CONTENT BASED IMAGE RETRIEVAL MENGGUNAKAN METODE COLOR HISTOGRAM DAN ALGORITMA K-MEANS CLUSTERING
Risa Fithrasari – 208700923 Jurusan Teknik Informatika Fakultas Sains dan Teknologi UIN Sunan Gunung Djati Bandung
Email : [email protected] ABSTRAK
Perkembangan teknologi yang semakin canggih memicu makin berkembangnya data di berbagai bidang seperti hiburan, perdagangan, pendidikan,
biomedicine, dan lain-lain. Data citra dari berbagai bidang tersebut semakin
bertambah dengan cepat pula. Data citra membutuhkan ruang simpanan yang besar, dan kemungkinan dalam suatu direktori penyimpanan pada harddisk terdapat banyak citra. Sehingga sistem penyimpanan dari berbagai macam informasi digital tersebut semakin meningkat dan membuat masalah dalam pencarian kembali dan pengolahannya.
Teknik pencarian yang sudah ada saat ini merupakan pencarian dengan
inputan berupa teks namun menghadapi berbagai masalah diantaranya kurang
praktis dan hasilnya terkadang tidak sesuai dengan yang dicari. Maka dibangunlah
Content Based Image Retrieval (CBIR). Metode color histogram digunakan untuk
mengekstraksi fitur warna dan juga sebagai nilai pembanding untuk menemukan kembali citra. Citra query maupun citra acuan diekstrak color histogramnya kemudian dihitung selisihnya. Selain itu digunakan pula teknik clustering menggunakan algortima K-Means. Penggunaan centroid hasil pengelompokan dataset yang berasal dari color histogram dari kumpulan citra dapat digunakan sebagai acuan untuk melakukan pencarian. Sistem ini dibangun dengan bahasa pemrograman Java. Metode pengembangan perangkat lunak menggunakan metode RUP (Rational Unified Process). Hasil percobaan dari pencarian dengan
color histogram dan teknik clustering ini ternyata berhasil menemukan citra yang
mirip dari segi warna dengan akurasi cukup tinggi dan waktu pencarian yang cepat.
Kata Kunci : Content Based image retrieval (CBIR), color histogram, K-Means
clustering
1. PENDAHULUAN Latar Belakang
Seiring berkembangnya teknologi, makin banyak pulalah hasil-hasil citra digital di berbagai aspek. Citra tersebut bisa merupakan hasil digitalisasi foto-foto analog, hasil foto dari kamera digital, lukisan, maupun gambar-gambar dari
bidang medis. Salah satu cara yang biasa digunakan untuk mencari kumpulan-kumpulan gambar tersebut adalah menggunakan pencarian citra berbasis teks. Teknik pencarian citra berbasis teks ini dilakukan dengan cara pengguna memasukkan query berupa teks untuk mendapatkan kembali citra. Namun teknik ini
dinilai kurang efektif dan banyak ditemukan ketidaksesuaian karena hasil yang didapatkan terkadang berbeda jauh dengan yang diinginkan dari query dan nama dari sebuah file tidak dapat mempresentasikan isinya. Selain itu dengan query yang berupa teks ini, maka kita harus mengetahui kata kunci yang benar-benar tepat agar gambar yang kita inginkan dapat ditampilkan.
Untuk menghindari kesulitan tersebut, maka digunakanlah sistem temu kembali citra berdasarkan isi
(Content Based Image Retrieval)
yang mencari citra berdasarkan komponen-komponen yang membentuk citra. Komponen pada citra diantaranya adalah warna, bentuk, tekstur, topologi dan lain-lain. Query yang digunakan pada sistem ini sudah bukan berupa teks lagi namun berupa citra. Fitur warna merupakan fitur yang paling banyak digunakan pada sistem ini.
Dalam tugas akhir ini, akan diuraikan tentang metode pencarian citra dengan query berupa citra menggunakan segmentasi (clustering) yang di dalamnya sudah tersimpan fitur warna berupa color histogram. Sedangkan teknik
clustering yang dipakai adalah
Algoritma K-Means. Teknik
clustering ini diharapkan dapat
mempercepat proses komputasi dan pencarian citra. Waktu pengambilan gambar pun biasanya diperlukan oleh beberapa orang untuk penelitian dari suatu kejadian, namun tidak semua gambar memiliki data lengkap tentang waktu pengambilannya.
Dengan adanya permasalahan-permasalahan tersebut maka penulis bermaksud mengambil judul “Content Based Image Retrieval
Menggunakan Metode Color
Histogram Dan Algoritma K-Means
Clustering”.
Rumusan Masalah
Berdasarkan dari latar belakang yang telah diuraikan, maka masalah yang akan dibahas yaitu :
a. Bagaimana melakukan ekstraksi fitur warna berupa color
histogram pada citra query dan citra acuan ?
b. Bagaimana hasil clustering
K-Means pada proses
pengelompokkan color histogram citra acuan dan menerapkannya pada aplikasi content based image
retrieval ?
c. Bagaimana membangun aplikasi yang dapat membantu pengguna menemukan kembali citra diantara sekumpulan citra dari segi kemiripan color histogram sekaligus mengetahui waktu pembuatan/pengambilan dari citra
query ?
Tujuan Penelitian
Tujuan dari pembuatan aplikasi ini yaitu :
a. Dapat mengekstraksi fitur warna berupa color histogram pada citra
query dan database.
b. Mengetahui hasil implementasi teknik clustering, yaitu K-Means
Clustering, dalam image retrieval
menggunakan fitur warna (color histogram).
c. Membantu pengguna menemukan kembali citra yang mirip dengan citra query diantara sekumpulan citra acuan dari segi content warna yang dihitung dari color histogram sekaligus mengetahui waktu pembuatan dari citra query
tersebut.
Batasan Masalah
Pembatasan dibatasi pada ruang lingkup :
a. Menggunakan citra digital, dengan tipe citra : jpg.
b. Image content yang digunakan
dalam ekstraksi fitur pada aplikasi
image retrieval ini adalah color
histogram.
2. LANDASAN TEORI Content Based Image Retrieval
Content Based Image Retrieval System (CBIR) merupakan suatu
teknik pencarian kembali citra yang mempunyai kemiripan karakteristik atau content dari sekumpulan citra. Sistem CBIR melakukan dua tugas utama, yang pertama adalah citra yang menjadi query dilakukan proses ekstraksi fitur, begitu halnya dengan citra yang ada pada database juga dilakukan proses seperti pada citra
query. Tugas yang kedua adalah
mengukur kesamaan (similarity measurement), dimana jarak antara
citra query dengan setiap citra dalam
database telah dihitung sehingga
sehingga citra dengan jarak terdekat dapat ditampilkan.[Silva, Xavier, 2006 ].
Citra Digital
Menurut Rodiyansyah (2010), citra digital (digital image) adalah citra kontinyu f(x,y) yang sudah didiskritkan baik koordinat spasial maupun tingkat kecerahannya. Setiap titik biasanya memiliki koordinat sesuai dengan posisinya dalam citra. Koordinat ini biasanya dinyatakan indeks x dan y hanya bernilai bilangan bulat positif, yang dapat dimulai dari 0 atau 1. Citra digital
yang selanjutnya akan disingkat “citra” sebagai matrik ukuran M x N yang baris dan kolomnya menunjukkan titik-titiknya yang diperlihatkan pada persamaan sebagai berikut :
( , ) = (0,0)(1,0) (0,1)(1,1) ⋯ (0, − 1)⋯ (1, − 1) ( − 1,0) ( − 1,1) … ( − 1, − 1)
(1) Color Histogram
Histogram citra menurut Rodiyansyah adalah representasi distribusi warna dalam sebuah gambar yang didapatkan dengan menghitung jumlah pixel dari setiap bagian range warna. Histogram juga dapat menunjukkan banyak hal tentang kecerahan (brightness) dan kontras (contrast) dari sebuah gambar. Secara grafis histogram ditampilkan dengan diagram batang.
Gonzales dan Woods (2002) menyatakan histogram dari sebuah gambar digital dengan gray level dalam rentang [0, L-1] merupakan fungsi :
ℎ( ) = (2) dimana rk adalah gray level
ke-k dan nk adalah jumlah pixel dalam
gambar yang memiliki gray level
ke-k. Umumnya histogram mengalami
proses normalisasi dengan cara membagi nilai tiap bin dengan jumlah seluruh pixel yang ada dalam gambar yang diwakili oleh variabel
n. dengan demikian, histogram ternormalisasi dari sebuah gambar dapat dinyatakan dengan persamaan berikut:
p( ) = (3)
Normalisasi
Perbedaan ukuran gambar mengakibatkan perbedaan histogram
meskipun memiliki distribusi warna yang sama, oleh karena itu diperlukan suatu normalisasi histogram. Daripada menggunakan jumlah aktual, lebih baik menggunakan persentase pembagian jumlah aktual dengan jumlah total piksel gambar yang digunakan color
histogram. [Widodo, 2007].
Pengukuran Jarak antar dua histogram
Color histogram antara dua
gambar dihitung jaraknya. Gambar yang memiliki jarak paling kecil, merupakan solusinya. Untuk menghitung jarak antara dua color histogram yaitu dengan menghitung akar dari kuadrat Euclidean distance (Wang, S., 2001), rumusnya :
( , ) = ∑ [ ] − [ ] (4)
K-Means
K di sini dimaksudkan sebagai konstanta jumlah cluster yang diinginkan. Means dalam hal ini berarti nilai suatu rata-rata dari suatu grup data yang dalam hal ini didefinisikan sebagai cluster. metode
K-means ini menggunakan nilai
rata-rata yang diambil dari setiap cluster. Langkah-langkah algoritma
K-means clustering :
1. Tentukan K
2. Bangkitkan k centroids (titik pusat cluster) awal secara random
3. Hitung jarak setiap data ke masing-masing centroids
4. Setiap data memilih centroids yang terdekat
5. Tentukan posisi centroids baru dengan cara menghitung nilai rata-rata dari data-data yang memilih pada centroid yang sama 6. Kembali ke langkah 3 jika posisi
centroids baru dengan centroids
lama tidak sama. [Barakbah,2010].
RUP
Rational Unified Process
(RUP) merupakan suatu metode rekayasa perangkat lunak yang dikembangkan dengan mengumpulkan berbagai best
practices yang terdapat dalam
industri pengembangan perangkat lunak. Ciri utama metode ini adalah menggunakan use-case driven dan pendekatan literatif. RUP menggunakan konsep object oriented, dengan aktifitas yang
berfokus pada pengembangan model dengan menggunakan Unified Model
Language (UML). Berikut metode
pengembangan sistem yang digunakan pada metode RUP :
1. Inception : Pada tahap ini pengembang mendefinisikan batasan kegiatan, melakukan analisis kebutuhan user, dan melakukan perancangan awal perangkat lunak (perancangan arsitektural dan use case).
2. Elaboration: Pada tahap ini dilakukan perancangan perangkat lunak mulai dari menspesifikasikan fitur perangkat lunak hingga perilisan prototipe versi Betha dari perangkat lunak. 3. Construction:
Pengimplementasian rancangan perangkat lunak yang telah dibuat dilakukan pada tahap ini. Pada akhir tahap ini, perangkat lunak versi akhir yang sudah disetujui administrator dirilis beserta dokumentasi perangkat.
4. Transition : Instalasi, deployment dan sosialisasi perangkat lunak dilakukan pada tahap ini.
3. ANALISIS SISTEM Fase Inception
Fase inception merupakan fase pertama dalam pengembangan perangkat lunak metode RUP. Pada fase ini didefinisikan masalah yang dihadapi, cara pemecahan masalah, analisis kebutuhan, dan pembuatan
bussiness modelling.
Deskripsi Masalah
Data citra membutuhkan ruang simpanan yang besar, dan kemungkinan dalam suatu direktori penyimpanan pada harddisk terdapat banyak citra (image). Sehingga sistem penyimpanan dari berbagai macam informasi digital tersebut semakin meningkat dan membuat masalah dalam pencarian kembali dan pengolahannya.
Pemecahan Masalah
Dengan masalah yang sudah diuraikan maka diambil solusi untuk membangun sebuah sistem yang dapat digunakan untuk mempermudah dan mempercepat pencarian/penemuan kembali citra dalam sebuah direktori/database berdasarkan content sebuah citra. Deskripsi Umum Sistem
Dalam penelitian ini dibangun sistem CBIR untuk melakukan pencarian dokumen citra berwarna. Pengguna menentukan sendiri nilai K yang digunakan sebagai konstanta pembentukan cluster untuk proses
clustering, selanjutnya pengguna
memilih citra acuan dan memberi
input berupa citra, kemudian sistem
akan mencari citra-citra lain yang mirip dengan citra input melalui proses matching. Kemiripan ditentukan berdasarkan nilai jarak antar histogram. Hasil pencarian
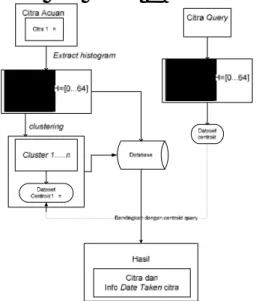
akan ditampilkan terurut berdasarkan nilai jarak histogramnya. Gambaran sistem pada gambar 1.
Gambar 1 Gambaran sistem secara keseluruhan
Berikut ini dipaparkan penjelasan dari sistem :
A. Ekstraksi Fitur
Ekstraksi fitur dilakukan pada citra query dan citra acuan. Pengguna memilih sekumpulan citra pada direktori, kemudian diekstrak fitur
color histogramnya. Hasil dari
ektraksi ini disimpan ke database. Selain diekstrak histogramnya, data
property citra query juga akan
diekstrak dengan bantuan exif tools untuk dapat mengetahui tanggal pembuatan citra.
Color histogram dari tiap citra
(citra acuan/database maupun citra
query) dihitung dengan cara
mendiskretkan warna dalam citra, dan menghitung jumlah dari tiap-tiap citra. Setelah pengambilan nilai RGB dari tiap pixel, kemudian langsung dikonversi ke HSV. Selanjutnya dilakukan kuantisasi warna. Warna yang semula berjumlah (255 x 255 x255) atau 16.581.375 kemungkinan
warna, diubah menjadi (4 x 4 x 4) atau 64 kemungkinan warna.
B. Clustering
Clustering dilakukan pada
sejumlah histogram dari citra acuan dengan menggunakan algoritma
K-Means clustering. Tahap clustering
diawali dengan inisialisasi besarnya K, dan inisialisasi dataset. Dataset masukan berasal dari obyek yang menyimpan array histogram tiap gambar. Algoritma K-Means ini akan memilih secara random dataset yang akan dijadikan centroid. Kemudian menghitung jarak setiap data ke masing-masing centroid. Setiap data memilih centroid yang terdekat yang dihitung dengan rumus euclidian
distance.
Gambar 2 Ilustrasi Klastering C. Pencocokan
Setelah proses clustering
selesai dilakukan, maka tiap cluster tersebut dihitung nilai histogram rata-ratanya (untuk dijadikan centroid). Nilai centroid-centroid ini kemudian dibandingkan dengan HSV histogram gambar query. Centroid yang memiliki jarak paling dekat merupakan solusinya, dan citra dengan centroid terdekat ini ditampilkan pada sistem. Kemudian sistem akan menampilkan pula
beberapa citra yang memiliki jarak terdekat. Penghitungan similarity antara histogram citra acuan dan citra
query yaitu menggunakan euclidian distance. Contoh :
H(citra 1) = {0,2,3} H(citra 2) = {0,1,2}
Mengacu pada persamaan 4, jarak antara histogram citra 1 dengan histogram citra 2 adalah:
= (0 − 0) + (2 − 1) + (3 − 2)
= √2 = 1,41
Analisis Kebutuhan Fungsional Dalam membangun image retrieval ini diperlukan batasan yang
jelas sebagai tujuan utamanya agar tidak keluar dari rencana yang telah ditetapkan. Beberapa kebutuhan sistem yang akan didefinisikan dalam
Software Requirement Specification
antara lain :
Tabel 1 Software Requirement
Specification No SRS ID Description 1 SRS -STK001 Pengguna dapat mengakses halaman utama aplikasi. 2 SRS -STK002 Pengguna dapat menentukan nilai K dan memilih sekumpulan citra yang akan dijadikan acuan. 3 SRS -STK003 Pengguna dapat menentukan citra query.
4 SRS -STK004 Pengguna dapat melakukan pencarian citra, sehingga memperoleh hasil berupa citra yang mirip dan tanggal pembuatan citra. Fase Elaboration
Identifikasi Aktor
Aktor pada aplikasi content
based image retrieval menggunakan color histogram dan algoritma
K-Means clustering ini yaitu user. User dapat menentukan sendiri sekumpulan citra database dan citra
query yang akan dilakukan
pencarian.
Use Case Diagram
Use case diagram ini berfungsi
untuk melihat proses interaksi aktor terhadap sistem. Use case diagram yang dirancang pada tugas akhir ini adalah use case diagram image
retrieval, terdapat pada gambar 3
berikut :
Gambar 3 Use Case Diagram Image
Retrieval
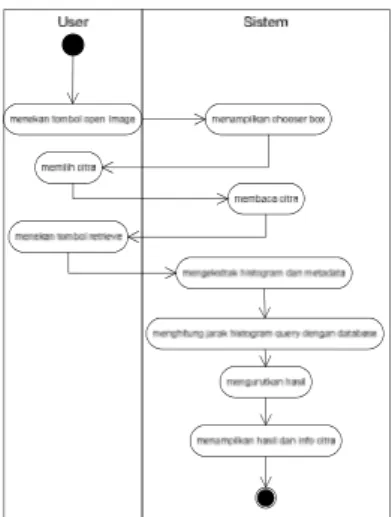
Activity Diagram
Activity Diagram memodelkan alur
kerja sebuah proses dan urutan aktivitas dalam suatu proses. Contoh
activity diagram pencarian pada
gambar 4.
Gambar 4 Activity Diagram Pencarian
Sequence Diagram
Sequence diagram
memperlihatkan kolaborasi dinamik antara objek-objek dengan suatu urutan pesan (a sequence of message) antar objek tersebut.
Contoh sequence diagram pencarian
dapat dilihat pada gambar 5 di bawah ini.
User
Halaman Utama Citra
tekan tombol open()
Histogram createHistogram() KMeansCluster calculatedistance() select() prosesOpen()
tekan tombol retrieve() getSelectedFile() imageHSVHistogram() search() Centroid result() panel.addFinalResult()
Gambar 5 Sequence Diagram Pencarian
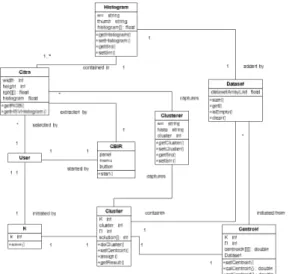
Class Diagram
Class adalah deskripsi
kelompok objek-objek dengan properti, perilaku (operasi) dan relasi yang sama. Dengan adanya class
diagram dapat memberikan
pandangan umum tentang sebuah sistem.
Adapun untuk perancangan
class diagram sistem ini terdapat
pada gambar 6.
1. Sistem dimulai ketika user
membuka aplikasi CBIR, dengan nilai K yang diinputkan sebagai konstanta.
2. Sistem akan membaca nilai K ini dan dijadikan parameter untuk pembentukan cluster.
3. User akan memilih sekumpulan citra yang kemudian citra-citra ini akan diekstrak fiturnya, berupa
color histogram, yang nanti
menjadi dataset. Sistem akan membaca dataset ini, kemudian membangkitkan centroid cluster secara acak dari dataset yang ada. Dataset yang lainnya akan dihitung jaraknya dengan centroid kemudian mengelompokkan sendiri dengan jarak yang paling kecil. Jika tidak ada lagi objek yang berpindah, maka proses
clustering selesai dan tiap citra
menempati clusternya masing-masing, dan data ini disimpan pada tabel clusterer.
4. User memilih citra query, sistem akan membaca histogram dari citra query kemudian menghitung jarak antara histogram query ini dengan histogram citra acuan. Jarak histogram terkecillah yang menjadi solusinya dan sistem menampilkan hasilnya.
Gambar 6 Class Diagram Perancangan Antarmuka (Interface)
Perancangan antarmuka bertujuan untuk memberikan gambaran tentang aplikasi yang akan dibangun, sehingga akan mudah dalam mengimplementasikan aplikasi.
A. Antarmuka Halaman Utama Di bawah ini merupakan perancangan antarmuka halaman utama, terdapat pada gambar 7.
Gambar 7 Antarmuka Halaman Utama
4. IMPLEMENTASI SISTEM Fase Construction
Fase construction merupakan fase ketiga dalam pengembangan perangkat lunak metode RUP.
Persiapan Sistem
Beberapa hal yang harus dipersiapkan dalam pengimplementasian adalah sebagai berikut :
A. Spesifikasi Perangkat Lunak Adapun untuk melengkapi perangkat keras yang telah disebutkan sebelumnya maka diperlukan juga perangkat lunak, diantaranya :
1. jdk-6u3-windows-i586-p.exe sebagai paket JDK untuk bahasa pemrograman Java, yaitu Java jdk 1.6.0_10, dengan menggunakan library jre6, dan library tambahan berupa jfreechart-1.0.14 dan jcommon-1.0.17.
2. Tools yang digunakan untuk pembuatan dan pengembangan aplikasi adalah IDE Eclipse Galileo, dan tool tambahan exiftool.
3. Perangkat lunak yang digunakan untuk pembuatan database adalah XAMPP MySQL 5.
Implementasi Sistem
Berdasarkan perancangan antarmuka sistem yang telah dibuat pada bab sebelumnya, maka implementasinya disajikan dalam gambar di bawah ini.
Gambar 8 Implementasi Antarmuka Halaman Utama
Pengujian
Pengujian dilakukan dengan dua tahap, yaitu uji keakuratan program dan uji aplikasi.
1. Parameter Uji Coba
Parameter uji coba merupakan bagian penting dari percobaan yang menentukan hasil akhir pencarian. Pada percobaan ini, parameter uji coba yang digunakan adalah sebagai berikut: a. Tipe citra digital: jpg.
b. Jumlah citra acuan: 233.
c. Metode clustering: K-Means dengan nilai K yang diisi oleh
user, 5– 10.
d. 10 citra query diambil dari folder yang sama dengan citra acuan, dan 10 lainnya cdiambil dari folder yang berbeda.
1) Hasil Clustering
Pada percobaan ini, citra masuk ke cluster 3, 5, dan 6.
Cluster 3 didominasi oleh
warna kuning dan jingga,
cluster 5 oleh warna biru muda
dan cluster 6 oleh warna biru tua. Hasil cluster 5 ditunjukkan pada gambar 9.
Gambar 9 Hasil Percobaan 1
Cluster 5
2) Hasil Pencarian
Query A (Citra Query yang Direktorinya Sama dengan Direktori Citra Acuan)
Hasil pencarian percobaan 1 terdapat pada gambar 10 di bawah ini.
Gambar 10 Hasil Pencarian Percobaan 1 (Query 1) Hasil pencarian citra query yang lainnya dapat dilihat pada tabel 1 di bawah ini.
Tabel 1 Tabel Pencarian Percobaan 1 Query Dikenali/ Akurasi Jarak gambar query Waktu 1 V 0.0 63 2 V 0.0 59 3 V 0.0 42 4 V 0.0 46 5 v 0.0 52 6 v 0.0 41 7 v 0.0 46 8 v 0.0 60 9 v 0.0 61 10 v 0.0 54 Jumlah 0.0 524
Query B (Direktori citra query tidak sama dengan direktori citra acuan)
Hasil pencarian percobaan 2 dapat dilihat pada gambar 4.11 di bawah ini.
Gambar 4.11 Hasil Pencarian Percobaan 2
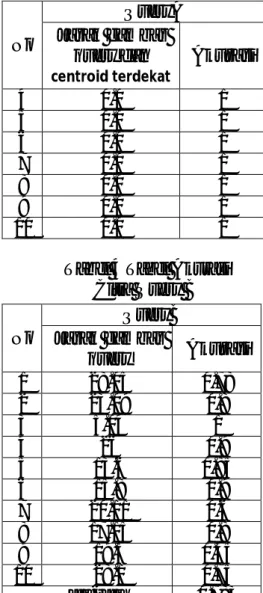
Analisa Data Hasil Clustering Berikut ini adalah tabel hasil pengujian dari tiap nilai K yang
dimasukkan range 5-10 beserta jumlah cluster yang terisi dan tingkat kemiripannya, terdapat pada tabel 2.
Tabel 2 HasilClustering Keseluruhan Percobaan
Berdasarkan data di atas, dapat menunjukkan bahwa banyaknya nilai K tidak mempengaruhi masuknya citra menjadi anggota pada cluster tertentu, serta semakin besar jumlah
cluster yang terisi maka semakin
besar pula tingkat kemiripan tiap
clusternya.
Analisis Data Hasil pencarian Berikut ini adalah tabel hubungan jarak antara centroid dan citra query dengan tingkat akurasi, terdapat pada tabel dan 4.
Tabel 3 Tabel Akurasi Citra Query A No QueryA Jarak gambar query dan centroid terdekat Akurasi 1 0.0 1 2 0.0 1 3 0.0 1 K Perco-baan Jumlah Cluster terisi Rata-Rata Kemiripan 5 1 2 0.725 2 2 0.715 6 1 3 0.73 2 2 0.725 7 1 2 0.665 2 2 0.675 8 1 2 0.665 2 1 0.55 9 1 1 0.55 2 1 0.55 10 1 1 0.55 2 3 0.72
Tabel 3 Tabel Akurasi Citra Query A(lanjut)
Tabel 4 Tabel Akurasi Citra Query B
Di bawah ini tabel 5 yang menunjukkan perbedaan waktu pencarian antara pencarian dengan
query yang berasal dari direktori
yang sama dengan citra (query A) dengan query yang berbeda direktori (query B).
Tabel 5 Perbandingan Waktu Percobaan ke-Waktu Rata-Rata Query A Query B 1 524 574 2 578 573 3 584 566
Tabel 5 Perbandingan Waktu(lanjut) Percobaan ke-Waktu Rata-Rata Query A Query B 4 551 572 5 590 613
Dari tabel di atas dapat diketahui bahwa waktu yang dibutuhkan untuk pencarian citra yang masih berasal dari direktori yang sama dengan direktori citra acuan lebih sedikit daripada waktu untuk menemukan kembali citra yang mirip dengan query yang bukan berasal dari citra yang sama dengan citra acuan.
PENUTUP Kesimpulan
Kesimpulan dalam penelitian skripsi ini adalah :
1. Untuk melakukan ekstraksi fitur warna, sistem akan membaca nilai histogram RGB. Color histogram dari tiap citra (citra acuan/database maupun citra
query) dihitung dengan cara
mendiskretkan warna dalam citra, dan menghitung jumlah dari tiap-tiap citra. Kemudian dilakukan kuantisasi warna serta proses normalisasi dan didapatlah nilai histogramnya .
2. K-Means digunakan dengan terlebih dahulu mengelompokkan citra yang memiliki nilai HSV histogram yang berdekatan. Kemudian sistem akan menampilkan hasil clusteringnya. Dengan cara ini, pada beberapa pengujian, nilai K yang diinputkan manual ternyata membentuk cluster sebanyak K namun tidak semua cluster
No QueryA Jarak gambar query dan centroid terdekat Akurasi 4 0.0 1 5 0.0 1 6 0.0 1 7 0.0 1 8 0.0 1 9 0.0 1 10 0.0 1 No QueryB Jarak gambar query Akurasi 1 28.05 0.78 2 23.09 0.8 3 5.04 1 4 26 0.9 5 13.6 0.85 6 15.8 0.9 7 20.11 0.6 8 17.15 0.8 9 19.5 0.45 10 28.1 0.75 Rata-rata 0.783
memiliki anggota. Semakin banyak jumlah cluster yang memiliki anggota maka semakin tinggi juga tingkat kemiripan tiap
clusternya.
3. Waktu yang dibutuhkan dalam pencarian untuk query yang berasal dari direktori yang sama dengan citra acuan lebih cepat dan jarak centroid dengan citra query memberi pengaruh 100% terhadap tingkat akurasi. Sedangkan untuk
query yang berasal dari direktori
yang berbeda dengan citra acuan, waktu yang dibutuhkannya lebih lama dan dekatnya jarak centroid dengan citra query, hanya mempunyai pengaruh sebesar 0.33% saja terhadap tingkat akurasi, sisanya sebesar 99.67%, nilai akurasi dipengaruhi oleh faktor bukan jarak. Maka sistem ini berhasil membantu pengguna menemukan citra yang mirip dan memberikan informasi tanggal pembuatan citra query. Aplikasi ini dirancang dengan tampilan yang simpel sehingga mudah digunakan.
Saran
1. Untuk lebih meningkatkan akurasi hasil pencarian pada sistem CBIR (khususnya fitur warna), perlu dipertimbangkan penggunaan LCH (Local Colour Histogram).
2. Untuk proses clustering perlu
menggunakan metode yang lebih baik lagi agar performa lebih baik selain K-Means ataupun FGKA. 3. Dapat melakukan ekstraksi fitur
yang lebih banyak, tidak hanya dari fitur warna, tapi juga dari tekstur maupun bentuk agar content based image retrieval ini dapat dikembangkan secara luas.
DAFTAR PUSTAKA
Barakbah, Ali R. 2006.Clustering. Workshop. Surabaya: Politeknik Elektronika Negeri Surabaya.
Gonzales, R., Woods, R. 2002.
Digital Image Processing. New
Jersey: Prentice Hall.
Rodiyansyah, Sandi Fajar. 2010.
Ekstraksi Histogram Citra
Digital Untuk mengukur
Similarity dengan
Menggunakan Metode
Euclidian Distance. Jurnal.
Yogyakarta: Universitas Gadjah Mada.
Silva Torres, R., Alexandre. 2006.Content-Based Image
Retrieval: Theory and
Applications. Jurnal. Brazil :
Institute of Computing, State University of Campinas, Campinas.
Suryana, Taryana. 2007. Metode
RUP. Materi. Bandung: STMIK LIKMI.
Wahono, R.S., Dharwiyanti, S. 2003.
Pengantar UML. Kuliah
Umum Ilmu Komputer.
Wang, Shengjiu. 2001. A Robust
CBIR Approach Using Local Color Histograms. Technical Report. Canada : Department
of Computer Science, University of Alberta, Edmonton, Alberta.
Widodo, Yanu. 2007. Penggunaan
Color Histogram Penggunaan Color Histogram Dalam Image Retrieval. Jurnal. Komunitas