40
Menurut Nuryaman & Veronica (2015:5), objek penelitian adalah
karakteristik, ciri, sifat, keadaan yang melekat pada beberapa subjek, yang nilainya
dapat berbeda-beda antar subjek satu dengan lainnya.
Objek pada penelitian ini adalah laporan keuangan tahunan pada perusahaan
manufaktur sektor aneka industri yang terdaftar di Bursa Efek Indonesia (BEI)
untuk periode 2015-2017.
1.2 Populasi dan Sampel Penelitian
1.2.1 Populasi Penelitian
Populasi mengacu pada keseluruhan kelompok orang, kejadian, atau hal-hal
menarik yang ingin peneliti investigasi. Populasi adalah kelompok orang, kejadian,
atau hal-hal menarik dimana peneliti ingin membuat opini (berdasarkan sampel)
(sekaran, 2017:53).
Populasi dalam penelitian ini adalah perusahaan manufaktur sektor aneka
industri yang terdaftar di Bursa Efek Indonesia (BEI) pada tahun 2015-2017.
1.2.2 Sampel Penelitian
Menurut Nazir (2014:240) sampel adalah suatu prosedur dimana hanya
sebagian dari populasi saja yang diambil dan dipergunakan untuk menentukan sifat
serta ciri yang dikendaki dari populasi.
Metode penarikan sampel pada penelitian ini adalah metode nonprobability
sampling dengan menggunakan teknik purposive sampling. Nonprobability sampling merupakan teknik sampling yang tidak semua unsur atau elemen populasi mempunyai kesempatan yang sama untuk bisa dipilih menjadi objek sampel
(Nuryaman dan Veronica, 2015:109).
Teknik purposive sampling merupakan teknik pengambilan sampel yang
digunakan peneliti berdasarkan kriteria atau tujuan tertentu (Sumarni dan Wahyuni,
2006:77). Sampel penelitian diambil dari populasi laporan keuangan perusahaan
manufaktur sektor aneka industri yang terdaftar di Bursa Efek Indonesia dengan
kriteria sampel yang diperlukan, yaitu:
1. Perusahaan manufaktur sektor aneka industri yang terdaftar di BEI
secara berturut-turut untuk periode 2015-2017.
2. Perusahaan manufaktur sektor aneka industri yang terdaftar di BEI
tersebut telah menerbitkan laporan keuangan atau laporan tahunan
(annual report) untuk periode 2015-2017.
3. Perusahaan manufaktur sektor aneka industri yang menyusun laporan
keuangan dengan satuan mata uang rupiah untuk periode 2015-2017.
Berdasarkan laporan kinerja keuangan perusahaan yang dipublikasikan oleh
di Bursa Efek Indonesia adalah 43 perusahaan. Perusahaan tersebut diseleksi
kembali sesuai dengan kriteria yang sudah ditetapkan. Seleksi sampel penelitian
disajikan pada tabel 3.1 berikut:
Tabel 3.1
Proses Pemilihan Sampel
No. Kriteria
Jumlah Perusahaan 1. Perusahaan manufaktur sektor aneka industri yang terdaftar di BEI. 43 2. Perusahaan manufaktur sektor aneka industri yang tidak terdaftar di BEI
secara berturut-turut untuk periode 2015-2017.
(0) 3. Perusahaan manufaktur sektor aneka industri yang terdaftar di BEI
tersebut tidak menerbitkan laporan keuangan atau laporan tahunan (annual report) untuk periode 2015-2017.
(2)
4. Perusahaan manufaktur sektor aneka industri yang tidak menyusun laporan keuangan dengan satuan mata uang rupiah untuk periode 2015-2017.
(15)
Jumlah sampel penelitian 26
Tahun observasi 3
Jumlah observasi 2015-2017 78
Sumber: www.idx.co.id (data diolah)
Berdasarkan kriteria-kriteria penentuan sampel tersebut, maka sampel
penelitian yang terpilih adalah sebanyak 26 perusahaan. Pengamatan pada sampel
penelitian dilakukan pada laporan tahunan perusahaan selama 3 tahun, yaitu dari
tahun 2015-2017, sehingga total pengamatan dalam penelitian ini adalah 78 laporan
tahunan. Daftar sampel penelitian disajikan pada tabel 3.2 sebagai berikut:
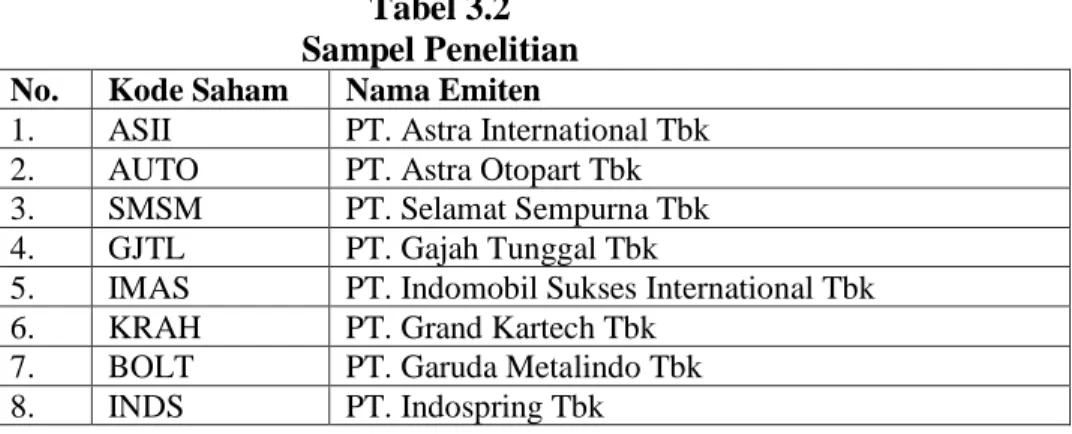
Tabel 3.2 Sampel Penelitian No. Kode Saham Nama Emiten
1. ASII PT. Astra International Tbk 2. AUTO PT. Astra Otopart Tbk 3. SMSM PT. Selamat Sempurna Tbk 4. GJTL PT. Gajah Tunggal Tbk
5. IMAS PT. Indomobil Sukses International Tbk 6. KRAH PT. Grand Kartech Tbk
7. BOLT PT. Garuda Metalindo Tbk 8. INDS PT. Indospring Tbk
9. KBLI PT. KMI Wire and Cable Tbk 10. VOKS PT. Voksel Electric Tbk 11. BATA PT. Sepatu Bata Tbk 12. NIPS PT. Nipress Tbk
13. STAR PT. Star Petrochem Tbk 14. AMIN PT. Atmindo Tbk
15. HDTX PT. Panasia Indo Resources Tbk 16. TRIS PT. Trisula International Tbk 17. KBLM PT. Kabelindo Murni Tbk
18. PRAS PT. Prima Alloy Steel Universal Tbk 19. RICY PT. Ricky Putra Globalindo Tbk 20. LPIN PT. Multi Prima Sejahtera Tbk 21. UNIT PT. Nusantara Inti Corpora Tbk
22. SCCO PT. Supreme Cable Manufacturing Corporation Tbk 23. JECC PT. Jembo Cable Company Tbk
24. MYTX PT. Asia Pacific Investama Tbk 25. SSTM PT. SunsonTextile Manufacturer Tbk 26. BIMA PT. Primarindo Asia Infrastucture Sumber: www.idx.co.id (data diolah)
3.3 Metode Pengumpulan Data
3.3.1 Jenis dan Sumber Data
Menurut Nuryaman dan Christina (2015:79) menyebutkan bahwa jenis dan
penelitian terdiri dari:
1. Data Primer
Data primer adalah data yang diperoleh langsung dari sumber data, yaitu
subjek atau benda.
2. Data Sekunder
Data sekunder adalah data yang tersedia dan dibuat oleh pihak tertentu
dalam bentuk dokumen.
Menurut Sugiyono (2017:137) menyebutkan bahwa sumber data penelitian
1. Sumber Primer
Sumber data yang langsung memberikan data kepada pengumpul data.
2. Sumber Sekunder
Sumber data yang tidak langsung memberikan data kepada pengumpul data,
misalnya lewat orang lain atau pengumpul data.
Jenis data yang digunakan dalam penelitian ini adalah data sekunder berupa
laporan keuangan tahunan perusahaan manufaktur sektor aneka industri yang
terdaftar di Bursa Efek Indonesia periode 2015-2017. Sedangkan sumber data
dalam penelitian ini adalah data sekunder yang bersumber dari www.idx.co.id.
3.3.2 Teknik Pengumpulan Data
Teknik pengumpulan data merupakan langkah yang paling strategis dalam
penelitian, karena tujuan utama dari penelitian adalah mendapatkan data (Sugiyono,
2017:225). Teknik pengumpulan data yang dilakukan penulis dalam penelitian ini
adalah sebagai berikut:
1. Studi Kepustakaan (Library Research)
Studi kepustakaan dilakukan untuk memperoleh landasan teori yang
berhubungan dengan masalah yang diteliti. Penelitian ini dilakukan
dengan membaca, menelaah dan meneliti jurnal-jurnal, buku dan
literature lainnya yang berhubungan erat dengan topik pada penelitian
ini sehingga memperoleh informasi sebagai dasar teori dan acuan untuk
2. Studi Dokumentasi
Penelitian ini menggunakan metode dokumentasi yaitu dengan cara
mengumpulkan data tentang dokumen-dokumen yang berhubungan
dengan penelitian ini. Data yang digunakan dalam penelitian ini adalah
laporan keuangan yang bersumber dari situs web Bursa Efek Indonesia.
Teknik pengumpulan data yang dilakukan dalam penelitian ini dilakukan
dengan studi kepustakaan untuk memenuhi literatur teori dan studi dokumentasi
untuk mengumpulkan laporan keuangan tahunan perusahan manufaktur sektor
aneka industri yang terdaftar di Bursa Efek Indonesia periode 2015-2017.
3.4 Operasionalisasi Variabel Penelitian
Operasionalisasi variabel adalah kegiatan atau proses yang dilakukan
peneliti untuk mengurangi tingkat abstraksi konsep sehingga konsep tersebut dapat
diukur (Zulganef, 2008:84). Sedangkan menurut Neuman dalam Zulganef
(2008:85) mengungkapkan bahwa operasionalisasi adalah suatu proses
mengkaitkan (linking) definisi konseptual dengan seperangkat teknik pengukuran
atau prosedur pengukuran.
Untuk menguji hipotesis yang diajukan, variabel yang diteliti dalam
penelitian ini diklasifikasikan menjadi:
1. Variabel Independen (X)
Variabel independen atau variabel bebas adalah variabel yang
mempengaruhi atau yang menjadi sebab perubahannya atau timbulnya
menjadi variabel independen adalah profitabilitas, leverage, dan ukuran
perusahaan.
2. Variabel dependen (Y)
Variabel dependen atau variabel terikat adalah variabel yang
dipengaruhi atau yang menjadi akibat, karena adanya variabel
independen (Sugiyono, 2017:39). Pada penelitian ini yang menjadi
variabel dependen adalah tax avoidance.
Tabel 3.3
Operasionalisasi Variabel Penelitian
Variabel Konsep Indikator Skala
Profitabilitas (X1) Profitabilitas merupakan rasio yang menggambarkan kemampuan perusahaan dalam menghasilkan laba melalui semua kemampuan dan sumber daya yang dimilikinya berasal dari kegiatan penjualan, penggunaan asset, maupun penggunaan modal. Menurut Hery (2016:192). 𝑅𝑂𝐴 =𝐿𝑎𝑏𝑎 𝑠𝑒𝑏𝑒𝑙𝑢𝑚 𝑏𝑢𝑛𝑔𝑎 𝑑𝑎𝑛 𝑝𝑎𝑗𝑎𝑘 𝑇𝑜𝑡𝑎𝑙 𝐴𝑘𝑡𝑖𝑣𝑎 Sujarweni (2017:65) Rasio Leverage (X2) Leverage merupakan rasio yang digunakan untuk mengukur sejauh mana aktiva perusahaan 𝐷𝐸𝑅 =𝑇𝑜𝑡𝑎𝑙 𝑈𝑡𝑎𝑛𝑔 𝑇𝑜𝑡𝑎𝑙 𝑀𝑜𝑑𝑎𝑙× 100% Hery (2016:168) Rasio
dibiayai dengan utang. Menurut Kasmir (2017:151). Ukuran Perusahaan (X3) Ukuran perusahaan adalah besar kecilnya perusahaan dilihat dari besarnya nilai equity, nilai penjualan atau nilai aktiva. Menurut Riyanto (2010:343). Size = 𝐿𝑛 (𝑇𝑜𝑡𝑎𝑙 𝐴𝑠𝑠𝑒𝑡) Jogiyanto (2013:282) Rasio Tax Avoidance (Y) Upaya penghindaran pajak yang dilakukan secara legal dan aman bagi wajib pajak karena tidak bertentangan dengan ketentuan perpajakan, dimana metode dan teknik yang digunakan cenderung memanfaatkan kelemahan-kelemahan (grey area) yang terdapat dalam undang-undang dan peraturan perpajakan itu sendiri, untuk memperkecil jumlah pajak yang terutang. Menurut Pohan (2016:23). 𝐶𝐸𝑇𝑅 = 𝑃𝑒𝑚𝑏𝑎𝑦𝑎𝑟𝑎𝑛 𝑝𝑎𝑗𝑎𝑘 𝐿𝑎𝑏𝑎 𝑠𝑒𝑏𝑒𝑙𝑢𝑚 𝑝𝑎𝑗𝑎𝑘 Dyreng, et.al (2010) Rasio
3.5 Metode Analisis Data
Analisis data yang digunakan dalam penelitian ini adalah analisis
kuantitatif. Analisis kuantitatif adalah metode penelitian yang berlandaskan pada
filsafat positivisme, digunakan untuk meneliti pada populasi atau sampel tertentu,
pengumpulan data menggunakan instrument penelitian, analisis data bersifat
kuantitatif/statistik, dengan tujuan untuk menguji hipotesis yang telah ditetapkan
(Sugiyono, 2017:13). Metode analisis data yang digunakan dalam penelitian ini
adalah analisis multivariate. Analisis multivariate adalah analisis beberapa variabel
dalam satu hubungan atau himpunan hubungan (Hair et al, 2010:2). Analisis
multivariate yang digunakan dalam penelitian ini yaitu analisis regresi linear berganda dengan menggunakan model data panel (regresi data panel) dengan
bantuan Software Eviews 9.
3.5.1 Analisis Statistik Deskriptif
Analisis statistik deskriptif adalah statistik yang digunakan untuk
menganalisa data dengan cara mendeskripsikan atau menggambarkan data yang
telah terkumpul sebagai mana adanya tanpa bermaksud membuat kesimpulan yang
berlaku untuk umum atau generalisasi (Sugiyono, 2017:29). Pada penelitian ini,
penulis akan mendeskripsikan untuk variabel profitabilitas (ROA), leverage (DER),
ukuran perusahaan (SIZE), dan tax avoidance perusahaan manufaktur sektor aneka
3.5.2 Analisis Regresi Data Panel
Menurut Sujarweni (2015:92) data panel adalah gabungan antara data seksi
silang (cross section) dan data runtut waktu (time series). Dalam penelitian ini,
variabel yang tergolong ke dalam variabel bebas (X) yaitu profitabilitas, leverage,
dan ukuran perusahaan sedangkan variabel terikatnya (Y) yaitu tax avoidance.
Metode analisis yang digunakan dalam penelitian ini adalah model regresi data
panel yang persamaannya dapat dituliskan sebagai berikut:
Yit = a + β1X1
it
+ β2X2it +
𝑒it Keterangan: Y = Tax Avoidance a = Konstanta X1 = Profitabilitas X2 = Leverage X3= Ukuran Perusahaan β = Koefisien arah garise = Error term
t = Waktu
i = Perusahaan
Nilai koefisien regresi disini sangat menentukan sebagai dasar analisis. Jika koefisien β positif (+) maka hal tersebut menunjukkan pengaruh searah antara
variabel independen dengan variabel dependen, setiap kenaikan nilai variabel
independen akan mengakibatkan kenaikan variabel dependen. Sedangkan, bila koefisien β bernilai negatif (-) maka menunjukkan adanya pengaruh negatif dimana
kenaikan nilai variabel independen akan mengakibatkan penurunan nilai variabel
dependen.
3.5.3 Pemilihan Model Regresi Data Panel
Terdapat tiga pendekatan dalam perhitungan model regresi yaitu model
common effect model (Pool Least Square/PLS),fixed effect model (FEM), dan random effect model (REM). Berdasarkan hasil ketiga model yang telah diestimasi akan dipilih model mana yang paling tepat atau sesuai dengan tujuan penelitian.
Ada tiga uji yang digunakan untuk memilih teknik estimasi data panel, yaitu: Uji
Chow dan Uji Hausman, Uji Langrange Multiplier (Widarjono, 2017:70).
3.5.3.1 Uji Chow
Uji chow digunakan untuk menentukan apakah model data panel diregresi
dengan model common effect atau model fixed effect (Widarjono, 2017:71).
Hipotesis dalam uji ini adalah sebagai berikut:
H0:Common Effect Model
H1:Fixed Effect Model
Keterangan :
1. Jika nilai probabilitas Cross-sectionChi-square< 0,05 ; maka H0 ditolak
2. Jika nilai probabilitas Cross-sectionChi-square> 0,05 ; maka H0 diterima
Pengujian dilakukan untuk menguji model data panel yang cocok untuk
digunakan antara model common effect atau model fixed effect. Setelah terpilih
selanjutnya yaitu uji hausman untuk memastikan bahwa model data panel yang
cocok sama dengan uji chow.
3.5.3.2 Uji Hausman
Uji hausman digunakan untuk menentukan apakah model data panel
diregresi dengan model fixed effect atau dengan model random effect (Widarjono,
2017:73). Dalam data panel dapat terjadi gangguan baik antar waktu (time series),
antar individu (cross-section) ataupun keduanya. Dengan adanya gangguan
tersebut, terdapat dua alternatif metode dalam menaksir niali regresi yaitu fixed
effect model (FEM) dan random effect model (REM). Untuk gangguan antar individu (cross-section) bersifat tetap maka digunakan fixed effect model (FEM)
dan jika bersifat acak maka digunakan random effect model (REM), hipotesis dalam
uji ini adalah sebagai berikut:
H0 : Random Effect Model
H1 : Fixed Effect Model
Keterangan :
1. Jika Probabilitas Cross-Section Chi Square < 0,05 ; maka H0 ditolak
2. Jika Probabilitas Cross-section Chi Square > 0,05 ; maka H0 diterima
Pengujian dilakukan untuk menguji model data panel yang cocok untuk
digunakan antara model fixed effect atau model random effect. Jika model data
panel yang diperoleh dalam uji hausman sama dengan model data panel yang di uji
dalam uji chow, maka tidak perlu dilakukan dengan pengujian lanjutan yaitu
hasil yang berbeda maka perlu dilakukan pengujian lanjutan yaitu uji langrange
multiplier.
3.5.3.3 Uji Langrange Multiplier
Uji ini digunakan untuk menentukan apakah model data panel diregresi
dengan model data panel diregresi dengan model common effect atau model
random effect (Widarjono, 2017:75). Hipotesis dalam uji ini adalah sebagai berikut:
H0 : Common Effect Model
H1 : Random Effect Model
Keterangan:
1. Jika nilai profitabilitas breusch-pagan < 0,05 ; maka H0 ditolak
2. Jika nilai profitabilitas breusch-pagan > 0,05 ; maka H0 diterima
Pengujian dilakukan untuk menguji model data panel yang cocok untuk
digunakan antara model common effect atau model random effect. Uji langrange
multiplier dilakukan apabila hasil model data panel yang dihasilkan pada uji chow dan uji hausman tidak sesuai, maka diperlukan uji langrange multiplier.
3.5.4 Pengujian Asumsi Klasik
Pengujian regresi linear dapat dilakukan setelah model dari penelitian ini
memenuhi syarat-syarat yaitu lolos dari asumsi klasik. Untuk itu sebelum
melakukan pengujian hipotesis dengan analisis regresi linear, harus dilakukan uji
klasik terlebih dahulu. Uji asumsi klasik dalam penelitian ini digunakan untuk
menguji kesalahan model regresi yang digunakan dalam penelitian. Uji asumsi
klasik merupakan syarat yang harus dipenuhi agar persamaan regresi dapat
regresi yang dihasilkan akan valid jika digunakan pada persamaan regresi. Hal ini
sejalan dengan pendapat Santosa (2012:342) tentang uji asumsi klasik sebagai
berikut:
“Sebuah model regresi akan digunakan untuk melakukan peramalan, sebuah model yang baik adalah model dengan kesalahan peramalan yang seminimal mungkin. Karena itu, sebuah model sebelum digunakan seharusnya memenuhi beberapa asumsi, yang biasa disebut asumsi klasik. Pengujian asumsi klasik ini dilakukan terlebih dahulu sebelum pembentukan model regresi, supaya model regresi yang terbentuk akan menghasilkan estimasi yang BLUE (best linier unbiased estimator).”
Pengujian yang digunakan adalah uji normalitas, uji multikolinearitas, uji
heteroskedastisitas, dan uji autokorelasi. Pengujian asumsi klasik dijelaskan yaitu
sebagai berikut:
3.5.4.1 Uji Normalitas
Sebelum dilakukan uji statistik, terlebih dahulu perlu diketahui apakah
sampel yang dipergunakan berdistribusi normal atau tidak. Menurut (Ghozali,
2013:160), uji normalitas bertujuan untuk menguji apakah dalam model regresi,
variabel dependen dan variabel independen keduanya mempunyai distribusi normal
ataukah tidak. Seperti diketahui bahwa uji t dan f mengasumsikan bahwa nilai
residual mengikuti distribusi normal, jika asumsi ini dilanggar maka uji statistik
menjadi tidak valid untuk jumlah sampel kecil. Data yang baik dan layak digunakan
dalam penelitian ini adalah data yang memiliki distribusi normal. Pengujian
normalitas dalam penelitian ini menggunakan software Eviews.
Dalam software Eviews, normalitas sebuah data dapat dilihat dari gambar
histogram, namun seringkali polanya tidak mengikuti bentuk kurva normal,
dan Probabilitasnya. Kedua angka ini bersifat saling mendukung. Jarque-Bera
adalah uji statistic utuk mengetahui apakah data berdistribusi normal (Winarno,
2015). Terdapat dua cara untuk melihat apakah data berdistribusi normal, yaitu:
a. Bila nilai J-B tidak signifikan (lebih kecil dari chi square table), maka
data berdistribusi normal.
b. Bila probabilitas lebih besar dari 5% (tingkat signifikansi), maka data
berdistribusi normal.
3.5.4.2 Uji Multikolinearitas
Menurut Ghozali (2013:105), uji multikolinearitas bertujuan untuk menguji
apakah model regresi ditemukan adanya korelasi antar variabel bebas (independen).
Model regresi yang baik seharusnya tidak terjadi korelasi di antara variabel
independen. Jika variabel independen saling berkolerasi, maka variabel-variabel ini
tidak orthogonal. Variabel orthogonal adalah variabel independen yang nilai
korelasi antar sesama variabel independen sama dengan nol.
Uji multikolinearitas dapat dilakukan dengan menggunakan nilai variance
inflation factor (VIF) dan tolerance value. Secara umum dapat dikatakan terdapat multikolinearitas jika tolerance value lebih kecil dari 0,10 atau VIF lebih besar
daripada 10. Maka dalam penelitian ini indikator nilai VIF yang digunakan adalah:
a. Jika nilai VIF < 10, maka tidak terdapat multikolinearitas yang serius.
3.5.4.3 Uji Heteroskedastisitas
Menurut Ghozali (2013:139), uji heteroskedastisitas bertujuan untuk
menguji apakah dalam model regresi terjadi ketidaksamaan variance dari residual
satu pengamatan ke pengamatan lain. Jika variance dari residual satu pengamatan
ke pengamatan lain tetap, maka disebut homoskedastisitas dan jika berbeda disebut
heteroskedastisitas. Model regresi yang baik adalah yang tidak terjadi
heteroskedastisitas. Penelitian ini uji heteroskedastisitas dilakukan dengan
menggunakan Uji-White.
Uji white dilakukan dengan meregresikan residual kuadrat sebagai variabel dependen dengan variabel dependen ditambah dengan kuadrat variabel independen,
kemudian ditambahkan lagi dengan perkalian dua variabel independen. Prosedur
pengujian dilakukan dengan hipotesis sebagai berikut:
H0 : Tidak ada heteroskedastisitas
Ha : Ada heteroskedastisitas
Pada tingkat signifikansi 0,05 apabila p-value obs*-square <0,05 maka
terdapat gejala heteroskedastisitas, sebaliknya apabila nilai probabilitas
obs*-square > 0,05 maka tidak terdapat gejala heteroskedastisitas.
3.5.4.4 Uji Autokolerasi
Pengujian ini dilakukan untuk menguji apakah dalam suatu model regresi
linear ada korelasi antara kesalahan pengguna pada periode t dengan kesalahan pada
periode t-1 (Ghozali, 2012:10). Model regresi yang baik adalah regresi yang bebas
dari autokolerasi. Salah satu cara untuk mendeteksi ada tidaknya autokolerasi
tidaknya autokolerasi dengan menggunakan Durbin-Watson adalah sebagai
berikut:
Hipotesis yang akan diuji adalah:
H0 : Tidak ada autokorelasi (r=0)
Ha : Ada autokolerasi (r≠0)
Pengambilan keputusan ada tidaknya autokolerasi dapat dilihat dalam tabel
3.4 sebagai berikut:
Tabel 3.4
Kriteria pengambilan keputusan Uji Durbin Watson
Hipotesis Nol Keputusan Jika
Tidak ada autokolerasi positif Tolak 0 < d < dl Tidak ada autokolerasi positif No decision dl ≤ d ≤ du
Tidak ada autokolerasi negatif Tolak 4-dl < d < 4 Tidak ada autokolerasi negatif No decision du ≤ d ≤
4-dl Tidak ada autokolerasi positif atau
negatif
Tidak ditolak du < d < 4-du Sumber : (Ghozali, 2013:111)
3.6 Pengujian Hipotesis
3.6.1 Uji Parsial (Uji t)
Menurut Ghozali (2013:98), uji statistik t pada dasarnya menunjukkan
seberapa jauh pengaruh satu variabel penjelas/independen secara individual dalam
menerangkan variasi variabel dependen. Langkah-langkah pengujian dengan
menggunakan Uji t adalah sebagai berikut:
Tingkat signifikansi 0,05 atau 5% artinya kemungkinan besar hasil
penarikan kesimpulan memiliki probabilitas 95% atau toleransi
kesalahan 5%. 2. Menghitung Uji t 𝑡ℎ𝑖𝑡𝑢𝑛𝑔= 𝑏 𝑠𝑏 Keterangan: b : Koefisien kolerasi Sb: Jumlah sampel
3. Kriteria penerimaan dan penolakan hipotesis
a. Tolak H0 dan terima Ha jika thitung > ttabel /-thitung<-ttabel
(berpengaruh)
b. Tidak berhasil menolak H0dan tolak Ha jika nilai thitung< ttabel
/-thitung>-ttabel
(tidak berpengaruh)
Nilai 𝑡𝑡𝑎𝑏𝑒𝑙 didapat dari : df = n-k-1 Keterangan:
n = jumlah observasi
k = variabel independen
Berdasarkan signifikansi dasar pengambilan keputusannya adalah:
a. Jika probabilitas (signifikansi) > 0,05, maka Ho tidak berhasil
ditolak (tidak berpengaruh)
b. Jika probabilitas (signifikansi) < 0,05 maka Ho ditolak
3.6.2 Uji Simultan (Uji F)
Menurut Ghozali (2013:98), uji statistik f digunakan untuk menguji
hubungan regresi secara simultan yang bertujuan untuk mengetahui apakah seluruh
variabel independen bersama-sama mempunyai pengaruh yang signifikan terhadap
variabel dependen. Langkah-langkah pengujian dengan menggunakan uji F adalah
sebagai berikut:
1. Menentukan tingkat signifikansi sebesar 𝛼 = 5%
Tingkat siginifikansi 0,05 atau 5% artinya kemugkinan besar hasil
penarikan kesimpulan memiliki probabilitas 95% atau toleransi
kesalahan 5%. 2. Menghitung Uji F Fhitung= 𝑅 2/k (1 − 𝑅2)/(𝑛 − 𝑘 − 1) Keterangan:
R2 = Koefisien determinasi gabungan
k = Jumlah variabel independen
n = Jumlah sampel
Adapun hipotesis dalam penelitian dirumuskan sebagai berikut:
a. Jika nilai F-hitung > F-tabel, maka variabel X secara simultan
memiliki pengaruh yang signifikan terhadap Y.
b. Jika nilai F-hitung < F-tabel, maka variabel X secara simultan
tidak memiliki pengaruh yang signifikan terhadap Y.
a. Jika nilai probabilitas lebih kecil dari atau sama dengan nilai Sig.(Prob ≤ 0,05) atau F-hitung > F-tabel maka H0 diterima dan artinya berpengaruh signifikan.
b. Jika nilai probabilitas lebih kecil atau sama dengan nilai Sig.
(Prob ≥ 0,05) atau F-hitung < F-tabel maka H0 ditolak yang artinya tidak berpengaruh signifikan.
3.6.3 Uji Koefisien Determinasi (R2)
Koefisien determinasi (R2) pada intinya bertujuan untuk mengukur seberapa
jauh kemampuan model dalan menerangkan variasi variabel dependen. Nilai
koefisien determinasi adalah antara nol dan satu. Nilai (R2) yang kecil berarti
kemampuan variabel-variabel independen dalam mejelaskan variasi variabel
dependen amat terbatas. Nilai yang mendekati satu berarti variabel-variabel
independen memberikan hampir semua informasi yang dibutuhkan untuk
memprediksi variasi variabel dependen. Secara umum koefisien determinasi untuk
data silang (crossection) relatif rendah karena adanya variasi yang besar antara
masing-masing pengamatan, sedangkan untuk data runtun waktu (time series)
biasanya mempunyai nilai koefisien determinasi yang tinggi (Ghozali, 2013:97).
Menurut Riduwan dan Sunarto (2012), koefisien determinasi dapat dirumuskan
sebagai berikut:
KD = R2 ×100% Keterangan:
KD = Koefisien determinasi
3.6.4 Penetapan Tingkat Signifikan
Tingkat signifikan yang ditetapkan dalam penelitian ini adalah sebesar 5%
atau 0,05 karena dinilai cukup untuk menguji suatu hubungan antar
variabel-variabel yang diuji untuk menunjukkan bahwa korelasi antara kedua variabel-variabel cukup
nyata. Tingkat signifikansi 0,05 artinya adalah kemungkinan besar dari hasil
penarikan kesimpulan mempunyai probabilitas 95% atau toleransi kesalahan 5%.
3.6.5 Penarikan Kesimpulan
Penarikan kesimpulan dilakukan berdasarkan hasil penelitian melalui
pengujian yang berdasarkan kriteria yang telah ditetapkan, juga dari teori-teori yang
mendukung objek dari masalah yang diteliti, kemudian dilakukan analisis dan
penarikan kesimpulan mengenai pengaruh Profitabilitas, Leverage, dan Ukuran