7
Bab 2
Tinjauan Pustaka
2.1
Penelitian Sebelumnya
Berbagai penelitian yang menerapkan algoritma ID3 (Iterative
Dichotomizer Three) sebagai metode perhitungannya telah banyak
dilakukan. ID3 (Iterative Dichotomizer Three) digunakan sebagai
perhitungan untuk menggambarkan pohon keputusan yang
digunakan sebagai acuan dalam penentuan penerima beasiswa
mahasiswa yang sesuai dengan ketentuan yang berlaku. Penelitian
tersebut merupakan perbandingan antara perhitungan menggunakan
ID3 (Iterative Dichotomizer Three) dan AHP (Analytic Hierarcy
Process). Atribut yang digunakan pada penelitian tersebut antara
lain IPA (Indeks Prestasi Akademik), wawancara, latar belakang
ekonomi serta rekomendasi wali studi. Setelah pengujian selesai
dilakukan, dapat diketahui perbedaan prioritasnya. Dalam
perhitungan ID3 (Iterative Dichotomizer Three) atribut yang
menentukan adalah atribut IPK sedangkan dalam perhitungan AHP
(Analytic Hierarcy Process) atribut yang menjadi prioritas adalah
latar belakang ekonomi. Namun terdapat persamaan yaitu atribut
terendah atau yang menjadi priorotas terendah adalah atribut
rekomendasi wali studi (Lee, 2010).
Penelitian mengenai pemilihan dosen penguji juga pernah
dilakukan dengan mencari hubungan melalui beberapa atribut yang
berpengaruh dalam pemilihan dosen penguji berdasarkan keterkaitan
mata kuliah dan kesesuaian jadwal. Dengan menggunakan banyak
atribut diharapkan dapat memberikan hasil yang maksimal dalam
menentukan dosen penguji serta dapat hadirnya dosen pembimbing
maupun dosen penguji pada saat pengujian dilaksanakan (Dhiwi,
2009).
Aplikasi pemilihan dosen penguji dan penjadwalan ujian
skripsi yang dibuat di Universitas Kristen Satya Wacana tersebut
mampu menyusun jadwal, mengatur dosen penguji dan memetakan
jadwal, namun ada beberapa hal yang masih harus diperbaiki yaitu
dalam hal pemilihan dosen penguji masih dilakukan secara manual
dengan melihat jadwal dari para dosen.
Pada penelitian ini, algoritma ID3 (Iterative Dichotomizer
Three) akan digunakan dalam menentukan pohon dalam pemilihan
dosen pembimbing yang sesuai dengan topik yang diambil
mahasiswa. Pada sistem hanya akan memiliki satu hak akses saja
dikarenakan hanya KPTA saja yang memiliki wewenang dalam hal
ini. Sedangkan mahasiswa hanya dapat melakukan pencarian dosen
pembimbing skripsi tanpa harus login atau mencantumkan
identitasnya seperti nama dan NIM.
2.2
Penentuan Dosen Pembimbing Skripsi di FTI,
UKSW
Skripsi merupakan tugas akhir mahasiswa untuk memperoleh
gelar akademisnya. Skripsi akan dibimbing oleh dua dosen
pembimbing yang memiliki keterkaitan dengan topik skripsi
tersebut. Misal mahasiswa dengan minat pengembangan Sistem
memiliki minat dibidang Sistem Cerdas dan Mobile, agar di saat
mahasiswa tersebut menemukan kendala saat pengerjaan dapat
terbantu dengan solusi yang diberikan pembimbingnya. Pembimbing
1 harus merupakan dosen dengan pendidikan terakhir minimal S2,
sedangkan pembimbing 2 merupakan dosen dengan pendidikan
terakhir S1 dengan tingkat kepangkatan yang lebih tinggi (misal
lektor, asisten ahli).
Untuk menentukan dosen pembimbing, melalui beberapa
tahap. Tahap seleksi awal ditentukan dengan mengklasifikasikan
proposal yang diajukan berdasarkan bidang pengembangan (misal:
Algoritma Pemrograman dan Database, Jaringan Komputer, Mobile
Application dan lain- lain). Tahap selanjutnya koordinator KPTA
menyerahkan proposal yang masuk kepada koordinator
masing-masing bidang pengembangan. Masing-masing bidang
pengembangan melakukan rapat guna menentukan proposal mana
yang layak diterima maupun ditolak. Setelah tahap ini selesai,
dilakukan rapat dengan seluruh staff pengajar guna menentukan
dosen pembimbing yang sesuai dengan topik yang telah diterima.
Apabila telah dicapai kesepakatan antara dosen untuk membimbing
mahasiswa dengan topik tersebut, maka dosen dapat melakukan
proses bimbingan dengan mahasiswa yang bersangkutan.
2.3
Sistem Pendukung Keputusan
2.3.1 Pengertian SPK
Konsep Sistem Pendukung Keputusan (SPK) / Decision
Support Sistem (DSS) pertama kali diungkapkan pada awal tahun
1970-an oleh Michael S. Scott Morton dengan istilah Management
berbasis komputer yang ditujukan untuk membantu pengambilan
keputusan dengan memanfaatkan data dan model tertentu untuk
memecahkan berbagai persoalan yang tidak terstruktur.
DSS sebagai “sekumpulan prosedur berbasis model untuk data pemrosesan dan penilaian guna membantu para manager mengambil keputusan”. Untuk dapat meraih kesuksesan, sistem tersebut haruslah sederhana, cepat, mudah dikontrol, adaptip, lengkap dengan
isu- isu penting, dan mudah berkomunikasi (Little, 1970).
Definisi klasik lainnya untuk Decision Support Sistem (DSS)
yaitu : Sistem Pendukung Keputusan memadukan sumber daya
intelektual dari individu dengan kapabilitas komputer untuk
meningkatkan kualitas keputusan (Keen dan Scott Morton, 1978).
2.3.2 Karakteristik dan manfaat
Karakteristik sistem pendukung keputusan:
Sistem Pendukung Keputusan dirancang untuk membantu
pengambil keputusan dalam memecahkan masalah yang
sifatnya semi terstruktur ataupun tidak terstruktur dengan
menambahkan kebijaksanaan manusia dan informasi
komputerisasi.
Dalam proses pengolahannya, sistem pendukung keputusan
mengkombinasikan penggunaan model-model analisis dengan
teknik pemasukan data konvensional serta fungsi-fungsi
pencari / interogasi informasi.
Sistem Pendukung Keputusan, dirancang sedemikian rupa
Sistem Pendukung Keputusan dirancang dengan menekankan
pada aspek fleksibilitas serta kemampuan adaptasi yang tinggi
(Kadarsah, 2002).
Dengan berbagai karakter khusus diatas, SPK dapat
memberikan berbagai manfaat dan keuntungan. Manfaat yang dapat
diambil dari SPK :
SPK memperluas kemampuan pengambil keputusan dalam memproses data / informasi bagi pemakainya.
SPK membantu pengambil keputusan untuk memecahkan
masalah terutama berbagai masalah yang sangat kompleks dan
tidak terstruktur.
SPK dapat menghasilkan solusi dengan lebih cepat serta
hasilnya dapat diandalkan.
Walaupun suatu SPK, mungkin saja tidak mampu
memecahkan masalah yang dihadapi oleh pengambil
keputusan, namun SPK dapat menjadi stimulan bagi
pengambil keputusan dalam memahami persoalannya, karena
mampu menyajikan berbagai alternatif pemecahan (Kadarsah,
2002).
2.3.3 Komponen SPK
Sebuah sistem pendukung keputusan terdiri dari beberapa
subsistem (Turban, 2005), antara lain :
a. Subsistem manajemen data, meliputi basis data yang
mengandung data yang relevan dengan keadaan yang ada dan
dikelola oleh sebuah sistem yang dikenal sebagai database
b. Subsistem manajemen model, yaitu sebuah paket perangkat
lunak yang berisi model-model finansial , statistik, management
science, atau model kuantitatif yang lain yang menyediakan
kemampuan analisis sistem dan management software yang terkait.
c. Subsistem manajemen pengetahuan (knowledge) yaitu
subsistem yang mampu mendukung subsistem yang lain atau
berlaku sebagai sebuah komponen yang berdiri sendiri.
d. Subsistem antarmuka pengguna (User Interface), yang
merupakan media tempat komunikasi antara pengguna dan sistem
pendukung keputusan serta tempat pengguna memberikan perintah
kepada sistem pendukung keputusan (Anonim, 2007).
2.4
Algoritma
Iterative Dichotomizer Three
(ID3)
Iterative Dichotomizer Three (ID3) merupakan suatu algoritma
matematika yang digunakan untuk menghasilkan suatu pohon
keputusan yang mampu mengklasifikasi suatu objek, ID3
diperkenalkan pertama kali oleh Ross Quinlan (1979). Aturan-aturan
yang dihasilkan oleh ID3 mempunyai hubungan yang hierarkis
seperti suatu pohon (mempunyai akar, titik, cabang, dan daun)
(Gunawan, 2007).
Algoritma ID3 membentuk pohon keputusan dengan cara
pembagian dan menguasai sampel secara rekursif dari atas ke
bawah. Algoritma ID3 dimulai dengan semua data yang ada sebagai
akar dari pohon keputusan, sebuah atribut yang dipilih akan menjadi
pembagi dari sampel tersebut. Untuk setiap atribut dari cabang yang
atribut cabang akan masuk dalam anggotanya dan dinamakan anak
cabang (Nugroho, 2007).
Iterative Dichotomizer 3 (ID3) merupakan sebuah metode
yang digunakan untuk membangkitkan pohon keputusan. Algoritma
pada metode ini berbasis pada Occam’s razor, lebih memilih pohon
keputusan yang lebih kecil (teori sederhana) dibanding yang lebih
besar. Tetapi tidak dapat selalu menghasilkan pohon keputusan yang
paling kecil dan karena itu occam’s razor bersifat heuristic, Occam’s razor diformalisasi menggunakan konsep dari entropi informasi (Setiawan, 2009).
Dasar dari algoritma ini mengasumsikan bahwa tidak ada
noise di domain, mencari untuk menjelaskan konsep untuk
mengklasifikasikan data uji secara sempurna. Namun, aplikasi pada
dunia nyata domain membutuhkan metode untuk menangani data
noise. Pada kenyataannya, dibutuhkan sebuah mekanisme yang
untuk mendeskripsikan konsep induksi data, dan ini memerlukan
kendala lemah bahwa deskripsi induksi harus mengklasifikasikan
data uji dengan sempurna (Clark dan Niblett, 1989).
Konsep perhitungan dalam algoritma ID3 adalah menentukan
objek yang akan dijadikan sebagai atribut utama. Semua objek yang
ada dihitung nilai kemungkinannya terlebih dahulu, dari perhitungan
tersebut diketahui mana objek yang memiliki nilai atribut paling
tinggi yang kemudian dijadikan sebagai atribut utama. Berikut
adalah langkah – langkah dalam algoritma ID3 : (Suyanto, 2007) Buat simpul Root
If Kumpulan Atribut kosong, Return pohon satu simpul Root
dengan label=nilai atribut target yang paling umum (yang
paling sering muncul)
Else
A <--- Atribut yang merupakan best classifer (dengan
information gain terbesar)
Atribut keputusan untuk Root <--- A
For vi (setiap nilai pada A)
Tambahkan suatu cabang di bawah Root sesuai
dengan nilai vi
Buat suatu variabel, misal Sampelvi, sebagai
himpunan bagian (subset) dari kumpulan sampel yang
bernilai vi pada atribut A
If Sampelvi kosong
* THEN di bawah cabang ini tambahkan suatu simpul daun
(leaf node, simpul yang tidak punya anak di bawahnya)
dengan label=nilai atribut target yang paling umum(yang
paling sering muncul)
* ELSE di bawah cabang ini tambahkan subtree dengan
memanggil fungsi ID3 (Sampelvi,, AtributTarget,
Atribut-{A})
End
End
Adapun sample data yang digunakan oleh ID3 memiliki beberapa
syarat, yaitu:
Deskripsi atribut-nilai. Atribut yang sama harus
mendeskripsikan tiap contoh dan memiliki jumlah nilai yang
sudah ditentukan.
Kelas yang sudah didefinisikan sebelumnya. Suatu atribut contoh harus sudah didefinisikan, karena mereka tidak
dipelajari oleh ID3.
Kelas-kelas yang diskrit. Kelas harus digambarkan dengan
jelas. Kelas yang kontinu dipecah-pecah menjadi
kategori-kategori yang relatif, misalnya saja metal dikategori-kategorikan menjadi “hard, quite hard, flexible, soft, quite soft”.
Jumlah contoh (example) yang cukup. Karena pembangkitan induktif digunakan, maka dibutuhkan test case yang cukup
untuk membedakan pola yang valid dari peluang suatu
kejadian. Pemillihan atribut pada ID3 dilakukan dengan
properti statistik, yang disebut dengan information gain. Gain
mengukur seberapa baik suatu atribut memisahkan training
example ke dalam kelas target. Atribut dengan informasi
tertinggi akan dipilih. Dengan tujuan untuk mendefinisikan
gain, pertama-tama digunakanlah ide dari teori informasi yang
disebut entropi. Entropi mengukur jumlah dari informasi yang
ada pada atribut.
Rumus Entropy Informasi dituliskan dalam persamaan 2.1 (Mitchell,
Keterangan :
S adalah ruang (data) sampel yang digunakan untuk training.
P+ adalah jumlah yang bersolusi positif (mendukung) pada data
sampel untuk kriteria tertentu.
P- adalah jumlah yang bersolusi negatif (tidak mendukung)
pada data sampel untuk kriteria tertentu.
Catatan:
Entropy(S) = 0, jika semua contoh pada S berada dalam kelas yang
sama.
Entropy(S) = 1, jika jumlah contoh positif dan jumlah contoh negatif
dalam S adalah sama.
0 < Entropy(S) < 1, jika jumlah contoh positif dan negatif dalam S
tidak sama.
Gambar 2.1 Grafik Fungsi Entropy Untuk Kumpulan Data Dalam 2 Kelas
Rumus menghitung Gain ditunjukkan dalam persamaan 2.2
Values(A) : himpunan yang mungkin untuk atribut A
|Sv| : jumlah sampel untuk nilai v
|S| : jumlah seluruh sampel data
Entropy(Sv): entropy untuk sampel-sampel yang memilki nilai v
2.5
Model View Control
(MVC)
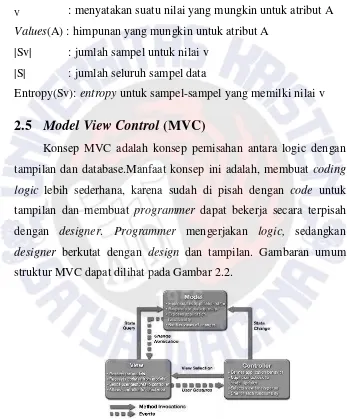
Konsep MVC adalah konsep pemisahan antara logic dengan
tampilan dan database.Manfaat konsep ini adalah, membuat coding
logic lebih sederhana, karena sudah di pisah dengan code untuk
tampilan dan membuat programmer dapat bekerja secara terpisah
dengan designer. Programmer mengerjakan logic, sedangkan
designer berkutat dengan design dan tampilan. Gambaran umum
struktur MVC dapat dilihat pada Gambar 2.2.
Gambar 2.2 Arsitektur MVC (Model View Control) (Jeni, 2009)
Model mencakup semua proses yang terkait dengan
pemanggilan struktur data baik berupa pemanggilan fungsi, input
processing atau mencetak output ke dalam browser.
View
View mencakup semua proses yang terkait layout output. Bisa
dibilang untuk menaruh template interface website atau aplikasi.
Layer ini mengandung keseluruhan detail dari implementasi user
interface. Disini, komponen grafis menyediakan representasi proses
internal aplikasi dan menuntun alur interaksi user terhadap aplikasi.
Tidak ada layer lain yang berinteraksi dengan user, hanya View
(Jeni, 2009).
Controller
Controller mencakup semua proses yang terkait dengan
pemanggilan database dan kapsulisasi proses-proses utama. Jadi
semisal di bagian ini ada file bernama member.php, maka semua
proses yang terkait dengan member akan dikelompokan dalam file