73
PERANCANGAN APLIKASI PREDIKSI JUMLAH KELULUSAN
MAHASISWA DENGAN METODE AUTO REGRESSIVE
INTEGRATED MOVING AVERAGE (ARIMA) (STUDI
KASUS : PRODI TI STMIK BUDIDARMA MEDAN)
Evi Sinaga1, Abdul Sani Sembiring2, Riswan Limbong3
1Mahasiswa Teknik Informatika STMIK Budi Darma Medan 2,3Dosen Tetap STMIK Budi Darma Medan Jl. Sisimangaraja No.338 Simpang Limun Medan
ABSTRAK
Prediksi adalah proses untuk meramalkan suatu variabel di masa mendatang dengan berdasarkan pertimbangan data pada masa lampau. Prediksi tidak harus memberikan jawaban secara pasti kejadian yang akan terjadi, melainkan berusaha untuk mencari jawaban sedekat mungkin dengan kejadian. Jumlah kelulusan program studi TI STMIK Budidarma selalu mengalami peningkatan dan penurun setiap tahunnya. Hal ini menyebabkan terjadinya penumpukan data mahasiswa di database. Selain itu masalah ketidakpastian ini juga menyebabkan pihak program studi TI STMIK Budidarma Medan menduga-duga tingkat kelulusan mahasiswa dan tidak memenuhi standar mutu yang telah di tetapkan kampus. Minimnya jumlah mahasiswa yang lulus tepat waktu menyebabkan turunnya kualitas dan mutu perguruan tinggi. Metode yang digunakan dalam memprediksi jumlah kelulusan mahasiswa yaitu menggunakan metode auto regressive integrated moving average. Metode ini diterapkan untuk analisis deret berkala, peramalan dan pengendalian. Metode ARIMA merupakan metode proyeksi yang merupakan gabungan antara metode pemulusan, metode regresi dan metode dekomposisi. Model ARIMA merupakan kombinasi dari model AR dan model MA sehingga dalam model ini yang menjadi variabel bebas adalah nilai sebelumnya dari variabel dependen (lag) dan nilai residual periode sebelumnya.
Kata Kunci : Prediksi, Kelulusan, Mahasiswa, ARIMA.
I. PENDAHULUAN
Prediksi adalah proses untuk meramalkan suatu variabel di masa mendatang dengan berdasarkan pertimbangan data pada masa lampau. Prediksi tidak harus memberikan jawaban secara pasti kejadian yang akan terjadi, melainkan berusaha untuk mencari jawaban sedekat mungkin dengan kejadian. Dalam upaya meningkatkan atau mempertahankan kinerja mahasiswa selama masa studi di perguruan tinggi, maka perlu diprediksi tingkat kelulusan mahasiswa di setiap tahunnya sebagai salah satu faktor yang menentukan kualitas perguruan tinggi tersebut.
Perguruan tinggi adalah satuan penyelenggara pendidikan akademik bagi mahasiswa. Lembaga penyelenggara perguruan tinggi terdiri dari akademik, sekolah tinggi, politeknik, institut dan universitas. Sekolah Tinggi Manajemen Informatika dan Komputer Budidarma Medan merupakan sekolah tinggi komputer pertama di Medan yang didirikan pada tanggal 1 Maret 1996 dan mendapatkan persetujuan dari pemerintah melalui Menteri Pendidikan dan Kebudayaan RI, pada tanggal 23 Juli 1996 dengan ijin operasional nomor 48/D/O/1996. STMIK Budidarma Medan sejak awal berdirinya sampai saat ini mengelola 2 program studi yakni Teknik Informatika untuk jenjang pendidikan S1 dan Manajemen Informatika untuk jenjang pendidikan D3. Kelulusan merupakan suatu keputusan bagi mahasiswa, dimana ia dinyatakan telah memenuhi berbagai macam persyaratan akademik dan administratif yang diwajibkan sehingga secara sah dinyatakan lulus dan berhak memperoleh gelar Sarjana (S1).
STMIK Budidarma adalah salah satu Sekolah Tinggi Manajemen Informatika dan Komputer Budidarma di Sumatera Utara yang pada setiap tahunnya mengalami naik turunnya jumlah kelulusan. Hal ini menyebabkan terjadinya penumpukan data mahasiswa di database. Selain itu masalah ketidakpastian ini juga menyebabkan pihak program studi TI STMIK Budidarma Medan menduga-duga tingkat kelulusan mahasiswa dan tidak memenuhi standar mutu yang telah di tetapkan kampus. Minimnya jumlah mahasiswa yang lulus tepat waktu menyebabkan turunnya kualitas dan mutu perguruan tinggi. Mahasiswa yang terlalu lama menempuh masa studi memiliki kecenderungan terkena ancaman
Drop-Out.
Pada penelitian sebelumnya Penerapan Metode ARIMA untuk Peramalan Pengunjung Perpustakaan UIN Suska Riau menyatakan bahwa metode auto
regressive integrated moving average untuk
menentukan estimasi parameter, menentuan model terbaik dengan uji statistik dan prediksi untuk data pada waktu yang akan datang[1], dan menurut penelitian lain tentang Analisis Peramalan Harga Saham Perusahaan Properti Dengan Metode ARIMA (Studi Kasus Ciputra Property CTRP.JK) menyatakan bahwa metode autoregressive integrated moving average dapat menghasilkan sebuah peramalan harga saham jangka waktu kedepan yang dapat digunakan untuk penunjang keputusan dalam berinvestasi pada perusahaan properti[2]. Sedangkan untuk penelitian ini, metode autoregressive integrated moving average untuk memprediksi jumlah kelulusan mahasiswa pada Prodi TI STMIK Budidarma Medan.
74
II. TEORITISA. Prediksi
Pengertian Prediksi menurut Kamus Besar Bahasa
Indonesia adalah hasil dari kegiatan memprediksi atau meramal atau memperkirakan. Prediksi bisa berdasarkan metode ilmiah ataupun subjektif belaka.
Prediksi adalah seni dan ilmu memprediksi peristiwa-peristiwa masa depan dengan pengambilan data historis dan memproyeksikannya ke masa depan dengan menggunakan beberapa bentuk model matematis[4].
B. Algoritma ARIMA
Metode ini diterapkan untuk analisis deret berkala, peramalan dan pengendalian. Dikembangkan oleh George Box dan Gwilym Jenkins sehingga disebut ARIMA Box-Jenkins. Metode ARIMA merupakan metode proyeksi yang merupakan gabungan antara metode pemulusan, metode regresi dan metode dekomposisi[4].
Model ARIMA merupakan kombinasi dari model AR dan model MA sehingga dalam model ini yang menjadi variabel bebas adalah nilai sebelumnya dari variabel dependen (lag) dan nilai residual periode sebelumnya.
Adapun langkah-langkah pada analisis runtun waktu dengan model ARIMA atau lebih dikenal dengan metode Box-Jenkins[4] adalah sebagai berikut :
1. Identifikasi Model
Pada tahap ini, kita memilih model tepat yang bisa mewakili deret pengamatan. Identifikasi model dilakukan dengan:
a. Membuat plot data time series melalui plot data dapat diketahui apakah data mengandung trend, musiman, outlier, variansi tidak konstan. Jika data time series tidak stasioner maka data harus distasionerkan terlebih dahulu. Jika data tidak stasioner dalam varians dan mean, maka langkah pertama harus menstabilkan variansinya.
b. Menghitung dan mencocokkan sampel Autokorelasi dan Autokorelasi Parsial dari data time series yang asli. Sampel Autokorelasi dan Autokorelasi Parsial dari data time series yang asli dapat digunakan untuk menentukan tingkat differencing yang sebaiknya digunakan.
c. Menghitung dan mencocokkan sampel Autokorelasi dan Autokorelasi Parsial dari data time series yang telah ditransformasikan dan didiferencing.
2. Estimasi Parameter Pada tahap ini, kita memilih taksiran model yang baik dengan melakukan uji hipotesis untuk parameter.
Hipotesis :
H0 : parameter tidak signifikan H1: parameter signifikan Level toleransi (α) = 5% = 0,05 Kriteria uji :
Tolak H0 jika p-value < α 3. Uji Diagnosis
Setelah mendapatkan estimator ARIMA, langkah selanjutnya adalah memilih model yang mampu menjelaskan data dengan baik. Caranya adalah dengan melihat apakah residual bersifat random sehingga merupakan residual yang relatif kecil. Jika tidak, maka harus kembali ke langkah pertama untuk memilih model yang lain.
4. Langkah terakhir dari proses runtut waktu adalah prediksi atau peramalan dari model yang dianggap paling sesuai dan bisa meramalkan untuk beberapa periode kedepan.
III. ANALISA A. Analisa Masalah
Untuk mengetahui prediksi jumlah kelulusan mahasiswa tahun berikutnya, maka dibuat suatu sistem perancangan aplikasi prediksi jumlah kelulusan mahasiswa dengan metode Autoregressive Integrated Moving Average. Berdasarkan pengalaman pendataan di STMIK Budiarma Medan menunjukkan bahwa jumlah kelulusan pada setiap tahunnya dipengaruhi oleh jumlah mahasiswa yang mendaftar pada tahun tersebut dan jumlah mahasiswa yang lulus persyaratan skripsi.
Berikut ini merupakan data jumlah kelulusan mahasiswa, jumlah mahasiswa yang mendaftar pada tahun tersebut dan jumlah mahasiswa yang lulus persyaratan skripsi dari tahun ajaran 2011/2012 sampai dengan tahun ajaran 2015/2016 :
Tabel 1. Jumlah kelulusan mahasiswa Tahun Ajaran Jumlah Mahasiswa
2011/2012 478 Mahasiswa
2012/2013 422 Mahasiswa
2013/2014 598 Mahasiswa
2014/2015 542 Mahasiswa
2015/2016 662 Mahasiswa
Tabel 2. Jumlah mahasiswa yang mendaftar Tahun Ajaran Jumlah Mahasiswa
2011/2012 650 Mahasiswa
2012/2013 600 Mahasiswa
2013/2014 800 Mahasiswa
2014/2015 750 Mahasiswa
2015/2016 850 Mahasiswa
Tabel 3. Jumlah mahasiswa lulus persyaratan skripsi Tahun Ajaran Jumlah Mahasiswa
2011/2012 500 Mahasiswa
75
2013/2014 750 Mahasiswa
2014/2015 600 Mahasiswa
2015/2016 700 Mahasiswa
Tabel 4. Jumlah Keseluruahn Data Tahun Ajaran 2011/ 2012 2012/ 2013 2013/ 2014 2014/ 2015 2015/ 2016 Jlh.Kel ulusan 478 422 598 542 662 Jlh.Pen daftaran 650 600 800 750 850 Jlh.Pers yaratan 500 450 750 600 700
B. Penerapan Metode Autoregressive Integrated Moving Average
Metode Autoregressive Integrated Moving Average ini akan diterapkan pada prediksi jumlah kelulusan mahasiswa. Berikut rumus untuk metode
Autoregressive Integrated Moving Average :
Yt = A1Yt−1+ A2Yt−2+ ⋯ + ApYt−p+ et Dimana :
Yt : nilai AR yang di prediksi
Yt−1, Yt−2, Yt−n : nilai lampau series yang bersangkutan ;
nilai lag dari time series.
Ap : koefisien
et : residual; error yang menjelaskan efek dari variabel yang tidak dijelaskan oleh model, kesalahan peramalan dengan ciri seperti sebelumnya.
1. Langkah pertama pada model identifikasi adalah menentukan apakah sebuah data timeseries
bersifat stasioner (nilai rata-rata tidak bergeser sepanjang waktu). Apabila data tidak bersifat stasioner, maka konversi data harus dilakukan (agar menjadi stasioner) dengan menggunakan metode diferensiasi.
Dik : Ukuran sampel N = 5
Data Aktual Yt = 478,422,598,542,662 Maka, N = 5 ∑Nt=1Yt = 2702 ∑Nt=1Yt2 = 1.496.180 ( ∑N Yt t=1 2) 2 = 7.300.800
Dimana : N = banyaknya data sebagai sampel pertahun
∑Nt=1Yt = 2702 adalah jumlah ataupun total keseluruhan dari data aktual
∑N Yt
t=1 2 = 1.496.180 adalah hasil perpangkatan dari masing-masing data aktual
( ∑Nt=1Yt2) 2 = 7.300.800 adalah hasil perpangkatan dari total data aktual Sehingga : N’ = (20√𝑁 ∑ 𝑌𝑡2 𝑁 𝑡=1 − ∑𝑁𝑡=1𝑌𝑡 ∑𝑁𝑡=1𝑌𝑡 ) 2 N’ = (20 √5(1.496.180) –(2702) 2 2702 ) 2 N’ = (20 √7.480.900 −7.300.800 2702 ) 2 N’ = (20 √180.100 2702 ) 2 N’ = (8.487.638 2702 ) 2 N’ = (3.141)2 = 9.865
Karena N’ < N maka data yang ada pada tabel sudah stasioner.
2. Menghitung dan mencocokkan sampel Autokorelasi dan Autokorelasi Parsial dari data
time series yang asli. Sampel Autokorelasi dan Autokorelasi Parsial dari data time series yang asli dapat digunakan untuk menentukan tingkat diferensiasi yang sebaiknya digunakan. a. Untuk menghitung nilai koefisien
autokorelasi dapat dihitung dengan menggunakan persamaan berikut :
rk= ∑t=1n−k (Yt−Y)(Yt+k− Y) ∑t=1n−k (Yt−Y) 2 Dengan : Y = ∑t=1n−k Yt n Maka : Y = 478+422+598+542+662 5 Y = 2702 5 Y = 540.4̇ = 540 1. Untuk r1 maka diperoleh :
(Y1−Y)(Y1+1−Y) + (Y2−Y)(Y2+1−Y)+ … + (Y4−Y)(Y5−Y)
(Y1−Y)2+ (Y2−Y)2+ (Y3−Y)2+ (Y4−Y)2+ (Y5−Y)2
r1= (478-540)(422-540) + (422-540)(598-540) + (598-540)(542-540)+ (542-540)(662-540) (478-540)2+ (422-540)2+ (598-540)2+ (542-540)2+ (662-540)2 r1= (-62)(-118) + (-118)(58) + (58)(2)+(2)(112) (-62)2+ (-118)2+ (58)2+ (2)2+ (122)2 r1= 3844+ (-13928)+ 3364+ 4+ 148847316+ (-6844)+ 116+244 r1= 8168832 = 0,101
2. Untuk r2 maka diperoleh :
r2=
(Y2−Y)(Y2+1−Y)+ … + (Y4−Y)(Y5−Y)
(Y2−Y) 2 + (Y3−Y) 2 + (Y4−Y) 2 + (Y5−Y) 2 r2= (422-540)(598-540) + (598-540)(542-540)+(542-540)(662-540) (422-540)2+ (598-540)2+ (542-540)2+ (662-540)2 r2= (-118)(58) + (58)(2)+(2)(112) (-118)2+ (58)2+ (2)2+ (122)2 r2= (-13928)+ 3364+ 4+ 14884(-6844)+ 116+244
76
r2= -6,4844,324 = 1,4993. Untuk r3 maka diperoleh :
r3=
(Y3−Y)(Y3+1−Y)+ (Y4−Y)(Y5−Y)
(Y3−Y) 2 + (Y4−Y) 2 + (Y5−Y) 2 r3= (598-540)(542-540)+(542-540)(662-540) (598-540)2+ (542-540)2+ (662-540)2 r3= (58)(58)(2)+(2)(112) 2+ (2)2+ (122)2 r3= 3364+ 4+ 14884116+244 r3= 18252360 = 0.019
b. Untuk menghitung nilai koefisien autokorelasi parsial dapat dihitung dengan menggunakan persamaan berikut :
𝑌𝑡+𝑘= 𝛼𝑘1𝑌𝑡+𝑘+𝛼𝑘1𝑌𝑡+𝑘+⋯+𝛼𝑘𝑘𝑌𝑡+𝑒𝑡+𝑘
(𝑌𝑡+1)2+(𝑌𝑡+2)2+(𝑌𝑡+3)2+(𝑌𝑡+4)2+(𝑌𝑡+5)2
Dengan : 𝛼𝑘1= 0
1. Untuk Y1 maka diperoleh :
𝑌0+1=(𝑌 𝑌0+1+𝑌0+2+𝑌0+3+𝑌0+4+𝑌0+5 𝑡+1)2+(𝑌𝑡+2)2+(𝑌𝑡+3)2+(𝑌𝑡+4)2+(𝑌𝑡+5)2 𝑌1=(478)2+(422)478+422+598+542+6622+(598)2+(542)2+(662)2 𝑌1= 478+422+598+542+662 228484+178084+357604+293764+438244 𝑌1= 2702 1496180 = 0,001 2. Untuk Y2 maka diperoleh :
𝑌0+2= 𝑌0+2+𝑌0+3+𝑌0+4+𝑌0+5 (𝑌𝑡+2)2+(𝑌𝑡+3)2+(𝑌𝑡+4)2+(𝑌𝑡+5)2 𝑌2= 422+598+542+662 (422)2+(598)2+(542)2+(662)2 𝑌2=178084+357604+293764+438244422+598+542+662 𝑌2= 2224 1267696 = 0,001 3. Untuk Y3 maka diperoleh :
𝑌0+3= 𝑌0+3+𝑌0+4+𝑌0+5 (𝑌𝑡+3)2+(𝑌𝑡+4)2+(𝑌𝑡+5)2 𝑌3= 598+542+662 (598)2+(542)2+(662)2 𝑌3=357604+293764+438244598+542+662 𝑌3= 1802 1089612 = 0,001
Maka, dari nilai nilai koefisien autokorelasi dan autokorelasi parsial dari data jumlah
kelulusan mahasiswa dapat diperoleh data seperti dibawah ini:
Tabel 5. Nilai Koefisien Autokorelasi dan Autokorelasi parsial Lag Autokorela si Lag Autokorelasi Parsial 1 0,101 1 0,0018 2 1,499 2 0,0017 3 0,001 3 0,0016
c. Menghitung dan mencocokkan sampel Autokorelasi dan Autokorelasi Parsial dari data time series yang telah ditransformasikan dan didiferencing. Untuk menentukan Standard Error dengan persamaan sebagai berikut:
−𝑆𝑒𝑟𝑘(1 √𝑛 ⁄ )
Dimana n menunjukkan jumlah observasi. Dengan interval kepercayaan yang dipilih, maka batas signifikansi koefisien
autokorelasi adalah : −𝑍𝛼 2 ⁄ 𝑥𝑥𝑆𝑒𝑟𝑘≤ 𝑍𝛼⁄ 𝑥2 𝑥𝑆𝑒𝑟𝑘 −0,001 (1 √5 ⁄ ) ≤ 0,001 (1 √5 ⁄ ) Atau berada pada batas nilai :
−0.0042 ≤ 0.0042
Terlihat bahwa data sudah stasioner, hanya 1 data yang koefisien autokorelasi yang tidak berada dalam interval batas penerimaan yaitu : lag-3 dengan nilai 0,001 dan hanya 1 nilai koefisien parsial yang tidak berada pada batas penerimaan yaitu lag-3 dengan nilai koefisien 0,0016 Dari ordo proses Autoregressive dan ordo proses Moving Average diperoleh model ARIMA (1,0,1), Sehingga dimiliki 3 model ARIMA yakni:
1. ARIMA (1,0,0) 2. ARIMA (0,0,1) 3. ARIMA (1,0,1)
Tahap selanjutnya setelah model ARIMA diperoleh maka mencari nilai estimasi terbaik atau paling efesien untuk parameter mode. Dalam tahap ini akan diestimasi parameter-parameter yang tidak diketahui yakni ϕ,θ.
1. Estimasi Parameter Model ARIMA (1,0,0) Bentuk umum model autoregressive dengan ordo p (AR(p)) atau model ARIMA (p,0,0) dinyatakan sebagai berikut:
𝑌𝑡= 𝜇′+ ∅
1𝑌𝑡−1+ ∅2𝑌𝑡−2+ ⋯ + ∅𝑝𝑌𝑡−𝑝+ 𝑒𝑡 dimana: 𝜇′ = suatu konstanta
∅𝑝 = parameter autoregresif ke-p
𝑒𝑡 = nilai kesalahan pada saat t
Yt= 0,05 + 0,001(478) + 0,101(422) + 1,499(598) + 0,0042
77
Yt= 0,05 + 0,478 + 42,622 + 896,402 + 0,0042
Yt= 939.024
2. Estimasi Parameter Model ARIMA (1,0,0) Bentuk umum model moving average ordo q (MA(q)) atau ARIMA (0,0,q) dinyatakan sebagai berikut:
𝑌𝑡= 𝜇′+ 𝑒𝑡− 𝜃1𝑒𝑡−1− 𝜃2𝑒𝑡−2− ⋯ − 𝜃𝑞𝑒𝑡−𝑘 dimana: 𝜇′ = suatu konstanta
𝜃1 sampai 𝜃𝑞 adalah parameter-parameter moving average
𝑒𝑡−𝑘 = nilai kesalahan pada saat t – k
𝑌𝑡= 0,05 + 0,0042 − 0,0016 − 0,0017 − 0,0018
𝑌𝑡= 0,0491
3. Estimasi Parameter Model ARIMA (1,0,1) Model umum untuk campuran proses AR(1) murni dan MA(1) murni, misal
ARIMA (1,0,1) dinyatakan sebagai berikut:
𝑌𝑡= 𝜇′+ ∅1𝑌𝑡−1+ 𝑒𝑡− 𝜃1𝑒𝑡−1 dimana: 𝜇′ = suatu konstanta
∅𝑝 = parameter autoregresif ke-p
𝑒𝑡 = nilai kesalahan pada saat t
𝜃1 sampai 𝜃𝑞 adalah parameter-parameter moving average
𝑌𝑡= 0,05 + 0,001(478) + 0,0042 − 0,0016
𝑌𝑡= 0,05 + 0,001(478) + 0,0042 − 0,0016
𝑌𝑡= 0,05 + 0,478 + 0,0042 − 0,0016
𝑌𝑡= 0,5306
Pada Tahap ini selanjutnya adalah memilih model yang mampu menjelaskan data dengan baik. Caranya adalah dengan melihat apakah residual bersifat random sehingga merupakan residual yang relatif kecil. Jika tidak, maka harus kembali ke langkah pertama untuk memilih model yang lain. Untuk menentukan hasil digunakan cara yang sama dengan model ARIMA (1,0,0). Berikut persamaan ARIMA (1,0,1)
Yt = α + A1Yt−1+ A2Yt−2+ ApYt−p+ et
Setelah didapat persamaan ARIMA maka dilakukan keakuratan model ARIMA dengan mengukur kesalahan peramalan.
1. Untuk Modek ARIMA (1,0,0)
𝑀𝑆𝐸 = ∑ Yt
𝑛
𝑀𝑆𝐸 = 939.024
5
𝑀𝑆𝐸 = 187,804
2. Untuk Modek ARIMA (0,0,1)
𝑀𝑆𝐸 = ∑ Yt
𝑛
𝑀𝑆𝐸 = 0.0491
5
𝑀𝑆𝐸 = 0,00982
3. Untuk Modek ARIMA (1,0,1)
𝑀𝑆𝐸 = ∑ Yt
𝑛
𝑀𝑆𝐸 = 0.5306
5
𝑀𝑆𝐸 = 0,10612
Dari ketiga MSE (Mean Squen Error) dari masing-masing model, terlihat bahwa nilai MSE pada model ARIMA (0,0,1) yang dibandingkan dengan model ARIMA (1,0,0) dan model ARIMA (1,0,1). Jadi dapat disimpulkan bahwa model yang tepat untuk data jumlah kelulusan adalah model ARIMA (1,0,0).
Sasa Langkah terakhir dari proses runtut waktu adalah prediksi atau peramalan dari model yang dianggap paling sesuai dan bisa meramalkan untuk beberapa periode kedepan. Untuk persamaannya adalah sebagai berikut :
Yt = α + A1Yt−1+ A2Yt−2+ ApYt−p+ et Yt = 0,05 + 939.024(478) + 0.0491(422) + 0,0042 Yt = 0,05 + 448.853 + 20.7202 + 0,0042 Yt = 469.62 = 470 Mahasiswa IV. IMPLEMENTASI A. Implementasi Sistem
Aplikasi prediksi jumlah kelulusan mahasiswa dengan metode autoregressive integrated moving average dibangun dengan menggunakan bahasa pemograman Visual Basic 2008. Adapun hasil tampilan program yang dibuat ditunjukkan pada gambar dibawah ini . Tampilan awal program merupakan halaman menu utama.
Gambar 1. Tampilan HalamanUtama
Form input digunakan untuk melakukan proses prediksi.
Gambar 2. Form prediksi jumlah kelulusan mahasiwa
78
Tampilan output merupakan hasil-hasil prediksiyang dilakukan pada sistem.
Gambar 3. Laporan hasil prediksi
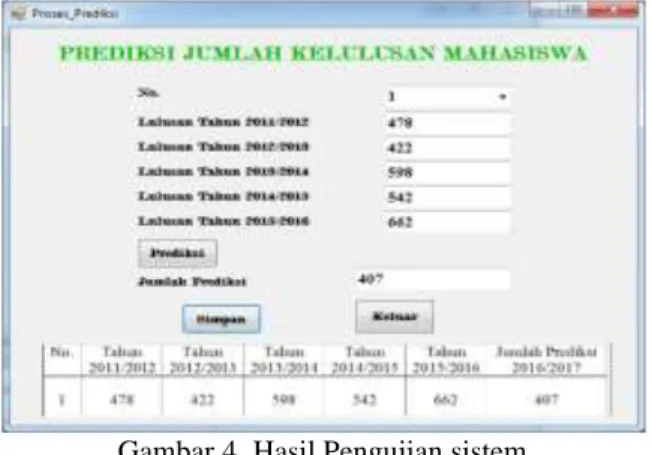
Gambar berikut menunjukkan hasil pnegujian sistem dalam memprediksi jumlah kelulusan mahasiswa di tahun 2016/2017.
Gambar 4. Hasil Pengujian sistem V. KESIMPULAN
Kesimpulan pada penelitian ini adalah sebagai berikut :
1. Proses prediksi jumlah kelulusan mahasiswa didasarkan pada mahasiswa yang mendaftar dan mahasiswa yang lulus persyaratan penyusunan skripsi.
2. Algoritma Autoregressive Integrated Moving Average adalah salah satu algoritma prediksi yang digunakan dalam melakukan prediksi jumlah kelulusan mahasiswa pada prodi TI STMIK Budidarma Medan.
3. Aplikasi prediksi jumlah kelulusan mahasiswa dibangun dengan bahasa pemograman Visual Basic 2008. Aplikasi ini diharapkan mampu membantu program studi Teknik Informatika STMIK Budidarma medan dalam memprediksi jumlah kelulusan mahasiwa.
REFERENCES
[1] Syarfi Aziz, Ahmad Sayuti, and Mustakim , "Penerapan Metode ARIMA untuk Peramalan Pengunjung Perpustakaan UIN Suska Riau," Seminar Nasional Teknologi Informasi, Komputer dan Industri.
[2] Asdi Atmin Fildananto, Sulistiowati , and Tegar Heru Susilo, "Analisa Peramalan Harga Saham Perusahaan Properti Dengan Metode ARIMA," JSIKA, vol. 5, 2016.
[3] Agustinawati Purba, "PERANCANGAN APLIKASI PERAMALAN JUMLAH CALON MAHASISWA BARU
YANG MENDAFTAR MENGGUNAKAN METODE SINGLE EXPONENTIAL SMOTHING (Studi Kasus : Fakultas Agama Islam UISU)," Junal Riset Komputer (JURIKOM), vol. 2, 2015.
[4] Chairunnisa , "ANALISA PREDIKSI JUMLAH PENJUALAN TIKET MENGGUNAKAN METODE AUTOREGRESSIVE INTEGRATED MOVING AVERAGE (ARIMA) PADA PT.CHARISMA RASA SAYANG HOLIDAYS MEDAN," Pelita Informatika Budidarma, vol. 9, 2015.
[5] Rosa A.S and M Sahaluddin, REKAYASA PERANGKAT LUNAK TERSTRUKTUR dan BERORIENTASI OBJEK. Bandung: Informatika Bandung, 2015.
[6] R Priyanto, LANGSUNG BISA VISUAL BASIC.NET 2008. Yogyakarta: ANDI, 2009.