PADA DATA INDEKS PEMBANGUNAN MANUSIA (IPM) DI INDONESIA
Kornelius Ronald Demu, Dewi Retno Sari Saputro, Purnami Widyaningsih Program Studi Matematika FMIPA UNS
Abstrak. Standar ukur pembangunan manusia di suatu negara ditetapkan dalam Indeks Pembangunan Manusia (IPM). Beberapa faktor diduga memengaruhi IPM di Indonesia, yaitu angka harapan hidup, PDRB, jumlah penduduk miskin, dan persentase penduduk buta huruf. Pengaruh faktor-faktor tersebut terhadap IPM di Indonesia dapat diketahui melalui model regresi. Apabila data IPM dan faktor-faktor tersebut diplotkan maka me-nunjukkan pola data yang bersifat tidak mengikuti pola tertentu, sehingga data IPM di Indonesia dapat diterapkan pada model regresi nonparametrik spline truncated. Model regresi nonparametrikspline truncated terbaik dipengaruhi oleh pemilihan orde dan titik
knotoptimal. Dalam artikel ini diterapkan model regresi nonparametrikspline truncated
orde satu dengan 3,4, dan 5 titikknot pada data IPM di Indonesia. Berdasarkan pene-litian, diperoleh kombinasi titikknot optimal 5-5-5-4 dengan angka harapan hidup dan persentase penduduk buta huruf yang memengaruhi IPM di Indonesia.
Kata Kunci: IPM, model regresi nonparametrik, spline truncated, titik knot optimal. 1. Pendahuluan
Indeks Pembangunan Manusia (IPM) merupakan standar ukur pembangunan
manusia di suatu negara dengan mempertimbangkan aspek kesehatan, pendidikan,
dan kelayakan hidup. Dalam beberapa tahun terakhir, IPM di Indonesia
menun-jukkan peningkatan. Berdasarkan data BPS [2], pada tahun 2013, IPM di Indonesia
68.1%, kemudian dalam kurun waktu dua tahun berturut-turut meningkat menjadi
68.4% dan 68.6%. Faktor-faktor yang diduga memengaruhi IPM yaitu, angka
ha-rapan hidup, produk domestik regional bruto (PDRB), jumlah penduduk miskin,
dan persentase penduduk buta huruf (UNDP [9]). Pengaruh faktor-faktor
terse-but terhadap IPM dapat diketahui melalui model regresi. Apabila data IPM dan
faktor-faktor tersebut diplotkan, maka menunjukkan pola data yang bersifat tidak
mengikuti pola tertentu. Pendekatan model regresi yang digunakan pada pola data
tersebut adalah model regresi nonparametrik (Eubank [5]).
Menurut Hardle [7], metode yang dapat digunakan pada model regresi
non-parametrik yaitu spline. Metode spline memiliki fleksibilitas dalam mengatasi pola
data yang bersifat tidak mengikuti pola tertentu. Spline merupakan potongan
fung-si polinomial yang memiliki fung-sifat tersegmen. Spline truncated merupakan modifikasi
fungsi spline. Metode spline truncated dilakukan menggunakan titik knot
(Budi-antara [3]). Titik knot merupakan titik terjadinya perubahan perilaku pola data
diperoleh berdasarkan titikknot optimal (Budiantara [3]). Titik knot optimal
dipe-roleh berdasarkan nilai generalized cross validation (GCV) minimum (Wahba [10]).
Menurut Lee [8], estimasi parameter model regresi nonparametrik spline truncated
menggunakan metode kuadrat terkecil (MKT). Penelitian ini bertujuan untuk
me-nerapkan model regresi nonparametrik spline truncated pada data IPM di Indonesia
dan menentukan faktor yang memengaruhi IPM di Indonesia.
2. Model Regresi Nonparametrik Spline Truncated
Model regresi nonparametrikspline truncated merupakan model regresi
pende-katan nonparametrik dengan fungsi regresi yang berbentuk polinomial spline
trun-cated (Budiantara [3]). Menurut Hardle [7], polinomial spline truncated berorde m
dengan titik knot (K1, K2, ..., Kr) didefinisikan sebagai
f(xi) = β0+ Σsl=1Σmj=1βjxjli+ Σrk=1βj+k(xli−Kkl)m+
dengan
(xli−Kkl)m+ =
{
(xli−Kkl)m, xli ≥Kkl; 0, xli < Kkl.
β0 adalah intersep, βj adalah parameter model, j = 1,2, . . . , m, βj+k adalah para-meter model pada orde ke-j dan titik knot ke-k,k = 1,2, . . . , r,r adalah banyaknya titik knot, Kkl adalah titik knot ke-k pada variabel prediktor ke-l, l = 1,2, . . . , s,
dan xli adalah nilai variabel prediktor ke-l pada pengamatan ke-i, i= 1,2, . . . , n.
3. Pemilihan Titik Knot Optimal
Model regresi nonparametrik spline truncated terbaik diperoleh berdasarkan titik knot optimal. Menurut Wahba [10], titik knot optimal diperoleh berdasarkan nilai GCV minimum. Rumus GCV dituliskan sebagai
GCV(K1, K2, ..., Kr) =
M SE(K1, K2, ..., Kr)
(n−1trace[I−A(K1, K2, ..., Kr)])2
dengan M SE(K1, K2, ..., Kr) = n−1Σni=1(yi −f(xi))2 dan A(K1, K2, ..., Kr)
meru-pakan matriks yang diperoleh dari rumus XK(X′ KXK)
−1 XK′ .
4. Metode Penelitian
4.1. Data Penelitian. Penelitian ini merupakan penelitian terapan yaitu mene-rapkan data IPM untuk 34 provinsi di Indonesia menggunakan model regresi
non-parametrik spline truncated. Data yang digunakan adalah data sekunder dari BPS
harapan hidup menurut provinsi (X1), PDRB menurut pengeluaran tahunan
provin-si (X2), jumlah penduduk miskin menurut provinsi (X3), dan persentase penduduk
buta huruf menurut provinsi (X4).
4.2. Langkah Penelitian. Langkah-langkah yang dilakukan pada penelitian ini di-mulai dari dibentuknya pola hubungan antara variabel respon dan masing-masing
variabel prediktor melalui scatter plot data. Kemudian ditentukan titik knot
opti-mal pada masing-masing variabel prediktor. Selanjutnya ditentukan model regresi
nonparametrik spline truncated terbaik berdasarkan titik knot optimal. Setelah itu
dilakukan estimasi parameter model dengan MKT. Tahapan terakhir penelitian ini
adalah dilakukannya uji signifikansi parameter, uji asumsi sisaan dan ditentukan
ko-efisien determinasi (R2) pada model regresi nonparametrikspline truncated terbaik.
5. Hasil dan Pembahasan
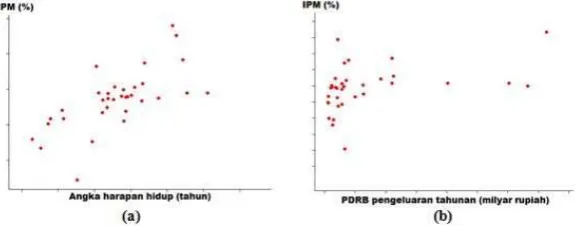
5.1. Pola Hubungan Variabel Respon dan Variabel Prediktor. Pemilihan model regresi pendekatan nonparametrik dalam memodelkan data IPM di Indonesia
disebabkan oleh pola hubunganY dengan masing-masingX1,X2,X3, danX4bersifat
tidak mengikuti pola tertentu. Dua pola hubunganY dengan masing-masingX1 dan
[image:3.595.167.455.530.643.2]X2 ditunjukkan pada Gambar 1(a) dan 1(b).
Gambar 1. Dua pola hubungan (a) Y danX1, (b)Y danX2
Berdasarkan Gambar 1(a) dan 1(b), nampak bahwa dua pola hubungan Y de-ngan masing-masingX1danX2 bersifat tidak mengikuti pola tertentu. Sama halnya
dengan pola hubungan Y dengan masing-masing X3 dan X4, sehingga pendekatan
model regresi yang digunakan adalah model regresi nonparametrik. Spline truncated
merupakan metode dalam model regresi nonparametrik yang baik digunakan apabila
5.2. Model Regresi Nonparametrik Spline Truncated. Titik knot optimal sebagai indikator model regresi nonparametrik spline truncated terbaik diperoleh
melalui nilai GCV minimum. Nilai GCV minimum dipengaruhi oleh pemilihan
orde (m) dan banyaknya titik knot (r). Berdasarkan penelitian, dipilih orde
sa-tu. Banyaknya titik knot yang digunakan yaitu 3, 4, dan 5 titik knot. Titik knot
yang dipilih pada masing-masing variabel prediktor dimulai dari 3 karena
pemilih-an bpemilih-anyaknya titik knot < 3 bersifat tidak mewakili keseluruhan data. Sedangkan untuk pemilihan banyaknya titik knot >5 akan menghasilkan nilai GCV yang tidak
minimum. Setelah dipilih orde dan banyaknya titikknot, selanjutnya dilakukan
per-hitungan nilai GCV. Nilai GCV minimum berdasarkan banyaknya titik knot yang
[image:4.595.192.426.380.466.2]digunakan pada masing-masing variabel prediktor ditunjukkan pada Tabel 1.
Tabel 1. Nilai GCV minimum berdasarkan banyaknya titik knot yang digunakan
No. r(X1)-r(X2)-r(X3)-r(X4) GCV minimum
1 3 - 3 - 3 - 3 8.3966
2 4 - 4 - 4 - 4 9.3048
3 5 - 5 - 5 - 5 9.9343
4 5-3-4-5, 5-5-5-4,etc. 7.6307
Berdasarkan Tabel 1, nilai GCV minimum sebesar 7.6307 diperoleh dari kom-binasi 5-5-5-4 titik knot yang merupakan titik knot optimal. Banyaknya titik knot
optimal pada variabel X1,X2, dan X3 sebanyak 5 titik knot, sedangkan banyaknya
titik knot optimal pada variabel X4 sebanyak 4 titik knot. Setelah diperoleh titik
knot optimal pada masing-masing variabel prediktor, dilakukan estimasi 24 para-meter model dengan MKT. Hasil estimasi parapara-meter model regresi nonparametrik
spline truncated dengan titik knot optimal ditunjukkan pada Tabel 2.
Tabel 2. Hasil estimasi parameter model
Parameter Estimasi Parameter Estimasi Parameter Estimasi ˆ
β0 −150.029 βˆ8 2.17312 ×10−
4 ˆ
β16 −2.05421 ×10− 2
ˆ
β1 3.45006 βˆ9 −1.73979 ×10−
4 ˆ
β17 0.003598 ˆ
β2 −18.1289 βˆ10 8.90236 ×10−
5 ˆ
β18 2.29005 ×10− 2
ˆ
β3 30.1189 βˆ11 −8.86224 ×10−
5 ˆ
β19 −19.6633 ˆ
β4 −20.0487 βˆ12 4.30924 ×10−
4 ˆ
β20 20.2997
ˆ
β5 5.73218 βˆ13 8.08703 ×10−3 βˆ21 −0.58512 ˆ
β6 −18.646 βˆ14 −3.57964 ×10−2 βˆ22 4.7376 ˆ
β7 −8.68926 ×10−
5 ˆ
β15 3.65047 ×10−
2 ˆ
[image:4.595.100.522.623.787.2]Berdasarkan hasil estimasi parameter model pada Tabel 2, diperoleh model regresi nonparametrik spline berikut.
ˆ
y = −150.029 + 3.45006x1−18.1289(x1−66.7) + 30.1189(x1−67.4)−
20.0487(x1−68.4) + 5.73218(x1−69.5)−18.646(x1−72.5)−
8.6892610×10−5x
2+ 2.17312×10−4(x2−80461.57)−
1.73979×10−4(x
2−141270.88) + 8.90236×10−5(x2−252022.86)−
8.86224×10−5(x
2−450936.6) + 4.30924×10−4(x2−1354102.11) +
8.08703×10−3x
3−3.57964×10−2(x3−245.54) + 3.65047×10−2
(x3−495.56)−2.05421×10−2(x
3−893.21) + 0.003598(x3−1005.68) +
2.29005×10−2(x
3−1608.14)−19.6633x4+ 20.2997(x4−0.55)−
0.58512(x4−3.55) + 4.7376(x4−7.79)−5.54316(x4−9.4)+.
Model regresi nonparametrikspline yang terbentuk dapat dituliskan kembali da-lam bentuk model regresi nonparametrik spline truncated. Penulisan model regresi nonparametrik spline truncated dilakukan berdasarkan interval titik knot optimal pada masing-masing variabel prediktor. Berikut dituliskan model regresi nonpara-metrik spline truncated berdasarkan interval titik knot optimal pada X1. Adapun
titik knot optimal pada variabel X1 yaitu 66.7, 67.4, 68.4, 69.5, dan 72.5.
ˆ
y =
−150.029 + 3.45006x1, x1 <66.7;
1059.168−14.67884x1, 66.7≤x1<67.4;
−970.84 + 15.44x1, 67.4≤x1<68.4; 400.49−4.6087x1, 68.4≤x1<69.5; 2.1 + 1.12348x1, 69.5≤x1<72.5; 1359.35−17.5223x1, x1 ≥72.5.
Model regresi nonparametrik spline truncated berdasarkan interval titik knot
optimal pada X2,X3, danX4 dituliskan dengan cara yang sama. Titikknot optimal
pada variabel X2 yaitu 80461.57, 141270.88, 252022.86, 450936.6, dan 1354102.11.
Titik knot optimal pada variabel X3 yaitu 245.54, 495.56, 893.21, 1005.68, dan 1608.14. Titik knot optimal pada variabel X4 yaitu 0.55, 3.55, 7.79, dan 9.4.
5.3. Uji Signifikansi Parameter. Setelah didapatkan model regresi nonparame-trik spline truncated berdasarkan interval titik knot optimal pada masing-masing
X1, X2, X3, dan X4, selanjutnya dilakukan uji signifikansi parameter. Uji signifi-kansi parameter bertujuan untuk mengetahui variabel prediktor yang berpengaruh
signifikan terhadap variabel respon (Gujarati [6]). Uji signifikansi parameter terdiri
5.3.1. Uji Keseluruhan. Hipotesis yang digunakan adalah H0 : β1 = β2 = β3 =
. . . = β23 = 0 (seluruh parameter model β tidak berpengaruh signifikan terhadap
model regresi) danH1 : paling tidak terdapat satuβh ̸= 0, h= 1,2,3, . . . ,23 (paling tidak terdapat satu parameter model βh yang signifikan terhadap model regresi). Taraf signifikansi α = 0.05. Kesimpulan H0 ditolak jika DK = {Fhitung|Fhitung >
F(α,h,n−h−1) = F0.05,23,10 = 2.75}. Statistik uji Fhitung = 8.6640. Karena 8.6640 ∈ DK, H0 ditolak yang berarti paling tidak terdapat satu parameter model βh yang signifikan terhadap model regresi. Kemudian dilakukan uji parsial untuk mengetahui
parameter model yang signifikan terhadap model regresi secara individu.
5.3.2. Uji Parsial. Hipotesis yang digunakan adalah H0 : βh = 0, h = 1,2, . . . ,23 (parameter model βh tidak signifikan terhadap model regresi) dan H1 :βh ̸= 0, h=
1,2, . . . ,23 (parameter model βh signifikan terhadap model regresi). Taraf signifi-kansi α = 0.05. Kesimpulan H0 ditolak jika DK = {thitung|thitung > t(α/2,n−h) =
t0.025,11 = 2.20}. Berdasarkan nilai thitung, diperoleh parameter model yang signi-fikan dengan nilai thitung melebihi 2.20, masing-masing β1 = 38.76, β2 = 203.69,
β3 = 338.41, β4 = 225.27, β5 = 64.41, β6 = 209.51, β19 = 108.22, β20 = 111.27,
β21 = 3.22, β22 = 26.07 dan β23 = 30.5. Karena nilai thitung dari β1, β2, β3, β4, β5, β6, β19, β20, β21, β22, dan β23 ∈ DK, maka β1, β2, β3, β4, β5, β6, β19, β20, β21, β22, dan β23 merupakan parameter model yang signifikan terhadap model regresi. Hal
ini mengindikasikan angka harapan hidup (X1) dan persentase penduduk buta huruf (X4) merupakan variabel yang berpengaruh signifikan terhadap IPM di Indonesia.
Setelah dilakukan uji signifikansi parameter pada model regresi nonparametrik
spline truncated yang terbentuk, selanjutnya dilakukan uji asumsi sisaan untuk
menguji kelayakan model regresi.
5.4. Uji Asumsi Sisaan. Uji asumsi sisaan bertujuan untuk menguji kelayakan model regresi (Gujarati [6]). Uji asumsi sisaan meliputi 3 asumsi yang harus
dipe-nuhi, yaitu asumsi kenormalan, independensi, dan heteroskedastisitas. Pengujian
asumsi kenormalan dilakukan menggunakan uji Kolmogorov Smirnov
(Bintarini-ngrum dan Budiantara [1]). Pengujian asumsi independensi dilakukan menggunakan
uji Durbin Watson (Gujarati [6]). Pengujian asumsi heteroskedastisitas dilakukan
5.4.1. UjiKolmogorov Smirnov. Hipotesis yang digunakan adalahH0 : sisaan
berdis-tribusi normal dan H1 : sisaan tidak berdistribusi normal. Taraf signifikansi yang
digunakan pada penelitian yaitu, α= 0.05. Kesimpulan pada ujiKolmogorov
Smir-nov yaitu,H0 ditolak jikaDK ={KS|KS > q(1−α,n) =q(0.950,34)= 0.152}. Statistik uji Kolmogorov Smirnov (KS) =0.076. Karena 0.076̸∈ DK, H0 tidak ditolak yang
berarti sisaan berdistribusi normal. Asumsi kenormalan dipenuhi.
5.4.2. Uji Durbin Watson. Hipotesis yang digunakan adalah H0 : tidak terdapat
autokorelasi pada sisaan dan H1 : terdapat autokorelasi pada sisaan. Taraf
sig-nifikansi yang digunakan pada penelitian yaitu, α = 0.05. Kesimpulan pada uji
Durbin Watson yaitu, H0 ditolak jika DK = {dhitung|dhitung < dl = 1.21 atau 4−dhitung < du = 1.73}. Statistik uji dhitung = 1.43 dan 4−dhitung = 2.57 . Ka-rena statistik uji dhitung dan 4−dhitung ̸∈ DK, H0 tidak ditolak yang berarti tidak
terdapat autokorelasi pada sisaan. Asumsi independensi dipenuhi.
5.4.3. Uji Glejser. Hipotesis yang digunakan adalah H0 : tidak terdapat
hetero-skedastisitas pada sisaan dan H1 : terdapat heteroskedastisitas pada sisaan. Taraf
signifikansi yang digunakan pada penelitian yaitu, α = 0.05. Kesimpulan H0
di-tolak jika DK = {Fhitung|Fhitung > F(α,h−1,n−h) = F0.05,22,11 = 2.60}. Statistik uji
Fhitung =0.1979. Karena 0.1979̸∈DK,H0 tidak ditolak yang berarti tidak terdapat
heteroskedastisitas pada sisaan. Asumsi heteroskedastisitas dipenuhi.
5.5. Koefisien Determinasi. Koefisien determinasi (R2) pada model regresi di-hitung untuk mengetahui seberapa besar variabel respon dijelaskan oleh variabel
prediktor (Drapper and Smith [4]). Berdasarkan perhitungan, nilai R2 adalah
R2 = Σ n
i=1( ˆyi−y)¯ 2 Σn
i=1(yi−y¯)2
= 541.946
573.2278 = 0.9454
Berdasarkan model regresi yang terbentuk, diperoleh nilai R2 sebesar 0.9454. Hal
tersebut mengindikasikan IPM di Indonesia dapat dijelaskan sebesar 94.54% oleh
angka harapan hidup dan persentase penduduk buta huruf. Sedangkan sisanya,
5.46% merupakan persentase faktor lain yang belum dimasukkan dalam model.
6. Kesimpulan
(1) Model regresi nonparametrik spline truncated pada data IPM di Indonesia yang sesuai adalah
ˆ y =
−150.029 + 3.45006x1, x1 <66.7;
1059.168−14.67884x1, 66.7≤x1 <67.4;
−970.84 + 15.44x1, 67.4≤x1 <68.4; 400.49−4.6087x1, 68.4≤x1 <69.5; 2.1 + 1.12348x1, 69.5≤x1 <72.5; 1359.35−17.5223x1, x1 ≥72.5;
−150.029−19.6633x4, x4 <0.55;
−161.1938 + 0.6364x4, 0.55≤x4 <3.55;
−159.1166 + 0.05128x4, 3.55≤x4 <7.79;
−196.0225 + 4.7888x4, 7.79≤x4 <9.4;
−143.9168−0.75428x4, x4 ≥9.4.
(2) Faktor yang memengaruhi IPM di Indonesia yaitu angka harapan hidup
me-nurut provinsi (X1) dan persentase penduduk buta huruf menurut provinsi (X4).
Daftar Pustaka
[1] Bintariningrum, M. F., dan I. N. Budiantara,Pemodelan Regresi Nonparametrik Spline Trun-cated dan Aplikasinya pada Angka Kelahiran Kasar Di Surabaya, Jurnal Sains dan Seni Pomits
Vol.3(2014), no. 1, 7-12.
[2] BPS, [Badan Pusat Statistik], Indeks Pembangunan Manusia di Negara Indonesia, Jakarta, 2015.
[3] Budiantara, I. N.,Penelitian Bidang Regresi Spline Menuju Terwujudnya Penelitian Statistika yang Mandiri dan Berkarakter, Seminar Nasional Matematika, Jurusan Matematika Universitas Pendidikan Ganesha, Bali, 2011.
[4] Drapper, N. R., and H. Smith, Applied Regression Analysis, Second edition, John Wiley and Sons, Inc., New York, 1992.
[5] Eubank, R. L.,Spline Smoothing and Nonparametric Regression, Second edition, Marcel Dek-ker, New York, 1999.
[6] Gujarati, N. D.,Essential Of Econometrics, Mc Graw-Hill. Inc, New York, 2006.
[7] Hardle, W.,Applied Nonparametric Regression, Cambridge University Press, New York, 1994. [8] Lee, T. C. M.,On Algorithms For Ordinary Least Squares Regression Spline Fitting:A
Compa-rative Study, Statistica,Vol.72(2002), no.8, 647-663.
[9] UNDP, [United Nations Development Programme], Human Development Report, New York, 1990.
[10] Wahba, G.,Spline Models For Observational Data, SIAM, Pennsylvania, 1990.