BAB 2
LANDASAN TEORI
2.1. Text Mining
Text mining merupakan teknik yang digunakan untuk menangani masalah klasifikasi, clustering, information extraction, dan information retrieval (Berry & Kogan, 2010). Text mining sebenarnya tidak jauh berbeda dengan data mining, yang membedakan hanyalah sumber data yang digunakan. Pada data mining data yang digunakan adalah
data yang terstruktur, sedangkan pada text mining data yang digunakan adalah data yang
tidak terstruktur berupa teks. Tujuan dari text mining secara keseluruhan adalah pada
dasarnya untuk mengubah suatu teks menjadi data yang dapat dianalisis.
2.2. Text Pre-Processing
Text pre-processing adalah proses pengubahan bentuk data yang belum terstruktur menjadi data yang terstruktur sesuai dengan kebutuhan, yang dilakukan untuk proses
mining yang lebih lanjut. Tahap-tahap pada text pre-processing secara umum adalah tokenizing, case-folding, filtering, phrase detection, dan stemming. Dimana penjelasan dari tahap-tahap tersebut adalah sebagai berikut:
2.2.1. Tokenizing
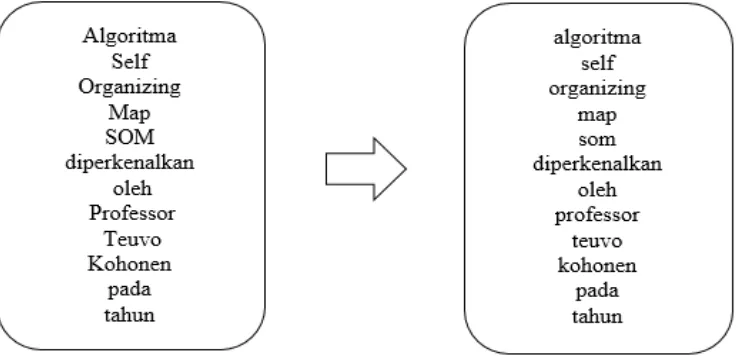
Tokenizing adalah tahap pemotongan teks input menjadi kata, istilah, symbol, tanda baca, atau elemen lain yang memiliki arti yang disebut token (Vijayarani & Janani, 2016). Pada proses, token yang merupakan tanda baca yang dianggap tidak perlu seperti
titik (.), koma (,), tanda seru (!), dan lain-lain akan dihapus. Contoh dari proses
Gambar 2.1. Proses Tokenizing
2.2.2. Case-folding
Case-folding adalah proses penyamaan case dalam artikel, Hal ini disebabkan karena tidak semua artikel teks konsisten dalam penggunaan huruf kapital. Oleh karena itu
dilakukan case-folding untuk mengkonversi semua teks kedalam suatu bentuk standar
(lowercase). Contoh dari proses case-folding dapat dilihat pada Gambar 2.2.
Gambar 2.2. Proses Case Folding
2.2.3. Filtering
Proses yang dilakukan pada tahap ini yaitu menghapus stop-word. Stop-word adalah kata yang bukan merupakan kata unik dalam suatu artikel atau kata-kata umum yang
“yang”, “dan”, “di”, “dari”, dan lain-lain (Tala, 2003). Contoh proses filtering stop-word dapat dilihat pada Gambar 2.3.
Gambar 2.3. Proses Filtering Stop-Word
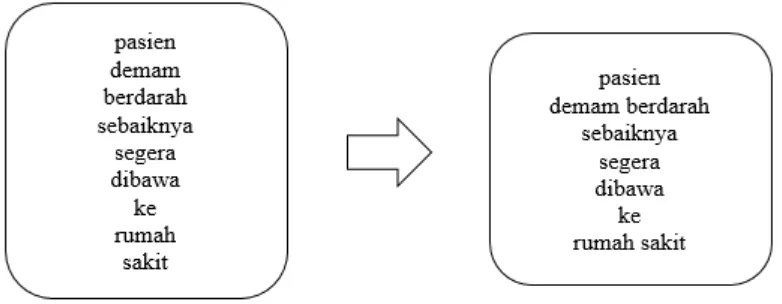
2.2.4. Phrase Detection
Tahap ini bertujuan untuk menemukan 2 kata atau lebih yang merupakan frase kata.
Pada bahasa Indonesia frase kata berbeda dengan kata majemuk. Dalam bahasa
Indonesia frasa adalah kumpulan kata nonpredikatif, sedangkan kata majemuk adalah
gabungan morfem dasar yang seluruhnya berstatus sebagai kata yang mempunyai pola
yang khusus menurut kaidah bahasa yang bersangkutan. Contoh dari phrase detection
untuk mendeteksi kata majemuk dapat dilihat pada Gambar 2.4.
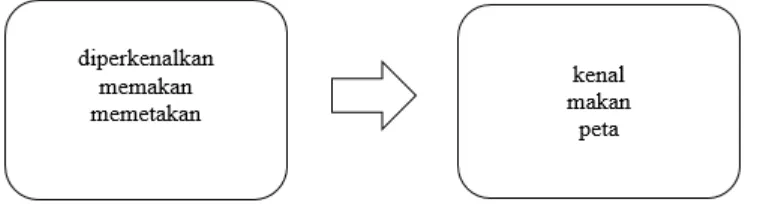
2.2.5. Stemming
Tahap ini bertujuan untuk menemukan kata dasar dari kata-kata yang bukan merupakan
frase yang didapatkan setelah proses phrase detection. Contoh dari proses stemming dapat dilihat pada Gambar 2.5.
Gambar 2.5. Proses Stemming
2.3. Algoritma Stemming Nazief Andriani
Algoritma nazief andriani merupakan algoritma stemming khusus untuk bahasa Indonesia. Algoritma ini menggunakan beberapa aturan morfologi untuk
menghilangkan affiks (awalan, imbuhan, dll) dari sebuah kata dan kemudian mencocokannya dalam kamus akar kata (kata dasar). Jadi dasar utama algoritma ini
adalah daftar kata dasar. Langkah pertama yang dilakukan adalah mengumpulkan daftar
kata dasar dalam bahasa Indonesia. Semakin lengkap daftarnya, semakin tinggi akurasi
algoritma ini.
Algoritma ini memiliki tahap-tahap sebagai berikut (Nazief & Adriani, 1996):
1. Cari kata yang akan di-stem di dalam kamus, jika kata tersebut ditemukan maka
kata tersebut adalah kata dasar dan algoritma berhenti. Jika tidak ada maka
lanjutkan ke langkah-2.
2. Hilangkan inflectional suffix (imbuhan infleksional) yaitu (“-lah”, “-kah”, “-tah”, “-ku”, “-mu”, “-nya”).
3. Hapus derivation suffix (imbuhan turunan) yaitu (“-i”, “-an”, atau “-kan”). Jika kata
ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah-3a.
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k” maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah-3b.
b. Akhiran yang dihapus (“-i”, “-an”, atau “-kan”) dikembalikan dan lanjut ke
4. Hapus derivation prefix (awalan turunan) yaitu (“be-“, “di-“, “ke-“, “me-“, “pe-“, “se-“, “te-“). Jika pada langkah 3 ada suffix yang dihapus maka pergi ke langkah-4a, jika tidak maka pergi ke langkah-4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak diizinkan. Jika ditemukan
maka algoritma berhenti, jika tidak pergi ke langkah-4b.
b. Untuk i=1 sampai 3, tentukan tipe awalan kemudian hapus awalan. Jika kata
dasar belum ditemukan juga lakukan langkah-5, jika sudah maka algoritma
berhenti.
Catatan: Jika awalan kedua sama dengan awalan pertama maka algoritma
berhenti.
5. Lakukan recording.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal
diasumsikan sebagai kata dasar. Proses selesai.
Tabel 2.1. Tabel Kombinasi Awalan dan Akhiran yang Tidak Diijinkan
(Nazief & Adriani, 1996)
Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
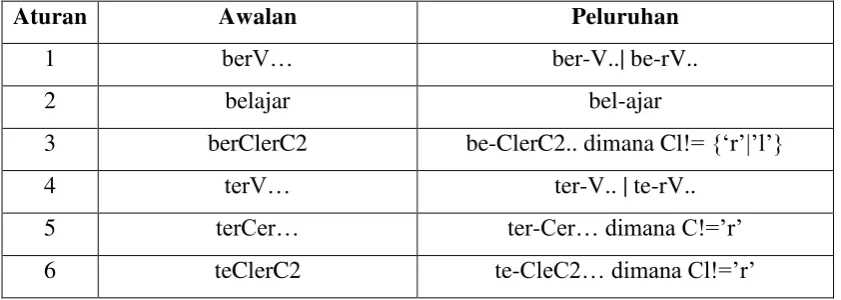
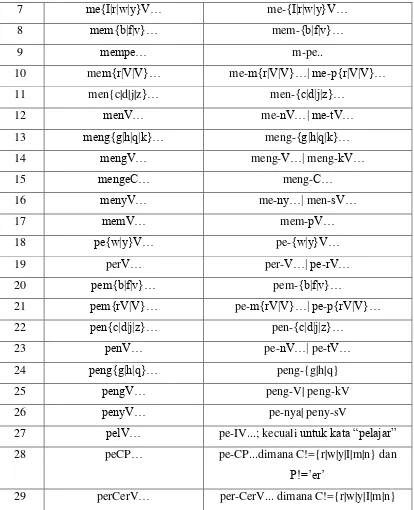
Tabel 2.2. Tabel Aturan Peluruhan Kata Dasar (Nazief & Adriani, 1996)
Aturan Awalan Peluruhan
1 berV… ber-V..| be-rV..
2 belajar bel-ajar
3 berClerC2 be-ClerC2.. dimana Cl!= {‘r’|’l’}
4 terV… ter-V.. | te-rV..
5 terCer… ter-Cer… dimana C!=’r’
Tabel 2.2. Tabel Aturan Peluruhan Kata Dasar (Lanjutan)
13 meng{g|h|q|k}… meng-{g|h|q|k}…
14 mengV… meng-V…| meng-kV…
25 pengV… peng-V| peng-kV
26 penyV… pe-nya| peny-sV
27 pelV… pe-IV...; kecuali untuk kata “pelajar”
28 peCP… pe-CP...dimana C!={r|w|y|I|m|n} dan
P!=’er’
29 perCerV… per-CerV... dimana C!={r|w|y|I|m|n}
Tipe awalan ditentukan melalui langkah-langkah sebagai berikut:
1. Jika awalannya adalah: “di-“, “ke-“, atau “se-“, maka tipe awalannya secara
berturut-turut adalah “di-“, “ke-“, atau “se-“.
2. Jika awalannya adalah: “te-“, “me-“, “be-“, atau “pe-“ maka dibutuhkan sebuah
3. Jika dua karakter pertama bukan “di-“, “ke-“, “se-“, “te-“, “be-“, “me-“, atau “pe-“
maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Hapus awalan jika ditemukan.
Untuk mengatasi keterbatasan yang ada, maka ditambahkan aturan-aturan dibawah ini:
(Adriani et al, 2007)
1. Aturan untuk reduplikasi.
a. Jika kedua kata yang dihubungkan penghubung adalah kata yang sama maka
root word adalah bentuk tunggalnya, contoh: “buku-buku” root wood-nya adalah “buku”.
b. Kata lain misalnya “bolak-balik”, “berbalas-balasan”, dan “seolah-olah”.
Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah. Jika
keduanya memiliki root word-nya yang sama maka diubah menjadi bentuk tunggal, contoh: kata “berbalas-balasan”, “berbalas” dan “balasan” memiliki root word yang sama yaitu “balas”, maka root wood “berbalas-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”, “bolak” dan “balik” memiliki root word yang berbeda, maka root word-nya adalah “bolak-balik”.
2. Tambahan bentuk awalan dan akhiran serta aturannya.
a. Tipe awalan “mem-“, kata yang diawali dengan awalan “ memp-“ memiliki
tipe awalan “mem-“.
b. Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-“ memiliki
tipe awalan “meng-“.
2.4. Automatic Keyphrase Extraction
Dewasa ini, jurnal yang dibuat sudah menyediakan daftar kata-kata kunci dari
artikelnya. Kata-kata kunci tersebut disebut keyphrases karna kata-kata kunci tersebut
kadang tidak hanya dalam satu kata tapi bisa dalam dua kata ataupun lebih (Turney,
1999). Artikel dapat dengan mudah disaring lebih mudah ketika keyphrases-nya ada
(Turney, 1999). Keyphrases juga dapat digunakan sebagai indeks kata-kata untuk mencari di dalam kumpulan koleksi artikel (Turney, 1999). Automatic keyphrase extraction adalah sebuah proses untuk menghasilkan daftar keyphrase yang dapat mewakili poin-poin penting dari sebuah teks. Keyphrase dari artikel ini dapat digunakan
menunjukan potensinya dalam meningkatkan hasil pekerjaan dari natural language processing (NLP) dan information retrieval (IR), seperti text categorization (Hulth & Megyesi, 2006) dan document indexing (Gutwin et al, 1999).
2.5. Term Frequency-Inverse Document Frequency (TF-IDF)
Metode TF-IDF merupakan metode untuk menghitung bobot dari kata yang digunakan
pada information retrieval. Metode ini juga terkenal efisien, mudah dan memiliki hasil
yang akurat. Metode ini akan menghitung nilai Term Frequency (TF) dan Inverse Document Frequency (IDF) pada setiap token (kata) di setiap dokumen dalam korpus. Bobot token (kata) semakin besar jika sering muncul dalam suatu dokumen dan semakin
kecil jika muncul dalam banyak dokumen (Robertson, 2004). Metode ini akan
menghitung bobot setiap token t di artikel d dengan persamaan 2.1.
Wdt = TFdt * IDFt (2.1)
Dimana: d = dokumen ke-d
t = token (kata) ke-t
W = bobot dokumen ke-d terhadap token (kata) ke-t
TF = Frekuensi kata yang dicari pada sebuah dokumen
IDF = Inversed Document Frequency
Nilai TF didapatkan dari persamaan 2.2
TF = Ntd / Nd (2.2)
Dimana: N = jumlah token (kata)
Nilai IDF didapatkan dari persamaan 2.3
IDF = log2 (D/Df) (2.3)
Dimana: D = total dokumen
2.6. Self Organizing Maps (SOM)
Self organizing maps merupakan salah satu model jaringan saraf tiruan yang menggunakan metode pembelajaran tanpa supervise (unsupervised learning). Salah satu keunggulan dari algoritma ini adalah mampu memetakan data berdimensi tinggi ke
dalam bentuk peta berdimensi rendah. Pada algoritma SOM, suatu lapisan yang berisi
neuron-neuron akan menyusun dirinya sendiri berdasarkan input nilai tertentu dalam suatu cluster bobotnya (Prasetyo, 2012). Selama proses penyusunan tesebut, cluster yang memiliki jarak paling dekat akan terpilih menjadi pemenang bobotnya (Prasetyo,
2012). Neuron yang menjadi pemenang akan memperbaiki nilai bobotnya beserta
neuron-neuron tetangganya (Prasetyo, 2012).
Arsitektur SOM terdiri atas satu lapisan input (x) dan satu lapisan output (y) dimana
setiap unit pada lapisan input akan dihubungkan dengan semua unit di lapisan output dengan suatu bobot wij (Prasetyo, 2012). Setiap neuron dalam SOM akan mewakili
suatu kelompok. Dalam SOM ada K neuron yang disusun dalam larik satu atau dua
dimensi (Prasetyo, 2012).
Berikut adalah algoritma Self Organizing Maps: (Kohonen, 1995)
1. Inisialisasi jumlah cluster (width x height), jumlah iterasi, learning rate, radius ketetanggaan, dan bobot pada setiap neuron.
2. Memilih salah satu vektor input dan disajikan ke jaringan.
3. Setiap neuron pada jaringan diuji untuk menghitung bobot neuron mana yang paling mirip dengan vektor input. Neuron pemenang sering disebut dengan Best Matching Unit (BMU). Untuk mendapatkan BMU dihitung dengan persamaan 2.4.
�� � � = ∑�=��= ��− �� (2.4)
Dimana: I = vektor input
W = bobot dari vector node
n = jumlah bobot
4. Menghitung radius ketetanggan dari BMU. Dimulai dengan nilai yang besar
kemudian berkurang setiap kali iterasi. Menghitung radius ketetanggan dilakukan
�� = � −� (2.5)
Dimana: t = iterasi yang sedang berlangsung
� = radius dari map λ = konstanta waktu
Nilai dari konstanta waktu dapat dihitung dari persamaan 2.6.
λ = � � � / � �� � (2.6)
5. Setiap neuron yang berada pada radius BMU disesuaikan agar mereka lebih mirip
dengan vektor input. Untuk menyesuaikan neuron yang berada pada radius BMU dihitung dengan persamaan 2.7.
��+ = ��+ ���� ��− �� (2.7)
Untuk menghitung nilai dari Lt digunakan persamaan 2.8.
��= � −λ (2.8)
Semakin dekat neuron dengan BMU, maka bobot pada neuron tersebut akan mengalami perubahan yang lebih besar. Jarak dari BMU digunakan dalam
persamaan 2.9.
��=
−�� � �����2
2�2 (2.9)
2.7. Penelitian Terdahulu
Lee & Yang (2003) menggunakan algoritma SOM untuk clustering terhadap corpus paralel yang berisi bahasa campuran yaitu bahasa Cina dan bahasa Inggris. Jaringan self
organizing maps yang dibangun memiliki 16 neuron dalam format 4x4 untuk melakukan eksperimen pada 18 artikel berbahasa Cina dan 18 artikel berbahasa Inggris.
Kemudian clustering dilakukan terhadap corpus hybrid, pada percobaan ini mereka menggunakan jaringan self organizing maps yang berisi 36 neuron dalam forma 6x6 untuk melakukan eksperimen pada 58 artikel berbahasa Cina dan 58 artikel berbahasa
Inggris.
Yusuf & Priambadha (2013) menggunakan algoritma K-means untuk mengelompokan artikel yang kemudian diklasifikasikan menggunakan multi-class Support Vector Machines (SVM). Hasil dari penelitian ini menunjukkan bahwa metode yang diusulkan mampu meningkatkan akurasi dengan menghasilkan akurasi sebesar
88,1% presisi sebesar 96,7% dan recall sebesar 94,4% dengan parameter jumlah kelompok sebesar 5 dibandingkan dengan tanpa menggunakan algoritma K-means untuk mengelompokkan artikel sebelum klasifikasi.
Husni et al (2015) menggunakan algortima K-Means untuk clustering berita web
berbahasa Indonesia. Proses text pre-processing pada penelitian ini tidak menggunakan
stemming. Artikel berita berhasil dikelompokan secara otomatis sesuai dengan derajat kesamaan berita sehingga menjadi kelompok artikel berita yang terstruktur dengan
diperoleh nilai rata-rata F-Measure 0.6129. Jumlah cluster dengan nilai puritas terbaik
0.75475 adalah 2 cluster.
Suryaningsih (2015) menggunakan algoritma SOM untuk clustering abstrak pada
sebuah penelitian. Namun dalam penelitian ini Suryaningsih menggunakan metode
TF-IDF untuk menghitung bobot kata kunci dalam setiap artikel. Pada penelitian ini
ditetapkan jumlah iterasi sebesar 1000, learning rate 0.1, serta jumlah cluster yang dibuat memiliki ukuran 9x9 grid. Proses clustering akan mengelompokkan artikel yang
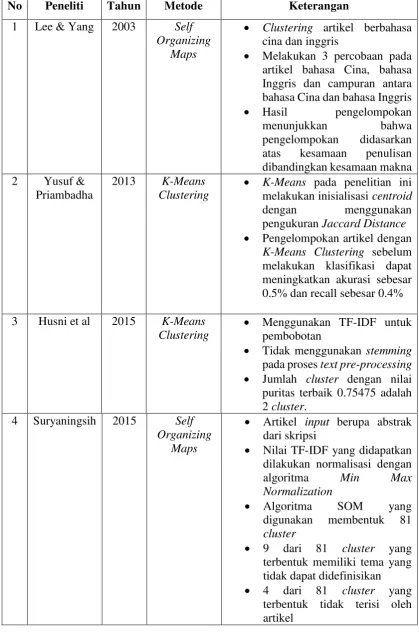
Tabel 2.3. Penelitian Terdahulu
No Peneliti Tahun Metode Keterangan
1 Lee & Yang 2003 Self Organizing
Maps
Clustering artikel berbahasa cina dan inggris
Melakukan 3 percobaan pada artikel bahasa Cina, bahasa Inggris dan campuran antara bahasa Cina dan bahasa Inggris
Hasil pengelompokan
menunjukkan bahwa
pengelompokan didasarkan atas kesamaan penulisan dibandingkan kesamaan makna
K-Means Clustering sebelum melakukan klasifikasi dapat meningkatkan akurasi sebesar 0.5% dan recall sebesar 0.4%
3 Husni et al 2015 K-Means Clustering
Menggunakan TF-IDF untuk pembobotan
Tidak menggunakan stemming pada proses text pre-processing Jumlah cluster dengan nilai puritas terbaik 0.75475 adalah 2 cluster.
Nilai TF-IDF yang didapatkan dilakukan normalisasi dengan
algoritma Min Max
Normalization
Algoritma SOM yang
digunakan membentuk 81 cluster
9 dari 81 cluster yang terbentuk memiliki tema yang tidak dapat didefinisikan 4 dari 81 cluster yang
Perbedaan penelitian yang dilakukan dengan penelitian terdahulu adalah penelitian
ini berfokus kepada clustering artikel web kesehatan dan pengelompokkan yang lebih
khusus dengan berusaha untuk mendapatkan multi-word expression dari kata-kata yang
berkaitan dengan kesehatan. Adapun metode yang diimplementasikan dalam penelitian
ini adalah sebagai berikut:
Melakukan text pre-processing untuk mendapatkan data teks yang sesuai dimana
hal ini bertujuan untuk mempercepat proses dan meningkatkan akurasi pada saat
proses automatic keyphrase extraction dan proses clustering. Pada tahap stemming
di proses text pre-processing ini menggunakan algoritma stemmer Nazief-Andriani.
Menghitung nilai bobot kata dengan metode TF-IDF untuk proses automatic keyphrase extraction dan sebagai data masukkan pada proses clustering.
Menggunakan algoritma Self Organizing Maps untuk melakukan clustering artikel