PENERAPAN MODEL AUTOREGRESSIVE FRACTIONALLY INTEGRATED MOVING AVERAGE (ARFIMA) DALAM PERAMALAN
SUKU BUNGA SERTIFIKAT BANK INDONESIA (SBI)
Oleh
LIANA KUSUMA NINGRUM M0105047
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan memperoleh gelar Sarjana Sains Matematika
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SEBELAS MARET SURAKARTA
BAB I PENDAHULUAN
1.1 Latar Belakang Masalah
Menurut Box, et. al. (1994), time series merupakan serangkaian data pengamatan berdasarkan urutan waktu. Observasi yang diamati merupakan barisan bernilai diskrit yang diperoleh pada interval waktu yang sama. Metode pemodelan time series yang telah dikembangkan adalah Exponential Smoothing, Autoregressive (AR), Moving Average (MA), Autoregressive Moving Average (ARMA), dan Autoregressive Integrated Moving Average (ARIMA). Metode yang paling umum digunakan adalah ARIMA. ARIMA sangat efektif digunakan untuk memodelkan data yang tidak stasioner, yang ditunjukkan oleh plot ACF yang turun secara eksponensial atau membentuk gelombang sinus. Ada beberapa data yang tidak stasioner dan plot ACF-nya tidak turun secara eksponensial melainkan secara lambat atau hiperbolik. Data seperti inilah yang dikategorikan sebagai time series memori jangka panjang (long memory). Untuk memodelkan time series jangka panjang, Hosking (1981) telah memperkenalkan model Autoregressive Fractionally Integreted Moving Average (ARFIMA) yang dapat mengatasi kelemahan model ARIMA. ARIMA hanya dapat menjelaskan time series jangka pendek (short memory), sedangkan ARFIMA dapat menjelaskan baik jangka pendek maupun jangka panjang.
Analisis time series jangka panjang telah banyak diterapkan di berbagai bidang ilmu. Dalam bidang ekonomi, Doornik dan Ooms (1999) melakukan penelitian terhadap indeks harga konsumen di Amerika Serikat dan Inggris menggunakan ARFIMA dengan estimasi parameter metode Exact Maximum Likelihood (EML). Menurut Ishida dan Watanabe (2008), Watanabe dan Yamaguchi melakukan perbandingan beberapa metode pemodelan dan peramalan terhadap Indeks Bursa Nikkei Jepang dengan menggunakan model ARFIMA, AR, Generalized Autoregressive Conditional Heterokedasticity (GARCH), dan Heterogen Interval Autoregressive (HAR). Hasil penelitian tersebut menyatakan
bahwa model ARFIMA merupakan model yang paling akurat untuk pemodelan dan peramalan Indeks Bursa Nikkei Jepang.
Dalam penelitian ini dilakukan pemodelan data suku bunga Sertifikat Bank Indonesia (SBI) dengan menggunakan pendekatan time series memori jangka panjang ARFIMA. Selanjutnya dari pemodelan ini dapat dilakukan peramalan dengan menggunakan model tersebut. Peneliti memilih data suku bunga SBI karena tingkat suku bunga merupakan salah satu faktor yang mempengaruhi kegiatan investasi, dan datanya mengandung memori jangka panjang, yang ditunjukkan oleh plot ACF yang turun secara lambat.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah di atas, rumusan masalah yang akan dikemukakan adalah sebagai berikut.
1. Bagaimana pemodelan ARFIMA pada data suku bunga SBI.
2. Bagaimana hasil peramalan model ARFIMA pada data suku bunga SBI untuk 4 periode ke depan.
1.3 Batasan Masalah
Dalam penelitian ini dilakukan pembatasan masalah yaitu estimasi parameter model ARFIMA menggunakan metode Exact Maximum Likelihood (EML), dan peramalan suku bunga SBI dilakukan dari periode 430 sampai dengan periode 433, yaitu dari tanggal 19 Agustus 2009 sampai dengan 9 September 2009.
1.4 Tujuan Penulisan
Tujuan penelitian ini adalah sebagai berikut.
1. Dapat menentukan model ARFIMA untuk data suku bunga SBI.
2. Meramalkan suku bunga SBI untuk 4 periode ke depan dengan menggunakan model ARFIMA.
1.5 Manfaat Penulisan
Manfaat yang diperoleh dari penelitian ini adalah model peramalan data dapat diketahui, sehingga dapat digunakan sebagai acuan para pelaku pasar dalam melakukan investasi.
BAB II
TINJAUAN PUSTAKA
2.1. Analisis Time Series
Time Series merupakan pengamatan terurut waktu atau barisan yang tergantung pada waktu dari observasi suatu variabel yang diamati. Pemodelan time series memerlukan asumsi bahwa data dalam keadaan stasioner. Time series dikatakan stasioner jika tidak ada perubahan dalam mean dan perubahan variansi.
Misal { } merupakan suatu variabel random. Menurut Wei (1990), { } dikatakan strictly stasioner jika
1. = { } = (mean konstan)
2. Jika ( ) <∞, maka = { − } = (variansi konstan)
3. { , } = {[ − ][ − ]} = untuk setiap t dan k bilangan bulat.
Dalam pemodelan time series sering ditemukan kondisi dengan mean tidak stasioner, sehingga diperlukan suatu cara untuk menstasionerkan data yaitu dengan cara pembedaan atau biasa ditulis (1− ) . Pembedaan ini dilakukan agar dapat mengatasi korelasi antara dengan , dengan k yang cukup besar. Pada memori jangka pendek, pembedaan dilakukan dengan d bernilai bilangan bulat, sedangkan pada memori jangka panjang, pembedaan dilakukan dengan d bernilai bilangan riil.
Dalam pemodelan time series juga sering ditemukan kondisi dengan variansi tidak stasioner atau tidak konstan. Untuk menstasionerkan data dalam
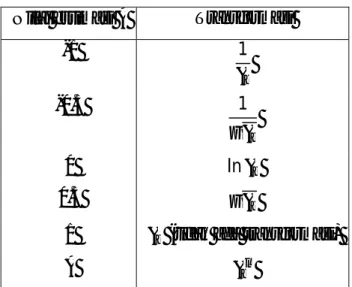
variansi dapat dilakukan dengan transformasi data sehingga didapatkan data yang stasioner dalam variansi. Salah satu transformasi yang biasa digunakan adalah transformasi Box-Cox (power transformation). Transformasi Box-Cox (Wei, 1990) untuk beberapa nilai yang sering digunakan ditampilkan pada Tabel 2.1.
Tabel 2.1. Transformasi Box-Cox Nilai estimasi Transformasi
-1 1
-0.5 1
0 ln
0.5
1 (tidak ada transformasi)
2.2. Autokorelasi dan Autokorelasi Parsial 2.2.1. Fungsi Autokorelasi (ACF)
Menurut Wei (1990), { } yang stasioner akan mempunyai nilai mean [ ] = , dan variansi ( ) = ( − ) = yang mempunyai nilai-nilai yang konstan, serta kovariansi ( , ) merupakan fungsi dari perbedaan waktu ( − ). Kovariansi antara dan dapat ditulis sebagai
= ( , ) = [( − )( − )]
sedangkan autokorelasi antara dan dapat ditulis sebagai
= ( , )
( ) ( ) ,
dengan ( ) = ( ) = , sehingga didapatkan
Menurut Wei (1990), untuk suatu proses yang stasioner, fungsi autokovariansi dan fungsi autokorelasi memenuhi sifat
1. = ( ), = 1 2. | |≤ , | |≤ 1
3. = , = , untuk semua nilai k.
2.2.2. Fungsi Autokorelasi Parsial (PACF)
Fungsi autokorelasi parsial berguna untuk mengukur tingkat keeratan hubungan antara dan setelah dependensi linear dalam variabel , , … , telah dihilangkan. Menurut Wei (1990), fungsi autokorelasi parsial (PACF) dapat dinyatakan sebagai
= ( , | , … , )
= − ∑ ,
1− ∑ ,
dengan = , − , , untuk j=1,2,…,k-1.
2.3. Model Time Series Stasioner 2.3.1. Model Autoregressive (AR)
Model runtun waktu autoregressive merupakan suatu observasi pada waktu t yang dinyatakan sebagai persamaan linear terhadap p waktu sebelumnya ditambah dengan sebuah variabel random . Dalam bentuk persamaan, model ini dapat dinyatakan dengan
= + +⋯+ + .
Diasumsikan { } variabel random yang berdistribusi identik dan independen, dengan mean nol untuk setiap t, akibatnya [ ] = 0 dan ( ) konstan (Cryer, 1986).
Fungsi autokorelasi pada model AR dicari dengan mengalikan pada kedua sisi persamaan AR(p) dan dicari ekspektasinya
= +⋯+ , > 0
dengan nilai ( ) = 0 untuk > 0. Dengan membagi persamaan di atas dengan diperoleh fungsi autokorelasinya
ρ = ϕ ρ +⋯+ϕ ρ , untuk k = 1,2, …
Pada proses ini kurva fungsi autokorelasinya akan turun secara eksponensial atau menyerupai gelombang sinus. Fungsi autokorelasi parsial untuk model AR adalah
= 0, >
Pada proses ini autokorelasi parsial bernilai nol setelah lag p atau kurva akan terputus setelah suku ke-p. untuk setiap proses, kurva estimasi akan dipandang sebagai himpunan parameter-parameter terakhir yang diperoleh jika berturut-turut model AR(p), p=1,2,… digunakan pada data.
2.3.2. Model Moving Average (MA)
Pada model moving average, observasi pada waktu t dinyatakan sebagai kombinasi linear dari sejumlah variabel random . Menurut Cryer (1986), model dari moving average dapat ditulis
= − − − ⋯ − .
Diasumsikan { } variabel random yang berdistribusi identik dan independen, dengan mean nol untuk setiap t. akibatnya [ ] = 0 dan ( ) konstan.
Untuk proses MA(q) variansinya adalah ( ) = ∑ , dengan nilai = 1 dan autokovariansinya adalah
= − + +⋯+ , = 1,2, … ,
0 , > sehingga diperoleh fungsi autokorelasinya
=
− + + +⋯+
1 + + +⋯+ , = 1,2, … ,
Pada grafik fungsi autokorelasi akan bernilai nol setelah lag q, dan grafik fungsi autokorelasi parsial akan turun secara eksponensial atau membentuk gelombang sinus untuk k yang semakin besar.
2.3.3. Model Autoregressive Moving Average (ARMA)
Untuk mendapatkan parameter parsimony (model mempunyai parameter yang sedikit), terkadang kedua bentuk autoregressive dan moving average perlu dimasukkan dalam model. Dengan demikian, model dapat ditulis dalam bentuk
= +⋯+ + − − ⋯ −
atau bisa ditulis sebagai
( ) = θ(L)
dengan ( ) = 1− − ⋯ − dan ( ) = 1− − ⋯ − . Model ini disebut sebagai model Autoregressive Moving Average orde (p,q), atau biasa disebut sebagai model ARMA(p,q), dimana p dan q masing-masing menunjukkan orde dari proses autoregressive dan moving average (Cryer, 1986).
2.4. Model Time Series Tidak Stasioner
2.4.1. Model Autoregressive Integrated Moving Average (ARIMA)
Apabila pola data stasioner terhadap mean tidak dipenuhi maka perlu dilakukan suatu cara untuk membuat menjadi stasioner. Runtun waktu yang tak stasioner dapat diubah menjadi stasioner dengan melakukan pembedaan.
Secara umum proses pembedaan pada suatu data runtun waktu dengan orde d dapat ditulis
= (1− ) ,
dengan nilai d=1,2,…,n. Proses pembedaan orde pertama dapat ditulis
= (1− ) = − ,
dengan adalah observasi pada waktu ke-t, t=1,2,…,n
adalah observasi pada satu periode sebelumnya (t-1) adalah data setelah pembedaan.
Apabila pola data stasioner dalam variansi tidak dipenuhi, maka dapat dilakukan transformasi data untuk menstasionerkan datanya.
Model ARIMA pertama kali diperkenalkan oleh Box-Jenkins pada tahun 1970 (Cryer, 1986). Bentuk umum ARIMA (p,d,q) adalah
( )(1− ) =θ +θ( ) dengan
1. ( ) dinamakan operator autoregressive.
2. ( )(1− ) dinamakan operator generalized autoregressive non stasioner.
3. θ( ) dinamakan operator moving average yang diasumsikan invertible.
2.4.2. Model ARFIMA (p,d,q)
Proses ARMA sering dinyatakan sebagai proses memori jangka pendek (short memory) karena autokorelasi antara dan turun sangat cepat untuk
→ ∞. Dalam kasus-kasus tertentu, autokorelasi turun lambat secara hiperbolik untuk lag yang semakin besar. Hal ini menunjukkan masih ada hubungan antara pengamatan yang jauh terpisah atau memiliki ketergantungan jangka panjang (long memory).
Suatu proses stasioner dengan fungsi autokorelasi dikatakan sebagai proses memori jangka panjang jika lim →∞∑ | | tidak konvergen (Hosking, 1981).
Penyelidikan terhadap proses memori dapat diamati pada fungsi autokorelasi. Deret berkala dikatakan mengikuti proses memori jangka pendek jika
lim
→∞ | | <∞ dan akan mengikuti proses memori jangka panjang jika
lim →∞∑ | | =∞.
Model ARFIMA merupakan pengembangan dari model ARIMA. Suatu proses dikatakan mengikuti model ARFIMA jika nilai d adalah riil. ARFIMA
disebut juga ARIMA yang nilai d tidak hanya berupa nilai integer, melainkan termasuk juga nilai-nilai riil yang disebabkan oleh adanya memori jangka panjang. Menurut Doornik dan Ooms (1999), model ARFIMA(p, d, q) dapat ditulis
( ) = θ(L) , = 1, 2, … ,
dengan level integrasi d merupakan bilangan riil dan ~ (0, ). Filter pembeda pada rumus di atas disebut Long Memory Filter (LMF) yang menggambarkan adanya ketergantungan jangka panjang dalam deret. Filter ini diekspansikan sebagai deret Binomial
∇ = (1− ) = (−1) ∞ , > dengan = ! !( )! = ( )
( ) ( ) dan Γ( ) merupakan fungsi gamma,
sehingga ∇ = 0 (−1) + 1 (−1) + 2 (−1) +⋯ = ! 0! ( −0)! − ! 1! ( −1)! + ! 2! ( −2)! +⋯ = 1− −1 2(1− ) − 1 6(2− )(1− ) +⋯
Asumsi-asumsi pada deret yang terintegrasi fraksional yang harus dipenuhi menurut Sowell (1992) adalah
1. ( ) mempunyai orde kurang dari atau sama dengan p, ( ) mempunyai orde kurang dari atau sama dengan q, akar-akar ( ) dan ( ) di luar unit circle dan ~ (0, ).
2. | | <
3. akar-akar dari ( ) sederhana, atau dengan kata lain akar-akar polynomial autoregressive tidak berulang.
Suatu proses dikatakan mengikuti model ARFIMA jika level integrasi yang ada dalam model adalah riil. Menurut Hosking (1981), karakteristik deret yang fractionally integrated untuk berbagai nilai d adalah
1. | |≥ menyatakan proses panjang dan tidak stasioner.
2. 0 < < menyatakan proses berkorelasi panjang stasioner dengan adanya ketergantungan positif antar pengamatan yang terpisah jauh yang ditunjukkan dengan autokorelasi positif dan turun lambat dan mempunyai representasi moving average orde tak hingga.
3. − < < 0 menyatakan proses berkorelasi panjang stasioner dengan memiliki ketergantungan negatif yang ditandai dengan autokorelasi negatif dan turun lambat serta mempunyai representasi autoregressive orde tak hingga.
4. = 0 menyatakan proses berkorelasi pendek.
Untuk fungsi autokovariansi dan autokorelasi dapat dicari sebagai berikut. Fungsi autokovariansi dari { } adalah
= ( , ) = (−1) (−2 )! ( − )! (− − )!. sehingga fungsi autokorelasi dari { } adalah
= =(− )! ( + −1)!
( −1)! ( − )! , = 0, ±1, … dengan = {(( )!})! serta = .
Ketika memodelkan time series memori jangka panjang, model ARFIMA memberikan hasil yang tidak dapat diperoleh dengan model tak fraksional ARIMA. Parameter pembedaan fraksional menangkap adanya fenomena jangka panjang tanpa menimbulkan masalah-masalah yang berkaitan dengan model ARMA. Menurut Sowell (1992), masalah yang mungkin muncul dalam memodelkan time series jangka panjang dengan ARMA antara lain
1. dengan menggunakan model ARMA untuk menangkap fenomena jangka panjang, apabila parameter AR atau MA mampu menangkap fenomena jangka panjang maka pendekatan untuk jangka pendek akan terabaikan. Sebagai contoh, dengan parameter AR(1) tidak mungkin dapat memodelkan korelasi yang tinggi pada siklus sepuluh tahunan. Masalah
yang sama muncul dalam memodelkan ketergantungan jangka panjang yang negatif.
2. sebaliknya, jika dugaan akan adanya fenomena jangka panjang pada deret diabaikan untuk mendapatkan model yang lebih baik untuk fenomena jangka pendek, maka tidak ada cara yang tepat dalam menggambarkan parameter AR dan MA untuk menggambarkan karakteristik jangka panjang pada deret, walaupun sebenarnya peneliti menemukan fenomena jangka panjang pada deret.
Model ARFIMA (p,d,q) lebih dapat diterima bahkan untuk permasalahan tidak fraksional ARMA (p,q). Model ARFIMA akan tak stasioner jika ≥ . Bagaimanapun juga ketergantungan jangka panjang ini berhubungan dengan seluruh > 0 yang menangkap fenomena jangka panjang tanpa berpengaruh terhadap jangka pendeknya.
Keuntungan yang didapat jika menggunakan model ARFIMA (p, d, q) menurut Sowell (1992) adalah
1. mampu memodelkan perubahan yang tinggi dalam jangka panjang (long term persistence).
2. mampu menjelaskan struktur korelasi jangka panjang dan jangka pendek sekaligus.
3. mampu memberikan model dengan parameter yang lebih sederhana (parsimony) baik untuk data dengan memori jangka panjang maupun jangka pendek.
Langkah-langkah yang ditempuh dalam pemodelan ARFIMA adalah estimasi parameter, pengujian parameter, pengujian diagnostik model, pemilihan model terbaik, serta peramalan model ARFIMA.
1. Estimasi Parameter
Menurut Doornik dan Ooms (1999), ada beberapa metode estimasi parameter model ARFIMA antara lain Geweke dan Porter Hudak (GPH), Non-Linear Least Square (NLS), Exact Maximum Likelihood (EML) dan Modified Profile Likelihood (MPL). Pada penelitian ini, akan digunakan metode EML.
= [( − )( − )].
Didefinisikan matriks kovariansi dari distribusi bersama = [ , , … , ]′ adalah [ ] = ⎣ ⎢ ⎢ ⎢ ⎡ … ⋮ ⋮ … ⎦ ⎥ ⎥ ⎥ ⎤ = ∑
dengan [ ] merupakan suatu matriks Toeplitz simetris, dinyatakan dengan [ , , … , ] dan diasumsikan berdistribusi normal ~ ( ,∑).
Berdasarkan persamaan pada model ARFIMA dengan ~ ( ,∑), fungsi densitas probabilitasnya adalah
( ,∑) = (2 ) / |∑| − ′∑
dengan adalah matriks kovariansi.
Penaksiran parameter model dengan metode EML dilakukan dengan membentuk fungsi log-likelihood dari parameter model. Dengan = − , fungsi tersebut dinyatakan sebagai
log ( , , , ) =− 2log(2 )− 1 2log|∑|− 1 2 ′∑ . dengan ∑= , maka persamaan menjadi
log ( , , , ) =− 2log(2 )− 1 2log| |− 1 2 ′ =− 2log(2 )− 1 2log( ) − 1 2log| |− 1 2 ′ =− 2log(2 )−2log( )− 1 2log| |− 1 2 ′ .
Nilai maksimum didapatkan dengan melakukan diferensiasi pada fungsi log-likelihood di atas terhadap .
(log ( , , , ))
=− + ′ .
Jika turunan pertama tersebut disamadengankan nol, maka persamaan di atas menjadi
− =− ′ sehingga didapat
= ′ .
2. Pengujian parameter
Uji signifikansi parameter model dilakukan untuk membuktikan bahwa model yang didapatkan cukup memadai. Bila estimasi parameter pada model ARFIMA adalah , sedangkan estimasi standar error dari estimasi parameter adalah , maka hipotesis yang digunakan dalam pengujian parameter adalah
i. H0: = 0 (parameter tidak berpengaruh terhadap model)
H1: ≠ 0 (parameter berpengaruh terhadap model)
ii. statistik uji
=
iii. kaidah pengambilan keputusan. Tolak H0 jika > ( ), dengan n
adalah banyaknya observasi, dan p adalah jumlah parameter yang ditaksir.
3. Pengujian Diagnostik Model
Suatu model dibangun dengan batasan-batasan (asumsi), sehingga kesesuaian model juga dipengaruhi oleh pemenuhan asumsi-asumsi yang telah ditetapkan. Hal ini bertujuan untuk mengetahui apakah model yang telah diestimasi cukup cocok dengan data runtun waktu yang diramalkan.
Pada pengujian diagnostik ini dilakukan analisis nilai sisa. Model dikatakan memadai jika nilai sisa adalah white noise, yaitu nilai sisa mempunyai mean nol dan variansi konstan, serta nilai sisa tidak berkorelasi. Selain itu nilai sisa juga harus memenuhi asumsi distribusi normal. Apabila ternyata model tidak memenuhi asumsi tersebut, maka harus dirumuskan kembali model yang baru, yang selanjutnya diestimasi dan parameternya diuji kembali.
Untuk mengetahui apakah autokorelasi dari nilai nilai sisa berbeda dengan nol atau tidak, bisa dilakukan uji Ljung-Box dengan hipotesis
i. H0: = =⋯ = = 0 (tidak ada korelasi antar nilai sisa)
H1: Minimal ada satu nilai ≠0; = 1,2, … ,
ii. statistik uji
= ( + 2) ( − )
dengan merupakan ACF dari nilai sisa pada lag k.
iii. kaidah pengambilan keputusan. Tolak H0 jika > χ( ; ), atau −
< dimana k adalah maksimum lag (Wei, 1990). 2) Asumsi nilai sisa berdistribusi normal
Uji Kolmogorof-Smirnov dapat digunakan untuk melihat apakah nilai sisa berdistribusi normal. Jika ( ) menyatakan distribusi empirik sampel acak yang nilainya merupakan fungsi peluang kumulatif dan ( )∗ menyatakan distribusi normal dengan mean dan variansi tertentu, ∼ ( , ), maka hipotesis yang digunakan adalah
i. H0: ( )= ( )∗
H1: ( ) ≠ ( )∗
ii. statistik uji
= ( )∗ − ( )
dengan D merupakan supremum pada setiap x dari absolut selisih ( )∗ − ( ). iii. kaidah pengambilan keputusan. Tolak H0 jika ≥ , atau − < ,
dimana adalah nilai tabel Kolmogorof-Smirnov pada kuantil (1− ).
4. Pemilihan Model Terbaik
Suatu model setelah diidentifikasi memungkinkan terbentuknya lebih dari satu model yang sesuai. Untuk memilih model terbaik pada analisis time series, kriteria pemilihan model biasanya didasarkan pada statistik yang diperoleh dari nilai sisa. Pada penelitian ini kriteria pemilihan model didasarkan pada nilai sisa
yaitu Mean Square Error (MSE), Mean Absolute Percentage Error (MAPE), serta Akaike Info Criterion (AIC).
1) MSE
= ∑
−
dengan adalah nilai sisa.
adalah banyak parameter. adalah banyaknya nilai sisa.
Nilai MSE juga merupakan nilai estimasi dari variansi nilai sisa . Sehingga model yang baik adalah model yang memiliki nilai MSE kecil, karena dengan nilai MSE kecil berarti nilai estimasi hampir sama dengan nilai sesungguhnya (Makridakis dan Wheelwright, 1995).
2) MAPE
MAPE adalah rata-rata persentase absolut dari kesalahan peramalan, oleh karena itu, semakin kecil nilai MAPE maka nilai ramalan akan semakin akurat. Untuk menghitung MAPE digunakan persamaan
= 1 − × 100%
dengan adalah nilai aktual dan adalah nilai ramalan (Makridakis dan Wheelwright, 1995).
3) AIC
Akaike pada tahun 1973 memperkenalkan suatu pemilihan model terbaik selain MSE. AIC digunakan untuk menemukan model yang dapat menjelaskan data dengan parameter bebas yang minimum. Model yang dipilih adalah model dengan nilai AIC terendah. Wei (1990) menjelaskan untuk menghitung AIC digunakan persamaan
= ln + 2
dengan n : banyaknya observasi.
Menurut Doornik dan Ooms (1999), = ( , , … )′ adalah nilai-nilai pengamatan setelah estimasi. Diasumsikan y adalah stasioner dan d > -1, maka prediksi linear terbaik dari y adalah
= [ ( −1 +ℎ) … (ℎ)]{ [ (0), … , ( −1)]} = ′
yang terdiri dari kebalikan fungsi autokovarian dikalikan dengan data aslinya yang diboboti oleh korelasinya. MSE peramalannya adalah
[ ] = [ (0)− ′ ].
BAB III
METODE PENELITIAN
3.1. Bahan Penelitian
Sesuai dengan permasalahan yang akan dibahas dalam skripsi ini, maka bahan yang digunakan dalam penelitian ini adalah sebagai berikut.
1. Jurnal dan buku referensi yang terkait dengan permasalahan.
2. Data sekunder Suku Bunga SBI yang diterbitkan oleh Bank Indonesia melalui
http://www.bi.go.id, yang berupa data mingguan dari periode 21 Juni 2000 sampai 12 Agustus 2009.
3. Software yang digunakan adalah Ox Metrics, dan Minitab 13.
3.2. Metode Penelitian
Metode yang digunakan dalam penelitian ini adalah studi kasus. Studi kasus adalah menerapkan teori yang telah dipelajari untuk menganalisis data.
Untuk mencapai tujuan penulisan skripsi ini, ditempuh langkah-langkah sebagai berikut.
1. Analisis pola data
a. Membuat plot time series data Suku Bunga SBI untuk mengetahui apakah data tersebut sudah stasioner atau belum.
b. Melakukan transformasi jika ada data yang tidak stasioner dalam variansi. c. Membuat plot ACF dan PACF data yang telah ditransformasi untuk
mengetahui adanya ketergantungan jangka panjang. 2. Pemodelan ARFIMA
Tahapan-tahapan dalam pemodelan ARFIMA adalah sebagai berikut. a. Estimasi parameter
Estimasi parameter model ARFIMA menggunakan metode Exact Maximum Likelihood (EML).
b. Uji diagnostik
Pada tahap ini diuji apakah residual memenuhi asumsi white noise dan berdistribusi normal.
c. Pemilihan model terbaik
Model yang telah memenuhi syarat (parameter signifikan, residual memenuhi asumsi white noise dan berdistribusi normal) akan dibandingkan berdasarkan kriteria MSE, MAPE, dan AIC.
3. Peramalan
Membuat ramalan Suku Bunga SBI untuk 4 periode ke depan dengan menggunakan model ARFIMA yang diperoleh.
Gambar 3.1. Diagram alur penelitian
BAB IV PEMBAHASAN
4.1. Deskripsi Data
Suku bunga adalah persentase dari pokok utang yang dibayarkan sebagai imbal jasa (bunga) dalam suatu periode tertentu. Sertifikat Bank Indonesia (SBI) adalah surat berharga yang dikeluarkan oleh Bank Indonesia sebagai pengakuan
Transformasi Identifikasi ARFIMA (p,d,q) ACF Tidak Stasioner Stasioner Estimasi Parameter Pemilihan Model Terbaik Uji Diagnostik Peramalan Tidak memenuhi Memenuhi Data Plot Data
utang berjangka waktu pendek (1-3 bulan) dengan sistem diskonto atau bunga. SBI merupakan salah satu mekanisme yang digunakan Bank Indonesia (BI) untuk mengontrol kestabilan nilai Rupiah. Ketika suku bunga dinaikkan, maka orang akan tertarik untuk menyimpan uang di bank, sehingga akan mengurangi jumlah uang beredar (http://www.wikipedia.org).
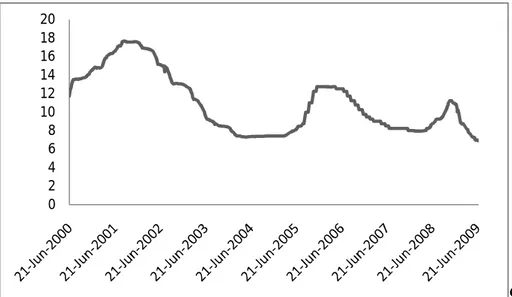
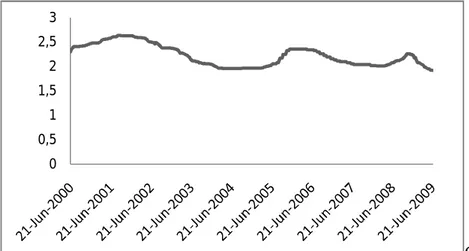
Data yang digunakan dalam penelitian ini adalah data mingguan suku bunga SBI dalam kurun waktu 21 Juni 2000 – 12 Agustus 2009, yang sebagian terlampir dalam Lampiran 1, dengan 423 data untuk membangun model dan 6 data untuk pengujian model. Plot time series data suku bunga SBI disajikan dalam Gambar 4.1.
Gambar 4.1. Plot time series data suku bunga SBI
4.2. Analisis Pola Data
Berdasarkan Gambar 4.1, pergerakan data suku bunga SBI berubah tiap waktu serta mengindikasikan bahwa data suku bunga SBI mingguan tidak stasioner dalam variansi.
0 2 4 6 8 10 12 14 16 18 20
Gambar 4.2. Plot ACF data suku bunga SBI
Berdasarkan Gambar 4.2 terlihat bahwa plot ACF mengindikasikan data mengalami trend, sehingga data tidak stasioner dalam mean. Plot time series pada Gambar 4.1 mengindikasikan data suku bunga SBI mingguan tidak stasioner dalam variansi. Oleh karena itu, dilakukan transformasi data karena syarat pemodelan time series adalah stasioner dalam variansi. Transformasi data yang digunakan adalah transformasi Box-Cox. Plot Box-Cox data suku bunga SBI disajikan dalam Gambar 4.3.
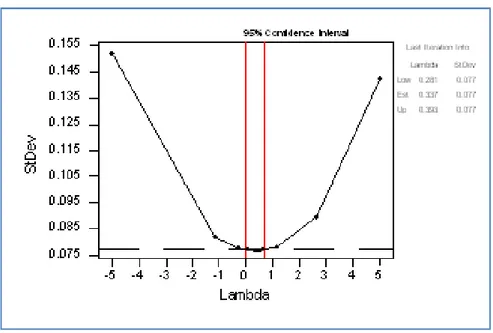
Gambar 4.3. Plot Box-Cox untuk data suku bunga SBI
Berdasarkan Gambar 4.3 terlihat bahwa lambda estimasi sebesar 0,337, maka dalam penelitian ini, transformasi yang digunakan adalah transformasi
Plot time series data suku bunga SBI setelah transformasi dapat dilihat pada Gambar 4.4.
Gambar 4.4. Plot time series data suku bunga SBI setelah transformasi
Berdasarkan Gambar 4.4 terlihat meskipun data hasil transformasi tersebut tidak stasioner dalam variansi, namun transformasi . merupakan transformasi yang dianggap cukup untuk menstabilkan variansi dalam data.
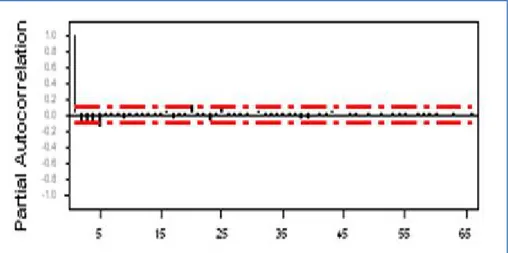
Plot ACF dan PACF data suku bunga setelah transformasi disajikan pada Gambar 4.5 dan Gambar 4.6.
Gambar 4.5. ACF data suku bunga SBI setelah transformasi 0 0,5 1 1,5 2 2,5 3
Gambar 4.6. PACF data suku bunga SBI setelah transformasi
Berdasarkan plot ACF (Gambar 4.5) yang turun menuju nol dan plot PACF (Gambar 4.6) yang signifikan pada lag kecil, dapat diamati bahwa data tersebut relatif baik untuk dimodelkan menurut prinsip parsimony. Berdasarkan Gambar 4.5 juga terlihat bahwa autokorelasi turun lambat, sehingga dapat disimpulkan bahwa data memiliki ketergantungan jangka panjang.
4.3. Pemodelan ARFIMA
4.3.1. Estimasi Parameter
Estimasi parameter ARFIMA dengan metode Exact Maximum Likelihood dilakukan secara serentak untuk semua parameter dan diperbaiki secara iteratif. Hal ini menyebabkan nilai estimasi parameter d bisa berbeda-beda. Berbagai model telah dicoba berdasarkan plot ACF dan PACF. Estimasi parameter beberapa model yang telah dicoba menggunakan software OxMetrics ditampilkan dalam Tabel 4.1, dan sebagian outputnya terlampir dalam Lampiran 2. Berdasarkan Tabel 4.1 terlihat bahwa semua model yang dicoba menghasilkan estimasi parameter model yang signifikan karena p-value semua estimasi parameter model lebih kecil dari tingkat kesalahan = 0.05.
Tabel 4.1. Estimasi parameter beberapa model ARFIMA No. Model
Arfima d
MA-1 MA-2 MA-3 MA-4 MA-5
1 (0,d,0) 0.499 0.000 2 (0,d,1) 0.499 0.727 0.000 0.000 3 (0,d,2) 0.499 1.034 0.651 0.000 0.000 0.000 4 (0,d,3) 0.498 1.126 0.941 0.363 0.000 0.000 0.000 0.000 5 (0,d,4) 0.498 1.013 0.875 0.530 0.358 0.000 0.000 0.000 0.000 0.001 6 (0,d,5) 0.498 0.809 0.706 0.653 0.758 0.456 0.000 0.000 0.000 0.000 0.000 0.000 7 (0,d,[3]) 0.499 0.767 0.000 0.000 8 (0,d,[4]) 0.499 0.746 0.000 0.000 9 (0,d,[1,3]) 0.499 0.321 0.440 0.000 0.001 0.000 10 (0,d,[2,3]) 0.499 0.260 0.590 0.000 0.001 0.000 11 (0,d,[2,4]) 0.499 0.776 0.716 0.000 0.000 0.000 12 (0,d,[1,3,4]) 0.499 0.523 0.546 0.686 0.000 0.000 0.000 0.000 13 (0,d,[5]) 0.499 0.746 0.000 0.000 14 (0,d,[1,5]) 0.499 0.419 0.403 0.000 0.000 0.000 15 (0,d,[2,5]) 0.499 0.417 0.488 0.000 0.000 0.000 16 (0,d,[3,5]) 0.499 0.255 0.488 0.000 0.003 0.000 17 (0,d,[4,5]) 0.499 0.478 0.492 0.000 0.000 0.000 18 (0,d,[1,4,5]) 0.499 0.697 0.649 0.522 0.000 0.000 0.000 0.000 19 (0,d,[1,2,4,5]) 0.499 0.616 0.274 0.624 0.365 0.000 0.000 0.000 0.000 0.000
Berdasarkan Tabel 4.1 dapat dilihat bahwa nilai parameter d berbeda-beda untuk beberapa model, tetapi semuanya menghasilkan nilai yang positif dan interval kepercayaan tidak melewati nilai nol. Hal ini menunjukkan parameter pembedaan fraksional signifikan untuk digunakan. Interval kepercayaan parameter d ditunjukkan Tabel 4.2.
Tabel 4.2. Interval kepercayaan parameter d No. Model
ARFIMA d SE(d)
Interval Kepercayaan Batas Bawah Batas Atas
1 (0,d,0) 0.499628 0.0004844 0.4986592 0.5005968 2 (0,d,1) 0.499505 0.0006698 0.4981654 0.5008446 3 (0,d,2) 0.499294 0.0009775 0.4973390 0.5012490 4 (0,d,3) 0.498938 0.0014860 0.4959660 0.5019100 5 (0,d,4) 0.498849 0.0016200 0.4956090 0.5020890 6 (0,d,5) 0.498802 0.0016790 0.4954440 0.5021600 7 (0,d,[3]) 0.499489 0.0006934 0.4981022 0.5008758 8 (0,d,[4]) 0.499525 0.0006400 0.4982450 0.5008050 9 (0,d,[1,3]) 0.499496 0.0006835 0.4981290 0.5008630 10 (0,d,[2,3]) 0.499482 0.0007036 0.4980748 0.5008892 11 (0,d,[2,4]) 0.499370 0.0008673 0.4979628 0.5007772 12 (0,d,[1,3,4]) 0.499324 0.0009331 0.4975894 0.5010586 13 (0,d,[5]) 0.499505 0.0006702 0.4976388 0.5013712 14 (0,d,[1,5]) 0.499506 0.0006685 0.4981656 0.5008464 15 (0,d,[2,5]) 0.499475 0.0007145 0.4981380 0.5008120 16 (0,d,[3,5]) 0.499475 0.0007145 0.4980460 0.5009040 17 (0,d,[4,5]) 0.499466 0.0007277 0.4980370 0.5008950 18 (0,d,[1,4,5]) 0.499283 0.0009927 0.4972976 0.5012684 19 (0,d,[1,2,4,5]) 0.499323 0.0009344 0.4974542 0.5011918 4.3.2. Pemeriksaan Diagnostik
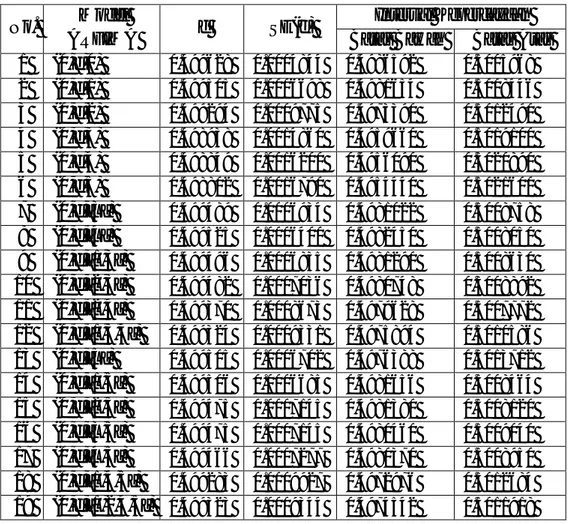
Pemodelan ARFIMA seperti halnya ARIMA, dibangun dengan batasan-batasan, sehingga setelah didapatkan model dengan estimasi parameter yang signifikan perlu dilakukan uji kesesuaian model. Pemeriksaan diagnostik yang dilakukan meliputi uji asumsi nilai sisa white noise dan berdistribusi normal. Plot normalitas nilai sisa model ARFIMA terlampir dalam Lampiran 3. Pengujian nilai sisa model ARFIMA sebagian ditampilkan dalam Tabel 4.3.
Tabel 4.3. Pengujian nilai sisa model ARFIMA No. Model ARFIMA Non Autokorelasi Distribusi Normal p-value p-value 1 (0,d,0) 0.0000 0.0015 2 (0,d,1) 0.0000 0.0000 3 (0,d,2) 0.0000 0.0000 4 (0,d,3) 0.0000 0.0000 5 (0,d,4) 0.0000 0.0000 6 (0,d,5) 0.0000 0.0000 7 (0,d,[3]) 0.0582 0.0660 8 (0,d,[4]) 0.0001 0.0250 9 (0,d,[1,3]) 0.0000 0.0360 10 (0,d,[2,3]) 0.0554 0.0840 11 (0,d,[2,4]) 0.0000 0.1020 12 (0,d,[1,3,4]) 0.0000 0.1160 13 (0,d,[5]) 0.0004 > 0.1500 14 (0,d,[1,5]) 0.0000 > 0.1500 15 (0,d,[2,5]) 0.0000 > 0.1500 16 (0,d,[3,5]) 0.0000 > 0.1500 17 (0,d,[4,5]) 0.0000 0.0210 18 (0,d,[1,4,5]) 0.0000 0.0290 19 (0,d,[1,2,4,5]) 0.0000 0.1430
Hasil pengujian asumsi nilai sisa menunjukkan bahwa tidak semua model yang didapat memenuhi asumsi white noise dan distribusi normal. Tabel 4.3 menunjukkan bahwa pemodelan ARFIMA menghasilkan 2 model yang layak yaitu ARFIMA (0,d,[3]) dan ARFIMA (0,d,[2,3]). Program Ox model ARFIMA (0,d,[3]) dan ARFIMA (0,d,[2,3]) terlampir dalam Lampiran 4.
4.3.3. Pemilihan Model Terbaik
Pemilihan model terbaik untuk metode ARFIMA dilakukan dengan membandingkan MSE, MAPE, dan AIC. Model yang akan dibandingkan adalah model yang telah memenuhi uji diagnostik nilai sisa, yaitu model ARFIMA (0,d,[3]) dan ARFIMA(0,d,[2,3]). Ukuran kebaikan model ARFIMA pada data suku bunga SBI ditampilkan pada Tabel 4.4.
Tabel 4.4. Ukuran kebaikan model ARFIMA pada data suku bunga SBI Model
ARFIMA
Ukuran Kebaikan Model
MSE MAPE AIC
(0,d,[3]) 0.00052 0.12186 -4.75373 (0,d,[2,3]) 0.00048 0.12233 -4.68247
Berdasarkan nilai AIC dan MAPE, maka didapatkan model terbaik adalah model ARFIMA (0,d,[3]) karena mempunyai nilai terkecil. Sedangkan berdasarkan MSE, model terbaik adalah ARFIMA (0,d,[2,3]) karena memiliki nilai terkecil.
4.3.4. Penjabaran Model Terbaik
a. Model ARFIMA (0;0.499,[3])
Model ARFIMA (0;0.499;[3]) secara matematis dituliskan sebagai (1−0)(1− ) . ∗ = (1−0.767 )
dengan ∗ = . .
Nilai (1− ) . menggambarkan ketergantungan jangka panjang dalam
deret. Jika (1− ) . ∗ dianggap sebagai yang menunjukkan ketergantungan jangka panjang, maka
= −0.767
dengan (1− ) . dijabarkan sebagai
(1− ) . = 1−0.499 −1
2(0.499)(1−0.499) −1
(1− ) . = 1−0.499 −0.125 −0.062 − ⋯.
Model ARFIMA (0;0.499;[3]) untuk data transformasi dapat dijabarkan sebagai
= −0.767 (1− ) . ∗ = −0.767 (1−0.499 −0.125 −0.062 − ⋯) ∗= −0.767 ∗−0.499 ∗ −0.125 ∗ −0.062 ∗ − ⋯= −0.767 ∗ = 0.499 ∗ + 0.1259 ∗ + 0.062 ∗ +⋯+ −0.767 dengan ∗ = . ⟺ = ∗( / . )
, dengan ∗ adalah data suku bunga SBI setelah transformasi, dan adalah data suku bunga SBI.
b. Model ARFIMA (0;0.499;[2,3])
Model ARFIMA (0;0.499;[2,3]) secara matematis dituliskan sebagai (1−0)(1− ) . ∗ = (1−0.261 −0.591 )
dengan ∗ = . .
Nilai (1− ) . menggambarkan ketergantungan jangka panjang dalam
deret. Jika (1− ) . ∗ dianggap sebagai yang menunjukkan ketergantungan jangka panjang, maka
= −0.261 −0.591
dengan (1− ) . dijabarkan sebagai
(1− ) . = 1−0.499 −1
2(0.499)(1−0.499) −1
6(0.499)(1−0.499)(2−0.499) − ⋯ (1− ) . = 1−0.499 −0.125 −0.062 − ⋯
Model ARFIMA (0;0.499;[2,3]) untuk data transformasi dapat dijabarkan sebagai
= −0.261 −0.591
(1− ) . ∗ = −0.261 −0.591
(1−0.499 −0.125 −0.062 − ⋯) ∗= −0.261 −0.591 ∗−0.499 ∗ −0.125 ∗ −0.062 ∗ − ⋯= −0.261 −
∗ = 0.499 ∗ + 0.125 ∗ + 0.062 ∗ +⋯+ −0.261 − 0.591
dengan ∗ = . ⟺ = ∗( / . ), dengan ∗ adalah data suku bunga SBI setelah transformasi, dan adalah data suku bunga SBI.
4.4. Peramalan
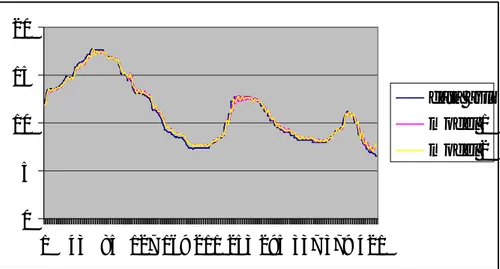
Setelah didapatkan model yang terbaik, langkah selanjutnya adalah membuat ramalan. Plot nilai ramalan dan nilai aktual data suku bunga SBI disajikan pada Gambar 4.7.
Gambar 4.7. Plot nilai ramalan dan nilai aktual data suku bunga SBI
Berdasarkan nilai ramalan yang diperoleh, selanjutnya dapat dicari nilai MSE dan MAPE yang disajikan dalam Tabel 4.5.
Tabel 4.5. MSE dan MAPE model ARFIMA pada data uji Model ARFIMA MSE MAPE
(0;0.499;[3]) 0.772240 0.121865 (0;0.499;[2,3]) 0.794663 0.122338
Berdasarkan Tabel 4.5 dapat dilihat bahwa nilai MSE dan MAPE data uji untuk ARFIMA (0;0.499;[3]) lebih kecil daripada ARFIMA (0;0.499;[2,3]), maka model yang selanjutnya digunakan untuk melakukan peramalan adalah model
0 5 10 15 20 1 43 85 127 169 211 253 295 337 379 421 data asli model 1 model 2
ARFIMA (0;0.499;[3]). Nilai ramalan model ARFIMA (0;0.499;[3]) untuk empat periode ke depan disajikan dalam Tabel 4.6.
Tabel 4.6. Peramalan 4 periode ke depan data suku bunga SBI Periode Tanggal Nilai
Ramalan
Interval Kepercayaan 95% Data Aktual Batas bawah Batas atas
430 19/8/2009 7.97% 7.63% 8.31% 7.58% 431 26/8/2009 8.06% 7.72% 8.40% 7.78% 432 2/9/2009 8.13% 7.78% 8.48% 7.83% 433 8/9/2009 8.19% 7.84% 8.54% 8.00%
Berdasarkan Tabel 4.6, peramalan menggunakan model ARFIMA (0;0.499;[3]) menghasilkan nilai yang baik karena hampir semua nilai aktual berada diantara batas bawah dan atas interval kepercayaan 95%.
BAB V PENUTUP
5.1. Simpulan
Dari hasil pembahasan berdasarkan analisis data pada bab sebelumnya, dapat diambil kesimpulan sebagai berikut.
1. Pemodelan dengan metode ARFIMA menghasilkan dua model yang memenuhi uji dignostik nilai sisa yaitu ARFIMA (0,d,[3]) dan ARFIMA (0,d,[2,3]). Dari perbandingan kedua metode, berdasarkan prinsip parsimony serta nilai AIC dan MAPE didapatkan model yang terbaik yaitu model ARFIMA (0;0.499;[3]) atau bisa ditulis
∗ = 0.499 ∗ + 0.125 ∗ + 0.062 ∗ +⋯+ −0.767
2. Dari model ARFIMA (0;0.499;[3]), diperoleh nilai ramalan suku bunga SBI untuk periode 19 Agustus 2009, 26 Agustus 2009, 2 September 2009,
dan 9 September 2009 berturut-turut adalah 7.97%; 8.06%; 8.13%; dan 8.19%.
3. Peramalan menggunakan model ARFIMA (0;0.499;[3]) menghasilkan nilai yang baik karena hampir semua nilai aktual berada diantara batas bawah dan atas interval kepercayaan 95% untuk ramalan.
5.2. Saran
Saran yang dapat peneliti berikan untuk penelitian selanjutnya dapat dilakukan
1. Peramalan data Suku Bunga SBI dengan menggunakan model ARFIMA-GARCH dengan memperhitungkan adanya heteroskedastistas dalam data. 2. Peramalan data Suku Bunga SBI dengan menggunakan model
INARFIMA.
DAFTAR PUSTAKA
Box, G., Jenkins, G. M., and Reinsel, G. 1994. Time Series Analysis: Forecasting and Control, 3rd Edition. Prentice Hall.
Cryer, D. J. 1986. Time Series Analysis. University of Iowa, Duxbury Press, Boston.
Doornik, J. A., and Ooms, M. 1999. A Package for estimating, forecasting and Simulating ARFIMA Models: Arfima Package 1.0 for Ox. Nuffield College, Rotterdam.
Hosking, J. R. M. 1981. Fractional Differencing. Biometrika 68: 165-176.
Ishida, Ishao and Watanabe, Toshiaki. 2008. Modeling and Forecasting the Volatility of the Nikkei 225 Realized Volatility Using the ARFIMA-GARCH Model. Institute of Economic Research Hitotsubashi University, Kunitatchi Tokyo, Japan.
Makridakis S., dan Wheelwright, Mc Gee. 1995. Metode dan Aplikasi Peramalan. Bina Rupa Aksara, Jakarta.
Sowell, F. B. 1992. Maximum Likelihood Estimation of Stationery Univariate Fractionally Integrated Time Series Models. Journal of Econometrics 53: 165-188.
Wei, W. W. S. 1990. Time Series Analysis Univariate and Multivariate Methods. Addison Wesley Publishing Company, Inc.
http://www.wikipedia.org http://www.bi.go.id

![Tabel 4.3. Pengujian nilai sisa model ARFIMA No. Model ARFIMA Non Autokorelasi Distribusi Normal p-value p-value 1 (0,d,0) 0.0000 0.0015 2 (0,d,1) 0.0000 0.0000 3 (0,d,2) 0.0000 0.0000 4 (0,d,3) 0.0000 0.0000 5 (0,d,4) 0.0000 0.0000 6 (0,d,5) 0.0000 0.0000 7 (0,d,[3]) 0.0582 0.0660 8 (0,d,[4]) 0.0001 0.0250 9 (0,d,[1,3]) 0.0000 0.0360 10 (0,d,[2,3]) 0.0554 0.0840 11 (0,d,[2,4]) 0.0000 0.1020 12 (0,d,[1,3,4]) 0.0000 0.1160 13 (0,d,[5]) 0.0004 > 0.1500 14 (0,d,[1,5]) 0.0000 > 0.1500 15 (0,d,[2,5]) 0.0000 > 0.1500 16 (0,d,[3,5]) 0.0000 > 0.1500 17 (0,d,[4,5]) 0.0000 0.0210 18 (0,d,[1,4,5]) 0.0000 0.0290 19 (0,d,[1,2,4,5]) 0.0000 0.1430](https://thumb-ap.123doks.com/thumbv2/123dok/1889131.2118639/26.892.274.663.200.878/tabel-pengujian-arfima-model-arfima-autokorelasi-distribusi-normal.webp)