K-Means Analysis Klasterisasi Kasus HIV/AIDS di Indonesia
Okta Riveranda
1), Warnia Nengsih, S.Kom., M.Kom.
2)1) Program Studi Sistem Informasi , Politeknik Caltex Riau, Pekanbaru 28265, email:
okta12si@mahasiswa.pcr.ac.id
2) Program Studi Sistem Informasi, Politeknik Caltex Riau, Pekanbaru 28265, email: warnia@pcr.ac.id Abstrak – Penggabungan Data mining dengan kemampuan dalam mengelola dan mengolah database, statistika dan kecerdasan buatan telah banyak diterapkan dalam berbagai bidang. Penerapannya beragam, tergantung pada bagaimana data itu didistribusikan dan dimanfaatkan. Ada yang diterapkan di bidang kemiliteran, pendidikan, kesehatan, keuangan dan masih banyak lagi lainnya. Tujuan utama dari penelitian ini ialah untuk menganalisis jumlah kasus HIV/AIDS yang ada di Indonesia dengan penyebaran di 33 provinsi. Data yang dijadikan sumber berasal dari Ditjen PP & PL Kemenkes RI. Analisis didukung dengan teknik clustering dengan pemilihan algoritma k-means dalam mengidentifikasi similaritas antar data. Jumlah kluster yang ditentukan dalam implementasi algoritma k-means adalah 3 kluster. Masing-masing kluster memiliki nilai rata-rata yang berbeda.
Masing-masing kluster menunjukkan label tingkat kerawanan terjadinya HIV di provinsi-provinsi di Indonesia.
Data dengan bar terendah mewakili kluster 1. Memiliki karakteristik data dengan anggota-anggota data yang jumlah kasus HIV-nya sedang mewakili kluster 2. Sementara bar tertinggi mewakili kluster 3 yang karakteristik datanya menunjukkan jumlah kasus HIV terbesar
Kata Kunci : Clustering, Data Mining, HIV/AIDS, Kesehatan, k-Means.
1. PENDAHULUAN
HIV/AIDS atau human immunodeficiency virus/aquired immune deficiency syndrome adalah suatu spektrum kondisi yang disebabkan oleh infeksi virus HIV. Diawali dengan adanya infeksi tersebut, seseorang yang terkena virus ini akan mengalami sakit seperti influenza. Hal tersebut biasanya diikuti dengan tanpa gejala yang cukup berkepanjangan.
Indonesia merupakan salah satu negara yang memiliki potensi kenaikan jumlah kasus HIV/AIDS tiap tahunnya. Hal itu dapat dilihat dari data yang diperoleh dari tahun 1987-2014 untuk AIDS dan dari tahun 2005-2014 untuk HIV. Kenaikan signifikan terjadi di hampir seluruh provinsi yang ada di Indonesia. Bukan hanya itu, kasus penderita yang meninggal akibat AIDS juga menjadi faktor penentu kenaikan potensi tersebut. Apabila pemerintah tidak menanggulangi kejadian ini, dikhawatirkan ke depannya Indonesia akan menjadi salah satu negara penyumbang terbesar penderita HIV/AIDS.
Data mining merupakan suatu disiplin ilmu dalam ilmu komputer yang digunakan untuk tujuan menggali informasi tersembunyi dari sekumpulan data set untuk kemudian digunakan dalam pengambilan keputusan maupun kebijakan yang berguna dalam bidang-bidang tertentu. Merujuk kepada kasus HIV/AIDS yang ada di Indonesia, dan dengan tersedianya data mentah yang dapat diolah, penelitian ini dapat dikembangkan untuk membantu pemerintah dalam melihat daerah atau provinsi dengan potensi HIV/AIDS terburuk. Oleh karena itu, dengan menggunakan metode clustering K-Means, diperoleh gambaran dari setiap wilayah di Indonesia
untuk pengambilan kebijakan dan strategi berikutnya..
2. LANDASAN TEORI 2.1 Data Mining
Data mining adalah disiplin ilmu yang membahas mengenai proses penggalian informasi, pengetahuan dan/atau pola menarik dari sekumpulan data yang berukuran sangat besar. Data tersebut tersimpan di dalam beberapa database, sebuah data warehouse, ataupun media penyimpanan data lainnya. Disiplin ilmu ini merupakan irisan dari beberapa disipilin ilmu yang sudah lebih dulu ada seperti, kemampuan pengelolaan database, statistika, matematika, visualisasi data, machine learning dan artificial intelligence (Han dan Kamber, 2006)[1].
Terlepas dari definisi-definisi data mining di atas, masih banyak peneliti yang memperdebatkan penamaan yang cocok untuk aktifitas ini. Karena, jika dianalogikan ke dalam contoh aktifitas penggalian dalam kehidupan nyata seperti penggalian emas, istilah data mining dirasa kurang tepat. Emas merupakan hasil yang diinginkan atau yang ingin dicapai dari sekumpulan aktifitas penggalian emas. Untuk mencapainya, diperlukan usaha yang besar untuk menggali bebatuan yang ada di sekitarnya. Aktifitas ini tidak disebut dengan rock mining ataupun sand mining, namun tetap disebut sebagai gold mining. Karena pada dasarnya, emas lah yang menjadi capaian akhir dari aktifitas tersebut. Oleh karena itu, beberapa peneliti memberikan nama lain untuk data mining sebagai
ganti untuk istilah yang menurut mereka kurang tepat tersebut, diantara lain, ada yang menyebut dengan Knowledge Discovery in Data (KDD), knowledge mining, knowledge extraction, dan data/pattern analysis (Han dan Kamber, 2006)[2].
2.2 Clustering
Clustering atau juga dikenal dengan istilah cluster analysis adalah salah satu metode atau teknik dalam data mining yang tepat digunakan untuk mengolah data yang tidak diketahui label atau kelasnya. Cara kerja teknik ini ialah mengelompokkan sekumpulan data ke dalam kelas-kelas atau kluster-kluster, yang mana objek-objek yang ada pada kelas tersebut memiliki similaritas yang tinggi jika dibandingkan dengan objek lain yang ada dalam kelas tersebut, namun memiliki similaritas yang rendah jika dibandingkan dengan objek yang ada di kelas/kluster lain (Han dan Kamber, 2006)[3].
Dalam sekelompok data, akan ada beberapa objek data yang ditempatkan ke dalam kluster yang sama berdasarkan sifat dan karakteristik data tersebut.
Namun, dalam kasus tertentu, akan ada suatu objek data yang memiliki karakteristik dan sifat yang sangat berlainan dengan data lain, dan biasanya, data ini ditempatkan ke dalam kluster tersendiri. Jumlah anggota kluster yang menempati kluster itu biasanya sangat sedikit jika dibandingkan dengan rasio jumlah data yang ada. Data tersebut dikenal dengan istilah data anomali atau outlier. Salah satu keunggulan teknik clustering ialah dapat mendeteksi data outlier (outlier detection) karena tidak adanya label/kelas ketika data ini pertama kali diolah (Han dan Kamber, 2006)[4].
2.3 Euclidean Distance
Euclidean Distance merupakan algoritma pengukur interval jarak antara satu data dengan data yang lain. Selain algoritma ini, juga ada algoritma Manhattan Block yang juga memiliki fungsi yang sama. Namun, algoritma k-means yang digunakan dalam penelitian ini menggunakan euclidean distance untuk mengukur similaritas antar data. Formulanya dapat didefinisikan sebagai berikut:
𝑑(𝑖, 𝑗)
= √(𝑥𝑖1− 𝑥𝑗1)2+ (𝑥𝑖2− 𝑥𝑗2)2+. . . +(𝑥𝑖𝑥− 𝑥𝑗𝑥)2. . . (2.1)
Keterangan:
d: Distance/jarak antara objek i ke objek j.
xi: variabel objek i.
xj: variabel objek j.
Dapat ditarik kesimpulan bahwa, semakin rendah nilai distance antar objek data, maka akan semakin tinggi similaritasnya[5].
2.4 K-means
Algoritma k-means menggunakan masukan berupa parameter, jumlah k, dan sekumpulan data set dari sekian objek untuk dimasukkan ke dalam k kelas/kluster sehingga similaritas intrakluster semakin tinggi sedangkan similaritas antarkluster semakin rendah. Similaritas kluster diukur berdasarkan nilai rata-rata dari keseluruhan objek yang ada di kluster tersebut, yang bisa dipandang sebagai pusat kluster.
Cara kerja k-means adalah sebagai berikut.
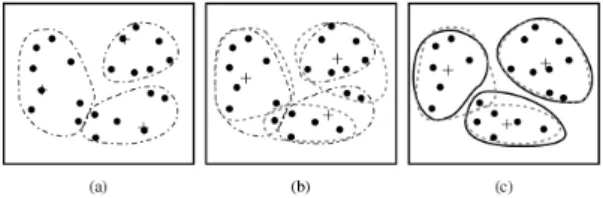
Pertama, algoritma ini akan memilih sejumlah k objek dari beberapa objek yang ada pada sekumpulan data. Masing-masing objek yang terpilih, merepresentasikan nilai rata-rata dari sejumlah k kluster. Kemudian objek yang tersisa, masing-masing akan di-assign ke dalam kluster yang sudah ditentukan berdasarkan similaritasnya dengan nilai rata-rata masing- masing kluster. Setelah itu, dilakukan perubahan nilai rata-rata kluster yang sudah menjadi beberapa anggota kluster. Ketiga langkah di atas dilakukan secara iteratif (berulang) hingga tidak ada lagi perubahan nilai rata-rata dan seluruh data sudah didistribusikan ke masing-masing kluster yang ada[6].
Gambar 1 Hasil analisis kluster dengan algoritma k-means
3. METODE PENELITIAN 3.1. Pemilihan Atribut
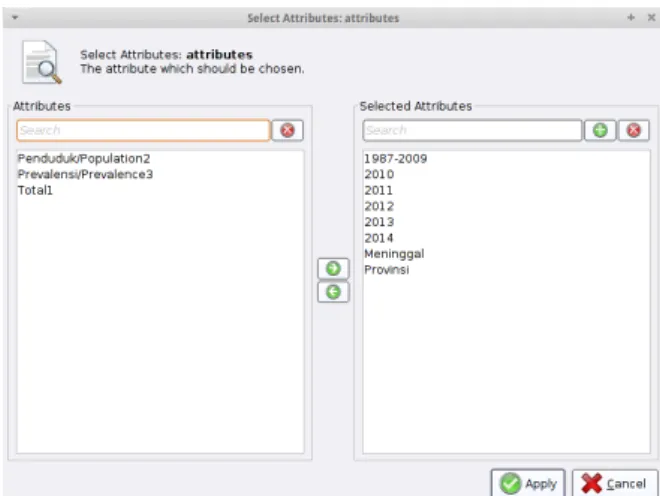
Pemilihan atribut dilakukan agar dalam analisis kluster hanya atribut yang memiliki nilai keterkaitan paling tinggi sajalah yang akan diproses. Atribut-atribut yang dianggap tidak mewakili objek data tidak akan digunakan dalam proses analisis. Berikut ini adalah gambar yang diambil dari rapidminer ketika melakukan pemilihan atribut.
Gambar 2 Pemilihan Atribut
Atribut-atribut yang dipilih sebagai predictor variable adalah sebagai berikut: Kasus pada tahun 1987-2009, 2010, 2011, 2012, 2013, 2014 dan jumlah korban meninggal. Sementara provinsi hanya digunakan sebagai kolom ID.Sumber data terdiri dari beberapa sheet, namun hanya digunakan 2 sheet saja sebagai data mentah untuk diolah. Kasus untuk HIV-AIDS dipisahkan untuk masing-masing sheet.
Untuk kasus AIDS, datanya terdiri dari tahun 1987 hingga 2014, sementara untuk kasus HIV, dari tahun 2005 hingga 2014. Keduanya menggunakan provinsi-provinsi di Indonesia sebagai objek data.
3.2. Implementasi algoritma k-means
Gambar di bawah ini menampilkan informasi dan opsi yang diatur sedemikian rupa untuk memproses data yang sudah dibersihkan pada tahap preprocessing.
Gambar 3 Implementasi algoritma k- means
Opsi add cluster atribut secara default sudah terpilih sejak pengambilan operator k-means ke dalam bagan proses. Sementara opsi add as label digunakan apabila ingin menjadikan kluster tersebut sebagai label bagi proses selanjutnya. Kolom k pada gambar di atas merepresentasikan jumlah kluster yang objek-objek data akan didistribusikan ke dalamnya.
Kolom max runs adalah jumlah iterasi maksimal yang boleh dilakukan dalam proses analisis kluster.
4. HASIL DAN PEMBAHASAN Jumlah kluster yang ditentukan dalam implementasi algoritma k-means adalah 3 kluster. Masing-masing kluster memiliki nilai rata-rata yang berbeda.
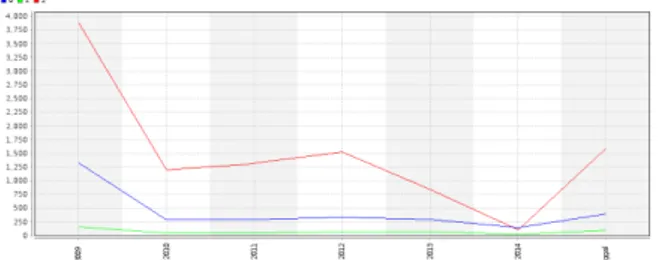
Sebagai langkah identifikasi awal, apabila diamati masing-masing kluster, maka peneliti bisa mengasumsikan masing-masing kluster itu sebagai label tingkat kerawanan terjadinya HIV di provinsi- provinsi di Indonesia. Data dengan bar terendah mewakili kluster 1. Memiliki karakteristik data dengan anggota-anggota data yang jumlah kasus HIV-nya sedang. Data dengan bar menengah mewakili kluster 2. Karakteristiknya, jumlah kasus pada tiap anggota kluster adalah yang terendah di antara yang lain. Sementara bar tertinggi mewakili kluster 3 yang karakteristik datanya menunjukkan jumlah kasus HIV terbesar. Berikut ini adalah grafik dari hasil perhitungan manual k-means dengan aplikasi pengolah angka LibreOffice Calc 4.4.
Gambar 4 Grafik hasil analisis kluster manual pada kasus HIV
Untuk menghasilkan grafik di atas, dibutuhkan iterasi manual algoritma k-means sebanyak 4 kali sehingga tiap data secara konsisten berada pada masing-masing klusternya. Sementara itu, hasil dari analisis kluster dengan k-means menggunakan aplikasi RapidMiner v5.3 adalah sebagai berikut:
Gambar 5 Grafik hasil analisis kluster kasus HIV dengan aplikasi RapidMiner
Grafik di atas menunjukkan bahwa jumlah dan sebaran data untuk masing-masing kluster adalah sama dengan hasil analisis kluster manual yang dilakukan pada aplikasi pengolah angka. Provinsi DKI Jakarta, Jawa Timur dan Papua sama-sama berada pada kluster dengan ciri jumlah kasus HIV terbanyak di Indonesia. Begitu pula provinsi- provinsi yang menjadi anggota kluster dengan jumlah kasus terendah dan sedang.
Sementara itu, hasil perhitungan manual k-means pada kasus AIDS di Indonesia dapat dilihat pada grafik di bawah ini.
Gambar 6 Grafik hasil analisis kluster manual pada kasus AIDS
Data dengan bar terendah adalah provinsi-provinsi yang memiliki jumlah kasus AIDS terendah. Lalu, data dengan bar sedang adalah provinsi-provinsi dengan jumlah kasus AIDS tertinggi. Terakhir, data dengan bar tertinggi adalah provinsi-provinsi dengan jumlah kasus AIDS menengah. Untuk menghasilkan grafik seperti di atas, diperlukan proses k-means manual sebanyak 3 kali iterasi.
Gambar 7 Grafik hasil analisis kluster kasus AIDS dengan aplikasi RapidMiner
Berbeda halnya dengan hasil yang didapatkan dari analisis kluster dengan aplikasi RapidMiner pada kasus AIDS, pada grafik di bawah ini, hanya kluster dengan jumlah kasus tertinggi saja lah yang anggotanya konsisten dengan grafik dari hasil manual. Provinsi DKI Jakarta, Jawa Timur dan Papua berada pada kluster dengan jumlah kasus terbanyak di antara provinsi lain. Sementara untuk kluster lain, ada beberapa anggota kluster yang tidak konsisten dengan keanggotaannya. Berikut tabel yang menunjukkan perbedaan antara hasil manual dengan RapidMiner:
Tabel 1 Perbandingan hasil manual terhadap RapidMiner pada kasus AIDS
Manual RapidMiner Cluster 'Ringan' - Papua
Barat - Sulawesi Selatan - Sumatera Utara
N/A
Cluster 'Menengah' N/A - Papua Barat - Sulawesi Selatan - Sumatera Utara Cluster 'Terbanyak' N/A N/A
Berdasarkan tabel di atas, dapat diambil diketahui bahwa, pada kluster dengan kasus AIDS paling ringan, hasil manual berlebih 3 objek data, yang mana objek-objek data tersebut justru berada di kluster menengah pada hasil dengan RapidMiner.
5. KESIMPULAN
Berdasarkan hasil analisis kluster pada data kasus HIV dan AIDS yang ada di Indonesia, dapat ditarik kesimpulan bahwa provinsi DKI Jakarta, Jawa Timur dan Papua berada dalam kondisi yang sangat kritis dan sangat rentan akan penyebaran virus HIV/AIDS. Hal itu dikarenakan jumlah kasus HIV dan AIDS terbanyak ada pada ketiga provinsi tersebut. Untuk itu, kampanye dan kebijakan pemerintah dapat difokuskan secara langsung kepada ketiga provinsi itu.
DAFTAR REFERENSI
[1] Han, Jiawei; Kamber, Micheline, Data Mining: Concepts and Techniques 2nd Edition, (2006) Morgan Kaufmann Publishers, San Fransisco. Hal. 5-6.
[2] Han, Jiawei; Kamber, Micheline, Data Mining: Concepts and Techniques 2nd Edition, (2006) Morgan Kaufmann Publishers, San Fransisco. Hal. 6-7.
[3] Han, Jiawei; Kamber, Micheline, Data Mining: Concepts and Techniques 2nd Edition, (2006) Morgan Kaufmann Publishers, San Fransisco. Hal 383.
[4] Han, Jiawei; Kamber, Micheline, Data Mining: Concepts and Techniques 2nd Edition, (2006) Morgan Kaufmann Publishers, San Fransisco. Hal. 384.
[5] Han, Jiawei; Kamber, Micheline, Data Mining: Concepts and Techniques 2nd Edition, (2006) Morgan Kaufmann Publishers, San Fransisco. Hal. 388-389.
[6] Han, Jiawei; Kamber, Micheline, Data Mining: Concepts and Techniques 2nd Edition, (2006) Morgan Kaufmann Publishers, San Fransisco. Hal. 402-403.
[7] Ditjen PP & PL Kemenkes RI