Penelitian ini bertujuan membuat sistem untuk mengelompokkan penyakit yang menyerang daun padi. Penelitian ini menggunakan dua jenis penyakit, yaitu : Cochliobolus Miyabeanus dan Xanthomonas oryzae pv. Oryzae. Penelitian ini menggunakan 20 data berupa citra. Setiap citra dirubah menjadi data vektor menggunakan filter gabor wavelet.
Penelitian ini menggunakan metode K-Means Clustering untuk pengelompokan penyakit. Data pada penelitian ini berupa data vektor. Proses penelitian ini melalui tahap preprocessing, clustering, dan uji akurasi. Preprocessing meliputi filter gabor wavelet untuk mengambil data vektor dari citra asli. Clustering menggunakan K-Means dengan menentukan titik awal secara manual dan menghitung kemiripan dengan menggunakan Euclidean Distance. Pengujian akurasi secara mandiri dengan membandingkan sistem dan manual.
Akurasi tertinggi sebesar 70% dan akurasi terendah 55% dari 100 uji akurasi. Data yang digunakan sebanyak 20 data. Hasil akurasi tertinggi dengan perbandingan antara sistem dan manual.
ABSTRACT
This research aims to create a system to clustering diseases that attacked in rice leaves. This research used two types of diseases: Cochliobolus Miyabeanus and Xanthomonas oryzae pv. Oryzae. This research used 20 data in the form of images. Each image is converted into vector data using filter Gabor wavelet.
This research used K-Means Clustering method to clustering of the disease. The data on this research in the form of vector data. This research process through stages of preprocessing, clustering, and test the accuracy. Preprocessing included Gabor wavelet filters for vector data from the original image. The Clustering used K-Means by choosing the start point and manually calculate the similarities by using Euclidean Distance. Accuracy Test independently compare between systems and manual.
Highest accuracy of 70% and accuracy of the lowest 55% of the 100 test accuracy. The data used as many as 20 data. The results of highest accuracy with comparison between systems and manual.
i
MEANS
JUDUL SKRIPSISKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
DHIAH RUSDIANA PRIINDARYANTI
NIM. 115314037
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
HALAMAN JUDUL (Bahasa Inggris)
THESISPresented as Partitial Fulfilment of The Requirements
To Obtain Sarjana komputer degree
In Informatics Engineering Department
By :
DHIAH RUSDIANA PRIINDARYANTI
Student Number : 115314037
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
vi
Saya yang bertanda tangan di bawah ini, mahasiswa Universitas Sanata Dharma
nama : Dhiah Rusdiana Priindaryanti
nomor mahasiswa : 115314037
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
PENGENALAN POLA CITRA PENYAKIT TANAMAN PADI PADA DAUN MENGGUNAKAN GABOR WAVELET DAN ALGORITMA K-MEANS
Dengan demikian saya memeberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademik tanpa perlu meminta ijin dari saya maupun memberi royalti kepada saya selama mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta
Pada tanggal 31 Januari 2017
Yang menyatakan,
vii
Penelitian ini bertujuan membuat sistem untuk mengelompokkan penyakit yang menyerang daun padi. Penelitian ini menggunakan dua jenis penyakit, yaitu : Cochliobolus Miyabeanus dan Xanthomonas oryzae pv. Oryzae. Penelitian ini menggunakan 20 data berupa citra. Setiap citra dirubah menjadi data vektor menggunakan filter gabor wavelet.
Penelitian ini menggunakan metode K-Means Clustering untuk pengelompokan penyakit. Data pada penelitian ini berupa data vektor. Proses penelitian ini melalui tahap preprocessing, clustering, dan uji akurasi. Preprocessing meliputi filter gabor wavelet untuk mengambil data vektor dari citra asli. Clustering menggunakan K-Means dengan menentukan titik awal secara manual dan menghitung kemiripan dengan menggunakan Euclidean Distance. Pengujian akurasi secara mandiri dengan membandingkan sistem dan manual.
Akurasi tertinggi sebesar 70% dan akurasi terendah 55% dari 100 uji akurasi. Data yang digunakan sebanyak 20 data. Hasil akurasi tertinggi dengan perbandingan antara sistem dan manual.
viii
This research aims to create a system to clustering diseases that attacked in rice leaves. This research used two types of diseases: Cochliobolus Miyabeanus and Xanthomonas oryzae pv. Oryzae. This research used 20 data in the form of images. Each image is converted into vector data using filter Gabor wavelet.
This research used K-Means Clustering method to clustering of the disease. The data on this research in the form of vector data. This research process through stages of preprocessing, clustering, and test the accuracy. Preprocessing included Gabor wavelet filters for vector data from the original image. The Clustering used K-Means by choosing the start point and manually calculate the similarities by using Euclidean Distance. Accuracy Test independently compare between systems and manual.
Highest accuracy of 70% and accuracy of the lowest 55% of the 100 test accuracy. The data used as many as 20 data. The results of highest accuracy with comparison between systems and manual.
ix
Dengan mengucap puji syukur kepada Tuhan Yang Maha Esa atas kasih dan
anugerah-Nya yang telah memberi kesempatan bagi penulis untuk dapat menyelesaikan laporan tugas akhir dengan judul “Pengenalan Pola Citra Penyakit Tanaman Padi Pada Daun Menggunakan Gabor Wavelet Dan Algoritma K-Means”. Laporan tugas akhir merupakan salah satu
persyaratan bagi para mahasiswa/mahasiswi untuk dapat menyelesaikan jenjang pendidikan
S1 pada Program Studi Teknik Mesin, Fakultas Sains dan Teknologi, Universitas Sanata
Dharma Yogyakarta. Dalam laporan tugas akhir ini membahas mengenai perancangan,
pembuatan kincir angin sumbu horizontal jenis propeler, dan perbandingan daya.
Dalam kesempatan ini, penulis ingin mengucapkan banyak terima kasih kepada:
1. Bapak Sudi Mungkasi,S.Si.,M.Math.Sci.,PhD., selaku Dekan Fakultas Sains dan
Teknologi, Universitas Sanata Dharma Yogyakarta.
2. Ibu Dr. Anastasia Rita Widiarti, S.Si., M.Kom selaku Ketua Program Studi Teknik
Informatika.
3. Ibu Sri Hartati Wijono, S.Si., M.Kom selaku Dosen Pembimbing Tugas Akhir.
4. Bapak J.B. Budi Darmawan, S.T., M.Sc. selaku Dosen Pembimbing Akademik.
5. Seluruh dosen program studi Teknik Informatika yang telah mendidik dan memberikan
ilmu pengetahuan kepada penulis.
6. Seluruh staf Fakultas Sains dan Teknologi atas kerja sama dan dukungan kepada penulis
untuk dapat menyelesaikan laporan tugas akhir.
7. Bapak Suyana dan Ibu Eka Mardayanti sebagai orang tua dari penulis, serta Rahmad
Anwar Rhomadhoni sebagai saudara dari penulis yang selalu berdoa, mendukung secara
material dan yang lain – lain kepada penulis.
8. Sisil, Vina, Pasca, Simeon, Enda, temen-temenku seperjuangan yang selalu memberi
semangat dan hiburan.
9. Teguh, Bianca dan Zahra Squad sebagai teman, sahabat dan keluarga baru yang selalu
x
Penulis menyadari bahwa masih ada kekurangan yang perlu diperbaiki. Oleh karena
itu, penulis mengharapkan saran dan kritik yang membangun untuk menyempurnakan
laporan tugas akhir. Semoga bermanfaat bagi semua pihak.
Yogyakarta, 31 Januari 2017
xi
JUDUL SKRIPSI ... i
HALAMAN JUDUL (Bahasa Inggris) ... ii
HALAMAN PERSETUJUAN ... Error! Bookmark not defined. HALAMAN PENGESAHAN... iv
PERNYATAAN KEASLIAN KARYA ... v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI... vi
ABSTRAK ... vii
1.5 Manfaat Penelitian ... 2
1.6 Metodologi Penelitian ... 2
1.7 Luaran Penelitian ... 3
1.8 Sistematika Penulisan ... 4
2.1 Teori Pola ... 6
2.1.1 Pengertian Pola ... 6
2.1.2 Ciri-Ciri Pola ... 6
2.1.3 Sistem pengenalan pola ... 6
2.2 Distance (Jarak) ... 8
a. Euclidean Distance ... 8
b. Normalized Euclidean Distance ... 8
2.3 Citra... 9
2.3.1 Pengertian ... 9
xii
a. Bipmap (.bmp) ... 11
b. Portable Network Graphics (.png) ... 11
c. JPEG (.jpg) ... 11
2.5 Teori Warna dan Texture ... 12
2.5.1 Warna ... 12
2.5.2 Tekstur ... 13
2.6 Filter Gabor Wavelet ... 13
2.7 Algoritma K-Means Clustering ... 15
BAB III ... 19
PERANCANGAN SISTEM ... 19
3.1 DATA ... 19
3.1.2 Data vektor ... 21
3.2 DESKRIPSI SISTEM ... 21
3.3 MODEL ANALISIS ... 21
3.3.1 Preprocessing Citra ... 22
3.3.2 K-Means Clustering ... 22
3.3.3. Perancangan hitung akurasi ... 23
3.4 KEBUTUHAN HARDWARE DAN SOFTWARE... 23
3.4.1 Hardware ... 23
4.1.2 K-Means Clustering ... 26
4.1.3 Hitung akurasi ... 37
BAB V ... 42
PENGUJIAN DAN ANALISA HASIL ... 42
xiii
xiv
Gambar 3. 1 Penyakit Cochliobolus Miyabeanus (Bercak Coklat) ... 20
Gambar 3. 2 Penyakit Xanthomonas oryzae pv. Oryzae (Hawar Bakteri) ... 20
Gambar 3. 3 Model Analisis ... 21
Gambar 4. 1 Contoh Citra Penyakit ... 24
Gambar 4. 2 Tampilan Antarmuka ... 26
Gambar 4. 3 Tampilan Cari ... 27
Gambar 4. 4 Mencari Data dalam File ... 28
Gambar 4. 5 Menampilkan File data1 ... 28
Gambar 4. 6 Mencari File data2... 29
Gambar 4. 7 Menampilkan File data2 ... 29
Gambar 4. 8 Tampilan Proses ... 30
Gambar 4. 9 Tampilan Memilih Titik Awal ... 34
xv
DAFTAR TABEL
1 BAB I
PENDAHULUAN
1.1 Latar Belakang
Pada zaman globalisasi ini masih banyak petani padi yang tidak
mengenali jenis-jenis penyakit pada tanaman padi mereka. Banyak sekali
penyakit-penyakit pada tanaman padi, sehingga membuat petani sulit
mengetahui tanaman padi yang terkena penyakit. Dengan begitu banyak juga
yang tidak bisa mengelompokan penyakit tanaman padi pada daun yang
terkena penyakit, misalnya disebabkan fungi(jamur) dan bakteri.
Pengetahuan tentang penyakit-penyakit padi dan pengelompokan
penyakit hanya berdasarkan pengalaman, penyuluhan dan belum bersifat
komputerisasi yang dalam sewaktu-waktu dapat dengan mudah menambah
data baru tentang penyakit dan hama terbaru dengan mengelompokan
penyakit padi yang baru dimasukan dalam sistem, sehingga petani dapat
mengetahui dan memahami kelompok penyakit tersebut. Pengelompokan
penyakit ini berdasarkan jenis penyakit dan bentuk bercak pada daun padi.
Dalam hal ini diperlukan suatu metode untuk merumuskan masalah tersebut.
Metode yang dipakai adalah citra digital dengan mengolah gambar penyakit
tanaman padi pada daun menggunakan Gabor Wavelet dan K-Means
Clustering. Masalah yang dibahas meliputi pada tanaman padi pada daun
yaitu Cochliobolus Miyabeanus dan Xanthomonas oryzae pv. Oryzae.
Dari masalah tersebut penulis akan membuat sistem pengenalan pola
citra penyakit tanaman padi pada daun menggunakan Gabor Wavelet dengan
algoritma K-Means Clustering, untuk mengelompokan penyakit pada
tanaman padi. Sistem ini juga dapat membantu petani padi mengelompokan
penyakit pada tanaman padi dengan cara mengambil gambar pada padi yang
terserang penyakit agar gambar dapat diproses untuk di masukkan pada
Dengan begitu petani dapat mengelompokan penyakit pada tanaman padi
dengan memasukkan citra tanaman padi yang sedang terkena penyakit, yaitu
pada daun, kemudian akan didapatkan sebuah vektor dengan menggunakan
Gabor Wavelet kemudian akan dikelompokkan menggunakan algoritma
K-Means Clustering sehingga mengetahui kelompok penyakit tanaman padi.
1.2 Rumusan Masalah
1. Bagaimana mengelompokan penyakit Cochliobolus Miyabeanus dan
Xanthomonas oryzae pv. Oryzae pada daun tanaman padi? 2. Bagaimana membuat fitur vector Gabor Wavelet dari citra asli?
1.3 Tujuan
1. Untuk membantu petani mengelompokan dan mengenali penyakit
Cochliobolus Miyabeanus dan Xanthomonas oryzae pv. Oryzae pada daun tanaman padi.
1.4 Batasan Masalah
Dalam tugas akhir ini penulis menentukan beberapa batasan masalah untuk
mempersempit lingkup permasalahan, antara lain:
1. Data citra yang dipakai hanya berupa citra berwarna RGB
2. Tipe data citra yang dipakai hanya bertipe .JPG dan.JPEG
3. Penyakit dibatasi yang disebabkan oleh bakteri dan jamur yaitu
Cochliobolus Miyabeanus dan Xanthomonas oryzae pv. Oryzae 4. Hanya diproses melalui citra foto daun.
1.5 Manfaat Penelitian
Manfaat yang didapat dari penelitian ini :
1. Membantu memudahkan masyarakat untuk mengetahui penyakit
Cochliobolus Miyabeanus dan Xanthomonas oryzae pv. Oryzae pada tanaman padi.
1.6 Metodologi Penelitian
1.Studi pustaka menegenai metode pengolahan citra
2.Pengembangan program menggunakan
Langkah-langkah:
System Engineering dan analysis.
Mengumpulkan data menentukan semua kebutuhan elemen sistem
Software Requirement Analysis.
Melakukan analisis terhadap permasalahan yang dihadapi dan
menetapkan kebutuhan software. Kebutuhan tersebut meliputi
Netbeans 7.3 dan Matlab
Design.
Proses menterjemahkan kebutuhan sistem kedalam sebuah gambaran
program. Desain akan menjadi dokumen dari program.
Coding.
Pengkodean merupakan proses penterjemahan desain ke dalam
bentuk yang dapat dieksekusi.
Testing.
Proses pengujian memastikan apakah semua fungsi-fungsi program
berjalan dengan baik dan menghasilkan output yang sesuai dengan
yang dibutuhkan.
1.7 Luaran Penelitian
Luaran penelitian ini adalah sebuah aplikasi yang mampu mengelompokan
1.8 Sistematika Penulisan
BAB I. PENDAHULUAN
Bab ini menjelaskan tentang latar belakang masalah, rumusan
masalah, batasan masalah, tujuan penulisan, manfaat penelitian,
metodologi penelitian yang digunakan dan sistematika penulisan dari
tugas akhir ini.
BAB II. LANDASAN TEORI
Bab ini membahas tentang landasan teori yang digunakan dalam
tugas akhir ini, yaitu: pengertian pola, pengertian citra, jenis-jenis citra,
sistem pencitraan, dan teori texture dengan menggunakan Gabor
Wavelet
BAB III. PERANCANGAN SISTEM
Bab ini membahas membahas analisis masalah yang
mempermudah dalam menyusun rancangan disain. Analisis ini terdiri
dari spesifikasi perangkat lunak, spesifikasi perangkat keras dan sistem
yang akan dikembangkan. Hasil rancangan program terdiri dari
rancangan antarmuka grafis yang akan diterapkan dalam pembuatan
aplikasi.
BAB IV. IMPLEMENTASI
Bab ini membahas tentang langkah-langkah implementasi dan hasil
program yang terdiri dari tampilan program, alur program dan
penjelasan program.
BAB V. PENGUJIAN DAN ANALISA HASIL
Bab ini membahas tentang uji akurasi dan menganalisa hasil akhir.
Hasil dari implementasi di bab iv akan di uji dan di analisa lebih lanjut.
Bab ini menjelaskan tentang kesimpulan dari uji coba perangkat
lunak dan saran untuk pengembangan, perbaikan serta penyempurna
6
BAB II
LANDASAN TEORI
2.1Teori Pola
2.1.1 Pengertian Pola
Pengenalan pola adalah suatu ilmu untuk mengklasifikasikan atau
menggambarkan sesuatu berdasarkan pengukuran kuantitatif fitur (ciri)
atau sifat utama dari suatu obyek.Pola adalah entitas yang terdefinisi
dan dapat diidentifikasi melalui ciri-cirinya. Ciri-ciri tersebut digunakan
untuk membedakan suatu pola dengan pola lainnya. Ciri yang bagus
adalah ciri yang memiliki daya pembeda yang tinggi, sehingga
pengelompokan pola berdasarkan ciri yang dimiliki dapat dilakukan
dengan keakuratan yang tinggi.
2.1.2 Ciri-Ciri Pola
Ciri pada suatu pola diperoleh dari hasil pengukuran terhadap objek
uji. Khusus pada pola yang terdapat di dalam citra, ciri-ciri yang dapat
diperoleh berasal dari informasi:
a. Spasial: intensitas pixel, histogram
b. Tepi: arah, kekuatan
c. Kontur: garis, elips, lingkaran
d. Wilayah/bentuk: keliling, luas, pusat massa
e. Hasil transformasi Fourier: frekuensi.
2.1.3 Sistem pengenalan pola
Pengenalan pola bertujuan menentukan kelompok atau kategori pola
berdasarkan ciri-ciri yang dimiliki oleh pola tersebut. Dengan kata lain,
dua pendekatan yang dilakukan dalam pengenalan pola, yaitu
pendekatan secara statistik dan pendekatan secara sintaktik atau
struktural.
Pendekatan ini menggunakan teori-teori ilmu peluang dan statistik.
Ciri-ciri yang dimiliki oleh suatu pola ditentukan distribusi statistiknya.
Pola yang berbeda memiliki distribusi yang berbeda pula. Dengan
menggunakan teori keputusan di dalam statistik, kita menggunakan
distribusi ciri untuk mengklasifikasikan pola.
Gambar 2. 1 Sistem Pengenalan Pola dengan Pendekatan Statistik
a. Pengenalan pola secara Sintaktik
Pendekatan ini menggunakan teori bahasa formal. Ciri-ciri yang
terdapat pada suatu pola ditentukan primitif dan hubungan struktural
antara primitif kemudian menyusun tata bahasanya. Dari aturan
produksi pada tata bahasa tersebut kita dapat menentukan kelompok
pola.
2.2 Distance (Jarak)
Jarak digunakan untuk menentukan tingkat kesamaan (similarity degree)
atau ketidaksamaan (dissimilarity degree) dua vektor fitur. Tingkat kesamaan
berupa suatu nilai dan berdasarkan sekor tersebut dua vektor fitur akan
dikatakan mirip atau tidak. Metode jarak yang dapat digunakan untuk
mengukur tingkat kemiripan dua vektor fitur adalah :
a. Euclidean Distance
Euclidean Distance adalah metrika yang paling digunakan untuk menghitung kesamaan 2 vektor. Euclidean Distance menghitung akar
dari kuadrat perbedaan 2 vektor.
Rumus dari Euclidean distance:
... 2.1
b. Normalized Euclidean Distance
Jarak Euclidean ternomalisasi dari dua vektor ciri u dan v adalah:
... 2.2
dengan:
... 2.3
disebut norm dari v yang dinyatakan sebagai:
...2.4
Semakin kecil skor maka semakin mirip kedua vektor fitur
semakin berbeda kedua vektor ciri. Sifat dari jarak Euclidean
ternomalisasi adalah hasilnya berada pada rentang
Normalized Euclidean distance dari vektor A dan B diatas adalah:
... 2.5
Citra adalah suatu representasi (gambaran), kemiripan atau imitasi
dari suatu objek. Citra sebagai keluaran suatu sistem perekaman data
dapat bersifat optic berupa foto, bersifat analog berupa sinyal-sinyal
video seperti gambar pada monitor televise, atau bersifat digital yang
dapat langsung disimpan pada suatu media penyimpan.
2.3.2 Macam-macam Citra
2.3.2.1 Citra Analog
Citra analog adalah citra yang bersifat kontinu, seperti
gambar pada monitor televise, fotosinar X, foto yang di cetak di
kertasfoto, lukisan, pemandangan alam, hasil CT scan,
analog tidak dapat direpresentasikan dalam komputer sehingga
tidakbisa diproses di komputer secara langsung.
2.3.2.1 Citra Digital
Citra digital adalahcitra yang dapat diolah oleh komputer.
Sebuah citra grayscale ukuran 150x150 piksel (elemen terkecil
dari sebuah citra) diambil sebagai (kotak kecil) berukuran 9x9
piksel.Maka, monitor akan menampilkan sebuah kotak kecil.
Namun, yang disimpan dalam memori komputer hanyalah
angka-angka yang menunjukan besar intensitas pada
masing-masing piksel tersebut.
2.3.3 Jenis-jenis Citra Digital
2.3.3.1Citra Biner (Monokrom)
Banyaknya warna 2, yaitu hitam dan putih. Dibutuhkan 1
bit di memori untuk menyimpan kedua warna ini.
Gradiasi warna:
bit 0 : warna hitam
bit 1 : warna putih
2.3.3.2 Citra Grayscale (Skala Keabuan)
Banyak warna tergantung pada jumlah bit yang
disediakan di memori untuk menampung kebutuhan warna ini.
Citra 2 bit mewakili dengan gradiasi warna berikut:
2.3.3.3Citra Warna (True Color)
Setiap pixel pada citra warna yang merupakan kombinasi
dari tiga warna dasar, yaitu RGB (Red Green Blue). Setiap
warna dasar menggunakan penyimpanan 8 bit =1 byte, yang
berarti setiap warna mempunyai gradiasi sebanyak 255 warna.
Setiap pixel mempunyai kombinasi warna sebanyak
28.28.28=224= 16 juta warna lebih. Dengan begitu maka
dinamakan true color karena mempunyai jumlah warna yang
cukup besar sehingga bisa dikatakan hamper mencakup semua
di alam.
2.4 Format File Citra
Format file citra standar yang digunakan saat ini terdiri dari beberapa
jenis. Format-format ini digunakan dalam menyimpan citra dalam sebuah file.
Setiap format memiliki karakteristik masing-masing. Berikut ini beberapa
format umum yang digunakan saat ini:
a. Bipmap (.bmp)
Format .bmp adalah format penyimpanan standar tanpa kompresi
yang umum dapat digunakan untuk menyimpan citra biner hingga
citra warna. Format ini terdiri dari beberapa jenis yang setiap jenisnya
ditentukan dengan jumlah bit digunakan untuk menyimpan nilai pixel.
b. Portable Network Graphics (.png)
Format .png adalah format penyimpanan citra terkompresi. Format
ini dapat digunakan pada citra grayscale, citra dengan palet warna, dan
juga citra fullcolor.
Format .jpg adalah format yang sangat umum digunakan saat ini
khususnya untuk transmisi citra. Format ini digunakan untuk
menyimpan citra hasil kompresi dengan metode JPEG.
2.5 Teori Warna dan Texture
2.5.1 Warna
Citra berdasarkan warna yang dikandungnya adalah salah satu
teknik yang paling banyak digunakan. Secara umum feature warna
hanya memperhatikan distribusi warna piksel-piksel dalam citra tanpa
memperhatikan ukuran dan orientasi posisi citra.. Berikut merupakan
proses pengklasifikasian dengan menghitung rata-rata nilai Red, Green,
= nilai piksel Red
Tekstur adalah tampilan permukaan (corak) dari suatu benda
yang dapat dinilai dengan cara dilihat atau diraba. Yang pada
prakteknya, tekstur sering dikategorikan sebagai corak dari suatu
permukaan benda, misalnya permukaan karpet, baju, kulit kayu, dan
lain sebagainya. Pada suatu citra, tekstur merupakan komponen dasar
pembentuk citra. Sehingga tekstur kerap kali digunakan sebagai
pembeda antara satu citra dengan citra lainnya.
2.6 Filter Gabor Wavelet
Filter Gabor merupakan sekelompok wavelet, dan setiap wavelet
menyimpan energi pada frekuensi dan arah/ruang tertentu. Reprentasi Gabor
Wavelet dari sebuah citra merupakan konvolusi citra dengan filter Gaboor
gmn.
Untuk setiap citra I(x,y) dengan ukuran PxQ, maka transformasi
Gabor Wavelet Wmn didefinisikan (Manjunath, 1996) :
gmn* merupakan complex conjugate dari gmn. gmn adalah fungsi self similar
yang dibentuk dari proses dilasi dan rotasi terhadap mother wavelet G(x,y).
Wmn merupakan hasil complex conjugate terhadap filter Gabor pada orientasi
n dan skala m. Filter Gabor akan dihitung untuk S skala dan K orientasi
...2.19
...2.20
...2.21
...2.22
...2.23
...2.24
Dengan :
m : skala =0,1,2,...(S-1)
n : orientasi =0,1,2,...(K-1)
Uh : Batas atas pusat frekuensi
Ul : Batas bawah pusat frekuensi
Self similar Gabor Wavelet adalah :
gmn (x,y) = aS-mG(x’ , y’ )
x’=x cos +y sin
y’=-x sin + y cos
Setelah filter Gabor di konvolusi terhadap citra dengan skala m dan
orientasi n, maka akan didapat energi citra pada skala dan orientasi yang
berbeda :
...2.25
Untuk mendapatkan tekstur ciri dapat sebuah area atau citra, maka
digunakan mean dan standar deviasi dari energi Emn tersebut.
...2.26
Algoritma K-means merupakan algoritma pengelompokan iteratif yang
melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan
di awal. Algoritma K-Means sederhana untuk diimplimentasikan dan
dijalankan, relatif cepat, mudah beradaptasi, umum penggunaannya dalam
praktek. Secara historis, K-Means menjadi salah satu algoritma yang paling
penting dalam bidang data mining (Wu dan Kumar, 2009).
Bentuk esensial K-Means ditemukan oleh sejumlah peneliti dari lintas
disiplin ilmu. Yang paling berpengaruh adalah harus ada di pustaka, ambil
salah satu saja dan masukkan ke pustaka. Algoritma K-Means berkembang
hingga menjadi konteks yang lebih besar sebagai algoritma hill-climbing,
K-Means dapat diterapkan pada data yang direpresentasikan dalam
r-dimensi ruang tepat. K-means mengelompokkan set data r-r-dimensi, X={ ǀ
i=1, ..., N}, dimana € Rd yang menyatakan data ke-i sebagai “titik data”. Seperti yang dijelaskan sebelumnya bahwa K-Means mempartisi X ke dalam
cluster, Algoritma K-Means mengelompokkan semua titik data dalam X
sehingga setiap xi hanya jauh dalam satu dari K partisi. Yang perlu
diperhatikan adalah titik berada dalam cluster yang mana, dilakukan dengan
cara memberikan setiap titik sebuah ID cluster. Titik dengan ID cluster yang
sama berarti beada dalam satu cluster yang sama, sedangkan titik dengan ID
cluster yang berbeda berada dalam cluster yang berbeda. Untuk menyatakan
hal ini, biasanya dilakukan dengan vektor keanggotaan cluster m dengan
panjang N, dimana mi bernilai ID cluster titik xi.
Dalam K-Means, setiap cluster dari K cluster diwakili oleh titik tunggal
dalam Rd. Set representatif cluster dinyatakan C={cjǀ=1, ..., K}. Sejumlah K
representatif cluster tersebut disebut juga sebagai cluster means atau cluster
centroid (atau centroid saja). Untuk set data dalam X dikelompokkan berdasarkan konsep kedekatan atau kemiripan. Meskipun konsep yang
dimaksud untuk data yang berkumpul dalam satu cluster adalah
data-data yang mirip, tetapi kuantitas yang digunakan untuk mengukurnya adalah
ketidakmiripan (dissimilarity). Artinya, data-data dengan ketidakmiripan
(jarak) yang kecil/dekat maka lebih besar kemungkinannya untuk untuk
bergabung dalam cluster. Metrik yang umum digunakan untuk
ketidakmiripannya adalah Euclidean.
Pada saat data sudah dihitung ketidakmiripan terhadap setiap centroid,
maka selanjutnya dipilih ketidakmiripan yang paling kecil sebagai cluster
yang akan diikuti sebagai relokasi data pada cluster di sebuah iterasi.
Relokasi sebuah data dalam cluster yang diikuti dapat dinyatakan dengan
nilai keanggotaan a yang bernilai 0 dan 1. Nilai 0 jika tidak menjadi anggota
sebuah cluster dan 1 jika menjadi anggota sebuah cluster. Karena K-Means
sebuah data pada semua cluster, hanya satu yang bernilai 1, sedangkan
lainnya 0 seperti dinyatakan persamaan berikut:
...2.29
d(xi,cj) menyatakan ketidakmiripan (jarak) dari ke-i ke cluster cj.
Langkah-langkah K-Means Clustering:
1.Analisasi: tentukan nilai K sebagai jumlah cluster yang diinginkan dan
metrik ketidakmiripan (jarak) yang diinginkan. Kika perlu, tetapkan
ambang batas perubahan fungsi objektif dan ambang batas perubahan
posisi centroid.
2.Pilih K dari set data X sebagai centroid.
3.Alokasikan semua data ke centroid terdekat dengan metrik jarak yang
sudah ditetapkan (memperbarui cluster ID setiap data).
4.Hitung kembali centroid C berdasarkan data yang mengikuti cluster
masing-masing.
5.Ulangi langkah 3 dan 4 hingga kondisi konvergen tercapai, yaitu (a)
perubahan fungsi objektif sudah di bawah ambang batas yang diinginkan;
atau (b) tidak ada data yang berpindah cluster; atau (c) perubahan posisi
centroid sudah di bawah ambang batas yang ditetapkan.
Secara iteratif melakukan dua langkah berikut sampai tercapai kondisi
konvergen:
Langkah 1: Data assignment. Setiap data ditetapkan ke centroid terdekat
dengan memecahkan hubungan apa adanya. Hasilnya berupa data yang
terpartisi.
Langkah 2: Relocation of “means”. Setiap representasi cluster direlokasi ke
pusat (center) dengan rata-rata aritmatika dari semua data yang ditetapkan
masuk ke dalamnya. Rasionalnya langkah ini didasarkan pada observasi
untuk set tersebut (dalam hal meminimalkan jumlah kuadrat Euclidean di
antara setiap titik data dan representatif) dalah dari rata-rata dari titik data.
Hal ini jugalah yang menyebabkan metode ini sering disebut dengan cluster
19 BAB III
PERANCANGAN SISTEM
3.1 DATA
Data yang digunakan pada penelitian ini adalah citra penyakit tanaman
padi. Citra yang dikumpulkan hanya penyakit pada daun dan hanya dua penyakit
yang dikumpulkan untuk penelitian yaitu Cochliobolus Miyabeanus (Bercak
Coklat) dan Xanthomonas oryzae pv. Oryzae (Hawar Bakteri). Penulis
mengumpulkan masing-masing 10 citra untuk setiap kelompok penyakit sehingga
total citra yang digunakan sebagai data berjumlah 20 citra.
Pengumpulan data dilakukan pada bulan Agustus sampai November 2015
secara manual yaitu menyalin citra penyakit tanaman padi dari pencarian di web
page. Pencarian dan pengumpulan data menggunakan kueri Cochliobolus
Miyabeanus dan Xanthomonas oryzae pv. Oryzae. Mencari kueri Cochliobolus Miyabeanus di google search image. Kemudian lihat satu gambar dan lihat keterangan gambar untuk dapat informasi mulai dari ciri-ciri penyakit bahwa
gambar penyakit tersebut ialah penyakit Cochliobolus Miyabeanus File citra
3.1.1 Data Citra Penyakit
3.1.1.1 Citra Penyakit Cochliobolus Miyabeanus (Bercak Coklat)
Gambar 3. 1 Penyakit Cochliobolus Miyabeanus (Bercak Coklat)
3.1.1.2 Citra Penyakit Xanthomonas oryzae pv. Oryzae (Hawar Bakteri)
3.1.2 Data vektor
Data vektor dihasilkan menggunakan perintah pada Matlab yaitu
untuk mendapatkan vector Gabor Wavelet dari data 20 citra.
Data vektor tersebut dapat dilihat pada lampiran nomor 1 halaman 51.
3.2 DESKRIPSI SISTEM
Setelah citra asli diubah menjadi vektor menggunakan filter gabor wevelet,
maka vektor ini akan di proses menggunakan K-means Clustering untuk
mengelompokan vektor-vektor dengan jenis penyakit yang sama. Data yang
ada sebanyak 20 data vektor dengan dua jenis penyakit tanaman padi.
Sistem ini menggunakan rumus jarak yaitu Euclidean Distance untuk
menghitung jarak antara vektor satu ke vektor yang lain, kemudian
dikelompokkan menggunakan rumus K-Means Clustering menjadi dua
kelompok dengan menentukan titik awal dari dua vektor dengan dua jenis
3.3.1 Preprocessing Citra
Preprocesing bertujuan untuk mengubah citra asli ke dalam data vektor menggunakan filter Gabor Wavelet. Pertama membaca gambar,
kemudian gambar dirubah menjadi abu-abu. Mengubah size kolom dan
baris sampai ukuran maksimal. . Filter Gabor Wavelet dari sebuah citra
merupakan konvolusi citra dengan filter Gabor gmn. Filter Gabor
Wavelet akan dihitung untuk skala dan orientasi. Setelah filter Gabor di
konvolusi terhadap citra dengan skala m dan orientasi n, maka akan
didapat energi citra pada skala dan orientasi yang berbeda. Untuk nilai
F menggunakan perhitungan, yaitu : (kolom dikali dengan (skala
dikurang 1) ditambah 1 sebanyak kolom, baris dikali dengan (orientasi
dikurang 1) ditambah 1 sebanyak baris. Dari perhitungan tersebut di
dapat mean dan standar deviasi untuk kolom dan baris. Vektor ciri dari
sebuah citra dibuat menggunakan µmndan σmn sebagai komponen ciri.
3.3.2 K-Means Clustering
Proses K-Means Clustering ini pertama menentukan jumlah cluster
yang diingikan untuk mengelompokkan data yang ada akan menjadi
berapa kelompok. Kemudian pilih beberapa data sejumlah cluster
sebagai centroid. Perbandingkan data centroid dengan data yang lainnya
untuk mengetahui apakah data 1 dengan centroid mempunyai kemiripan
atau tidak, jika mempunyai kemiripan maka akan menjadi satu
kelompok dan begitu sebaliknya dengan mengitung menggunakan
Euclidean Distance. Kemudian setelah perhitungan tersebut
mendapatkan kelompok sejumlah cluster yang telah ditentukan, maka
kita mendapatkan centroid baru dan membandingkan centroid baru
dengan data yang lain dan mengulangi lagi lagi langkah perhitungan
Euclidean Distance sampai cluster tidak berubah atau data akhirnya
3.3.3. Perancangan hitung akurasi
Hitung akurasi dengan cara membandingkan pengelompokan
cluster dari sistem dengan cluster manual. Jika cluster sistem dengan
cluster manual sama-sama satu kelompok maka dinilai benar tetapi jika
ada yang tidak sama maka akan dinilai error. Menghitung akurasinya
cluster 1 yang dinilai benar dengan cluster 2 yang dinilai benar akan
dijumlahkan kemudian dibagi sejumlah data yang ada. Maka akan
mendapatkan berapa persen tingkat akurasi. Hal tersebut dilakukan
dengan semua data yang ada samapi mendapatkan titik akurasi paling
tinggi dari semua data.
3.4 KEBUTUHAN HARDWARE DAN SOFTWARE
3.4.1 Hardware
Spesifikasi perangkat keras yang digunakan untuk sistem yang akan
dibangun adalah sebagai berikut:
Untuk menunjang kinerja perangkat keras yang ada, dibutuhkan
perangkat lunak dengan spesifikasi sebagai berikut:
1. Sistem operasi minimal Windows 7
2. Bahasa pemrograman yang digunakan adalah java dengan
24 BAB IV
IMPLEMENTASI SISTEM
4.1 IMPLEMENTASI
4.1.1 Preprocessing
Inputan citra asli
Gambar 4. 1 Contoh Citra Penyakit
Program untuk mengubah citra asli menjadi vektor.
Memasukkan citra asli kedalam coding. Membaca citra menjadi
4.1.2 K-Means Clustering
4.1.2.1 Tampilan Antarmuka Sistem
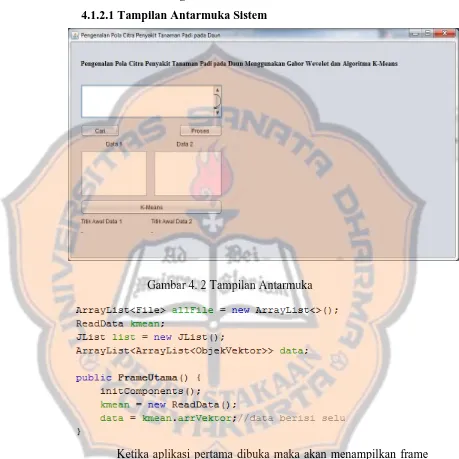
Gambar 4. 2 Tampilan Antarmuka
Ketika aplikasi pertama dibuka maka akan menampilkan frame
utama untuk form percarian data yang akan diinput untuk
tampilan data. Kemudian untuk form proses data yang sudah
diinputkan dan akan dimunculkan kedalam form data 1 dan
form data 2, selanjutkan dari form data 1 dan form data 2
tersebut dapat kita pilih data yang akan diproses kedalam
mengelompokan data-data vektor yang paling dekat akan
menjadi satu kelompok.
4.1.2.2 TAMPILAN CARI
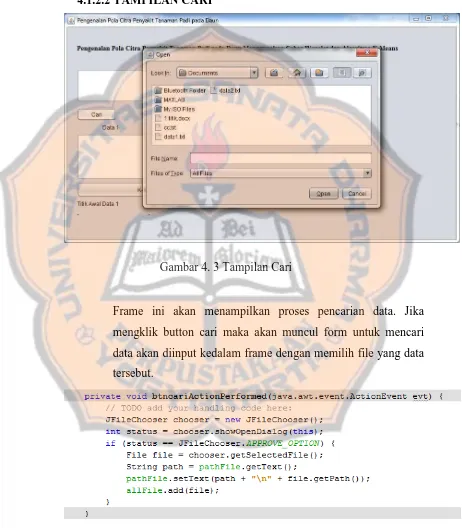
Gambar 4. 3 Tampilan Cari
Frame ini akan menampilkan proses pencarian data. Jika
mengklik button cari maka akan muncul form untuk mencari
data akan diinput kedalam frame dengan memilih file yang data
Button cari proses pencarian data dengan mencari letak file data
yang ingin dibuka, jika file yang diingikan sudah terpilih maka
dapat ditampilkan ke dalam frame tersebut.
Gambar 4. 4 Mencari Data dalam File
Jika file data sudah terpilih maka klik open untuk menampilkan
data ke dalam frame tampilan.
Frame ini menampilkan data yang sudah dicari dalam form
pencarian dan ditampilkan di dalam scrollpane yang sudah
tersedia.
Gambar 4. 6 Mencari File data2
Frame ini menampilkan untuk pencarian file data yang kedua,
karena file data yang digunakan dua maka mencari dan
membuka dua kali untuk form pencarian.
Frame ini menampilkan jumlah file data yang sudah diinputkan
ke dalam scrollpane.
4.1.2.3 TAMPILAN PROSES
Gambar 4. 8 Tampilan Proses
Frame ini menampilkan form proses data yang sudah diinput
kedalam scrollpane untuk dimunculkan kedalam scrollpane,
untuk proses pecarian data 1 maka akan muncul kedalam
tampilan scrollpane data 1 dan untuk data 2 maka akan muncul
Form proses diatas dapat menampilkan data yang ada dalam
vektor. Data tersebut ditampilkan kedalam from output data
pada aplikasi untuk mengecek bahwa data yang tampil dalam
scroll pane data 1 dan data 2 tersebut berisi data vektor sebanyak
Gambar 4. 9 Tampilan Memilih Titik Awal
Frame ini menampilkan data 1 dan data dua dapat dipilih untuk
menentukan titik awal data yang akan dihitung untuk K-Means
4.1.2.4 TAMPILAN PROSES K-MEANS
Gambar 4. 10 Tampilan Proses dan Hasil K-Means
Frame ini menampilkan perhitungan K-Means Clustering
dengan menampilkan perhitungan centroid 1 dan centroid 2,
membandingkan nilai terkecil atau perhitungan terdekat dengan
titik awal maka dikelompokkan dengan menampilkan cluster.
Cluster 1 untuk kelompok titik data awal 1 dan cluster 2 untuk
titik data awal 2. Perhitungan ini menampilkan sampai beberapa
iterasi. Iterasi akan berhenti atau selesai jika data
4.1.3 Hitung akurasi
Menghitung akurasi dari pengelompokan K-means Clustering yaitu
membandingkan tingkat kemiripan dari hasil perhitungan centroid 1
dan centroid 2. Misalnya membadingkan vektor 3 dengan vektor 13,
untuk centrod 1 menghitung kemiripan vektor 3 dengan semua vektor
dan untuk centroid menghitung kemiripan vektor 13 dengan semua
vektor. Misal, mehitung tingkat kemiripan untuk vektor 3 dengan
vektor 4 untuk centroid 1 dan menghitung vektor 13 dengan 4 untuk
perhitungan centroid 2 maka vektor 4 masuk dalam kelompok centroid
1 dan begitu sebaliknya.
Centroid 1: menghitung kemiripan vektor 3 ke semua vektor.
Untuk cluster sistem menggunakan angka, karena hanya dua cluster
maka angka yang digunakan 1 dan 2. Untuk cluster manual
Gambar diatas untuk warna kuning kelompok cluster 1 yang benar dan
untuk warna hijau kelompok cluster 2 yang benar.
Cluster 1 : 8 centroid
Cluster 2 : 5 centroid
Untuk perbandingan antara sistem dengan manual menghasilkan
penjumlahan cluster 1 dan cluster 2.
Tingkat akurasi untuk perhitungan perbandingan vektor 3 dan vektor 13
adalah 65%.
Jika sudah dapat pengelompokan cluster seperti diatas maka
membandingkan angka 1 sama dengan huruf A dan angka 2 sama
dengan huruf B. Jika cluster sistem 1 dan cluster manual A maka
pengelompokannya benar, tetapi jika cluster sistem 1 dan cluster
manual B maka disebut pengelompokan error dan begitu juga jika
cluster sistem 2 dan cluster manual B maka pengelompokannya benar,
tetapi jika cluster sistem 2 dan cluster manual A maka disebut
pengelompokan error.
Menghitung akurasi cluster untuk cluster sistem 1 dan cluster manual A
dihitung yang sama, dan untuk cluster sistem 2 dan cluster manual B
dihitung yang sama. Kemudian centroid 1 dan centroid dua yang
bernilai benar dijumlahkan. Misalnya, gambar diatas yang bernilai
benar untuk centroid 1 berjumlah 8 dengan warna kuning dan bernilai
Cluster 1 dan cluster 2 di jumlahkan yaitu 8+5= 13. Kemudian
hasil penjumlahannya dibagi dengan jumlah vektor yang ada dan di
sistem tersebut ada 20 data, maka 13/20= 0,65 hasil tersebut diubah
menjadi persen untuk hasil akurasi perbandingan pengelompokan
42 BAB V
PENGUJIAN DAN ANALISA HASIL
5.1 ANALISIS HASIL
5.1.1 UJI AKURASI
Uji akurasi ini dari data sebanyak 20 data dari dua penyakit yaitu
Cochliobolus Miyabeanus(Bercak Coklat) dan Xanthomonas Oryzae pv. Oryzae (Hawar Bakteri) masing penyakit ada 10 data. Untuk akurasi ini setiap penyakit di ambil lima gambar atau vektor dengan jarak
kemiripan paling jauh.
5.1.1.1 Hasil Uji Akurasi dari Perbandingan sistem dengan manual Tabel 5. 1 Hasil Uji Akurasi
Titik Awal
Akurasi Centroid 1 Centroid 2
Vektor 10 Vektor 19 60% Vektor 10 Vektor 20 55%
5.1.1.2 Kesimpulan akurasi
Uji akurasi diperoleh dari data sebanyak 20 data vektor dari
dua penyakit yaitu Cochliobolus Miyabeanus(Bercak coklat)
dan Xanthomonas oryzae pv. Oryzae (Hawar Bakteri)
masing-masing penyakit ada 10 data vektor. Vektor-vektor pengujian
didapat dengan membandingkan vektor 1 (citra 1) dengan semua
vektor untuk satu kelompok penyakit Cochliobolus Miyabeanus(Bercak coklat) dan membandingan vektor 11 (citra 11) dengan semua vektor untuk satu kelompok Xanthomonas
oryzae pv. Oryzae (Hawar Bakteri). Perhitungan akurasi dari pengelompokan K-means Clustering dengan membandingkan
jarak kemiripan dari hasil perhitungan centroid 1 dan centroid 2
untuk memndapatkan cluster setiap centroid. Jika hasil
perhitungan jarak centroid lebih dekat ke centroid 1 maka akan
dikelompokkan ke centroid 1 dan jika hasil perhitungan jarak
centroid lebih dekat ke centroid 2 maka akan dikelompokkan ke
centroid 2. Dari hasil pengelompokkan tersebut akan diuji
akurasi hasil pengelompokan sistem dengan hasil
pengelompokkan manual. Jika kelompok sistem dengan
kelompok manual mempunyai cluster yang sama maka
pengelompokkan benar tetapi jika tidak mempunyai kelompok
yang sama maka pengelompokkan error. Cluster sistem dan
cluster manual yang pengelompokkannya benar dijumlahkan,
ada 2 cluster dalam pengelompokkan tersebut cluster 1 yang
benar dijumlahkan dan cluster 2 yang benar dijumlahkan.
Kemudian cluster 1 dan cluster 2 dijumlahkan dan hasil
penjumlahan dibagi dengan 20 data yang digunakan dalam
untuk hasil akurasi. Dengan perbandingan tersebut
memndapatkan tingkat akurasi paling tinggi yaitu 70% dan
akurasi paling rendah 55% dari 100 uji akurasi. Tingkat akurasi
tertinggi didapat dengan perhitungan perbandingan vektor 6
dengan vektor 18 dan perbandingan vektor 4 dengan vektor 11
dari perhitungan tersebut mendapatkan tingkat akurasi sebesar
70% dari 100 pengujian ada dua uji akurasi yang tingkat
akurasinya 70%. Untuk tingkat akurasi paling rendah didapat
dari perhitungan tersebut mendapatkan tingkat akurasi 55% dari
100 pengujian ada 34 perbandingan yang mendapatkan tingkat
akurasi 55%.
Dari data citra asli diubah menjadi vektor sebanyak 20 data
dari 2 penyakit, kemudian di kelompokkan menggunakan
K-Means Clustering. Hasil pengelompokkan K-K-Means Clustering, kemudian di uji akurasi dengan membandingan cluster sistem
dengan cluster manual dan di dapat hasil dari tingkat akurasi
tertinngi sebesar 70% dan tingkat akurasi paling rendah sebesar
47 BAB VI
PENUTUP
5.1 Kesimpulan
Berdasarkan hasil penelitian ini, pengenalan pola citra tanaman padi pada
daun menggunakan Gabor Wavelet dan K-Means Clustering, di peroleh
kesimpulan sebagai berikut:
1. Uji akurasi diperoleh dari data sebanyak 20 data dari dua penyakit yaitu
Cochliobolus Miyabeanus(Bercak coklat) dan Xanthomonas oryzae pv. Oryzae (Hawar Bakteri) masing-masing penyakit ada 10 data.
2. Perhitungan akurasi dari pengelompokan K-means Clustering dengan
membandingkan jarak kemiripan dari hasil perhitungan centroid 1 dan
centroid 2 untuk memndapatkan cluster setiap centroid Cluster sistem dan
cluster manual yang pengelompokkannya benar dijumlahkan, ada 2 cluster
dalam pengelompokkan tersebut cluster 1 yang benar dijumlahkan dan
cluster 2 yang benar dijumlahkan. Kemudian cluster 1 dan cluster 2
dijumlahkan dan hasil penjumlahan dibagi dengan 20 data yang digunakan
dalam sistem ini. Hasil pembagian tersebut diubah menjadi persen untuk
hasil akurasi. Dengan perbandingan tersebut memndapatkan tingkat
akurasi paling tinngi yaitu 70% dan akurasi paling rendah 55% dari 100 uji
akurasi. Vektor yang digunakan untuk perbandingan uji akurasi 20 vektor.
5.2 Saran
Berikut ini adalah saran yang dapat membantu peneliti ini agar lebih baik dan
berkembang:
1. Sistem dapat dikembangkan dengan penyakit tamanan pada padi lebih
banyak dan lebih komplit.
2. Data yang digunakan lebih banyak sehingga dapat mencakup lebih banyak
3. Jumlah data yang digunakan lebih banyak dalam pengujian akurasi
sehingga tingkat akurasinya lebih tinggi.
4. Pengumpulan data dilakukan menggunakan hasil foto asli agar lebih tinggi
49
DAFTAR PUSTAKA
Fadhilah, Anisa Nurul dkk. Perncangan Aplikasi Sistem Pakar Penyakit
Kulit pada Anak dengan Metode Expert System Development Life Cycle.Vol 09
No. 13 2012.
Ferdian, Erhandkk. Sistem Pakar Mengidentifikasi Kerusakan Gangguan
Sambungan Telepon PT. TELKOM. 2001
Gunadharma. Modul Kuliah Pengenalan Sistem pakar.
ITS EDU. Modul Kuliah Sistem Pakar Teknik Informatika.
Kadir, Abdul and Susanto, Adhi. Teori dan Aplikasi Pengolahan Citra.
Yogyakarta:ANDI.
Prasetyo, Eko. 2014. Data Mining Mengolah Data Menjadi Informasi
Menggunakan Matkab. Yogyakarta:ANDI.
Putra, Dharma. 2010. Pengolahan Citra Digital. Yogyakarta:ANDI.
Sutoyo, T dkk. 2009. Teori Pengolahan Citra Digital. Yogyakarta:ANDI.
Wijono, Sri Hartati, and Aniati Murni. "PENAMBANGAN CITRA
INDERAJA MENGGUNAKAN INFORMASI SPASIAL DAN
SPEKTRAL." Seminar Nasional Aplikasi Teknologi Informasi (SNATI). 2010.
50
LAMPIRAN I
I. Data vektor
I.1. Data Cochliobolus Miyabeanus (Bercak Coklat)
I.2. Vektor Xanthomonas oryzae pv. Oryzae (Hawar Bakteri)
LAMPIRAN II
II. PROGRAM