KLASIFIKASI TIPE KEPRIBADIAN PENGGUNA SOSIAL MEDIA BERDASARKAN TEORI BIG FIVE MENGGUNAKAN
K-NEAREST NEIGHBOR
NABILA HUTAGALUNG 121402040
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2018
KLASIFIKASI TIPE KEPRIBADIAN PENGGUNA SOSIAL MEDIA BERDASARKAN TEORI BIG FIVE MENGGUNAKAN K-NEAREST NEIGHBOR
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
NABILA HUTAGALUNG 121402040
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2018
PERNYATAAN
KLASIFIKASI TIPE KEPRIBADIAN PENGGUNA SOSIAL MEDIA BERDASARKAN TEORI BIG FIVE MENGGUNAKAN K-NEAREST NEIGHBOR
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 28 Mei 2018
Nabila Hutagalung 121402040
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan ke hadirat Tuhan Yang Maha Esa yang telah memberikan rahmat serta restu-Nya sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana.
Pertama, penulis ingin mengucapkan terima kasih kepada Bapak Dani Gunawan, ST., M.T selaku pembimbing pertama dan Ibu Dr.Erna Budhiarti Nababan, M.IT selaku pembimbing kedua yang telah meluangkan waktu serta tenaganya untuk membimbing penulis dalam penelitian serta penulisan skripsi ini. Tanpa inspirasi serta motivasi yang diberikan oleh kedua pembimbing, tentunya penulis tidak akan dapat menyelesaikan skripsi ini. Penulis juga mengucapkan terima kasih kepada Bapak Dr.Sawaluddin, M.IT sebagai dosen pembanding pertama dan Ibu Ulfi Andayani, S.Kom., M.Kom sebagai dosen pembanding kedua yang telah memberikan masukan serta kritik yang bermanfaat dalam penulisan skripsi ini. Ucapan terima kasih juga ditujukan kepada semua dosen serta pegawai di lingkungan Fakultas Ilmu Komputer dan Teknologi Informasi yang turut membantu serta membimbing penulis selama proses perkuliahan.
Penulis tentunya tidak lupa berterima kasih juga kepada kedua orang tua penulis, yaitu Bapak Alm.Hasbullah Hutagalung, SH dan Ibu Hj.Deliana Rasyid, SH yang telah membesarkan penulis dengan sabar dan penuh kasih sayang, serta doa dan dukungan berupa moral maupun materiil yang selalu menyertai selama ini. Penulis juga berterima kasih kepada seluruh anggota keluarga penulis yang namanya tidak dapat disebutkan satu persatu.
Terima kasih juga penulis ucapkan kepada sahabat seperjuangan di kampus yang telah memberikan dukungan dan bantuan selama masa perkuliahan ini, khususnya Ramadan Putra Siregar, Nur Amalia, Safrida Budiarti, Nelam Mariani, Joko Kurnianto serta seluruh teman-teman angkatan 2012 dan mahasiswa Teknologi Informasi lainnya yang namanya tidak dapat disebutkan satu persatu.
ABSTRAK
Sekarang ini, hampir tiap orang mempunyai sosial media. Twitter adalah salah satu sosial media yang digemari di Indonesia. Semua orang dapat memberikan opini pribadinya di laman twitter pribadi mereka. Beberapa perusahaan menjadikan aktivitas sosial sebagai salah satu parameter dalam merekrut pegawainya. Tiap orang memiliki pola dalam menggunakan sosial media berdasarkan tipe kepribadian mereka. Namun, karena tingginya aktivitas sosial media dan miripnya kecenderungan pola aktivitas sosial media beberapa tipe kepribadian menyebabkan HRD kesulitan untuk menganalisis data tekstual tersebut secara manual. Oleh karena itu, penelitian ini menggunakan algoritma K-Nearest Neighbor untuk menganalisis data tekstual yang berupa aktivitas sosial media pengguna Twitter tersebut dengan mengklasifikasikannnya menjadi beberapa kelas, yakni tipe kepribadian Big 5. Pada penelitian ini metode yang digunakan terbagi menjadi empat tahapan. Tahapan pertama yaitu web extraction untuk mendapatkan data aktivitas sosial media pengguna Twitter dengan memanfaatkan Twitter API. Tahapan kedua adalah ekstraksi data-data yang diperlukan untuk proses pengklasifikasian, yakni seperti jumlah tweet, retweet, likes, following dan follower. Tahapan ketiga yaitu proses klasifikasi menggunakan algoritma K-Nearest Neighbor dengan jumlah data latih sebanyak 70 akun twitter.
Data pelatihan akan terus bertambah karena data uji yang telah diklasifikasikan akan ditambahkan sebagai data latih baru. Kemudian data uji sebanyak 30 akun pengguna twitter. Tahapan terakhir yaitu proses menampilkan hasil kepribadian pengguna twitter yang telah diklasifikasikan. Kemudian hasil klasifikasi sistem akan dibandingkan dengan hasil survey psikologi dari situs openpsychometrics untuk menguji tingkat akurasi sistem. Hasil evaluasi yang didapat dari penelitian ini dengan data uji berjumlah dari 30 akun pengguna twitter adalah akurasi yang mencapai 90%.
Kata kunci: Big 5, Klasifikasi, Twitter, K-Nearest Neighbor, Sosial Media
CLASSIFICATION OF SOCIAL MEDIA USERS 'PERSONALITY TYPE BASED ON BIG FIVE USING THEORY
K-NEAREST NEIGHBOR
ABSTRACT
Today, almost everyone has social media. Twitter is one of the popular social media in Indonesia. Everyone can give their personal opinion on their personal twitter page.
Some companies make social activities as one of the parameters in recruiting employees. Each person has a pattern in using social media based on their personality type. However, due to the high social media activity and the similar tendency of the social media activity patterns of some personality types cause HRD difficulties to analyze the textual data manually. Therefore, this research uses K-Nearest Neighbor algorithm to analyze textual data in the form of social activity of Twitter user's media by classifying it into several classes, that is Big 5 personality type. In this research the method used is divided into four stages. The first step is web extraction to get the data of social activity of Twitter user media by utilizing Twitter API. The second stage is the extraction of data needed for the process of classification, such as the number of tweets, retweets, likes, following and follower. The third stage is the process of classification using K-Nearest Neighbor algorithm with the amount of data train as much as 70 twitter account. Training data will continue to grow as tested data will be added as new training data. Then test data as many as 30 twitter user account. The last stage is the process of displaying the results of personality twitter users who have been classified. Then the results of the classification system will be compared with the results of psychological surveys from the site openpsychometrics to test the system accuracy. The results of the evaluation obtained from this study with test data amounting from 30 twitter user account is accuracy reaching 90%.
Keywords: Big 5, Classification, Twitter, K-Nearest Neighbor, Social Media
DAFTAR ISI
Hal.
PERSETUJUAN i
PERTANYAAN ii
UCAPAN TERIMA KASIH iii
ABSTRAK iv
ABSTRACT v
DAFTAR ISI vi
DAFTAR TABEL ix
DAFTAR GAMBAR x
BAB 1 PENDAHULUAN 1 1.1. Latar Belakang 1
1.2. Rumusan Masalah 2 1.3. Tujuan Penelitian 3 1.4. Batasan Masalah 3
1.5. Manfaat Penlitian 3 1.6. Metodologi Penelitian 3 1.7. Sistematika Penulisan 5 BAB 2 LANDASAN TEORI 6 2.1. Teori Big Five 6 2.2. Data Mining 10
2.3. Twitter API 12
2.4. Klasifikasi 15
2.5. K-Nearest Neighbor 15
2.6. Penilitian Terdahulu 24
BAB 3 ANALISIS DAN PERANCANGAN 27
3.1. Arsitekur Umum 27
3.2. Data yang Digunakan 28
3.3. Pre-processing 30
3.3.1. Memisahkan Postingan Tweet dan Retweet 30
3.3.2. Menghitung Jumlah Tweet 30
3.3.3. Menghitung Jumlah Retweet 30
3.3.4. Mengitung Jumlah Follower 31 3.3.5. Menghitung Jumlah Following 31
3.3.6. Menghitung Jumlah Likes 31
3.4. Klasifikasi 31
3.5. Perancangan Sistem 45
BAB 4 IMPLEMENTASI DAN PENGUJIAN 51
4.1. Spesikasi Perangkat Keras dan Perangkat Lunak 51
4.2. Implementasi Perancangan Antarmuka 51
4.2.1. Halaman utama (dashboard) 52
4.2.2. Tampilan halaman data latih 52
4.2.3. Tampilan halaman data Uji 53
4.2.4. Tampilan halaman KNN 54
4.2.5. Tampilan halaman proses 54
4.3. Data Latih 55
4.. Data Uji 58
4.4.1. Hasil Perhitungan K-Nearest Neighbor 58
4.5. Hasil Evaluasi 66
4.5.1. Akurasi 66
BAB 5 KESIMPULAN DAN SARAN 68
5.1. Kesimpulan 68
5.2. Saran 68
DAFTAR PUSTAKA 69
LAMPIRAN : Data Uji 70
DAFTAR TABEL
Tabel 2.1. Tabel Kasus 17
Tabel 2.2. Definisi Bobot Atribut 18
Tabel 2.3. Kedekatan Nilai Atribut Jenis Kelamin 18 Tabel 2.4. Rincian Kedekatan Nilai Atribut Jenis Kelamin 18
Tabel 2.5. Kedekatan Nilai Atribut Pendidikan 19
Tabel 2.6. Rincian Kedekatan Nilai Atribut Pendidikan 19
Tabel 2.7. Kedekatan Nilai Atribut Status 20
Tabel 2.8. Rincian Kedekatan Nilai Atribut Status 20
Tabel 2.9. Penelitian Terdahulu 26
Tabel 3.1. Range Jumlah Tweets 32
Tabel 3.2. Range Jumlah Retweet 33
Tabel 3.3. Range Jumlah Likes 33
Tabel 3.4. Range Jumlah Following 34
Tabel 3.5. Range Jumlah Followers 34
Tabel 3.6. Contoh Beberapa Data Latih 35
Tabel 3.7. Definisi Bobot Parameter 35
Tabel 3.8. Kedekatan Nilai Atribut Tweets 36
Tabel 3.9. Kedekatan Nilai Atribut Likes 36
Tabel 3.10. Kedekatan Nilai Atribut Following 36
Tabel 3.11. Kedekatan Nilai Atribut Followers 37
Tabel 3.12. Kedekatan Nilai Atribut Retweet 37
Tabel 3.13. Nilai Kedekatan secara keseluruhan 37
Tabel 4.1. Contoh Beberapa Data Latih 57
Tabel 4.2. Contoh Beberapa Hasil Klasifikasi 65
Tabel 4.3. Hasil Pengujian 66
Tabel 4.4. Hasil Pengujian Tiap Akurasi 67
Tabel 4.5. Analisis Hasil Penulusan 67
DAFTAR GAMBAR
Gambar 2.1. Arsitektur Twitter API 13
Gambar 2.2. Ilustrasi Kedekatan Status 16
Gambar 3.1. Arsitektur Umum 28
Gambar 3.2. Form Kuesioner Survey 29
Gambar 3.3. Contoh Hasil Kepribadian Partisipan Berdasarkan Survey 29
Gambar 3.4. Tampilan Utama 45
Gambar 3.5. Rancangan Tampilan Halaman Data Latih 46
Gambar 3.6. Rancangan Tampilan Proses Data Latih 47
Gambar 3.7. Rancangan Tampilan Halaman Data Uji 48
Gambar 3.8. Rancangan Tampilan Halaman Proses Data Uji 48
Gambar 3.9. Rancangan Tampilan Halaman KNN 49
Gambar 3.10. Rancangan Tampilan Halaman Hasil Proses KNN 50
Gambar 4.1. Halaman Utama (Dashboard) 52
Gambar 4.2. Tampilan halaman data latih 53
Gambar 4.3. Tampilan data uji 53
Gambar 4.4. Tampilan halaman KNN 54
Gambar 4.5. Tampilan Proses 54
Gambar 4.6. Kuesioner Tes Kepribadian Big 5 55
Gambar 4.7. Hasil kepribadian Tes Big 5 56
BAB 1 PENDAHULUAN
1.1 Latar Belakang
Big Five Personality merupakan pendekatan dalam psikologi kepribadian yang mengelompokkan kepribadian dengan analisis faktor. Tokoh pelopornya adalah Allport dan Cattell. Big Five Personality adalah suatu pendekatan yang digunakan dalam psikologi untuk melihat kepribadian manusia melalui lima buah domain kepribadian yang telah dibentuk dengan menggunakan analisis faktor. Berdasarkan teori kepribadian big five Lewis R. Goldberg (1981) manusia digolongkan menjadi lima jenis kepribadian, yaitu Openness (O), Conscientiousness(C), Extraversion (E), Agreeableness(A), Neuroticism(N). Saat ini banyak perusahaan menjadikan sosial media pelamar menjadi salah satu aspek penilaian dalam proses rekrutmen pegawai.
Berdasarkan konten yang paling sering dikunjungi, pengguna internet paling sering mengunjungi situs onlineshop sebesar 82,2 juta atau 62%. Selain itu, situs yang banyak dikunjungi oleh pegguna internet adalah social media. Berdasarkan hasil survey Asosiasi Penyelenggara Jasa Internet Indonesia (APJII) pada tahun 2016, pengguna aktif media sosial Twitter di Indonesia sebanyak 7,2 juta akun.
Indonesia juga sering menjadi Trending Topik Dunia karena banyaknya tweet yang masuk dari pengguna twitter Indonesia. Hal tersebut yang melatar belakangi penulis untuk melakukan penelitian menggunakan objek media sosial Twitter.
Untuk menempatkan orang yang tepat pada suatu pekerjaan, pewawancara perlu memperhatikan kepribadian pelamar tersebut apakah akan sesuai dengan pekerjaan yang akan diembannya. Ketidaksesuaian pekerjaan terhadap kepribadian akan merugikan perusahaan dan karyawan itu sendiri. Salah satu contoh ketidaksesuaian penempatan karyawan yang tidak tepat adalah seorang yang pemalu ditempatkan sebagai customer service. Alat ukur kepribadian dapat dikorelasikan dari beberapa variable seperti : jumlah tweet, retweet, likes, followers, dan following.
Berdasarkan hasil survei career builder saat ini banyak perusahaan menjadikan sosial media pelamar menjadi salah satu aspek penilaian dalam perekrutan pegawai. Menurut survei rekrutmen media sosial Career Builder yang terbaru terhadap
lebih dari 2.000 manajer perekrutan dan profesional SDM dan lebih dari 3.000 pekerja A.S. penuh waktu, 60 persen pengusaha mengungkapkan bahwa mereka menggunakan situs jejaring sosial untuk meneliti kandidat pekerjaan. Angka ini naik secara signifikan dari 52 persen tahun lalu, 22 persen di tahun 2008 dan 11 persen di tahun 2006, saat survei dilakukan pertama kali. Selain itu, 59 persen manajer perekrutan menggunakan mesin pencari untuk meneliti kandidat dibandingkan dengan 51 persen tahun lalu. Dan sosial media yang sering digunakan untuk meneliti calon kandidat pekerjaan adalah Facebook dan Twitter memungkinkan pengusaha untuk melihat sekilas kandidat yang berada di luar batas resume atau surat pengantar. Enam dari 10 pengusaha yang saat ini menggunakan situs jejaring sosial untuk meneliti calon pekerjaan (60 persen) adalah "mencari informasi yang mendukung kualifikasi pekerjaan mereka," menurut survei tersebut.
Melalui sosial media pewawancara dapat mengetahui kepribadian, pandangan sosial, agama dan politik pelamar. Hal tersebut sangat membantu perusahaan untuk menilai apakah pelamar tersebut merupakan orang yang cocok dan tepat bagi perusahaan atau tidak sama sekali. Namun pada umumnya pewawancara masih memeriksa akun untuk menganalisis data tekstual pada akun sosial media pelamar (penulis memilih twitter) sehingga didapatkan kecenderungan jenis kepribadiannya.
Dalam penelitian ini penulis mengajukan metode K-Nearest Neighbor dalam menyelesaikan permasalahan tersebut.
Jurnal psikologi UGM Volume 34, No.2, halaman 112-129 melakukan penelitian terhadap beberapa kepribadian Big 5 dalam menggunakan email dan sosial media. Hasilnya pengguna sosial media Extraversion, Neuroticism dan Openness adalah kepribadian yang aktif dalam menggunakan teknologi dan sosial media dalam namun terdapat kecenderungan pola tersendiri dalam menggunakan sosial media.
Sehingga peneliti tertarik untuk meneliti apakah pengguna twitter juga memiliki pola tertentu dalam menggunakan sosial media berdasarkan kepribadiannya.
Berdasarkan latar belakang diatas, maka penulis mengajukan penelitian dengan judul“KLASIFIKASI TIPE KEPRIBADIAN PENGGUNA SOSIAL MEDIA
BERDASARKAN TEORI BIG FIVE MENGGUNAKAN K-NEAREST
NEIGHBOR”.
1.2 Rumusan Masalah
Untuk menempatkan orang yang tepat pada suatu pekerjaan, pewawancara perlu memperhatikan sifat kepribadian orang tersebut apakah akan sesuai dengan pekerjaan yang akan diembannya. Ketidaksesuaian pekerjaan terhadap kepribadian akan merugikan perusahaan dan karyawan itu sendiri. Saat ini metode yang dilakukan untuk mengetahui kriteria kepribadian seseorang adalah dengan melihat akun sosial media secara manual. Oleh karena itu, dibutuhkan sebuah pendekatan untuk menganalisis data pengguna sosial media pelamar tersebut dengan mengklasifikasikannya menjadi beberapa jenis kepribadian, yaitu Openness (O), Conscientiousness(C), Extraversion (E), Agreeableness(A), Neuroticism(N).
Adapun beberapa parameter yang digunakan dalam penelitian ini adalah Tweet, Retweet, Likes, Following, dan Followers
1.3 Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah mengklasifikasi jenis kepribadian melalui sosial media menggunakan K-Nearest Neighbor dan teori Big Five.
1.4 Batasan Masalah
Dalam penelitian ini, penulis memberikan batasan ruang masalah agar tidak terjadi kesalahan pada saat penelitian. Batasan masalah dalam melakukan proses penelitian ini yaitu:
1. Data di ambil dari sosial media pengguna Twitter.
2. Dokumen yang dijadikan data set adalah dalam bahasa Indonesia.
3. Data yang digunakan adalah berdasarkan data dalam 6 bulan terakhir.
1.5 Manfaat Penelitian
Manfaat yang diperoleh dalam penelitian ini adalah:
1. Sebagai bahan referensi pewawancara dalam menerima karyawan saat interview
2. Membantu seseorang untuk mengetahui kepribadiannya
1.6 Metodologi Penelitian
Tahapan-tahapan yang akan dilakukan pada pelaksanaan penelitian adalah sebagai berikut:
a) Studi Literatur
Studi Literatur dilakukan untuk mengumpulkan bahan referensi yang menunjang dalam melakukan penelitian. Bahan referensi yang dikumpulkan adalah mengenai text mining, Twitter API, text categorization, text classification, K-Nearest Neighbor, dan stemming algorithm.
b) Analisis Permasalahan
Analisis permasalahan merupakan tahap untuk menganalisis seluruh bahan referensi yang telah dikumpulkan.Tahapan ini dilakukan untuk mendapatkan pemahaman mengenai metode yang tepat untuk diterapkan pada penelitian.Adapun metode yang digunakan untuk menyelesaikan permasalahan adalah K-Nearest Neighbor, yakni sebagai algoritma penggolong klasifikasi.
Masalah yang akan diselesaikan mencakup permasalahan klasifikasi pada data tekstual.
c) Pengumpulan Data
Pengumpulan data merupakan tahapan yang sangat penting dalam perancangan arsitektur. Data yang telah dikumpulkan akan dilatih sebagai data pelatihan (training dataset) sedangkan untuk data pengujian(testing dataset) dilakukan secara real-time dengan menarik data langsung dari situs twitter.
d) Implementasi
Implementasi dilakukan dengan menguji metode K-Nearest Neighbor dalam menyelesaikan masalah klasifikasi teks. Data pelatihan digunakan untuk melatih sistem, sedangkan data pengujian digunakan untuk menguji sistem.
e) Evaluasi dan Analisis Hasil
Evaluasi dan analisis bertujuan untuk mengetahui apakah pengujian telah berjalan sesuai dengan yang diharapkan dalam penelitian ini. Tahap ini menggambarkan hasil yang didapat setelah mengimplementasikan metode klasifikasi, K-Nearest Neighbor dalam menyelesaikan masalah klasifikasi kepribadian melalui postingan twitter.
f) Dokumentasi dan Pelaporan
Pada tahap ini, penulis melakukan dokumentasi berupa penyusunan laporan hasil evaluasi, analisis, dan implementasi K-Nearest Neighbor dalam penyelesaian masalah klasifikasi kepribadian melalui postingan twitter.
1.7. Sistematika Penulisan
Sistematika penulisan dari penelitian ini terdiri atas lima bagian utama, yakni sebagai berikut:
Bab 1: Pendahuluan
Bab ini berisi latar belakang dari peneltian yang dilakukan, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
Bab 2: Landasan Teori
Bab ini menjabarkan teori-teori yang mendukung dan dibutuhkan dalam memahami permasalahan. Selain itu, pada bagian ini diuraikan juga mengenai penelitian terdahulu, kerangka pikir dan hipotesis yang diperoleh dari acuan yang mendasari untuk melakukan kegiatan penelitian tugas akhir ini.
Bab 3: Analisis dan Perancangan
Bab ini berisi membahas analisis dan penerapan metode K-Nearest Neighbor untuk menyelesaikan masalah klasifikasi kepribadian melalui postingan twitter. Selain itu, dijabarkan pula arsitektur umum dan tahap pre-process yang digunakan untuk proses cleaning data.
Bab 4: Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari perancangan sistem dari hasil analisis dan perancangan yang telah dijabarkan pada Bab 3. Selain itu, dijabarkan pula hasil yang didapatkan dari pengujian.
Bab 5: Kesimpulan dan Saran
Bab ini berisi ringkasan serta kesimpulan dari hasil penelitian yang telah dilakukan.
Bagian akhir dari bab ini akan berisi saran-saran yang diajukan untuk pengembangan lebih lanjut terkait topik penelitian yang telah dibahas
BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan metode K-Nearest Neighbor untuk mengklasifikasi jenis kepribadian.
2.1. Teori Big Five
Nilai-nilai yang dihasilkan lewat tes Big Five akan membantu mengetahui lebih lanjut sifat-sifat yang ada pada diri Anda. Tidak ada sifat yang paling benar karena sifat-sifat tersebut memiliki kelemahan dan kelebihan tersendiri. Sifat-sifat ini akan membantu menemukan kelebihan yang ada. Yang perlu dilakukan jika sudah cukup mengerti kelebihan sifat-sifat, pilihlah pekerjaan atau kegiatan yang cocok dengan sifat-sifat agar dapat meningkatkan kinerja dengan lebih baik. Bahkan, jika pekerjaan itu cocok dengan sifat seseorang, kemungkinan besar akan merasa jauh lebih semangat saat bekerja.
Selain faktor kepribadian, terdapat faktor yang penting juga untuk disesuaikan saat bingung memilih jenis pekerjaan faktor tersebut merupakan faktor potensi. Jika bekerja sesuai potensi, sangat memungkinkan bahwa akan lebih memiliki motivasi hidup saat bekerja. Untuk itulah dorongan para pembaca untuk membaca tulisan dari Oktobo tentang menemukan kekuatan agar dapat mendapatkan motivasi hidup saat bekerja.
Pada tulisan kali ini akan dijelaskan secara singkat saja dimensi-dimensi dari Big Five tersebut.
Openness (O) to Experience/Intellect merupakan dimensi yang mengukur tingkat penyesuaian seseorang. Openness terhadap pengalaman merupakan faktor yang paling sulit untuk dideskripsikan, karena faktor ini tidak sejalan dengan bahasa yang digunakan tidak seperti halnya faktor-faktor yang lain. Openness mengacu pada bagaimana seseorang bersedia melakukan penyesuiaan pada suatu ide atau situasi
yang baru. Openness mempunyai ciri mudah bertoleransi, kapasitas untuk menyerap informasi, menjadi sangat fokus dan mampu untuk waspada pada berbagai perasaan, pemikiran dan impulsivitas. Seseorang dengan tingkat openness yang tinggi digambarkan sebagai seseorang yang memiliki nilai imajinasi, broadmindedness, dan a world of beauty. Sedangkan seseorang yang memiliki tingkat openness yang rendah memiliki nilai kebersihan, kepatuhan, dan keamanan bersama, kemudian skor openess yang rendah juga menggambarkan pribadi yang mempunyai pemikiran yang sempit, konservatif dan tidak menyukai adanya perubahan. Openness dapat membangun pertumbuhan pribadi. Pencapaian kreatifitas lebih banyak pada orang yang memiliki tingkat openness yang tinggi dan tingkat agreeableness yang rendah. Seseorang yang kreatif, memiliki rasa ingin tahu, atau terbuka terhadap pengalaman lebih mudah untuk mendapatkan solusi untuk suatu masalah.
Jika nilai Openness Anda tinggi, maka Anda cenderung terbuka terhadap ide-ide baru, Anda mudah bertoleransi terhadap perubahan dan senang dengan pengalaman- pengalaman baru. Jika nilai Openness Anda rendah, maka Anda bisa digolongkan ke dalam golongan Closed-Minded yang berarti cenderung tertutup dengan ide-ide baru.
Conscientiousness (C) merupakan dimensi yang mengukur tingkat kehati-hatian seseorang. Conscientiousness adalah faktor yang terakhir, dapat disebut juga dependability, impulse control, dan will to achieve, yang menggambarkan perbedaan keteraturan dan self discipline seseorang. Seseorang yang conscientious memiliki nilai kebersihan dan ambisi. Orang-orang tersebut biasanya digambarkan oleh teman-teman mereka sebagai seseorang yang well-organize, tepat waktu, dan ambisius.
Conscientiousness mendeskripsikan kontrol terhadap lingkungan sosial, berpikir sebelum bertindak, menunda kepuasan, mengikuti peraturan dan norma, terencana, terorganisir, dan memprioritaskan tugas. Di sisi negatifnya trait kepribadian ini menjadi sangat perfeksionis, kompulsif, workaholic, membosankan. Tingkat conscientiousness yang rendah menunjukan sikap ceroboh, tidak terarah serta mudah teralih perhatiannya.
Jika nilai Conscientiousness Anda tinggi, maka Anda cenderung mengerjakan sesuatu dengan berhati-hati. Orang dengan Conscientiousness merupakan orang yang terorganisir serta disiplin karena sifat hati-hatinya itu. Jika nilai Conscientiousness
Anda rendah, maka Anda masuk ke golongan Disorganized yang berarti cenderung tidak teratur atau kacau.
Extraversion (E) merupakan dimensi yang mengukur tingkat keterbukaan seseorang.
Menurut penelitian, seseorang yang memiliki faktor extraversion yang tinggi, akan mengingat semua interaksi sosial, berinteraksi dengan lebih banyak orang dibandingkan dengan seseorang dengan tingkat extraversion yang rendah. Dalam berinteraksi, mereka juga akan lebih banyak memegang kontrol dan keintiman.
Peergroup mereka juga dianggap sebagai orang-orang yang ramah, fun-loving, affectionate, dan talkative. Extraversion dicirikan dengan afek positif seperti memiliki antusiasme yang tinggi, senang bergaul, memiliki emosi yang positif, energik, tertarik dengan banyak hal, ambisius, workaholic juga ramah terhadap orang lain.
Extraversion memiliki tingkat motivasi yang tinggi dalam bergaul, menjalin hubungan dengan sesama dan juga dominan dalam lingkungannya Extraversion dapat memprediksi perkembangan dari hubungan sosial. Seseorang yang memiliki tingkat extraversion yang tinggi dapat lebih cepat berteman daripada seseorang yang memiliki tingkat extraversion yang rendah. Extraversion mudah termotivasi oleh perubahan, variasi dalam hidup, tantangan dan mudah bosan. Sedangkan orang-orang dengan tingkat ekstraversion rendah cenderung bersikap tenang dan menarik diri dari lingkungannya.
Jika nilai Extraversion Anda tinggi, maka Anda adalah orang yang memiliki tingkat sosial tinggi, senang berinteraksi serta bersahabat. Sebaliknya, nilai Extraversion yang rendah menunjukkan bahwa orang tersebut masuk ke golongan Introverted dimana orang ini cenderung tenang dan tidak memiliki tingkat motivasi yang tinggi dalam bergaul.
Agreeableness (A) merupakan dimensi yang mengukur tingkat keramahan seseorang.
Agreebleness dapat disebut juga social adaptibility atau likability yang mengindikasikan seseorang yang ramah, memiliki kepribadian yang selalu mengalah, menghindari konflik dan memiliki kecenderungan untuk mengikuti orang lain.
Berdasarkan value survey, seseorang yang memiliki skor agreeableness yang tinggi digambarkan sebagai seseorang yang memiliki value suka membantu, forgiving, dan
orang yang memiliki tingkat agreeableness yang tinggi, dimana ketika berhadapan dengan konflik, self esteem mereka akan cenderung menurun. Selain itu, menghindar dari usaha langsung dalam menyatakan kekuatan sebagai usaha untuk memutuskan konflik dengan orang lain merupakan salah satu ciri dari seseorang yang memiliki tingkat aggreeableness yang tinggi. Pria yang memiliki tingkat agreeableness yang tinggi dengan penggunaan power yang rendah, akan lebih menunjukan kekuatan jika dibandingkan dengan wanita. Sedangkan orang-orang dengan tingkat agreeableness yang rendah cenderung untuk lebih agresif dan kurang kooperatif.Pelajar yang memiliki tingkat agreeableness yang tinggi memiliki tingkat interaksi yang lebih tinggi dengan keluarga dan jarang memiliki konflik dengan teman yang berjenis kelamin berlawanan.
Orang dengan nilai Agreeableness yang tinggi biasanya digambarkan dengan seseorang yang suka membantu, pemaaf dan penyayang. Nilai Agreeableness yang rendah menunjukkan bahwa orang tersebut masuk ke golongan Disagreeable, orang dengan tipe ini merupakan orang yang senang memberikan kritik, susah diajak kerjasama karena sifat kritisnya tersebut.
Neuroticism (N) merupakan dimensi yang mengukur tingkat kecemasan seseorang.
Neuroticism menggambarkan seseorang yang memiliki masalah dengan emosi yang negatif seperti rasa khawatir dan rasa tidak aman. Secara emosional mereka labil, seperti juga teman-temannya yang lain, mereka juga mengubah perhatian menjadi sesuatu yang berlawanan. Seseorang yang memiliki tingkat neuroticism yang rendah cenderung akan lebih gembira dan puas terhadap hidup dibandingkan dengan seseorang yang memiliki tingkat neuroticism yang tinggi. Selain memiliki kesulitan dalam menjalin hubungan dan berkomitmen, mereka juga memiliki tingkat self esteem yang rendah. Individu yang memiliki nilai atau skor yang tinggi di neuroticism adalah kepribadian yang mudah mengalami kecemasan, rasa marah, depresi, dan memiliki kecenderungan emotionally reactive.
Orang dengan nilai Neuroticism yang tinggi cenderung lebih mudah merasa kuatir dalam hidupnya, secara emosional labil dan mudah merasa tidak aman. Karena rasa khawatirnya tersebut, orang seperti ini sering mengalami kesulitan dalam menjalin hubungan dan komitmen. Nilai Neuroticism yang rendah masuk ke golongan Calm /
Relaxed yang membuat orang dengan tipe ini cenderung lebih gembira dan puas terhadap hidup dibandingkan orang dengan Neuroticism yang tinggi karena memiliki sifat yang tenang dan rileks.
2.2. Data Mining
Data mining adalah kegiatan mengekstraksi atau menambang pengetahuan dari data yang berukuran/berjumlah besar, informasi inilah yang nantinya sangat berguna untuk pengembangan. Dimana langkah-langkah untuk melakukan data mining adalah sebagai berikut :
– Data cleaning (untuk menghilangkan noise data yang tidak konsisten) Data integration (di mana sumber data yang terpecah dapat disatukan)
– Data selection (di mana data yang relevan dengan tugas analisis dikembalikan ke dalam database)
– Data transformation (di mana data berubah atau bersatu menjadi bentuk yang tepat untuk menambang dengan ringkasan performa atau operasi agresi)
– Data mining (proses esensial di mana metode yang intelejen digunakan untuk mengekstrak pola data)
– Pattern evolution (untuk mengidentifikasi pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan atas beberapa tindakan yang menarik)
– Knowledge presentation (di mana gambaran teknik visualisasi dan pengetahuan digunakan untuk memberikan pengetahuan yang telah ditambang kepada user).
Ada beberapa jenis data dalam data mining yaitu :
– Relation Database : Sebuah sistem database, atau disebut juga database management system (DBMS), mengandung sekumpulan data yang saling berhubungan, dikenal sebagai sebuah database, dan satu set program perangkat lunak untuk mengatur dan mengakses data tersebut.
– Data Warehouse : Sebuah data warehouse merupakan sebuah ruang penyimpaan informasi yang terkumpul dari beraneka macam sumber, disimpan dalam skema yang menyatu, dan biasanya terletak pada sebuah site.
Kegunaan data mining adalah untuk menspesifikasikan pola yang harus ditemukan dalam tugas data mining. Secara umum tugas data mining dapat diklasifikasikan ke dalam dua kategori: deskriptif dan prediktif. Tugas menambang secara deskriptif adalah untuk mengklasifikasikan sifat umum suatu data di dalam database. Tugas data mining secara prediktif adalah untuk mengambil kesimpulan terhadap data terakhir untuk membuat prediksi.
- Konsep/Class Description
Data dapat diasosiasikan dengan pembagian class atau konsep. Untuk contohnya, ditoko All Electronics, pembagian class untuk barang yang akan dijual termasuk komputer dan printer, dan konsep untuk konsumen adalah big Spenders dan budget Spender. Hal tersebut sangat berguna untuk menggambarkan pembagian class secara individual dan konsep secara ringkas, laporan ringkas, dan juga pengaturan harga. Deskripsi suatu class atau konsep seperti itu disebut class/concept descripition.
- Association Analysis
Association analysis adalah penemuan association rules yang menunjukkan nilai kondisi suatu attribute yang terjadi bersama-sama secara terus-menerus dalam memmberikan set data. Association analysis secara luas dipakai untuk market basket atau analisa data transaksi.
- Klasifikasi dan Predikasi
Klasifikasi dan prediksi mungkin perlu diproses oleh analisis relevan, yang berusaha untuk mengidentifikasi atribut-atribut yang tidak ditambahkan pada proses klasifikasi dan prediksi. Atribut-atribut ini kemudian dapat di keluarkan.
- Cluster Analysis
Tidak seperti klasifikasi dan prediksi, yang menganalisis objek data dengan kelas yang terlabeli, clustering menganalisis objek data tanpa mencari keterangan pada label kelas yang diketahui. Pada umumnya, label kelas tidak ditampilkan di dalam latihan data simply, karena mereka tidak tahu bagaimana memulainya. Clustering dapat digunakan untuk menghasilkan label-label.
- Outlier Analysis
Outlier dapat dideteksi menggunakan test yang bersifat statistik yang mengambil sebuah distribusi atau probabilitas model untuk data, atau menggunakan langkah- langkah jarak jauh di mana objek yang penting jauh dari cluster lainnya dianggap outlier. Sebuah database mungkin mengandung objek data yang tidak mengikuti tingkah laku yang umum atau model dari data. data ini disebut outlier.
- Evolution Analysis
Data analisa evolusi menggambarkan ketetapan model atau kecenderungan objek yang memiliki kebiasaan berubah setiap waktu. Meskipun ini mungkin termasuk karakteristik, diskriminasi, asosiasi, klasifikasi, atau clustering data berdasarkan waktu, kelebihan yang jelas seperti analisa termasuk analisa data time-series, urutan atau pencocokan pola secara berkala, dan kesamaan berdasarkan analisa data melakukan data mining yang baik ada beberapa persoalan utama yaitu menyangkut metodologi mining dan interaksi user, performance dan perbedaan tipe database. Hal inilah yang sering kali dihadapi disaat kita ingin melakukan data mining.
2.3.Twitter API
Data Twitter merupakan sumber data yang kaya serta beragam dan dapat di gunakan untuk mengungkap informasi tentang topik yang kita inginkan. Data ini dapat digunakan dalam penggunaan yang berbeda-beda seperti menemukan kasus yang sedang popular, prediksi, kategorisasi berdasarkan tag atau kata kunci tertentu, mengukur sentimen merek maupun mengumpulkan umpan balik tentang produk layanan baru. Hal tersebut memicu para programmer atau developer untuk mengembangkan kreatifitas dalam membangun suatu sistem berdasarkan data melimpah yang dimiliki oleh twitter tersebut. Oleh karena itu, twitter menyediakan API programming yang dapat dikembangkan oleh pihak ketiga untuk membangun suatu aplikasi baru.
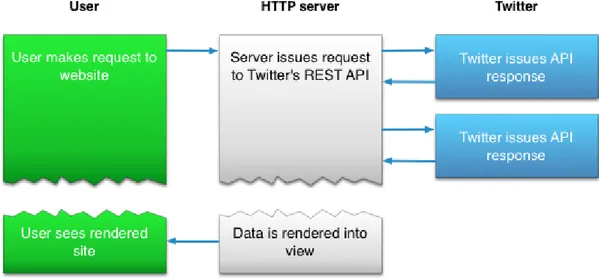
Gambar 2.1. Arsitektur Twitter API(sumber code.tutsplus.com)
Twitter API tersedia untuk berbagai platform dan bahasa pemrograman. Untuk menggunakannya dibutuhkan pemasangan paket-paket tertentu serta melengkapi library dari Twitter API itu sendiri. Pengembang yang ingin mengimplementasikan Twitter API melalui bahasa pemrograman Hypertext Prepocessor (PHP) dapat menggunakan Twitter OAuth, yaitu PHP library untuk berkomunikasi dengan Twitter API. Hasil yang didapat akan diekstrak dalam bentuk format data JSON yang bisa diolah sebelum disimpan ke dalam database. Ada 3 bagian penting dari platform Twitter, yakni :
a) OAuth authentication
OAuth dapat memungkinkan pengguna untuk mengakses situs twitter yang dimiliki pengguna tanpa harus melalui dari situs twitter. Otentikasi dibutuhkan untuk sign in ke akun twitter yang dimiliki pengguna. Sign in adalah tahapan yang harus dilalui pengguna untuk dapat masuk ke akun twitter-nya. Otentikasi application-user diperlukan untuk mendapatkan user-specific API. Dengan kata lain, ketika kita mulai untuk mengakses API twitter menggunakan akun pengguna, pengguna akan diarahkan menuju twitter untuk mengotorisasi aplikasi kita. Twitter akan memberikan akses token yang akan berakhir sampai pengguna tidak lagi menggunakannya. Pengembang akan menggunakan token-token tersebut untuk otentikasi aplikasi yang akan dibuat atas nama akun pengembang sebagai pengguna.
b) Representational state transfer (REST) API
Cara paling umum yang digunakan oleh pengembang untuk mendapatkan akses data twitter adalah melalui REST API. REST API menggunakan token yang akan diperoleh melalui OAuth sehingga sistem yang kita buat akan melakukan permintaan (request) kepada twitter untuk menarik data tertentu. Misalnya, kita akan mengakses data status pengguna. REST API dapat memenuhi kebutuhan para pengembang aplikasi twitter.
c) Streaming API OAuth Authentication
Streaming API memungkinkan pengguna untuk menerima postingan-postingan (tweets) dan pemberitahuan secara real-time dari twitter. Namun, membutuhkan kinerja yang tinggi dan koneksi yang harus selalu ada antara server dengan twitter. Ada tiga variasi pada twitter streaming API, yakni :
The Public Stream. Hal ini memungkinkan sistem untuk memonitor data publik di Twitter, seperti tweet yang dibagikan secara publik, filter hashtag dan sebagainya.
The User Stream. Hal ini memungkinkan untuk melacak aliran tweet pengguna secara real-time.
Site Stream. Site stream membutuhkan persetujuan terlebih dahulu dari pihak Twitter yang memungkinkan sistem untuk memonitor real-time Twitter feeds untuk sejumlah besar pengguna. Tujuan dari implementasi streaming adalah untuk melacak peristiwa yang masuk secepat mungkin dan mengolahnya pada suatu aplikasi tertentu menggunakan REST API untuk mendapatkan data yang lebih dalam. Penggunaan REST API memiliki berbagai batasan-batasan yang diberikan oleh twitter. Penting bagi pengembang untuk menggunakan dan bertanggung jawab atas penggunaan Twitter API dengan merencanakan batasan-batasan aktivitas dalam sistem yang dibuat dan memantau respon- respon yang ada.
Token Key
Token key sangat dibutuhkan oleh pengembang apabila ingin membangun sebuah sistem yang membutuhkan akses data melalui Twitter. Pengembang terlebih dahulu mendaftarkan sistem yang akan dibangun beserta penjelasan
singkat mengenai sistem untuk mendapatkan token key, baik itu berbasis Java atau PHP.
2.4. Klasifikasi
Proses klasifikasi dilakukan untuk menggolongkan data dari twitter yang diposting oleh beberapa akun menjadi beberapa kategori kelas yang yang telah ditentukan.
Tujuan dari proses klasifikasi ini adalah untuk membangun model prediktif yang dapat mengklasifikasikan dokumen secara otomatis sehingga dapat diketahui kategori kelas dari sejumlah besar data secara efektif dan efisien. Proses klasifikasi menggunakan prinsip machine learning dimana pembuatan model klasifikasi dilakukan dengan mempelajari sejumlah data latihan (data training) dan mengujinya dengan sejumlah data uji (data test). Pengklasifikasian (classification) dilakukan pada untuk menggolongkan akun twitter pengguna tersebut termasuk kedalam kategori kepribadian Big 5 yang mana berdasarkan postingan twitternya. Klasifikasi dilakukan dengan menggunakan metode K-Nearest Nieghbor. Pada penerapan K-Nearest Neighbor, setiap set data yang akan dikelompokkan akan dibagi menjadi data latihan (data training) dan data uji (data test). Jumlah data set kelas yang akan dikelompokkan adalah sebanyaklima data set, yaitu kelas Openness (O), Conscientiousness(C), Extraversion(E), Agreeableness(A), Neuroticism(N).
2.5. K-Nearest Neighbor
K-Nearest Neighbor (KNN) adalah suatu metode yang menggunakan algoritma supervised dimana hasil dari query instance yang baru diklasifikan berdasarkan mayoritas dari kategori pada KNN. Tujuan dari algoritma ini adalah mengklasifikasikan obyek baru bedasarkan atribut dan training sample. Classifier tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. Diberikan titik query, akan ditemukan sejumlah k obyek atau (titik training) yang paling dekat dengan titik query. Klasifikasi menggunakan voting terbanyak diantara klasifikasi dari k obyek.. algoritma KNN menggunakan klasifikasi ketetanggaan sebagai nilai prediksi dari query instance yang baru.
Algoritma metode KNN sangatlah sederhana, bekerja berdasarkan jarak terpendek dari query instance ke training sample untuk menentukan KNN-nya. Training sample diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi bagian-bagian berdasarkan klasifikasi training sample. Sebuah titik pada ruang ini ditandai kelac c jika kelas c merupakan klasifikasi yang paling banyak ditemui pada k buah tetangga terdekat dari titik tersebut. Pada fase training, algoritma ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk testing data (yang klasifikasinya tidak diketahui). Jarak dari vektor baru yang ini terhadap seluruh vektor training sample dihitung dan sejumlah k buah yang paling dekat diambil. Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik-titik tersebut.
Gambar 2.2. Ilustrasi Kedekatan Status (sumber Shellvia Kusuma,2017) Seperti tampak pada Gambar 2.2. Ada 2 pasien lama A dan B. Ketika ada pasien Baru, maka solusi yang akan diambil adalah solusi dari pasien terdekat dari pasien Baru.
Seandainya d1 adalah kedekatan antara pasien Baru dan pasien A, sedangkan d2 adalah kedekatan antara pasien Baru dengan pasien B. Karena d2 lebih dekat dari d1 maka solusi dari pasien B lah yang akan digunakan untuk memberikan solusi pasien Baru.
Adapun rumus untuk melakukan perhitungan kedekatan antara 2 kasus adalah sebagai berikut :
d2 B
d1 Baru
A
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 𝑇, 𝑆 = 𝑛𝑖=1𝑓 𝑇𝑖 , 𝑆𝑖 𝑥 𝑤𝑖 𝑤𝑖
(2.1) dengan
T : kasus baru
S : kasus yang ada dalam penyimpanan n : jumlah atribut dalam masing-masing kasus i : atribut individu antara 1s/d n
f : fungsi similarity atribut i antara kasus T dan kasus S w : bobot yang di berikan pada atibut ke i
Kedekatan biasanya berada pada nilai antara 0 s/d 1. Nilai 0 artinya kedua kasus mutlak tidak mirip, sebaliknya untuk nilai 1 kasus mirip dengan mutlak.
Kasus :
Kemungkinan seorang nasabah bank akan bermasalah dalam pembayaran atau tidak
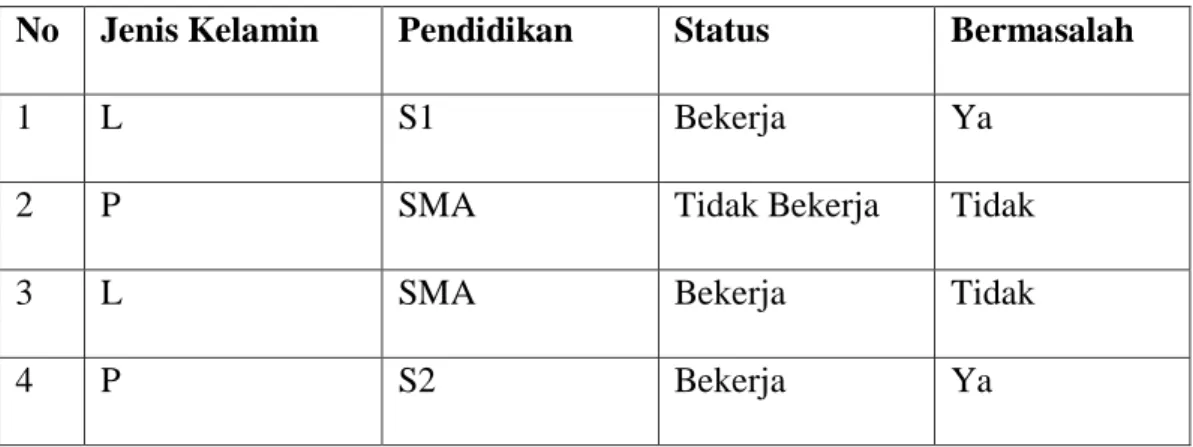
Tabel 2.1. Tabel Kasus
No Jenis Kelamin Pendidikan Status Bermasalah
1 L S1 Bekerja Ya
2 P SMA Tidak Bekerja Tidak
3 L SMA Bekerja Tidak
4 P S2 Bekerja Ya
Atribut Bermasalah merupakan atribut tujuan.
Bobot antara satu atribut dengan atribut yang lain pada atribut bukan tujuan dapat didefinisikan dengan nilai berbeda.
Tabel 2.2. Definisi Bobot Atribut
Atribut Bobot
Jenis Kelamin 0,5
Pendidikan 1
Status 0,75
Kedekatan antara nilai-nilai dalam atribut juga perlu didefinisikan, seperti yang terlihat pada Tabel 2.3. hingga Tabel 2.8.
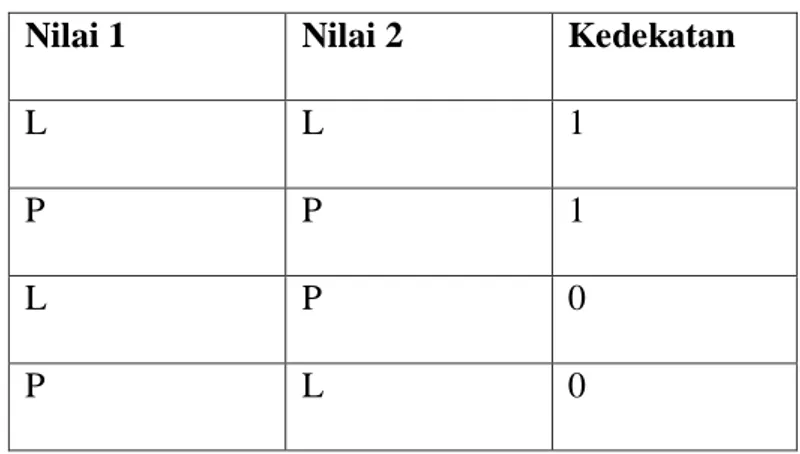
Tabel 2.3. Kedekatan Nilai Atribut Jenis Kelamin
Jenis Kelamin L P
L 1 0
P 0 1
Tabel 2.4. Rincian Kedekatan Nilai Atribut Jenis Kelamin Nilai 1 Nilai 2 Kedekatan
L L 1
P P 1
L P 0
P L 0
Pada Tabel 2.3. adalah keterangan kedekatan nilai atribut jenis kelamin. Apabila kasus baru berjenis kelamin Laki-laki dan kasus lama berjenis kelamin yang sama,
yang berbeda, yakni perempuan maka bobotnya 0. Begitu seterusnya hingga atribut lainnya.
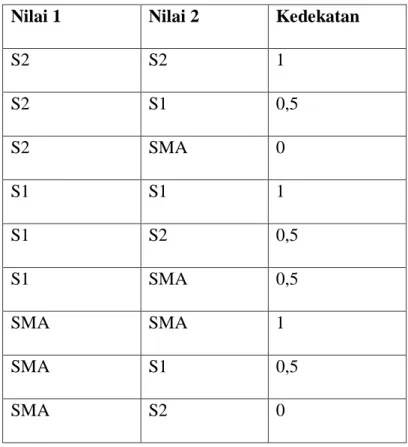
Tabel 2.5. Kedekatan Nilai Atribut Pendidikan
Pendidikan SMA S1 S2
SMA 1 0,5 0
S1 0,5 1 0,5
S2 0 0,5 1
Tabel 2.6. Rincian Kedekatan Nilai Atribut Pendidikan Nilai 1 Nilai 2 Kedekatan
S2 S2 1
S2 S1 0,5
S2 SMA 0
S1 S1 1
S1 S2 0,5
S1 SMA 0,5
SMA SMA 1
SMA S1 0,5
SMA S2 0
Tabel 2.7. Kedekatan Nilai Atribut Status
Status Bekerja Tidak Bekerja
Bekerja 1 0
Tidak Bekerja 0 1
Tabel 2.8. Rincian Kedekatan Nilai Atribut Status
Nilai 1 Nilai 2 Kedekatan
Bekerja Bekerja 1
Tidak Bekerja Tidak Bekerja 1
Bekerja Tidak Bekerja 0
Tidak Bekerja Bekerja 0
Misalkan ada kasus nasabah baru dengan nilai atribut : Jenis Kelamin : L
Pendidikan : SMA
Status : Tidak Bekerja
Untuk memprediksi apakah nasabah tersebut akan bermasalah atau tidak dapat dilakukan langkah-langkah sebagai berikut :
1. Meghitung kedekatan kasus baru dengan kasus no.1 Diketahui :
a : Kedekatan nilai atribut Jenis Kelamin (Laki-laki dengan Laki-laki) : 1
: 0,5
c : Kedekatan nilai atribut Pendidikan (SMA dengan S1) : 0,5
d : Bobot Atribut Pendidikan : 1
e : Kedekatan nilai atribut Status (Tidak Bekerja dengan Bekerja) : 0
f : Bobot Atribut Status : 0,75
Dihitung:
𝐽𝑎𝑟𝑎𝑘 = 𝑎 ∗ 𝑏 + 𝑐 ∗ 𝑑 + (𝑒 ∗ 𝑓) 𝑏 + 𝑑 + 𝑓
𝐽𝑎𝑟𝑎𝑘 = 1 ∗ 0,5 + 0,5 ∗ 1 + 0 ∗ 0,75 0,5 + 1 + 0,75
𝐽𝑎𝑟𝑎𝑘 = 1 2,25
Jarak = 0,44 (2.2)
2. Menghitung kedekatan kasus baru dengan kasus no.2 Diketahui :
a : Kedekatan nilai atribut Jenis Kelamin (Laki-laki dengan Perempuan) : 0
b : Bobot Atribut Jenis Kelamin : 0,5
c : Kedekatan nilai atribut Pendidikan (SMA dengan SMA) : 1
d : Bobot Atribut Pendidikan : 1
e : Kedekatan nilai atribut Status (Tidak Bekerja dengan Tidak Bekerja) : 1
f : Bobot Atribut Status : 0,75
Dihitung :
𝐽𝑎𝑟𝑎𝑘 = 𝑎 ∗ 𝑏 + 𝑐 ∗ 𝑑 + (𝑒 ∗ 𝑓) 𝑏 + 𝑑 + 𝑓
𝐽𝑎𝑟𝑎𝑘 = 0 ∗ 0,5 + 1 ∗ 1 + 1 ∗ 0,75 0,5 + 1 + 0,75
𝐽𝑎𝑟𝑎𝑘 =1,75 2,25
Jarak = 0,778 (2.3)
3. Menghitung kedekatan kasus baru dengan kasus no.3 Diketahui :
a : Kedekatan nilai atribut Jenis Kelamin (Laki-laki dengan Laki-laki) : 1
b : Bobot Atribut Jenis Kelamin : 0,5
c : Kedekatan nilai atribut Pendidikan (SMA dengan SMA) : 1
d : Bobot Atribut Pendidikan : 1
e : Kedekatan nilai atribut Status (Tidak Bekerja dengan Bekerja) : 0
f : Bobot Atribut Status : 0,75
Dihitung :
𝐽𝑎𝑟𝑎𝑘 = 𝑎 ∗ 𝑏 + 𝑐 ∗ 𝑑 + (𝑒 ∗ 𝑓) 𝑏 + 𝑑 + 𝑓
𝐽𝑎𝑟𝑎𝑘 = 1 ∗ 0,5 + 1 ∗ 1 + 0 ∗ 0,75 0,5 + 1 + 0,75
𝐽𝑎𝑟𝑎𝑘 = 1,5 2,25
Jarak = 0,667 (2.4)
4. Menghitung kedekatan kasus baru dengan kasus no.3 Diketahui :
Diketahui :
a : Kedekatan nilai atribut Jenis Kelamin (Perempuan dengan Laki-laki) : 0
b : Bobot Atribut Jenis Kelamin : 0,5
c : Kedekatan nilai atribut Pendidikan (SMA dengan S2) : 0
d : Bobot Atribut Pendidikan : 1
e : Kedekatan nilai atribut Status (Tidak Bekerja dengan Bekerja) : 0
f : Bobot Atribut Status : 0,75
Dihitung :
𝐽𝑎𝑟𝑎𝑘 = 𝑎 ∗ 𝑏 + 𝑐 ∗ 𝑑 + (𝑒 ∗ 𝑓) 𝑏 + 𝑑 + 𝑓
𝐽𝑎𝑟𝑎𝑘 = 0 ∗ 0,5 + 0 ∗ 1 + 0 ∗ 0,75 0,5 + 1 + 0,75
𝐽𝑎𝑟𝑎𝑘 = 0 2,25
Jarak = 0 (2.5)
5. Memilih kasus dengan kedekatan terdekat
Dari langkah 1,2 dan 3 dapat diketahui bahwa nilai tertinggi adalah kasus 2.
Berarti kasus yang terdekat dengan kasus baru adalah 2.
6. Menggunakan klasifikasi dari kasus dengan kedekatan terdekat.
Berdasarkan hasil pada langkah 4, maka klasifikasi dari kasus 2 yang akan digunakan untuk memprediksi kasus baru. Yaitu kemungkinan nasabah baru akan Tidak Bermasalah.
2.6. Penelitian Terdahulu
Pada tahun 2016, APJII berdasarkan konten yang paling sering dijunjungi, pengguna internet paling sering mengunjungi webonlineshopsebesar 82,2 juta atau 62%. Dan kontensocial mediayang paling banyak dikujungi adalahTwittersebesar 71,6 juta pengguna atau 54% dan urutan kedua adalah Instagram sebesar 19,9 juta pengguna atau 15%.
Pada tahun 2013, Renxian Zhang et al dengan pertumbuhan media sosial layanan twitter, dibutuhkan suatu teknik untuk mengotomatiskan peringkasan pesan twitter dari banyaknya informasi twitter. Peringkasan twitter harus dapat mengatasi permasalahan jumlah, pendek, kemiripan dan gangguan lainnya.
Teknik yang digunakan adalah speech acts recognition berdasarkan penggunaan kata dan simbol. Speech act recognition pada pesan twitterakan mengarahkan ekstraksi kata kunci dan frasa menjadi sebuah template untuk mendesain speech acts kategori untuk tahap perangkingan kata-kata dan frasa menggunakan algoritma round-robin untuk menghasilkan template berbasis ringkasan. Penilitian ini menggunakan 200 dataset.
Pada tahun 2007, Sandu Popa et al pada paper ini diajukan sebuah metode pembelajaran supervised yang disebut dengan Matrix Regrission. Algoritma ini digunakan untuk mengaplikasikan laporan rumah sakit secara otomatis. Penilitian ini dibandingkan dengan KNN dan hasilnya cukup baik. Data yang dibutuhkan : nama pasien, umur, keturanan, data histori pasien, perubahan pasien serta kesimpulan.
Paragraf terakhir berisi daftarkode ICD (International Classification of Disease).
Kode mengacu pada penyakit pasien dan pasien akan diberikan penyesuaian Statistic Classification of Disease and Connected Health Problems, ini adalah standar pengodean penyakit.
Terdapat sekitar 10.000 kode ICD, diantaranya ada 1000 yang sering digunakan. Hal tersebut menyebabkan kesulitan untuk menentukannya secara manual.
Penelitian ini menggunakan 31.000 HR (Hospital Report) yang sudah di klasifikasi setiap dokumen dapat memiliki lebih dari 1 kategori hingga 32 kategori.
Pada tahun 2013, Sara Keretna et al tujuan penelitian ini adalah membedakan akun asli dengan akun palsu pada media sosial Twitter menggunakan gaya penulisan biometric. Pertama kali ekstraksi fitur menggunakan teknik text mining, kemudian pelatihan dengan metode supervised machine learning dimulai dengan ekstraksi fitur yang relevaan dan mengukur kemiripan fitur vektor sehingga didapatkan database pengetahuan. Lalu akan dicocokkan dengan data testing. Apabila mirip dengan database pengetahuan maka akan dikenali sebagai akun asli atau palsu terverifikasi.
Pada tahun 2016, Xiaoping Zhou et al pada penelitian ini akan mengidentifikasi pengguna sosial media yang anonim (belum terverifikasi) pada Multiple Social Media Networks. Pada penelitian ini memiliki beberapa aspek untuk mengenali struktur akun yang sudah terverifikasi (resmi) dengan akun yang anonim (fake), salah satunya adalah dengan mengidentifikasi keselarasan daftar teman.
Penelitian ini mengembangkan algoritma novel friend relationship based atau disingkat dengan FRUI. Untuk menambahkan 2 teorema yang ditujukan untuk kompleksitas FRUI dapat mengidentifikasi User Anonim dengan baik secara multi- platform seperti Twitterdan Foursquare berdasarkan hubungan pertemanan.
Pada tahun 2016, Mondher Bouazizi dan Tomoaki Ohtsuki pada penilitian ini dilakukan analis sentimen terhadap 7 kasus atau kategori yang berbeda. Biasanya sentimen analis hanya menilai dari 1 kategori saja, namun pada penelitian ini melakukan sentimen analisi pada pesan twitter dengan 7 kategori, yaitu : Happiness, Love, Sadness, Anger, Hate, Sarcasm, Neutral. Masing-masing kategori atau kelas memiliki training dataset sebanyak 3000, sedangkan untuk dataset testing diambil sebanyak 1.400 tweet. Algoritma : Multi Class, Classification Confusion Matrix dengan akurasi sebesar 83%. Untuk mendapatkan data dari twitter penelitian ini menggunakan teknik Twitter API, untuk mengoleksi data-data dari 100 akun pengguna twitter yang berbeda. 70 data sebagai data latih dan 30 data sebagai data uji Penelitian terdahulu yang telah dipaparkan akan diuraikan secara singkat pada
Tabel 2.9.
Tabel 2.9. Penelitian Terdahulu
No Judul Peneliti Tahun Metode
1 Automatic Twitter Topic Summarization With Speech Acts
Renxian Zhang 2013 speech acts recognition
2 Text Categorization for Multi-label Documents and
Many Categories
Sandu Popa 2007 Matrix Regrission
3 Recognising User Identity in Twitter Social Networks via Text Mining
Sara Keretna 2013 supervised machine learning
4 Cross-Platform Identification of Anonymous
Identical Users in Multiple Social Media Networks
Xiaoping Zhou 2016 Friend Relationship- Based User (FRUI)
5 Sentiment Analysis: from Binary to Multi-Class
Classification
Mondher Bouazizi dan
Tomoaki Ohtsuki
2016 Multi Class, Classification Confusion Matrix
BAB 3
ANALISIS DAN PERANCANGAN
Bab ini membahas mengenai data yang digunakan, penerapan algoritma dan analisis perancangan sistem terhadap implementasi algoritma K-Nearest Neighbor dalam melakukan proses klasifikasi tipe kepribadian seseorang melalui media sosial. Ada dua tahapan yang akan dibahas pada bab ini yaitu tahap analisis dan tahap perancangan sistem. Tahap analisis akan membahas mengenai analisis terhadap data dan metode yang digunakan, sedangkan tahap perancangan sistem akan membahas mengenai perancangan tampilan antarmuka.
3.1.Arsitektur Umum
Metode yang dilakukan pada penelitian ini dapat dilihat pada Gambar 3.1 yang menggambarkan arsitektur umum dari rangkaian langkah dalam melakukan proses klasifikasi tipe kepribadian. Adapun tahapan yang dilakukan adalah sebagai berikut:
pengumpulan postingan twitter melalui Twitter API yang akan digunakan sebagai data pelatihan (training dataset) dan data pengujian (testing dataset); penghilangan tanda khusus atau simbol tertentu untuk mengurangi noise (pengganggu) dengan menerapkan proses filtering; kemudian melakukan pemisahan antara postingan tweet dengan postingan retweet pada akun twitter yang menjadi data uji pada penelitian ini;
kemudian jumlah postingan masing-masing parameter akan dihitung yakni jumlah postingan, jumlah retweet, jumlah likes, jumlah following, jumlah followers;
pengujian sistem dengan menerapkan metode K-Nearest Neighbor dengan menggunakan data pengujian; hasil pengujian dimasukkan ke dalam database beserta hasil klasifikasi, yang nantinya akan digunakan sebagai data latih baru;
Gambar 3.1. Arsitektur Umum
3.2. Data yang Digunakan
Data yang dikumpulkan adalah dari 100 akun pengguna twitter. Data tersebut dibagi menjadi 2 bagian, yaitu data latih dan data uji. Data latih sebanyak 70 akun sedangkan data uji sebanyak 30 akun. Pertama-tama partisipan mengisi kuesioner pada situs openpsychometrics.org seperti yang ada pada Gambar 3.2
Gambar 3.2. Form Kuesioner Survey
Kemudian apabila partisipan telah menyelesaikan menjawab seluruh pertayaan kuesioner, maka hasil kepribadian partisipan tersebut dapat dilihat pada halaman result seperti yang ada pada Gambar 3.3.
Gambar 3.3. Contoh Hasil Kepribadian Partisipan Berdasarkan Survey
Apabila kepribadian partisipan telah diketahui melalui survey, kemudian data-data akun twitter partisipan tersebut akan dimasukkan ke dalam database sebagai data latih.
Data-data akun twitter yang diretrieve dari twitter partisipan adalah dari tanggal 11 November 2017 hingga 11 Februari 2018.
3.3.Pre-Processing
Sebelum melakukan proses klasifikasi, data-data dari akun pengguna twitter diolah terlebih dahulu. Data yang diekstrak dari akun pengguna twitter adalah berupa jumlah likes, following, followers, retweets dan tweet.
3.3.1. Memisahkan Postingan Tweet dan Retweet
Retweet merupakan salah satu bentuk posting tweet dengan cara mengulang ataumenulis kembali tweet yang ditulis seseorang, sehingga retweet harus dihilangkan karena tidak menggambarkan kepribadian yang sebenarnya. Retweet pada twitter dapat dilakukan dengan 2 metode, metode pertama dilakukan dengan cara menekan tombol retweet yang sudah disediakan oleh twitter, sedangkan metode kedua dilakukan dengan cara menyalin tweet orang lain dan ditambahkan “RT” pada awal tweet. API Twitter hanya dapat menyaring retweet yang dilakukan dengan metode pertama, namun untuk menyaring metode kedua diperlukan. Pencarian keyword “RT”
dan apabila ditemukan maka tweet tersebut tidak akan dipakai sebagai data training.
3.3.2. Menghitung Jumlah Postingan Tweet
Pada tahap ini gunanya untuk menghitung jumlah postingan akun pengguna twitter selama tiga bulan terakhir. Hal tersebut digunakan untuk mengidentifikasi keaktifan pengguna dalam menggunakan twitter. 6 bulan terakhir tersebut adalah dimulai dari tanggal 11 November 2017 hingga 11 Februari 2018. Jumlah postingan pengguna akan diwakilkan ke dalam atribut A-E tergantung jumlah postingan tweet pengguna akun twitter tersebut seperti yang terlihat pada Tabel 3.1.
3.3.3. Menghitung Jumlah Retweet
Pada tahap ini gunanya untuk menghitung jumlah retweet pengguna twitter tersebut.
Beberapa pengguna lebih sering menggunakan fitur retweet daripada melakukan postingan sendiri. Hal tersebut tersebut merupakan salah satu kecenderungan tipe
dihitung dan diwakilkan ke dalam atribut A-E tergantung jumlah retweet pengguna seperti yang terlihat pada Tabel 3.2.
3.3.4. Menghitung Jumlah Follower
Pada tahap ini adalah untuk menghitung jumlah follower pengguna twitter tersebut.
Jumlah follower yang tinggi dan rendah menjadi salah satu factor penilaian dalam menentukan kepribadian pengguna twitter tersebut. Apabila jumlah followernya tinggi, ada kemungkinan pengguna tersebut populer sedangkan jumlah yang follower rendah kemungkinan pengguna tersebut tertutup.
3.3.5. Menghitung Jumlah Following
Pada tahap ini adalah untuk menghitung jumlah following pengguna twitter tersebut.
Jumlah following yang tinggi dan rendah menjadi salah satu faktor penilaian dalam menentukan kepribadian pengguna twitter tersebut. Following yang tinggi kemungkinan memiliki sifat terbuka dan tidak memilih-milih dalam pertemanan atau bisa juga tidak canggung melakukan following terlebih dulu. Sedangkan yang memiliki following rendah kemungkinan pengguna tersebut memiliki sifat yang tertutup dan hanya ingin berhubungan dengan lingkungan tertentu saja.
3.3.6. Menghitung Jumlah Likes
Pada tahap ini adalah untuk menghitung jumlah likes pengguna twitter tersebut.
Jumlah likes yang tinggi dan rendah menjadi salah satu faktor penilaian dalam menentukan kepribadian pengguna twitter tersebut. Jumlah like yang tinggi menjadi tolak ukuran interaksi seorang pengguna twitter terhadap pengguna lain. Apabila jumlah likes pengguna twitter tersebut tinggi, maka ada kecenderungan interaksi sosial yang kuat pada pengguna tersebut. Sebaliknya apabila jumlah likesnya rendah berarti pengguna twitter tersebut menggunakan sosial media untuk berinteraksi dengan sesama pengguna sosmed.
3.4.Klasifikasi
Proses klasifikasi dilakukan untuk menggolongkan data dari twitter yang diposting oleh beberapa akun menjadi beberapa kategori kelas yang yang telah ditentukan.
Tujuan dari proses klasifikasi ini adalah untuk membangun model prediktif yang dapat mengklasifikasikan dokumen secara otomatis sehingga dapat diketahui kategori
kelas dari sejumlah besar data secara efektif dan efisien. Proses klasifikasi smenggunakan prinsip machine learning dimana pembuatan model klasifikasi dilakukan dengan mempelajari sejumlah data latihan (data training) dan mengujinya dengan sejumlah data uji (data test). Pengklasifikasian (classification) dilakukan pada untuk mennggolongkan akun twitter pengguna tersebut termasuk kedalam kategori kepribadian Big 5 yang mana berdasarkan postingan twitternya. Klasifikasi dilakukan dengan menggunakan metode K-Nearest Neighbor Pada penerapan K-Nearest Neighbor, setiap set data yang akan dikelompokkan akan dibagi menjadi data latihan (data training) dan data uji (data test). Jumlah data set kelas yang akan dikelompokkan adalah sebanyak lima data set, yaitu kelas Openness (O), Conscientiousness(C), Extraversion (E), Agreeableness(A), Neuroticism(N).
Berikut adalah pemberian range pada kuantitas data pada setiap kategori : Tabel 3.1. Range jumlah Tweets
Range Jumlah Tweets Parameter
0-200 A
201-400 B
401-600 C
601-800 D
>800 E
Pada tahap ini akan dihitung jumlah range tweets pengguna twitter atau seberapa banyak pengguna twitter tersebut mengupdate tweets atau status dari skala terkecil yaitu 0 dan skala lebih besar dari 800.
Tabel. 3.2. Range jumlah Retweet Range Jumlah Retweet Parameter
0-200 A
201-400 B
401-600 C
601-800 D
>800 E
Sama dengan range tweets pada tahap ini akan dihitung jumlah range retweets pengguna twitter namun bedanya dihitung pada 6 bulan terakhir dari skala terkecil yaitu 0 dan skala lebih besar dari 800.
Tabel 3.3.Range jumlah Likes Range Jumlah Likes Parameter
0-100 A
101-200 B
201-300 C
301-400 D
>400 E
Lalu pada tahap ini akan dihitung range likesnya seberapa banyak pengguna melakukan likes pada tweets pengguna twitter lain pada 6 bulan terkhir dari skala terkecil yaitu 0 hingga skala lebih besar dari 400.
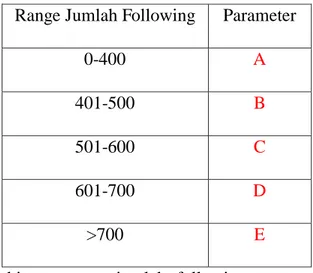
Tabel 3.4.Range Jumlah Following Range Jumlah Following Parameter
0-400 A
401-500 B
501-600 C
601-700 D
>700 E
Pada tahap ini menghitung range jumlah following pengguna twitter dari skala terkecil 0 hingga skala lebih besar dari 700.
Tabel 3.5.Range jumlah Followers Range Jumlah Followers Parameter
0-500 A
501-600 B
601-700 C
701-800 D
>800 E
Pada tahap ini menghitung range jumlah followers atau pengikut pengguna twitter dari skala terkecil 0 hingga skala lebih besar dari 800.
Tabel – tabel diatas adalah rincian atribut tiap range parameter. Huruf A, B, C, D, dan E adalah nama atribut. Dan untuk data latih yang akan digunakan itu adalah 70 data latih dan 30 data uji.
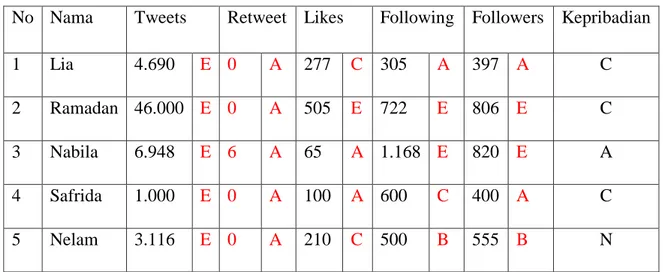
Tabel 3.6. Contoh Beberapa Data Latih
No Nama Tweets Retweet Likes Following Followers Kepribadian
1 Lia 4.690 E 0 A 277 C 305 A 397 A C
2 Ramadan 46.000 E 0 A 505 E 722 E 806 E C 3 Nabila 6.948 E 6 A 65 A 1.168 E 820 E A 4 Safrida 1.000 E 0 A 100 A 600 C 400 A C
5 Nelam 3.116 E 0 A 210 C 500 B 555 B N
Tabel 3.7. Definisi Bobot Parameter
Parameter Bobot
Tweets 1
Likes 0,5
Following 0,75
Followers 0,75
Retweet 0.75
Tabel 3.7 menggambarkan definisi bobot parameter yang ada. Maksudnya adalah dari kelima parameter tersebut, mana yang menjadi prioritas parameter tertinggi. Dari tabel 3.7, terlihat bobot yang paling tinggi adalah parameter jumlah tweet dan yang paling rendah adalah parameter jumlah like. Sedangkan parameter following, followers dan retweet memiliki prioritas yang sama kuat. Penentuan bobot parameter ini berdasarkan hasil pantauan penulis secara manual, yakni parameter likes paling jarang digunakan oleh pengguna. Jadi, parameter likes memiliki bobot prioritas terendah dibandingkan parameter lain.
Tabel 3.8. Kedekatan Nilai Atribut Tweets
A B C D E
A 1 0,75 0,50 0,25 0
B 0,75 1 0,75 0,50 0,75
C 0,50 0,75 1 0,75 0,50
D 0,25 0,50 0,75 1 0,75
E 0 0,25 0,50 0,75 1
Tabel 3.9. Kedekatan Nilai Atribut Likes
A B C D E
A 1 0,75 0,50 0,25 0
B 0,75 1 0,75 0,50 0,75
C 0,50 0,75 1 0,75 0,50
D 0,25 0,50 0,75 1 0,75
E 0 0,25 0,50 0,75 1
Tabel 3.10. Kedekatan Nilai Atribut Following
A B C D E
A 1 0,75 0,50 0,25 0
B 0,75 1 0,75 0,50 0,75
C 0,50 0,75 1 0,75 0,50
D 0,25 0,50 0,75 1 0,75
E 0 0,25 0,50 0,75 1
Tabel 3.11. Kedekatan Nilai Atribut Followers
A B C D E
A 1 0,75 0,50 0,25 0
B 0,75 1 0,75 0,50 0,75
C 0,50 0,75 1 0,75 0,50
D 0,25 0,50 0,75 1 0,75
E 0 0,25 0,50 0,75 1
Tabel 3.12. Kedekatan Nilai Atribut Retweet
A B C D E
A 1 0,75 0,50 0,25 0
B 0,75 1 0,75 0,50 0,75
C 0,50 0,75 1 0,75 0,50
D 0,25 0,50 0,75 1 0,75
E 0 0,25 0,50 0,75 1
Tabel 3.13. Nilai Kedekatan secara keseluruhan
Nilai 1 Nilai 2 Kedekatan
A A 1
A B 0,75
A C 0,50
A D 0,25
A E 0
B B 1
B A 0,75
B C 0,75
B D 0,50
B E 0,25
C C 1
C A 0,50
C B 0,75
C D 0,75
C E 0,50
D D 1
D A 0,25
D B 0,50
D C 0,75
D E 0,75
E E 1
E A 0
E B 0,25
E C 0,50
E D 0,75