Fakultas Ilmu Komputer
Universitas Brawijaya
6160
Penerapan Metode Learning Vector Quantization (LVQ) untuk Klasifikasi
Fungsi Senyawa Aktif Menggunakan Notasi Simplified Molecular Input
Line System (SMILES)
Suhhy Ramzini1, Dian Eka Ratnawati2, Syaiful Anam3
1, 2Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya
3Program Studi Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Brawijaya
Email: 1suhhyr@gmail.com, 2dian_ilkom@ub.ac.id, 3syaiful@ub.ac.id
Abstrak
Senyawa aktif merupakan suatu zat (obat) yang mampu memberikan efek baik terhadap kondisi buruk tubuh manusia. Penggunaan senyawa aktif adalah untuk proses pencegahan bahkan penyembuhan suatu penyakit. Senyawa aktif sangat dibutuhkan dan berperan penting dalam dunia medis. Notasi Simplified
Molecular Input Line System atau disingkat dengan SMILES merupakan representasi dari suatu senyawa
(ikatan karbon) yang diciptakan oleh David Weininger pada tahun 1980. Tersusun dari karakter ASCII (American Standard Code for Information Interchange) sehingga dapat disimpan dalam variabel string dan diproses oleh komputer dengan mudah. Jumlah senyawa (notasi SMILES) saat ini sangat banyak dan perlu dilakukan klasifikasi untuk senyawa yang sudah teruji mampu dijadikan sebagai obat (senyawa aktif). Penelitian ini dilakukan untuk proses klasifikasi fungsi senyawa aktif menggunakan notasi SMILES menerapkan metode Learning Vector Quantization (LVQ) dengan dua kelas fungi senyawa aktif, yaitu kelas senyawa aktif untuk penyakit metabolisme dan kelas senyawa aktif untuk penyakit kanker. Terdapat 467 dataset dengan masing-masing data memiliki 11 fitur. Dalam proses pengujian didapatkan nilai learning rate sebesar 0,1, nilai decrement alpha sebesar 0,3, nilai minimum
alpha sebesar 1 ∗ 10−14, dan maksimal epoch sebanyak 15 dengan menggunakan persentase data latih 80% dan data uji 20% dihasilkan akurasi sebesar 76,34%.
Kata kunci: senyawa aktif, notasi simplified molecular input line system, metode learning vector quantization, learning rate, decrement alpha, minimum alpha, maksimal epoch
Abstract
Active compound is a substance (medicine) capable of providing kind effect when the human bodies are in bad shape. Active compound often used for preventing or curing a disease. Active compound takes an important role in medical world. Simplified Molecular Input Line System notation, in short SMILES notation is representation of compound (carbon bond) created by David Weininger in 1980. SMILES notation composed of ASCII (American Standard Code for Information Interchange) characters so that it can be stored in string variable and easily processed by the computer. Currently, there are numbers of compounds (SMILES notation) and it makes the classification for tested compound that can be made into a medicine (active compound) becomes necessary. The purpose of this research is to classify the active compound function utilizing SMILES notation with Learning Vector Quantization (LVQ) method by using 2 active compound function classes, one for metabolic disease, and another for cancer disease. There are 467 datasets with each 11 features. On testing process, the obtained value for learning rate is 0.1, decrement alpha is 0.3, minimum alpha is 1 ∗ 10−14, and maximum epoch is 15 by using a
percentage of 80% training data and 20% testing data which produce accuracy of 76.34%.
Keywords: active compound, simplified molecular input line system notation, learning vector quantization method, learning rate, decrement alpha, minimum alpha, maximum epoch
1. PENDAHULUAN
Senyawa aktif merupakan zat yang sangat bermanfaat bagi kesehatan manusia karena
kemampuannya untuk melakukan penyembuhan atau pencegahan apabila tubuh sedang dalam kondisi yang buruk (Rizki et al, 2015). Senyawa aktif dapat disebut sebagai obat yang mampu
memberikan efek fisiologis terhadap organisme lain dan biasanya senyawa aktif ditemukan dalam hewan dan tumbuhan (Salni et al, 2011). Pada dunia medis, penggunaan senyawa aktif ditujukan untuk melakukan penyembuhan atau pencegahan terhadap penyakit yang diderita oleh pasien. Pada tahun 80-an, David Weininger melakukan sebuah penelitian dan dalam penelitian itu dia berhasil membuat sebuah notasi yang berisi informasi-informasi dari kimia modern. Notasi kimia ini terdiri dari karakter
ASCII (American Standart Code for Information Interchange), sehingga membuat notasi kimia
ini dapat disimpan dalam suatu variabel string.
Simplified Molecular Input Line System atau
disingkat dengan SMILES adalah nama dari bentuk representasi ikatan kimia atau ikatan karbon. Setiap senyawa aktif memiliki notasi
SMILES, hal tersebut berfungsi agar pada saat
proses komputerisasi dapat berjalan dengan mudah dan dapat disimpan dalam komputer dengan ukuran yang kecil (Junaedi, 2011).
Fungsi dari senyawa aktif sangatlah berguna dan dibutuhkan oleh para akademisi kesehatan agar dapat dilakukan penelitian dan dapat dijadikan sebagai obat untuk proses penyembuhan atau pencegahan suatu penyakit. Sebuah aplikasi atau program untuk memberikan informasi apakah senyawa yang didapatkan merupakan senyawa aktif yang dapat dijadikan obat penyembuhan atau pencegahan penyakit pada pasien belum ada di Indonesia, begitupun juga mengenai penggunaan notasi SMILES dalam hal untuk mengetahui fungsi senyawa aktifnya masih jarang dilakukan di Indonesia.
Jumlah senyawayang ada saat ini sangat banyak, ada senyawa yang sudah dijadikan sebagai obat dan ada juga senyawa yang belum dapat dijadikan obat (masih dalam penelitian). Senyawa yang sudah dijadikan obat disebut sebagai senyawa aktif. Karena jumlah senyawa yang ada saat ini sangat banyak dan di antaranya banyak senyawa yang belum diketahui fungsi aktivitasnya (kegunaannya), maka perlu dilakukan klasifikasi agar dapat dikatehui fungsi senyawa aktif yang terdapat di dalamnya (sebagai obat penyakit tertentu pada manusia).
Jaringan syaraf tiruan merupakan salah satu ilmu pembelajaran yang di dalamnya terdapat metode untuk melakukan klasifikasi dan proses ini dapat dilakukan terhadap senyawa aktif. Salah satu metode yang biasa dipakai dalam proses klasifkasi adalah Learning Vector
Quantization (LVQ). Metode ini disebut sebagai supervised karena adanya proses pembelajaran
melalui data latih, proses ini dinamakan training. Sehingga dengan adanya training, metode LVQ mampu mengenali pola dari suatu objek dengan menghasilkan nilai bobot optimal (Martinuva, 2015). Kelebihan dari metode ini adalah mampu melakukan peringkasan terhadap dataset yang berukuran besar menjadi kecil, kemudian dibandingkan metode Backpropagation nilai
error yang dihasilkan metode LVQ lebih kecil
(Sela et al, 2011).
Berdasar alasan yang sudah disampaikan sebelumnya, solusi yang perlu dilakukan adalah dengan membuat program yang berfungsi untuk memberikan informasi mengenai kegunaan dari senyawa aktif agar dijadikan sebagai obat penyembuh atau pencegah suatu penyakit pada manusia. Program dibangun dengan menerapkan metode LVQ untuk melakukan proses klasifkasi, sedangkan notasi SMILES adalah objeknya.
Pada penelitian ini dilakukan juga pemrosesan teks (preprocessing) menggunakan
regular expression (regex), karena notasi SMILES tersusun dari deretan karakter huruf,
angka, dan simbol. Regex berfungsi untuk melakukan pencocokan terhadap pola teks atau
string (Yunmar, 2011). Regex digunakan dalam
penelitian ini agar bisa menemukan masing-masing atom yang terdapat dalam notasi
SMILES. Atom yang dicari adalah karbon (C),
boron (B), nitrogen (N), oksigen (O), fosfor (P), belerang (S), fluor (F), klor (Cl), brom (Br), yodium (I), dan juga senyawa hidroksida (OH).
Preprocessing juga berperan dalam menentukan
jumlah masing-masing atom dan panjang dari notasi SMILES, kemudian dilakukan operasi pembagian terhadap keduanya dan hasil dari proses ini dijadikan sebagai nilai fitur untuk perhitungan menggunakan metode LVQ.
2. LANDASAN KEPUSTAKAAN 2.1. Kajian pustaka
Dasar dari pelaksanaan penelitian ini berasal dari beberapa studi literatur dan penelitian yang dilakukan sebelumnya menggunakan metode Learning Vector Quantization (LVQ) dengan objek penelitian
yang berbeda.
Penelitian dengan judul “Klasifikasi Stroke berdasarkan Kelainan Patologis dengan
Learning Vector Quantization”, dihasilkan
akurasi sebesar 96% (Arifianto et al, 2014) dan penelitian dengan judul “Penerapan Learning
Status Gizi Anak” dihasilkan akurasi sebesar 88% (Budianita et al, 2013).
2.2. Senyawa aktif
Suatu zat yang mampu bereaksi untuk penyembuhan atau pencegahan pada saat tubuh dalam kondisi yang tidak stabil (buruk) diakibatkan oleh penyakit tertentu disebut sebagai senyawa aktif (Rizki et al). Senyawa aktif dapat ditemukan pada organisme lain seperti hewan dan tumbuhan. Senyawa aktif dimanfaatkan sebagai bahan obat yang mampu memberikan efek fisiologis terhadap organisme lain, senyawa aktif disebut juga sebagai senyawa bioaktif (Salni et al, 2011). Berdasarkan beberapa pendapat sebelumnya, dapat disimpulkan bahwa senyawa aktif adalah zat untuk dijadikan sebagai obat penyembuhan atau pencegahan penyakit tertentu pada manusia. 2.3. Simplified Molecular Input Line System (SMILES)
Notasi SMILES diciptakan oleh David Weininger pada tahun 1980 sebagai pemroses dari informasi-informasi dalam kimi modern. Notasi ini merupakan representasi dari ikatan kimia atau ikatan karbon. SMILES terdiri dari karakter-karakter ASCII (American Standard
Code for Information Interchange) sehingga
mampu disimpan ke dalam variabel string dan dapat lebih mudah diproses oleh komputer (Junaedi, 2011).
Suatu notasi SMILES terdiri dari beberapa atom dan senyawa, adapun atom-atom yang biasanya terdapat dalam notas SMILES menurut Weininger. (1988): Karbon (C). Boron (B). Nitrogen (N). Oksigen (O). Fosfor (P). Belerang (S). Fluor (F). Klor (Cl). Brom (Br). Yodium (I).
Senyawa hidroksida (OH).
Dalam notasi SMILES ikatan antar atom dilambangkan dengan tanda “-“ (strip) artinya ikatan tunggal, tanda “=” (sama dengan) artinya ikatan rangkap dua, dan tanda “#” (kres/pagar) artinya ikatan rangkap tiga. Kondisi
percabangan dilambangkan dengan atom yang berada dalam tanda “( )” (kurung buka dan kurung tutup). Terakhir adalah kondisi apabila atom berikatan siklik (melingkar) diberikan angka yang mengikuti atom, seperti contoh notasi SMILES C1CCCBrCOC1 (Weininger, 1988).
2.4. Learning Vector Quantization (LVQ)
LVQ adalah metode yang melakukan
pembelajaran terarah agar mampu mengenali pola suatu objek. Konsep dari metode ini adalah
competitive learning neural networks,
maksudnya dalam metode ini terjadi proses
training sel agar terbentuknya lapisan masukan
(input layer) (Akbari et al, 2017). LVQ akan menghasilkan keluaran yang merupakan representasi dari sebuah kelas dan melalukan pengelompokann dengan jumlah kelas yang sudah ditentukan. Berikut kelebihan dan kelemahan yang dimiliki oleh metode LVQ, yaitu (Sela, 2011):
1. Nilai error yang dihasilkan lebih kecil dibanding backpropagation.
2. Mampu meringkas dataset yang besar dan mengubanya menjadi lebih kecil.
3. Tidak ada pembatasan dimensi seperti pada
nearest neighbour.
4. Dapat melakukan update model secara bertahap.
5. Setiap atribut perlu dilakukan perhitungan jarak.
6. Besar akurasi yang dihasilkan bergantung pada inisialisasi model dan parameter masukan, serta jumlah data latih.
LVQ memiliki arsitektur single layer net
sehingga pada lapisan masukan akan terhubung secara langsung dengan setiap neuron yang ada pada lapisan keluaran. Penghubung antar neuron adalah bobot (Martinuva, 2015). Struktur jaringan LVQ terdiri dari lapisan masukan (input
layer), lapisan kompetitif (competitive layer),
dan lapisan keluaran (output layer). Dalam lapisan kompetitif, input akan berkompetisi agar dapat masuk ke dalam suatu kelas klasifikasi.
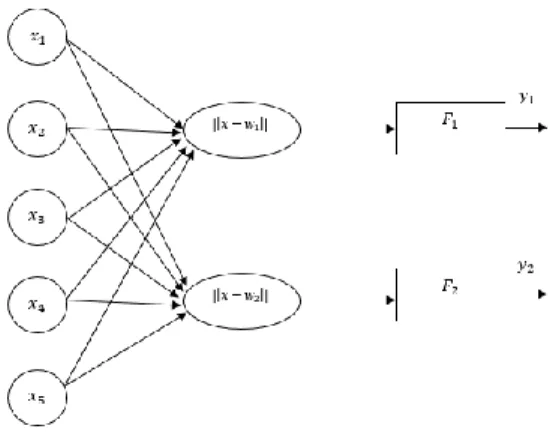
Berdasarkan Gambar 1, simbol 𝑥1− 𝑥5
adalah parameter masukan, simbol 𝑤1− 𝑥2
merupakan nilai bobot, kemudian simbol ||𝑥 − 𝑤1|| dan ||𝑥 − 𝑤2|| merupakan proses
perhitungan jarak, simbol 𝐹1 dan 𝐹2 mewakili
kelas, terakhir terdapat 𝑦1 dan 𝑦2 yang
merupakan lapisan keluaran. Algoritme dari proses pelatihan LVQ adalah sebagai berikut (Fausett, 1994):
0. Inisialisasi bobot dan alpha.
1. Selama kondisi berhenti belum terpenuhi, kerjakan langkah 2-6.
2. Setiap parameter masukan, kerjakan langkah 3-4.
3. Tentukan 𝐽 𝑚𝑖𝑛𝑖𝑚𝑢𝑚 dari ||𝑥 − 𝑤𝑗|| (1)
4. Melakukan update bobot 𝑤𝑗 dengan syarat
𝑇 = 𝐶𝑗, maka
𝑤𝑗(𝑏𝑎𝑟𝑢) = 𝑤𝑗(𝑙𝑎𝑚𝑎) + 𝛼[𝑥 − 𝑤𝑗(𝑙𝑎𝑚𝑎)]; (2)
𝑇 ≠ 𝐶𝑗, maka
𝑤𝑗(𝑏𝑎𝑟𝑢) = 𝑤𝑗(𝑙𝑎𝑚𝑎) − 𝛼[𝑥 − 𝑤𝑗(𝑙𝑎𝑚𝑎)]; (3)
5. Pengurangan nilai alpha.
6. Cek kondisi berhenti dengan syarat iterasi sudah mencapai maksimal atau alpha lebih kecil dari minimal alpha.
Gambar 1. Struktur Jaringan LVQ
2.5. Preprocessing
Preprocessing adalah proses untuk melakukan perubahan bentuk data yang semula tidak terstruktur menjadi bentuk data terstruktur. Proses ini juga berfungsi dalam mengetahui posisi dan banyak dari suatu huruf atau kata (Manning et al, 2009). Regular expression (regex) formula yang digunakan dalam proses pencarian pola string/kalimat (Muliantara, 2009). Penggunaan regex ini adalah dalam pencarian dan mengambil karakter huruf, angka, atau simbol yang diinginkan.
Pada penelitian ini, penggunaan regex dalam proses preprocessing terhadap notasi
SMILES adalah untuk melakukan pencarian dan
mengambil lambang atom yang terdapat pada notasi sehingga dapat ditentukan jumlah masing-masing atom dan panjang notasi SMILES. Jumlah masing-masing atom dan panjang
SMILES akan dilakukan proses pembagian,
kemudian hasilnya dijadikan sebagai nilai fitur dalam proses perhitungan metode LVQ.
3. METODOLOGI PENELITIAN 3.1. Pengumpulan data
Data notasi SMILES didapatkan pada
website https://pubchem.ncbi.nlm.nih.gov. Total
jumlah data notasi SMILES yang terkumpul adalah sebanyak 467 yang terdiri dari 340 data notasi SMILES yang berfungsi untuk penyakit atau gangguan pada metabolisme dan 127 data notasi SMILES yang berfungsi untuk penyakit kanker. Data notasi SMILES akan dibagi menjadi data latih dan data uji dalam proses perhitungan
LVQ. Berdasarkan data notasi SMILES yang
didapatkan, maka akan ada dua pola kelas yang akan dipelajari oleh metode LVQ yaitu kelas metabolisme dan kelas kanker. Hasil akhir dari proses ini adalah hasil kelas klasifikasi notasi
SMILES yang berfungsi untuk dijadikan obat
penyakit pada metabolisme atau penyakit kanker.
3.2. Analisis kebutuhan
Analisis kebutuhan dilakukan untuk mengetahui kebutuhan apa saja yang diperlukan agar program atau aplikasi dapat berjalan dengan baik. Kebutuhan yang diperlukan dalam membangun program klasifikasi fungsi senyawa aktif menggunakan notasi SMILES dengan menerapkan metode LVQ ini parameter masukan berupa nilai fitur. Kemudian kebutuhan yang harus terpenuhi oleh program adalah dapat menerima masukan berupa notasi SMILES, mampu melakukan preprocessing menggunakan
regex terhadap notasi SMILES, mampu melakukan klasifkasi dengan menerapkan metode LVQ, terakhir adalah dapat memberikan hasil (output) berupa informasi mengenai fungsi senyawa aktif dari notasi SMILES yang dimasukkan oleh pengguna.
4. PERANCANGAN
4.1. Perancangan perangkat lunak
Program klasifikasi fungsi senyawa aktif menggunakan notasi SMILES dengan menerapkan metode LVQ yang dibuat ini berbasis bahasa pemrograman PHP. Dalam proses penyimpanan data digunakan database
MySQL.
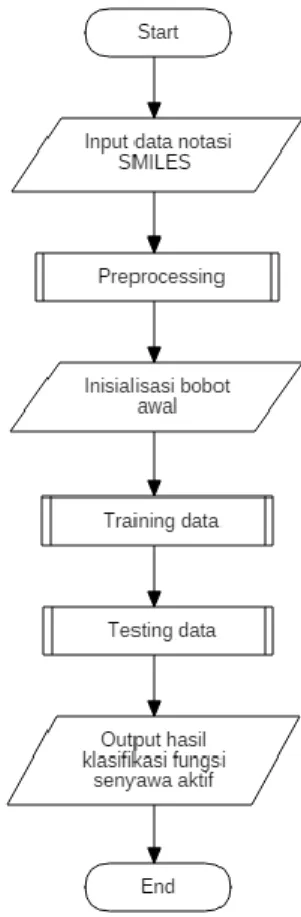
Berdasarkan Gambar 2, program ini memiliki beberapa alur yaitu pertama adalah proses memasukkan data notasi SMILES, kemudian data notasi SMILES akan dilakukan
Setelah nilai fitur didapatkan, maka akan dilakukan proses selanjutnya:
- Pelatihan data
Proses metode LVQ untuk melakukan
pembelajaran terhadap pola masing-masing kelas yang akan diklasifikasikan yaitu kelas metabolisme dan kelas kanker. Proses ini memerlukan nilai fitur dan nilai bobot awal,
alpha, decrement alpha, minimum alpha, serta
maksimum epoch. - Pengujian data
Proses ini adalah untuk menguji data latih agar diketahui kelas fungsi senyawa aktifnya. Proses pengujian juga dapat memberikan besar akurasi dari klasifikasi kelas.
Gambar 2. Alur Proses Program
4.2. Preprocessing
Preprocessing menggunakan regex
terhadap notasi SMILES bertujuan untuk melakukan pencarian dan mengambil lambang atom yang terdapat pada notasi SMILES, sehingga diketahui jumlah masing-masing atom dan panjang notasi SMILES. Hasil akhir dari
preprocessing menggunakan notasi SMILES
adalah berupa nilai fitur yang didapatkan dari proses operasi pembagian antara jumlah masing-masing atom dan panjang notasi SMILES. Nilai fitur digunakan untuk proses perhitungan menggunakan metode LVQ. Adapun 11 fiturnya yaitu atom C, atom Cl, atom B, atom Br, atom O, senyawa OH, atom N, atom S, atom P, atom I, dan atom F yang masing-masing atom sudah dilakukan operasi bagi dengan panjang notasi
SMILES.
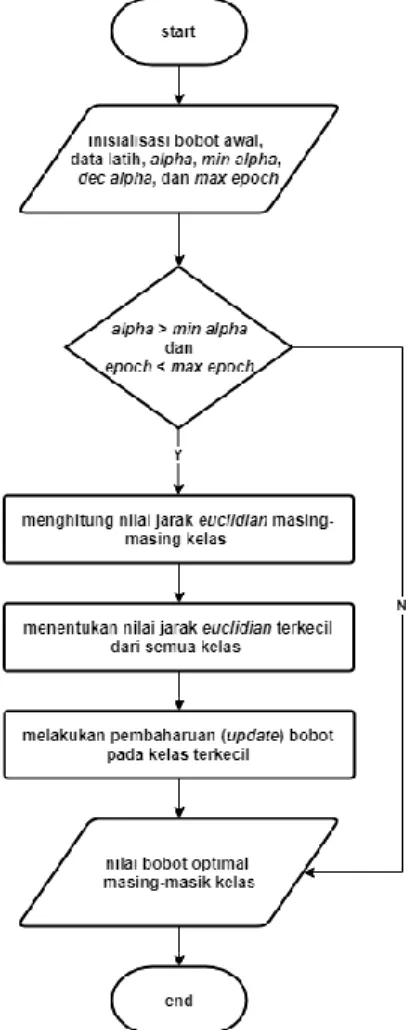
4.3. Pelatihan data
Proses pelatihan data dilakukan setelah nilai fitur didapatkan pada saat preprocessing. Sebagian dari nilai fitur yang didapatkan akan dijadikan sebagai nilai bobot awal kelas. Proses ini memerlukan nilai alpha, decrement alpha,
minimum alpha, dan epoch maksimal sebagai
masukan (inputan). Kemudian dilakukan perhitungan nilai euclidian terhadap masing-masing kelas. Dari hasil perhitungan ini, akan ditentukan kelas mana yang memiliki nilai
euclidian terkecil, sehingga dapat dijadikan
sebagai kelas keluaran. Terkahir adalah melakukan pembaharuan (update) bobot terhadap kelas dengan nilai euclidian terkecil. Pelatihan data bertujuan untuk memberikan pembelajaran kepada metode LVQ agar mampu mengenali pola masing-masing kelas dan menghasilkan bobot optimal. Bobot optimal yang didapatkan adalah nilai yang mewakili setiap kelas klasifikasi dan dipakai pada saat proses pengujian data uji. Alur dari proses pelatihan data menggunakan metode LVQ terdapat pada Gambar 3.
4.4. Pengujian data
Setelah dilakukan proses pelatihan data, maka akan dihasilkan bobot akhir yang berfungsi sebagai bobot optimal dan digunakan sebagai bobot kelas pada proses pengujian data. Hasil dari proses pengujian adalah kelas klasifikasi fungsi senyawa aktif dari notasi
SMILES.
Dalam proses pengujian ini akan diberikan informasi mengenai besar akurasi yang didapatkan dari klasifikasi kelas. Dari nilai akurasi ini dapat diketahui mengenai keberhasilan metode LVQ dalam melakukan pembelajaran pada saat proses pelatihan data. Alur dari proses pengujian data menggunakan metode LVQ terdapat pada Gambar 4.
Gambar 3. Alur Proses Pelatihan Data
Gambar 4. Alur Proses Pengujian Data
5. PENGUJIAN DAN ANALISIS
Skenario pengujian yang dilakukan pada program klasifikasi fungsi senyawa aktif menggunakan notasi SMILES dengan menerapkan metode LVQ adalah:
1. Pengujian untuk mengetahui pengaruh jumlah data latih terhadap besar akurasi. 2. Pengujian untuk mengetahui pengaruh
learning rate terhadap besar akurasi.
3. Pengujian untuk mengetahui pengaruh
decrement alpha terhadap besar akurasi.
4. Pengujian untuk mengetahui pengaruh
minimum alpha terhadap besar akurasi.
5. Pengujian menggunakan cross validation. 5.1. Pengujian pengaruh jumlah data latih
Dataset yang digunakan pada pengujian ini
berjumlah 467 data yang terdiri dari 340 data kelas metabolisme dan 127 data kelas kanker. Masing-masing kelas diambil dengan persentase sebanyak 40%, 50%, dan 80% untuk data latih dan 20% sebagai data uji. Nilai alpha, minimum
alpha, decrement alpha, dan epoch maksimal
secara berturut-turut adalah sebesar 0,1, 1 ∗ 10−14, 0,15, dan 15. Pengujian ini bertujuan
untuk mengetahui pengaruh jumlah data latih terhadap akurasi yang dihasilkan.
Gambar 5. Grafik Besar Akurasi Jumlah Data Latih Pada Gambar 5 dapat disimpulkan bahwa semakin banyak komposisi jumlah data, maka akurasi yang dihasilkan meningkat. Sebaliknya semakin sedikit komposisi jumlah data, maka akurasi yang dihasilkan menurun. Penggunaan komposisi data latih dengan persentase 80% menghasilkan akurasi terbaik, yaitu sebesar 76,34%. Proses pembelajaran LVQ berjalan dengan baik dalam mengenali pola data kelas metabolisme namun hanya sedikit pola data kelas kanker yang dikenal, karena komposisi data latih kelas kanker lebih sedikit dibandingkan komposisi data latih kelas
40% 50% 80% Besar akurasi 24,73% 53,76% 76,34% 0,00% 20,00% 40,00% 60,00% 80,00% 100,00%
A
kur
as
i
Pengaruh jumlah data latih
terhadap akurasi
metabolisme.
5.2. Pengujian learning rate
Data latih yang digunakan pada pengujian ini adalah data latih pada pengujian sebelumnya, yaitu data latih dengan persentase 80%. Data berjumlah sebanyak 374 yang terdiri dari 272 data kelas metabolisme dan 102 data kelas kanker. Sebanyak 20% data dijadikan sebagai data uji (data yang sama pada pengujian sebelumnya). Nilai learning rate yang ingin diuji adalah 0,1 sampai 0,9. Nilai minimum alpha,
decrement alpha, dan epoch maksimal secara
berturut-turut adalah sebesar 1 ∗ 10−14, 0,15,
dan 15. Pengujian ini bertujuan untuk mengetahui besar pengaruh learning rate terhadap besar akurasi yang dihasilkan.
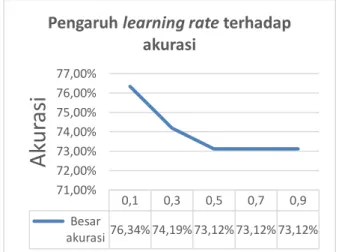
Pada Gambar 6 dapat dilihat bahwa
learning rate yang menghasilkan akurasi terbaik
pada klasifikasi data uji notasi SMILES adalah 0,1 dengan besar 76,34%. Disimpulkan bahwa dengan penggunaan learning rate yang berbeda, maka akan memengaruhi besar akurasinya.. Pada penelitian ini, semakin besar learning rate, maka membuat algoritme berjalan tidak stabil dan akurasi yang dihasilkan menurun. Sedangkan semakin kecil learning rate, maka besar akurasi yang dihasilkan meningkat. Hal itu terjadi karena proses pembelajaran LVQ dalam mengenali pola data kelas metabolisme dan pola data kelas kanker berjalan lebih lama.
Gambar 6. Grafik Besar Akurasi Learning Rate
5.3. Pengujian decrement alpha
Data latih yang digunakan pada pengujian ini adalah data latih pada pengujian sebelumnya, yaitu data latih dengan persentase 80%. Nilai
learning rate adalah sebesar 0,1 karena
menghasilkan akurasi terbaik pada proses
sebelumnya. Data berjumlah sebanyak 374 yang terdiri dari 272 data kelas metabolisme dan 102 data kelas kanker. Sebanyak 20% data dijadikan sebagai data uji (data yang sama pada pengujian sebelumnya). Nilai decrement alpha yang ingin diuji adalah 0,1 sampai 0,9. Nilai minimum
alpha dan epoch maksimal secara berturut-turut
adalah sebesar 1 ∗ 10−14 dan 15. Pengujian ini bertujuan untuk mengetahui besar pengaruh
decrement alpha terhadap besar akurasi yang
dihasilkan.
Gambar 7. Grafik Besar Akurasi Decrement Alpha Pada Gambar 7 dapat dilihat bahwa decrement alpha yang menghasilkan akurasi terbaik pada klasifikasi data uji notasi SMILES adalah pada saat penggunaan 0,3, 0,5, dan 0,7 dengan besar 76,34%. Dapat disimpulkan bahwa dengan penggunaan decrement alpha yang berbeda, maka akan memengaruhi besar akurasinya. Decrement alpha tidak boleh terlalu besar ataupun terlalu kecil, karena akan menghasilkan akurasi yang kurang baik bahkan sangat jelek. Artinya LVQ tidak mampu melakukan pengenalan pola data kelas secara baik dan benar apabila decrement alpha terlalu besar atau terlalu kecil.
5.4. Pengujian minimum alpha
Data latih yang digunakan pada pengujian ini adalah data latih pada pengujian sebelumnya, yaitu data latih dengan persentase 80%. Nilai
learning rate dan decrement alpha berturut-turut
adalah sebesar 0,1 dan 0,3 karena menghasilkan akurasi terbaik pada proses sebelumnya. Data berjumlah sebanyak 374 yang terdiri dari 272 data kelas metabolisme dan 102 data kelas kanker. Sebanyak 20% data dijadikan sebagai data uji (data yang sama pada pengujian sebelumnya). Nilai minimum alpha yang ingin diuji adalah 1 ∗ 10−6, 1 ∗ 10−8, 1 ∗ 10−10, 1 ∗ 0,1 0,3 0,5 0,7 0,9 Besar akurasi76,34% 74,19% 73,12% 73,12% 73,12% 71,00% 72,00% 73,00% 74,00% 75,00% 76,00% 77,00%
A
kur
as
i
Pengaruh learning rate terhadap
akurasi
0,1 0,3 0,5 0,7 0.9 Besar akurasi 27,95% 76,34% 76,34% 76,34% 73,12% 0,00% 20,00% 40,00% 60,00% 80,00% 100,00%A
kur
as
i
Pengaruh decrement alpha terhadap
akurasi
10−14, dan 1 ∗ 10−16. Banyak epoch maksimal adalah 15. Pengujian ini bertujuan untuk mengetahui pengaruh minimum alpha terhadap besar akurasi yang dihasilkan.
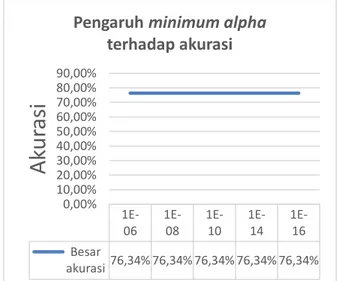
Pada Gambar 8 dapat dilihat semua
minimum alpha yang diujikan menghasilkan
besar akurasi yang sama yaitu 76,34%. Disimpulkan bahwa dengan penggunaan
minimum alpha yang berbeda pada klasifikasi
data notasi SMILES tidak memengaruhi besar akurasi yang dihasilkan.
Gambar 8. Grafik Besar Akurasi Minimum Alpha
5.5. Pengujian cross validation
Pengujian cross validation bertujuan untuk mengetahui apakah dengan melakukan pertukaran data latih menjadi data uji dan data uji menjadi data latih akan memengaruhi besar akurasi yang diperoleh. Dalam pengujian ini terbagi menjadi 5 fold (kelompok data) denga nama L1, L2, L3, L4, dan L5. Masing-masing kelompok akan berisi 93 data yang terdiri dari 68 (340 data dibagi 5) data kelas metabolisme dan 25 (127 dibagi 5) data kelas kanker. Adapun
learning rate, decrement alpha, minimum alpha
yang digunakan adalah nilai yang menghasilkan akurasi terbaik pada proses pengujian sebelumnya dan epoch maksimal berturut-turut
0
,1, 0,3, 1 ∗ 10−14, dan 15.Tabel 1. Pengujian Cross Validation
FOLD DATA LATIH DATA UJI BESAR AKURASI (%) 1 L1, L2, L3, dan L4 L5 68,81% 2 L1, L2, L3, dan L5 L4 75,26% 3 L1, L2, L4, dan L5 L3 72,04% 4 L1, L3, L4, dan L5 L2 73,12% 5 L2, L3, L4, dan L5 L1 71,57% RATA-RATA AKURASI 72,16% Berdasarkan Tabel 1 dapat disimpulkan bahwa dengan adanya proses pertukaran data latih menjadi data uji dan data uji menjadi data latih dapat memengaruhi besar akurasi yang dihasilkan. Pada pengujian ini, fold 2
menghasilkan akurasi terbaik yaitu 75,26% dengan data latih merupakan gabungan dari kelompok data L1, L2, L3, dan L5 sedangkan data ujinya adalah kelompok data L4. Terjadinya perbedaan besar akurasi yang dihasilkan pada masing-masing fold karena adanya perbedaan pola data notasi SMILES yang dikenali atau dipelajari oleh metode LVQ pada saat proses pelatihan data.
6. PENUTUP 6.1. Kesimpulan
1. Cara melakukan preprocessing terhadap notasi SMILES adalah pertama dengan membuat pola regular expression (regex) untuk proses menemukan dan mengambil karakter. Digunakan fungsi preg_replace yang terdapat pada PHP agar dapat melakukan manipulasi karakter sehingga mampu membedakan atom O dan OH. Kemudian menghitung panjang notasi
SMILES dan jumlah masing-masing atom.
Terakhir adalah melakukan operasi pembagian antara jumlah masing-masing atom dengan panjang notasi SMILES, sehingga dapat diketahui nilai fitur untuk proses perhitungan LVQ.
2. Nilai fitur yang didapatkan pada
preprocessing digunakan untuk proses
pembelajaran LVQ dengan pelatihan data. Dari proses pelatihan data didapatkan bobot optimal masing kelas (kelas metabolisme dan kelas kanker). Proses terakhir adalah pengujian data dengan menggunakan nilai
1E-06 1E-08 1E-10 1E-14 1E-16 Besar akurasi76,34% 76,34% 76,34% 76,34% 76,34% 0,00% 10,00% 20,00% 30,00% 40,00% 50,00% 60,00% 70,00% 80,00% 90,00%
A
kur
as
i
Pengaruh minimum alpha
terhadap akurasi
bobot optimal sebagai penentu kelas klasifkasi dari data uji. Hasil yang diberikan adalah kelas klasifikasi dari metode LVQ terhadap data uji (notasi SMILES).
3. Penggunaan persentase 80% data latih, nilai
learning rate sebesar 0,1, nilai decrement alpha sebesar 0,3, nilai minimum alpha
sebesar
1 ∗ 10−14, dan epoch maksimal adalah sebanyak 15 dalam klasifikasi terhadap data notasi SMILES dihasilkan akurasi sebesar 76,34%. Setiap perubahan nilai learning rate dan decrement alpha pada pelatihan data notasi SMILES akan memengaruhi besar akurasi yang didapat, sedangkan perubahan nilai minimum alpha tidak memengaruhi besar akurasi.
6.2. Saran
Saran yang dapat disampaikan untuk penelitian selanjutnya adalah dengan melakukan penambahan terhadap data kanker agar metode
LVQ dapat melakukan pembelajaran dalam
mengenali pola kelas kanker dengan baik, sehingga nilai akurasi yang dihasilkan lebih besar. Perlu dicoba dengan penggunaan metode lain seperti LVQ2 dan LVQ3 yang bertujuan untuk dijadikan sebagai pembanding besar akurasi yang dihasilkan, sehingga dapat diketahui metode dengan akurasi terbaik dalam melakukan klasifikasi data notasi SMILES. DAFTAR PUSTAKA
Akbari, M I. H. A. D., A. Novianty, dan C. Setianingsih. 2017. Analisis Sentimen Menggunakan Metode Learning Vector Quantization. e-Proceeding of Engineering(4): 2283-2292.
Arifianto, A. S., M. Sarosa, dan O. Setyawati. 2014. Klasifikasi Stroke Berdasarkan Kelainan Patologis dengan Learning Vector Quantization. Jurnal EECCIS(8): 117-122.
Budianita, E., dan W. Prijodiprodjo. 2013. Penerapan Learning Vector Quantization (LVQ) untuk Klasifikasi Status Gizi Anak. IJCSS(7): 155-166.
Fausett, L. 1994. Fundamentals of neural
networks: architectures, algorithms,
and applications. New Jersey:
Prentice-Hall, Inc.
Junaedi, H. 2011. Penggambaran Rantai Karbon dengan Menggunakan Simplified Molecular Input Line System (SMILES).
Prosiding Konferensi Nasional “Inovas i dalam Desain dan Teknologi”IdeaTeh ch 2011. Sekolah Tinggi Teknik Surabaya: 219-226.
Manning, C. D., P. Raghavan, dan H. Schütze. 2009. An Introduction to Information
Retrieval. Cambridge: Cambridge University Press.
Martinuva, E. D. 2015. Implementasi Learning
Vector Quantization (LVQ) Dalam Pemilihan Keminatan (Studi Kasus: Program Studi Teknik Informatika Universitas Brawijaya). S1. Universitas
Brawijaya.
Muliantara, A. 2009. Penerapan Regular Expression dalam Melindungi Alamat Email dari Spam Robot pada Konten Wordpress. Jurnal Ilmu Komputer(2): 16-23.
Rizki, M. I., dan E. M. Hariandja. 2015. Aktivitas Farmakologis, Senyawa Aktif, dan Mekanisme Kerja Daun Salam (Syzygium polyanthum).
Prosiding Seminar Nasional & Workshop “Perkembangan Terkini Sains Farmasi & Klinik(5): 239- 244.
Salni, H. Marisa, dan W. R. Mukti. 2011.Isolasi Senyawa Antibakteri Dari Daun Jengkol (Pithecolobium lobatum Benth) dan Penentuan Nilai KHM-nya. Jurnal
Penelitian Sains(14): 38-41
.
Sela, E. I., dan S. Hartati. 2011. Pengenalan Jenis Penyakit THT Menggunakan Jaringan Learning Vector Quantization.
Prosiding Seminar Nasional Riset Teknologi Informasi(5): 71-76.
Weininger, D. 1988. SMILES, a Chemical Language and Information System. 1. Introduction to Methodology and Encoding Rules. Journal of
Chemical Information and Cumputer Sciences(28): 31-36.
Yunmar, R. A. 2011. Modul Pemrograman Web
Regular Expression. Yogyakarta: STMIK AMIKOM.