2
Partial Fulfillment of the Requirements for the Degree of
Systems Engineering Specialization Degree, Honors, University of Lima, 1977
M.Sc. Computer Science, U.S.A. Naval Postgraduate School, 1979 M.Sc. Computer Systems Management U.S.A. Naval Postgraduate
4
COPYRIGHT @ 1989
Francisco J. Mariategui
All Rights Reserved
M.Sc. Computer Systems Management, U.S. Naval Postgraduate School, 1979
6
combining different concurrency control approaches has been recognized but never thoroughly investigated.
A high level design of a Multi-‐Group Multi-‐Layer approach to concurrency control for object-‐oriented message-‐passing based databases is presented. The design follows a formal definition of transaction. The concurrency control takes advantage of the
structured nature of transactions to manage an on-‐line serializer. The serializer is specified as a set of filters. These filters are specifications of algorithms that ensure serializable histories. The concurrency control manages these histories by layers. Each layer, along with its corresponding filters, constitutes a different level of abstraction in concurrency control processing. Mutually exclusive groups of transactions being processed in parallel are assumed. The availability of a processor per group is also assumed. The performance is
improved when this case of large granularity and limited interaction is applied. The decomposition of the histories into layers allows the problem to be more manageable, the principles of hierarchical design to be applied, and the benefits of hierarchical thought to be utilized.
7
1) First cut definition of an Object-‐Oriented Data Model (OODM) which encompasses data structures, operations, and integrity constraints.
2) Transaction processing model for the OODM environment, which facilitates not only definition of transactions but also, allows investigation of concurrency control.
3) Multi-‐group Multi-‐Layer concurrency control technique built on the OODM and transaction models that allow the use of several different concurrency control techniques in parallel in the same environment.
12
CHAPTER 8 -‐ CONCLUSIONS AND FURTHER RESEARCH
249
8.1 CONCLUSIONS
249
8.1.1
S
UMMARY OFA
CCOMPLISHMENTS249
8.1.2
R
ESULTS BYS
TAGES250
8.2 SUGGESTIONS FOR FURTHER WORK
255
8.2.1
S
IMULATION255
8.2.2
C
OMMITTED BUTN
OTD
ELETEDT
RANSACTIONS257
8.2.3
L
IBRARIES OFT
YPEDO
BJECTS259
8.2.4
C
ONFLICTP
REDICATES260
8.2.5
E
ARLYE
VALUATION OFI
NTER-‐G
ROUPC
ONFLICTS261
8.2.6
I
NCREASE THEN
UMBER OFP
ROCESSORS262
8.2.7
P
IPELINE THEC
YCLEA
LGORITHM263
8.2.8
R
OUTERI
SSUES264
REFERENCES
267
14
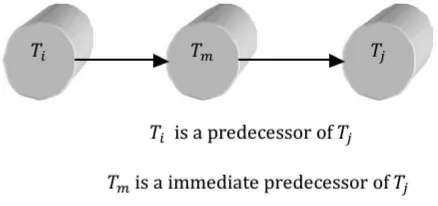
6-‐9 Tight Predecessors
6-‐10 Necessary and Sufficient Condition to Remove a Transaction 6-‐11 Steps of the History Hierarchy Cycle Algorithm
7-‐1 Work Done with Traditional Approach
7-‐2 Work Done with Partitioning & Parallel Execution
15
ACKNOWLEDGEMENTS
This dissertation is dedicated to my parents, Carmela and Francisco Mariategui, as a small tribute of my admiration and love.
Special and most sincere thanks to my advisor, Maggie Eich, for things too numerous to list here.
Also, I thank Dennis Frailey, Milan Milenkovic, Marion Sobol, and David Yun, for their careful reading of the dissertation, and their helpful comments.
I gratefully acknowledge the Fulbright Commission of Peru, the National Science Foundation, and the Texas Advanced Research
16
CHAPTER 1
-‐
INTRODUCTION
1.1 The Problem
In the last few years, a number of self-‐named object-‐oriented database systems have appeared in the literature, most of which addresses specific areas such as office information systems (OIS), computer aided design (CAD), computer aided manufacturing (CAM), software engineering (SE), and artificial intelligence (AI). Unfortunately hardly any one of them addresses the problem of concurrency control from the general-‐purpose database point of view. These specialized databases are not general database management systems (DBMS) in the sense that they are just applications; they are specific applications with their own file system.
17
consistency, a transaction must see the values of all the objects either before or after other transactions have updated them.
This work is aimed at an encompassing solution to concurrency control for databases in general, and object-‐oriented databases in particular. An approach to a solution can be accomplished by focusing our efforts in Structured Concurrency Control, which provides flexibility and adaptability. This methodology allows object-‐oriented databases to accomplish an efficient concurrency level with a tolerable amount of overhead, even in the presence of a variety of transactions, each one with its own requirements (short lived, long lived, etc.). Such a methodology will be developed in the framework of object-‐oriented databases, which, in theory, are capable of handling a variety of environments.
18
different technique should be chosen, it does show how to combine them in the framework of an original design.
1.2 The Approach
The concurrency controller is a key module within any DBMS, it encompasses most of the activities of the other modules in a DBMS in the sense that they must "obtain permission to continue" in order to perform their own tasks.
To be able to cope with the new demands of the newer applications (OIS, CAD, CAM, SE, Al, etc.), the concurrency controller should no longer be "single-‐minded" (e.g., one concurrency control technique only). The different types of applications impose different demands on the DBMS, and thus affect the concurrency control.
19
activity, and in others perhaps combining the use of several techniques together. Different transactions may use different techniques. It is also possible that different executions of the same transaction may use different techniques. This approach must be able to ensure correctness across all the different techniques being used. In order to accomplish success in this endeavor, the new flexible concurrency controller must be able to keep track of the states of the database as indicated by the type of transactions active at any point in time.
1.3 Contribution
This research has led to the following results:
1) First cut definition of an Object-‐Oriented Data Model (OODM) which encompasses data structures, operations, and integrity constraints. 2) Transaction Processing model for the OODM environment which facilitates not only definition of transactions but also allows investigation of concurrency control.
20
The first two results are considered as supporting result number three. A special section is included in this introductory chapter to introduce the latter.
1.4 Significance
Due to the extreme differences in types of transactions to be executed in an object-‐oriented database (long lived and short lived), the need for combining different (concurrency control) approaches has been recognized but never totally investigated.
21
1.5 The Concurrency Control Manager
The goal in this dissertation is to describe and define an effective and flexible mechanism to control concurrency in object-‐oriented databases. In order to achieve this objective the theory has been created, the rationale has been discussed, the architecture has been specified, and the costs involved in a Concurrency Control Manager
Module (CCMM) have been analyzed. The models, algorithms, and
specifications used to this effect are the result of original research as well as adaptations of state of the art technology. The resulting CCMM is an algorithmic specification of the proposed approach that could be implemented in hardware (the hardware could take the form of a Concurrency Control Board). This dissertation is concerned with the presentation of the underlying technology to make the software CCMM possible.
1.5.1 Purpose
The purposes of the CCMM module are as follows:
• Reduce the overhead attributable to the concurrency controller. • Improve throughput (i.e., number of transactions per unit of
22
• Provide multiple concurrency control technique capability in parallel.
• Contribute to the ongoing research in Concurrency Control Management.
1.5.2 Concepts and Means
The concepts and means used to specify the CCMM are as follows:
• Conflict-‐graph based serializability. • Current concurrency control techniques. • Model of transactions in OODBs.
• Multi-‐layer approach to the treatment of histories. • Parallel processing technology.
1.5.3 Benefits
Summarizing, the potential benefits of the CCMM are as follows:
• Speed: throughput.
• Flexibility: several concurrency control techniques.
• Modularity: different environments may use different techniques.
23
1.5.4 Interface
The CCMM interfaces with transaction managers and data managers as shown in Figure 1-‐1. Transaction managers send requests to the CCMM, such as BEGIN, END, COMMIT, ABORT, LOCK, and UNLOCK. The CCMM informs the transaction manager about the state of execution of transactions. The CCMM sends requests to the data manager to perform database accesses on its behalf. This document is not concerned with the details of the protocols used to achieve proper interface among these modules. It is (mainly) concerned with the internal workings of the CCMM.
24
1.6 General Overview of the CCMM
25
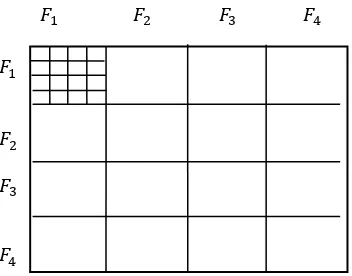
The first novelty in the approach is that the CCMM manages several forests (or groups) of transactions in parallel. In Figure 1-‐2, four forests are shown. These four forests are 𝐹!, 𝐹!, 𝐹! y 𝐹!. This fact is
26
27
partitioning is done for 𝑙𝑒𝑣𝑒𝑙!, 𝑙𝑒𝑣𝑒𝑙
!, and 𝑙𝑒𝑣𝑒𝑙!. This is due to the
fact that the synchronization between groups is done at the upper level, that is, 𝑙𝑒𝑣𝑒𝑙!.
28
is only when the forests meet at the highest level of the hierarchy that they must follow, as a group, the Group Concurrency Control technique.
1.7 Outline of the Dissertation
This dissertation is structured as follows. Chapter 2 provides an initial first cut definition for an Object-‐Oriented Data Model (OODM). An overview of the state of the art in object-‐oriented databases is provided, terms are defined and basic properties of OODBs are identified and described. The importance of describing an OODM lies in the fact that it gives a formal framework on which later concepts, introduced in this work, are presented.
In Chapter 3 a new model of transactions in object-‐oriented databases is proposed. The model captures the structure (a transaction tree) as well as the dynamics of an execution or progress of a transaction. The definition is dynamic, in the sense that it captures the progress that a transaction makes over time. It is shown how messages, that are the means by which objects communicate, correspond to accesses to the database.
29
serializability are expanded and adapted (respectively) to the model of transactions. Serializability is the correctness criterion applied to concurrency control algorithms.
In Chapter 5, the rationale for undertaking the Multi-‐Group Multi-‐ Layer approach to concurrency control is explained. Also, the theory of execution defined in the previous chapter is expanded to include groups of forests of transactions instead of having only one forest. Each forest contains a group of transactions that is driven by a specific concurrency control technique.
The content of Chapter 6 is synthesized in section "General Overview of the CCMM" in this chapter.
In Chapter 7 an analysis of the approach from the time and space points of view is presented. It is shown that the group partitioning technique combined with the hierarchy of histories technique yields an expected behavior, which is no worse than a pure conflict-‐based serializable scheduler. It is also shown that the Multi-‐Group Multi-‐ Layer approach to concurrency is feasible and flexible. Although the overall time complexity is still in O(𝑛!q), the problem to be solved is
smaller.
30
CHAPTER 2
-‐
AN OBJECT
-‐
ORIENTED DATA
MODEL
2.1 Introduction
An Object-‐Oriented Database (OODB) is one that captures the
behavior as well as the structure of part of the real world with no (theoretic) limit as far as its extensibility is concerned. The development of the OODB concept is in a similar stage as the transition of powerful (by the standards of that time) file systems to database systems was in the late sixties. It can be distinguished very clearly several particular topics highlighting current problems in the OODB development process:
• There is little consensus about what the Object-‐Oriented Data
Model (OODM) is.
31
• There are differences in the definitions of background information (let alone the differences in the semantics of the underlying technology, namely the so called Object-‐Oriented Programming
Languages).
• Many of the papers published in the current OODM research literature ignore vital issues such as concurrency control, security, integrity, and recovery, which have been extensively researched and developed in connection with conventional database models and operating systems.
• Only a few authors mention the manipulation language aspect of the OODB, even though it should be considered as a constituent aspect of any database model, not only with regard to its power (or lack of it) but because any database will be of little use without one. A more important question about the manipulation language is whether it is powerful enough to exploit all the properties that an OODB should possess. For example, it must be able to support extensibility of data and processes.
32
There is no need to go on; the point should be well understood. OODBs represent the birth of a new, very powerful method of handling views of the world in a computer system. This may be one, which is in fact the glue, which researchers have been seeking to help make a smooth and efficient transition to the information era. The objective of this chapter is to provide an initial first cut definition for an Object-‐Oriented Data Model (OODM). This chapter is organized as follows: Section 2 provides an overview of the state of the art in object-‐oriented databases, terms are defined and basic properties of OODBs are identified and described. Section 3 describes the major portions that a data model should consider in its definition. Section 4 describes the OODM in detail. Section 5 comments briefly about the expressive power of the proposed model. Finally, Section 6 summarizes the chapter.
2.2 Object-‐Oriented Databases: An Overview
33
FLAVORS [Weinreb, 1981], and others. Ideas such as Objects, Classes, Methods, Inheritance, and Messages (to be introduced below) prompted researchers to experiment with a new kind of database system, namely the OODB.
The purpose of this section is to describe the properties of an OODB. Since there is yet no standardized model to refer to, an incremental approach in describing the understanding of these and other related concepts has been used.
2.2.1 Background
34
The term Object as well as most of the other terms used in the Object-‐
Oriented Paradigm have different meanings for different authors in
different areas. Therefore, in the discussion that follows, the common aspects of the different concepts involved in the definition of an Object-‐Oriented Database have been factored out. It appears that all definitions for an Object-‐Oriented Database System have certain properties in common [Lochovsky, 1985], and these are:
• Abstraction of data, • Inheritance of properties, • Persistence of data,
• Encapsulation of data and operations, • Automatic triggering of operations, and • Extensibility of data types.
35
2.2.2 Definition of Terms
In lieu of the differences in terminology in the literature used to define basic concepts within the object-‐oriented paradigm, it is a good idea to avoid semantic traps by making certain where each one stands when using basic concepts to define more complex ideas. Therefore, what follows is a succinct description of the most important terms:
• Objects: Entities and concepts from the application domain being
modeled. They are unique entities in the database, with their own identity and existence, and they can be referred to. Objects consist of an external and an internal portion. They are referenced by the external portion only, that is, its public interface. The internal portion is the actual storage contents.
• Messages: Used to describe or affect the behavior of an object.
36
• Methods: Procedures, written in some programming language,
used to implement messages.
• Instance Variables: The private storage of an object is divided
into units called instance variables. Each object assigns specific values to these instance variables.
• Data Type: A collection of operators, called the protocol, for
operating on a particular set of instance variables.
• Class: The encapsulation mechanism used to identify behavior
(methods) and structure (instance variables) for a group of objects. The set of objects following a prescribed structure is often viewed as a class. A class is not specifically an object, but can alternatively be thought of as the template, which all instances (objects) of that grouping must follow, or as the set of instances themselves.
• Object Class: When the class must be acted on with methods to
create, delete, or modify existing classes, the classes are then treated explicitly as objects and are called object classes.
• Instances: All members of a class are said to be instances of that
class.
• Class Hierarchy: A structured view of classes, which is organized
37
the relationship between classes. Classes preceding a given class are called super classes while those following it in the graph are called subclasses. The specific methods and instance variables of a class are directly affected by its super classes. This concept is called inheritance. A class automatically takes on or inherits the methods and instance variables of each of its predecessors. Classes may also add additional instance variables and methods as needed, or indicate that different code is to be used for some methods. This last idea is called overloading. The hierarchy is in
actuality a directed graph. Thus, a class can potentially have several conflicting super classes. In that case the methods and instance variables to be inherited must be defined based upon some conflict resolution technique.
38
2.2.3 Definition of Properties of OODBs
The six definitions of the OODB properties introduced above follow:
Data Abstraction:
This concept is related to the concept of messages, in the sense that message sending supports the implementation of data abstraction. The principle is that calling programs should not make any assumptions about either the implementation or the internal representation of the data types that they use. In this way it is possible to make changes to the implementation without the need to change the calling programs. "A data type is implemented by choosing a representation for values and by writing a method for each operation allowed. Data abstraction is supported if there exists a mechanism for bundling together all of the methods for the data type" [Stefik, 1986].
Inheritance of Properties:
A class may inherit methods from super classes and may have its methods inherited by subclasses. Inheritance from a single superclass
39
the economy of expression that results when a class shares descriptions with its super class. Multiple inheritance increases shar-‐ ing by making it possible to combine descriptions from several classes [Stefik, 1986].
Persistence of Data:
“When objects persist beyond the execution of a program, as in the case of library objects and database objects, one has the capability of manipulating objects without being aware of the distinction between internal storage and external storage” [Cockshot, 1984]. Any data structure built can be automatically transferred to external storage at the end of a program and brought back the next time the data is used by the program. This enables the abstraction from the physical properties of disk and other external stores, the same as the already used abstraction from the physical properties of RAM. This allows the view of both with a uniform set of conceptual abstractions. Thus, a uniform view of the entire store is available to the user.
Encapsulation of Data and Operations:
40
an interface part, which is public, and of an implementation part, which is kept private [Zaniolo, 1986]. The data of the object, that is, its private storage, is structured as a list of named or numbered instance variables. The fact that the data and the methods of an object cannot be referenced directly by other objects, but only through its public interface, and the fact that no other methods are allowed, is called
encapsulation. This is a concept similar to that of Monitors introduced
in the mid sixties in the field of computer operating systems as an aid to solve the problems encountered when programs were executing concurrently within a computer system [Peterson, 1985].
Automatic Triggering of Operations:
Methods are not activated due to direct procedure calls but rather due to the fact that an object receives a message. The message indicates the method to be performed but does not specifically indicate the code to use. Due to the possibility of overloading of methods, the exact determination of code to use can only be determined at execution time. This late binding of message to code can be compared to an indirect procedure call and is often called
triggering [Croft, 1985]. Also, one method could trigger other
41
Extensibility of Data Types:
This is perhaps one of the most important reasons for researchers to pursue the conceptualization and formalization of OODBs. It refers to the capability of adding new data types to a database and being able to handle it with a very smooth process of adaptation. It is a gateway to adding new concepts to the current view of the world stored in the database. Exotic and unexpected (by current standards) data types could be added with minimum disruption on the operation of the data bank. For example, a database should be able to handle such concepts as voice, graphics, images, text, records, sound, and taste. As of today, there is no known way to handle all these different kinds of data within a single database system. OODBs have the potential to do it.
2.3 Data Models
42
definition of an OODB. On the other hand, the concepts and capabilities of the RDB approach are well known and a Relational Data Model (RDM) standardizing the RDB exists [Codd, 1982].
The characteristics and precise requirements of a database approach are identified by defining the corresponding data model. As defined by Codd ([Codd, 1981], [Codd, 1982]), a data model consists of three components:
1) Data Structure,
2) Operators or Rules of Inference, and 3) Integrity Rules.
43
corresponding database approach. It also guarantees consistency in terminology and requirements among database researchers and implementors. The relational database approach grew out of mathematical theory and formalisms. As a result, the precise definition of a RDM was easily defined. However, the OODB approach came out of the programming languages and operating systems communities.
There are not many formalisms or theory providing a common basis for communication and understanding. Indeed, there are probably as many definitions of the OODB concept as there are people interested in it. To guarantee the proper development of the OODB paradigm, to facilitate discussions and understanding, and to provide some degree of consistency among OODB implementations, an Object-‐Oriented Data Model definition is crucial.
44
2.4 An Object-‐Oriented Data Model
45
OODM. What is needed is the ability to create these if and when needed.
What, then, is required as part of the OODM definition? It should provide a minimum definition of each of the three portions of the data model concept. The model thus created must be flexible enough to ensure extensibility and abstraction of data. The model does not need to include all operations and data types ever needed by any OODB. As a matter of fact, it should not really include any. It is to provide the basic facilities needed to create any data types or operators. Whether the data is viewed as simple data types (integer, real, etc.) or as created in some manner from existing types (sets, lists, relations, etc.), the OODM definition must be able to define any data types. Similarly for any required methods. The only needed operators are those to create/modify/delete object-‐classes and instances of classes.
2.4.1 Data Structure
The basic building block in the OODM is (obviously) an object, which is defined below:
46
An object is an ordered pair <𝐼, 𝑀> of sets 𝐼 and 𝑀 respectively called
Instance Variables and Methods. Instance variables describe the state
of an object while methods are pieces of code used to activate an object in some specific way. Each method has an external name
unique within the object used to identify the code. There are four types of objects:
Object Class:
In an object class, <𝐼!, 𝑀c>, each 𝑖 ε 𝐼! identifies a domain of possible values, 𝑑𝑜𝑚(𝑖), while each 𝑚 ε 𝑀c identifies a specific piece of code which may act on one or more of these values. The state of an object class is simply the collection of labels for the instance variables rather than the values from the domains.
Complex Object:
Each complex object, <𝐼! ,𝑀!>, is uniquely associated with an object class, <𝐼!,𝑀𝑐> where 𝑀! = 𝑀c and there is a one-‐to-‐one and onto mapping, 𝑓, 𝐼! to 𝐼! such that for all 𝑖 ε 𝐼! , 𝑓(𝑖) ε 𝑑𝑜𝑚(𝑖). There are no restrictions placed on the domains for these instance variables.
Simple Object:
47
values (integers, strings) and exists as an instance variable within a complex object.
Message:
A message, <𝐼! , Ф >, has no methods. The only operations allowed to act on a message are those specifically identified in the next section. Each message contains at least four instance variables: identification of sending object, identification of receiving object, data sent, and external name of method.
All objects, which are associated with the same object class, are grouped into a class, and the objects from this grouping are called
Instances of the Class. The domains of instance variables may be
extremely complex in that they themselves may contain objects (simple or complex) and operations on objects. In this manner, domains such as visual objects, sets, lists, etc. are allowed.
The structure portion of the OODM is defined using an Object Graph.
48
49
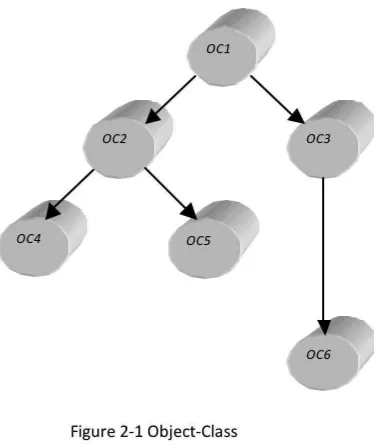
object classes and complex objects are shown as dashed lines). A total of seven complex objects are shown in this figure.
50
51
some function acting on another object class. The object graph does not show the function involved, but it would be needed to be included as one of the methods in the object class. This composition level of
52
All communication between objects is through messages. Each message is only aware of the external method names and not the internal portion of the object (instance variables and procedures). Therefore, the instance variables associated with a message must indicate the object to which the message is to be sent, the external name of the method within the object to be activated, and any parameters to be passed to the method. It is crucial to stress that this data is passed in the form of arguments and is not directly related to the instance variables of the object. These are hidden from external view. The external portion of the object, include the interface (protocol), to be used by messages for the methods in the object. Messages are shown in an object graph using the concept of hyper arcs. A hyper arc defines an ordered set of edges. In this case, a message can be shown as a fourth type of node in the object graph and its association to other nodes using a hyper arc relating the sending object, receiving object, and message nodes in the graph. This is shown in Figure 2-‐4. Message 𝑀1 is sent from 𝑂𝐶4 𝑡o 𝑂𝐶6.
53
shows the processing involved in the OODB system. Since all processing is performed using messages, the dynamic part shows the sending of messages between objects and thus captures all database processing.
54
Classes may be related based upon common instance variables and/or methods. These relationships are described based upon the use of a
Directed Acyclic Graph (DAG) called a Class Hierarchy.
Definition 2.2:
The Class Hierarchy is a DAG, <𝑉, 𝐴>, where the vertices, 𝑉, represent
classes and the arcs, 𝐴, ordered pairs of vertices. For all arcs < 𝑉! , 𝑉! > in the DAG, where 𝑉! , 𝑉! ε 𝑉 the following apply:
1) 𝑉! is a superclass of 𝑉!.
2) 𝑉! is a subclass of 𝑉!.
3) 𝑉! inherits all the instance variables and methods from 𝑉!. Let
< 𝐼!, 𝑀! > be the object class for 𝑉! and < 𝐼!, 𝑀! > be the object class for 𝑉!. This means that 𝐼!⊂𝐼! and for all 𝑚! ε
𝑀! there is an 𝑚! ε 𝑀! such that both 𝑚! and 𝑚! have the same external name. There may indeed be some 𝑚! ε 𝑀!,
which are not in 𝑀!.
4) 𝑉! is a generalization of 𝑉!.
55
The third restriction above indicates that a subclass must contain those instance variables found in any superclass, and also contain the same external names as all the methods in any of its super classes. A subclass may contain more instance variables and methods. Notice that only the external names of subclass methods must equal the external names of superclass methods. The actual code of the methods may vary. This is included to guarantee the ability of overloading.
56
57
2.4.2 Operators
The operators defined below are to be considered as a minimum set of operators for an OODM. These operators are given in terms of the structure of the OODM described above. Prior to specifically identifying the operations, what the operations must do is described:
Nodes in the DAG (Classes) 1) Insert a new class. 2) Delete an existing class. 3) Modify an existing class.
Paths (Inheritance) in the DAG
1) Insert a class Vi as a super class of class Vj. 2) Delete a class Vi from the super classes of Vj. 3) Modify the ordering of the edges in the DAG.
Instance Variables
1) Insert an instance variable to a class. 2) Delete an instance variable from a class.
3) Modify an instance variable (name, default value, inheritance, etc.).
58
1) Insert a new method to a class. 2) Delete an existing method from a class.
3) Modify a method (name, code, inheritance, etc.).
Messages
1) Send a message to an object. 2) Respond to a message.
3) Trigger the appropriate method to execute the act on the object in response to a message.
To facilitate all of the above actions, only four types of operations are allowed: Create, Delete, Modify, and Trigger. Each operation must be performed on an object. No exact format or structure of these operations is given, instead the allowed combinations of operations and objects is indicated:
CREATE
Object Class:
59
placed in the hierarchy and indicate conflict resolution and method overloading, where needed. Initially the associated class is empty.
Simple Object:
Create a simple object by indicating the methods.
Complex Object:
Create a complex object by providing values for the instance variables defined in the associated object class. This operation must identify the corresponding object class as it is creating an instance of the associated class.
Message:
Create a message to be sent to another object. This is performed by indicating values for the required instance variables. Inserting a message actually results in having the message sent to the receiving object.
DELETE
Object Class:
60
Simple Object:
Remove object.
Complex Object:
Delete object from class. The associated class still exists.
Message:
Remove message as an object automatically performed by a Trigger.
MODIFY
Object Class:
Change the definition of the object class by modifying the sets 𝐼! or 𝑀!. Note that this operation creates modify operations on each of the objects in the associated class.
Simple Object:
Change definition of the methods.
61
Change values for instance variables. No direct modification of the basic structure is allowed unless created by an object class modify.
TRIGGER
Object Class or Simple or Complex Object:
Upon receipt of a message by either, an object class, simple object, or complex object, this operation is invoked. Its only purpose is to validate the message and to invoke the correct method indicated by the external name of the method in the message. Identification of correct method may require examination of the class hierarchy to examine methods in super classes. The Trigger operation deletes the message and always replies to the message by creating a
62
2.4.3 Integrity Rules
The collection of general integrity rules as the third constituent part of an OODM can be subdivided in several groups as described below:
Identity and Referential Integrity
1) For any object in a database, there must exist a corresponding and unique Object Identifier (𝑂𝐼𝐷).
2) This 𝑂𝐼𝐷 must span the lifetime of the database. That is, no two objects may be assigned the same 𝑂𝐼𝐷 for any reason at any time.
3) All references to objects, including sending of messages is by the 𝑂𝐼𝐷. Messages must contain valid sending and receiving 𝑂𝐼𝐷s.
4) All objects exist alive forever until explicitly deleted.
5) The memory space is one and only one. That is, there is no recognition of a Memory Hierarchy. The only mechanism to recognize an object is its 𝑂𝐼𝐷.
63
Second, no object can reference another object without first knowing its OID. The third rule guarantees referential integrity. The last two rules ensure the persistence of objects.
Data Abstraction
1) The communication between objects is through messages. 2) All messages interface through the public part of the objects. 3) The contents of an object is (assumed) not to be known by
the message.
4) A method may only act on its own object.
These rules support the data abstraction concept of the Object-‐ Oriented Paradigm, that is, no assumption is to be made about "what" is contained in an object, variables or methods.
Encapsulation of Data and Operations
The only valid methods performed on an object are those specifically identified in the object or listed in the set of OODM operations.
2.4.4 Summary
64
Data Structure:
• Object (object class, simple, complex, message). • Class Hierarchy (inheritance).
Operations:
• Create (object class, simple, complex, message). • Delete (object class, simple, complex, message). • Modify (object class, simple, complex).
• Trigger (object class, simple, complex).
Integrity Rules:
• OID.
• Data Abstraction.
• Encapsulation.
65
operation, while extensibility follows from the other operations included in the OODM definition.
2.5 Modeling Ability of the OODM
The usual way in which people deal with complexity is by abstraction. Three abstractions used very frequently [Ontologic, 1986] are:
• an-‐instance-‐of (AIR),
• a-‐kind-‐of (AKO), and
• a-‐part-‐of (APO).
66
knowledge of the potential database entities considerably simplifying the model. It is interesting to note that the model captures these abstractions in a very natural way.
The an-‐instance-‐of abstraction is captured by the notion of instances of classes. This abstraction is represented by the relation between an object class and a complex object in the model (the dashed lines in the object graphs depicted in the data structure portion of the model). The a-‐kind-‐of abstraction is captured by the powerful notion of inheritance. If a car is a-‐kind-‐of vehicle, then it inherits all of the variables and methods defined in vehicle. This works because an object which is an instance of a lower-‐level class (in this case a car) is also an instance of each class which is a superclass of its most immediate class (e.g., car, vehicle, entity). This abstraction is represented by the relation between object classes in the model (the solid lines in the object graph).
67
hierarchy (or lattice) is a basic characteristic of this feature. In the model, this abstraction is represented by a combination of solid lines and composition, that is, the dotted lines.
2.6 Summary
The significance of the definition of an Object-‐Oriented Data Model (OODM) can be summarized by the following arguments:
• The OODM places no restrictions on the external view of data or operations.
• Any data view (hierarchical, network, relational, etc.) may be created as needed.
• No specific operations such as those found in the relational algebra exist. Instead, any needed operations (methods) can be created as needed.
• There is no restriction on the type of data to be used. Simple and complex instance variables are treated the same.
68
• The message-‐passing paradigm provides a uniform mechanism of communication among objects.
An object-‐oriented environment is the most appropriate for current data models, such as the relational, network, and hierarchical, as well as the models of the near future. It encompasses all of them. The message-‐passing paradigm provides the tool needed to formulate a new and appropriate model for transactions in object-‐oriented databases. This new model is the topic of Chapters 3 and 4. Also, it is very important to develop concurrency control techniques for this model because of its variety of types and size of applications. From the general-‐purpose database point of view, it seems very appropriate to develop dynamic and adaptable synchronization techniques that will react appropriately to different external stimuli, such as types of transactions, size of transactions, duration of transactions, and other parameters that could affect the performance and effectiveness of
69
CHAPTER 3 -‐ UNIT OF CONSISTENCY
3.1 Introduction
The objective in this chapter is to intuitively and formally describe the notion of Unit of Consistency (transaction) in an object-‐oriented database environment. In order to accomplish this goal a sequence of informal examples followed by their appropriate formalism is given. In order to maintain the generality of the definitions, concurrency aspects within or between transactions are not mentioned. Also, no use is made of any particular concurrency control technique to define the structure and characteristics of transactions. These topics are described in subsequent chapters of this document.
70
3.2 Preliminaries
In the previous chapter it was shown that all interactions among objects are via messages. The public interface of each object lists the methods available for execution in each object. A message can be viewed as a command to activate a specific method within the object to which the message is sent, i.e., object 𝐴 sends a message to object 𝐵 to activate (object 𝐵’s) method 𝑋. Method 𝑋 is part of the public interface (protocol) of object 𝐵. Object 𝐴 knows that method 𝑋 is available in object 𝐵 because object 𝐴 sees the public interface of object 𝐵.
For example, the following illustrates (in a very informal manner) the point described above:
Suppose there are objects 𝐴 and 𝐵
object 𝐴 whose protocol is (𝑃,𝑄,𝑅) object 𝐵 whose protocol is (𝑋,𝑌,𝑍)
A valid message would be