1
PENGELOMPOKAN KABUPATEN / KOTA
DI JAWA TIMUR BERDASARKAN
FAKTOR-FAKTOR PENYEBAB PERCERAIAN TAHUN 2010
Luthfi Kurnia Hidayati1 Dra. Lucia Aridinanti, MS2
1 MahasiswaJurusan Statistika Institut Teknologi Sepuluh Nopember 2Dosen Jurusan Statistika Institut Teknologi Sepuluh Nopember email : 1luthfi.kurnia09@mhs.statistika.its.ac.id, 2
lucia_a@statistika.its.ac.id
ABSTRAK
Perceraian merupakan kasus tertinggi pada tahun 2010 di Pengadilan Agama (PA). Dari tahun ke tahun angka perceraian semakin mengalami kenaikan. Sehingga oleh Pengadilan Tinggi Agama (PTA) dilakukan penyuluhan untuk mengantisipasi kenaikan kasus perceraian secara terus menerus. Untuk menunjang keberhasilan dari pelaksanaan penyuluhan yang dilakukan oleh PTA diperlukan suatu penelitian yang dapat mengelompokkan kabupaten/kota yang mempunyai ciri-ciri atau karakteristik yang hampir sama. Menurut penelitian (Febriani,1999), berdasarkan penyebab perceraian di wilayah 36 Kabupaten/kota di Jawa Timur pada tahun 1996 dan tahun 1997 dibagi menjadi 3 kelompok. Faktor pembeda dari masing pengelompokan adalah pada tahun 1996 terdapat 4 variabel pembeda, sedangkan tahun 1997 terdapat 6 variabel pembeda. Dalam penelitian ini analisis yang digunakan analisis multivariat meliputi analisis cluster dan analisis diskriminan. Penelitian ini mengelompokkan wilayah Jawa Timur berdasarkan faktor penyebab perceraian dengan menggunakan metode single linkage, average linkage, complete linkage, ward linkage dan 3 jarak kedekatan. Variabel yang digunakan dalam penelitian ini adalah 7 variabel faktor penyebab perceraian yang diambil dari data PTA. Metode ward linkage merupakan metode pengelompokan terbaik. Hasil pengelompokan terbaik terbentuk menjadi 3 kelompok dan tiap-tiap kelompok terdiri dari Kelompok 1(11 Kabupaten/kota), kelompok 2(7 Kabupaten/kota) dan kelompok 3(19 Kabupaten/kota). Ada 3 variabel pembeda yaitu meninggalkan kewajiban, kawin dibawah umur dan penganiayaan. Dengan ketepatan fungsi diskriminan yang sudah dibentuk adalah 94,5%.
Kata Kunci : Perceraian, Analisis Cluster, Analisis Diskriminan
1. Pendahuluan
Perceraian adalah putusnya suatu hubungan suami istri, yang di karenakan sudah tidak ada kecocokan satu sama lain. Putusnya perkawinan oleh suami atau istri atau atas kesepakatan kedua-duanya apabila hubungan mereka tidak lagi memungkinkan tercapainya tujuan perkawinan. Oleh karena itu, perceraian dapat dilakukan apabila dengan alasan yang kuat dengan Hukum Perkawinan yang berlaku di Indonesia dituangkan di dalam Undang-Undang Nomor 1 tahun 1974 dan Peraturan Pemerintah Nomor 9 Tahun 1975.
Menurut data Pengadilan Tinggi Agama Surabaya, dari tahun ke tahun perceraian mengalami peningkatan. Hal ini dapat dilihat dari data perceraian, dari tahun 2007 sampai 2010. Pada tahun 2007 jumlah perceraian di Jawa Timur 47.356 perkara. Dan pada tahun 2008 perceraian meningkat menjadi 56.378 perkara. Begitu pula pada tahun 2009 perceraian mengalami meningkat menjadi 62.720 perkara. Sedangkan pada tahun 2010 menjadi 67.923 perkara.
Menurut penelitian RR arief Surya febriani (1999),berdasarkan faktor penyebab perceraian di wilayah 36 Kabupaten/Kota di Jawa Timur pada tahun 1996 dan tahun 1997 dibagi menjadi 3 kelompok. Faktor pembeda dari masing pengelompokan adalah pada tahun 1996 terdapat 4 variabel pembeda, sedangkan pada tahun 1997 terdapat 6 variabel pembeda.
2
Usaha pihak Pengadilan Tinggi Agama untuk mengantisipasi terjadinya perceraian tersebut adalah dengan mengadakan suatu penyuluhan, berupa penyuluhan hukum. Tujuan penyuluhan ini untuk memperkenalkan UU perkawinan dan UU peradilan agama guna memberikan informasi hukum agar dapat diketahui, dipahami, dihayati dan selanjutnya dapat diwujudkan dalam pola berfikir dan bertingkah laku masyarakat. Diharapkan, hal ini bisa memberikan solusi dari masalah perkawinan dan menyempitkan kasus perceraian yang terjadi melalui program mediasi.
Untuk membantu mewujudkan program dari Pengadilan Tinggi Agama tersebut, maka perlu suatu informasi tentang keadaan dari masyarakat Jawa Timur. Penelitian ini bertujuan mengelompokkan Kabupaten/Kota di Provinsi Jawa Timur berdasarkan penyebab perceraian pada tahun 2010 dan membandingkan hasil pengelompokan Kabupaten/Kota di Provinsi Jawa Timur berdasarkan penyebab perceraian pada tahun 1996 dan 1997 dengan hasil pengelompokan Kabupaten/Kota di Provinsi Jawa Timur berdasarkan penyebab perceraian pada tahun 2010. Untuk pengelompokan menggunakan Analisis Multivariat meliputi Analisis Cluster dan Analisis Diskriminan.
2. Tinjauan Pustaka 2.1 Analisis Cluster
Analisis kelompok (Cluster analiysis) merupakan sebuah metode analisis untuk mengelompokkan objek-objek pengamatan menjadi beberapa kelompok sehingga akan diperoleh kelompok dimana objek-objek dalam satu kelompok mempunyai banyak persamaan sedangkan dengan anggota kelompok yang lain mempunyai banyak perbedaan (Johnson dan Wichern, 2002). Prosedur pengelompokan pada dasarnya ada dua, yaitu pengelompokan dengan prosedur hierarki dan tak berhierarki. Pada penelitian ini metode yang dipakai adalah prosedur hierarki karena jumlah kelompok yang akan dibentuk belum ditentukan. Pembentukan kelompok dilakukan dengan pemotongan dendogram yang dihasilkan dari analisis. Dalam pembentukan kelompok ditentukan jarak antara dua objek yang nantinya digabungkan menjadi satu. Beberapa macam jarak yang biasa dipakai di dalam analisis kelompok: Euclidean, Manhatan, dan Pearson. Empat Metode yang digunakan dalam analisis Cluster ini yaitu (1) single linkage, (2) complete linkage, (3) average linkage, dan (4) metode ward’s.
2.2 Pengujian Asumsi 2.2.1 Uji Kenormalan Data
Pemeriksaan kenormalan data merupakan tahap awal sebelum dilakukan analisis diskriminan. Pemeriksaan kenormalan, untuk memeriksa data apakah merupakan suatu multivariate normal, dapat dilihat dari hasil plot antara dj2 dengan chi-square
n j 2 1 , apabila hasil plot menggambarkan garis lurus maka data tersebut dapat dinyatakan sebagai multivariate normal. Hasil yang diperoleh berdasarkan pemeriksaan sifatnya sangat subyektif dan tergantung pada orang yang menafsirkan plot tersebut. Untuk memperoleh hasil yang lebih obyektif, didasarkan pada anggapan jika observasi berasal dari distribusi normal dan kontur densitas konstantanya berbentuk ellips. Sehingga persamaannya adalah:
n
j
X
X
S
X
X
dj
2
(
j
)
'.
1(
j
)
,
1
,
2
,...,
Pengujian ini dapat dilakukan untuk menguji asumsi multivariat normal distribusi berdimensi p. Pengujian nilai-nilai dj2 dari persamaan diatas.
Hipotesanya adalah :
H0 : Data mengikuti sebaran distribusi multivariat normal.
H1 : Data tidak mengikuti sebaran distribusi multivariat normal.
Kriterianya adalah tolak H0 jika terdapat 50% nilai jarak dj2
2p;0,5 dimana p3
2.2.2 Uji Kehomogenan Varian KovarianPada uji homogenitas matriks varians-kovarians digunakan untuk melihat homogenitas dari antar variabel. Beberapa analisa statistika multivariat seperti
diskriminan analysis dan MANOVA membutuhkan syarat matriks varians-kovarians yang homogen. Untuk menguji syarat ini dapat dipergunakan statistik uji Box’s-M. Hipotesis dan statistik uji Box’s-M adalah:
Hipotesa :
H0 :12....k
H1 : Paling sedikit ada satu i j(untuk
i
j
)Statistik Uji :
k i k ii i pool i i hitung c v v 1 1 1 2 ln 2 1 ln 2 1 ) 1 ( 2 S S Keputusan :Tolak H0 yang berarti matriks varians-kovarians bersifat homogen jika 2 ) 1 ( ) 1 ( 2 1 2
p p k hitung
Apabila asumsi kehomogenan matrik varian kovarian belum terpenuhi, maka perlu dilakukan transformasi nilai Wilks Lambda ke uji F.
2.2.3 Uji Vektor rata-rata
Untuk menyelidiki apakah rata-rata vektor dari k buah populasi sama atau tidak maka dilakukan pengujian terhadap vektor rata-rata antar kelompok dilakukan dengan langkah sebagai berikut:
Hipotesis :
H0 : µ1= µ2=…= µg
H1 : paling sedikit ada satu µi (i= 1,2,...,g)
Statistik uji yang digunakan statistik Wilk’s Lamda (Λ*), yaitu :
Λ*
W
B
W
Wilk’s LambdaApabila hasil pengamatan menolak H0 maka Λ* sangat kecil. Uji statistik Wilks Lambda
ini mendekati statistik uji F dan H0 ditolak jika Statistik hitung F > Ftabel ini berarti ada
perbedaan vektor rata-rata, maka fungsi Diskriminan layak untuk digunakan.
2.3 Analisis Diskriminan
Analisis Diskriminan merupakan salah satu metode analisis multivariat yang digunakan untuk mengetahui variabel-variabel ciri yang membedakan tiap-tiap kelompok yang terbentuk dan bertujuan untuk mengklasifikasikan beberapa kelompok data yang sudah terkelompokkan dengan cara membentuk kombinasi linear fungsi diskriminan, sedemikian hingga setiap objek menjadi anggota dari salah satu kelompok, selain itu juga menjelaskan hubungan dependensi antara variabel respon dan variabel penjelas.
Dalam analisis diskriminan terdapat dua macam pengelompokan, yaitu untuk dua kelompok dan lebih dari dua kelompok. Dalam penelitian ini yang digunakan pengelompokan untuk dua kelompok dan lebih dari dua kelompok. Fungsi diskriminan merupakan suatu kombinasi linier dari p variabel dengan memaksimumkan jarak antara dua grup atau kelompok vektor rata-rata.
Setelah diperoleh fungsi diskriminan maka dapat dihitung skor faktor diskriminan untuk tiap observasi dengan memasukkan nilai-nilai variabelnya. Cutting score dapat dihitung dengan rumus sebagai berikut:
1 2
2
1
X
X
m
atau 2 1 2 2 1 1n
n
X
n
X
n
m
4
nk adalah jumlah sampel ada kelompok ke-k, k=1,2
Kemudian nilai-nilai disriminan score tiap observasi akan dibandingkan dengan nilai cutting score, sehingga dapat diklasifikasikan suatu observasi akan termasuk kedalam kelompok yang mana. Suatu observasi multivariat dengan karakteristik z akan diklasifikasikan sebagai anggota kelompok/ group 1 jika :
Z
a
'x
m
untukselanjutnya akan dimasukkan ke dalam kelompok 2.
3. Metodologi 3.1 Sumber Data
Data yang digunakan pada penelitian ini adalah data sekunder, data tersebut diperoleh dari Laporan perkara yang diputus pada Pengadilan Agama Se Wilayah Pengadilan Tinggi Agama Surabaya dan Penyebab-Penyebab Perceraian pada Kasus Cerai Gugat dan Cerai Talak pada tahun 2010 yang dipublikasikan oleh Pengadilan Tinggi Agama Surabaya. Wilayah dari Pengadilan Tinggi Agama Surabaya mencakup dari Pengadilan Agama Se Jawa Timur.
3.2 Variabel Penelitian
Variabel
-variabel yang digunakan dalam penelitian ini adalah sebagai
berikut:
X1 =Persentase penyebab utama perceraian karena Moral per Kabupaten/Kota. Variabel
ini diukur berdasarkan rasio jumlah perceraian karena poligami tidak sehat, krisis akhlak, dan cemburu terhadap total perceraian pada Kabupaten/Kota.
X2 =Persentase penyebab utama perceraian karena Meninggalkan kewajiban per
Kabupaten/Kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena kawin paksa, ekonomi, dan tidak tanggung jawab terhadap total perceraian pada Kabupaten/Kota.
X3 =Persentase penyebab utama perceraian karena Kawin di bawah umur per
Kabupaten/Kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena Kawin dibawah umur terhadap total perceraian pada Kabupaten/Kota.
X4 =Persentase penyebab utama perceraian karena Penganiayaan per Kabupaten/Kota.
Variabel ini diukur berdasarkan rasio jumlah perceraian karena kekejaman mental dan kekejaman fisik terhadap total perceraian pada Kabupaten/Kota.
X5 =Persentase penyebab utama perceraian karena Dihukum per Kabupaten/Kota.
Variabel ini diukur berdasarkan rasio jumlah perceraian karena dihukum terhadap total perceraian pada Kabupaten/Kota.
X6 =Persentase penyebab utama perceraian karena Cacat Biologis per Kabupaten/Kota.
Variabel ini diukur berdasarkan rasio jumlah perceraian karena Cacat Biologis terhadap total perceraian pada Kabupaten/Kota.
X7 =Persentase penyebab utama perceraian karena Terus Menerus berselisih per
Kabupaten/Kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena politis, gangguan pihak ketiga, tidak ada keharmonisan terhadap total perceraian pada Kabupaten/Kota.
3.3 Langkah-langkah Analisis Data
Analisis data dibutuhkan untuk menjawab permasalahan dalam penelitian ini. Langkah-langkah yang dilakukan adalah sebagai berikut:
1. Untuk menjawab permasalahan pertama dilakukan langkah-langkah sebagai berikut: a. Menentukan metode yang digunakan dalam cluster analisis, yaitu menggunakan
metode hirarki, karena banyak nya kelompok yang akan terbentuk belum ditentukan terlebih dahulu. Dalam pembentukan kelompok akan dilakukan pemotongan dendogram.
b. Menentukan kemiripan dalam satu kelompok.
c. Memaparkan dari setiap anggota kelompok yang terbentuk. d. Menguji kenormalan data.
5
e. Menguji matriks varian kovarian antar kelompok homogen. f. Menguji vektor rata-rata.
g. Menghitung ketepatan klasifikasi dari hasil analisis kelompok yang terbentuk dengan analisis diskriminan.
2. Untuk menjawab permasalahan kedua dilakukan dengan membandingkan hasil pengelompokan yang diperoleh dari pengelompokan daerah tingkat II di Jawa Timur berdasarkan faktor-faktor penyebab perceraian pada tahun 1996 dan 1997. dengan hasil pengelompokan kabupaten/kota di Provinsi Jawa Timur berdasarkan faktor-faktor penyebab perceraian pada tahun 2010.
4. Analisis dan Pembahasan 4.1 Statistik Deskriptif
Faktor-faktor penyebab perceraian di setiap Pengadilan Agama di Kabupaten/Kota merupakan tolak ukur yang digunakan oleh Pengadilan Tinggi Agama Surabaya untuk menghitung jumlah perceraian yang terjadi pada 38 Kabupaten/Kota di Jawa Timur. Ada 15 variabel penyebab perceraian yang digunakan oleh seluruh Pengadilan Agama. Penelitian ini menggunakan 7 variabel penyebab perceraian karena sudah terjadi penggabungan dari variabel yang sebelumnya. Penelitian ini dilakukan untuk mengelompokkan Kabupaten/Kota di Jawa Timur berdasarkan faktor-faktor penyebab perceraian pada tahun 2010. Angka perceraian tertinggi diantara 38 kabupaten/kota di Provinsi Jawa Timur pada tahun 2010 adalah Kabupaten Banyuwangi yaitu sebesar 4.655 kasus perceraian dan angka terendah pada Kota Madiun yaitu sebesar 344 kasus perceraian. Faktor penyebab perceraian paling tinggi pada tahun 2010 dikarenakan variabel terus menerus berselisih dan paling rendah yaitu variabel dihukum.
4.2 Analisis Kelompok
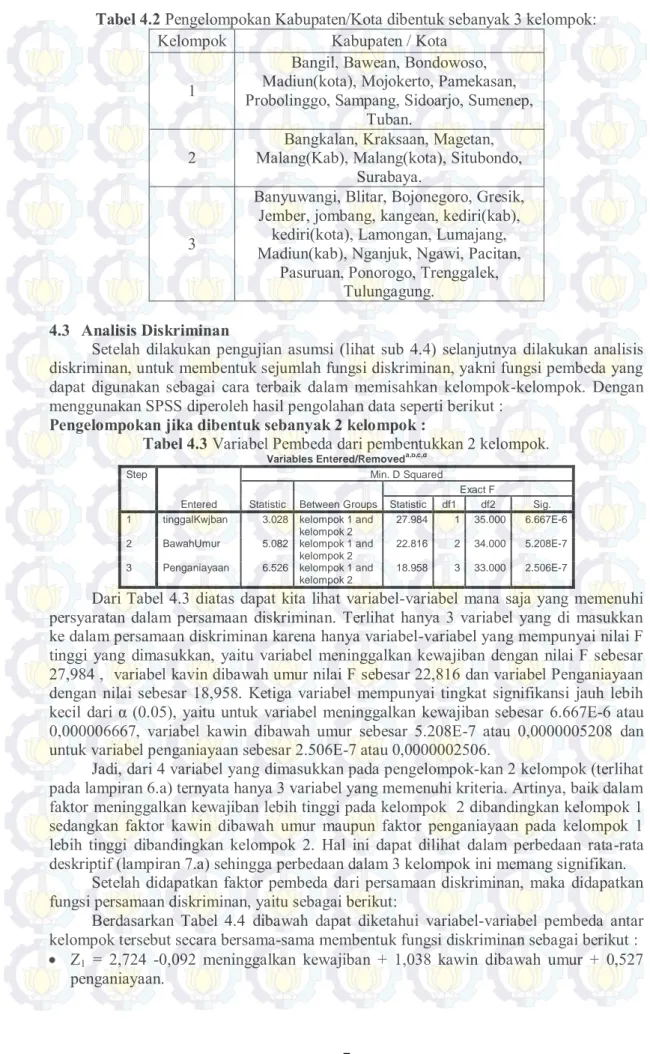
Pada analisis cluster ini metode yang digunakan adalah cluster hirarki, karena banyaknya kelompok yang akan terbentuk tidak ditentukan terlebih dahulu, sehingga dalam pembentukannya dilakukan pemotongan dendogram. Untuk menentukan kemiripan dalam satu kelompok dan metode paling baik digunakan metode ward linkage dengan jarak nya pearson. Tidak menggunakan metode yang lain karena pada metode single linkage, average linkage, dan complete linkage meskipun dengan jarak euclidean, manhattan atau pearson tidak memenuhi asumsi-asumsi dari fungsi diskriminan. Pengelompokan dijadikan menjadi 2 yaitu akan dibentuk menjadi 2 kelompok dan 3 kelompok. Berikut adalah grafik yang didapat dari output minitab :
Gambar 4.1 dan tabel 4.1 menunjukkan Pengelompokan didasarkan pada jumlah data atau banyak nya observasi yaitu sebanyak 37 data, sehingga dapat diketahui data dibagi menjadi 2 kelompok besar yaitu kelompok 1 terdiri dari 18 kabupaten/kota dan kelompok 2 terdiri dari 19 kabupaten/ kota. Berikut adalah tabel hasil pengelompokan dengan meng-gunakan metode ward linkage.
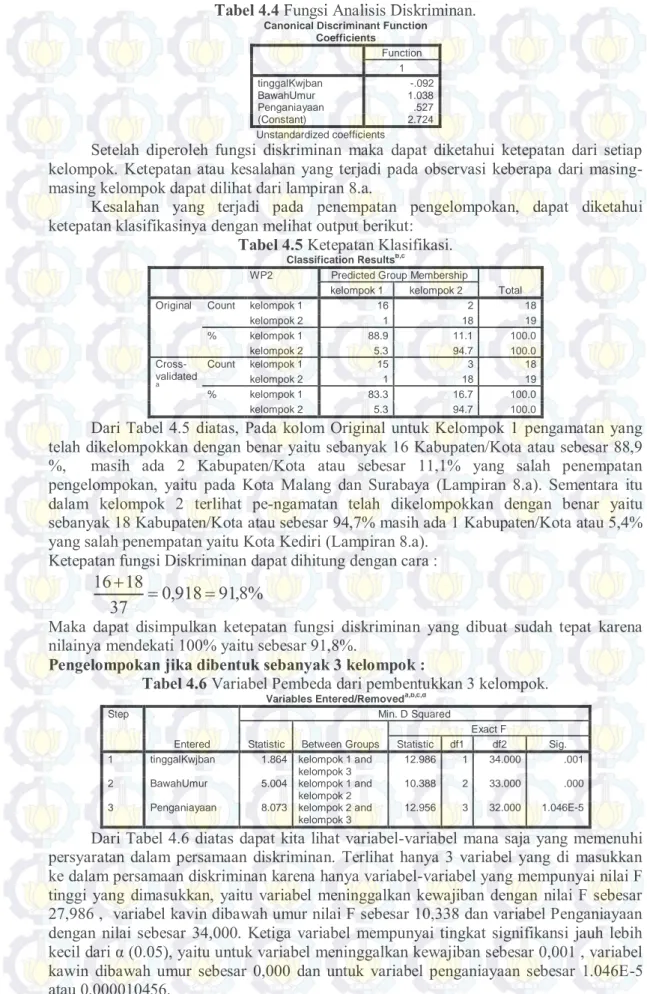
Gambar 4.2 dan tabel 4.2 menunjukkan Pengelompokan diatas didasarkan pada jumlah data atau banyaknya observasi yaitu sebanyak 37 data, sehingga dapat diketahui data dibagi menjadi 3 kelompok besar yaitu kelompok 1 terdiri dari 11 kabupaten/kota, kelompok 2 terdiri dari 7 kabupaten/kota sedangkan kelompok ke 3 terdiri dari 19 kabupaten/kota. Berikut adalah tabel hasil pengelompokan dengan menggunakan metode ward linkage.
Gambar 4.1 Dendogram dengan metode Ward linkage, Pearson Distance untuk 2 kelompok.
6
Tulun gagu ng Ngaw i Pacit an Ngan juk Lamo ngan Kang ean Madiu n (k a b) Gresi k Bojo nego ro Kedir i (kab ) Blitar Tren ggale k Pono rogo Kedir i (Kot a) Pasu ruan Luma jang Jemb er Jomb ang Bany uwan gi Mage tan Surab aya Malan g (ko ta) Malan g (ka b) Krak saan Situb ondo Bang kalan Sume nep Tuba n Sidoa rjo Mojok erto Pame k asa n Madiu n (ko ta) Bond owos o Bawe an Samp ang Prob oling go Bang il 15.82 10.55 5.27 0.00 Observations D is ta n ce Dendrogram Ward Linkage, Pearson DistanceTabel 4.1 Pengelompokan Kabupaten/Kota sebanyak 2 kelompok:
Kelompok Kabupaten / Kota
1
Bangil, Bangkalan, Bawean, Bondowoso,Kraksaan, Madiun(kota), Magetan, Malang(Kab), Malang(kota),
Mojokerto, Pamekasan, Probolinggo, Sampang, Sidoarjo, Situbondo, Sumenep,
Surabaya, Tuban. 2
Banyuwangi, Blitar, Bojonegoro, Gresik, Jember, jombang, kangean, kediri(kab),
kediri(kota), Lamongan, Lumajang, Madiun(kab), Nganjuk, Ngawi, Pacitan,
Pasuruan, Ponorogo, Trenggalek, Tulungagung.
Berikut adalah Pengelompokan dibentuk sebanyak 3 kelompok :
Gambar 4.2 Dendogram dengan metode Ward linkage, Pearson Distance untuk 3 kelompok. Tulun gagu ng Ngaw i Pacit an Ngan juk Lamo ngan Kang ean Madiu n (k a b) Gresi k Bojo nego ro Kedir i (kab ) Blitar Tren ggale k Pono rogo Kedir i (Kot a) Pasu ruan Luma jang Jemb er Jomb ang Bany uwan gi Mage tan Surab aya Malan g (ko ta) Malan g (ka b) Krak saan Situb ondo Bang kalan Sume nep Tuba n Sidoa rjo Mojok erto Pame k asa n Madiu n (ko ta) Bond owos o Bawe an Samp ang Prob oling go Bang il 15.82 10.55 5.27 0.00 Observations D is ta n ce Dendrogram
7
Tabel 4.2 Pengelompokan Kabupaten/Kota dibentuk sebanyak 3 kelompok:
Kelompok Kabupaten / Kota
1
Bangil, Bawean, Bondowoso, Madiun(kota), Mojokerto, Pamekasan, Probolinggo, Sampang, Sidoarjo, Sumenep,
Tuban.
2 Malang(Kab), Malang(kota), Situbondo, Bangkalan, Kraksaan, Magetan, Surabaya.
3
Banyuwangi, Blitar, Bojonegoro, Gresik, Jember, jombang, kangean, kediri(kab),
kediri(kota), Lamongan, Lumajang, Madiun(kab), Nganjuk, Ngawi, Pacitan,
Pasuruan, Ponorogo, Trenggalek, Tulungagung.
4.3 Analisis Diskriminan
Setelah dilakukan pengujian asumsi (lihat sub 4.4) selanjutnya dilakukan analisis diskriminan, untuk membentuk sejumlah fungsi diskriminan, yakni fungsi pembeda yang dapat digunakan sebagai cara terbaik dalam memisahkan kelompok-kelompok. Dengan menggunakan SPSS diperoleh hasil pengolahan data seperti berikut :
Pengelompokan jika dibentuk sebanyak 2 kelompok :
Tabel 4.3 Variabel Pembeda dari pembentukkan 2 kelompok.
Variables Entered/Removeda,b,c,d
Step
Entered
Min. D Squared Statistic Between Groups
Exact F
Statistic df1 df2 Sig.
1 tinggalKwjban 3.028 kelompok 1 and
kelompok 2
27.984 1 35.000 6.667E-6
2 BawahUmur 5.082 kelompok 1 and
kelompok 2
22.816 2 34.000 5.208E-7
3 Penganiayaan 6.526 kelompok 1 and
kelompok 2
18.958 3 33.000 2.506E-7
Dari Tabel 4.3 diatas dapat kita lihat variabel-variabel mana saja yang memenuhi persyaratan dalam persamaan diskriminan. Terlihat hanya 3 variabel yang di masukkan ke dalam persamaan diskriminan karena hanya variabel-variabel yang mempunyai nilai F tinggi yang dimasukkan, yaitu variabel meninggalkan kewajiban dengan nilai F sebesar 27,984 , variabel kavin dibawah umur nilai F sebesar 22,816 dan variabel Penganiayaan dengan nilai sebesar 18,958. Ketiga variabel mempunyai tingkat signifikansi jauh lebih kecil dari α (0.05), yaitu untuk variabel meninggalkan kewajiban sebesar 6.667E-6 atau 0,000006667, variabel kawin dibawah umur sebesar 5.208E-7 atau 0,0000005208 dan untuk variabel penganiayaan sebesar 2.506E-7 atau 0,0000002506.
Jadi, dari 4 variabel yang dimasukkan pada pengelompok-kan 2 kelompok (terlihat pada lampiran 6.a) ternyata hanya 3 variabel yang memenuhi kriteria. Artinya, baik dalam faktor meninggalkan kewajiban lebih tinggi pada kelompok 2 dibandingkan kelompok 1 sedangkan faktor kawin dibawah umur maupun faktor penganiayaan pada kelompok 1 lebih tinggi dibandingkan kelompok 2. Hal ini dapat dilihat dalam perbedaan rata-rata deskriptif (lampiran 7.a) sehingga perbedaan dalam 3 kelompok ini memang signifikan.
Setelah didapatkan faktor pembeda dari persamaan diskriminan, maka didapatkan fungsi persamaan diskriminan, yaitu sebagai berikut:
Berdasarkan Tabel 4.4 dibawah dapat diketahui variabel-variabel pembeda antar kelompok tersebut secara bersama-sama membentuk fungsi diskriminan sebagai berikut :
Z1 = 2,724 -0,092 meninggalkan kewajiban + 1,038 kawin dibawah umur + 0,527
8
Tabel 4.4 Fungsi Analisis Diskriminan.
Canonical Discriminant Function Coefficients Function 1 tinggalKwjban -.092 BawahUmur 1.038 Penganiayaan .527 (Constant) 2.724 Unstandardized coefficients
Setelah diperoleh fungsi diskriminan maka dapat diketahui ketepatan dari setiap kelompok. Ketepatan atau kesalahan yang terjadi pada observasi keberapa dari masing-masing kelompok dapat dilihat dari lampiran 8.a.
Kesalahan yang terjadi pada penempatan pengelompokan, dapat diketahui ketepatan klasifikasinya dengan melihat output berikut:
Tabel 4.5 Ketepatan Klasifikasi.
Classification Resultsb,c
WP2 Predicted Group Membership
Total kelompok 1 kelompok 2
Original Count kelompok 1 16 2 18
kelompok 2 1 18 19 % kelompok 1 88.9 11.1 100.0 kelompok 2 5.3 94.7 100.0 Cross-validated a Count kelompok 1 15 3 18 kelompok 2 1 18 19 % kelompok 1 83.3 16.7 100.0 kelompok 2 5.3 94.7 100.0
Dari Tabel 4.5 diatas, Pada kolom Original untuk Kelompok 1 pengamatan yang telah dikelompokkan dengan benar yaitu sebanyak 16 Kabupaten/Kota atau sebesar 88,9 %, masih ada 2 Kabupaten/Kota atau sebesar 11,1% yang salah penempatan pengelompokan, yaitu pada Kota Malang dan Surabaya (Lampiran 8.a). Sementara itu dalam kelompok 2 terlihat pe-ngamatan telah dikelompokkan dengan benar yaitu sebanyak 18 Kabupaten/Kota atau sebesar 94,7% masih ada 1 Kabupaten/Kota atau 5,4% yang salah penempatan yaitu Kota Kediri (Lampiran 8.a).
Ketepatan fungsi Diskriminan dapat dihitung dengan cara :
%
8
,
91
918
,
0
37
18
16
Maka dapat disimpulkan ketepatan fungsi diskriminan yang dibuat sudah tepat karena nilainya mendekati 100% yaitu sebesar 91,8%.
Pengelompokan jika dibentuk sebanyak 3 kelompok :
Tabel 4.6 Variabel Pembeda dari pembentukkan 3 kelompok.
Variables Entered/Removeda,b,c,d
Step
Entered
Min. D Squared Statistic Between Groups
Exact F
Statistic df1 df2 Sig.
1 tinggalKwjban 1.864 kelompok 1 and
kelompok 3
12.986 1 34.000 .001
2 BawahUmur 5.004 kelompok 1 and
kelompok 2
10.388 2 33.000 .000
3 Penganiayaan 8.073 kelompok 2 and
kelompok 3
12.956 3 32.000 1.046E-5
Dari Tabel 4.6 diatas dapat kita lihat variabel-variabel mana saja yang memenuhi persyaratan dalam persamaan diskriminan. Terlihat hanya 3 variabel yang di masukkan ke dalam persamaan diskriminan karena hanya variabel-variabel yang mempunyai nilai F tinggi yang dimasukkan, yaitu variabel meninggalkan kewajiban dengan nilai F sebesar 27,986 , variabel kavin dibawah umur nilai F sebesar 10,338 dan variabel Penganiayaan dengan nilai sebesar 34,000. Ketiga variabel mempunyai tingkat signifikansi jauh lebih kecil dari α (0.05), yaitu untuk variabel meninggalkan kewajiban sebesar 0,001 , variabel kawin dibawah umur sebesar 0,000 dan untuk variabel penganiayaan sebesar 1.046E-5 atau 0.000010456.
9
Jadi, dari 5 variabel yang dimasukkan (terlihat pada lampiran 6.b) ternyata hanya 3 variabel yang memenuhi kriteria. Artinya, baik dalam faktor meninggalkan kewajiban lebih tinggi pada kelompok 3 dibandingkan kelompok 2 maupun kelompok 1 sedangkan faktor kawin dibawah umur maupun faktor penganiayaan pada kelompok 1 lebih tinggi dibandingkan kelompok 2 dan kelompok 3. Hal ini dapat dilihat dalam perbedaan rata-rata deskriptif (Lampiran 7.b) sehingga perbedaan dalam 3 kelompok ini memang signifikan.
Setelah didapatkan faktor pembeda dari persamaan diskriminan, maka didapatkan fungsi persamaan diskriminan, yaitu sebagai berikut:
Tabel 4.7 Fungsi Analisis Diskriminan.
Canonical Discriminant Function Coefficients
Function 1 2 tinggalKwjban -.033 .100 BawahUmur 1.742 .369 Penganiayaan 1.098 .420 (Constant) -.924 -5.033 Unstandardized coefficients
Berdasarkan Tabel 4.7 diatas dapat diketahui variabel-variabel pembeda antar kelompok tersebut secara bersama-sama membentuk fungsi diskriminan sebagai berikut :
Z1 = - 0,924 -0,033 meninggalkan kewajiban + 1,742 kawin dibawah umur + 1,098
penganiayaan.
Z2 = - 5,033 + 0,1 meninggalkan kewajiban + 0,369 kawin dibawah umur + 0,42
penganiayaan.
Setelah diperoleh fungsi diskriminan maka dapat diketahui ketepatan dari setiap kelompok. Ketepatan atau kesalahan yang terjadi pada observasi keberapa dari masing-masing kelompok dapat dilihat dari lampiran 8.b.
Kesalahan yang terjadi pada penempatan pengelompokan, dapat diketahui ketepatan klasifikasinya dengan melihat output berikut:
Tabel 4.8 Ketepatan Klasifikasi.
Classification Resultsb,c
WP3 Predicted Group Membership
Total kelompok 1 kelompok 2 kelompok 3
Original Count kelompok 1 10 1 0 11
kelompok 2 0 7 0 7 kelompok 3 0 1 18 19 % kelompok 1 90.9 9.1 .0 100.0 kelompok 2 .0 100.0 .0 100.0 kelompok 3 .0 5.3 94.7 100.0 Cross-validateda Count kelompok 1 10 1 0 11 kelompok 2 0 6 1 7 kelompok 3 0 1 18 19 % kelompok 1 90.9 9.1 .0 100.0 kelompok 2 .0 85.7 14.3 100.0 kelompok 3 .0 5.3 94.7 100.0
Dari Tabel 4.8 diatas Pada kolom Original untuk Kelompok 1 pengamatan yang telah dikelompokkan dengan benar yaitu sebanyak 10 Kabupaten/Kota atau sebesar 90,9 %, masih ada 1 Kabupaten/Kota atau sebesar 9,1% yang salah penempatan pengelompokan, yaitu pada Kabupaten Pamekasan (Lampiran 8.b). Sementara itu dalam kelompok 2 terlihat pengamatan telah dikelompokkan dengan benar yaitu sebanyak 7 Kabupaten/Kota atau sebesar 100 %. Dalam kelompok 3 terlihat pengamatan telah dikelompokkan dengan benar yaitu sebanyak 18 Kabupaten/Kota atau sebesar 94,7%.Dan penempatan pengelompokan salah sebanyak 1 Kabupaten/Kota atau 5,3% yaitu kabupaten Pasuruan (Lampiran 8.b).
Ketepatan fungsi Diskriminan dapat dihitung dengan cara :
%
5
,
94
945
,
0
37
18
7
10
10
Maka dapat disimpulkan ketepatan fungsi diskriminan yang dibuat sudah tepat karena nilainya mendekati 100% yaitu sebesar 94,5%.
Dengan demikian, dari hasil fungsi diskriminan dan ketepatan fungsi pada pembentukan 2 kelompok dan 3 kelompok dapat disimpulkan bahwa hasil lebih baik jika pengelompokan menjadi 3 kelompok yaitu dengan ketepatan fungsi diskriminan nya bernilai 94,5%.
4.4 Pengujian Asumsi 4.4.1 Uji kenormalan data
Uji kenormalan data dilakukan untuk mengetahui apakah data yang digunakan mengikuti distribusi multivariat normal atau tidak. Karena multivariat normal merupakan syarat utama dalam melakukan analisa multivariat.
Hipotesa :
H0:Data mengikuti sebaran distribusi multivariat normal.
H1:Data tidak mengikuti sebaran distribusi multivariat normal.
Statistik uji = nilai dj2berdasarkan persamaaan (2.5) diperoleh hasil
;0,05 2 2 p dj
lebih dari 50% yaitu 94,5.Daerah kritis : tolak H0 jika nilai dj2
27;0,05 kurang dari 50%.Keputusan : Gagal tolak H0 karena nilai dj2 2,167 lebih dari 50 % yaitu sebesar
94,5%. Secara grafik dapat dilihat pada plot qq (lampiran 5) yang menunjukkan bahwa plot cenderung mem-bentuk garis lurus. Hasil tersebut menunjukkan bahwa data mengikuti sebaran distribusi multivariat normal. Maka dapat disimpulkan pada pemeriksaan multivariat normal variabel mengikuti sebaran distribusi multivariat normal, maka dapat dilakukan analisis selanjutnya.
4.4.2 Uji kehomogenan Varian Kovarian
Pengujian ini dilakukan untuk mengetahui apakah variabel satu dengan yang lainnya memiliki hubungan yang homogen. Dalam uji homogenitas digunakan statistic uji
Box’s-M pada program SPSS. Berikut ini hasil pengujiannya : Uji Homogenitas untuk 2 kelompok :
Hipotesis: H0 1 2
H1 = Paling sedikit ada satu 1 2
Taraf Signifikan : α =0,05
Daerah penolakan : Tolak H0 jika P-value < α (0,05)
Tabel 4.9 Uji Homogenitas untuk 2 kelompok :
Test Results Box's M 114.095 F Approx. 4.420 df1 21 df2 4474.994 Sig. .000
Tests null hypothesis of equal population covariance matrices.
Pvalue = 0.000
Keputusan : tolak H0, karena nilai significance statistik uji Box’s-M kurang dari α (0.05).
Dapat disimpulkan bahwa matriks varians-kovarians dari kelompok 1 dan kelompok 2 tersebut tidak homogen. Karena hasilnya tidak homogen maka selanjutnya dilakukan transformasi nilai Wilks Lambda ke uji F pada variabel x1 sampai x8.
11
81
,
29
)
2
7
7
(
2
1
077
,
5
5
,
10
)
2
(
2
1
49
7
7
7
7
)
1
2
(
)
1
(
2 1
H H Hpv
wt
df
pv
df
p
k
v
5 , 10 ) 1 7 7 ( 2 1 7 11 ) 1 ( 2 1 f vH p vH w Maka:1451
,
0
60836
,
0
80744
,
0
19255
,
0
49
81
,
29
3376
,
0
3376
,
0
1
1
*
077 , 5 / 1 077 , 5 / 1 1 2 / 1 / 1
df
df
F
t t Karena nilai F*< F(df1;df2;α) yaitu 0,1451<1,766 maka dapat disimpulkan tolak H0 jadi
matriks varian-kovarian pada pem-bentukan 2 kelompok tidak homogen. Analisis tetap dilanjutkan untuk mengetahui ketepatan dari pengelompokan yang sudah dibentuk. Uji Homogenitas untuk 3 kelompok :
Hipotesis:
H0 1 2 3
H1 = Paling sedikit ada satu i j Taraf Signifikan : α =0,05
Daerah penolakan : Tolak H0, jika P-value < α (0,05)
Tabel 4.10 Uji Homogenitas untuk 3 kelompok :
Test Results Box's M 198.327 F Approx. 3.090 df1 42 df2 1186.565 Sig. .000
Tests null hypothesis of equal population covariance matrices.
Pvalue = 0.000
Keputusan : tolak H0, karena nilai significance statistik uji Box’s-M kurang dari α (0.05).
077 , 5 77 , 25 5 7 7 4 7 7 5 4 2 2 2 2 2 2 2 2 H H v p v p t
12
Dapat disimpulkan bahwa matriks varians-kovarians dari kelompok 1, kelompok 2 dan kelompok 3 tersebut tidak homogen. Karena hasilnya tidak homogen maka selanjutnya dilakukan transformasi nilai Wilks Lambda ke uji F pada variabel x1 sampai x8.
Dengan persamaan (2.10) didapatkan perhitugan sebagai berikut:
469
,
59
)
2
14
7
(
2
1
321
,
6
0012
,
17
)
2
(
2
1
98
14
7
14
7
)
1
3
(
)
1
(
2 1
H H Hpv
wt
df
pv
df
p
k
v
0012 , 17 ) 1 14 7 ( 2 1 14 0012 , 4 ) 1 ( 2 1 f vH p vH w Maka:2825
,
0
606827
,
0
68237
,
0
31763
,
0
98
469
,
59
0893
,
0
0893
,
0
1
1
*
321 , 6 / 1 321 , 6 / 1 1 2 / 1 / 1
df
df
F
t t Karena nilai F*< Ftabel yaitu 0,2825<1,485 maka dapat disimpul-kan tolak H0 jadi
matriks varian-kovarian pada kelompok 1 sampai kelompok 3 tidak homogen. Analisis tetap dilanjutkan untuk mengetahui ketepatan dari pengelompokan yang sudah dibentuk.
4.4.3 Uji Vektor rata-rata
Dalam Dalam pembentukan fungsi diskriminan harus diketahui setiap variabel yang terlibat antara populasi berbeda secara signifikan. Untuk kepentingan tersebut dilakukan uji kesamaan vektor rata-rata.
Untuk melakukan pengujian kesamaan rata-rata digunakan dua cara, pertama dengan menggunakan angka Wilks’ Lambda dengan ketentuan sebagai berikut : Besarnya angka Wilks’ Lambda ialah antara 0-1. Jika angka mendekati 0, maka data cenderung berbeda ; sebaliknya jika angka mendekati 1, maka data cenderung sama. Cara kedua dengan menggunakan angka signifikansinya, dengan ketentuan sebagai berikut :
Jika signifikansi > 0,05 , maka tidak ada perbedaan dalam kelompok.
Jika signifikansi < 0,05 , maka ada perbedaan dalam kelompok. (Sarwono, 2009). 321 , 6 95 , 39 5 14 7 4 14 7 5 4 2 2 2 2 2 2 2 2 H H v p v p t
13
Dengan pengujian hipotesis : H0 : µ1= µ2
H1 : paling sedikit ada satu µi (i= 1,2,...,g)
Kriterua pengujian tolak H0 jika signifikan < α =0,05.
Dengan menggunakan perhitungan SPSS 18 diperoleh output pada 2 kelompok dan 3 kelompok sebagai berikut :
Pengelompokan sebanyak 2 kelompok :
Tabel 4.11 Uji Vektor rata-rata untuk 2 kelompok :
Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
1 .324 36.058 6 .000
Berdasarkan Tabel 4.11 diatas, dapat dilihat untuk nilai Wilks’ Lambda mendekati 0 artinya variabel pembeda yang terbentuk cenderung berbeda. Angka chisquare sebesar 36,058 dengan angka signifikansi sebesar 0,000 menunjukkan adanya perbedaan yang signifikan dalam kedua kelompok pada 3 variabel pembeda yang terbentuk.
Dengan demikian, jumlah variabel-variabel diatas merupakan faktor pembeda dalam kelompok 1 dan kelompok 2 yang terbentuk. Artinya Jumlah perceraian karena variabel-variabel diatas besar atau kecil akan mempengaruhi kelompok kabupaten atau kota. Kesimpulannya H0 di tolak artinya terdapat perbedaan yang signifikan anatara
beberapa variabel yang diteliti maka fungsi diskriminan layak untuk di bentuk. Pengelompokan sebanyak 3 kelompok :
Berdasarkan Tabel 4.12 dibawah, dapat dilihat untuk nilai Wilks’ Lambda mendekati 0 artinya variabel pembeda yang terbentuk cenderung berbeda. Angka chisquare sebesar 76,097 dengan angka signifikansi sebesar 0,000 menunjukkan adanya perbedaan yang signifikan dalam ketiga kelompok pada 3 variabel pembeda yang terbentuk.
Tabel 4.12 Uji Vektor rata-rata untuk 3 kelompok:
Wilks' Lambda
Test of Function(s) Wilks'
Lambda Chi-square df Sig.
1 through 2 .089 76.097 12 .000
2 .403 28.666 5 .000
Dengan demikian, jumlah variabel-variabel diatas merupakan faktor pembeda dalam kelompok 1, kelompok 2 dan kelompok 3 yang terbentuk. Artinya Jumlah perceraian karena variabel-variabel diatas besar atau kecil akan mempengaruhi kelompok kabupaten atau kota. Kesimpulannya H0 di tolak artinya terdapat perbedaan yang
signifikan antara beberapa variabel yang diteliti maka fungsi diskriminan layak untuk di bentuk.
4.5
Penyebab perceraian tahun 1996, tahun 1997 dan tahun 2010.
Pada Pada Bagian ini akan dibahas hasil perbandingan dari pengelompokan Kabupaten/Kota di Jawa Timur dari hasil penelitian tahun 1999 yang dilakukan oleh RR arief Surya febriani. Penelitian tentang penyebab perceraian ini menggunakan metode untuk pengelompokan yaitu analisis cluster. Penelitian ini juga dilakukan pada Propinsi Jawa Timur dengan jumlah 36 Kabupaten/Kota dan menggunakan 13 variabel. Dari 13 variabel tersebut direduksi menjadi 5 faktor, serta di bentuk menjadi 3 kelompok Kabupaten/Kota.
Pengelompokan menggunakan Analisis Cluster pada tahun 1996 dan pada tahun 1997 semuanya menggunakan metode complete linkage. Pada penelitian ini semua asumsi terpenuhi, sehingga tidak memerlukan transformasi data. Berikut hasil pengelompokan kabupaten/Kota pada tahun 1996 dan tahun 1997 :
Pada Tabel 4.13 dibawah terlihat Kelompok 1 terdapat 33 Kabupaten/Kota, pada kelompok 2 terdapat 2 Kabupaten/Kota, dan pada kelompok 3 terdapat hanya 1 Kabupaten/Kota yaitu Kabupaten Sampang. Jika pada analisis cluster ini hanya
14
menggunakan 2 kelompok maka Kabupaten Sampang akan masuk ke dalam kelompok 2. Begitu juga terlihat pada Tabel 4.14 terlihat jumlah anggota dari setiap kelompok sama dengan pengelompokan pada tahun 1996. Ada 1 kelompok yang ber-anggotakan 1 Kabupaten yaitu Kabupaten Sumenep yang berada pada kelompok 3. Jika pada analisis cluster ini hanya mengguna-kan 2 kelompok maka Kabupaten Sumenep akan masuk ke dalam kelompok 2. Hal ini disebabkan karena pada dasarnya analisis cluster meggunakan penggabungan variabel yang berkarakteristik sama.
Tabel 4.13 Pengelompokan Kabupaten/Kota pada tahun 1996.
Kelompok Kabupaten / Kota
1
Bangil, Bangkalan, Bawean, Blitar, Bojonegoro, Bondowoso, Gresik, Jember, Jombang, Kangean, Kraksaan, Kab.Kediri,
Kod.Kediri, Lamongan, Lumajang, Kab.Madiun, Kod.Madiun, Magetan, Malang, Mojokerto, Nganjuk, Ngawi, Pacitan, Ponorogo, Pamekasan, Pasuruan,
Probolinggo, Sidoarjo, Situbondo, Sumenep, Surabaya, Trenggalek, dan
Tulungagung.
2 Banyuwangi dan Tuban
3 Sampang
Tabel 4.14 Pengelompokan Kabupaten/Kota pada tahun 1997.
Kelompok Kabupaten / Kota
1
Bangil, Bangkalan, Bawean, Blitar, Bojonegoro, Bondowoso, Gresik, Jember, Jombang, Kangean, Kraksaan, Kab.Kediri,
Kod.Kediri, Lamongan, Lumajang, Kab.Madiun, Kod.Madiun, Magetan, Malang, Mojokerto, Nganjuk, Ngawi, Pacitan, Ponorogo, Pamekasan, Pasuruan,
Probolinggo, Sidoarjo, Situbondo, Surabaya, Trenggalek, Tuban dan
Tulungagung.
2 Banyuwangi dan Sampang
3 Sumenep
Pada Pengelompokan kabupaten/Kota pada tahun 1996 terdapat 4 variabel pembeda yaitu krisis akhlak, penganiayaan, politis dan gangguan pihak-3. Sedangkan pada pengelompokan Kabupaten/Kota pada tahun 1997 terdapat 6 variabel pembeda yaitu krisis akhlak, cemburu, ekonomi, kawin dibawah umur, penganiayaan, dan gangguan pihak-3.
Pengelompokan Kabupaten/Kota di Jawa Timur berdasar-kan penyebab-penyebab perceraian pada tahun 2010 yang saat ini di teliti menggunakan analisis cluster dengan metode pengelompokan yang terbaik yaitu metode ward linkage. Penelitian ini dilakukan pada 38 Kabupaten/Kota di Jawa Timur dengan 7 variabel penyebab perceraian dan di bentuk menjadi 2 kelompok kabupaten/kota dan 3 kelompok Kabupaten/Kota. Berikut hasil pembentukan 2 kelompok Kabupaten/Kota di Jawa Timur pada tahun 2010 :
Pada Tabel 4.15 dibawah dapat dilihat Kelompok 1 ber-anggotakan 18 kabupaten/Kota, kelompok 2 beranggotakan 19 Kabupaten/ Kota. Begitu juga terlihat pada Tabel 4.16 dapat dilihat Kelompok 1 beranggotakan 11 kabupaten/Kota, kelompok 2 beranggotakan 7 kabupaten/kota sedangkan kelompok ber-anggotakan 19
15
Kabupaten/Kota. Pada pengelompokan menjadi 2 kelompok maupun 3 kelompok terdapat 3 variabel pembeda yaitu variabel meninggalkan kewajiban, variabel kawin dibawah umur dan variabel penganiayaan.
Tabel 4.15
Pengelompokan Kabupaten/Kota pada tahun 2010.
Kelompok
Kabupaten / Kota
1
Bangil, Bangkalan, Bawean,
Bondowoso,Kraksaan, Madiun(kota),
Magetan, Malang(Kab), Malang(kota),
Mojokerto, Pamekasan, Probolinggo,
Sampang, Sidoarjo, Situbondo,
Sumenep, Surabaya, Tuban.
2
Banyuwangi, Blitar, Bojonegoro,
Gresik, Jember, jombang, kangean,
kediri(kab), kediri(kota), Lamongan,
Lumajang, Madiun(kab), Nganjuk,
Ngawi, Pacitan, Pasuruan, Ponorogo,
Trenggalek, Tulungagung.
Berikut hasil pembentukan 3 kelompok Kabupaten/Kota di Jawa Timur pada
tahun 2010 :
Tabel 4.16
Pengelompokan Kabupaten/Kota pada tahun 2010.
Kelompok
Kabupaten / Kota
1
Bangil, Bawean, Bondowoso,
Madiun(kota), Mojokerto, Pamekasan,
Probolinggo, Sampang, Sidoarjo,
Sumenep, Tuban.
2
Malang(Kab), Malang(kota), Situbondo,
Bangkalan, Kraksaan, Magetan,
Surabaya.
3
Banyuwangi, Blitar, Bojonegoro,
Gresik, Jember, jombang, kangean,
kediri(kab), kediri(kota), Lamongan,
Lumajang, Madiun(kab), Nganjuk,
Ngawi, Pacitan, Pasuruan, Ponorogo,
Trenggalek, Tulungagung.
5. KesimpulanBerdasarkan hasil analisis data dan pembahasan, maka kesimpulan yang dapat diambil dari penelitian ini adalah:
1. Angka perceraian tertinggi diantara 38 kabupaten/kota di Provinsi Jawa Timur pada tahun 2010 adalah Kabupaten banyuwangi yaitu sebesar 4.655 kasus perceraian dan angka terendah pada Kota madiun yaitu sebesar 344 kasus perceraian. Faktor penyebab perceraian paling tinggi pada tahun 2010 dikarenakan variabel terus menerus berselisih dan paling rendah kedua yaitu variabel dihukum.
2. Pada penelitian ini diperoleh perbandingan hasil antara pengelompokan menjadi 2 kelompok dan 3 kelompok Kabupaten/Kota dengan menggunakan metode terbaik yaitu metode ward linkage. Dari pengelompokan tersebut diketahui hasil terbaik yaitu pengelompokan menjadi 3 kelompok dengan 3 variabel pembeda yaitu variabel meninggalkan kewajiban, variabel kawin dibawah umur dan variabel penganiayaan.
16
Dengan ketepatan fungsi diskriminan yang terbentuk adalah 94,5% atau ketepatannya tinggi karena mendekati 100%.
3. Dari pengelompokan pada tahun 1996 dan 1997 dapat di-bandingkan dengan pengelompokan pada tahun 2010 yaitu variabel pembeda pada pengelompokan Kabupaten/Kota tahun 1996 ada 4 yaitu yaitu krisis akhlak, penganiayaan, politis dan gangguan pihak-3. Pada pengelompokan Kabupaten/Kota tahun 1997 ada 6 yaitu krisis akhlak, cemburu, ekonomi, kawin dibawah umur, penganiayaan, dan gangguan pihak-3. Sedangkan pada pengelompokan Kabupaten/Kota tahun 2010 ada 3 yaitu meninggalkan kewajiban, kawin dibawah umur dan penganiayaan.
6. Daftar Pustaka
Bunkers W.J., Miller J.R., DeGaetano A.T. 1996. Definition of Climate Regions in the Northern Plains Using an Objective Cluster Modification Technique. J.Climate
9:130-146.
Chatfield, C. and Collins. A. J .1980. Introduction to Multivariate Analysis, Chapman and hall in Assosiation with Methuen,Inc. 733 Third Avenve, New York.
Dillon, W. R, and Goldstein, M. (1984). Multivariate Analysis Methods and Aplication.
John Willey & Sons: Canada.
Febriani,Arief Surya. 1999. Studi Pengelompokan daerah tingkat II di Jawa Timur berdasarkan faktor-faktor penyebab perceraian pada tahun 1996 dan 1997. Tugas Akhir Jurusan Statistika Institut Teknologi Sepuluh Nopember Surabaya, Surabaya.
Iwan, Sugeng. “Pengasuh anak dalam keluarga”. Diunduh dari
http://id.wikipedia.org/wiki/keluarga. pada minggu, 25 September 2011, 18.00
Johnson, R.A and Winchern, D.W. (2002). Applied Multivariate Analysis, Third Edition. Prentice Hall Inc:New Jersey.
Muchtar Natsir, et.all. 1980. “Pedoman Pegawai Pencatat Nikah”. PPN. Departemen Agama. Jakarta.
Pengadilan Tinggi Agama Surabaya.2010. jumlah Perceraian di Jawa timur. Diunduh dari website http://www.pta.surabaya.go.id, pada minggu, 19 September 2011, 17.26. Sarwono, jonathan. 2009. “Statistik itu mudah, Panduan lengkap untuk belajar komputasi
statistik menggunakan SPSS 16”. Penerbit ANDI. Jogjakarta.
Soemiyati. 1986. “Hukum perkawinan Islam dan Undang-Undang perkawinan”. Liberty. Yogyakarta.
Undang-Undang perkawinan tahun 1974 dan Peraturan Pemerintah tentang perkawinan tahun 1975.