PERANCANGAN APLIKASI KAMUS BAHASA GAYO DENGAN
MENGGUNAKAN METODE BOYER-MOORE
Ramadhansyah (12110817)
Mahasiswa Program Studi Teknik Informatika, STMIK Budidarma Medan Jl. Sisimangaraja No.338 Simpang Limun Medan
www.stmik-budidarma.ac.id // ramadhansyah817@yahoo.co.id ABSTRAK
Lahirnya teknologi informasi komputer dan fasilitas pendukungnya seperti layanan internet saat ini membuat perkembangan yang sangat luas. Segala informasi-informasi dapat didapatkan begitu cepat membuat jarak dan waktu tidak menjadi masalah. Namun disamping itu masih jarang ditemukan aplikasi yang dapat mempermudah proses translasi suatu kata dalam bahasa Gayo-Indonesia. Aplikasi kamus ini dirasa perlu karna banyaknya masarakat pendatang yang belum mengetahui sebagian dari arti bahasa Gayo itu sendiri. Proses translasi kata ini dilakukan hanya dalam bentuk kata dimana setiap kata yang akan dicari akan muncul beserta arti(keterangan) kata tersebut.
Pencarian kata menerapkan prinsip good sufix(dimana karakter yang dicari sejajar dengan karakter yang menyerupainya)serta prinsip bad character(dimana jika karakter tidak memiliki kemiripan maka langsung dieliminasi
Pada Skripsi ini akan dideskripsikan mengenai pembuatan suatu kamus dalam bahasa Gayo-Indonesia yang bermanfaat sebagai pembelajaran bagi masarakat Gayo itu sendiri, serta untuk mempermudah pengguna dalam proses translasi suatu kata dan arti dari kata tersebut yang akan dilakukan dengan memenfaatkan algoritma Boyer-Moore. Metode Boyer-Moore merupakan pencocokan string dianggap paling efisien pada aplikasi ini. Dan dirancang menggunakan Microsoft Visual Studio 2008, untuk mengimplementasikan cara kerja dan hasil dari translasi kata tersebut.
Kata Kunci : Kamus, Bahasa Gayo, Boyer-Moore
1. Pendahuluan
Pada saat sekarang ini banyak ditemui kamus digital yang dapat membantu dalam menerjemahkan kata dalam bahasa asing dengan cepat sehingga dapat mempermudah proses
translasi bahasa. Namun, masih jarang ditemukan aplikasi yang dapat mempermudah penerjemahan suatu kata khususnya dalam bahasa Gayo. Aplikasi ini dirasa perlu karena masih banyaknya kosakata dan makna dari bahasa Gayo yang belum diketahui oleh masarakat gayo itu sendiri dan para pendatang yang berada pada daerah Gayo tersebut sehingga mereka menggunakan kamus dalam proses translasi untuk belajar bahasa Gayo-Indonesia tersebut. Hal ini sangat memakan banyak waktu karna harus mencari kata perkata dalam sebuah kamus yang sangat tebal.
Dengan adanya sebuah aplikasi kamus dalam bahasa Gayo-Indonesia, diharapkan proses translasi dalam bahasa Gayo-Indonesia dapat dilakukan dengan lebih mudah dan cepat oleh masarakat Gayo maupun masarakat luar. Proses translasi
dalam bahasa Gayo-Indonesia ini dapat dilakukan dengan memanfaatkan algoritma pencarian string
seperti algoritma Boyer-Moore melakukan pencarian kata dimulai dari posisi kanan hingga akhirnya sampai pada posisi paling kiri. Langkah ini berbeda dengan algoritma pencarian string
sejenis yang memulai pencarian kata dari kiri.
Algoritma ini menerapkan prinsip good sufix(dimana karakter yang dicari disejajarkan dengan karakter yang menyerupainya) serta prinsip
bad character (dimana jika karakter tidak memiliki kemiripan akan langsung dieliminasi).
Dengan kedua prinsip ini, informasi string yang diperoleh dalam pencarian akan semakin banyak sehingga output yang dihasilkan akan menjadi lebih baik.
1.1Perumusan Masalah
Berdasarkan latar belakang masalah yang telah penulis uraikan, maka permasalahan dapat dirumuskan sebagai berikut :
1. Bagaimana teknik pencarian kosa kata dalam kamus bahasa Gayo ?
2. Bagaimana menerapkan metode Boyer-Moore dalam aplikasi kamus Bahasa Gayo-Indonesia ?
3. Bagaimana merancang aplikasi kamus bahasa
Gayo-Indonesia dengan menggunakan bahasa pemrograman Visual Studio 2008?
1.2 Batasan Masalah
Untuk menghindari pembahasan tidak menyimpang dari permasalahan yang ada, maka perlu dibuat batasan masalah yang akan dibahas oleh penulis dalam penulisan Skripsi ini.
Adapun batasan masalah dalam penelitian ini adalah sebagai berikut:
1. Kata-kata yang dicari merupakan kata-kata baku berdasarkan pedoman kamus besar bahasa Gayo-Indonesia.
2. Proses pencarian kata bahasa Gayo-Indonesia dilakukan hanyalah dalam bentuk satu buah kata, bukan dalam bentuk kalimat.
3. Bahasa Gayo yang dibahas hanyalah bahasa Gayo Lues saja.
a. Bahasa pemrograman yang digunakan adalah Microsoft Visual Studio 2008 dan
Microsoft SQL Server sebagai database.
2. Landasan Teori
Bahasa Gayo (pengucapan: Gayô) adalah sebuah bahasa dari rumpun Austronesia yang dituturkan oleh suku Gayo di propinsi Aceh, yang terkonsentrasi di Kabupaten Aceh Tengah, Bener Meriah, Gayo Lues dan Lokop di kabupaten Aceh Timur. Keempat daerah ini merupakan wilayah inti suku Gayo.
Bahasa Gayo merupakan salah satu bahasa yang ada di Nusantara. Keberadaan bahasa ini sama tuanya dengan keberadaan orang Gayo “urang Gayo” itu sendiri di Indonesia. Sementara orang Gayo “urang Gayo” merupakan suku asli yang mendiami Aceh . Mereka memiliki bahasa, adat istiadat sendiri yang membedakan identitas mereka dengan suku-suku lain yang ada di Indonesia. Daerah kediaman mereka sendiri disebut dengan tanoh Gayo (tanah Gayo), tepatnya berada di tengah-tengah propinsi Aceh[8].
2.1 Algoritma Boyer-Moore
Algoritma Boyer-Moore adalah salah satu algoritma pencarian string, dipublikasikan oleh Robert S. Boyer, dan J. Strother Moore pada tahun 1977. Algoritma ini dianggap sebagai algoritma yang paling efisien pada aplikasi umum.Tidak seperti algoritma pencarian string yang ditemukan sebelumnya, algoritma Boyer-Moore mulai mencocokkan karakter dari sebelah kanan pattern. Ide dibalik algoritma ini adalah bahwa dengan memulai pencocokkan karakter dari kanan, dan bukan dari kiri, maka akan lebih banyak informasi yang didapat [9].
Misalnya ada sebuah usaha pencocokan yang terjadi pada teks[i…i+ n-1], dan anggap ketidakcocokan pertama terjadi di antara teks [i+j] dan pattern [j], dengan 0<j<n. Berarti, teks [i+j+1..i+n-1] dan [j+1..n] dan a=teks [i+j] tidak sama dengan b = pattern [j]. Jika u adalah akhiran dari pattern sebelum b dan v adalah sebuah awalan dari pattern, maka penggeseran-penggeseran yang mungkin adalah:
1. Penggeseran good-suffix yang terdiri dari mensejajarkan potongan teks [I +j + 1..i+ n-1]= pattern [j+1..n-1 ]dengan kemunculannya paling kanan di pattern yang didahului oleh karakter
yang berbeda dengan pattern [j]. Jika tidak ada potongan seperti itu, maka algoritma akan mensejajarkan akhiran v dari [I +j +1..i+n-1] dengan awalan dari pattern yang sama.
2. Penggeseran bad-character yang terdiri dari mensejajarkan teks [i +j] dengan kemunculan paling kanan karakter tersebut di pattern. Bila karakter tersebut tidak ada di pattern, maka pattern akan disejajarkan dengan teks [I +n +1 ]. Secara sistematis, langkah-langkah yang dilakukan algoritma Boyer-Moore pada saat mencocokkan string adalah:
1. Algoritma Boyer-Moore mulai mencocokkan pattern pada awal teks.
2. Dari kanan ke kiri, algoritma ini akan mencocokkan karakter per karakter pattern dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi: a. Karakter di pattern dan di teks yang
dibandingkan tidak cocok (mismatch). b. Semua karakter di pattern cocok. Kemudian
algoritma akan memberitahukan penemuan di posisi ini.
3. Algoritma kemudian menggeser pattern dengan memaksimalkan nilai penggeseran good-suffix dan penggeseran bad-character, lalu mengulangi langkah 2 sampai pattern berada di ujung teks. 2.2 Pencarian Kata Dengan Boyer-Moore
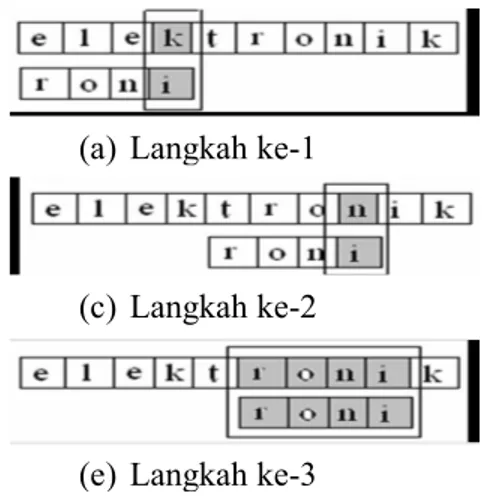
Ilustrasi pencarian kata kunci "roni" pada kata "elektronik" dapat dilihat pada Gambar 1. Dari Gambar 1(a), dapat dilihat bahwa karakter terakhir dari kata kunci adalah huruf "i" yang dicocokkan dengan huruf "k" pada kata "elektronik". Karena huruf "i" dan huruf "k" berbeda, maka akan dilakukan pencocokan huruf "k" dengan seluruh karakter pada kata kunci. Karena huruf "k" tidak terdapat pada seluruh karakter kata kunci, maka kata kunci bergeser ke kanan sebanyak empat karakter sesuai dengan panjang karakter kata kunci seperti yang tampak pada Gambar 1(b). Setelah dilakukan pergeseran, maka dicocokkan kembali karakter terakhir pada kata kunci yaitu huruf "i" dengan huruf "n". Karena kedua huruf ini berbeda, maka huruf "n" dicocokkan dengan keseluruhan karakter pada kata kunci. Karena pada kata kunci terdapat huruf "n", maka kata kunci akan bergeser sedemikian rupa sehingga huruf "n" pada kata kunci memiliki posisi yang sejajar dengan posisi huruf "n" pada kata yang dicocokkan seperti yang ditunjukkan pada Gambar 1(c). Setelah itu dilakukan kembali pencocokan karakter terakhir pada kata kunci, yaitu huruf "i" dengan karakter yang terletak sejajar dengan huruf "i" tersebut.
Karena karakter tersebut sama maka dicocokkan kembali karakter berikut yang berada di sebelah kiri huruf "i" sehingga keseluruhan karakter pada kata kunci selesai diperiksa. Algoritma ini memiliki kompleksitas (n=m) dalam kasus terbaiknya dan (n) dalam kasus terburuknya . Kasus
terbaik terjadi jika karakter terakhir pada kata kunci berbeda dengan karakter kata yang dicocokkan tetapi seluruh kata kunci terdapat pada kata yang dicocokkan. Sedangkan kasus terburuk terjadi jika karakter kata kunci yang dicari hanya satu karakter saja dan kata yang dicocokkan terdiri dari beberapa karakter.
Gambar 1: Langkah-langkah pencarian algoritma Boyer-Moore 3. Analisa Dan Perancangan 3.1 Analisa Metode Boyer-Moore
Sebelum mengimplementasikan metode boyer-moore ke dalam bentuk sebuah bahasa pemrograman, terlebih dahulu dilakukan analisa mengenai cara kerja sistem yang akan dihasilkan. Analisa ini dilakukan berdasarkan kerja metode boyer-moore dalam melakukan pencarian terhadap sebuah string.
Dalam melakukan analisa ini, penulis menggunakan sebuah contoh kasus pencarian sebuah kata”bacar” dari sekumpulan kata-kata” abang” ,”male”, “one” dan ”bacar”.
Tahap pertama dalam metode boyer-moore adalah membentuk sebuah array geser yang berisi daftar kata-kata yang akan dicari. Hasil dari tahap ini adalah sebuah array yang diberiksn nama AK dengan bentuk sebagai berikut : AK= [abang, male, one,bacar].
Tahap kedua adalah melakukan pencocokan terhadap huruf paling kanan dari kata yang akan dicari dengan elemen pertama dari AK. Dalam tahap ini, huruf terakhir dari kata “bacar” yaitu huruf “r” dicocokan dengan setiap huruf dari elemen pertama AK yaitu kata “abang”. Terlihat bahwa huruf “r” tidak dapat dalam baris huruf-huruf “abang”, sehingga kata”abang” dapat diabaikan.
Selanjutnya, dilakukan pencocokan terhadap elemen kedua dari AK, yaitu kata “male”. Kemudian dilakukan pencocokan huruf “r” dengan setiap huruf dari elemen kedua AK, yaitu kata “male”. Terlihat bahwa huruf “r” tidak terdapat dalam baris huruf-huruf “male”, sehingga
kata”male” dapat diabaikan. Langkah ini kemudian diulangi untuk elemen AK berikutnya yaitu kata”one” dan “bacar” .
Tahap terakhir dari metode boyer-moore adalah melakukan pengecekan panjang karakter pada seluruh hasil pencocokan yang diperoleh. Dari contoh kasus ini, kata “bacar” yang dicari memiliki panjang karakter sebanyak lima.
Kali ini saya akan menjelaskan cara kerja dari sebuah algoritma pencarian string dalam dokumen teks, yaitu algoritma Boyer-Moore. Boyer-Moore secara rata-rata merupakan algoritma pencarian string yang paling baik jika dibandingkan dengan algoritma pencarian string lainnya seperti Brute-Force ataupun Knuth-Morris-Pratt. Jika kita menggunakan fasilitas Find atau Search pada berbagai aplikasi pengolah teks, web browser, dan aplikasi lainnya mungkin saja kita telah memanfaatkan algoritma Boyer-Moore dalam pencarian tersebut, karena algoritma ini paling banyak diimplementasikan dalam berbagai aplikasi untuk fasilitas pencarian teksnya.
Algoritma Boyer-Moore adalah salah satu algoritma untuk mencari suatu string di dalam teks, dibuat oleh R.M Boyer dan J.S Moore. Ide utama algoritma ini adalah mencari string dengan melakukan pembandingan karakter mulai dari karakter paling kanan dari string yang dicari. Dengan mengunakan algoritma ini, secara rata-rata proses pencarian akan menjadi lebih cepat jika dibandingakan dengan algoritma lainnya. alasan melakukan pencocokan dari kanan (posisi terakhir string yang dicari) ditunjukan berikut ini :
Tabel 1: Tabel Pencarian Tahap Pertama
pada contoh diatas, dengan melakukan pembandingan dari posisi paling akhir string dapat dilihat bahwa karakter “g” pada string “kanan” tidak cocok dengan karakter “r” pada string “bacar” yang dicari, dan karakter “g” tidak pernah ada dalam string “bacar” yang dicari sehingga string “bacar” dapat digeser melewati string “kanan” sehingga posisinya menjadi :
Tabel 2 : Tabel Pencarian Tahap kedua
Dalam contoh terlihat bahwa algoritma Boyer-Moore memiliki loncatan karakter yang besar sehingga mempercepat pencarian string karena dengan hanya memeriksa sedikit karakter, dapat langsung diketahui bahwa string yang dicari tidak ditemukan dan dapat digeser ke posisi berikutnya yaitu :
Tabel 3 : Tabel Pencarian Tahap ketiga
(a)
Langkah ke-1
(c)
Langkah ke-2
Pada tahap string “one” juga tidak terdapat kecocokan oleh karena itu dapat digeser melewati string “one” untuk menuju tahap selanjutnya, sehingga menjadi :
Tabel 4 : Tabel Pencarian Tahap Keempat
Pada table keempat inilah akhir dari pencarian karena adanya kecocokan antara posisi karakter “r” yang paling kanan sesuai dengan string “bacar” yang diatasnya, sehingga dapat disimpulkan bahwa pencarian kata tersebut akan terus dilakukan sampai memenuhi string yang akan dicari.
3.2 Perancangan Sistem Yang Diusulkan Dari hasil analisa sistem yang dilakukan, selanjutnya dilakukan perancangan terhadap bentuk sistem yang akan dihasilkan. Dalam tahap perancangan ini, dirancang bentuk-bentuk form yang akan ditampilkan sebagai media interaksi antara pengguna dengan sistem, struktur table dari database sistem, dan digunakan alat bantu berupa
Use Case, Activity Diagram dan Squence Diagram.
Gambar 2 : Use Case
Selanjutnya akan digambarkan squencial diagram untuk menggambarkan interaksi antar objek yang mengindikasikan komunikasi diantara obyek-obyek tersebut. Sequence diagram
menggambarkan interaksi antar objek di dalam dan di sekitar sistem (termasuk pengguna, display, dan sebagainya) berupa message yang digambarkan terhadap waktu. Sequence diagram terdiri atar dimensi vertical (waktu) dan dimensi horizontal (objek-objek yang terkait). Adapun squencial diagram yang akan dirancang adalah sebagai berikut :
1. Squencial Menu Utama
Gambar 3 : Squensial Diagram pada menu tama
2. Squencial Form Kamus Gayo-Indonesia
Gambar 4 : Squensial form Kamus Gayo-Indonesia
3. Squencial Form Kamus Indonesia-Gayo
Gambar 5 : Squensial form Kamus Indonesia-Gayo
4. Squencial Menu About
Gambar 5 : Squencial Menu About Untuk menampung kata-kata yang akan digunakan sebagai bahan acuan dalam pencariaan translasi kata, dilakukan perancangan database sistem. Dengan adanya database sistem tersebut sejumlah kata yang diinputkan akan tersimpan dan di dalam pengejaannya akan dipanggil satu persatu sesuai dengan kata yang diinginkan. Adapun database sistem yang dirancang terdiri dari satu tabel yang diberi nama tabel pencarian kata. Database sistem ini dirancang menggunakan aplikasi MYSQL Server dengan struktur pada tabel.
Tabel 5 : Database Bahasa
4. Algoritma Dan Implementasi
Dalam matematika dan komputasi, algoritma merupakan kumpulan perintah untuk menyelesaikan suatu masalah. Perintah-perintah ini dapat diterjemahkan secara bertahap dari awal hingga akhir. Masalah tersebut dapat berupa apa
saja, dengan catatan untuk setiap masalah, ada kriteria kondisi awal yang harus dipenuhi sebelum menjalankan algoritma. Algoritma akan dapat selalu berakhir untuk semua kondisi awal yang memenuhi kriteria, dalam hal ini berbeda dengan heuristik. Algoritma sering mempunyai langkah pengulangan (iterasi) atau memerlukan keputusan (logika Boolean dan perbandingan) sampai tugasnya selesai.
4.1 Algoritma Translasi Kata Pada Kamus Algoritma translasi kata adalah algoritma yang dirancang oleh pengguna untuk melakukan pencarian kata bahasa Indonesia yang tersimpan di dalam database. Adapun bentuk algoritmanya terlihat pada pseudocode berikut ini :
Input : Masukan kata bahasa Gayo yang akanditerjemahkan
Output : Terjemahan bahasa Gayo dalam bahasa Indonesia
Proses : Cari bahasa yang diinputkan Buka database
Baca tabel Db_bahasa
Cari translasi bahasa yang diinputkan dalam database
If translasi bahasa ditemukan then
Klik “ terjemahan” untuk menampilkan translasi bahasa dan keterangan Else if bahasa dan keterangan dihapus then
Klik tombol “bersih” Else
Tampilkan translasi bahasa beserta keterangan
End if End if
Output : Tampilkan hasil translasi bahasa Gayo dan keteranga
4.2Algoritma Pencocokan String Boyer-Moore Algoritma ini adalah pencarian string dari kanan ke kiri, namun dalam melakukan pencarian translasi ini yang dicari hanyalah dalam bentuk kata, bukan kalimat oleh sebab itu kata-kata yang sudah terdaftar dalam database akan dicari sesuai dengan string yang dibutuhkan.
Adapun bentuk algoritma psoudocodenya adalah terlihat pada contoh di bawah ini :
Input :Pencarian kata dengan Boyer-Moore Output :Menampilkan translasi bahasa yang
sesuai pada list hasil Proses :If txt search =” ” then
Buka database
Baca jumlah kata dalam tabel bahasa Jlh=jumlah kata
Array AK (jlh) For i= 0 to jlh
Ak(i)= Data ke_i pada tabel bahasa Baca data selanjutnya Next
For i= 0 to jlh
Baca huruf paling kanan dari Ak (i) If huruf= huruf paling kanan dan cari then End if
Output :Tampilkan pencarian translasi kata yang sesuai pada list hasil
5. Keimpulan
Setelah penulis menguraikan semuanya tentang perancangan dan implementasi dari aplikasi kamus ini, maka penulis mengambil beberapa kesimpulan yaitu :
1. Teknik pencarian kosa kata dengan menggunakan kamus yang dilakukan oleh masarakat Gayo adalah dengan mecari urutan abjad dari suatu kata yang dicari, sehingga proses translasi yang dilakukan memakan waktu yang lama.
2. Dengan digunakannya metode Boyer-Moore dalam pembuatan aplikasi ini maka proses pencarian translasi kata pada database dapat berjalan dengan lebih cepat dan akurat . 1. Dengan dirancangnya Aplikasi kamus bahasa
Gayo-Indonesia maka mesarakat dapat melakukan translasi bahasa dengan menggunakan komputer PC atau notebook pribadi.
Daftar Pustaka
[1]. AL-Bahra bin Ladjamudin,2006, Analisis dan Desain Sistem Informasi, PT. Gramedia Pustaka Utama, Jakarta.
[2]. A.S Rosa, Salahuddin, M., 2011, Modul Pembelajaran Rekayasa Perangkat Lunak (Terstruktur dan Berorientasi Objek). [3]. Edy winarno ST, M. Eng, Ali Zaki, 2008,
Visual Studio 2008, PT. Gramedia Pustaka Utama, Jakarta.
[4]. George Scoot, 2008, Principles Of Manajement Information System, yang diterjemahkan oleh Jogianto H.M.
[5]. Sumber: http://id.wikipedia.org/wiki/Algoritma Diakses 25 Mei 2013
[6]. Sumber : http://id.wikipedia.org/wiki/Aplikasi Diakses 24 Mei 2013
[7]. Sumber: http://id.wikipedia.org/wiki/Kamus Diakses pada tanggal 15 Juli 2013
[8]. http://id.wikipedia.org/wiki/Bahasa_Gayo Diakses pada tanggal 15 Juli 2013
[9]. Stania Vandika(2009)” kinerja Algoritma Paralel untuk pencarian kata dengan metode Boyer-Moore menggunakan PVM [9]. Windra Swastika, “VB & MySQL Proyek
Membuat Aplikasi Point of sales ” Dian Rakyat, 2007 : hal 24