7 BAB II
TINJAUAN PUSTAKA
2.1 Pengertian Pendidikan
Ki Hajar Dewantara (Bapak Pendidikan Nasional Indonesia, 1889-1959) menjelaskan tentang pengertian pendidikan yaitu: “Pendidikan umumnya berarti daya upaya untuk memajukan budi pekerti (karakter, kekuatan batin), pikiran dan jasmani anak-anak selaras dengan alam dan masyarakat”.
Menurut Undang-Undang No.20 Tahun 2003 tentang Sistem Pendidikan Nasional menyatakan bahwa pendidikan adalah usaha sadar dan terencana untuk mewujudkan suasana belajar dan proses pembelajaran agar peserta didik secara aktif mengembangkan potensi dirinya untuk memiliki kekuatan spiritual keagamaan, pengendalian diri, kepribadian, kecerdasan, akhlak mulia, serta keterampilan yang diperlukan untuk dirinya, masyarakat, bangsa dan Negara.
2.2 Pengertian Perguruan Tinggi
Menurut Peraturan Pemerintah No.30 tahun 1990 perguruan tinggi adalah organisasi satuan pendidikan, yang menyelenggarakan pendidikan di jenjang pendidikan tinggi, penelitian dan pengabdian kepada masyarakat.
Menurut Hamalik (1983) Perguruan tinggi adalah lembaga pendidikan tinggi. Pada umumnya istilah “Perguruan Tinggi” dapat dinyatakan sebagai lembaga pendidikan tertinggi yang mendidik para calon sarjana dalam bidang keilmuan tertentu. Melalui lembaga ini para mahasiswa dididik untuk menjadi seorang yang ahli, professional dalam suatu ilmu atau suatu bidang keilmuan serta sanggup mengabdikannya guna kepentingan masyarakat dan bangsa.
2.3 Pengertian Mahasiswa
Menurut Sarwono (1978) mahasiswa adalah setiap orang yang secara resmi terdaftar untuk mengikuti pelajaran di perguruan tinggi dengan batas usia sekitar 18-30 tahun. Mahasiswa merupakan suatu kelompok dalam masyarakat yang memperoleh statusnya karena ikatan dengan perguruan tinggi. Mahasiswa juga merupakan calon intelektual atau cendikiawan muda dalam suatu lapisan masyarakat.
Mahasiswa sebagai pelajar perguruan tinggi dituntut untuk belajar dengan cara yang berbeda ketika di sekolah menengah, yang ternyata tidak cukup hanya bersifat reseptif dan reproduktif, tetapi harus cukup mengadakan penelitian, belajar mandiri, mencoba sendiri dan menemukan sendiri. Dengan demikian belajar di perguruan tinggi juga berbeda dengan lingkungan di sekolah menengah, di mana mahasiswa harus lebih intim dan lebih cakap dalam menggunakan sumber-sumber belajar seperti perpustakaan, laboratorium, studi lapangan, diskusi kerja, seminar.
Sehingga diharapkan seorang mahasiswa dapat bersifat objektif, berfikir logis, kritis, sistematis, dan kontruktif (Musnawar, 1979 dalam Hamalik, 1989).
2.4 Prestasi Belajar
Prestasi selalu dihubungkan dengan pelaksanaan suatu kegiatan atau aktivitas. Prestasi belajar merupakan hal yang tidak dapat dipisahkan dari kegiatan belajar, karena kegiatan belajar merupakan proses, sedangkan prestasi belajar merupakan
output dari proses belajar.
Menurut Sukmadinata (2005), prestasi atau hasil belajar (achievement) merupakan realisasi dari kecakapan-kecakapan potensial atau kapasitas yang dimiliki seseorang. Penguasaan hasil belajar dapat dilihat dari perilaku, baik perilaku dalam bentuk penguasaan pengetahuan, keterampilan berpikir maupun keterampilan motorik. Di perguruan tinggi, hasil belajar atau prestasi belajar ini dapat dilihat dari penguasaan mahasiswa akan mata kuliah yang telah ditempuh. Alat untuk mengukur prestasi atau hasil belajar disebut tes prestasi belajar atau achievement test yang disusun oleh dosen yang mengajar mata kuliah yang bersangkutan.
Faktor-faktor yang memengaruhi prestasi belajar dapat berasal dari diri sendiri (faktor internal) dan dari luar dirinya sendiri (faktor eksternal).
2.4.1 Faktor Internal
Adapun faktor internal yang memengaruhi prestasi belajar adalah sebagai berikut:
1. Motivasi kemampuan intelektual
Dari beberapa penelitian, ditemukan adanya korelasi positif dan cukup kuat antara taraf intelegensi dengan prestasi seseorang yaitu berkisar 0,70.
2. Minat
Pada umumnya, seseorang akan merasa senang untuk melakukan sesuatu sesuai dengan minatnya.
3. Bakat
Bakat merupakan kapasitas untuk belajar dan itu baru terwujud kalau sudah mendapat latihan.
4. Sikap
Seseorang akan menerima atau menolak sesuatu berdasarkan penilaiannya pada obyek yang dinilainya berguna atau tidak.
5. Motivasi berprestasi
Semakin tinggi motivasi berprestasi seseorang maka akan semakin baik prestasi yang akan diraihnya.
6. Konsep Diri
Konsep diri menunjukkan bagaimana seseorang memandang dirinya serta kemampuan yang ia miliki. Mahasiswa yang memiliki konsep diri yang positif akan lebih berhasil di Perguruan Tinggi.
7. Sistem Nilai
Sistem ini merupakan keyakinan yang dimiliki seseorang tentang cara bertingkah laku dan kondisi akhir dari yang diinginkannya. Sistem nilai yang dianut dapat memengaruhi gaya hidup dan tindakan seseorang.
2.4.2 Faktor Eksternal
Faktor eksternal adalah faktor-faktor yang dapat memengaruhi prestasi belajar yang sifatnya di luar diri mahasiswa, yaitu beberapa pengalaman-pengalaman, keadaan keluarga, lingkungan sekitarnya dan sebagainya. Pengaruh lingkungan ini pada umumnya bersifat positif dan tidak memberikan paksaan kepada individu. Menurut Slameto (2003) faktor-faktor eksternal yang dapat memengaruhi belajar adalah keluarga, lingkungan kampus dan lingkungan masyarakat.
a. Faktor Keluarga
Keluarga adalah suatu lingkungan yang terdiri dari orang-orang terdekat bagi seorang anak. Banyak sekali waktu dan kesempatan bagi seorang anak untuk berjumpa dan berinteraksi dengan keluarganya. Kondisi yang harmonis dalam keluarga dapat memberikan stimulasi dan respon yang baik dari anak sehingga
prilaku dan prestasinya menjadi baik. Sebaliknya jika keluarga tidak harmonis atau
broken home akan berdampak negatif bagi perkembangan mahasiswa, perilaku dan
prestasi cenderung terhambat, dan akan muncul masalah-masalah dalam perilaku dan prestasinya. Dalam faktor lingkungan keluarga yang sangat perlu diperhatikan adalah suasana rumah, cara orang tua mendidik, fasilitas belajar dan keadaan ekonomi keluarga.
b. Lingkungan Kampus
Kampus merupakan tempat kegiatan dan proses pendidikan berlangsung. Faktor-faktor yang memengaruhi proses belajar mengajar dilingkungan kampus adalah metode mengajar dosen, hubungan mahasiswa dengan dosen, hubungan mahasiswa dengan mahasiswa, keadaan gedung, sarana yang mendukung dilingkungan kampus, metode belajar, dan kurikulum atau sistem pembelajaran.
c. Lingkungan Masyarakat
Masyarakat disekitar mahasiswa sangat berpengaruh terhadap belajar mahasiswa. Masyarakat yang terdiri dari orang-orang yang tidak terpelajar dan mempunyai kebiasaan yang tidak baik akan berpengaruh pada mahasiswa. Mahasiswa akan tertarik untuk berbuat seperti yang dilakukan orang-orang di sekitarnya. Akibatnya belajarnya terganggu dan bahkan anak akan kehilangan semangat untuk belajar karena perhatiannya terpusat kepada pelajaran berpindah ke perbuatan-perbuatan yang selalu dilakukan orang-orang di sekitarnya.
Sebaliknya, jika lingkungan anak adalah orang-orang yang terpelajar yang baik-baik, mereka mendidik dan menyekolahkan anaknya, antusias dengan cita-cita
yang luhur akan masa depan anaknya, anak juga akan terpengaruh ke hal-hal yang dilakukan oleh orang dilingkungannya, sehingga akan berbuat seperti orang-orang yang ada dilingkungannya. Keadaan masyarakat juga menentukan prestasi belajar. bila di sekitar tempat tinggal keadaan masyarakatnya terdiri dari orang-orang yang berpendidikan, terutama anak-anaknya rata-rata bersekolah tinggi dan moralnya baik. hal ini akan mendorong anak lebih giat belajar.
2.5 Uji Chi -Square (Khi-kuadrat, 𝝌𝟐)
Uji Chi-Square (𝜒2) pertama dikembangkan oleh statistika Inggris yang
bernama Karl Pearson. Uji Chi-Square (𝜒2) antara lain dapat digunakan untuk mengetahui hubungan diantara dua variabel tertentu (untuk uji independensi), dalam hal ini variabel yang dimaksud mempunyai skala pengukuran nominal dan ordinal. Jika tidak terdapat hubungan antara variabel-variabel tersebut, bisa dikatakan variabel-variabel tersebut bersifat saling bebas (independen).
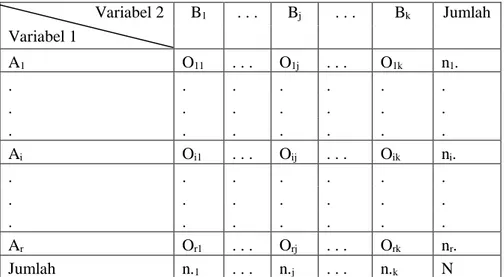
Misalkan suatu variabel pertama memiliki r kategori yaitu A1, A2, . . ., Ar dan variabel kedua memiliki k kategori yaitu B1, B2, . . ., Bk. Banyak pengamatan pada kategori ke-i (i = 1, 2, . . ., r) variabel pertama dan kategori ke-j (j = 1, 2, . . ., k) variabel kedua akan dinyatakan dengan Oij. Hasilnya dapat dilihat dalam sebuah tabel kontingensi r x k sebagai berikut:
Tabel 2.1 Struktur Data Uji Chi Square Variabel 1 Variabel 2 B1 . . . Bj . . . Bk Jumlah A1 O11 . . . O1j . . . O1k n1. . . . . . . . . . . . . . . Ai Oi1 . . . Oij . . . Oik ni. . . . . . . . . . . . . . . . Ar Or1 . . . Orj . . . Ork nr. Jumlah n.1 . . . n.j . . . n.k N Sumber: Usman dan Setiady (2006)
Keterangan:
Oij = Banyaknya pengamatan pada baris ke-i dan kolom ke-j
ni. = Total banyaknya pengamatan pada baris ke-i
n.j = Total banyaknya pengamatan pada kolom ke-j
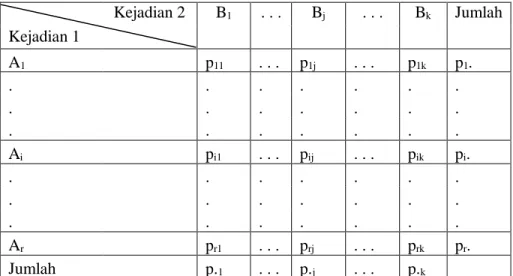
Misalkan peluang kejadian Ai dan Bj adalah pij dengan i = 1, 2, . . ., r dan j = 1, 2, . . ., k, maka peluang kejadian untuk setiap Ai dan Bj dapat disajikan pada Tabel 2.2.
Tabel 2.2 Peluang Kejadian Kejadian 1 Kejadian 2 B1 . . . Bj . . . Bk Jumlah A1 p11 . . . p1j . . . p1k p1. . . . . . . . . . . . . . . Ai pi1 . . . pij . . . pik pi. . . . . . . . . . . . . . . . Ar pr1 . . . prj . . . prk pr. Jumlah p.1 . . . p.j . . . p.k Sumber: Usman dan Setiady (2006)
Keterangan: pij = Peluang kejadian Ai dan Bj
pi. = Peluang total pada baris ke-i
p.j = Peluang total pada kolom ke-j
Rumus peluang kejadian adalah:
𝑃𝑖𝑗 =𝑂𝑖𝑗
𝑁 ; ∀𝑖, ∀𝑗 (2.1)
Nilai harapan untuk masing-masing sel adalah:
𝐸𝑖𝑗 = (𝑛𝑖.)(𝑛.𝑗)
𝑁 ; i = 1, . . . , r dan j = 1, . . . , k (2.2)
Statistik yang digunakan dalam alat uji hipotesis adalah:
𝜒2 = ∑ ∑ (𝑂𝑖𝑗−𝐸𝑖𝑗) 2 𝐸𝑖𝑗 𝑘 𝑗=1 𝑟 𝑖=1 ; i = 1, . . . , r dan j = 1, . . . ,k (2.3)
Dengan:
𝑂𝑖𝑗 = Jumlah individu yang diamati pada baris ke-i dan kolom ke-j
𝐸𝑖𝑗 = Jumlah individu yang diharapkan pada baris ke-i dan kolom ke-j
N = Total banyaknya individu yang diamati
∑ ∑𝑘
𝑗=1 𝑟
𝑖=1 = Jumlah seluruh sel menurut kolom dan baris
Statistik uji 𝜒2 berdistribusi chi-square dengan derajat bebas (r-1)(k-1). Berikut adalah langkah-langkah uji hipotesis chi-square :
1. Hipotesis
H0 : pij = pi. p.j (kedua variabel saling bebas) H1 : pij ≠ pi. p.j (kedua variabel tidak saling bebas)
2. Susun frekuensi-frekuensi pengamatan dalam tabel kontingensi k x r, dengan k kolom untuk kelompok-kelompoknya.
3. Menentukan 𝛼
4. Menentukan daerah penolakan, yaitu 𝜒2 > 𝜒𝛼(𝑟−1)(𝑘−1)2 5. Tentukan nilai frekuensi harapan tiap sel yaitu:
𝐸𝑖𝑗 = (𝑛𝑖.)(𝑛.𝑗) 𝑁 6. Mencari 𝜒2 = ∑ ∑ (𝑂𝑖𝑗−𝐸𝑖𝑗) 2 𝐸𝑖𝑗 𝑘 𝑗=1 𝑟 𝑖=1
7. Menarik kesimpulan
a. Bila 𝜒2 masuk daerah penolakan, maka H
0 ditolak. b. Bila 𝜒2 tidak masuk dalam daerah penolakan, maka H
0 diterima.
2.6 Analisis CHAID (Chi-Squared Automatic Interaction Detection)
Metode CHAID (Chi-Squared Automatic Interaction Detection) pertama kali diperkenalkan pada sebuah artikel yang berjudul “An Exploratory Technique for
investigating Large Quantities of Categorical Data” oleh Dr. G. V. Kass tahun 1980
pada buku Applied Statistics. Teknik tersebut merupakan teknik yang lebih awal dikenal sebagai Automatic Interaction Detection (AID). Metode CHAID secara umum bekerja dengan mempelajari hubungan antara variabel respon dengan beberapa variabel prediktor kemudian mengklasifikasi sampel berdasarkan hubungan tersebut.
Menurut Gallagher (2000), CHAID merupakan suatu teknik iteratif yang menguji satu persatu variabel prediktor yang digunakan dalam klasifikasi, dan menyusunnya berdasarkan pada tingkat signifikansi statistik chi-square terhadap variabel respon. CHAID digunakan untuk membentuk segmentasi yang membagi sebuah sampel menjadi dua atau lebih kelompok yang berbeda berdasarkan sebuah kriteria tertentu. Hal ini kemudian diteruskan dengan membagi kelompok-kelompok tersebut menjadi kelompok yang lebih kecil berdasarkan variabel-variabel prediktor yang lain.
CHAID adalah sebuah metode untuk mengklasifikasikan data kategori yang tujuan dari prosedurnya adalah untuk membagi rangkaian data menjadi subgrup-subgrup berdasarkan pada variabel respon (Lehmann dan Eherler, 2001). Hasil dari pengklasifikasian dalam CHAID akan ditampilkan dalam sebuah diagram pohon.
2.6.1 Variabel-Variabel Dalam Analisis CHAID
Variabel respon dan variabel prediktor dalam analisis CHAID adalah variabel kategorik. Menurut Gallagher (2000), CHAID akan membedakan variabel-variabel prediktor kategorik menjadi tiga bentuk yang berbeda, yaitu:
1. Monotonik
Yaitu variabel prediktor yang kategorinya dapat dikombinasikan atau digabungkan oleh CHAID hanya jika keduanya berdekatan satu sama lain, yaitu variabel-variabel yang kategorinya mengikuti urutan aslinya (data ordinal).
2. Bebas
Yaitu variabel prediktor yang kategorinya dapat dikombinasikan atau digabungkan ketika keduanya berdekatan atau tidak satu sama lain (data nominal). 3. Mengambang (floating)
Yaitu variabel prediktor yang kategori didalamnya dapat diperlakukan seperti monotonik kecuali untuk kategori yang missing value, yang dapat berkombinasi dengan kategori manapun.
2.6.2 Algoritma CHAID
Menurut Magidson dalam Kunto dan Hasana (2006), algoritma CHAID digunakan untuk melakukan penggabungan dan pemisahan kategori-kategori dalam variabel yang akan di analisis. Secara garis besar algoritma ini dapat dibagi menjadi tiga tahap, yaitu penggabungan (merging), pemisahan (splitting), dan penghentian (stopping).
1. Penggabungan (Merging)
Tahap pertama dalam algoritma CHAID adalah penggabungan (merging). Pada tahap ini akan diperiksa signifikansi dari masing-masing kategori variabel prediktor terhadap variabel respon adalah sebagai berikut:
a. Bentuk tabel kontingensi dua arah untuk masing-masing variabel prediktor dengan variabel responnya.
b. Hitung statistik chi-square untuk setiap pasang kategori yang dapat dipilih untuk digabung menjadi satu, untuk menguji kebebasannya dalam sebuah sub tabel kontingensi 2 x J yang dibentuk oleh sepasang kategori tersebut dengan variabel responnya yang mempunyai sebanyak J kategori.
c. Untuk masing-masing nilai chi-square berpasangan, hitung p-value berpasangan bersamaan. Diantara pasangan-pasangan yang tidak signifikan, gabungkan sebuah pasangan kategori yang paling mirip (yaitu pasangan yang mempunyai nilai
chi-square berpasangan terkecil dan p-value terbesar) menjadi sebuah kategori
d. Periksa kembali kesignifikanan kategori baru setelah digabung dengan kategori lainnya dalam variabel prediktor. Jika masih ada pasangan yang belum signifikan, ulangi langkah c. Jika semuanya sudah signifikan lanjutkan kelangkah e.
e. Hitung p-value terkoreksi Bonferroni didasarkan pada tabel yang telah digabungkan.
2. Pemisahan (Splitting)
Tahap pemisahan memilih variabel prediktor yang akan digunakan sebagai split
node (pemisahan node) yang terbaik. Pemisahan dikerjakan dengan membandingkan p-value (dari tahap penggabungan) pada setiap variabel prediktor. Langkah
pemisahan adalah sebagai berikut:
a. Pilih variabel prediktor yang memiliki p-value terkecil (paling signifikan) yang akan digunakan sebagai split node.
b. Jika p-value kurang dari atau sama dengan tingkat spesifikasi alpha, split node menggunakan variabel prediktor ini. Jika tidak ada variabel prediktor dengan nilai
p-value yang signifikan, tidak dilakukan split dan node ditentukan sebagai terminal node (node akhir).
3. Penghentian (Stopping)
Tahap penghentian dilakukan jika proses pertumbuhan pohon harus dihentikan sesuai dengan peraturan pemberhentian di bawah ini:
a. Tidak ada lagi variabel prediktor yang signifikan menunjukkan perbedaan terhadap variabel respon.
b. Jika pohon sekarang mencapai batas nilai maksimum pohon dari spesifikasi, maka pertumbuhan akan berhenti.
c. Jika ukuran nilai child node kurang dari nilai ukuran child node minimum spesifikasi, atau berisi pengamatan-pengamatan dengan jumlah yang terlalu sedikit maka node tidak akan di gabung.
2.6.3 Koreksi Bonferroni (Bonferroni Correction)
Koreksi Bonferroni adalah suatu proses koreksi yang digunakan ketika beberapa uji statistik untuk kebebasan atau ketidakbebasan dilakukan secara bersamaan (Sharp et al., 2002). Koreksi Bonferroni biasanya digunakan dalam pembandingan berganda.
Ketika terdapat sebanyak M uji perbandingan yang sudah dikatakan bebas satu sama lain, peluang untuk melakukan kesalahan tipe 1 atau α (dalam satu atau lebih uji-uji tersebut), akan sama dengan 1 dikurangi peluang untuk tidak melakukan kesalahan tipe 1 dalam uji-uji tersebut, dimana nilainya akan lebih besar dari α yang telah ditentukan. Secara umum, hal tersebut dapat dirumuskan sebagai berikut (Bagozzi, 1994):
1 − (1 − 𝛼)𝑀 > 𝛼 (2.4)
Dengan:
M = pengali Bonferroni 𝛼 = kesalahan tipe 1
Pengali Bonferrani untuk masing-masing tipe variabel-variabel prediktor adalah berbeda. Menurut Gallagher (2000) pengali Bonferroni untuk masing-masing jenis variabel-variabel prediktor adalah sebagai berikut:
1. Variabel prediktor monotonik 𝑀 = (𝑐 − 1
𝑟 − 1) (2.5) 2. Variabel prediktor bebas
𝑀 = ∑ (−1)𝑖 (𝑟−𝑖)𝑐 𝑖!(𝑟−𝑖)! 𝑟−1
𝑖=0 (2.6)
3. Variabel prediktor mengambang 𝑀 = (𝑐 − 2 𝑟 − 2) + 𝑟 ( 𝑐 − 2 𝑟 − 1) (2.7) Dengan: M = pengali Bonferroni
c = banyaknya kategori variabel prediktor awal
2.6.4 Diagram Pohon Klasifikasi CHAID
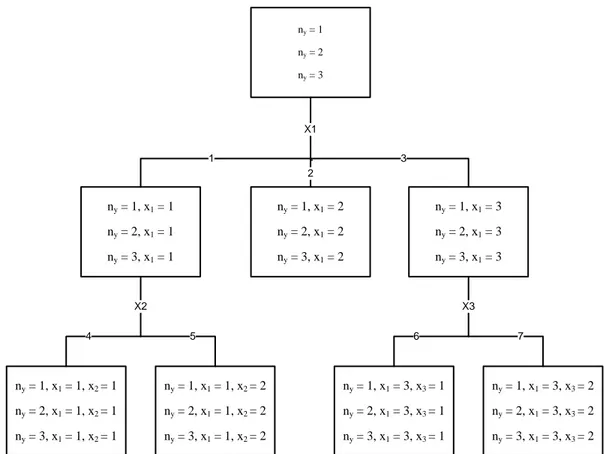
CHAID akan menghasilkan sebuah diagram pohon klasifikasi yang menggambarkan pembentukan segmen. Diagram CHAID terdiri dari batang pohon (tree trunk) dengan membagi (split) menjadi lebih kecil berupa cabang-cabang (brances). ny = 1 ny = 2 ny = 3 ny = 1, x1 = 3 ny = 2, x1 = 3 ny = 3, x1 = 3 ny = 1, x1 = 2 ny = 2, x1 = 2 ny = 3, x1 = 2 ny = 1, x1 = 1 ny = 2, x1 = 1 ny = 3, x1 = 1 ny = 1, x1 = 1, x2 = 2 ny = 2, x1 = 1, x2 = 2 ny = 3, x1 = 1, x2 = 2 ny = 1, x1 = 1, x2 = 1 ny = 2, x1 = 1, x2 = 1 ny = 3, x1 = 1, x2 = 1 ny = 1, x1 = 3, x3 = 1 ny = 2, x1 = 3, x3 = 1 ny = 3, x1 = 3, x3 = 1 ny = 1, x1 = 3, x3 = 2 ny = 2, x1 = 3, x3 = 2 ny = 3, x1 = 3, x3 = 2 X1 2 1 3 X2 4 5 6 7 X3 Y
Gambar 2.1 Diagram Pohon Dalam Analisis CHAID Sumber: Lehmann dan Eherler (2001)
Menurut Myers dalam Kunto dan Hasana (2006) diagram pohon CHAID mengikuti aturan “dari atas ke bawah” (top-down stopping rule). Diagram pohon disusun mulai dari kelompok induk (parent node), berlanjut dibawahnya sub kelompok (child node) yang berturut-turut dari hasil pembagian kelompok induk berdasarkan kriteria tertentu. Node pada ujung pohon yang tidak terdapat percabangan lagi disebut terminal node. Tiap-tiap node dari diagram pohon ini menggambarkan sub kelompok dari sampel yang diteliti dan berisi keseluruhan sampel dan frekuensi absolute ni untuk setiap kategori yang disusun.
Pada pohon klasifikasi CHAID terdapat istilah kedalaman (depth) yang berarti banyaknya tingkatan node-node sub kelompok sampai ke bawah pada node sub kelompok yang terakhir. Pada kedalaman pertama, sampel dibagi oleh X1 sebagai variabel prediktor terbaik untuk variabel respon berdasarkan uji chi-square. Tiap
node berisi informasi tentang frekuensi variabel Y, sebagai variabel respon, yang
merupakan bagian dari sub kelompok yang dihasilkan berdasarkan kategori yang disebutkan (X1). Pada kedalaman ke-2 (node X2 dan X3) merupakan pembagian dari X1 (untuk node ke-1 dan ke-3). Dengan cara yang sama, sampel selanjutnya dibagi oleh variabel prediktor yang lain, yaitu X2 dan X3, dan selanjutnya menjadi sub kelompok pada node ke-4, 5, 6, dan 7 (Lehmann dan Eherler, 2001). Pada masing-masing node ditampilkan persentase responden untuk setiap kategori dari variabel respon, dan juga ditunjukkan jumlah total responden untuk masing-masing node (Myers, dalam Kunto dan Hasana, 2006).
2.7 Analisis Regresi Logistik Biner
Analisis regresi logistik biner merupakan suatu teknik untuk menganalisis data yang variabel responnya memiliki dua kategori dengan satu atau lebih variabel prediktor yang berskala kontinu dan atau kategorik.
Metode regresi logistik merupakan metode regresi dengan variabel respon Y dalam bentuk kategorik yaitu variabel biner atau dikotomi yang mempunyai dua kemungkinan nilai (Ryan, 1997). Apabila variabel Y merupakan variabel biner atau dikotomi dalam artian nilai variabel respon terdiri dari dua kategori yaitu “sukses” (Y=1) atau “gagal” (Y=0), maka variabel Y mengikuti sebaran Bernoulli yang mempunyai fungsi peluang:
𝑓(𝑌 = 𝑦) = 𝑝𝑦(1 − 𝑝)1−𝑦 ; 𝑦 = 0,1 (2.8)
Nilai harapan dari variabel respon Y untuk nilai variabel prediktor x yang diberikan adalah [𝐸(𝑌|𝑥)]. Untuk menyerderhanakan notasi, digunakan 𝑔(𝑥) = 𝛽0+ 𝛽1𝑋1+ 𝛽2𝑋2 + … + 𝛽𝑝𝑋𝑝 dan 𝜋(𝑥) = 𝐸(𝑌|𝑥) yang menjelaskan rataan bersyarat dari Y untuk nilai x yang diberikan apabila digunakan distribusi logistik (Hosmer&Lemeshow,1989). Dapat dilihat pada persamaan berikut:
𝜋(𝑥) = exp [𝑔(𝑥)]
1+exp [𝑔(𝑥)]=
exp (𝛽0+𝛽1𝑋1+𝛽2𝑋2+ …+𝛽𝑝𝑋𝑝)
1+exp (𝛽0+𝛽1𝑋1+𝛽2𝑋2+ …+𝛽𝑝𝑋𝑝) (2.9) Persamaan 2.8 disebut fungsi logistik 𝑓[𝑔(𝑥)], sehingga dapat dituliskan sebagai berikut:
𝑓[𝑔(𝑥)] = exp [𝑔(𝑥)]
Apabila ditetapkan nilai g(x) pada persamaan 2.9, maka akan diperoleh: lim
𝑔(𝑥)→−∞𝑓[𝑔(𝑥)] = 0
lim
𝑔(𝑥)→∞𝑓[𝑔(𝑥)] = 1 (2.11)
Dari persamaan 2.11 dapat dilihat bahwa nilai 𝑓[𝑔(𝑥)] selalu berada pada selang 0 dan 1 untuk semua nilai g(x), sehingga nilai 𝑓[𝑔(𝑥)] menunjukkan bahwa model logistik menggambarkan peluang suatu kejadian atau risiko dari suatu kejadian.
Hubungan antara variabel prediktor dan peluangnya adalah hubungan tidak linier sehingga untuk mendapatkan hubungan yang linier dilakukan suatu tranformasi logit. Hasil transformasinya sebagai berikut:
𝑔(𝑥) = ln ( 𝜋(𝑥)
1−𝜋(𝑥)) = 𝛽0+ 𝛽1𝑋1+ 𝛽2𝑋2 + … + 𝛽𝑝𝑋𝑝 (2.12)
Fungsi sebaran responnya adalah 𝑦 = 𝜋(𝑥) + 𝜀, sehingga apabila nilai y=1 maka 𝜀 = 1 − 𝜋(𝑥) dengan peluang 𝜋(𝑥), sedangkan apabila y=0 maka 𝜀 = − 𝜋(𝑥) dengan peluang 1 − 𝜋(𝑥). Sebaran 𝜀 mengikuti sebaran Binomial dengan rataan 0 dan ragam 𝜋(𝑥)[1 − 𝜋(𝑥)].
2.8 Pendugaan Parameter
Metode paling umum yang digunakan untuk menduga parameter pada model
regresi logistik adalah metode kemungkinan maksimum (Methode of Maximum
Likelihood) (Hosmer & Lemeshow, 1989). Secara umum fungsi likelihood
didefinisikan sebagai fungsi peluang bersama dari variabel acak yang dibentuk oleh sampel. Khususnya, untuk sampel dengan ukuran n dengan amatannya
) , , ,
(y1 y2 yn korespondensi variabel acaknya adalah
Y1,Y2,,Yn
. Selama Yidianggap independen, maka fungsi densitas peluang bersamanya adalah sebagai berikut:
𝑔(𝑌1, 𝑌2, … , 𝑌𝑛) = ∏𝑛 𝑓(𝑌𝑖; 𝜃)
𝑖=1 (2.13)
Jika Y dikodekan 0 dan 1 maka menurut persamaan (2.9) 𝜋(𝑥) = 𝑃(𝑌 = 1|𝑥) dan 1 − 𝜋(𝑥) = 𝑃(𝑌 = 0|𝑥) sehingga, untuk pasangan-pasangan (𝑥𝑖, 𝑦𝑖) berlaku 𝑦𝑖 = 1 dengan fungsi kemungkinan maksimumnya adalah 1 − 𝜋(𝑥𝑖).
Secara sistematis fungsi kemungkinan maksimum untuk pasangan (𝑥𝑖, 𝑦𝑖) adalah sebagai berikut:
𝑓(𝑥𝑖) = 𝜋(𝑥𝑖)𝑦𝑖[1 − 𝜋(𝑥
𝑖)]1−𝑦𝑖 (2.14)
Apabila amatan-amatan diasumsikan saling bebas, fungsi kemungkinan maksimum dapat ditulis sebagai berikut:
𝑙(𝛽) = ∏𝑛 𝑓(𝑥𝑖)
𝑖=1 = ∏𝑛𝑖=1𝜋(𝑥𝑖)𝑦𝑖[1 − 𝜋(𝑥𝑖)]1−𝑦𝑖 (2.15)
Metode kemungkinan maksimum memberikan nilai penduga dari vektor 𝛽′ =
(𝛽0𝛽1… 𝛽𝑝) dengan memaksimumkan fungsi kemungkinan bersama pada persamaan (2.15), secara matematik bentuk logaritma dari fungsi kemungkinan bersama adalah sebagai berikut:
𝐿(𝛽) = ln[𝑙(𝛽)] = ∑𝑛 [𝑦𝑖ln[𝜋(𝑥𝑖)] + (1 − 𝑦𝑖) ln[1 − 𝜋(𝑥𝑖)]]
Dengan substitusi 𝜋(𝑥𝑖) = exp [𝑔(𝑥𝑖)] 1+exp [𝑔(𝑥𝑖)] dimana 𝑔(𝑥𝑖) = 𝛽0+ 𝛽1𝑋1+ 𝛽2𝑋2+ … + 𝛽𝑝𝑋𝑝 maka diperoleh: 𝐿(𝛽) = ∑ [∑ 𝑦𝑖ln [ exp[𝑔(𝑥𝑖)] 1+exp[𝑔(𝑥𝑖)]] + 𝑛 𝑖=1 (1 − 𝑦𝑖)ln [ 1 1+exp[𝑔(𝑥𝑖)]]] 𝑛 𝑖=1 = ∑ [[𝑦𝑖𝑙𝑛 exp[𝑔(𝑥𝑖)] − 𝑦𝑖ln(1 + exp[𝑔(𝑥𝑖)]) + 𝑙𝑛 [ 1 1+exp[𝑔(𝑥𝑖)]] − 𝑦𝑖𝑙𝑛 [ 1 1+exp[𝑔(𝑥𝑖)]]] 𝑛 𝑖=1 = ∑ [𝑦𝑖 [𝑔(𝑥𝑖)] −𝑦𝑖ln(1 + exp[𝑔(𝑥𝑖)])+[ln 1 − ln[1 + exp[𝑔(𝑥𝑖)]]]− 𝑦𝑖[ln 1 − 𝑛 𝑖=1 ln[1 + exp[𝑔(𝑥𝑖)]]]] = ∑𝑛𝑖=1(𝑦𝑖[𝑔(𝑥𝑖)]− 𝑦𝑖ln (1 + exp[𝑔(𝑥𝑖)]))− ln[1 + exp[𝑔(𝑥𝑖)]]+ 𝑦𝑖ln[1 + exp[𝑔(𝑥𝑖)]] = ∑𝑛 𝑦𝑖[𝑔(𝑥𝑖)]− ln[1 + exp[𝑔(𝑥𝑖)]] 𝑖=1 = ∑ 𝑦𝑖(𝛽0+ 𝛽1𝑋1+ 𝛽2𝑋2+ … + 𝛽𝑝𝑋𝑝) − ln (1 + exp(𝛽0+ 𝛽1𝑋1+ 𝛽2𝑋2+ … + 𝛽𝑝𝑋𝑝)) 𝑛 𝑖=1
Untuk memperoleh nilai penduga 𝛽̂ , dimana i = 1, 2, . . ., p yang 𝑖
memaksimumkan nilai fungsi 𝐿(𝛽). Selanjutnya 𝐿(𝛽) dideferensialkan terhadap setiap 𝛽𝑖. 𝐿(𝛽) = ∑ (𝛽0𝑦𝑖+ 𝛽1𝑥1𝑦𝑖+ ⋯ + 𝛽𝑝𝑥𝑝𝑦𝑖− ln (1 + exp(𝛽0𝑦𝑖+ 𝛽1𝑥1𝑦𝑖+ ⋯ + 𝛽𝑝𝑥𝑝𝑦𝑖))) 𝑛 𝑖=1 𝛿𝐿(𝛽) 𝛿𝛽0 = ∑ [𝑦𝑖− ( 1 1 + exp(𝛽0𝑦𝑖+ 𝛽1𝑥1𝑦𝑖+ ⋯ + 𝛽𝑝𝑥𝑝𝑦𝑖) . exp(𝛽0𝑦𝑖+ 𝛽1𝑥1𝑦𝑖+ ⋯ + 𝛽𝑝𝑥𝑝𝑦𝑖))] 𝑛 𝑖=1 𝛿𝐿(𝛽) 𝛿𝛽1 = ∑ [𝑥1𝑦𝑖− 1 1+𝑒𝑥𝑝[𝑔(𝑥𝑖)]. 𝑥1exp [𝑔(𝑥𝑖)]] 𝑛 𝑖=1 dan
𝛿𝐿(𝛽) 𝛿𝛽𝑝 = ∑ [𝑥𝑝𝑦𝑖− 1 1+𝑒𝑥𝑝[𝑔(𝑥𝑖)]. 𝑥1exp [𝑔(𝑥𝑖)]] 𝑛 𝑖=1
Untuk mendapatkan 𝛽𝑖, i= 1, 2, . . ., p maka 𝛿𝐿(𝛽) 𝛿𝛽𝑝 =0 𝛿𝐿(𝛽) 𝛿𝛽0 = ∑ [𝑦𝑖− ( 1 1+exp(𝛽0𝑦𝑖+𝛽1𝑥1𝑦𝑖+⋯+𝛽𝑝𝑥𝑝𝑦𝑖). exp(𝛽0𝑦𝑖+ 𝛽1𝑥1𝑦𝑖+ ⋯ + 𝛽𝑝𝑥𝑝𝑦𝑖))] 𝑛 𝑖=1 = 0 𝛿𝐿(𝛽) 𝛿𝛽1 = ∑ [𝑥1𝑦𝑖− 1 1+𝑒𝑥𝑝[𝑔(𝑥𝑖)]. 𝑥1exp [𝑔(𝑥𝑖)]] 𝑛 𝑖=1 = 0 (2.17) 𝛿𝐿(𝛽) 𝛿𝛽𝑝 = ∑ [𝑥𝑝𝑦𝑖− 1 1+𝑒𝑥𝑝[𝑔(𝑥𝑖)]. 𝑥1exp [𝑔(𝑥𝑖)]] 𝑛 𝑖=1 = 0 (2.18) 2.9 Pengujian Parameter
Pengujian terhadap parameter–parameter model dilakukan untuk mengetahui
peran seluruh variabel prediktor baik secara bersama–sama (simultan) maupun secara parsial. Menurut Hosmer dan Lemeshow (2000), untuk pengujian parameter secara bersama dapat digunakan uji nisbah kemungkinan yaitu uji G dengan hipotesis: H0 : β1= β2= ... = βp= 0 (Tidak ada pengaruh sekumpulan variabel prediktor terhadap
variabel respon).
H1 : minimal ada satu βi≠0 (Minimal satu dari variabel prediktor berpengaruh terhadap variabel respon).
Statistik uji yang digunakan adalah statistik uji G di mana rumus uji G adalah:
ln 2 0 k L L G (2.19) Keterangan: 0
L
= fungsi kemungkinan maksimum tanpa variabel prediktor kJika H0 benar, statistik uji G akan mengikuti sebaran distribusi 𝜒2 dengan derajat bebas (p-1). Hipotesis nol akan ditolak jika nilai statistika uji G > 𝜒𝑝−1,𝛼2 .
Kriteria uji yang digunakan adalah:
0 2 , 2 / 0 2 , 2 / H Tolak , H Terima ,
db GSedangkan pengujian parameter βi secara parsial dilakukan dengan membandingkan model terbaik yang dihasilkan oleh uji simultan terhadap model tanpa variabel bebas di dalam model terbaik. Pengujian hipotesis yang dilakukan yaitu:
H0 : βi = 0 (Tidak ada pengaruh variabel bebas yang diuji terhadap variabel respon). H1 : βi ≠ 0 (Terdapat pengaruh variabel bebas yang diuji terhadap variabel respon). Statistik ujinya adalah:
ˆ ˆ ^ i i SE W (2.20)Jika H0 benar, maka statistik uji W akan mengikuti sebaran normal baku Z, H0 akan ditolak jika W > 𝑍𝛼
2 ⁄ .
2.10 Regresi Logistik Bertatar (Stepwise Logistic Regression)
Regresi logistik bertatar adalah sebuah metode yang digunakan untuk memasukkan atau mengeluarkan variabel-variabel dari suatu model (Hosmer & Lemeshow, 1989). Metode ini diawali dengan metode seleksi langkah maju kemudian dilanjutkan dengan eliminasi langkah mundur.
Seleksi langkah maju didasarkan pada nilai log likelihood (L). Uji yang digunakan adalah Log Likelihood Ratio Test dengan statistik uji G, yaitu:
L Lj
G2 0 (2.21)
Keterangan:
L0 : Nilai log likelihood model hanya dengan konstanta. Lj : Nilai log likelihood model dengan variabel ke-j.
Pada langkah awal, dimasukkan nila p yang minimum, selanjutnya diteruskan dengan penambahan variabel yang dilakukan dengan uji G. Seleksi langkah maju berhenti jika pada langkah kedua atau seterusnya diperoleh nilai p pada uji G yang bermakna (Hosmer & Lemeshow, 1989). Kemudian dilanjutkan dengan langkah mundur dengan menggunakan statistik uji:
𝐺 = 2 (𝐿𝑒1𝑒2 − 𝐿𝑒𝑗) (2.22)
𝐿𝑒1𝑒2 : Nilai log likelihood hasil seleksi langkah maju dengan variabel yang dimasukkan adalah variabel 1 dan variabel 2.
𝐿𝑒𝑗 : Nilai log likelihood jika variabel yang masuk pada tahap ke-j dibuang.
Pembuangan langkah ke-j dengan pertimbangan nilai p yang maksimum. Langkah eliminasi langkah mundur dihentikan jika diperoleh statistik G dengan nilai
p-value > α. Kemudian dilakukan analisis untuk menyusun model regresi logistik dan
2.11 Interpretasi Koefisien
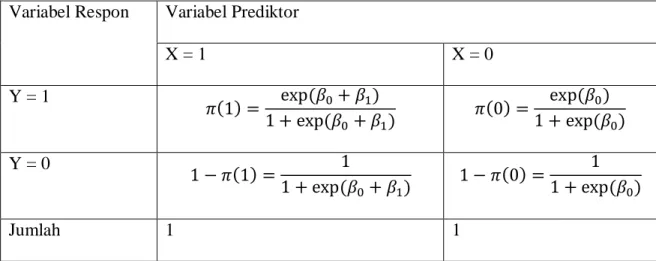
Interpretasi koefisien dilakukan pada variabel-variabel yang berpengaruh nyata. Pada regresi logistik dengan satu variabel prediktor β1= g(x+1) – g(x) menunjukkan perubahan nilai logit untuk setiap satu unit perubahan pada variabel prediktor x untuk model regresi logistik dengan satu variabel prediktor dikotomi dapat diilustrasikan dalam tabel 2.3 berikut (Hosmer & Lemeshow, 1989).
Tabel 2.3. Nilai-nilai Dari Model Logistik untuk Variabel Prediktor Dikotomi Variabel Respon Variabel Prediktor
X = 1 X = 0 Y = 1 𝜋(1) = exp (𝛽0+ 𝛽1) 1 + exp (𝛽0+ 𝛽1) 𝜋(0) = exp (𝛽0) 1 + exp (𝛽0) Y = 0 1 − 𝜋(1) = 1 1 + exp (𝛽0+ 𝛽1) 1 − 𝜋(0) = 1 1 + exp (𝛽0) Jumlah 1 1
Sumber: Hosmer & Lemeshow (1989)
Nilai odds rasio antara Y=1 dengan Y=0 untuk X=1 adalah 𝜋(1) [1 − 𝜋(1)]⁄ , sedangkan nilai odds rasio antara Y=1 dengan Y=0 untuk X=0 adalah 𝜋(0) [1 − 𝜋(0)]⁄ . Log dari kedua odds rasio tersebut didefinisikan sebagai g(1) dan g(0). Odds ratio (ψ) didefinisikan sebagai rasio dari odds untuk x=1 dengan x=0 sehingga:
Ψ= P(Y=1|X=1)/P(Y=0|X=1)
P(Y = 1|X = 0)/P(Y=0|X=0)=
[𝜋(1) [1−𝜋(1)]⁄ ]
𝐿𝑛(Ψ) = Ln ([π(1)/[1−π(1)]]
[π(0)/[1−π(0)]]) = g(1) − g(0) = 𝛽1 = 𝑏𝑒𝑑𝑎 𝑙𝑜𝑔𝑖𝑡 (2.24)
Model logistik dengan satu peubah bebas dikotomi, koefisien β1 adalah beda logit, sedangkan exp(β1) adalah nilai rasio dari odds (Hosmer &Lemeshow. 1989).
Berdasarkan persamaan (2.23) dapat diinterpretasikan bahwa rasio odds (ψ)=1 berarti bahwa individu dengan nilai X = 1 mempunyai peluang yang sama dengan individu nilai X = 0 dalam kaitannya dengan Y = 1. Jika 1 < ψ < ∞ maka individu X = 1 mempunyai peluang yang lebih besar dibanding dengan X = 0 dalam kaitannya dengan Y = 1. Sebaliknya jika 0 < ψ < 1 individu dengan X = 1 mempunyai peluang yang lebih kecil dibanding X = 0 dalam kaitannya dengan Y = 1.