Dynamic Query Scheduling for
Online Integration of Semistructured Data
Handoko
School of Computer Science and Software Engineering University of Wollongong, Australia
Email: [email protected]
Janusz R. Getta
School of Computer Science and Software Engineering University of Wollongong, Australia
Email: [email protected]
Abstract—In data integration systems a user request issued at a central site is decomposed into a number of sub-requests, which later on are processed at the remote sites. The results are sent back to a central site for data integration and the results of integration are returned to a user. Data integration systems often failed to show its best performance due to unpredictable data arrival rate. Traditionally, data integration requires the complete results from the remote sites to be available at a central site before final computations begin. An online integration system starts and continues the computations at the central site shortly after every piece of data is received from the remote sites.
Execution of online integration plan in static scheduling strategy causes poor performance of data integration system as unnecessary computations are executed in some circumstances. This paper proposes a dynamic scheduling for online integration plans, which employs data increment monitoring system which is able to dynamically change the data integration plans whenever it is necessary.
Keywords—Online data integration, dynamic query scheduling, semistructured data
I. INTRODUCTION
Data integration systems employs classical distributed query processing where a query execution plan (QEP) is generated at compile time and query engine executes the query at runtime. Although this approach has been proven, integration processing at the central site can create a bad performance because the central site does not have enough information about remote site’s behavior. The complexity of sub-query sent to remote sites, the load of the particular remote site and the characteristic of network are responsible to the data arrival rate at the central site. In addition, the characteristic of sub-query results are difficult to asses [1]. Moreover, evaluation of a data integration after all data available at the central site causes a slow response to a data integration system.
Online integration is a continuous process to combine data transmitted over a network with data which are already available at a central site. Online integration applies online processing to instantly compute the smallest unit of increment data without waiting for entire set of data available. Then, the result of computation is combined with the current result to obtain a new state of processing.
In online integration systems, user requests are transformed intoglobal query expressions. After decomposition of global query expressions,data integration expressionsare generated, where results from remote sites become their arguments in the
form of data containers. A set of increment expressions are generated from data integration expressions such that every data container is assigned to an increment expression. Based on increment expressionsgenerated earlier,online integration
plans are produced, and processing increment data is
per-formed through evaluation of selected online integration plan.
Many works and algorithms have been proposed to increase performance of online integration regarding to unpredictable data arrival rate. Most of the works answer the problem at one or some of three levels, i.e. operator, scheduling, and query execution plan level [1]. This paper proposes a mixed dynamic strategy to response this problem as follow:
• we propose an online integration system to compute every single increment data received at a central site as soon as it is arrived. We employ an algebraic system for semistructured data which has enough properties to generate an increment expression for every data container in a data integration expression.
• we propose a system to reduce expensive IO cost of mate-rialization updates by priority execution of data arrivals and materialization management.
The structure of this paper is as follows: section 2 describes previous work. Section 3 and 4 covers online integration system architecture and scheduling of online integration plan. Then, we discuss evaluation of online integration plans in section 5, and section 6 concludes the paper.
II. PREVIOUSWORK
Data integration systems for semistructured data require data model and algebra that allow for efficient processing of semistructured structures. XAnswer and XAL systems provide operators on relational-like data structures which require trans-formation process from tree structure to relational model and vice versa. TAX(Tree algebra for XML) is based on tree view of XML documents [2]. XTreeGraph [3] system handles a set of overlapping trees. XML algebra proposed in [2] is a tree-based algebra generalizing the relational algebra.
Data integration systems can be classified into two groups i.e. materialized view (data warehousing) and virtual view ( vir-tualization). Viyanon [4] proposed a data integration systems for of XML Data by detecting the similarity of sub trees. Whereas, Poggi in [5] proposed integration system based on an identification of nodes.
In order to overcome critical and time consuming task of integration systems for DW and BI, researchers put their efforts to propose many algorithms and techniques. Fegaras [6] and Bonifati [7] proposed systems for incremental maintenance of XML view. Meanwhile, a system to maintain materialized XQuery view by performing incremental update to gain a better access to data sources is proposed in [8].
Dynamic scheduling strategy proposed in [9] is to mod-ify the query plan whenever unexpected delay (initial delay, burstly arrival, and slow delivery) occurs at any data sources. Bouganim [1] employs monitoring arrival rate and available memory in the execution strategy of integration system.
III. ONLINEINTEGRATIONSYSTEMARCHITECTURE
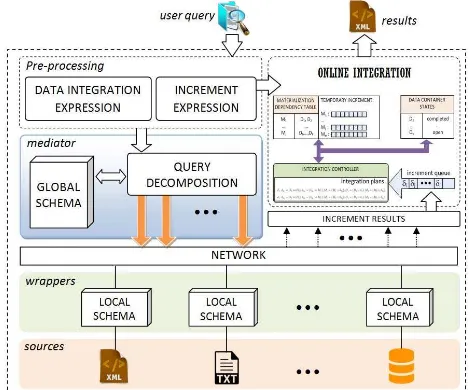
In this paper an online integration system contains a mediator and a number of wrappers (see Fig. 1). Amediator
transforms a user query into a global query expression and apply standard syntax-based optimisation, e.g. moving filtering before binary operations.Restructuringoperation (π) is pushed to the top of aglobal query expression.
Fig. 1. Online integration system architecture
Definition 1: Let {x1, ..., xn} be a set of pointers to the data containers with XML documents located at remote sites. A global query expressione(x1, ..., xn)is an expression built from the operations offiltering(σ),join(⊲⊳),semijoin,antijoin
(∼) andunion (∪) on{x1, ..., xn}[10].
A. XML Algebra Rules
Online integration system operates on an algebraic system which is defined in [10]. The operators are conceptually consistent with the basic operators of relational data model. If we simplify each document in a data container such that it represents a row in a relational table, then the system of operations reduce to relational algebra.
XML algebra operators possess common associativity and distributivity properties as in a relational algebra model. Dis-tributivity properties overunionoperation are as follows:
Fig. 2. (a) A syntax tree of aglobal query expressionand decomposition strategy to balance central and remote site processing (b) A data integration expression (c) Increment expression for increment dataδ1
(1) Filtering:σϕ(r∪s) =σϕ(r)∪σϕ(s); (2) Union:(r∪s)∪t= (r∪s)∪t=r∪s∪t; (3) Join:(r∪s)⊲⊳ρ,ϕt= (r ⊲⊳ρ,ϕt)∪(s ⊲⊳ρ,ϕt); (4) Antijoin:(r∪s)∼ϕt= (r∼ϕt)∪(s∼ϕt), and (5)r∼ϕ(s∪t) = (r∼ϕs)∼ϕ((r∼ϕs)⋉ϕt).
When data containersr, s,andtshare common tree pattern to satisfy propositional condition of operations, then distribu-tivity of antijoin operation over join, union andantijoin can be determined as follows:
(6)(r∼ϕs)⊲⊳ρ,ϕt= (r ⊲⊳ρ,ϕt)∼ϕ(s ⊲⊳ρ,ϕt); (7)r ⊲⊳ρ,ϕ(s∼ϕ t) = (r ⊲⊳ρ,ϕs)∼ϕ(r ⊲⊳ρ,ϕ(s⋉ϕt)); (8)(r∼ϕs)∪t= (r∪t)∼ϕ (s∼ϕt);
(9)r∪(s∼ϕt) = (r∪s)∼ϕ(t∼ϕ(r⋉ϕs)); (10)(r∼ϕs)∼ϕt=r∼ϕs∼ϕt;
(11)r∼ϕ(s∼ϕ t) = (r∼ϕ s)∪(r⋉ϕ(s⋉ϕt))
B. Data Integration Expression
In order to achieve an optimal integration solution, the
global query expressionis decomposed into a number of sub-expressions where remote sites do part of computations, and the central site integrates their results to produce a final result. Borrow from [10], query decomposition and data integration expression is formally defined in definition 2 and 3.
Definition 2: Query decomposition is as a process, that transforms aglobal query expressione(x1, . . . , xn)into an ex-pressionf(q1, . . . , qk)where for alli= 1, . . . , k,qi=ei(xi1,
. . . ,xij),{xi1, . . . ,xij} ⊆ {x1, . . . , xn},xi1, . . . ,xij point
to the same remote site, andqi, qj might be sent to the same remote site. Results of processing off(q1, . . . , qk)are identical with the results of processing ofe(x1, . . . , xn).
Definition 3: Letf(q1, ..., qk)be a result of decomposition of e(x1, . . . , xn). Let Di be a result of processing qi at a remote site for i = 1, . . . , k. A data integration expression
f(D1, ..., Dk) is an expression obtained from f(q1, . . . , qk) by a systematic replacement of the symbols q1, . . . , qk with the data containerD1, . . . , Dk.
To simplify the idea of creatingincrement expression, we assume that a data container Diexists in a single occurrence in a data integration expression.
C. Increment Expression
Data integration expression generated from the earlier step must be transformed into a form to allow instant computation when an increment of a data container arrives at the central site. We consider a data increment (δ) as a complete XML document and leave increment of fragmented document for the future work. Let δij be an increment of a data container
Di, then a data container is formed asDi=δi1∪δi2∪. . .∪δin.
In this work a data integration operation is aunionoperation.
Definition 4: Let Di be a data container, δi be an in-crement data of Di, and Ma = ha(D1, . . . , Dk) : a =
1, . . . , j be a set of intermediate materializations. Increment expression gi(δi, M1, . . . , Mj) is an expression to compute an increment data (δi) against intermediate materializations. gi has a form of left/right deep expression such that gi = gij(. . .(gi2(gi1(δi, M1), M2), . . .), Mj).gij operates on XML
operators, i.e. join, antijoin,semijoinandunion. In a special case,Macan be an identity function of any data containerDa.
Theorem 1: Any data integration expression f(D1,
. . . , Di∪δi, . . . , Dk)can be always transformed into one of equivalent expressions:
f(D1, . . . , Di, . . . , Dk)∪gi(δi, M1, . . . , Mj) (1) f(D1, . . . , Di, . . . , Dk)∼gi(δi, M1, . . . , Mj) (2)
Proof: Fork = 1, an expression f operates on a unary operator. Then according to the rule (1), f(D1 ∪ δ1) = f(D1) ∪ g(δi) is true; For k = 2, an expression f is operated on binary operators. Then according rules (2)-(3), transformation of f(D1, Di∪δi)into f(D1, Di)∪g(δi, D1) orf(D1, Di)∼g(δi, D1)is true; Assume forkdata containers f(D1, . . . , Di∪δi, . . . , Dk)can be transformed into expression (1) or (2). Letf(D1, . . . , Di∪δi, . . . , Dk+1)be an extension off(D1, . . . , Di∪δi, . . . , Dk)with a data containerDk+1by operator of∪, ⊲⊳,or∼.
We extend an expression f(D1, . . . , Di∪δi, . . . , Dk)with a
union (∪) operator where f(D1, . . . , Di∪δi, . . . , Dk)is the first argument andDk+1 is the second argument. The expres-sionf(D1, . . . , Di∪δi, . . . , Dk)is transformed as follows: =f(D1, . . . , Di∪δi, . . . , Dk)∪Dk+1
=(f(D1, . . . , Dk)∪g(δi, M1, . . . , Mj))∪Dk+1, (rule 2) =(f(D1, . . . , Dk)∪Dk+1)∪g(δi, M1, . . . , Mj)
=f(D1, . . . , Dk+1)∪g(δi, M1, . . . , Mj)
Since Ma =ha(D1, . . . , Dk) : a = 1, . . . , j, we are able to formM′
a=h′a(D1, . . . , Dk+1) :a= 1, . . . , j. Then: =f(D1, . . . , Dk+1)∪g(δi, M1′, . . . , Mj′)
The same steps can be applied to prove extension of f(D1, . . . , Di∪δi, . . . , Dk) with a data container Dk+1 by operator of⊲⊳,and∼.
Transformation of a data integration expression into an increment expression is by an application of distributivity properties, and performed in the following steps:(1)we replace Diin data integration expression withDi∪δi;(2)then, we use rules (1-11) explained earlier to moveδi inside an expression such that it forms an expression (1) or expression (2).
For example, let D1, . . . , D5 be the data containers in an expression f(D1, . . . , D5) = ((D1 ⊲⊳ D2) ⊲⊳ D3) ⊲⊳ (D4 ∼ D5), and δ1 is an increment of data container D1. Transformation of data containers produces:
δ1:f(D1, D2, D3, D4, D5)∪(((δ1⊲⊳ D2)⊲⊳ D3)⊲⊳ M3); δ2:f(D1, D2, D3, D4, D5)∪(((D1⊲⊳ δ2)⊲⊳ D3)⊲⊳ M3); δ3:f(D1, D2, D3, D4, D5)∪((M1⊲⊳ δ3)⊲⊳ M3); δ4:f(D1, D2, D3, D4, D5)∪(M2⊲⊳(δ4∼D5)); δ5:f(D1, D2, D3, D4, D5)∼δ5.
Therefore we get g1 = (((δ1 ⊲⊳ D2)⊲⊳ D3) ⊲⊳ M3)where M3= (D4∼ D5),g2 = (((D1 ⊲⊳ δ2)⊲⊳ D3)⊲⊳ M3), g3 = ((M1⊲⊳ δ3)⊲⊳ M3), g4 = (M2 ⊲⊳(δ4 ∼D5)) andg5 =δ5 whereM1= (D1⊲⊳ D2), M2= (M1⊲⊳ D3).
Figure 2(c) shows an example of increment processingδ1 in a form of a syntax tree. Results of processing an increment expressiong1 is combined with previous final materialization f(D1, D2, D3, D4, D5)to get a new state of processing.
At the end of transformation process we get a number of increment expressions{g1, . . . , gk}and a list of intermediate materializations {M1, . . . , Mj} to compute increment data. Since an intermediate materialization (Mi) is a result of computations of a data integration expressionha(D1, . . . , Dk), then updating an intermediate materializations is performed in exactly the same way.
D. Online Integration Plans
In the next step, an online integration plan is generated for every increment expression from the earlier stage.
Definition 5: LetDibe a data container,Ma:a= 1. . . j be a set of materializations.gix : x = 1, . . . j is a series of
computation for increment expressiongi(δi, M1, . . . , Mj), and di is a plan to computegi.ps : s= 1, . . . , m is a sequence of steps where in each step a simple expression is evaluated. Eachps might be associated with eithergix, a data container
update, or a materialization update. Anonline integration plan
ofDiis defined asdi:p1;. . .;pmwhereps:s= 1, . . . , mis evaluated to accomplish increment operation by passing result from one to the next step.
An online integration plandiis generated in the following steps: (1)stepp1 is created to update data container Di.(2) then, a step ps is created for every gix : x = 2, . . . , j of
the increment expression; (3) next, we add a step pm+1 to combine the last result of the increment computation to the final materialization (Me);(4)last, we update all intermediate materializations affected by performing the same procedure to all Ma = ha(D1, . . . , Dk), but without data container and materializations updates.
In example above, transformation of an increment expres-siong1 creates the following online integration plan:
d1:D1= (D1∪δ1);δd1= (δ1⊲⊳ D2);δd2= (δd1⊲⊳ D3);
δd3= (δd2 ⊲⊳ M3);Me= (Me∪δd3);M1= (M1∪δd1).
IV. SCHEDULING OFONLINEINTEGRATIONPLAN
A. Static Scheduling
In static scheduling mode, a single increment received at any data container triggers an execution of integration plan assigned. An integration plan allows any increment data received at the central site to be computed and results a new final state of computation. A static scheduling strategy is performed in the following ways:
pick a plan for corresponding increment data for each step in integration plan di do
load data to main memory if needed perform an algebraic operation if (step=materialization update)
perform writing to a secondary storage
Static scheduling strategy in an online integration plan might create poor performance in several circumstances:
1) At the initial stage. At this stage most of data containers are empty; therefore executing all steps in a corresponding integration plan unlikely gives the correct answer for user query. The most important step to be executed in this stage is updating data container itself;
2) A sequence of increment at data containers. When some increments occur at a single data container, update to intermediate materializations are unnecessary as the cor-responding materialization will not in use for next com-putation. Increment results are kept in a temporary list; 3) At the ending stage. At this stage most data containers are
completed. Then, updating intermediate materialization can be ignored if we identify the particular materialization will not participate in any further computation.
B. Dynamic Scheduling
Dynamic scheduling in this paper eliminates inefficiency of static scheduling described earlier. We employ a monitoring system (Fig. 1) to continuously collect behavior of increment data, data container and materializations. The monitoring sys-tem contains of anincrement queue, anintegration controller, amaterialization dependency table,temporary increment lists, and adata container state table.
An increment queue takes responsibility to manage docu-ments received at the central site, and has a role to serialize concurrent increments data. A materialization dependency tablekeeps relationship between intermediate materializations and data containers. The table contains information about which materializations are affected by an increment of a data container, and it determines which data containers includes a particular intermediate materializations in its integration plan. This table is created during the process to generate increment expressions and integration plans.
An integration controllercontains a collection of integra-tion plans for every data container. As a central of dynamic monitoring system, it utilizes all components to decide whether to continue the current plan, skip some steps of the current plan, or terminate the plan.Temporary increment listsare used to keep temporary increment results which later on will be combined to a materialization. A temporary increment list is associated to each of materialization, and will be flushed to the corresponding materialization whenever needed. Meanwhile, a
data container state table is used to determine the status of
data containers. When any data container is completed, the proposed system will identify which materializations can be excluded from materialization update process.
In this paper we assume that the central site is equipped with a single processor, to show the main idea of rescheduling for online integration plan. Any parallel dynamic scheduling algorithm which employs parallel processing such as pipelin-ing, parallel processor, or multi threading is not covered in this discussion, but can be extended by considering dependency between steps in integration plans.
The first consideration is to reduce the number of doc-uments involve in the computation process. In online data integration system an increment expression can be union -ed (∪) orantijoin-ed (∼) with previous final materialization (see expression 1 and 2), where processing of increment data which has increment expression is in the second form (∼) may potentially reduce the number of documents in the computation results. By giving a higher priority in process-ing increments which have such form, we might potentially increase the performance of online integration system. Using the previous example, D5 is a data container which its in-crement data forms an inin-crement expression in the second form (f(D1, D2, D3, D4, D5) ∼ δ5). Meanwhile, the other data containers possess increment expressions in the first form. Then, all increment data fromD5will have the highest priority to be executed.
Then, we minimize materialization update by management of increment processing. Every incoming increment data at a central site is labeled to identify its associated data container. Data containers with higher data arrival rate will get increment data more often than the lower data arrival rate. Letδi andδj be a sequence of increment data, whereδiarrives at the central site beforeδj. Two consecutive increments might have three possible conditions as follows:
1) Both increments (δi andδj) occur at a single data con-tainer. For example, both increments are associated with a data container D1, whereδi=δ11 andδj = δ12. For further discussion, it is named as sequence with Type 1. 2) Both increments occur at different data containers (Di, Dj), and the data containers form an expression of an intermediate materializationha(Di, Dj). For example, based on data integration expression in Figure 2 (c), δi is an increment of data containerD1(e.g. δ11) andδj is an increment of data containerD2(e.g.δ21). Intermediate materializationM1is computation result of an expression ha(D1, D2) = (D1⊲⊳ D2). This is increment in Type 2. 3) Both increments occur at different data containers (Di, Dj), and computation of increment dataδj requires an updated materialization which involves data container Di. In the example Figure 2 (c),δi can be the increment of data containerD1(e.g.δ11) andδjis increment at data containerD3, D4orD5. Ifδjis at data containerD3(e.g. δ31), then materializationM1needs to be updated before computation of increment δ31 is initiated. For further discussion, it is named as Type 3.
We propose a dynamic scheduling based onsliding window
1) we collect a set of increment data from asliding window; 2) then, we give a highest priority for all data containers where their increment expressions are in the second form (see expression 2). Increment data from these data containers will be scheduled at the first rows. If there exists increment data from more than one of these data containers, increment data that appears most often will have higher priority;
3) next, we select increment data at data container that appears most often among all data containers in the currentsliding window;
4) last, the next increment data is determined by the current increment data. We choose the next increment data which satisfies type 1, followed by increment data in type 2, and the rest of increment data will have the least priority. We repeat step 3 until all increment data insliding window
are scheduled.
For example, let a sequence of increment δ11 ← δ12 ← δ21 ← δ31 ← δ41 ← δ51 arrive at the central site in an integration expression as in Figure 2 (c). Suppose, all increment data fit the size of asliding window. Then, priority labeling and sorting produce a sequence of increment data δ51←δ41←δ11←δ12←δ21←δ31.
Dynamic scheduling system proposed reduces materializa-tion updates bytermination of plan, and delayof plan. Ter-mination of plan is removing unneeded steps of computation when the current step has no impact to the rest of plan. For an example, in online integration di, when computation of
(δ1⊲⊳ D2)result nothing, then the rest steps of plandi can be eliminated, and plandi is terminated.
Delayof plan is employed to defer materialization updates if the corresponding materialization is not involved in next plan. By defer of plan, we collect the result of increments in a list and perform materialization update only when it is necessary. The delayed update will be flushed when the corresponding materialization takes place in the next integra-tion plan. Algorithm 1 shows a generic dynamic scheduling algorithm.
Algorithm 1:Dynamic scheduling system
1 while(not empty queue)do
2 Get increment data from asliding window; 3 Sort increment data based on their priority; 4 foreach(sorted increment data)do
5 Prepare online integration plan; 6 foreach(steppiin integration plan)do
7 if(piis a materialization (Mi) update &Miis not used by next plan)then
8 Defer steppi;
else
9 Execute steppi; 10 if(pihas no result)then
11 Terminate rest steps of current plan;
end end end end
12 Slide to the nextsliding window;
end
Using a sequence of increment data described earlier, dynamic scheduling will perform in the following steps:
1) every increment data is labeled and sorted by their prior-ity, and gives us:δ51←δ41←δ11←δ12←δ21←δ31;
2) δ51: after updatingD5, the monitoring system identifies thatD4is empty. Then, anearly terminationis performed; 3) δ41: all prepared plan are executed including
materializa-tion update, because the next increment occurs atD1; 4) δ11, δ12: processing integration plan for increment δ11
andδ12 will perform all prepared steps, except material-ization update as next consecutive increment is atD1; 5) δ21: all prepared plan are executed;
6) δ31: all prepared plan are executed exceptM2update, as D4andD5are completed andM2will be unused.
At theending stageof online data integration, we consider
permanent termination of increment data. Permanent
termi-nation is a process to cancel all running plan and stop the current online integration process when any new increment has no impact to the final result. For example, letD4 andD5 in Fig. 2c are completed and computation of (D4∼D5) returns nothing. Then, computation of any increment at D1, D2, and D3 produces nothing as the final result. In this case, dynamic scheduling allows termination of the current plan, and terminates current integration process.
An increment data which has been processed is removed from the current sliding window. Then, dynamic scheduling system allows sliding window to slide and collect a new increment data. The process of labeling and sorting is repeated with new increment data in a newsliding window. Sorting the currentsliding windowwith a new increment data will be much easier because data in previoussliding windowhas been sorted.
It may happen that a significant delay can exists between arrivals of increment data. Dynamic scheduling performance might fall to the static scheduling performance if all steps in an integration plan are executed before a new increment arrives. Dynamic scheduling might employs statistical information of the previous increments to predict the next likely increment to occur. Then, the decision to continue or defer materialization update can be made. In this paper we assume that delay between arrival of increment data is relatively small.
V. EVALUATION OFONLINEINTEGRATIONPLANS
Online integration performance is defined by decompo-sition strategy and online integration plans. Performance of decomposition strategy is measured by processing cost at central and remote resources, and communication cost to bring data to the central site [10]. Meanwhile, performance of online integration plans based on the utilization of materialization at the central site where integration process is performed.
Performance of online integration plans is determined at a central site and measured by a total cost function:
CT = m
j=1
(CPj+CIj) (3)
whereCPj andCIj represent CPU cost and I/O cost of a single
step pj in an online integration plan respectively. Although CPU time is typically ignored, it is important to measureCPj
tree is|P|=n, then the worst case time complexity of pattern tree matching isO(m∗n).
Stepps mostly operate on an increment data against a data container or materialization. After processing online integra-tion in a period of time, the size of materializaintegra-tions grows and significantly larger than increment data. Increment data and data containers are fit enough to reside in transient memory, whereas materializations which normally have a huge size, will reside in a secondary storage. For step ps that compute an increment data against a data container, no I/O cost is needed because no access to a secondary storage needed.
For step ps which compute an increment data against a materialization, I/O cost to read materializations from a secondary storage is the main cost component. CPU cost can be ignored because it is much smaller than I/O cost. Since processing materialization data is critical, implementation of physical XML algebra operations is an important factor. In general, steppsoperate on two arguments where an argument (increment) is smaller than the other (materialization). In such condition when increment data fits in the main memory, implementation of block-nested loop for binary operations of XML algebra is preferable. Block-nested loop allows us to force the increment data as the outer loop, and then it is computed with a block of materialized document as the inner loop. In a few cases where increment getting larger (e.g. ps = Mi ∼ δ), implementation of block-nested loop significantly increase I/O cost if materialization and increment results do not fit in the transient memory, and a secondary storage is employed to store the increment results.
The last type ofps is an operation to update materializa-tions. At least one materialization update exists in an online integration plan, which is updating a final materialization. If a materialization update is performed using aunionoperation (equation 1), then increment results (δj) are appended to a secondary storage where the materialization is stored. I/O cost to update materialization byunionoperation is determined by the number of block B(δdij)to be appended to a secondary
storage. When materialization update is in the form ofantijoin
operation (equation 2), then I/O cost is determined by the cost model described earlier with an additional I/O cost to write the increment results to a secondary storage.
I/O cost is generally more expensive than CPU cost, therefore dynamic scheduling is employed to eliminate un-necessary materialization updates in order to minimize the costs. Materialization update can be postponed by collecting increment results to be integrated in a list. Whenever the materialization (Mi) is included in the next online integration plan, operation to update materialization is triggered and Mi will be updated with a corresponding list of increment results.
VI. CONCLUSIONS ANDFUTUREWORK
Dynamic scheduling system proposed in this paper opti-mizes the online integration of semistructured data by remov-ing unnecessary computations in the runnremov-ing phase. Increment data arrived in an online integration system is assigned to an online integration plan which is a sequence of simple expression evaluations over increment data and materialization. Effectiveness of an online integration plan is measured by a cost model which involves CPU costs to compute operations,
and I/O costs for accessing materialization. At the initial state of integration, the ending state of integration, and consecutive increments, executing all sequence of online integration plan is unnecessary and cost ineffective. The system is able to stop the plan when there is no increment result to pass to the next operation, but enable to update intermediate materialization if needed. Based on atree-based algebra generalizing the rela-tional algebra, this system is applicable to online integration systems which based on relational model.
During a decomposition process, it may happen that a data containerDishows as multiple arguments in a data integration expression. In this case, increment processing is performed for each argumentDi serially, such that one argument Di is computed at a time, and otherDiarguments are considered as different data containers. It is a challenge to work on increment of document fragments in our work.
VII. ACKNOWLEDGMENTS
This work is supported by Directorate General of Higher Education (Dikti), Indonesian Ministry of National Education.
REFERENCES
[1] L. Bouganim, F. Fabret, C. Mohan, and P. Valduriez, “Dynamic query scheduling in data integration systems,” in Data Engineering, 2000. Proceedings. 16th International Conference on, 2000, pp. 425–434. [2] Handoko and J. R. Getta, “An XML algebra for online processing of
XML documents,” in The 15th International Conference on Information Integration and Web-based Applications & Services, IIWAS ’13, Vienna - December 2-4, 2013.
[3] W. May, “Logic-based XML data integration: a semi-materializing approach,” Journal of Applied Logic, vol. 3, no. 2, 2005, pp. 271 – 307. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1570868304000618 [4] W. Viyanon, S. Madria, and S. Bhowmick, “XML data integration
based on content and structure similarity using keys,” in On the Move to Meaningful Internet Systems: OTM 2008, ser. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2008, vol. 5331, pp. 484–493. [Online]. Available: http://dx.doi.org/10.1007/978-3-540-88871-0 35
[5] A. Poggi and S. Abiteboul, “XML data integration with identification,” in Database Programming Languages, ser. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2005, vol. 3774, pp. 106–121. [Online]. Available: http://dx.doi.org/10.1007/11601524 7
[6] L. Fegaras, “Incremental maintenance of materialized XML views,” in Database and Expert Systems Applications, ser. Lecture Notes in Computer Science, A. Hameurlain, S. Liddle, K.-D. Schewe, and X. Zhou, Eds. Springer Berlin Heidelberg, 2011, vol. 6861, pp. 17–32. [Online]. Available: http://dx.doi.org/10.1007/978-3-642-23091-2 2 [7] A. Bonifati, M. Goodfellow, I. Manolescu, and D. Sileo, “Algebraic
incremental maintenance of XML views,” ACM Trans. Database Syst., vol. 38, no. 3, Sep 2013, pp. 14:1–14:45. [Online]. Available: http://doi.acm.org.ezproxy.uow.edu.au/10.1145/2508020.2508021 [8] M. EL-Sayed, L. Wang, L. Ding, and E. A. Rundensteiner, “An
algebraic approach for incremental maintenance of materialized XQuery views,” in Proceedings of the 4th International Workshop on Web Information and Data Management, ser. WIDM ’02. New York, NY, USA: ACM, 2002, pp. 88–91. [Online]. Available: http://doi.acm.org.ezproxy.uow.edu.au/10.1145/584931.584950 [9] T. Urhan, M. J. Franklin, and L. Amsaleg,
“Cost-based query scrambling for initial delays,” SIGMOD Rec., vol. 27, no. 2, Jun. 1998, pp. 130–141. [Online]. Available: http://doi.acm.org.ezproxy.uow.edu.au/10.1145/276305.276317 [10] Handoko and J. R. Getta, “Query decomposition strategy for integration