Vol. 1, No 1 (2006) 1–130 c
2006 T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner DOI: 10.1561/1800000001
A Framework for Web Science
Tim Berners-Lee
1, Wendy Hall
2,
James A. Hendler
3, Kieron O’Hara
4,
Nigel Shadbolt
4and Daniel J. Weitzner
51 Computer Science and Artificial Intelligence Laboratory, Massachusetts
Institute of Technology
2 School of Electronics and Computer Science, University of Southampton 3 Department of Computer Science, Rensselaer Polytechnic Institute 4 School of Electronics and Computer Science, University of Southampton 5 Computer Science and Artificial Intelligence Laboratory, Massachusetts
Institute of Technology
Abstract
This text sets out a series of approaches to the analysis and synthesis of the World Wide Web, and other web-like information structures. A comprehensive set of research questions is outlined, together with a sub-disciplinary breakdown, emphasising the multi-faceted nature of the Web, and the multi-disciplinary nature of its study and develop-ment. These questions and approaches together set out an agenda for
1
Introduction
The World Wide Web is a technology that is only a few years old, yet its growth, and its effect on the society within which it is embedded, have been astonishing. Its inception was in support of the information requirements of research into high energy physics. It has spread inex-orably into other scientific disciplines, academe in general, commerce, entertainment, politics and almost anywhere where communication serves a purpose [142, 143]. Freed from the constraints of printing and physical distribution, the results of scientific research, and the data upon which that research is carried out, can be shared quickly. Linking allows the work to be situated within rich contexts. Meanwhile, innovation has widened the possibilities for communication. Weblogs and wikis allow the immediacy of conversation, while the potential of multimedia and interactivity is vast.
But neither the Web nor the world is static. The Web evolves in response to various pressures from science, commerce, the public and politics. For instance, the growth of e-science has created a need to inte-grate large quantities of diverse and heterogeneous data; e-government and e-commerce also demand more effective use of information [34]. We need to understand these evolutionary and developmental forces.
Without such an appreciation opportunities for adding value to the Web by facilitating more communicative and representational possibil-ities may be missed. But development is not the whole of the story. Though multi-faceted and extensible, the Web is based on a set of architectural principles which need to be respected. Furthermore, the Web is a social technology that thrives on growth and therefore needs to be trusted by an expanding user base – trustworthiness, personal control over information, and respect for the rights and preferences of others are all important aspects of the Web. These aspects also need to be understood and maintained as the Web changes.
A research agenda that can help identify what needs to stay fixed and where change can be profitable is imperative. This is the aim of
Web Science, which aims to map how decentralised information struc-tures can serve these scientific, representational and communicational requirements, and to produce designs and design principles govern-ing such structures [34]. We contend that this science of decentralised information structures is essential for understanding how informal and unplanned informational links between people, agents, databases, organisations and other actors and resources can meet the informa-tional needs of important drivers such as e-science and e-government. How an essentially decentralised system can have such performance designed into it is the key question of Web Science [34].
‘Web Science’ is a deliberately ambiguous phrase. Physical science is an analytic discipline that aims to find laws that generate or explain observed phenomena; computer science is predominantly (though not exclusively) synthetic, in that formalisms and algorithms are created in order to support particular desired behaviour. Web science has to
be a merging of these two paradigms; the Web needs to bestudied and
understood, and it needs to beengineered. At the micro scale, the Web
technology interacts with human society mean that interdisciplinarity is a firm requirement of Web Science.
Such an interdisciplinary research agenda, able to drive Web devel-opment in socially and scientifically useful ways, is not yet visible and needs to be created. To that end, in September 2005 a Web Science Workshop was convened in London, UK (details of the contributors to the Workshop are given in the Acknowledgements). The workshop examined a number of issues, including:
• Emerging trends on the Web.
• Challenges to understanding and guiding the development of
the Web.
• Structuring research to support the exploitation of
opportu-nities created by (inter alia) ubiquity, mobility, new media
and the increasing amount of data available online.
• Ensuring important social properties such as privacy are
respected.
• Identifying and preserving the essential invariants of the Web
experience.
This text grew out of the Web Science Workshop, and it attempts to summarise, expand and comment on the debates. That an interdis-ciplinary approach was required was agreed by all, encompassing com-puter science and engineering, the physical and mathematical sciences, social science and policymaking. Web Science, therefore, is not just about methods for modelling, analysing and understanding the Web at the various micro- and macroscopic levels. It is also about engineering protocols and providing infrastructure, and ensuring that there is fit between the infrastructure and the society that hosts it. Web Science must coordinate engineering with a social agenda, policy with technical constraints and possibilities, analysis with synthesis – it is inherently interdisciplinary, and this text is structured to reflect that.
the full exploitation of the pre-existing Internet infrastructure (such as the Domain Name System) as the platform on which the Web was built. Standards are also crucial, and the World Wide Web Consortium’s (W3C) work of creating and recommending standards while maintain-ing stakeholder consensus shows that engineermaintain-ing needs to go hand in hand with a social process of negotiation.
Section 2 reviews these basic scientific and architectural principles in more detail. Exploring the metaphor of ‘evolution’ may help us to envisage the Web as a populated ecology, and as a society with the usual social requirements of policies and rules. Connecting rele-vant approaches, covering variant methodologies, varying spatiotem-poral grain sizes and modelling across a wide range of domains, will be challenging.
Section 3 looks at some of the issues to do with engineering the Web, and how to promote, and be promoted by, new technologies such as grids or services. Perhaps one of the most important potential devel-opments to be discussed in this section is the Semantic Web. The Web is usually characterised as a network of linked documents many of which are designed to be read by humans, so that machine-readability requires the heuristics of natural language processing. However, the Semantic Web, a vision of extending and adding value to the Web, is intended to exploit the possibilities of logical assertion over linked relational data to allow the automation of much information processing. Research and development has been underway for some time now on developing the languages and formalisms that will support querying, inference, align-ing data models, visualisation and modellalign-ing.
and are not published (in contrast to the WWW, where documents are routinely made available to a wider audience).
Section 4 looks at attempts to analyse the Web in ways that can feed back into the engineering effort. For instance, modelling the Web mathematically will enable search and information retrieval to keep pace with its growth, especially if linked to important fields such as natural language processing, network analysis and process modelling. Understanding emergent structures and macroscopic topology will help to generate the laws of connectivity and scaling to which the Web conforms.
As noted, the Web’s value depends on its use by and in society, and its ability to serve communication needs without destroying other valuable types of interaction. This means understanding those needs, their relation to other social structures, and the two-way interaction with technological development. Social issues such as these are dis-cussed in Section 5, and include philosophical issues to do with the meaning of symbols, logical problems such as methods of reasoning, and social issues including the creation and maintenance of trust, and the mapping of social communities via their activities on the Web.
Some of the interactions between society and Web technology are current and require policies for regulation and expressing preferences. For instance, the Semantic Web clearly motivates a corporate and indi-vidual cultural imperative to publish and share data resources, which in turn will require policies dealing with access control, privacy, identity and intellectual property (as well as interfaces and systems that can express policy rules to a heterogeneous user base). Policy, governance and political issues such as these are discussed in Section 6.
2
The Web and its Science
We may paraphrase Web Science as the science of the Web. Whilst this equivalence may be obvious we will begin by breaking down the phrase and sketching the components that enable the Web to function as an effective decentralised information system. We will review the basic architectural principles of the Web, designed to support growth and the social values of information-sharing and trustworthy behaviour in Section 2.1. Section 2.2 will then offer a few methodological reflections on the scientific investigation of the Web.
2.1 Web architecture
The architecture of the Web exploits simple technologies which connect efficiently, to enable an information space that is highly flexible and usable, and which, most importantly, scales. The Web is already an impressive platform upon which thousands of flowers have bloomed, and the hope is it can grow further, encompassing more languages, more media and more activities, hosting more information, as well as providing the tools and methods for interrogating the data that is out there. In this opening section we will briefly review the main principles
underlying Web architecture; this section is indebted to [155], and for more detail see that document.
The Web is a space in which resources are identified by Uniform
Resource Identifiers (URIs – [33]). There are protocols to support
interaction between agents, and formats to represent the information resources. These are the basic ingredients of the Web. On their design depends the utility and efficiency of Web interaction, and that design depends in turn on a number of principles, some of which were part of the original conception, while others had to be learned from experience. Identification of resources is essential in order to be able to share information about them, reason about them, modify or exchange them. Such resources may be anything that can be linked to or spoken of; many resources are purely information, but others not. Furthermore,
not all resources are on the Web, in that they may beidentifiable from
the Web, but may not be retrievable from it. Those resources which
are essentially information, and which can therefore be rendered with-out abstraction and characterised completely in a message are called
information resources.
For these reasoning and referring functions to happen on the global scale, an identification system is required to provide a single global standard; URIs provide that system. It would be possible for
alterna-tive systems to URIs to be developed, but the added value of a single
global system of identifiers, allowing linking, bookmarking and other functions across heterogeneous applications, is high. Resources have URIs associated with them, and each URI ideally identifies a single resource in a context-independent manner. URIs act as names (and addresses – see Section 3.1.2 below for discussion of this issue), and so if it is possible to guess the nature of a resource from its URI, that is a contingent matter; in general URIs refer opaquely. These principles of relationship between URIs and resources are desirable but not strictly enforceable; the cost of failing to associate a URI with a resource is the inability to refer to it, while the cost of assigning two resources to a URI will be error, as data about one resource gets applied to the other.
of which perhaps the most commonly understood are HTTP, FTP and mailto; such schemes are registered with the Internet Assigned Numbers Authority (IANA – http://www.iana.org/assignments/uri-schemes). These schemes need to be operated on principled lines in order to be effective.
So if we take HTTP as an example, HTTP URIs are owned and dis-bursed by people or organisations; and hence can be allocated respon-sibly or irresponrespon-sibly. For instance, an HTTP URI should refer to a single resource, and be allocated to a single owner. It is also desirable for such a URI to refer to its resource permanently, and not change its reference over time (see Section 5.4.6 below). Communication over the Web involves the exchange of messages which may contain data or metadata about a resource. One common aim of communication is to
access a resource via a URI, or to dereference the URI. If a resource
has been given an identifier, the resource has to be in some way recov-erable from the identifier for it to be of value. Dereferencing typically involves finding an appropriate index to look up the identifier. There are often clues in the identifier, or the use of the identifier, that help here, particularly if the naming authorities have some kind of hierar-chical structure.
maintenance programme could mean that some resources held on its servers were unlocatable.
What accessing an information resource entails varies from context to context, but perhaps the most common experience is receiving a representation of the (state of the) resource on a browser. It certainly need not be the case that dereferencing a URI automatically leads to the agent getting privileged access to a resource. It may be that no representation of the resource is available, or that access to a resource is secure (e.g. password controlled), but it should be possible to refer to a resource using its URI without exposing that resource to public view. The development of the Web as a space, rather than a large and complex notice board, follows from the ability of agents to use interactions to alter the states of resources, and to incur obligations and responsibilities. Retrieving a representation is an example of a so-called
safeinteraction where no alteration occurs, while posting to a list is an
unsafe interaction where resources’ states may be altered. Note that the universal nature of URIs helps the identification and tracking of obligations incurred online through unsafe interactions.
Not all URIs are intended to provide access to representa-tions of the resources they identify. For instance, the mailto: scheme identifies resources that are reached using Internet mail (e.g. mailto:[email protected] identifies a particular mailbox), but those
resources aren’t recoverable from the URI in the same way as a
web-page is. Rather, the URI is used todirect mail to that particular
mail-box, or alternatively to find mail from it.
useful, which is generally done in part by the server and in part by the client, the exact ratio between the two depending on the context of the interaction.
The power of the Web stems from the linking it makes possible. A resource can contain a reference to another resource in the form of an embedded URI which can be used to access the second resource. These links allow associative navigation of the Web. To facilitate linking, a for-mat should include ways to create and identify links to other resources, should allow links to any resources anywhere over the Web, and should not constrain content authors to using particular URI schemes.
An important aim of Web Science is to identify the essential aspects of identification, interaction and representation that make the Web work, and to allow the implementation of systems that can support or promote desirable behaviour. The experience of linking documents and, increasingly, data releases great power, both for authors and users. The possibility of serendipitous reuse of content empowers authors by increasing their influence, and users by providing access to much more information than would be possible using other technologies.
In particular, the three functions of identification, interaction and representation need to be separated out. Altering or adding a scheme for identification, say, should have no effect on schemes for interaction or representation, allowing independent, modular evolution of the Web architecture as new technologies and new applications come on stream (which is not to say that orthogonal specifications might not co-evolve cyclically with each other). Similarly, technologies should be extensible, that is they should be able to evolve separately without threatening their interoperability with other technologies.
of interoperability require that agents should be able to recover from errors, without, of course, compromising user awareness that the error has occurred.
As the Web grows and develops to meet new situations and pur-poses, the architecture will have to evolve. But the evolution needs to be gradual and careful (the slow and necessarily painstaking negotiations of standards committees are a good way to combine gradualism with fit-ness for purpose), and the principle of keeping orthogonal developments separate means that evolution in one area should not affect evolution elsewhere. The evolution needs to respect the important invariants of the Web, such as the URI space, and it is important that developers at all times work to preserve those aspects of the Web that need to be preserved. This is part of the mission of the W3C’s Technical Archi-tecture Group [154], although standards can only ever be part of the story. Web architectural principles will always be debated outside the W3C, quite properly, as well as within it.
2.2 Web science: Methodology
If the investigation of the Web is to be counted as properly scien-tific, then an immediate question is how scientific method should apply to this particular domain. How should investigators and engineers approach the Web in order to understand it and its relation to wider society, and to innovate?
Various aspects of the Web are relatively well-understood, and as an engineered artefact its building blocks are crafted, not natural phe-nomena. Nevertheless, as the Web has grown in complexity and the number and types of interactions that take place have ballooned, it remains the case that we know more about some complex natural phe-nomena (the obvious example is the human genome) than we do about this particular engineered one.
how these principles and standards should be arrived at. And of course there should be methods for moving from assessments of the Web and its evolution to the development and implementation of innovation.
To take one example, there are a number of technologies and meth-ods for mapping the Web and marking out its topology (see Section 4.1 below). What do such maps tell us (cf. e.g. [80])? The visualisations are often very impressive, with three-dimensional interpretations and colour-coded links between nodes. But how verifiable are such maps? In what senses do they tell us ‘how the Web is’ ? What are the limitations? The obvious application, in methodological terms, of maps and graphs of the Web’s structure is to direct sampling, by specifying the properties that models and samples of the Web should have. The rapid growth of the Web made a complete survey out of the question years ago, and information scientists need rapid and timely statistics about the content of Web-available literature. Representative sampling is key to such methods, but how should a sample be gathered in order to be properly called representative [188]? To be properly useful, a
sam-ple should be random; ‘randomness’ is usually defined for particular
domains, and in general means that all individuals in the domain have an equal probability of being selected for the sample. But for the Web that entails, for example, understanding what the individuals are; for instance, are we concerned with websites or webpages? If the former, then one can imagine difficulties as there is no complete enumeration of them. And sampling methods based on, say, IP addresses are compli-cated by the necessarily sparse population of the address space [219].
Furthermore, so cheap are operations on the Web that a small num-ber of operators could skew results however carefully the sample is chosen. A survey reported in more detail below [99] apparently dis-covered that 27% of pages in the .de domain changed every week, as compared with 3% for the Web as a whole. The explanation turned out not to be the peculiar industriousness of the Germans, but rather over a million URLs, most but not all on German servers, which resolved to a single IP address, an automatically-generated and constantly-changing pornography site.
The Web has lots of unusual properties that make sampling trickier;
properties such as, for instance, the percentage of pages updated daily, weekly, etc? How can we factor in such issues as the independence of underlying data sources? Do we have much of a grasp of the distribution of languages across the Web (and of terms within languages – cf. [167]), and how does the increasing cleverness in rendering affect things [138]? And even if we were happy with our sampling methodology, how amidst all the noise could we discover interesting structures efficiently [191]?
Furthermore, although for many purposes the Web can be treated as a static information space, it is of course dynamic and evolving. So any attempt at longitudinal understanding of the Web would need to take that evolution into account [218], and models should ideally have the growth of the system (in terms of constant addition of new vertices and edges into the graph), together with a link structure that is not invariant over time, and hierarchical domain relationships that are constantly prone to revision, built into them (cf. e.g. [253]).
Analytic modelling combined with carefully collected empirical data can be used to determine the probabilities of webpages being edited (altering their informational content) or being deleted. One experiment of observation of hundreds of thousands of pages over several months produced interesting results: at any one time round about 20% of web-pages were under 11 days old, while 50% appeared in the previous three months. On the other hand, 25% were over a year old – age being defined here as the difference between the time of the last modifica-tion to the page and the time of downloading [43]. Another experiment involved crawling over 150m HTML pages once a week for 11 weeks, and discovered, for example, strong connections between the top-level domain and the frequency of change (.com pages changed more fre-quently than .gov or .edu pages), and that large documents (perhaps counterintuitively) changed more frequently than small ones.
So one aspect of Web Science is the investigation of the Web in order to spot threats, opportunities and invariants for its development. Another is the engineering of new, possibly unexpected methods of dealing with information, which create non-conservative extensions of the Web. Such engineering may be research-based, or industry-based. The synthesis of new systems, languages, algorithms and tools is key to the coherent development of the Web, as, for example, with the study of cognitive systems, where much of the progress of the last few years has come with exploratory engineering as well as analysis and description (cf. e.g. [51]). So, for instance, the only way to discover the effects of radically decentralised file sharing is to develop peer to peer systems and observe their operation on increasingly large scales. Such pioneering engineering efforts are vital for the Web’s development; it is after all a construction. It is essential for the Web as a whole that implementations of systems interact and don’t interfere, which is where standards bodies play an important role.
3
Engineering the Web
Tracking the Web’s development, determining which innovations are good (e.g. P2P) and which bad (e.g. phishing), and contributing to the beneficial developments are key aims of Web Science. In this section, we will review some of the current directions for builders of the Web. We will look at the Semantic Web and some of the issues and controversies surrounding that (Section 3.1), issues to do with reference and identity (that are important for the Semantic Web to be sure, but also for any type of fruitful information analysis – Section 3.2), and then a selection of further initiatives, including Web services, P2P, grid computing and so on (Section 3.3).
3.1 Web semantics
The Web is a principled architecture of standards, languages and formalisms that provides a platform for many heterogeneous applica-tions. The result might easily be a tangle, and decisions made about the standards governing one formalism can have ramifications beyond, which can of course lead to complex design decisions (cf. [146]). Indeed, the multiple demands on the Web create a temptation to model it
semantically with highly expressive formalisms, but such expressivity generally trades off against usability and a small set of well-understood principles.
However, it is often the case that the trade-off between expressivity
and usability is a result of common misuse of such formalisms. For
instance – we will discuss this example in more detail below – the use of the machinery, implemented and proposed, of the Semantic Web [35, 17] for extending the Web is a common aim. But the design of the SW and its associated formalisms and tools is intended to extend the Web to cover linked data, not, as is often assumed, to improve search or get greater power from annotated text (which is another, separate, type of extension of the Web).
It may be, as many claim and hope, that local models and emergent semantics form an important part of our methods of comprehending the Web. If this is so, there will be a serious trade-off with interoperabil-ity: the benefits of structured distributed search and data sharing are large but require interoperable semantics. Leaving semantics underde-termined means forcing the (human) user to do the sense making, as for example with current P2P systems which, if they impose semantics at all, tend only to use very simple, low-level, task-relative structures. In particular, the assumption that the apparatus of the Semantic Web is designed to extend the technologies available for looking at documents can lead to a worry about the trade-off between “easy” emergent seman-tics and “difficult” logic that is misplaced; we must be careful not to confuse two separate application areas.
3.1.1 The Semantic Web
to make them accessible by link following. The rapid growth of the Web, and the way in which this change was quickly adopted in all sectors of Western society have perhaps obscured the radicalism of this step.
The Semantic Web (SW) is an attempt to extend the potency of the Web with an analogous extension of people’s behaviour. The SW
tries to get people to make theirdata available to others, and to add
links to make them accessible by link following. So the vision of the SW is as an extension of Web principles from documents to data. This extension, if it happens and is accepted, will fulfil more of the Web’s potential, in that it will allow data to be shared effectively by wider communities, and to be processed automatically by tools as well as manually [34]. This of course creates a big requirement: such tools must be able to process together data in heterogeneous formats, gathered using different principles for a variety of primary tasks. The Web’s power will be that much greater if data can be defined and linked so that machines can go beyond display, and instead integrate and reason about data across applications (and across organisational or community boundaries). Currently, the Web does very well on text, music and images, and passably on video and services, but data cannot easily be
used on the Web scale [135]. The aim of the SW is to facilitate theuse
of data as well as their discovery, to go beyond Google in this respect. In this context it is worth mentioning the distinction between
information retrieval and data retrieval (alias automated question-answering). The goal of the former is to produce documents that are relevant to a query; these documents need not be unique, and two successful episodes of information retrieval may nevertheless produce entirely different outcomes. The aim of the latter is to produce the correct answer to the query. There are vast differences between these two types of retrieval, and the stricter adherence to formal principles that the latter project requires may well be a key determinant of what structures one should select when one is finding schemes to provide significance for the terms in one’s query. Data are in a very real sense more fundamental than a document; hence the potential increase in the Web’s power. There are also a lot of data out there.
Traditionally, in AI for example, knowledge bases or expert systems, or even databases within an organisation, are used to represent certi-fied information that is reliable, trustworthy, probably consistent and often based on centralised acquisition strategies and representational protocols. On the Web, of course, these assumptions don’t necessarily apply. For instance, we must make sure that inconsistencies (which we must expect to encounter on the Web) don’t derail all inferences from a particular group of mutually inconsistent knowledge sources. Many of the applications for the SW are yet to come on stream, but some way of coming to terms with the potential scruffiness even of well-structured data from several sources is an issue [278].
The strategy the SW follows, therefore, is to provide a common framework for this liberation of data, based on the Resource Descrip-tion Framework (RDF), which integrates a variety of applicaDescrip-tions using XML as the interchange syntax [195]. Raw data in databases are brought together, and connected to models of the world (via ontologies – see below), which then allows the aggregation and analysis of data by producing consistent interpretations across heterogeneous data sources. The focus, therefore, is on the data itself. The SW is not simply a matter of marking up HTML documents on the Web, nor a variant on the traditional IR problem of document retrieval. It is an attempt to bring together data across the Web so as to create a vast database transcending its components, which makes possible applica-tions that infer across heterogeneous data, such as CS AKTive Space which allows browsing and inference across various data sources that chronicle the state of the computer science discipline in the United Kingdom [251].
So, for example, such a table might represent data about cars. Each row (record) would be associated with a particular car, and each column some property or field (colour, owner, registration number, type, recent mechanical history and so on). So some particular property of the car represented in a record would be represented in the appropriate record field. The table might also contain extra information that is harder to express in RDF or in the relational model itself. For instance, Mas-sachusetts State might own a relational database of cars that includes a field for the Massachusetts plate. In that event, the database might be intended to be definitive, i.e. a car is represented in the database if and only if it has a legal Massachusetts plate. That is of course an important property of the table [28].
This sort of database is the type of knowledge source whose exploita-tion is conceived as the basis for the SW. So the SW is an extension of the WWW in terms of its being the next stage of linking – linking
data not documents. It isnot a set of methods to deal specifically with
the documents that are currently on the Web, not a set of inference methods based on metadata or a way of classifying current webpages, or a super-smart way of searching. It is intended to function in the context of the relational model of data.
Linking is key to the SW. In particular, although the publishing of data and the use of RDF is essential, in many cases the practice has been the conversion of data into RDF and its publication divorced from real-world dataflow and management. The languages, methods and tools are still being rolled out for the SW, layer by layer, and it is perhaps unsurprising that quick wins don’t appear from the publi-cation of RDF before the tools for viewing, querying and manipulat-ing databases have reached the market. Indeed, as data publication often removes data from its organisational context, the new situation for many will seem worse than the pre-SW era: the application- and organisation-specific tools for manipulating data that had evolved with organisations will have provided a great deal of functionality that may have been lost or eroded. Meanwhile, the lack of linking between data undermines the even greater potential of the SW.
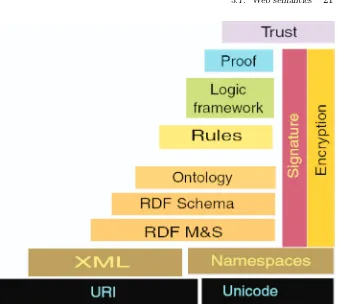
Fig. 3.1 The layers of the Semantic Web.
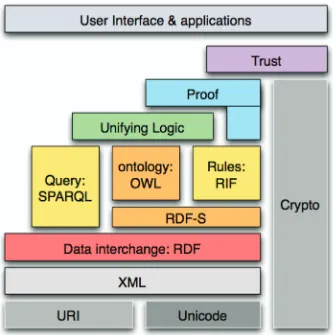
(as also does RDF Schema or RDF-S – [44]). RDF and OWL allow the exchange of data in a real-world context; on top of this core will sit a query language for RDF which will allow distributed datasets to be queried in a standardised way and with multiple implementations. SPARQL enables the interrogation of amalgamated datasets to provide access to their combined information [232].
Fig. 3.2 The Semantic Web Stack c.2006.
3.1.2 URIs: Names or addresses? Or both?
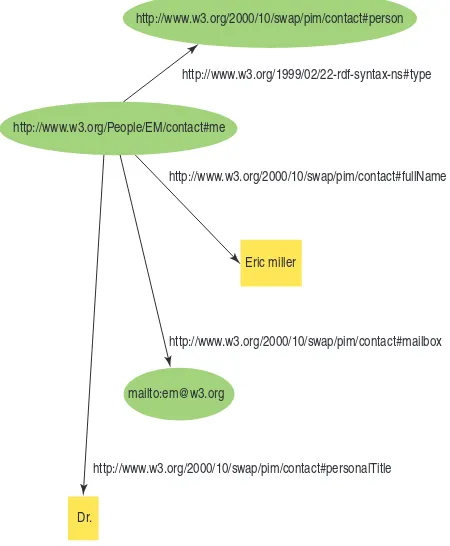
RDF is based on the identification of resources via URIs, and describing them in terms of their properties and property values [195]. Compare RDF with XLink, the linking language for XML, which provides some information about a link but doesn’t provide any external referent to anything with respect to which the link is relevant. In contrast, RDF assigns specific URIs to individual things, as we see in the following example. As we create the RDF graph of nodes and arcs (Figure 3.3), we can see that URIs are even used for the relations. A URI reference used as a node in an RDF graph identifies what the node represents; a URI used as a predicate identifies a relationship between the things identified by the nodes that are connected [172].
http://www.w3.org/2000/10/swap/pim/contact#person
http://www.w3.org/2000/10/swap/pim/contact#fullName
http://www.w3.org/2000/10/swap/pim/contact#mailbox
http://www.w3.org/2000/10/swap/pim/contact#personalTitle mailto:[email protected]
Eric miller
Dr.
http://www.w3.org/1999/02/22-rdf-syntax-ns#type
http://www.w3.org/People/EM/contact#me
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:contact="http://www.w3.org/2000/10/swap/pim/contact#"> <contact:Person rdf:about="http://www.w3.org/People/EM/contact#me"> <contact:fullName>Eric Miller</contact:fullName>
<contact:mailbox rdf:resource="mailto:[email protected]"/> <contact:personalTitle>Dr.</contact:personalTitle> </contact:Person>
</rdf:RDF>
In general, using URIs to identify resources is an important factor in the development of the Web [33]. Using a global naming syntax
con-vention (however arbitraryquasyntax) provides global network effects,
from which the benefits of the Web derive; URIs have global scope and are interpreted consistently across contexts. Associating a URI with a resource should happen if anyone might reasonably wish to link to it, refer to it or retrieve a representation of it [155].
Performing this foundational function needs a shift in our under-standing of how we use URIs. Typically, names and addresses are different; the name of something refers directly to it, the address tells you where it is (if not exactly how to get hold of it). In traditional com-puting identifiers turned up in programming languages, addresses were locations in memory. Names are nailed to objects, addresses to places, and therefore an object should have one name forever while its address may change arbitrarily often. This in some ways fed into a “classical” view of the Web: there was an assumption that an identifier (a URI) would be one of two kinds of thing. It would either be the name of something, understood separately from location – a URN – or specify the location of that thing – a URL. So the class of URIs partitioned into the class of URNs and the class of URLs (and maybe one or two others, such as Uniform Resource Citations). The HTTP scheme, for example, was seen as a URL scheme.
This extra layer of conceptual complication was gradually seen to be of less use, and the notion of a URI became primary. URIs can do their identifying either directly or via location, but this is not a deep conceptual distinction. Hence HTTP is a URI scheme, although an HTTP URI identifies its object by representing its primary access mechanism, and so (informally) we can talk about the HTTP URI being a URL. The name/address distinction is a spatial metaphor that works perfectly well in a standard computing environment, but in networked computing systems the distinction breaks down. Similarly, objects can be renamed, and often are (reasons why they shouldn’t be are discussed in Section 5.4.6 below). If a hierarchical system of naming is set up and maintained by an authority, then the name will function only as long as that authority supports that hierarchical system, and at the limit only as long as the authority itself remains in existence.
but implicitly contain reference to routing information, so the com-puter corresponding to a given IP address cannot be moved far in the routing structure. Domain names get used to refer to a computer or what the computer presents when we wish to reserve the right to move the thing corresponding to the identification from one part of the Inter-net to another. So the Domain Name System (DNS), being indepen-dent of the routing system, does not restrict the IP addresses that can be given to a computer of a given domain name. DNS does look like a system of names, whereas IP addresses do seem to function like addresses [26].
However, it is also very observable that domain names for particular resources do change, because the protocols used for naming them are altered – the reason being that there is information embedded in the name. In the offline world, names can survive the failure of such embed-ded information to remain true (John Stuart Mill gives the example of ‘Dartmouth’ as a place whose location may or may not remain at the mouth of the River Dart). Such changes are unproblematic. But online, this is harder to ensure.
Consider the example http://pegasus.cs.example.edu/disk1/
students/ romeo/cool/latest/readthis.html [26]. There are all sorts of reasons why this URI might change. ‘pegasus’, ‘cs’, ‘students’ etc may all change over the years as different computers get used to host the information, or as Romeo graduates and becomes a faculty member. His opinions about what is ‘cool’ or what is ‘latest’ will also evolve over time (one hopes). ‘http’, being the protocol used to present the resource, and ‘readthis’ being relatively meaningless are the least likely parts of the URI associated with the particular resource to change.
Such matters were of relatively small significance as long as humans were the main users and exploiters of the Web – after all, one is mainly after a resource and the content it contains, and although it may be frustrating to follow a URI only to find the resource no longer lived there, that was an irritation rather than a serious breakdown in the sys-tem. People are also relatively flexible in online retrieval and can toler-ate ambiguities. But some kind of resolution to the name/address issue is required if we expect formal systems to deal with URIs. The SW is a tool for doing things in a social space, not merely a set of rules for manipulating formulae, so we need to know what we are referring to, and how to get at those referents where appropriate. It is desirable for an e-commerce system, for example, to refer without ambiguity to a number of things: documents such as bills and invoices, abstract items such as prices, and concrete things like buyers and the items that are actually bought and sold. [31] summarises and provides a critique of a large num-ber of ways of understanding this issue in the context of HTTP.
Naming, ultimately, is a social set of contractual arrangements. We should not let the virtual nature of cyberspace blind us to the fact that people ask and pay for, and get given, domain names and space on servers. Authorities maintain these things, and also act as roots for dereferencing purposes. The stability of these institutional setups will help determine the stability of the Web’s naming system.
3.1.3 Ontologies
Data can be mapped onto an ontology, using it as alingua francato facilitate sharing. Ontologies are therefore intended to put some sort of order onto information in heterogeneous formats and representations, and so contribute to the ideal of seeing the Web as a single knowledge source. To that extent, an ontology is similar to a database schema, except that it will be written with a comparatively rich and expressive language, the information will be less structured, and it determines a theory of a domain, not simply the structure of a data container [96].
So ontologies are seen as vital adjuncts to data sharing, and the ultimate goal of treating the Web as a single source of information, but they also have detractors. Many commentators worry that the focus on ontologies when it comes to postulating formalisms for the future Web is to make the mistake of over-privileging classification when it comes to understanding human language and communication [113]. It should certainly be pointed out that many ontologies actually in use, for example in industry, are taxonomies for special-purpose classification of documents or webpages, tend not to be elaborate, and do not rely on highly expressive formalisms [88].
OWL has its roots in an earlier language DAML+OIL [65] which included description logic (DL – [42]) among its various influences. OWL goes beyond DL, which sets out domain concepts and terminology in a structured fashion, by using the linking provided by RDF to allow ontologies to be distributed across systems, compatible with Web stan-dards, open, extensible and scalable. Ontologies can become distributed as OWL allows ontologies to refer to terms in other ontologies. In this way OWL is specifically engineered for the Web and Semantic Web, and of many languages sharing symbols ([cf. 134]).
It is difficult to specify a formalism that will captureall the
Causal logic [e.g. 258] developed out of logics of action in AI, and is intended to capture an important aspect of common sense understand-ing of mechanisms and physical systems. Temporal logic formalises the rules for reasoning with propositions indexed to particular times; in the context of the fast-growing Web, the prevalence of time-stamping online and the risks of information being used that is out of date ensures the relevance of that. Certainly temporal logic approaches have been suggested for ontology version management [149].
Probabilistic logics are calculi that manipulate conjunctions of prob-abilities of individual events or states, of which perhaps the most well-known are Bayesian, which can be used to derive probabilities for events based on prior theories about how probabilities are distributed (and very limited real data). Bayesian reasoning is commonplace in search engines, and even the search for spam (cf. [117]). In domains where rea-soning under uncertainty is essential, such as bioinformatics, Bayesian ontologies have been suggested to support the extension of the Web to include such reasoning [19]. The utility of Bayesian approaches in computational systems cannot be doubted; more controversially some also claim that human reasoning conforms to a Bayesian pattern [118], although a significant body of work suggests humans are not Bayesian estimators [162]. Notwithstanding, at the very least machines that con-sistently adjust their probabilities in the light of experience will have a complementary role supporting human decision making.
Hence there is certainly logical and conceptual apparatus that will enable a rich variety of reasoning to be expressed, although the deeper argument made by many critics, such as [113], that a great many lim-itations result from the situated, embodied and embedded nature of much reasoning and conceptualisation, won’t be addressed by the pro-liferation of abstract formalisms. But equally we must try to avoid the assumption that the SW is intended as a single overarching system, with a single way of interacting and a particular set of representation requirements that force all knowledge into one form (cf. [158]).
As we have seen, the SW is intended in particular to exploit one type of data, relational data. If such data have value in a context, then SW technologies should similarly have value, and indeed should add value as they should (a) enable further inference to be done on the data, and (b) allow, via ontologies, the data to be linked to potentially vast stores of data elsewhere. The SW claim, then, is not that all data or knowledge has to be representable in some narrow set of formalisms, but rather that the power of linking data allows much more to be done with it. For many purposes, and in some contexts for most usual purposes, unambitious representation schemes that may appear to lack a rich range of expressive possibilities may well be entirely adequate. The SW is not intended to be a system that will meet all purposes, but it is an extension of the Web that is intended to exploit the potential of the linking of unprecedented quantities of data. Ontologies will allow a common understanding of data pulled together from heterogeneous sources, as long as their relevant parts are appropriate for the task in hand. The ambition is in the range of data that such an approach can exploit, and in the value SW technologies hope to add, not in the extension of the range of inference that can be achieved automatically (though extending the range should also be possible).
3.1.4 Folksonomies and emergent social structures
popular name of social software. For instance, a wiki is a website that allows users and readers to add and edit content, which allows communication, argument and commentary; the Wikipedia (http://en. wikipedia.org/wiki/Main Page for the English language version), an online encyclopaedia written by its user community, has become very reliable despite ongoing worries about the trustworthiness of its entries
and fears of vandalism. Ontologies may be supplemented by
folk-sonomies, which arise when a large number of people are interested
in some information, and are encouraged to describe it – ortag it (they
may tag selfishly, to organise their own retrieval of content, or altruisti-cally to help others’ navigation). Rather than a centralised form of clas-sification, users can assign key words to documents or other informa-tion sources. And when these tags are aggregated, the results are very interesting. Examples of applications that have managed to harness and exploit tagging are Flickr (http://www.flickr.com/ – a photogra-phy publication and sharing site) and del.icio.us (http://del.icio.us/ –
a site for sharing bookmarks). Keepers of unofficial weblogs (blogs) tag
their output. The British Broadcasting Corporation (BBC) has seen opportunities here with a radio programme driven by users’ tagging (via mobile phone) of pop songs [61].
tagging data, can be tracked to show these patterns developing through time [84].
Such structures allow semantics to emerge from implicit
agree-ments, as opposed to the construction of ontologies indicating explicit
agreements; the field of semiotic dynamics is premised on the idea
that agreed communication or information organisation systems often develop through similar decentralised processes of invention and nego-tiation [268]. It has been argued that implicit agreement, in the form of on-demand translations across information schemas can be adequate to support interoperable semantics for, and distributed search through, P2P systems – though whether such implicit translations will be easy to generate across information sources designed for different tasks is very much an open question [2].
3.1.5 Ontologies v folksonomies?
It is argued – though currently the arguments are filtering only slowly into the academic literature – that folksonomies are preferable to the use of controlled, centralised ontologies [e.g. 259]. Annotating Web pages using controlled vocabularies will improve the chances of one’s page turning up on the ‘right’ Web searches, but on the other hand the large heterogeneous user base of the Web is unlikely to contain many people (or organisations) willing to adopt or maintain a complex ontology. Using an ontology involves buying into a particular way of carving up the world, and creating an ontology requires investment into methodologies and languages, whereas tagging is informal and quick. One’s tags may be unhelpful or inaccurate, and no doubt there is an art to successful tagging, but one gets results (and feedback) as one learns; ontologies, on the other hand, require something of an investment of time and resources, with feedback coming more slowly. And, crucially, the tools to lower the barriers to entry to controlled vocabularies are emerging much more slowly than those being used to support social software [61].
of metadata, with all the disadvantages of informality and all the advan-tages of low barriers to entry and a high user base. But tags are only part of the story about Web resources [128].
Ontologies and folksonomies have been caricatured as opposites. In actual fact, they are two separate things, although some of the function-ality of ontologies can uncontroversially be taken over by folksonomies in a number of contexts. There are two separate (groups of) points to make. The first has to do with the supposed trade-off between ontolo-gies and folksonomies; the second to do with perceptions of ontoloontolo-gies. Ontologies and folksonomies are there to do different things, and deal with different cases. Folksonomies are a variant on the keyword-search theme, and are an interesting emergent attempt at information retrieval – how can I retrieve documents (photographs, say) relevant to the concept in which I am interested? Ontologies are attempts to regulate parts of the world of data, and to allow mappings and interac-tions between data held in disparate formats or locainterac-tions, or which has been collected by different organisations under different assumptions. What has been represented as a trade-off, or a competition, or even a zero-sum game may be better represented as two separate approaches to two different types of problem. It may be that the sets of problems they are approaches to overlap, in which case there may on occasion be a choice to be made between them, but even so both ontologies and folksonomies have definite uses and are both potentially fruitful avenues of research [257].
complementary development of SW technologies and technologies that exploit the self-organisation of the Web [e.g. 101].
Perceptions of ontologies depend on the understanding of this dis-tinction. Consider, for example, the costs of ontologies. In the first place, there will be areas where the costs, be they ever so large, will be easy to recoup. In well-structured areas such as scientific applications, the effort to create canonical specifications of vocabulary will often be worth the gain, and probably essential; indeed, Semantic Web tech-niques are gaining ground in scientific contexts with rich data in which there exists the need for data processing and the willingness to reach a consensus about terms. In certain commercial applications, the poten-tial profit from the use of well-structured and coordinated specifications of vocabulary will outweigh the sunk costs of developing or applying an ontology, and the marginal costs of maintenance. For instance, facil-itating the matching of terms in a retailer’s inventory with those of a purchasing agent will be advantageous to both sides.
And the costs of developing ontologies may decrease as the user base of an ontology increases. If we assume that the costs of building ontologies are spread across user communities, the number of ontology engineers required increases as the log of the size of the user community, and the amount of building time increases as the square of the number of engineers – simple assumptions of course but reasonable for a basic
model – the effort involved per user in building ontologies for large
communities gets very small very quickly [29]. Furthermore, as the use of ontologies spreads, techniques for their reuse, segmentation and merging will also become more familiar [212, 256, 10], and indeed there will be an increasing and increasingly well-known base of ontologies there to be reused.
use cannot be enforced. If the SW is seen as requiring widespread buy-in to a particular pobuy-int of view, then it is understandable that emergent structures like folksonomies begin to seem more attractive (cf. [259]).
But this is not an SW requirement. In fact, the SW’s attitude to ontologies is no more than a rationalisation of actual data-sharing practice. Applications can and do interact without achieving or attempting to achieve global consistency and coverage. A system that presents a retailer’s wares to customers will harvest information from suppliers’ databases (themselves likely to use heterogeneous formats) and map it onto the retailer’s preferred data format for re-presentation. Automatic tax return software takes bank data, in the bank’s preferred format, and maps them onto the tax form. There is no requirement for global ontologies here. There isn’t even a requirement for agreement or
global translations between the specific ontologies being usedexcept in
the subset of terms relevant for the particular transaction. Agreement need only be local.
The aim of the SW should be seen in the context of the routine nature of this type of agreement. The SW is intended to create and manage standards for opening up and making routine this partial agree-ment in data formats; such standards should make it possible for the exploitation of relational data on a global scale, with the concomitant leverage that that scale buys.
3.1.6 Metadata
In general, metadata are important for effective search (they allow resources to be discovered by a wide range of criteria, and are help-ful in adding searchable structure to non-text resources), organis-ing resources (for instance, alloworganis-ing portals to assemble composite webpages automatically from several suitably-annotated resources), archiving guidance (cf. [58]), and identifying information (such as a unique reference number, which helps solve the problem of when one Web resource is the ‘same’ as another). Perhaps the most important use for metadata is to promote interoperability, allowing the combination of heterogeneous resources across platforms without loss of content. Metadata schema facilitate the creation of metadata in standardised formats, for maximising interoperability, and there are a number of such schemes, including the Dublin Core (http://dublincore.org/) and the Text Encoding Initiative (TEI – http://www.tei-c.org/). RDF pro-vides mechanisms for integrating such metadata schemes.
There are a number of interesting questions relating to metadata. In the first place, what metadata need to be applied to content? Sec-ondly, how will metadescription affect inference? Will it make it harder? What can be done about annotating legacy content? Much has been written about all these questions, but it is worth a small digression to look at some approaches to the first.
As regards the metadata required, needless to say much depends on the purposes for which resources are annotated. For many purposes – for example, sharing digital photos – the metadata can look after them-selves, as the success of sites like Flickr show. More generally, interesting possibilities for metadata include time-stamping, provenance, uncer-tainty and licensing restrictions.
can be given in XML tags in the normal way. However, in the body of the resource, which we cannot assume to be structured, there may be a need for temporal information too, for users to find manually. In such a case, it is hard to identify necessary temporal information in a body of unstructured text, and to determine whether a time stamp refers to its own section or to some other part of the resource. It may be that some ideas can be imported from the temporal organisation of more structured resources such as databases, as long as over-prescription is avoided [173]. In any case, it is essential to know the time of creation and the assumptions about longevity underlying information quality; if the content of a resource ‘is subject to change or withdrawal with-out notice, then its integrity may be compromised and its value as a cultural record severely diminished’ [107].
Another key factor in assessing the trustworthiness of a document is the reliability or otherwise of the claims expressed within it; meta-data about provenance will no doubt help in such judgements but need not necessarily resolve them. Representing confidence in reliability has always been difficult in epistemic logics. In the context of knowledge representation approaches include: subjective logic, which represents an opinion as a real-valued triple (belief, disbelief, uncertainty) where the three items add up to 1 [159, 160]; grading based on qualitative judge-ments, although such qualitative grades can be given numerical inter-pretations and then reasoned about mathematically [110, 115]; fuzzy logic (cf. [248]); and probability [148]. Again we see the trade-off that the formalisms that are most expressive are probably the most difficult to use.
Finally, metadata relating to licensing restrictions has been growing with the movement for ‘creative commons’, flexible protections based on copyright that are more appropriate for the Web and weblike con-texts. Rather than just use the blunt instrument of copyright law, cre-ative commons licenses allow authors to fine-tune the exercise of their rights by waiving some of them to facilitate the use of their work in various specifiable contexts [187]. We discuss copyright in more detail in Section 6.2 below.
The questions about the difficulties of reasoning with metadata, and the giant task of annotating legacy data, remain very open. It has been argued that annotating the Web will require large-scale auto-matic methods, and such methods will in turn require particular strong knowledge modelling commitments [170]; whether this will contravene the decentralised spirit of the Web is as yet unclear. Much will depend on creative approaches such as annotating on the fly as annotations are required, or else annotating legacy resources such as databases under-lying the deep Web [283].
3.2 Reference and identity
system is essentially decentralised and not policed, in accordance with the Web’s governing principles, but this lack of centralisation allows different schemes and conventions, and indeed carelessness, to flourish, which in turn opens up the possibility of failures of unique reference.
3.2.1 Reference: When are two objects the same?
Decentralisation is a problem from a logical point of view, though a huge advantage from that of the creator of content. The same object might be referred to online, perfectly correctly, as ‘Jane Doe’, ‘Janey Doe’, ‘Jane A. Doe’, ‘Doe, J.A.’ and so on. Furthermore, any or all of these terms may be used to refer to another distinct object. And, of course, the orig-inal Jane Doe may be misnamed or misspelled: ‘Jnae Doe’, etc. These failures of unique reference are relatively trivial for human users to dis-entangle, but are of course very hard for machines to work out. And if we are hoping to extract usable information from very large reposi-tories of information, where hand-crafted solutions and checking refer-ence by eye are not feasible, machine processing is inevitable. Referrefer-ence problems are particularly likely to occur when information sources are amalgamated, a ubiquitous problem but a serious one in the context of the Semantic Web. And the decentralisation of the Web precludes making a unique name assumption, in the manner of [240].
A heuristic method for resolving such clashes, in the real world, is to make an intelligent judgement based on collateral information, and this has been mimicked online by the computation of the community of practice of a name, based on the network of relationships surrounding each of the disputed instances. For example, if ‘Jane Doe’ and ‘Doe, J.A.’ have both got strong associations with ‘University of Loamshire’, one because she works there, the other because she has worked on a
project of which UoL was a partner, then that isprima facie evidence
that the two terms refer to the same object – though of course such a judgement will always be highly defeasible [11].
In general, reference management, and the resolution of reference problems, will always be tricky given that the Web covers a vast amount of information put together for a number of different reasons and to solve various tasks; meanings and interpretations often shift, and there may on occasion be little agreement about the referents of terms. An important issue for Web Science is precisely how to understand refer-ence and representation, and to determine which management systems and formalisms will allow greater understanding and tracking of what the Web is purporting to say about which objects.
3.2.2 When are two pages the same?
An alternative take on the reference problem is that of determining
when two webpages arethe same page. This of course would be trivial
The basis for making similarity judgements need not only be the content on the page, but could also be the structure of hyperlinks within which the page is embedded. The information that a user requires need not come from a single page, but instead can be gleaned from the cluster of documents around the basic topic, and so the linkage structures there can be extremely important. And a further possible way of understanding similarity is between particular usage patterns of the page – are two pages often accessed at similar points in a Web surfing session [76]?
Content-based similarity can be approached by matching words or subsequences from the two pages. Relatively simple techniques can be used to determine the resemblance between two pages (the ratio between the size of the intersection of the subsequences and the size of their union), and the containment of one by the other (the ratio between the intersection and the size of the contained set) [48]. Link-based metrics derive from bibliometrics and citation analysis, and focus on the links out and links in that two pages have in common, relative to the general space of links in the topic cluster. Usage-based metrics exploit information gathered from server logs and other sources about when pages are visited, on the assumption that visits from the same user in the same session in the same site are likely to be conceptually related, and the greater the similarity between the times of users’ access to webpages, the greater the likelihood of those pages being somehow linked conceptually [227].
3.3 Web engineering: New directions
on being able to keep its cache tractable while also of a significant size. Greater demand for personalised services and search will also put pres-sure on the system. Widening the scope of search to encompass items such as multimedia, services or ontology components, will also require the pursuit of academic research programmes, effective interfaces and plausible business models before commercial services come on stream. Existing and developing approaches to leveraging the Web have to be extended into new Web environments as they are created (such as P2P networks, for example).
3.3.1 Web services
Services are a key area where our engineering models of the Web need to be engaged and extended. Web services are distributed pieces of code written to solve specific tasks, which can communicate with other ser-vices via messages. Larger-scale tasks can be analysed and recursively broken down into subtasks which with any luck will map onto the spe-cific tasks that can be addressed by services. If that is the case, and if services are placed in a Web context, that means that users could invoke the services that jointly and cooperatively meet their needs.
Software abstracts away from hardware and enables us to specify computing machines in terms of logical functions, which facilitates the specification of problems and solutions in relatively intuitive ways. The evolution of the Web to include the provision and diffusion of services opens up new abstraction prospects: the question now is how we can perform the same abstraction away from software. What methods of describing services will enable us to cease to worry about how they will be performed?
facilitates Web service integration to achieve new goals, while also pro-viding a formalism for integration evaluation [296].
Process algebras (see Section 4.2.5) have also been applied to services. Again, as with the Petri net approach, the use of a formal algebra allows both design and evaluation to take place (or indeed one or the other, depending on what alternative methods are available to generate or survey the code). For instance, [98] describes the mapping between an expressive process algebra and BPEL4WS (a standard-ised XML-based notation for describing executable business processes), which allows both the creation of services in BPEL4WS followed by their evaluation and verification using the process algebra, or the gen-eration of BPEL4WS code automatically from the use of the algebra to specify the desired services. In general, the algebraic specification of services at an abstract level and reasoning about them has been a major area of research on services [e.g. 75, 105, 208].
BPEL4WS is an extended version of the Business Process Execution Language BPEL, which is becoming an increasingly important way to interleave Web services with business processes. BPEL has its limits, but allows the creation of composite services from existing services. The next stage is to adapt this approach for the P2P environment, and the vehicle currently under development for that is CDL, aka WS-CDL, aka Choreography (Web Services Choreography Description Language – [164]), an XML-based language for defining the common and comple-mentary observable behaviour in P2P collaborations. The aim is that interoperable P2P collaborations can be composed using Choreography without regard to such specifics as the underlying platforms being used; instead the focus is on the common goal of the collaborators. Whereas BPEL allows existing services to be combined together, Choreography shifts the focus onto the global description of collaborations, informa-tion exchanges, ordering of acinforma-tions and so on, to achieve agreed goals.
3.3.2 Distributed approaches: Pervasive computing, P2P and grids
to large-scale, more-or-less fixed dedicated computing machines don’t necessarily apply. Obvious examples include mobile computing, ubiqui-tous (or pervasive) computing where interoperability becomes an issue, P2P systems and grid computing. Mobile computing makes all sorts of engineering demands; the computing power available isn’t vast and users must be assumed to be constantly on the move with variable bandwidth and access. Furthermore, presenting information to the user requires different paradigms from the PC, for example to allow the user to receive enough information on the small screen to make brows-ing compellbrows-ing [20, 193]. Mobile access to the Web may become the dominant mode in many nations, particularly developing ones, thanks to relatively low prices and reliability of wireless connections and bat-tery power [222]. Research in this area is important for the equitable distribution of Web resources.
Ubiquitous computing, P2P and grid computing share many seri-ous research issues, most notably the coordination of behaviour in large scale distributed systems. Ubiquitous computing envisages small, rel-atively low-powered computing devices embedded in the environment interacting pervasively with people. There are various imaginative pos-sibilities, such as smart threads which can be woven into clothing. But without second-guessing the trends it is clear that smaller devices will need wireless connections to network architectures allowing automatic
ad hoc configuration, and there are a number of engineering difficulties associated with that issue (cf. [244, 176]).
For instance, service discovery in the pervasive paradigm must take place without a human in the loop. Services must be able to adver-tise themselves to facilitate discovery. Standards for publishing services would be required to ensure security and privacy, trust of the service’s reliability, the compensation for the service provider, and exactly how the service would be composed with other invoked services to achieve some goal or solve the problem at hand [179].
P2P networks, characterised by autonomy from central servers, intermittent connectivity and the opportunistic use of resources [220], are another intriguing environment for the next generation Web. In such networks (including file-sharing networks such as Napster, com-munication networks such as Skype, and computation networks such as SETI@home), the computer becomes a component in a distributed system, and might be doing all sorts of things: backing up others’ files, storing encrypted fragments of files, doing processing for large-scale endeavours in the background, and so on. There are clearly many potential applications for both structured and unstructured P2P net-works in the Web context. The question for Web scientists is what essential functions for the Web experience can be preserved in loosely coupled autonomous systems. Given the unusual characteristics of P2P, including the potentially great number and heterogeneity of P2P nodes, traditional engineering methods such as online experimentation (which would require unfeasibly large numbers of users to sign up to an archi-tecture and allow their transactions to be monitored) or large-scale sim-ulation (the scale is simply too large) will be inappropriate. The scale licensed by the Web, which we will continue to see in P2P networks, makes network modelling theory essential (cf. e.g. [249, 189]), but we must expect radical experimentation, innovation and entrepreneurial-ism to lead the way in this field.
The temptation to exploit radically decentralised environments such as P2P networks in the next generation of the Web is strong; decentral-isation is a key aspect of the Web’s success. So, for example, one could imagine P2P networks being used to locate cached pages for backups in the event of failure or error leading to missing pages or dangling links. It needs to be established whether the ability of a P2P network to do that (which itself is currently unproven) would undermine the domain name system or support it.
![Fig. 4.1 The bowtie shape of the Web and its fractal nature [78].](https://thumb-ap.123doks.com/thumbv2/123dok/1485371.1529028/56.612.146.466.125.333/fig-bowtie-shape-web-fractal-nature.webp)
![Fig. 4.2 Demand and supply for a network good [281].](https://thumb-ap.123doks.com/thumbv2/123dok/1485371.1529028/65.612.161.460.117.321/fig-demand-supply-network-good.webp)
