BAB 2
LANDASAN TEORI
Text-to-speech engine pada sistem operasi Windows dengan Microsoft Visual Basic 6.0 dapat diintegrasikan dengan menggunakan sebuah perantara yaitu Microsoft Speech SDK 4.0. Sebelum sampai pada pembahasan mengenai objek ini terlebih dahulu akan dijelaskan secara singkat mengenai text-to-speech yang akan digunakan serta komponen-komponen lain yang terlibat dalam perancangan aplikasi ini.
2.1 Teknologi Text-to-Speech
Text-to-speech telah ada sejak beberapa dekade, yakni sejak tahun 1939. Sayangnya kualitas output khususnya kealamian suaranya masih seperti robot [12]. Salah satu catatan literatur awal yang berhubungan dengan sistesis ucapan adalah pernyataan seorang ahli matematika dan engineer terkenal yang bernama Leonhard Euler pada tahun 1761. Euler menyatakan “It would be a considerable invention indeed, that of a machine able to mimic speech, with its sounds and articulations. I think it is not imposible” [3].
Salah satu perusahaan yang telah menghasilkan text-to-speech berkualitas baik adalah perusahaan Lernout and Hauspie di Belgia yang telah bangkrut pada tahun 2001. Perusahaan tersebut sudah memproduksi sistem text-to-speech berkualitas tinggi untuk bahasa Inggris, Jerman, Perancis, Belanda, Spanyol, Portugis, Jepang, dan beberapa bahasa lain untuk digunakan dengan Microsoft Agent Active-X control pada Microsoft Visual Studio. Pembangkit suara (speech synthesizer/text-to-speech engine) adalah sistem berbasis komputer yang dapat membaca setiap text menjadi suara yang alami. Mesin L&H TTS3000 merupakan produk text-to-speech yang diproduksi perusahaan ini. L&H TTS3000 menyediakan sejumlah fitur yang ditingkatkan dan manfaat seperti berikut [10].
Natural Sounding
Concatenative Synthesizer Menawarkan suara yang mudah dimengerti, keduanya suara pria dan wanita berdasarkan sampel dari pengucapan yang sebenarnya. Prosody Models Menyediakan intonasi yang alami untuk
kalimat dan frase.
Intelligent
Intelligent, powerful normalizer Memungkinkan pengucapan yang benar dari singkatan, akronim, angka, dan nama dalam bidang riset dan konfigurasi pengguna standar.
Unlimited vocabulary Menghasilkan suara pengucapan yang dihasilkan oleh aturan fonetik, bukan mencari dalam kamus.
Advanced linguistic processing Menganalisis serta memberikan pengucapan yang sesuai untuk homograf, atau kata-kata yang dapat diucapkan berbeda tergantung pada penggunaannya dalam konteks.
Support for preprocessors Dapat mendukung aplikasi cerdas yang spesifik.
Flexible
Exception dictionaries Dapat dengan mudah dibuat oleh pengguna untuk disesuaikan pada text-to-speech, menggunakan pembangun kamus.
Control Tingkat volume, pitch, dan speech,
digabungkan dengan dukungan pengontrol urutan yang memungkinkan untuk menentukan jeda, penekanan, atau input fonetik.
huruf, kata demi kata, dan lain-lain.
Run-time switching Bahasa, kecuali kamus, dan parameter lain. Multiple language support Termasuk mesin text-to-speech untuk bahasa
American English, British English, Perancis, Jerman, Spanyol, Belanda, Italia, Korea, dan Jepang.
Multiple Output Formats Termasuk gelombang 8 kHz dan 11 kHz
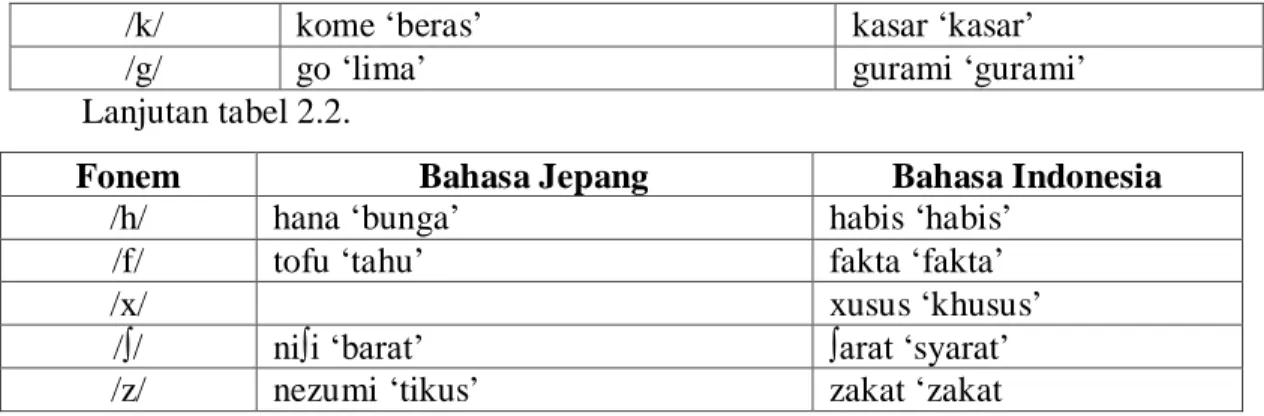
Gambar 2.1 memperlihatkan diagram fungsional sebuah text-to-speech synthesizer secara umum. Sistem text-to-speech secara garis besar terdiri dari dua subsistem utama, yaitu: NLP (Natural Language Processing) atau text to phoneme dan DSP (Digital Signal Processing) atau phone-to-speech [11].
Gambar 2.1 Diagram Text-to-Speech Sistem [5]
Pada bagian pengolahan bahasa alami (NLP) merupakan modul konversi teks ke fonem yang menghasilkan transkripsi fonetik beserta informasi intonasi dan ritme (dikenal dengan prosodi) dan pada subsistem DSP merupakan modul konversi fonem ke ucapan, yang mengubah informasi fonetis yang diterima menjadi sinyal ucapan. Parsons (1987) juga membagi proses sistem text-to-speech menjadi dua tahapan atau subsistem, yakni:
1. grapheme-to-phoneme translation dan 2. phoneme-to-speech translation.
Tahapan-tahapan utama konversi dari teks menjadi ucapan dapat dilihat pada gambar 2.2. Bagian konverter teks ke fonem (text-to-phoneme conversion) secara menyeluruh berfungsi untuk mengolah kalimat masukan dalam suatu bahasa tertentu yang berbentuk teks menjadi urutan kode-kode bunyi yang direpresentasikan dengan kode fonem, durasi, serta pitch-nya. Kode-kode fonem adalah kode yang merepresentasikan unit bunyi yang ingin diucapkan. Pengucapan kata atau kalimat pada prinsipnya adalah urutan bunyi atau secara simbolik adalah urutan kode fonem.
Tahapan yang paling awal konversi dari teks menjadi ucapan merupakan masukan berupa teks yang kemudian masuk pada bagian konverter teks ke fonem (text-to-phoneme conversion). Blok normalisasi teks atau text normalization pada awal bagian ini merupakan bagian yang berfungsi untuk memperluas setiap bentuk singkatan serta format non-teks yang ingin diucapkan menjadi bentuk rangkai huruf yang dapat dibaca atau memperlihatkan cara pengucapannya. Berdasarkan analisis secara semantik (arti kata) pragmatik (pengetahuan), dan sintaktik (struktural), penekanan-penekanan pada suatu kata ditambahkan dan fonem-fonem dikonversikan dari huruf-huruf.
Dalam suatu bahasa dapat terjadi kondisi dimana tidak dapat ditemukan keteraturannya. Misalnya simbol huruf e yang diucapkan pada kata ‘empati’ dan ‘telur’, pada kondisi seperti ini harus dikonversi menjadi fonem yang berbeda untuk kondisi yang berbeda. Pada gambar 2.2, kondisi yang masih dapat ditangani oleh aturan diimplementasikan dalam blok Letter-to-Phoneme Conversion sedangkan untuk kondisi yang tidak dapat ditangani oleh aturan diimplementasikan dengan blok Exception Dictionary Lookup. Hasil dari tahapan ini merupakan rangkaian fonem yang merepresentasikan bunyi kalimat yang ingin diucapkan.
Setiap unit fonem dilengkapi dengan data berupa durasi dan pitch pada bagian Prosody Generation. Data-data tersebut diperoleh berdasarkan kombinasi antara tabel atau database serta model prosodi. Setiap fonem harus dilengkapi dengan informasi durasi dan pitch. Informasi durasi diperlukan untuk menentukan berapa lama suatu fonem diucapkan, sedangkan informasi pitch diperlukan untuk menentukan tinggi rendahnya nada pengucapan suatu fonem. Durasi dan pitch bersama-sama akan
membentuk intonasi. Tahap selanjutnya dari proses ini merupakan Phonetic Analysis yang dapat dikatakan merupakan tahapan penyempurnaan yang melakukan perbaikan di tingkat bunyi.
Gambar 2.2 Urutan Proses Konversi Teks Menjadi Ucapan (text-to-speech) dalam Speech Engine Secara Umum (dimodifikasi dari Pelton, 1992 dalam
Arman [2])
Pada bagian konverter fonem ke ucapan (phoneme-to-speech conversion) di gambar 2.2 akan menerima masukan kode-kode fonem serta pitch dan durasi yang telah dihasilkan oleh bagian sebelumnya. Berdasarkan kode-kode tersebut, bagian ini akan menghasilkan bunyi atau sinyal ucapan yang sesuai dengan kalimat yang ingin diucapkan.
Ada beberapa alternatif teknik yang dapat digunakan untuk implementasi bagian konverter fonem ke ucapan. Dua teknik yang paling banyak digunakan adalah formant synthesizer serta diphone concatenation. Saat ini, teknik kedua lebih banyak digunakan karena dapat menghasilkan ucapan dengan kualitas yang lebih alami. Teknik formant synthesizer memodelkan aliran suara, baik sumber dan filter di kontrol
oleh suatu aturan fonetis. Sedangkan teknik diphone concatenation melakukan pembangkitan ucapan dengan cara menggabung-gabungkan segmen-segmen bunyi yang berupa diphone (dua fonem) [2].
2.2 Proses Pembentukan Bunyi
Bunyi apa saja, termasuk bunyi bahasa, pada dasarnya adalah getaran atas benda apa saja karena adanya energi yang bekerja. Getaran ini disadari sebagai bunyi apabila getaran itu cukup kuat dan dihantarkan ke alat dengar oleh udara sekitar. Proses pembentukan bunyi bahasa juga demikian. Sumber energi utamanya adalah arus udara yang mengalir dari/ke paru-paru. Getaran-getaran itu timbul pada pita suara sebagai akibat tekanan arus udara, yang dibarengi dengan gerakan alat-alat ucap sedemikian rupa sehingga menimbulkan perbedaan/perubahan rongga udara yang terdapat dalam mulut dan/atau hidung. Dari penjelasan tersebut dapat diketahui bahwa sarana utama yang berperan dalam proses pembentukan bunyi bahasa adalah arus udara, pita suara, dan alat ucap [1].
2.3 Sistem Pembentuk Ucapan
Ucapan manusia dihasilkan oleh suatu sistem produksi ucapan yang dibentuk oleh alat-alat ucap manusia. Proses tersebut dimulai dengan formulasi pesan dalam otak pembicara. Pesan tersebut akan diubah menjadi perintah-perintah yang diberikan kepada alat-alat ucap manusia, sehingga akhirnya dihasilkan ucapan yang sesuai dengan pesan yang ingin diucapkan.
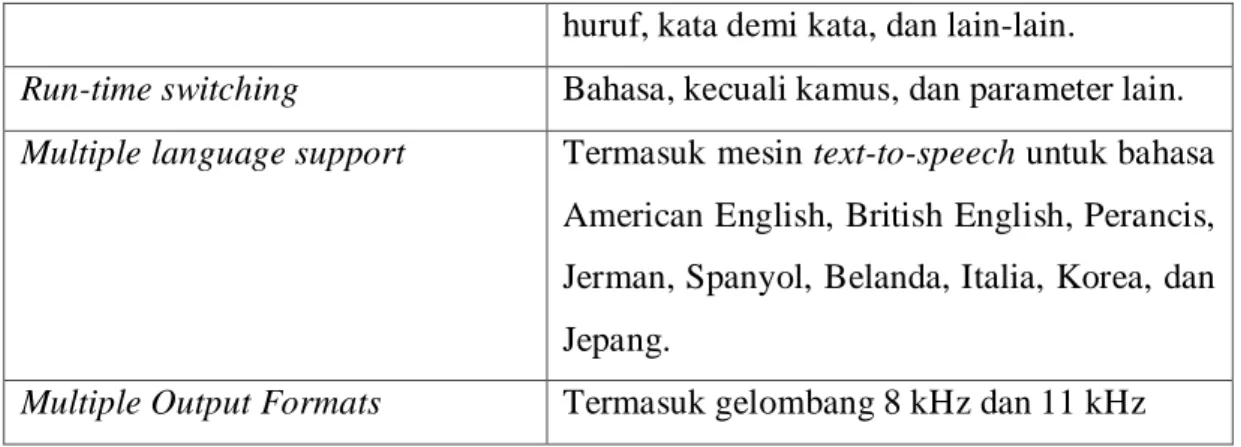
Gambar 2.3 Foto Sinar X Penampang Alat-Alat Ucap Manusia (Rabbiner, 93 dalam Arman [1])
Gambar 2.3 memperlihatkan foto sinar X penampang alat-alat ucap manusia. Vocal tract pada gambar tersebut ditandai oleh garis putus-putus, dimulai dari vocal cords atau glottis, dan berakhir pada mulut. Vocal tract terdiri dari pharynx (koneksi antara esophagus dengan mulut) dan mulut. Panjang vocal tract pria pada umumnya sekitar 17 cm. Daerah pertemuan vocal tract ditentukan oleh lidah, bibir, rahang, dan bagian belakang langit-langit; luasnya berkisar antara 20 𝑐𝑚2 sampai dengan mendekati nol. Nasal tract mulai dari bagian belakang langit-langit dan berakhir pada nostrils. Pada keadaan tertenu, suara nasal akan dikeluarkan melalui rongga ini.
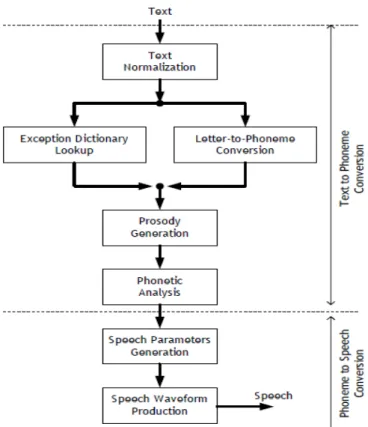
Gambar 2.4 memperlihatkan model sistem produksi ucapan manusia yang disederhanakan. Pembentukan ucapan dimulai dengan adanya hembusan udara yang dihasilkan oleh paru-paru. Cara kerjanya mirip seperti piston atau pompa yang ditekan untuk menghasilkan tekanan udara. Pada saat vocal cord berada dalam keadaan tegang, aliran udara akan menyebabkan terjadinya vibrasi pada vocal cord dan menghasilkan bunyi ucapan yang disebut voiced speech sound. Pada saat vocal cord berada dalam
keadaan lemas, aliran udara akan melalui daerah yang sempit pada vocal tract dan menyebabkan terjadinya turbulensi, sehingga menghasilkan suara yang dikenal sebagai unvoiced sound [1].
Gambar 2.4 Model Sistem Produksi Ucapan Manusia (Rabbiner, 93 dalam Arman [1])
Ucapan dihasilkan sebagai rangkaian atau urutan komponen-komponen bunyi-bunyi pembentuknya. Setiap komponen bunyi-bunyi yang berbeda dibentuk oleh perbedaan posisi, bentuk, serta ukuran dari alat-alat ucap manusia yang berubah-ubah selama terjadinya proses produksi ucapan.
2.3.1 Representasi Sinyal Ucapan
Sinyal ucapan merupakan sinyal yang berubah terhadap waktu dengan kecepatan perubahan yang relatif lambat. Jika diamati pada selang waktu yang pendek (antara 5
sampai dengan 100 mili detik), karakteristiknya praktis bersifat tetap sedangkan jika diamati pada selang waktu yang lebih panjang karakteristiknya terlihat berubah-ubah sesuai dengan kalimat yang sedang diucapkan. Gambar 2.5 memperlihatkan contoh sinyal ucapan dari suatu kata dalam bahasa Jepang “ago”. Seluruh gambar tersebut memperlihatkan sinyal ucapan sepanjang 4.0 mili detik.
Gambar 2.5 Contoh Klasifikasi Sinyal Ucapan Pada Kata “ago” [Rabbiner, 93 dalam Arman [1]
Cara yang dipakai untuk mengklasifikasikan bagian-bagian atau komponen sinyal ucapan adalah dengan diklasifikasikan menjadi tiga keadaan yang berbeda, yaitu:
1. silence (S), merupakan keadaan pada saat tidak ada ucapan yang diucapkan, 2. unvoiced (U), merupakan keadaan pada saat vocal cord tidak melakukan
vibrasi, sehingga suara yang dihasilkan bersifat tidak periodik atau random, 3. voiced (V), merupakan keadaan pada saat terjadinya vibrasi pada vocal cord,
sehingga menghasilkan suara yang bersifat kuasi periodik.
Dari gambar 2.5 tercantum label-label S, U, V, yang dapat dipergunakan untuk mengamati perbedaan-perbedaan dari setiap keadaan tersebut. Pada gambar dengan label S berarti bagian tersebut keadaan diam direpresentasikan yakni belum ada kata yang diucapkan oleh pembicara. Amplitudo kecil yang tampak pada perioda noise latar belakang yang ikut terekam. Suatu periode singkat unvoiced (U) tampak mengakhiri kata, sebelumnya dapat dilihat daerah voiced (V) sedangkan silence (S) bagian yang mengawali dan mengakhiri kata.
Dari contoh pada gambar 2.5 tersebut jelas bahwa segmentasi ucapan menjadi S, U, dan V tidak bersifat eksak, yakni terdapat daerah-daerah yang tidak dapat dikategorikan dengan tegas kedalam salah satu dari tiga kategori tersebut. Perubahaan dari keadaan-keadaan alat ucap manusia yang tidak bersifat diskrit dari satu keadaan ke keadaan lainnya merupakan salah satu penyebabnya, sehingga bunyi transisi dari satu segmen ke segmen lainnya menghasilkan bentuk yang tidak mudah ditentukan. Selain itu juga terdapat segmen-segmen ucapan yang mirip atau bahkan terkandung silence di dalamnya [1].
2.4 Karakteristik Bahasa Jepang
Bahasa Jepang dikenal sebagai bahasa yang kaya dengan huruf, tetapi miskin dengan bunyi. Karena, bunyi dalam bahasa Jepang terdiri dari lima buah vokal, dan beberapa buah konsonan yang diikuti vokal tersebut dalam bentuk suku kata terbuka. Jumlah suku kata (termasuk bunyi vokal) dalam bahasa Jepang hanya 102 buah, dan tidak ada suku kata tertutup atau kata yang diakhiri dengan konsonan kecuali bunyi [N] saja. Bagi penutur bahasa Jepang akan sulit untuk mempelajari bahasa lain dengan keterbatasan bunyi seperti ini. Di samping itu, dalam bahasa Jepang ada konsonan
rangkap dan bunyi vokal yang dipanjangkan sampai dua ketukan, serta aksen yang semuanya berfungsi sebagai pembeda arti. Aksen yang menjadi pembeda arti tidak terjadi dalam bahasa Indonesia. Pada struktur kalimat, struktur yang dipakai dalam kalimat bahasa Jepang adalah S-O-P sedangkan struktur bahasa Indonesia adalah S-P-O. Untuk menyampaikan bunyi yang jumlahnya terbatas tadi, digunakan empat macam huruf, yaitu [17]:
1. huruf hiragana, 2. huruf katakana, 3. huruf kanji, dan 4. huruf roomaji.
2.4.1 Huruf Kana
Huruf kana mencakup hiragana dan katakana, keduanya termasuk onsetsu moji. Onsetsu moji merupakan huruf-huruf yang menyatakan sebuah silabel yang tidak memiliki arti tertentu. Hal ini menjadi salah satu perbedaan antara huruf kana dengan huruf kanji yang memiliki arti tertentu.
1. Huruf hiragana, digunakan untuk menulis kosakata bahasa Jepang asli, apakah secara utuh atau digabungkan dengan huruf kanji.
2. Huruf katakana, digunakan untuk menulis kata serapan dari bahasa asing (selain bahasa Cina), dalam telegram, atau ketika ingin menegaskan suatu kata dalam kalimat.
Jumlah huruf hiragana dan katakana yang sekarang digunakan masing-masing 46 huruf, bunyi yang sama dilambangkan oleh kedua jenis huruf ini. Dari huruf tersebut, ada yang dikembangkan dengan menambahkan tanda tertentu untuk membentuk bunyi lainnya yang jumlahnya masing-masing mencapai 56 bunyi. Huruf-huruf tersebut berbentuk suku kata, sehingga bunyi dalam bahasa Jepang secara total terdiri dari sekitar 102 suku kata. Jika dibandingkan dengan bahasa Indonesia yang
menggunakan 26 huruf alfabet (Latin dari a sampai dengan z), jumlah suku kata dalam bahasa Jepang sangat terbatas. Bahasa Indonesia bisa melahirkan beberapa suku kata yang lebih banyak daripada bunyi dalam bahasa Jepang [17].
2.4.2 Huruf Kanji
Huruf kanji yaitu suatu huruf yang merupakan lambang, ada yang berdiri sendiri, ada juga yang harus digabungkan dengan huruf kanji yang lainnya atau diikuti dengan huruf hiragana ketika digunakan untuk menunjukkan suatu kata [17].
2.4.3 Huruf Roomaji (Huruf Latin)
Selain huruf-huruf kanji, hiragana, katakana, ada satu huruf lagi yang harus diperhatikan yaitu roomaji. Memang huruf yang utama untuk penulisan bahasa Jepang adalah kanji, hiragana, dan katakana, tetapi ada saja saatnya diperlukan pemakaian roomaji. Sebagai bukti dalam tulisan yang berbahasa Jepang baik dalam surat-surat kabar, majalah-majalah, buku-buku pelajaran, dan sebagainya yang ditulis dengan huruf Jepang, di sana-sini selalu tampak penggunaan huruf roomaji.
Keperluan dalam penggunaan huruf roomaji untuk penulisan bahasa Jepang dirasakan juga oleh para praktisi bidang pengajaran bahasa Jepang bagi orang asing. Pada tahap-tahap permulaan pengajaran bahasa Jepang tingkat dasar ada juga yang diselenggarakan menggunakan roomaji untuk memudahkan pemahaman orang-orang yang mempelajari bahasa ini [15].
2.4.4 Silabel dalam Bahasa Jepang
Silabel merupakan salah satu satuan bunyi bahasa, dalam bahasa Jepang disebut onsetsu. Sebagian besar silabel dalam bahasa Jepang dilambangkan dengan sebuah huruf kana (hiragana atau katakana). Tetapi ada juga silabel yang dilambangkan
dengan dua buah huruf kana seperti silabel-silabel yoo’on yang ditulis dengan cara menggabungkan huruf-huruf kana き(ki), し(shi), ち(chi), に(ni), ひ(hi), み(mi), り (ri), ぎ(gi), じ(ji),び(bi), dan ぴ(pi) dengan huruf-huruf kana や(ya), ゆ(yu), よ(yo) yang ditulis dalam ukuran kecil sehingga menjadi silabel-silabel きゃ(kya), きゅ(kyu), きょ(kyo), しゃ(sha), しゅ(shu), しょ(sho), dan sebagainya. Silabel dalam bahasa Jepang, terutama akan lebih jelas bila silabel itu ditulis dengan huruf Latin, dapat dibagi menjadi beberapa fonem. Silabel dalam bahasa Jepang dapat terbentuk dari susunan fonem [16].
1) V (satu vokal), yakni vokal-vokal /a/, /i/, /u/, /e/, dan /o/.
2) KV (satu konsonan dan satu vokal), misalnya silabel-silabel /ka/, /ki/, /ku/, /ke/, /ko/, /sa/, /shi/, dan sebagainya.
3) KSV (satu konsonan, satu semi vokal, dan satu vokal), misalnya silabel-silabel /kya/, /kyu/, /kyo/, /sha/, /shu/, /sho/, dan sebagainya.
4) SV (satu semi vokal dan satu vokal), yaitu silabel-silabel /ya/, /yu/, /yo/, dan /wa/.
2.5 Fonem
Fonem adalah satuan bunyi terkecil suatu bahasa yang berfungsi membedakan makna. Pengertian fonem juga bisa diarahkan pada distribusinya, yaitu perilaku bentuk linguistik terkecil dalam bentuk linguistik yang lebih besar [13].
Fonologi dalam bahasa Jepang memiliki perbedaan dengan bahasa Indonesia. Fonem bahasa Jepang berjumlah 30 buah yang terdiri dari 10 buah fonem vokal (/a/, /i/, /u/, /e/, /o/, /a:/, /i:/, /u:/, /e:/, /o:/), yakni 5 buah fonem vokal biasa dan 5 buah vokal panjang, 18 buah fonem konsonan (/p/, /b/, /m/, /t/, /𝑡𝑠/, /d/, /n/, /s/, /r/, /ç/, /j/, /k/, /g/, /h/, /£/, /∫/, /z/, /𝑛�/) dan 2 (/w/, /y/) buah fonem semi konsonan. Sebaliknya dalam bahasa Indonesia terdapat 27 buah fonem yang terdiri dari 5 buah fonem vokal (/a/, /i/, /u/, /e/, dan /o/), 20 buah fonem konsonan, yaitu 16 buah fonem asli (/p/,
/b/,/m/, /t/, /d/, /n/, /s/,/r/,/l/,/c/, /j/, /𝑛�/, /k/, /g/, / /, /h/), 4 buah fonem yang berasal dari bahasa asing (/f/, /z/, /x/, dan /∫/), dan 2 buah fonem semi konsonan (/w/, /y/).
Vokal panjang dan vokal biasa memiliki perbedaan dalam bahasa Jepang, hal ini tidak terjadi dalam bahasa Indonesia. Pada umumnya fonem konsonan yang ada dalam bahasa Indonesia juga ditemukan dalam bahasa Jepang, kecuali /l/, /c/, /x/, dan /
/. Terdapat dua buah konsonan bahasa Jepang yang tidak ditemukan dalam bahasa
Indonesia, yakni /ç/ dan /𝑡𝑠/ [19].
Tabel 2.1 Kontras Fonem Vokal
Fonem Bahasa Jepang Bahasa Indonesia
/a/ akai ‘merah’ lama ‘lama’
/i/ isu ‘kursi’ sapi ‘sapi’
/u/ mu∫i ‘kumbang’ buta ‘buta’
/e/ me ‘mata’ belah ‘belah’
/o/ awoi ‘biru’ toko ‘toko’
/a:/ oka:san ‘ibu’ /I:/ oji:san ’kakek’
/u:/ senpu:ki ‘kipas angin’ /e:/ one:sa ‘kakak perempuan’ /o:/ hiko:ki ‘pesawat’
Tabel 2.2 Kontras Fonem Konsonan
Fonem Bahasa Jepang Bahasa Indonesia
/p/ peji ‘lembar’ simpati ‘simpati’
/b/ tobu ‘terbang’ bosan ‘bosan’
/m/ mimi ‘telingan’ sampah ‘sampah’
/t/ anata ‘kamu’ tugas ‘tugas’
/𝑡𝑠/ tsuku ‘tiba’ toko ‘toko’
/d/ do ‘tembaga’ pindah ‘pindah’
/n/ niku ‘daging’ Santan ‘santan’
/𝑛�/ gyu: 𝑛�u: ‘susu’ 𝑛�o𝑛�a ‘nyonya’
/ / ilu ‘ngilu’
/j/ mijikai ‘pendek’ jajan ‘jajan’
/c/ cari ‘cari’
/ ç/ mi çi ‘jalan’
/s/ yasai ‘sayur’ sayap ‘sayap’
/r/ roku ‘enam’ risau ‘risau’
/k/ kome ‘beras’ kasar ‘kasar’
/g/ go ‘lima’ gurami ‘gurami’
Lanjutan tabel 2.2.
Fonem Bahasa Jepang Bahasa Indonesia
/h/ hana ‘bunga’ habis ‘habis’
/f/ tofu ‘tahu’ fakta ‘fakta’
/x/ xusus ‘khusus’
/∫/ ni∫i ‘barat’ ∫arat ‘syarat’
/z/ nezumi ‘tikus’ zakat ‘zakat
Tabel 2.3 merupakan tabel lambang bunyi bahasa Jepang. Pada tabel tersebut dapat dilihat gabungan fonem-fonem menjadi silabel dalam bahasa Jepang secara lengkap.
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
![Gambar 2.3 Foto Sinar X Penampang Alat-Alat Ucap Manusia (Rabbiner, 93 dalam Arman [1])](https://thumb-ap.123doks.com/thumbv2/123dok/2455913.3597818/7.893.283.674.133.568/gambar-foto-sinar-penampang-alat-manusia-rabbiner-arman.webp)
![Gambar 2.4 Model Sistem Produksi Ucapan Manusia (Rabbiner, 93 dalam Arman [1])](https://thumb-ap.123doks.com/thumbv2/123dok/2455913.3597818/8.893.294.701.256.712/gambar-model-sistem-produksi-ucapan-manusia-rabbiner-arman.webp)
![Gambar 2.5 Contoh Klasifikasi Sinyal Ucapan Pada Kata “ago” [Rabbiner, 93 dalam Arman [1]](https://thumb-ap.123doks.com/thumbv2/123dok/2455913.3597818/9.893.169.790.315.954/gambar-contoh-klasifikasi-sinyal-ucapan-pada-rabbiner-arman.webp)