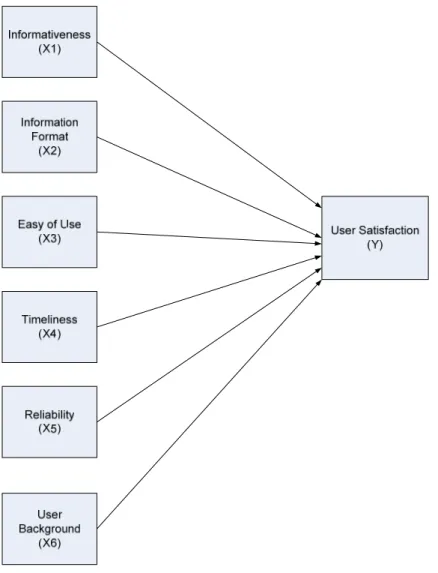
METODOLOGI PENELITIAN
3.1 Kerangka Pikir
Dalam penelitian ini akan dilakuan analisa terhadap tingkat kepuasan penggunaan
system informasi serta menguji hubungan kepuasan penggunaan system tersebut dengan
beberapa variable yang diduga mempengaruhinya. Berikut adalah gambar konsep dari
kerangka berpikir :
Penelitian akan dimulai dari pengumpulan data adalah kuesioner yang berisi pertanyaan yang diajukan kepada responden untuk mengumpulkan informasi mengenai sistem informasi perkreditan. Pertanyaan-pertanyaan yang diajukan harus sesuai dengan apa yang akan dicapai dan sesuai dengan yang tercermin di dalam hipotesis. Pertanyaan-pertanyaan diabuat berdasarkan variable-variable yang mempengaruhi tingkat kepuasan pengguna sistem informasi seperti informativeness, information format, timeliness, easy of use, reliability, dan user background.
3.2 Tempat dan Waktu Penelitian
Penelitian dilakukan di Koperasi Perumahan Wanabakti Nusantasa (KPWN) yang beralamat di Gedung Manggala Wanabakti Blok 1 lantai 15 Jl. Jendral Gatot Subroto Jakarta-Pusat, penelitian akan dilakukan di serluruh divisi KPWN yang menggunakan sistem informasi perkreditan yang ada.
Waktu penelitian pada bulan Desember 2008 sampai dengan Januari 2009. pengumpulan data diperoleh dari populasi pengguna sistem informasi perkreditan KPWN di seluruh divisi yang akan dilakukan dengan pertanyaan melalui kuesioner.
3.3 Metode Pengumpulan Data
3.3.1 Populasi
populasi adalah wilayah generalisasi yang terdiri atas : obyek/subyek yang mempunyai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulan (Sugiyono, 2002, p72).
Target populasi penelitian ini adalah seluruh pegawai KPWN di setiap divisi yang menggunakan sistem informasi perkreditan.
3.3.2 Teknik pengumpulan data
Teknik pengumpulan data yang digunakan pada penelitian ini adalah dengan melakukan survey dan menyebarkan kuesioner kepada pemakai sistem informasi perkreditan, Teknik sampling yang digunakan adalah simple random sampling. Menurut Umar (2002, p92) kuesioner adalah suatu cara pengumpulan data dengan menyebarkan daftar pertanyaan kepada responden dengan harapan mereka akan memberikan respon terhadap daftar pertanyaan tersebut. Daftar pertanyaant ersebut bersifat terbuka jika jawaban tidak ditentukan sebelumnya dan bersifat tertutup jika alternative-alternatif jawaban telah disediakan. Instrument lembar daftar pertanyaan dpat berupa angket (kuesioner), checklist, ataupun skala.
3.3.3 Instrumen
Instrumen penelitian adalah suatu alat yang digunakan untuk mengukur fenomena alam maupun social yang diamati. Secara spesifik semua fenomena ini desebut variable penelitian. Instumen yang dibuat sendiri harus diuji validitas dan reabilitasnya. Setiap instrument memiliki skala pengukuran, salah satu skala pengukuran yang dipakai dalam penelitian ini adalah skala Likert.
variable yang akan diukur dijabarkan menjadi indicator variablel. Kemudian indicator tersebut dijadikan sebagai titik tolak untuk menyusun item-item instrument yang dapat berupa pernyataan atau pertanyaan.
Jawaban setiap instrument yang menggunakan skala Likert mempunyai gradasi dari sangat positif sampai sangat negarif, yang dapat berupa kata-kata yaitu untuk keperluan analisis kuantitatif, maka jawaban dapat diberika score misalnya :
• Sangat setuju/selalu/sangat positif Score 5
• Setuju / sering/positif Score 4
• Ragu-Ragu/kadang-kadang/netral Score 3
• Tidak setuju/Hampir/tidak pernah/negative Score 2
• Sangat tidak setuju/tidak pernah/sangat negative Score 1
3.4 Validitas dan Realibilitas
Perlu dibedakan antara hasil penelitian yang valid dan reliable dengan
instrument yang valid dan reliable. Hasil penelitian yang valid bila terdapat kesaman antara data yang terkumpul dengan data yang ssungguhnya terjadi pada obyek yang diteliti, selanjutnya hasil penelitian yang reliable, bila terdapat kesamaan data dalam waktu yang berbeda. Instrument yang valid berate alat ukur yang digunakan untuk mendapatkan data itu valid. Valid berarti instrument tersebut dapat digunakan untuk mengukur apa yang seharusnya diukur. Instrument yang reliable adalah instrument yang digunakan bebearpa kali untuk mengukur obyek yang sama.
- Validitas
Menurut Sugiyono (2002, pp115-116) uji validitas kuesioner terhadap responden (minimum 30 sample), kemudian uji hasilnya dengan menggunakan perangkat lunak SPSS. Ulangi proses ini sampai keseluruhan nilai validitas oleh r diuji berdasarkan aturan yang direkomendasikan yaitu :
a. Apabila r > 0.3 artinya item-item variable adalah valid b. Apabila r < 0.3 artinya item-item variable adalah tidak valid
- Reliabilitas
Reabilitas berarti dapat diandalkan atau konsistensi, artinya hasil numeric yang dihasilkan oleh suatu indicator tidak bervariasi karena karakteristik dari proses pengukuran atau alat pengukur itu sendiri (Neuman, 2000, p164). Kuesioner sebagai suatu alat yang digunakan untuk mengukur kepuasan pemakai sistem informasi harus reliable. Analisis ini akan dilakukan setelah melakukan analisis validitas SPSS menggunakan koefisien α dari Cronbach untuk mengkalkulasikan reliablitias.
Menurut Usman (1995, p291) α Cronbach dapat digunakan untuk menguji reliablitas instrument skala likert (1 sampai 5 ) atau instrument yang item-itemnya dalam bentuk essay.
Rumusnya ialah :
Keterangan :
α = reabilitas instrument
N = banyaknya butir pertanyaan
= Jumlah varians butir
= Jumlah varians skor local
Test reabilitas untuk skala Likert paling sering menggunakan analisis item, yaitu untuk masing-masing skor item tertentu dikorelasikan dengans skor totalnya. Menurut Usman (1995, p293) “
a. Apabila r α (positif) atau ≥ 0.7 maka variable tersebut dinyatakan reliable. b. apabila r α (negative) atau ≤ 0.7 maka variable tersebut dinyatakan tidak
reliable.
3.5 Metode Analisis
Model dari penelitian ini adalah mengukur tingkat kepuasan berdasarkan faktor-faktor dari harapan dan kinerja layanan sistem informasi, serta mengukur korelasi variable X dan variable Y. Variable X adalah variable bebas yang berisi variable-variabel yang akan diuji apakah memiliki korelasi dengan variable Y yaitu
kepuasan pengguna. variable X yang akan diuji adalah kinerja layanan sistem informasi perkreditan yang akan dibagi menjadi 6 kategori :
Gambar 3.2 Model Analisis Penelitian
Sedangkan persamaan regresi untuk penelitian ini dapat digambarkan sebagai berikut :
Keterangan :
Y = Variabel user satisfaction (Dependent)
βo = Konstanta
β1 =Kemiringan
E = Error
X1 = Variabel Informativeness (Independent)
X2 = Variabel Information Format (Independent)
X3 = Variabel Easy of Use (Independent)
X4 = Variabel Timeliness (Independent)
X5 = Variabel Reliability (Independent)
X6 = Variabel User Background (Independent)
3.6 Variabel Penelitian
Dalam penelitian ini terdapat 2 variabel, yaitu variable bebas (Xi) yang berupa
kinerja sistem informasi perkreditan dan variable terikatnya (Y) berupa tingkat kepuasan pemakai dimana tingkat kepuasan tergantung pada semua aspek yang dimiliki oleh sistem informasi perkreditan tersebut dapat memnuhi kebutuhan pemakai atau tidak.
variable bebas adalah faktor-faktor sistem informasi perkreditan KPWN yang diukur dengan :
- Informativeness : mengukur apakah sistem infromasi menyediakan informasi yang sesuai dengan kebutuhan pemakai. komponen-komponen dari informativeness adalah sebagai berikut :
a. Sistem informasi yang dapat menydiakan informasi yang sesuai dengan kebutuhan operasional pemakai sisfo
b. Informasi yang dihasilkan oleh sistem informasi berguna bagi pemakai c. Informasi yang akurat singkat, padat, jelas dan terinci
- Information format : mengukur apakah sistem informasi menyediakan format yang baik, komponen-komponen dari information format adalah sebagai berikut :
a. Informasi yang dikeluarkan mudah dibaca dan dimengerti b. Output yang dihasilkan sesuai dengan kebutuhan pemakai
c. Menimbulkan satu persepsi bagi pemakai yang membaca hasil atau output dari sistem informasi
- Easy of use : mengukur informasi yang digunakan sangat mudah dilakukan oleh pemakai. komponen-komponen dari Easy of use adalah sebagai berikut : a. User friendly
b. Mudah digunakan c. Mudah dipelajari
- Timeliness : mengukur apakah sistem informasi yang tersedia yang memiliki ketepatan dan kecepatan waktu proses yang baik. komponen-komponen dari timeliness adalah sebagai berikut :
a. Informasi yang diterima selalu tepat waktu b. Selalu menerima informasi terbaru
c. Informasi yang cepat yang dapat mendukung pengambilan keputusan
- User background : mengukur apakah sistem informasi yang tersedia dipengaruhi oleh latar belakang formal maupun informal dari si pemakai. komponen-komponen user background yang akan digunakan dalam penelitian ini adalah sebagai berikut :
a. Usia
b. Pengalaman Kerja
c. Latar Belakang Pendidikan Formal d. Latar Belakang Jurusan Pendidikan e. Pelatihan Sistem
f. Lama Penggunaan Komputer
- Reliability : mengukur apakah sistem informasi yang tersedia dapat diandalkan. komponen-komponen dari reliability adalah sebagai berikut :
a. Informasi yang dapat diandalkan
b. Informasi yang berguna sebagai pengambilan keputusan dan pemecahan masalah
c. Informasi yang dapat digunakan untuk membantu merancang strategi perusahaan
d. Informasi yang relevan dan terperinci
e. Informasi yang tidak mengambang, tidak berulang-ulang f. Informasu yang sesuai dengan keadaan yang sebenarnya
Variabel terikat adalah kepuasan pemakai sistem informasi perkreditan Koperasi Perumahan Wanabakti Nusantara (KPWN)
3.7 Hipotesis
Hipotesis yang dirumuskan dalam penelitian ini adalah hubungan antara berbagai faktor dan tentang kesenjangan untuk berbagai kualitas system informasi terhadap tingkat kepuasan pengguna system informasi.
Hipotesis mengenai kesenjangan berbagai faktor, adalah :
1. Ada kesenjangan yang signifikan antara harapan dengan kinerja untuk faktor informativeness.
2. Ada kesenjangan yang signifikan antara harapan dengan kinerja untuk faktor information format.
3. Ada kesenjangan yang signifikan antara harapan dengan kinerja untuk faktor easy of use.
5. Ada kesenjangan yang signifikan antara harapan dengan kinerja untuk faktor reliability.
Hipotesis untuk analisis regresi, adalah :
6. Ada pengaruh signifikan antara informativeness sistem informasi perkreditan KPWN dengan kepuasan pemakai.
7. Ada pengaruh signifikan antara information format sistem informasi perkreditan KPWN dengan kepuasan pemakai.
8. Ada pengaruh signifikan antara easy of use sistem informasi perkreditan KPWN dengan kepuasan pemakai.
9. Ada pengaruh signifikan antara timeliness sistem informasi perkreditan KPWN dengan kepuasan pemakai.
10. Ada pengaruh signifikan antara reliability sistem informasi perkreditan KPWN dengan kepuasan pemakai.
Hipotesis untuk analisis Chi-Square, adalah :
11. Ada pengaruh signifikan antara Usia pengguna sistem informasi perkreditan KPWN dengan kepuasan pemakai.
12. Ada pengaruh signifikan antara Pengalaman Kerja pengguna sistem informasi perkreditan KPWN dengan kepuasan pemakai.
13. Ada pengaruh signifikan antara Latar Belakang Pendidikan Formal pengguna sistem informasi perkreditan KPWN dengan kepuasan pemakai.
14. Ada pengaruh signifikan antara Latar Belakang Jurusan Pendidikan pengguna sistem informasi perkreditan KPWN dengan kepuasan pemakai.
15. Ada pengaruh signifikan antara Pelatihan pengguna sistem informasi perkreditan KPWN dengan kepuasan pemakai.
16. Ada pengaruh signifikan antara Penggunaan komputer dengan kepuasan pemakai.
3.8 Analisis Kesenjangan
Model analisis kesenjangan digunakan untuk mengukur tingkat kepuasan pemakai sisfo. nilai tingkat kepuasan diadapat dengan cara menghitung selisih antara
nilai rata-rata harapan (Xh) dengan nilai rata-rata kinerja (Xk)
Rumus dari kesenjangan adalah :
Kesenjangan yang akan dihitung adalah kesenjangan antara harapan dan kinerja untuk variable X1 sampai X6 sehingga dapat diketahui tingkat kepuasan karyawan terhadap 6 variabel tersebut.
Uji statistik ini digunakan untuk mengetahui rata-rata dari besarnya kepuasan pelanggan terhadap variable Informativeness, Information format, timeliness, easy of use, reliability, dan user background. uji ini dilakukan paired sample t-test adalah sebuah sample dengan subyek yang sama namun mengalami dua perlakuan atau pengukuran yang berbeda.
t = D / Sd / √n , D = Xk – Xh
Ho : μ1 = μ2 (tidak ada gap)
H1 : μ1 < μ2 (ada gap antara kinerja < harapan)
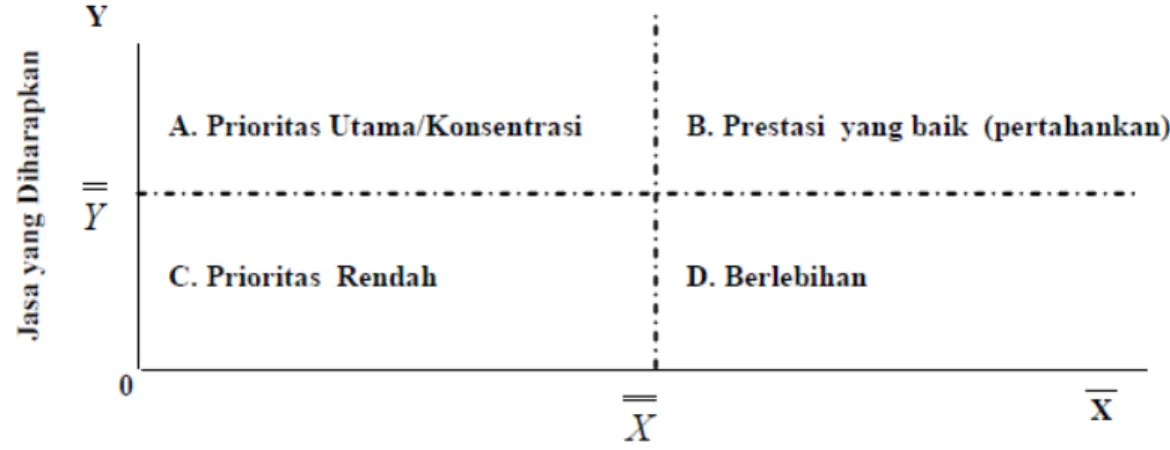
Diagram Kartesius Kinerja - Harapan
Menurut Kotler (1997:95), jasa dapat diperingkat menurut kepentingan pelanggan (Customer Importance) dan kinerja perusahaan (Company Performance). Kepentingan diperingkat dengan skala empattitik, seperti; sangat penting, penting, kurang penting,dan tidak penting. Sedangkan kinerja juga diperingkatdengan skala empat titik, seperti: sangat baik, baik,kurang baik, dan tidak baik.
Dalam pelaksanaan penelitian, metode ini akandigunakan untuk menganalisis secara deskriptif kualitas jasa, dilihat berdasarkan tingkat kesesuaian antara jasa yang diharapakan (kepentingan konsumen) dengan jasa yang dirasakan (kinerja perusahaan).
Tingkat kesesuaian yang dimaksud dalam pelaksanan penelitian adalah hasil perbandingan skor nilai jasa yang diharapkan (kepentingan konsumen) dengan skor nilai jasa yang dirasakan (kinerjaperusahaan). Formula yang digunakan untuk penilaian tingkat kesesuaian adalah:
Keterangan:
Tki = Tingkat kesesuaian
Yi = Skor penilian jasa yang diharapan **
* Simbol Xi tidak diartikan sebagai variabel independent.
** Simbol Yi tidak diartikan sebagai variabel dependent.
Untuk sumbu mendatar (X) merupakan skor untuk jasa yang dirasakan, sedangkan untuk sumbu tegak (Y) merupakan skor untuk jasa yang diharapkan.
Skor-skor penilaian tersebut akan disederhanakan untuk mendapatkan nilai rata-rata masing-masing faktor. Penyederhanaan masing-masing faktor penilaian tersebut dengan menggunakan formula sebagai berikut:
Keterangan:
Xi = Skor penilaian jasa yang dirasakan
Yi = Skor penilaian jasa yang diharapankan
X = Skor rata-rata penilaian jasa yang dirasakan
Y = Skor rata-rata penilaian jasa yang diharapkan
rata-rata dari rata-rata skor jasa yang dirasakan, dan Y adalah rata-rata dari rata-rata skor jasa yang diharapkan. Untuk jelasnya rumus yang dimaksud adalah:
Gambar 3.3 Diagram Kartesius Kinerja dan Harapan
Keterangan:
X = Skor rata-rata penilaian jasa yang dirasakan
Y = Skor rata-rata penilaian jasa yang diharapkan
X = Rata-rata skor rata-rata penilaian jasa yang
dirasakan
Y = Rata-rata skor rata-rata penilaian jasa yang
diharapkan
Masing-masing dimensi penilaian baik skor ratarata penilaian jasa yang dirasakan (X) maupun skor rata-rata penilaian jasa yang diharapkan (Y) dijabarkan ke dalam empat bagian Diagram Kartesius.
3.9 Analisis Regresi
3.9.1 Regresi Berganda
Analisis regresi berganda digunakan oleh peneliti karena tujuan penelitian adalah meramalkan bagaimana bergeraknya variable dependen, bila dua atau lebih cariabel independen sebagai faktor predictor digerakkan nilainya. Jadi analisis regresi ganda akan digunakan karena jumlah variable independen-nya terdiri dari 6 variabel. Perhitungan dilakukan dengan menggunakan analisis korelasi dan regresi berganda, yaitu menganalisis hubungan variable tak bebas Y dengan beberapa variable bebas, yang bertujuan untuk mengetahui kuatnya hubungan antara beberapa variable bebas X (X1…X6) secara serentak terhadap variable tak bebas Y dengan menggunakan koefisien berganda.
3.9.2 Uji Penyimpangan Regresi
Dalam melakukan perhitungan statistic menggunakan teknik regresi, terdapat beberapa asumsi yang perlu dikaji ulang. Hal ini untuk memperoleh gambaran pasti apakah hasil pengujian statistic tersebut adalah valid. Oleh sebab itu, setelah regresi dilakukan pengujian tambahan yaitu multikolinearitas, atuokorelasi, maupun
3.9.2.1 Pengujian Multikolinearitas
Pengujian multikolinearitas bertujuan untuk mengetahui apakah variable independen yang ada memang benar-benar mempunyai pengaruh yang erat dengan variable dependen sehingga variable indpenden benar-benar dapat menjelaskan lebih pasti bagi variable dependen. Dengan menggunakan software SPSS yang sudah menyediakan fasilitas pengujian ini maka disini juga akan digunakan variance inflation faktor (VIF) yang merupakan kebalikan dari toleransi.
3.9.2.2 Pengujian Autokorelasi
Pengujian autokorelasi merupakan kondisi dimana kesalahan pengaggu (varian e) saling berkolerasi dan hal ini terjadi apabila terdapat hubungan yang signifikan antar dua data yang berdekatan. Kenyatan yang diharapkan adalah autokorelasi itu tidak ada. Adanya korelasi mengakibatkan estimatornya menjadi konsisten. Tidak bias, tetapi tidak efisien karena interval estimasinya akan melebar sehingga daya prediksinya menjadi underestimate, dan menyebabkan F yang diperoleh tidak valid. Keberadaan autokorelasi dapat di identifikasikan melalui analisis korelasi dengan menggunakan metoda grafik atau secara statistic dikenal dengan statistic dari Durbin Watson.
3.9.2.3 Pengujian Heteroskedatisitas
Pengujian ini akan terjadi bila ada varian e (gangguan/disturbance) tidak mempunyai penyebaran yang sama, sehingga model yang sudah dibuat menjadi kurang efisien. Asumsi yang diharapkan untuk terpenuhi dalam kenyataan adalah bahwa variasi error dari peramalannya homogen bukan heterogen.
3.10 Analisis Chi-Square
J chi-square test (chi-squared juga atau χ 2 test) adalah statistik uji hipotesa yang memiliki uji statistik distribusi chi-square bila null hipotesa yang dianggap yang benar, atau di mana kemungkinan distribusi ujian statistik ( menganggap hipotesa null yang benar) dapat dibuat untuk perkiraan yang distribusi chi-square semaksimal yang diinginkan dengan membuat sampel ukuran yang cukup besar.
Beberapa contoh uji chi-squared dimana chi-square distribusi hanya berlaku kira-kira:
• Pearson's chi-square test, juga dikenal sebagai chi-square goodness-of-fit test atau chi-square untuk menguji independensi. Ketika disebutkan tanpa Modifiers atau lainnya tanpa precluding konteks, tes ini biasanya dipahami.
• Yates' chi-square test, juga dikenal sebagai Yates' koreksi untuk kontinuitas.
• Mantel-Haenszel chi-square test. Mantel Haenszel-chi-square test.
• Linear-by-linear association chi-square test. Linear-by-linear association chi-square test.
• Yang koper tes dalam waktu-seri analisis, pengujian untuk keberadaan autocorrelation
• Tes Rasio Kemungkinan umum dalam statistik modelling, untuk menguji apakah ada bukti yang perlu untuk berpindah dari yang sederhana untuk model yang lebih rumit satu (dimana model sederhana
Untuk kasus dimana distribusi ujian statistik yang tepat adalah chi-square distribusi adalah ujian yang berbeda dari biasanya didistribusikan-populasi memiliki nilai diberikan berdasarkan sampel berbeda. Seperti tes jarang dalam prakteknya karena nilai variances untuk menguji terhadap yang jarang diketahui persis.
Chi-square untuk menguji perbedaan dalam populasi normal
Jika contoh ukuran x diambil dari populasi yang memiliki distribusi normal, maka ada dikenal hasil (lihat pembagian sampel variance) yang memungkinkan untuk dilakukan tes apakah yang berbeda dari populasi mempunyai nilai sebelumnya. Sebagai contoh, sebuah proses manufaktur mungkin sudah dalam kondisi stabil dalam waktu yang panjang, sehingga nilai yang berbeda akan ditentukan pada dasarnya tanpa kesalahan. Misalnya yang berbeda dari proses sedang diuji, sehingga menimbulkan sampel beberapa item produk yang variasi yang akan diuji. Ujian statistik T dalam contoh ini dapat diatur untuk menjadi squares tentang jumlah sampel mean, dibagi dengan nilai nominal yang berbeda (yaitu nilai yang akan diuji sebagai holding). Kemudian T mempunyai distribusi chi-square dengan n -1 derajat kebebasan. Misalnya jika ukuran sampel adalah 21, maka penerimaan daerah untuk T untuk tingkat signifikansi 5% adalah 9,59 interval ke 34,17.