ANALISIS MODEL RISIKO KOLEKTIF PADA ASURANSI
JIWA KREDIT MENGGUNAKAN MODEL KLAIM
AGREGASI
Riaman, Yusup Supena, Eman Lesmana, F. Sukono, Ridhan Firdaus Jurusan Matematika FMIPA Universitas Padjadjaran
Jl. Raya Bandung-Sumedang km 21 Jatinangor
ABSTRAK
ANALISIS MODEL RISIKO KOLEKTIF PADA ASURANSI JIWA KREDIT MENGGUNAKAN MODEL KLAIM AGREGASI. Dalam asuransi jiwa kredit, apabila debitur meninggal dunia, maka akan dijamin oleh perusahaan asuransi untuk pengembalian sisa kredit yang belum terlunasi yang telah dikeluarkan oleh bank. Perusahaan asuransi yang menjamin kredit debitur bank harus memperhatikan dengan sungguh-sungguh risiko yang muncul dari pihak bank selama periode asuransi karena jika tidak akan menimbulkan risiko kerugian. Pada paper ini, digunakan Model Risiko Kolektif untuk mengukur risiko perusahaan asuransi dengan cara membentuk model klaim agregasi dari data besar klaim individual dan jumlah klaim yang terjadi. Kemudian model risiko kolektif diterapkan pada perusahaan asuransi jiwa dan diperoleh hasil bahwa model klaim agregasi asuransi jiwa kredit berdistribusi binomial negatif kumpulan. Besarnya risiko yang ditanggung oleh perusahaan asuransi tergantung pada besarnya klaim individual dan jumlah klaim yang terjadi selama periode asuransi.
Kata Kunci : asuransi jiwa kredit, risiko, klaim, klaim agregasi, model risiko kolektif
ABSTRACT
COLLECTIVE RISK MODEL ANALYSIS ON CREDIT LIFE INSURANCE USE AGGREGATION CLAIMED MODEL. In the credit life insurance, Insurance company ensuring that will be refund the reamaining credit that has been issued by bank if the debitor was died. Insurance company in ensuring that debitor credit this bank must be keep a close check on risk came out of bank authority during insurance period because if do nothing it will be raised amount of loss. In this paper, the Collective Risk Model is used to measure the risk of insurance companies with claims by forming model claim agregation from individual claim amount and number of claim occurence. Then the application of the collective risk model conducted in insurance life company Bumiputera and the results concluded that the aggregate claims model of credit life insurance distributed compound negative binomial. The amount of risk responsible by the insurance company determinated by individual claim value and amount of claim during insurance period.
Keywords : credit life insurance, risk, claims, claims aggregation, collective risk model.
1. PENDAHULUAN
Kegiatan usaha perbankan secara terus menerus selalu berhubungan dengan berbagai bentuk risiko termasuk dalam
kegiatan perkreditan. Satu kondisi yang tidak dapat dipungkiri dan selalu melekat dalam pemberian kredit adalah adanya risiko, sehingga pemberian kredit disebut juga sebagai penanaman dana dalam bentuk
risk assets [10]. Atas pertimbangan itu,
Bank berusaha semaksimal mungkin untuk memperkecil atau mengurangi risiko dalam setiap pemberian kredit. Salah satu usaha bank untuk memperkecil atau mengurangi risiko adalah dengan cara mengalihkan resiko tersebut pada pihak lain yaitu perusahaan asuransi.
Salah satu produk asuransi yang ditawarkan oleh perusahaan asuransi untuk menangani risiko yang terjadi dalam pemberian kredit adalah asuransi jiwa kredit [8]. Asuransi jiwa kredit adalah asuransi yang menjamin pengembalian pinjaman kredit yang telah dikeluarkan oleh para kreditur yang umumnya adalah bank, apabila para debitur tersebut mengalami musibah meninggal dunia. Perusahaan asuransi akan membayar sisa kredit yang ada setelah debitur meninggal dunia sesuai dengan manfaat asuransi yang diterima [9].
Pada asuransi jiwa kredit tugas perusahaan asuransi adalah mananggung beban risiko yang dipindahkan oleh bank kepada perusahaan asuransi berupa pengembalian pinjaman yang dikeluarkan oleh bank jika debiturnya meninggal dunia. Dalam suatu sistem asuransi terjadinya risiko dari tertanggung dapat memunculkan klaim. Klaim adalah ganti rugi atas suatu risiko kerugian.
Sebagai lembaga pengambil alih dan penerima risiko, perusahaan asuransi tentunya harus bisa mengantisipasi risiko jika terjadi banyak klaim, karena jika tidak akan menimbulkan kerugian yang bisa membuat perusahaan asuransi tersebut bangkrut.Dalam pengelolaan risiko, perusahaan asuransi harus mengetahui karakter dari risiko tersebut untuk memprediksi kerugian yang akan terjadi di masa yang akan datang. Karakter risiko tersebut dapat dipelajari dalam suatu model distribusi klaim [7]. Terdapat dua pendekatan standar untuk membentuk model distribusi klaim selama periode asuransi, yaitu model risiko kolektif dan model risiko individual.
Dalam model risiko kolektif, klaim yang muncul setiap terjadi risiko disebut dengan klaim individual, akumulasi dari
klaim-klaim individual selama satu periode asuransi disebut sebagai klaim agregasi. Model distribusi klaim agregasi dapat dibentuk dari model besar dan jumlah klaim individual, sehingga untuk membentuk model distribusi klaim agregasi terlebih dahulu harus ditentukan model distribusi besar dan jumlah klaim individual [7].
Penelitian mengenai model risiko kolektif telah banyak dilakuakan antara lain aplikasi teori risiko kolektif untuk mengestimasi variabilitas dalam menentukan cadang kerugian [11], model risiko kolektif untuk distribusi cadangan klaim [5], model risiko kolektif untuk distribusi outstanding cadangan klaim [11] dan analisis data total klaim untuk menghitung pure premium asuransi mobil [6].
Berdasarkan uraian di atas, dalam penelitian ini penulis mencoba mengaplikasikan model risiko kolektif untuk menentukan dan menganalisis besarnya risiko yang ditanggung oleh perusahaan asuransi di mana objeknya adalah asuransi jiwa kredit. Data total klaim dari perusahaan asuransi jiwa kredit dianalisis untuk membentuk model distribusi besar dan jumlah klaim individual yang selanjutnya akan digunakan dalam membentuk model klaim agregasi.
2. MODEL RISIKO ASURANSI
Pada awal periode asuransi perlindungan, insurer tidak mengetahui berapa banyak klaim yang akan terjadi, dan jika klaim terjadi, berapa jumlah dari klaim tersebut. Oleh karena itu, dibutuhkan untuk membangun suatu model yang memuat perhitungan dari dua sumber variabilitas.
Untuk model risiko yang bersifat kolektif, dapat digunakan suatu asumsi proses acak yang klaimnya berkelanjutan pada portofolio polis asuransi. Secara umum dapat diformulasikan dengan :
Misalkan N sebagai jumlah klaim yang dihasilkan dari portofolio polis yang diberikan dalam periode waktu tertentu dan
besar klaim ke 2 dan seterusnya, sehingga besar klaim kumpulan hanyalah penjumlahan dari besar klaim individual, maka dapat dituliskan sebagai berikut
Persamaan (1) merepresentasikan
agregat klaim yang dihasilkan oleh portofolio dari periode tersebut. Nomor/angka klaim N adalah variabel acak dan merupakan kumpulan dari frekuensi klaim. Jumlah individual klaim
adalah variabel acak dan disebut measure
the severity of claims.[3]
Dalam membangun suatu model, harus diawali dengan dua asumsi yang fundamental, yaitu :
1) variabel acak yang
berdistribusi identik,
2) Variabel acak saling
bebas.
Alat dasar untuk mengembangkan teori ini adalah fungsi pembangkit momen [1].
Pada awal periode asuransi perlindungan, insurer tidak mengetahui berapa banyak klaim yang akan terjadi, dan jika klaim terjadi, berapa jumlah dari klaim tersebut.[2] Oleh karena itu, dibutuhkan untuk membangun suatu model yang memuat perhitungan dari dua sumber variabilitas.
Untuk model risiko yang bersifat kolektif, dapat digunakan suatu asumsi proses acak yang klaimnya berkelanjutan pada portofolio polis asuransi.
Pengujian dengan Ratio Likelihood tidak cukup untuk menentukan model distribusi mana yang paling baik. NLL setiap fungsi densitas yang diuji harus ditambahkan dengan penalty kemudian membandingkannya. Metode ini dikenal dengan Metode Schwartz Bayesian Criterion (SBC) [4].
Besarnya penalty adalah
Di mana:
r : banyaknya parameter n : besar sampel
Selanjutnya NLL (Negative Log Likelihood ) dari setiap fungsi densitas yang diuji ditambahkan dengan penalty-nya masing-masing. Fungsi densitas yang mempunyai score paling kecil adalah fungsi densitas yang dipilih.
2.1 Transformasi Variabel Acak Kontinu dengan Jacobian
Misalkan X adalah variabel acak pada ruang sampel dengan ruang dari X adalah x.Dengan demikian, fungsi
berharga real Y = g(X) yang merupakan fungsi dari X dapat dicari distribusinya dengan beberapa cara, salah satunya adalah melalui transformasi variabel acak dengan
Jacobian [5].
Teorema 2.2 :
Variabel acak X kontinu pada x
dengan fungsi kepadatan peluang di
mana . Jika diambil
transformasi pada x yang
bersifat 1-ke-1, maka fungsi kepadatan peluang variabel Y dapat diperoleh dengan cara : lainnya yang , 0 , ) ( )] ( [ ) ( 1 1 y y dy y dg y g f y f X Y Y (3) y = { y, y = g(x) untuk x x }
Jika fungsi Y = g(X) tidak bersifat 1-ke-1, maka daerah dungsi Y = g(x) dapat dipartisi sedemikian sehingga setiap partisi akan tetap berisfat 1-ke-1. Dengan demikian fungsi kepadatan peluang dari variabel Y diperoleh dengan cara :
lainnya yang , 0 , ) ( )] ( [ ) ( 1 1 1 y y dy y dg y g f y f Y j j X Y j (4) y = { y, y = g(x) untuk x x }3. HASIL DAN PEMBAHASAN
Data penelitian yang digunakan dalam
penelitian ini adalah data klaim asuransi jiwa kredit perusahaan Asuransi Jiwa Bumiputera dengan periode waktu 1 Januari 2009 sampai dengan 31 Desember 2011. Data klaim asuransi tersebut selanjutnya dibagi ke dalam 2 kelompok, yaitu data jumlah terjadinya klaim dan data besarnya nilai klaim. Tabel 1 berikut memaparkan jumlah terjadinya klaim dan besarnya nilai klaim yang terjadi, selama periode waktu 1 Januari 2009 sampai dengan 31 Desember 2011.
Selanjutnya dari data jumlah klaim dan data besarnya klaim tersebut akan dicari fit
distribution atau model distribusi yang
paling cocok dengan menggunakan
software EasyFit 5.5. dan diuji secara
statistik dengan menggunakan uji goodness
of fit.
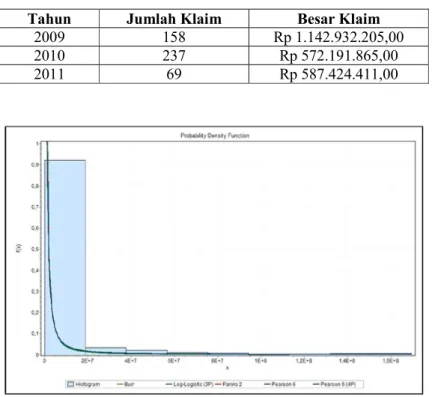
Hasil pencocokan kurva disajikan pada Gambar 1. Hasil dari pencocokan kurva dengan menggunakan software EasyFit
5.5diperoleh 5 kandidat model distribusi
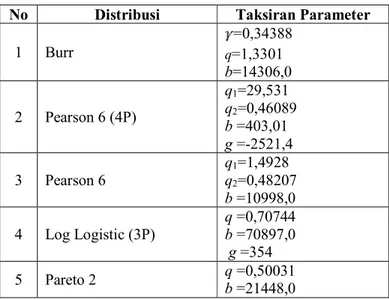
yang cocok untuk data klaim individual yaitu distribusi Burr, Pearson 6(4P), Pearson 6, Log Logistic (3P) dan Pareto 2. Kandidat-kandidat yang masuk seleksi akan ditentukan taksiran parameternya secara parametrik, yaitu dengan menggunakan metode maksimum likelihood. Taksiran parameter untuk distribusi yang masuk seleksi disajikan pada Tabel 2.
Tabel 1. Jumlah Klaim dan Besarnya Klaim Perusahaan Asuransi Jiwa
Tahun Jumlah Klaim Besar Klaim
2009 158 Rp 1.142.932.205,00
2010 237 Rp 572.191.865,00
2011 69 Rp 587.424.411,00
Gambar 1. Perbandingan histogram fungsi densitas dari data klaim dengan kurva fungsi densitas dari distribusi standar.
Tabel 2. Taksiran Parameter 5 Kandidat Distribusi Besar Klaim
No Distribusi Taksiran Parameter
1 Burr =0,34388 q=1,3301 b=14306,0 2 Pearson 6 (4P) q1=29,531 q2=0,46089 b =403,01 g =-2521,4 3 Pearson 6 q1=1,4928 q2=0,48207 b =10998,0 4 Log Logistic (3P) q =0,70744 b =70897,0 g =354 5 Pareto 2 q =0,50031 b =21448,0
Dari kelima kandidat distribusi tersebut selanjutnya akan dibentuk satu distribusi yang paling cocok untuk besar klaim agregate. Dalam menganalisis risiko dengan sebuah model distribusi, bisa dilakukan melalui fungsi kepadatan peluang (fkp), fungsi distribusi komulatif, ekspektasi, dan variansi dari distribusi tersebut, sehingga taksiran parameter dari distribusi yang terpilih harus sesuai dengan persyaratan secara teoritik. Melihat taksiran parameter dari Tabel 2 semua distribusi yang terpilih memiliki taksiran parameter yang tidak sesuai dengan persyaratan secara teoritik khususnya dalam menentukan ekspektasi dan variansi. Sebagai contoh, distribusi Pareto 2, ekspektasi distribusi Pareto 2 ada hanya untuk , dan variansinya ada hanya untuk , sedangkan hasil penaksiran sehingga tidak bisa ditentukan nilai ekspektasi dan variansinya. Oleh karena itu, diperlukan teknik statistika untuk menganalisis data klaim individual tersebut. Teknik statistika yang digunakan yaitu, transformasi data.
Transformasi terhadap suatu data biasanya dilakukan agar data empirik yang diperoleh dari lapangan sesuai dengan distribusi teoritik yang ditentukan. Dengan kata lain, data tersebut memenuhi persyaratan dari distribusi teoritik yang
ditentukan. Transformasi yang lazim digunakan dalam data jumlah klaim individual adalah fungsi logaritma natural karena data jumlah klaim individual tidak mungkin negatif. Hasil dari analisis data selanjutnya ditansformasikan kembali ke data awal.
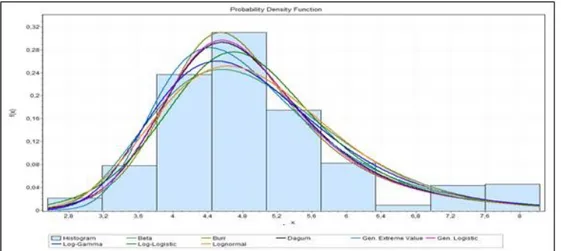
Setelah data ditransformasikan dengan menggunakan fungsi ln, selanjutnya histogram fungsi densitas data hasil transformasi akan dicocokan dengan kurva fungsi densitas dari distribusi standard. Hasil pencocokan kurva dengan menggunakan software EasyFit 5.5
disajikan Gambar 2.
Hasil dari pencocokan kurva diperoleh 8 kandidat model distribusi yang cocok dengan data transformasi klaim individual, yaitu distribusi Beta, Burr, Dagum, Gen. Ekstreme Value, Gen.Logistic, Log-Gamma, Log-Logistic dan Lognormal. Selanjutnya model distribusi yang masuk seleksi akan ditentukan taksiran parameternya secara parametrik, yaitu dengan menggunakan metode maksimum likelihood. Taksiran parameter untuk distribusi yang masuk seleksi disajikan pada Tabel 3.
Gambar 2. Perbandingan histogram fungsi densitas hasil transformasi data klaim dengan kurvafungsi densitas dari distribusi standar. Tabel 3 Taksiran Parameter 8 Kandidat Distribusi Transformasi Data Klaim
Individual
No Distribusi Taksiran Parameter
1 Beta q1=7,4925 q2=1,1366E+7 a=1,9816 b =4,5154E+6 2 Burr = 0,59842 q =10,858 b = 10,203 3 Gen. Logistic k =0,19227 s =1,272 m =10,986 4 Dagum k =1,5848 q=7,5995 b =10,165
5 Gen. Extreme Value
k =0,03447 s =0,8202 m =4,4513 6 Log-Gamma q =55,42 b =0,02846 7 Log-Logistic q =8,3415 b =4,8358 8 Lognormal s =0,21163 m =1,5772
Penentuan model distribusi yang paling cocok untuk besar klaim individual, untuk menentukan pilihan fungsi densitas yang paling tepat dari 8 kandidat tersebut digunakan uji Kolmogorov-Smirnov dan uji
ratio likelihood untuk menentukan model
distribusi yang paling baik. Berdasarkan nilai NLL, untuk model distribusi dengan 2 parameter dipilih distribusi Log-Logistic dan untuk model distribusi dengan 3
parameter dipilih distribusi Burr. Agar model yang dipilih akurat harus ditambahkan penalty untuk kedua distribusi tersebut, kemudian memban-dingkannya. Besarnya penalty adalah , dimana adalah banyaknya parameter dan adalah besar sample. Model distribusi dengan
score yang paling kecillah yang paling
cocok dengan data klaim individual yang ditransformasi. Berdasarkan hasil transformasi variabel dengan metode
Jacobian diperoleh model yang paling
cocok untuk data klaim individual adalah model distribusi Burr, dengan parameter =
0,59842, = 10,858 =10,203.
Nilai ekspektasi dan variansi untuk distribusi besar klaim individual dapat diperoleh dengan cara mengeksponenkan nilai dari ekspektasi dan variansi distribusi data besar klaim individual yang ditransformasi karena data besar klaim individual ditransformasikan dengan fungsi ln. Nilai ekspektasi dan variansi dari distribusi besar klaim individual yang ditransformasi dapat diperoleh sebagai berikut:
Berdasarkan hasil tersebut maka nilai ekspektasi dan variansi untuk besar klaim individual adalah sebagai berikut :
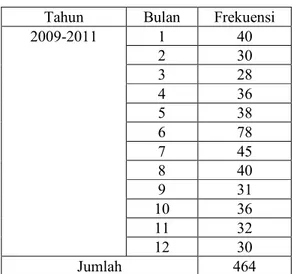
Sedangkan jumlah klaim yang terjadi dalam suatu sistem asuransi merupakan peristiwa acak yang dapat diprediksikan melalui distribusi jumlah klaim. Distribusi jumlah klaim ini ditentukan melalui fungsi densitas probabilitas dan fungsi densitas kumulatif. Penentuan model distribusi jumlah klaim dilihat dari banyaknya klaim yang terjadi selama tiga tahun terakhir. Jumlah klaim yang terjadi selama tiga tahun, yaitu klaim yang terjadi pada tahun 2009 - 2011dapat dilihat pada Tabel 4.
Selanjutnya penentuan model distribusi jumlah klaim dilakukan dengan menggunakan software EasyFit 5.5. Hasil dari pencocokan kurva dapat dilihat pada Gambar 3. Berdasarkan hasil pencocokan kurva dengan menggunakan software EasyFit 5.5 diperoleh 2 kandidat model
distribusi yang cocok untuk jumlah klaim yaitu distribusi Poisson dan distribusi Binomial Negatif. Taksiran parameter dengan menggunakan metode maksimum
likelihood untuk kedua kandidat tersebut
disajikan dalam Tabel 5.
Tabel 4. Jumlah Klaim Tahun 2009-2011
Tahun Bulan Frekuensi
2009-2011 1 40 2 30 3 28 4 36 5 38 6 78 7 45 8 40 9 31 10 36 11 32 12 30 Jumlah 464
Tabel 5. Taksiran Parameter 2 Kandidat Distribusi Jumlah Klaim
No Distribusi Taksiran Parameter
1 Poisson
2 Binomial Negatif k = 11
p = 0,23521
Gambar 3 Perbandingan histogram fungsi distribusi komulatif dari data klaim dengan kurva fungsi distribusi komulatif dari distribusi standar.
Tabel 6. Nilai Penalty dan Negative Log Likelihood 2 Kandidat Distribusi Jumlah Klaim Terpilih
Model NLL Penalty Score
Poisson 54,0411 0,646627165 54,68773
Binomial Negatif 47,2259 1,29325433 41,51919
Dalam penentuan model distribusi yang paling cocok untuk jumlah klaim, dilakukan dengan uji Kolmogorof-Smirnov dan uji
Ratio Likelihood yang akan digunakan
dalam analisis statistik dengan melakukan
uji Goodness Of Fit. Selanjutnya
dilakukan uji Ratio Likelihood dan ditambahkan dengan penalty score untuk melihat distribusi mana yang paling cocok untuk jumlah klaim, yang hasilnya disajikan pada tabel berikut ini.
Berdasarkan Tabel 6 terlihat bahwa distribusi Binomial Negatif merupakan model distribusi yang memiliki score yang
paling kecil. Jadi, dapat diambil kesimpulan bahwa model yang paling cocok untuk jumlah klaim adalah model distribusi Binomial Negatif dengan parameter k = 11 dan p = 0,23521.
Berdasarkan hasil pengolahan data, jumlah terjadinya klaim berdistribusi binomial negatif, sehingga model distribusi untuk klaim agregate berdistribusi binomial negatif kumpulan.
Besarnya risiko dengan model risiko kolektif dalam asuransi dapat dilihat dari ekspektasi dan variansi klaim agregate. Untuk menghitung ekspektasi dan variansi
klaim agregate yang merupakan risiko asuransi jiwa kredit dengan memasukan
nilai serta parameter k =
11 dan p = 0,23521 yang telah ditaksir
sebelumnya, sehingga diperoleh nilai sebagai berikut :
maka nilai ekspektasi dari klaim agregasi adalah 3.267.240,95 dan
sehingga diperoleh nilai variansi dari klaim agregasi adalah:
.
Berdasarkan nilai tersebut maka dapat diambil kesimpulan, selama periode asuransi, rata-rata terjadinya klaim agregasi adalah sebesar Rp 3.267.240,95 dengan
variansi sebesar Rp . Nilai
dari rata-rata dan variansiklaim agregasi ini dapat digunakan oleh perusahaan asuransi sebagai acuan dalam menentukan cadangan premi, cadangan klaim pada perusahaan reasuransi.
4. KESIMPULAN
Berdasarkan hasil pengolahan data, model klaim agregasi yang terbentuk dari distribusi besar klaim individual berdistribusi Burr, sedangkan jumlah klaim individu berdistribusi binomial negative dan agregatenya berdistribusi binomial negative kumpulan. Berdasarkan hasil pengolahan data besarnya ekspektasi klaim agregasi yang terjadi pada perusahaan asuransi jiwa kredit adalah sebesar Rp 3.267.240,95
dengan variansi sebesar Rp
. Nilai dari rata-rata dan variansi klaim agregasi ini dapat digunakan oleh perusahaan asuransi sebagai acuan
dalam menentukan cadangan premi, cadangan klaim pada perusahaan reasuransi.
5. DAFTAR PUSTAKA
1. BOWERS, N., GERBER, H., HICKMAN, J., JONES, D., dan NESBITT, C. 1997. Actuarial
Mathematics. Schaumburg, IL: Society
of Actuaries.
2. DICKSON, DAVID C.M. 2005.
Insurence Risk and Ruin. Cambridge :
Cambridge University Press.
3. HAYNE, R. M. 1985. Aplication of collective risk theory to estimate variability in loss reserves (online), (http://www.casact.org/pubs/dpp/dpp88 /88dpp275.pdf, diakses 24 Juli 2012) 4. HOGG, R.V, McKEAN, J.W, dan
CRAIG, A.T. 1995. Introduction to
Mathematical Statistics Sixth Edition,
New Jersey: Percentile Hall.
5. IDROES, FERRY N. 2008.
Manajemen Risiko Perbankan :
Pemahaman Pendekatan 3 Pilar
Kesepakatan Basel II terkait Aplikasi Regulasi dan Pelaksanaannya di Indonesia. Jakarta : PT RajaGrafindo
Persada.
6. KLUGMAN, S. A., PANJER, H. H., WILLMOT, G., E. 1990. Loss Models
: from data to decisions. New York :
John Wiley & Sons.
7. MANURUNG, TOHAP. 2011.
Analisis Data Total Klaim Untuk Menghitung Pure Premium Asuransi Mobil. Jurnal Ilmiah Vol. 11 No.2.
Oktober 2011
8. MUJAHID, ABU. 2007. Pengertian
Kredit (Online),
(http://isbs.wordpress.com /2007/11/13/anuitas-angsuran-tetap/,diakses 12 Februari 2012)
9. PRAMESTI, GETUT. 2011.
Distribusi Rayleigh Untuk Klaim Agregasi. Media Statistika Vol. 4, No.
2. Desember 2011 : 105-112.
10. RAHMAN, HASANUDIN. 1998.
Aspek-Aspek Pemberian Kredit
Adtya Bakti.
11. SAVELLI, N., CLEMENTE, G. P. 2010. A Collective risk model for
outstanding claims reserve distribution
(online).
(http://www.ica2010.com/docs/176_PP T_ Savelli. pdf, diakses 24 Juli 2012)