlah data dan jumlah fitur pada pengolahan data tentunya dapat menimbulkan permasalahan yang serius pada tingkat skalabilitas dan kinerja sistem untuk beberapa algoritme. Misalkan pada data dengan dimensi yang tinggi yaitu pada data yang memiliki ratusan bahkan ribuan fitur dapat berisi data-data yang tidak relevan yang bisa menurunkan kinerja dari algoritme. Oleh karena itu, pemilihan fitur menjadi sangat perlu dilakukan dalam menghadapi data-data dengan dimensi yang tinggi.
2.4 Extreme Learning Machine (ELM)
Extreme Learning Machine (ELM) merupakan bagian dari jaringan syaraf tiruan yang biasanya disebut dengan single hidden layer feedforward neural network (SLNs). Metode ini memiliki learning speed yang ribuan kali lebih cepat dibandingkan metode feedforward konvensional lainnya seperti Backpropagation dan performansi generalisasi yang lebih baik (Huang, et al., 2006). Pada JST semua parameter harus ditentukan secara manual termasuk input dan bias sehingga membutuhkan learning speed yang lama. Namun pada ELM, semua parameter dipilih secara random sehingga tidak membutuhkan learning speed yang lama dan mampu menghasilkan good generalization performance (Siwi, et al., 2016).
Jaringan ELM terdiri dari 3 layer, yaitu input layer, hidden layer dan output layer. Setiap node pada input layer terhubung dengan hidden node yang dihubungkan oleh bobot input dengan nilai yang berbeda–beda. Setiap input node terhubung ke semua hidden node dan semua hidden node terhubung ke semua output node (Azizah, et al., 2016). Langkah–langkah pada metode ELM dibagi menjadi 2 proses, yaitu proses training dan proses testing. Langkah-langkah tersebut adalah sebagai berikut (Cholissodin, 2016):
A.Proses Training:
Langkah 1:
Inisialisasi input weight (Wjk) dan bias
secara random dengan ukuran matriks j x k, di mana j merupakan banyak hidden node dan k adalah banyak input node.
Langkah 2:
Menghitung matriks keluaran hidden layer (H) dengan fungsi aktivasi sigmoid untuk memetakan nilai matriks keluaran hidden layer pada interval 0 sampai 1 menggunakan persamaan 1.
𝐻 = 1/( 1 + exp(−(𝑋. 𝑊𝑇+
𝑜𝑛𝑒𝑠(𝑁𝑡𝑟𝑎𝑖𝑛, 1) ∗ 𝑏))) (1) Keterangan:
H = Keluaran Hidden Layer exp = Eksponensial
X = Matriks Data Masukan (Input) WT = Matriks Transpose Input weight
kolom. 𝑏 = Bias
Langkah 3:
Menghitung matriks moore–penrose pseudo inverse yang didapatkan dari perkalian matriks inverse dan transpose keluaran hidden layer. Perhitungan Matriks Moore–Penrose Pseudo Inverse ditunjukkan pada persamaan 2.
𝐻+= (𝐻𝑇. 𝐻)−1. 𝐻𝑇 (2) Keterangan:
H+ = Matriks Moore–Penrose Pseudo Inverse
H = Matriks Keluaran Hidden Layer HT = Transpose Matriks Keluaran
Hidden Layer Langkah 4:
Menghitung output weight (𝛽̂) yang dihasilkan oleh hidden layer dan output layer menggunakan persamaan 3.
𝛽̂ = 𝐻+ . 𝑌 (3)
Keterangan:
𝛽̂ = Output weight
𝐻+ = Matriks Moore–Penrose Pseudo Inverse
𝑌 = Matriks Data Output atau Target Langkah 5:
Mengghitung hasil prediksi (𝑌̂) yang didapatkan dari proses perkalian antara matriks keluaran hidden layer dengan output weight menggunakan persamaan 4.
𝑌̂ = 𝐻. 𝛽̂ (4)
Keterangan:
𝑌̂ = Hasil Prediksi
𝐻 = Matriks Keluaran Hidden layer
𝛽̂ = Matrik Output weight B. Proses Testing
Langkah–langkah proses testing pada ELM sama seperti yang dilakukan pada proses training. Namun proses testing tidak perlu menghitung input weight, bias dan output weight. Input weight, bias dan output weight pada proses testing menggunakan bobot yang telah dihitung pada proses training.
Langkah 1:
Menggunakan input weight (Wjk), bias
dan output weight (𝛽̂) yang didapatkan dari
proses training. Langkah 2:
Menghitung matriks keluaran hidden Layer (H) menggunakan persamaan 1. Langkah 3:
Menghitung hasil prediksi (𝑌̂) menggunakan persamaan 4.
Langkah 4:
Menghitung nilai evaluasi, misalnya menggunakan MAPE atau Akurasi.
2.5 Particle Swarm Optimization (PSO)
Particle Swarm Optimization (PSO) merupakan salah satu metode seleksi fitur yang didasarkan pada perilaku sekawanan ikan dan burung yang bergerak untuk mendapatka posisi terbaik. Karena terinspirasi dari perilaku sekawanan makhluk hidup, individu pada PSO biasanya disebut dengan partikel. Setiap partikel pada PSO melakukan perpindahan posisi dengan cara terbang seperti burung dengan suatu kecepatan yang dinamis pada ruang pencarian yang disesuaikan dengan perilaku historis mereka. Oleh karena itu, setiap partikel memiliki kecenderungan untuk terbang menuju posisi yang terbaik (Muhamad, et al., 2016). Langkah– langkah pada Particle Swarm Optimization (PSO) secara sederhana adalah sebagai berikut:
Langkah 1: Proses Inisialisasi
a. Inisialisasi Kecepatan Awal Partikel Pada iterasi awal atau iterasi ke-0, nilai kecepatan awal semua partikel diset 0. b. Inisialisasi Posisi Awal Partikel
Pada iterasi awal atau iterasi ke-0, posisi awal partikel dibangkitkan secara random.
c. Menghitung Nilai Fitness
d. Inisialisasi Nilai Pbest dan Gbest.
Pada iterasi awal atau iterasi ke-0, nilai Pbest sama dengan nilai posisi awal partikel. Sedangkan nilai Gbest didapatkan melalui salah satu Pbest dengan nilai fitness tertinggi.
Langkah 2: Update Kecepatan Partikel
Untuk melakukan update kecepatan partikel, digunakan persamaan 5.
𝑣𝑖,𝑗𝑡+1= 𝑤. 𝑣𝑖,𝑗𝑡 + 𝑐1. 𝑟1(𝑃𝑏𝑒𝑠𝑡𝑖,𝑗𝑡 − 𝑥𝑖,𝑗𝑡 ) +
𝑐2. 𝑟2(𝐺𝑏𝑒𝑠𝑡𝑔,𝑗𝑡 − 𝑥𝑖,𝑗𝑡 ) (5)
Keterangan:
pada iterasi 𝑡+1 (update)
𝑣𝑖,𝑗𝑡 = kecepatan partikel 𝑖 dimensi 𝑗 pada iterasi 𝑡 ( t sebelumnya)
𝑤 = bobot inersia
𝑐1 = konstanta kecepatan 1
𝑐2 = konstanta kecepatan 2
𝑟1, 𝑟2 = nilai acak ∈ [0,1]
𝑃𝑏𝑒𝑠𝑡𝑖,𝑗𝑡 = posisi terbaik dari partikel 𝑖 dimensi 𝑗 pada iterasi 𝑡
𝐺𝑏𝑒𝑠𝑡𝑔,𝑗𝑡 = global optimal dari partikel 𝑔 dimensi 𝑗 pada iterasi 𝑡
𝑥𝑖,𝑗𝑡 = posisi partikel 𝑖 dimensi 𝑗 pada iterasi 𝑡
Langkah 3: Update Posisi Partikel
Untuk melakukan update posisi partikel, dilakukan beberapa langkah perhitungan, yaitu:
a. Menghitung nilai sigmoid pada update kecepatan menggunakan persamaan 6.
𝑆𝑖𝑔(𝑉𝑖,𝑗𝑡) = 1
1+𝑒𝑥𝑝−(𝑣𝑖,𝑗𝑡 ) (6)
Keterangan:
𝑆𝑖𝑔(𝑉𝑖,𝑗𝑡) = posisi partikel 𝑖 dimensi 𝑗 pada iterasi 𝑡
𝑒𝑥𝑝−(𝑣𝑖,𝑗𝑡 ) = kecepatan partikel 𝑖 dimensi 𝑗 pada iterasi 𝑡+1 (update)
b. Membuat nilai random pada interval [0,1] sepanjang banyaknya partikel
c. Menentukan update posisi menggunakan persamaan 7.
𝑥𝑖,𝑗𝑡+1= {1, 𝑗𝑖𝑘𝑎 𝑟𝑎𝑛𝑑[0,1] < 𝑆𝑖𝑔(𝑉𝑖,𝑗 𝑡)
0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 (7)
Keterangan:
𝑟𝑎𝑛𝑑[0,1] = nilai random pada interval [0,1]
𝑆𝑖𝑔(𝑉𝑖,𝑗𝑡) = nilai sigmoid pada update kecepatan
Langkah 4: Update Nilai Pbest dan Gbest
Untuk mendapatkan nilai Pbest dilakukan perbandingan antara Pbest pada iterasi sebelumnya dengan hasil dari update posisi. Fitness yang lebih tinggi dari keduanya akan menjadi Pbest yang baru. Sedangkan untuk mendapatkan nilai Gbest terbaru dapat dilakukan dengan cara melihat Pbest yang memiliki nilai fitness tertinggi.
Langkah 5 : Terminatin Condition
Mengulang langkah 2–4 sampai kondisi berhenti (Terminatin Condition) terpenuhi. Ada
beberapa kondisi berhenti yang dapat digunakan, yaitu:
a. Ketika Iterasi sudah mencapai Maximum b. Iterasi berhenti ketika tidak ada perubahan
yang signifikan
c. Ketika telah mecapai waktu Maximum.
3. PERANCANGAN DAN
IMPLEMENTASI
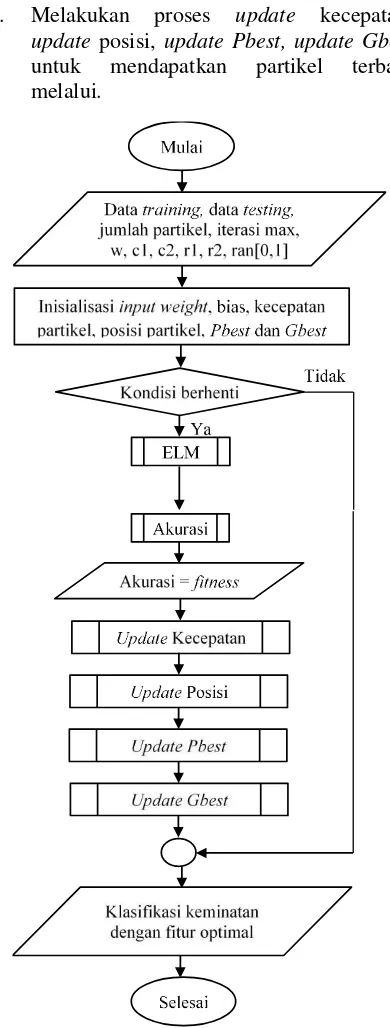
Proses klasifikasi keminatan menggunakan algoritme Extreme Learning Machine dan Particle Swarm Optimization untuk seleksi fitur ditunjukkan pada Gambar 1.
Langkah-langkah yang dilakukan dalam implementasi klasifikasi keminatan menggunakan algoritme Extreme Learning Machine dan Particle Swarm Optimization untuk seleksi fitur adalah:
1. Inisialisasi parameter ELM yaitu data training, data testing, input weight dan bias. Inisialisasi input weight dan bias pada ELM dilakukan secara ramdom pada range [-1,1] dan [0,1] dengan ukuran matriks j x k, di mana j merupakan banyak hidden node dan k adalah banyak input node.
2. Inisialisasi parameter PSO yaitu jumlah partikel, iterasi max, w, c1, c2, r1, r2, ran[0,1], kecepatan partikel, posisi partikel, Pbest dan Gbest. Pada penelitian ini inisialisasi partikel dilakukan secara random yang terdiri dari nilai 1 atau 0 (PSO biner) dengan panjang partikel sama dengan jumlah fitur yang digunakan. Partikel dengan nilai 1 menandakan bahwa fitur diseleksi/digunakan, sedangkan partikel dengan nilai 0 menandakan bahwa fitur tidak digunakan dalam perhitungan. Contoh representasi partikel pada penelitian ini ditunjukkan pada Tabel 1
Tabel 1 Representasi Partikel
No P X1 X2 … X25 Fitness
1 X1(0) 1 0 … 1 0.5
3. Melakukan klasifikasi keminatan menggunakan algoritme ELM untuk setiap partikel.
4. Menghitung nilai akurasi dari hasil klasifikasi yang nantinya akan digunakan sebagai nilai fitness pada PSO menggunakan persamaan 8.
5. Melakukan proses update kecepatan, update posisi, update Pbest, update Gbest untuk mendapatkan partikel terbaik melalui.
Gambar 1. Diagram Alir ELM dan PSO
4. PENGUJIAN DAN ANALISIS
4.1 Pengujian Normalisasi Data
Tujuan dari pengujian normalisasi data adalah untuk mengetahui pengaruh normalisasi data terhadap nilai fitness yang dihasilkan dengan cara membandingkan nilai fitness yang yang diperoleh dari algoritme ELM&PSO dengan menggunakan normalisasi data dan tanpa normalisasi data. Parameter yang digunakan pada pengujian ini yaitu 20 partikel, 100 iterasi,
bobot inersia 1, c1 dan c2 2, jumlah node pada hidden node 20, banyaknya data training dan testing 80%:20%. Hasil pengujian normalisasi data ditunjukkan pada Tabel 2.
Tabel 2. Hasil Pengujian Normalisasi Data
Percobaan ke-i
ELM&PSO dengan Normalisasi
ELM&PSO Tanpa Normalisasi
1 83.33% 77.77%
2 88.89% 77.77%
3 83.33% 77.77%
4 83.33% 77.77%
5 83.33% 77.77%
6 88.89% 77.77%
7 83.33% 77.77%
8 83.33% 77.77%
9 88.89% 77.77%
10 83.33% 83.33%
Rata-rata
Fitness 84.998% 78.326%
Berdasarkan Tabel 2, dapat dilihat bahwa nilai fitness yang dihasilkan algoritme ELM&PSO dengan normalisasi lebih baik dari pada tanpa normalisasi. Hal ini dikarenakan normalisasi data akan mengubah semua data yang ada pada range yang sama yaitu antara 0 sampai 1 sehingga semua data yang ada memiliki jarak data yang tidak terlalu jauh.
4.2 Pengujian dan Analisis Jumlah Hidde Node
Tujuan dari pengujian jumlah hidden node adalah untuk mengetahui pengaruh jumlah node pada hidden node agar menghasilkan hasil klasifikasi yang baik. Banyaknya jumlah node yang digunakan pada pengujian ini adalah dari angka 3 sampai dengan 10 dan 20. Nilai parameter lain yang digunakan pada pengujian ini yaitu 20 partikel, 100 iterasi, bobot inersia 1, c1 dan c2 2, banyaknya data training dan testing 80%:20%.
Gambar 2. Grafik hasil pengujian jumlah hidden node
65 70 75 80 85
3 4 5 6 7 8 9 10 20
Ra
ta
-ra
ta
fi
tn
e
ss
%
Jumlah node
Berdasarkan Gambar 2, hasil pengujian jumlah node pada hidden node menunjukkan bahwa semakin banyak jumlah node pada hidden node maka semakin besar pula rata-rata nilai fitness yang dihasilkan walaupun terdapat beberapa penurunan nilai fitness yang disebabkan karena pengaruh input weight, bias dan bilangan random1, random2 yang diinisialisasi secara acak. Hal ini dikarenakan semakin banyak jumlah node yang digunakan maka semakin banyak penghubung (connector) yang terbentuk antara input layer dan output layer sehingga semakin banyak hasil yang dapat dihasilkan. Dari pengujian ini, didapatkan nilai rata-rata fitness tertinggi sebesar 83.89% dengan jumlah node sebanyak 20.
4.3 Pengujian dan Analisis Jumlah Data Training
Tujuan dari pengujian jumlah data training adalah untuk mengetahui pengaruh dari jumlah data training terhadap proses pelatihan serta nilai fitness yang dihasilkan. Terdapat 5 persentase perbandingan data yang akan digunakan pada pengujian ini, yaitu 80%:20%, 70%:20%, 60%:20%, 50%:20% dan 40%:20% untuk data training dan data testing dengan tujuan untuk mengetahui pengaruh dari jumlah data training terhadap jumlah data testing sebesar 20% dari keseluruhan data. Nilai parameter lain yang digunakan pada pengujian ini yaitu 20 partikel, 100 iterasi, bobot inersia 1, c1 dan c2 2, jumlah node pada hidden node 20.
Gambar 3. Grafik hasil pengujian jumlah data training
Berdasarkan Gambar 3, hasil pengujian jumlah data training menunjukkan bahwa semakin besar jarak antara jumlah data training dan jumlah data testing maka semakin besar pula
rata-rata nilai fitness yang dihasilkan. Hal tersebut dibuktikan dengan perolehan nilai fitness tertinggi oleh data training terbesar yaitu 72 data dan data testing 18 data. Hal ini dikarenakan metode ELM merupakan metode pelatihan, sehingga semakin banyak data training yang digunakan maka banyak data yang dapat dilatih dan dikenali pada proses pelatihan sehingga mempunyai banyak pertimbangan keputusan untuk menghasilkan klasifikasi yang baik. Dari pengujian yang telah dilakukan, didapatkan rata-rata nilai fitness tertinggi sebesar 83.89%.
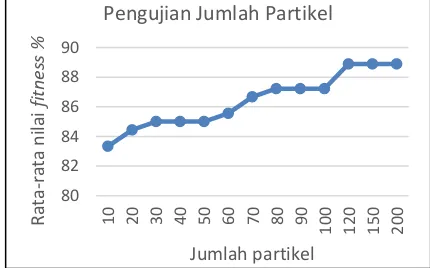
4.4 Pengujian dan Analisis Jumlah Partikel
Tujuan dari pengujian jumlah partikel adalah untuk mengetahui besarnya ukuran populasi partikel yang paling optimal untuk menghasilkan solusi dan nilai fitness yang terbaik. Besarnya jumlah partikel yang akan diuji adalah kelipatan 10 mulai dari 10 sampai 100, 120, 150 dan 200 partikel. Nilai parameter lain yang digunakan pada pengujian ini yaitu 100 iterasi, bobot inersia 1, c1 dan c2 2, jumlah node pada hidden node 20, banyaknya data training dan testing 80%:20%.
Gambar 4. Grafik hasil pengujian jumlah partikel
Berdasarkan Gambar 4, hasil pengujian jumlah partikel menunjukkan bahwa semakin banyak jumlah partikel yang digunakan maka semakin besar pula rata-rata nilai fitness yang dihasilkan. Hal tersebut dikarenakan besarnya populasi partikel mampu meningkatkan kerja partikel dalam mencari solusi yang terbaik sehingga mampu menghasilkan variasi solusi yang beragam. Nilai fitness mengalami peningkatan dari jumlah pertikel 10 sampai 120 namun pada jumlah partikel 120 sampai 200 tidak mengalami peningkatan yang signifikan. Hal ini dikarenakan dengan populasi partikel yang besar mungkin proses pembangkitan 72
Perbandingan data training dan data
testing
Pengujian Jumlah Data Training 80
populasi awal memiliki variasi sebaran yang jauh dari solusi optimal (Hapsari, et al., 2015).
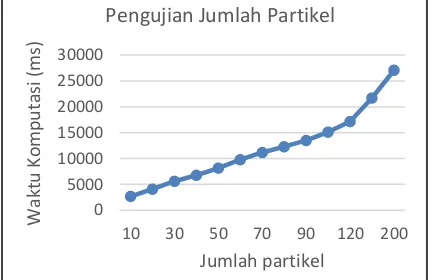
Selain itu semakin banyak jumlah partikel yang digunakan maka waktu komputasi yang dibutuhkan juga lama. Hal ini ditunjukkan pada Gambar 5 yang menunjukkan waktu komputasi yang dibutuhkan partikel. Oleh Karena itu, berdasarkan pengujian yang telah dilakukan, jumlah partikel yang baik dengan waktu komputasi yang efisien adalah 120 dengan rata-rata nilai fitness 88.89% dan waktu komputasi yang dibutuhkan 21708.8 ms.
Gambar 5. Grafik waktu komputasi pengujian jumlah partikel
4.5 Pengujian dan Analisis Maksimum Iterasi
Pengujian maksimum iterasi bertujuan untuk mengetahui hubungan antara jumlah iterasi terhadap nilai fitness. Besarnya jumlah iterasi yang digunakan pada pengujian ini adalah kelipatan 100 mulai dari 100 sampai 1000. Nilai parameter lain yang digunakan pada pengujian ini yaitu 120 partikel, bobot inersia 1, c1 dan c2 2, jumlah node pada hidden node 20, banyaknya data training dan testing 80%:20%.
Gambar 6. Grafik hasil pengujian maksimum iterasi
Berdasarkan Gambar 6, hasil pengujian maksimum iterasi menunjukkan bahwa semakin
banyak iterasi maka semakin besar pula rata-rata nilai fitness yang dihasilkan. Hal tersebut dikarenakan semakin banyak jumlah iterasi maka proses pencarian solusi lebih banyak dilakukan sampai mendapatkan solusi terbaik. Namun dengan banyaknya jumlah iterasi yang digunakan, perubahan posisi partikel menjadi tidak terlalu signifikan sehingga perubahan nilai fitness-nya pun juga tidak mengalami peningkatan yang signifikan. Hal ini mungkin dikarenakan dengan banyaknya jumlah partikel maka solusi yang dihasilkan hampir sama dengan jumlah iterasi lainnya atau mengalami konvergen, hal ini ditunjukkan pada Gambar 6. Pada gambar grafik tersebut, nilai fitness mengalami peningkatan dari jumlah maksimum iterasi 100 sampai 600 namun pada jumlah maksimum iterasi 600 sampai 1000 tidak mengalami peningkatan yang signifikan. Sama seperti pengujian jumlah partikel, semakin banyak jumlah maksimum iterasi yang digunakan maka waktu komputasi yang dibutuhkan juga lama. Hal ini ditunjukkan pada Gambar 7 yang menunjukkan waktu komputasi yang dibutuhkan partikel untuk setiap jumlah iterasi. Oleh Karena itu, berdasarkan pengujian yang telah dilakukan, jumlah maksimum iterasi yang baik dengan waktu komputasi yang efisien adalah 600 dengan rata-rata nilai fitness 90.56% dan waktu komputasi yang dibutuhkan 65454 ms.
Gambar 7. Grafik waktu komputasi pengujian maksimum iterasi
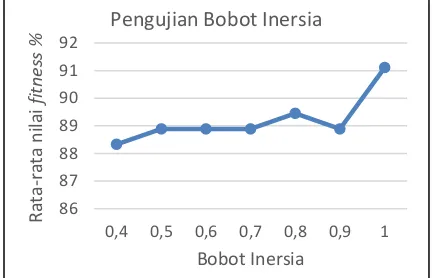
4.6 Pengujian dan Analisis Bobot Inersia
Pengujian bobot inersia bertujuan untuk mendapatkan bobot inersia yang paling optimal untuk mendapatkan nilai fitness terbaik. Bobot inersia yang akan digunakan pada pengujian ini antara 0,4 sampai 1. Nilai parameter lain yang digunakan pada pengujian ini yaitu 120 partikel, 0
100 200 300 400 500 600 700 800 900
600 iterasi, c1 dan c2 2, jumlah node pada hidden node 20, banyaknya data training dan testing 80%:20%.
Gambar 8. Grafik hasil pengujian bobot inersia
Berdasarkan Gambar 8, hasil pengujian bobot inersia menunjukkan bahwa variasi bobot inersia yang digunakan akan menghasilkan nilai rata-rata fitness yang berbeda. Berdasarkan pengujian ini, bobot inersia yang menghasilkan nilai fitness tertinggi adalah 1 yaitu mencapai 91.11%. Hal ini dikarenakan semakin besar nilai bobot inersia maka nilai kecepatan partikel yang dihasilkanpun menjadi besar sehingga kecepatan partikel tersebut menjadi lebih lambat diawal pencarian solusi yang menyebabkan parikel mempunyai kesempatan eksploitasi yang besar.
4.7 Analisis Global Hasil Pengujian
Berdasarkan hasil pengujian yang telah dilakukan didapatkan parameter-parameter yang optimal dengan nilai fitness terbaik. Pengujian pertama terkait pengaruh normalisasi data pada proses komputasi menunjukkan bahwa proses normalisasi sangat dibutuhkan pada penelitian ini untuk mendapatkan hasil yang baik. Pada pengujian jumlah node pada hidden node didapatkan node yang paling optimal dan menghasilkan nilai fitness tertinggi adalah 20 node dengan nilai fitness 83.89%. Pada pengujian jumlah data training didapatkan rata-rata nilai fitness tertinggi sebesar 83.89% dengan jumlah data training 72 data dan data testing 18 data. Pada pengujian ketiga dan keempat terkait pengaruh jumlah partikel dan maksimum iterasi didapatkan jumlah partikel dan maksimum iterasi yang paling optimal yaitu 120 partikel dan 600 iterasi dengan rata-rata nilai fitness 88.89% dan 90.56%. Pada pengujian terakhir yaitu pengujian bobot inersia didapatkan bobot inersia yang paling optimal yaitu 1 dengan nilai fitness 91.11%.
Dengan menggunakan semua parameter yang paling optimal dari hasil pengujian, didapatkan akurasi dari hasil klasifikasi sistem dan seleksi fitur menggunakan algoritme ELM dan PSO sebesar 94.44%. Sedangkan hasil akurasi sistem jika hanya menggunakan metode ELM tanpa seleksi fitur PSO hanya mencapai 66.67%. Hal ini menunjukkan bahwa metode seleksi fitur PSO mampu meningkatkan akurasi untuk permasalahan klasifikasi keminatan.
5. KESIMPULAN
Berdasarkan perancangan, implementasi dan hasil pengujian sistem Klasifikasi Keminatan Menggunakan Algoritme Extreme Learning Machine dan Particle Swarm Optimization Untuk Seleksi Fitur, maka didapatkan kesimpulan sebagai berikut:
1. Algoritme Extreme Learning Machine dan Particle Swarm Optimization dapat diimplementasikan pada permasalahan klasifikasi keminatan. Proses klasifikasi keminatan dilakukan dengan cara memasukkan nilai hasil studi mahasiswa dan membagi data tersebut menjadi data training dan data testing, melakukan klasifikasi menggunakan algoritme ELM, melakukan seleksi fiur dengan algoritme PSO untuk menghasilkan fitur-fitur yang relevan berdasarkan pola data yang digunakan sehingga mampu meningkatkan akurasi. Hasil fitness PSO didapatkan dari hasil akurasi klasifikasi ELM. Hasil fitness tertinggi dijadikan sebagai keputusan akhir untuk fitur dan hasil klasifikasi terbaik. 2. Proses seleksi fitur menggunakan PSO
partikel dengan hasil fitur yang paling optimal dengan nilai fitness tertinggi. 3. Berdasarkan pengujian yang telah
dilakukan, didapatkan parameter terbaik (optimal) dari hasil pengujian yaitu jumlah node 20, data training yang digunakan 72 data, data testing yang digunakan 18 data, jumlah partikel 120, maksimum iterasi 600 dan bobot inersia 1. Dari parameter tersebut didapatkan tingkat akurasi sebesar 94.44% dengan 11 fitur terpilih dari hasil seleksi fitur menggunakan algoritme ELM dan PSO. Sedangkan akurasi yang didapatkan dari algoritme ELM biasa hanya mencapai 66.67%. Dari hasil akurasi yang didapatkan, menunjukkan bahwa penambahan algoritme PSO pada ELM mampu meningkatkan akurasi algoritme ELM biasa.
DAFTAR PUSTAKA
Cholissodin, I., 2016. Model Analisisi Big Data-Semester Ganjil 2016-2017.
Siwi, I.P., Cholissodin, I. & Furqon, M,T., 2016. Peramalan Produksi Gula Pasir Menggunakan ELM pada PG Candi Baru Sidoarjo. S1. Universitas Brawijaya.
Pacifico, L.D.S. & Ludermir, T.B., 2013. Evolutionary Extreme Learning Machine Based on Particle Swarm Optimization and Clustering Strategies. Federal University of Pernambuco.
Prakoso, E.C., Wisesty, U.N. & Jondri., 2016. Klasifikasi Keadaan Mata Berdasarkan Sinyal EEG Menggunakan Extreme Learning Machines. Journal On Computing, pp.97-116.
Shahsavari, M.K., Bakhsh, H.R. & Rashidi, H., 2016. Efficient Classification of
Parkinson’s Disease Using Extreme
Learning Machine and Hybrid Particle Swarm Optimization. 2016 4th International Conference on Control, Instrumentation, and Automation (ICCIA). Qazvin Islamic Azad University. Qazvin, Iran, 27-28 january 2016.
Yu, L. & Liu, H., 2003. Feature Selection for High – Dimensional Data : A Fast Correlation – Based Filter Solution. Proceedings of the Twentieth International Conference on Machine Learning. Preceeding of the Twentieth
International Conference on Machine Learning (ICML-2003). Washington DC, 2003.
Azizah, A.N., Santoso, E. & Cholissodin, I., 2016. Penentuan Kualitas Air Sungai Menggunakan Metode Extreme Learning Machine. S1. Universitas Brawijaya.
Huang, G.B., Zhu, Q.Y. & Siew, C.K., 2006. Extreme Learning Machine: Theory and Applications. Neuron Computing, pp.489-501. Nanyang Technological University. Singapore.
Muhamad, H., Cahyo, A.P., Sugianto, N.A., Surtiningsih, L., 2016. Optimasi Naïve Bayes Classifier Dengan Menggunakan Pasrticle Swarm Optimization Pada Data Iris. Jurnal Teknologi Informasi dan Ilmu Komputer. Universitas Brawijaya.