6 selanjutanya yang akan dikunjungi. Pada
kajian kali ini starting URL yang digunakan yaitu http://www.deptan.go.id/news/.
Kata kunci pada kajian kali ini adalah “pertanian agriculture tani petani padi jagung agri agribisnis”, dengan tujuan untuk mendapatkan halaman web yang berhubungan dengan pertanian.
2. Memasukkan link ke frontier
Frontier adalah daftar URL yang belum dikunjungi oleh web crawler (unvisited pages). Berdasarkan terminologi graf, frontier adalah sebuah node yang belum diekspan (unexpanded nodes). Aturan pada frontier tidak boleh ada duplikasi URL, untuk memastikannya digunakan pengecekan secara kueri basis data.
Memasukkan link ke frontier adalah proses memasukkan setiap link yang didapat dari starting URL atau link dari sebuah halaman web. Implementasi frontier pada kajian ini yaitu menggunakan basis data, rancangan struktur tabel pada basis data dapat dilihat di Lampiran 1.
3. Pengecekan pemberhentian crawling Pemberhentian crawling dilakukan jika total halaman web yang dikunjungi mencapai total maksimum yang ditentukan, atau jika frontier telah mencapai batas maksimum dalam sebuah penyimpanan.
4. Mengambil link dari frontier berdasarkan algoritme crawler
Mengambil link dari frontier berdasarkan aturan dari setiap algoritme yaitu algoritme breadth first, breadth first with time constraint, best first, dan page rank.
5. Fetch
Fetch adalah proses mengunjungi dan mengambil isi halaman web.
6. Parsing
Parsing adalah proses mengekstrak link dan kata atau frase dari sebuah halaman web. Pada tahapan ini dilakukan pengecekan apakah sebuah kata atau frase termasuk stop list, jika stop list maka tidak dimasukkan dalam penyimpanan.
Pada penelian ini menggunakan stop list Bahasa Indonesia dan Bahasa Inggris, alasan menggunakan stop list Bahasa Inggris dikarenakan beberapa dokumen web berbahasa Indonesia menggunakan istilah
Bahasa Inggris. Daftar stop list Bahasa Indonesia dan Bahasa Inggris dapat dilihat pada Lampiran 2.
7. Pengindeksan
Hasil dari tahapan fetch, dihitung bobot setiap kata atau frase yang didapat dengan term frequency (tf), kata atau frase dan bobotnya disimpan dalam basis data.
Evaluasi Algoritme
Evaluasi algoritme merupakan proses evaluasi terhadap algoritme web crawer yang telah diimplementasikan. Evaluasi dilakukan dengan tiga cara yaitu :
1. Menghitung nilai precision untuk setiap algoritme.
2. Menghitung kompleksitas untuk setiap algoritme.
3. Menghitung rata-rata fetch time sebanyak dua puluh iterasi untuk setiap algoritme.
HASIL DAN PEMBAHASAN Penggunaan Cronjob
Cronjob adalah aplikasi yang digunakan untuk penjadwalan, sehingga memungkinkan pengguna melakukan eksekusi aplikasi atau script program sesuai dengan waktu yang telah ditentukan. Pada penelitan ini digunakan aplikasi cronjob yang sudah terkonfigurasi langsung dengan Cpanel pada sebuah hosting. Tujuan dari penggunaan cronjob adalah untuk mengatur proses crawling sesuai dengan waktu yang ditentukan.
Memasukkan Link ke Frontier
Untuk mendapatkan link dari dokumen HTML yaitu dengan mengambil semua tag hyperlinks. Link yang benar (valid) harus memenuhi aturan sebagai berikut :
1. Sebuah link dengan nilai atribut href tidak boleh bernilai #.
2. Atribut href dari tidak mengandung ekstensi file yang telah dijelaskan pada ruang lingkup.
Pemberhentian Crawling
Pemberhentian crawling yaitu memberi nilai kontanta MAX_PAGES pada setiap algoritme dengan nilai tertentu, pada kajian ini menggunakan nilai konstanta sepuluh. Tujuan dari pemberhentian crawling yaitu agar
7 algoritme crawling tidak jalan terus menerus
yang akan menyebabkan membebani server. Mengambil Link dari Frontier Berdasarkan Algoritme Crawler
Proses ini merupakan pokok dari algoritme crawler yang digunakan untuk menentukan link mana saja yang didahulukan untuk dikunjungi. Berikut ini penjelasan proses pengambilan link dari frontier berdasarkan algoritme :
1. Breadth first
Proses penentuan link yang didahulukan untuk dikunjungi sangat sederhana yaitu menggunakan konsep FIFO, jika link yang terlebih dahulu masuk ke frontier maka akan dikunjungi terlebih dahulu.
2. Breadth first with time constraint
Proses penentuan link yang didahulukan pada algoritme ini sama persis dengan algoritme breadth first. Pada algoritme ini terdapat pengecualian dengan melakukan pengecekan, yaitu selisih antar waktu sekarang (now) dengan waktu terakhir sebuah link dikunjungi, selisih waktu tersebut harus memenuhi time threshold yang ditentukan.
Pada penelitian ini time threshold yang digunakan yaitu 24 jam (86400 detik), dengan alasan karena rata-rata sebuah halaman web diperbaharui dalam waktu sehari semalam.
3. Best first
Proses penentuan link yang didahulukan untuk dikunjungi dengan menggunakan nilai cosine similarity. Nilai cosine similarity sebuah halaman web dihitung berdasarkan kata kunci yang diberikan, nilai yang didapat akan diberikan pada setiap link yang ada pada halaman web tersebut. Untuk melihat algoritme cosine similarity dan perhitungan nilai cosine similarity secara manual pada sebuah halaman web dapat dilihat pada Lampiran 3.
4. Page rank
Proses penentuan link yang didahulukan untuk dikunjungi menggunakan dua pendekatan, yaitu nilai cosine similarity atau nilai page rank dari sebuah halaman web. Pertimbangan nilai cosine similarity digunakan hanya pada iterasi satu sampai lima, karena pada iterasi tersebut nilai page rank belum dihitung.
Ketentuan proses algoritme page rank pada web crawler yaitu sebagai berikut :
a) Jika jumlah halaman web kelipatan dari lima, maka dilakukan perhitungan nilai page rank untuk setiap link yang didapat dari frontier.
b) Untuk menentukan links yang akan dihitung nilai page rank-nya, yaitu dengan mengambil beberapa link dari frontier yang memiliki nilai cosine similarity tertinggi.
c) Jumlah links yang diambil dari frontier yaitu sepuluh, dengan pertimbangan jumlah MAX_PAGES sama dengan sepuluh, jadi penentuan link yang didahulukan untuk dikunjungi pada iterasi berikutnya tetap menggunakan nilai page rank.
d) Proses selanjutnya yaitu mendapatkan link keluar (out link) dari setiap link yang diambil dari frontier. Setelah diperoleh link keluar, maka dilakukan proses perhitungan nilai page rank.
Algoritme page rank dan implementasi page rank menggunakan bahasa pemrograman PHP dapat dilihat pada Lampiran 4.
Fetch
Implementasi fetch menggunakan library PHP (Client URL) merupakan sebuah library yang memungkinkan untuk terhubung dan berkomunikasi antar berbagai macam tipe server dengan berbagai macam protokol, salah satunya adalah HTTP. Halaman HTML yang didapat disimpan ke dalam basis data, kemudian akan digunakan untuk proses parsing.
Parsing
Untuk mendapatkan kata atau frase pada halaman web dilakukan pemrosesan HTML. Tujuan pemrosesan HTML yaitu agar karakter-karakter khusus serta nilai di dalam tag style dan tag script tidak dihitung sebagai kata atau frase.
Proses untuk mendapatkan kata atau frase yang benar (valid) dari sebuah halaman HTML, dilakukan dengan menggunakan regular expression, yaitu mengganti karakter-karakter khusus, tag style dan tag script dengan karakter kosong atau spasi. Implementasi regular expression dengan menggunakan bahasa pemrograman PHP dan karekter-karakter khusus yang harus disaring dapat dilihat pada Lampiran 5.
8 Pengideksan
Setelah proses parsing selesai, maka proses selanjutnya yaitu pengindeksan. Tabel 2 menunjukkan rekapitulasi lima kata atau frase paling banyak terdapat pada halaman web, yang didapat dari proses pengindeksan.
Tabel 2 Rekapitulasi lima kata atau frase paling banyak terdapat pada halaman web.
Breadth First Term Jumlah Kata Jumlah Dokumen pertanian 2230 138 berita 1677 162 biro 806 124 indonesia 788 173 nasional 713 173 Total link : 1617
Total link yang dikunjungi : 200 Total link yang belum dikunjungi : 1417
Breadth First with Time Constraint
Term Jumlah Kata Jumlah Dokumen pertanian 2800 152 berita 1549 180 biro 857 128 informasi 804 140 indonesia 779 174 Total link : 1612
Total link yang dikunjungi : 200 Total link yang belum dikunjungi : 1412
Best First Term Jumlah Kata Jumlah Dokumen pertanian 1984 158 berita 822 126 indonesia 604 145 biro 483 68 tanaman 482 86 Total link : 1646
Total link yang dikunjungi : 200 Total link yang belum dikunjungi : 1446
Page Rank Term Jumlah Kata Jumlah Dokumen pertanian 3386 161 gorontalo 2737 80 provinsi 1500 82 dinas 1022 75 berita 859 149 Total link : 1659
Total link yang dikunjungi : 200 Total link yang belum dikunjungi : 1459
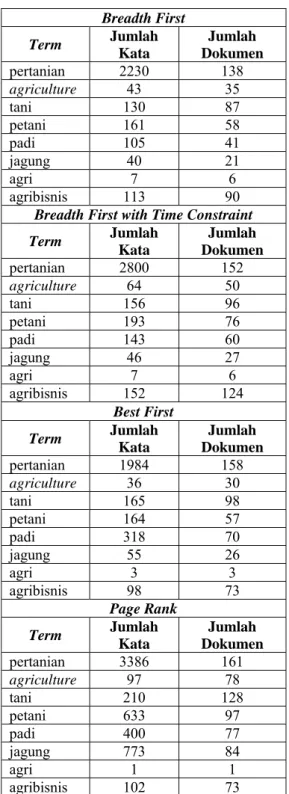
Tabel 3 menunjukkan rekapitulasi kata atau frase sesuai dengan kata kunci. Pada Tabel 3 terlihat bahwa kata “Pertanian” mempunyai jumlah dokumen paling banyak untuk setiap algoritme.
Tabel 3 Rekapitulasi kata atau frase sesuai dengan kata kunci.
Breadth First Term Jumlah Kata Jumlah Dokumen pertanian 2230 138 agriculture 43 35 tani 130 87 petani 161 58 padi 105 41 jagung 40 21 agri 7 6 agribisnis 113 90
Breadth First with Time Constraint
Term Jumlah Kata Jumlah Dokumen pertanian 2800 152 agriculture 64 50 tani 156 96 petani 193 76 padi 143 60 jagung 46 27 agri 7 6 agribisnis 152 124 Best First Term Jumlah Kata Jumlah Dokumen pertanian 1984 158 agriculture 36 30 tani 165 98 petani 164 57 padi 318 70 jagung 55 26 agri 3 3 agribisnis 98 73 Page Rank Term Jumlah Kata Jumlah Dokumen pertanian 3386 161 agriculture 97 78 tani 210 128 petani 633 97 padi 400 77 jagung 773 84 agri 1 1 agribisnis 102 73
9 Tabel 4 menunjukkan peluang kata kunci
per algoritme. Peluang dihitung dengan membagi antara jumlah dokumen kata atau frase dengan total dokumen yang didapat. Pada Tabel 4 terlihat bahwa rata-rata peluang algoritme page rank lebih baik dibanding dengan ketiga algoritme lainnya yaitu 0,437. Tabel 4 Peluang kata kunci per algoritme.
Term Peluang Algoritma ke-
1 2 3 4 pertanian 0,690 0,760 0,790 0,805 agriculture 0,175 0,250 0,150 0,390 tani 0,435 0,480 0,490 0,640 petani 0,290 0,380 0,285 0,485 padi 0,205 0,300 0,350 0,385 jagung 0,105 0,135 0,130 0,420 agri 0,030 0,030 0,015 0,005 agribisnis 0,450 0,620 0,365 0,365 Rata-rata 0,298 0,369 0,322 0,437 Keterangan : (1) Breadth First, (2) Breadth First with Time Constraint, (3) Best First, dan (4) Page Rank.
Evaluasi Algoritme
Evaluasi algoritme menggunakan beberapa pendekatan yaitu :
1. Nilai Precision
Untuk mendapatkan halaman web yang relevan sesuai dengan kata kunci dilakukan secara manual, yaitu dengan membuka setiap halaman web yang didapat, kemudian dilihat apakah relevan atau tidak dengan kata kunci.
Tabel 5 menunjukkan nilai precision untuk setiap algoritme, data mentah setiap algoritme untuk menghasilkan nilai precision dapat dilihat pada Lampiran 6. Berdasarkan evaluasi nilai precision, terlihat bahwa algoritme yang mempertimbangkan nilai estimasi antara kata kunci dengan halaman web lebih baik dibandingkan dengan algoritme yang tidak mempertimbangkan nilai estimasi.
Tabel 5 Perbandingan nilai precision.
Algoritme Halaman Relevan Precision
1 200 51 0,255
2 200 59 0,295
3 200 74 0,370
4 200 79 0,395
Keterangan : (1) Breadth First, (2) Breadth First with Time Constraint, (3) Best First, dan (4) Page Rank.
Gambar 10 sampai dengan Gambar 13 menunjukkan grafik hubungan antara nilai cosine similarity dengan urutan halaman web yang dikunjungi. Algoritme breadth first yang
tidak menggunakan nilai estimasi menunjukkan semakin besar iterasi maka nilai cosine similarity menuju ke nol.
Gambar 10 Grafik nilai cosine similarity algoritme breadth first.
Gambar 11 Grafik nilai cosine similarity algoritme breadth first with time constraint.
Gambar 12 Grafik nilai cosine similarity algoritme best first.
Gambar 13 Grafik nilai cosine similarity algoritme page rank
10 Pada penelitian ini dihitung juga nilai
rata-rata cosine similarty terhadap dua ratus dokumen yang dikumpulkan. Hasil yang didapat untuk algoritme page rank, breadth first with time constraint, best first dan breadth first dan yaitu masing-masing 0,175, 0,146, 0,143 dan 0,110.
2. Kompleksitas Algoritme a. Breadth first
Perhitungan kompleksitas algoritme breadth first sebagai berikut :
T(n) = 4n2 + 11n = O(n2)
Jadi, kompleksitas algoritme breadth first yaitu O(n2).
b. Breadth first with time constraint
Perhitungan kompleksitas algoritme breadth first with time constraint sebagai berikut :
T1(n) = 4n2 + 13n + 1 = O(n2)
T2(n) = 8n + 1 = O(n)
Jadi, kompleksitas algoritme breadth first with time constraint yaitu O(n2) atau O(n).
O(n2) yaitu worst case, terjadi saat
pengecekan time threshold terpenuhi. O(n) yaitu best case, terjadi saat pengecekan time threshold tidak terpenuhi.
c. Best first
Perhitungan kompleksitas algoritme best first sebagai berikut :
T(n) = 4n2 + 11n + (F(n)) n
dengan F(n) merupakan fungsi kompleksitas untuk algoritme cosine similarity. Perhitungan kompleksitas algoritme cosine similarity dapat dilihat pada Lampiran 3, dengan hasil sebagai berikut :
F(n) = 18n + 11, maka
T(n) = 4n2 + 11n + (18n + 11) n
T(n) = 22n2 + 22n = O(n2)
Jadi, kompleksitas algoritme best first yaitu O(n2).
Breadth-First(starting_urls) { for each link (starting_urls) {
enqueue(frontier, link); }
while (visited < MAX_PAGES ){ start_time; link=dequeue_link(frontier); page=fetch(link); visited = visited + 1; enqueue(frontier, extract_links(page)); end_time; } } Time 3n n n n n n 2n 4n2 n BestFirst(keyword,starting_urls){ for each link (starting_urls) {
enqueue(frontier,link, 1); }
while (visited < MAX_PAGES){ start_time;
link=dequeue_top_link( frontier);
page = fetch(link); score = sim(keyword, page); visited = visited + 1; enqueue(frontier, extract_links(page), score); end_time; } } Time 3n n n n n n (F(n)) n 2n 4n2 n Breadth-First(starting_urls) { for each link (starting_urls) {
enqueue(frontier, link); }
url = first(frontier); while (visited < MAX_PAGES){ if(Now()-
timeLastAccessToServer(url) > timeThereshld){ start_time; page = fetch(url); visited = visited + 1; enqueue(frontier, extract_links(page)); url = first(frontier); end_time; }else{ url = nextElement(frontier); } } } Time 3n n 1 n 2n n n 2n 4n2 n n n
11 d. Page rank
Perhitungan kompleksitas algoritme Page Rank sebagai berikut :
T1(n) = 4n2 + 16n + (F(n)) n
dengan F(n) merupakan fungsi kompleksitas untuk algoritme cosine similarity. Perhitungan kompleksitas algoritme cosine similarity dapat dilihat pada Lampiran 3, dengan hasil sebagai berikut :
F(n) = 18n + 11, maka
T1(n) = 4n2 + 16n + (18n + 11) n
T1(n) = 22n2 + 27n = O(n2)
T2(n) = T1 (n) + 3n2 + (G(n)) n2
dengan G(n) merupakan fungsi kompleksitas untuk algoritme page rank. Perhitungan kompleksitas algoritme page rank dapat dilihat pada Lampiran 4, dengan hasil sebagai berikut :
G(n) = 6n3 + 22n2 + 9n + 2
T2(n) = 25n2 + 27n + (G(n)) n2
T2(n) = 6n5 + 22n4 + 9n3 + 27n2 + 27n
Jadi, kompleksitas algoritme page rank adalah O(n2) atau O(n5). O(n2) yaitu best
case, terjadi saat algoritme page rank tidak dijalankan. O(n5) adalah worst case, terjadi
saat algoritme page rank dijalankan.
Tabel 6 menunjukkan perbandingan kompleksitas algoritme crawler. Algoritme page rank menunjukkan nilai kompleksitas lebih tinggi dibandingkan dengan algoritme lainnya, sehingga algoritme page rank membutuhkan sumber daya komputer yang lebih baik.
Tabel 6 Perbandingan kompleksitas.
Algoritme Kompleksitas
Breadth First O(n2)
Breadth First with Time
Constraint O(n
2)
Best First O(n2)
Page Rank O(n5)
3. Fetch Time
Fetch time adalah waktu yang dibutuhkan suatu algoritme crawler untuk mengunjungi dan mengambil suatu halaman web. Setiap itarasi yang menghasilkan sepuluh halaman web, kemudian dihitung nilai rata-rata fetch time.
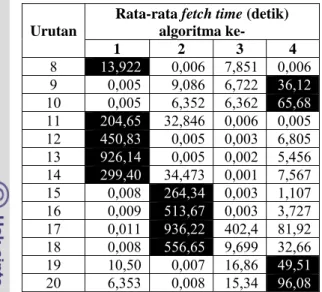
Tabel 7 menunjukkan rata-rata fetch time berdasarkan urutan pengulangan untuk setiap algoritme web crawler dijalankan. Untuk setiap urutan pengulangan, terlihat bahwa algoritme page rank sebelas kali mencapai nilai terbesar dibandingkan dengan algoritme lain. Hal ini terjadi dikarenakan proses perhitungan nilai page rank membutuhkan waktu.
Selain itu, terlihat bahwa algoritme best first lebih stabil dibanding dengan algoritme lain, karena tidak mencapai fetch time maksimum pada setiap iterasi. Pada iterasi ke sebelas sampai ke delapan belas, terlihat bahwa peningkatan fetch time yang tinggi untuk algoritme breadth first dan breadth first with time constraint. Hal ini terjadi karena akses ke server mulai melambat, atau akses ke halaman web tersebut memang lambat. Setelah dilakukan pengecekan ulang dengan data mentah, yang menyebabkan fetch time tinggi yaitu adanya komponen flash dalam halaman web tersebut. Tabel 7 Rata-rata fetch time.
Urutan
Rata-rata fetch time (detik) algoritma ke- 1 2 3 4 1 0,005 0,005 0,005 1,622 2 0,005 0,005 0,006 28,36 3 6,373 7,080 7,656 29,66 4 0,004 0,003 0,004 93,02 5 6,867 5,839 5,176 71,36 6 18,556 8,227 0,005 55,24 7 23,053 0,006 11,29 30,87 PageRank (keyword,starting_url){ for each link (starting_urls) { enqueue(frontier, link, 1); }
while (visited < MAX_PAGES){ start_time;
if(multiplies-X (visited)){ for each link (frontier){ PR(link) = compute_score_PR; }
}
link = dequeue_max_PR(frontier); if(link not found){
link = dequeuetoplink(frontier); }
page = fetch(link); score = sim(topic, page); visited = visited + 1; enqueue(frontier, extract_links(page),score); end_time; } } Time 3n n n n 3n 3n2 (G(n)) n2 n n n n (F(n)) n 2n 4n2 n
12 Urutan Rata-rata fetch time (detik) algoritma
ke-1 2 3 4 8 13,922 0,006 7,851 0,006 9 0,005 9,086 6,722 36,12 10 0,005 6,352 6,362 65,68 11 204,65 32,846 0,006 0,005 12 450,83 0,005 0,003 6,805 13 926,14 0,005 0,002 5,456 14 299,40 34,473 0,001 7,567 15 0,008 264,34 0,003 1,107 16 0,009 513,67 0,003 3,727 17 0,011 936,22 402,4 81,92 18 0,008 556,65 9,699 32,66 19 10,50 0,007 16,86 49,51 20 6,353 0,008 15,34 96,08 Keterangan : (1) Breadth First, (2) Breadth First with Time Constraint, (3) Best First, dan (4) Page Rank. Cell dengan latar hitam menunjukkan nilai terbesar untuk setiap iterasi per algoritme.
Gambar 14 menunjukkan grafik hubungan antara urutan pengulangan web crawler dengan rata-rata fetch time, dengan data diambil dari Table 7.
KESIMPULAN DAN SARAN Kesimpulan
Hasil penelitian berdasarkan nilai precision dan peluang kata kunci per algoritme menunjukkan bahwa algoritme page rank lebih baik dibanding dengan algoritme lainnya. Hasil penelitian berdasarkan kompleksitas algoritme, menunjukkan bahwa algoritme page rank memiliki kompleksitas lebih tinggi dibandingkan dengan algoritme lainnya. Selain itu, berdasarkan rata-rata fetch time menunjukkan bahwa algoritme best first lebih stabil dibanding dengan algoritme lainnya.
Saran
1. Implementasi pada penelitian ini menggunakan share hosting, sehingga tidak leluasa dalam menggunakan resources server. Perlu adanya server tersendiri untuk web crawler agar pengambilan halaman web lebih cepat.
2. Masih terdapat algoritme web crawler lain selain ke-4 algoritme yang telah dikaji pada penelitian ini, sehingga pada penelitian selanjutnya diharapkan dapat mengkaji algoritme web crawler yang lain.
3. Proses pengindeksan masih menggunakan metode sederhana yaitu term frequency (tf), diharapkan pada penelitian selanjutnya menggunakan metode pengindeksan lain yang lebih baik.
DAFTAR PUSTAKA
Brin, Page. 1998. The Anatomy of a Large-Scale Hypertextual Web Search Engine. http://infolab.stanford.edu/~backrub/google. htm.
Cormen et al. 2002. Introduction to Algorithms Second Edition. England. The MIT Press Cambridge.
Manning et al. 2009. Introduction to Information Retrieval. England. Cambridge University Press.
Menczer et al. 2004. Topical Web Crawlers: Evaluating Adaptive Algorithms. ACM Transactions on Internet Technology. http://dollar.biz.uiowa.edu/~pant/Papers/TO IT.pdf.
Romero T, Rafael. 2006. Simulation tool to study focused web crawling strategies. http://combine.it.lth.se/CrawlSim/CrawlSim. pdf.
Srinivasan. 2004. Target Seeking Crawlers and their Topical Performance. http://citeseerx.ist.psu.edu/viewdoc/downloa d?doi=10.1.1.23.6092.