LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA
Modul IV
KLASIFIKASI
TUJUAN PRAKTIKUMSetelah mengikuti praktikum modul ini diharapkan:
1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar mengenai metode pencarian pengetahuan/pola data dari sejumlah data dengan menggunakan teknik Klasifikasi.
2. Mahasiswa mampu menyelesaikan kasus klasifikasi data dengan menggunakan/menerapan decision tree.
LANDASAN TEORI 4.1 Definisi Klasifikasi
Klasifikasi adalah sebuah proses untuk menemukan model yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang kelasnya tidak diketahui (Tan et all, 2004). Di dalam klasifikasi diberikan sejumlah record yang dinamakan training set, yang terdiri dari beberapa atribut, atribut dapat berupa kontinyu ataupun kategoris, salah satu atribut menunjukkan kelas untuk record.
Gambar 1. Klasifikasi sebagai suatu tugas memetakan atribut x
ke dalam label kelas y (Tan et all, 2006) Model Klasifikasi terdiri dari (Tan et all, 2006):
1. Pemodelan Deskriptif
Dapat bertindak sebagai suatu alat yang bersifat menjelaskan untuk membedakan antara objek dengan klas yang berbeda.
2. Pemodelan Prediktif
Model klasifikasi juga dapat menggunakan prediksi label kelas yang belum diketahui recordnya.
4.2 Tujuan Klasifikasi
Tujuan dari klasifikasi adalah untuk:
1. Menemukan model dari training set yang membedakan record kedalam kategori atau kelas yang sesuai, model tersebut kemudian digunakan untuk mengklasifikasikan
record yang kelasnya belum diketahui sebelumnya pada test set.
2. Mengambil keputusan dengan memprediksikan suatu kasus, berdasarkan hasil klasifikasi yang diperoleh .
4.3 Konsep Pembuatan Model dalam Klasifikasi
Untuk mendapatkan model, kita harus melakukan analisis terhadap data latih (training set). Sedangkan data uji (test set) digunakan untuk mengetahui tingkat akurasi dari model yang telah dihasilkan. Klasifikasi dapat digunakan untuk memprediksi nama atau nilai kelas dari suatu obyek data. Proses klasifikasi data dapat dibedakan dalam 2 tahap, yaitu :
1. Pembelajaran / Pembangunan Model
Tiap – tiap record pada data latih dianalisis berdasarkan nilai – nilai atributnya, dengan menggunakan suatu algoritma klasifikasi untuk mendapatkan model.
2. Klasifikasi
Pada tahap ini, data uji digunakan untuk mengetahui tingkat akurasi dari model yang dihasilkan. Jika tingkat akurasi yang diperoleh sesuai dengan nilai yang ditentukan, maka model tersebut dapat digunakan untuk mengklasifikasikan record – record data baru yang belum pernah dilatihkan atau diujikan sebelumnya.
Untuk meningkatkan akurasi dan efisiensi proses klasifikasi, terdapat beberapa langkah pemrosesan terhadap data, yaitu :
1. Data Cleaning
Data cleaning merupakan suatu pemrosesan terhadap data untuk menghilangkan noise dan penanganan terhadap missing value pada suatu record.
2. Analisis Relevansi
Pada tahap ini, dilakukan penghapusan terhadap atribut – atribut yang redundant ataupun kurang berkaitan dengan proses klasifikasi yang akan dilakukan. Analisis relevansi dapat meningkatkan efisiensi klasifikasi karena waktu yang diperlukan untuk pembelajaran lebih sedikit daripada proses pembelajaran terhadap data – data dengan atribut yang masih lengkap (masih terdapat redundansi).
3. Transformasi Data
Pada data dapat dilakukan generalisasi menjadi data dengan level yang lebih tinggi. Misalnya dengan melakukan diskretisasi terhadap atribut degan nilai kontinyu. Pembelajaran terhadap data hasil generalisasi dapat mengurangi kompleksitas pembelajaran yang harus dilakukan karena ukuran data yang harus diproses lebih kecil.
(a)
(b)
Gambar 2. Proses Klasifikasi: (a) Learning: Training data dianalisis dengan
algoritma klasifikasi. Disini atribut label kelas adalah ”Tenured“, dan “Learned Model“ atau “classifier“ di gambarkan pada blok aturan klasifikasi. (b). Classification: Test data digunakan untuk memperkirakan keakuratan aturan klasifikasi. Jika keakuratan tersebut dianggap diterima, maka aturan itu dapat diaplikasikan untuk mengkalsifikasikan data tuples baru.
Pada Gambar 2 terdiri dari pembuatan model dan penggunaan model. Pembuatan model menguraikan sebuah set dari penentuan kelas-kelas sebagai:
1. Setiap tuple diasumsikan sudah mempunyai kelas yang dikenal seperti ditentukan oleh label kelas atribut.
2. Kumpulan tuple yang digunakan untuk membuat model disebut kumpulan pelatihan (training set)
3. Model direpresentasikan sebagai classification rules, decision tree atau formula
matematika.
Penggunaan model menguraikan pengklasifikasian masa yang akan datang atau obyek yang belum ketahui, yaitu taksiran keakuratan dari model yang terdiri dari:
1. Label yang telah diketahui dari contoh tes dibandingkan dengan hasil klasifikasi dari model.
2. Nilai keakuratan adalah prosentase dari kumpulan contoh tes yang diklasifikasikan secara tepat oleh model.
3. Kumpulan tes tidak terikat pada kumpulan pelatihan,
4. Jika akurasi diterima, gunakan model untuk mengklasifikasikan data tuple yang label kelasnya belum diketahui.
Untuk mengevaluasi performansi sebuah model yang dibangun oleh algoritma klasifikasi dapat dilakukan dengan menghitung jumlah dari test record yang di prediksi secara benar (akurasi) atau salah (error rate) oleh model tersebut. Akurasi dan error rate didefinisikan sebagai berikut.
Akurasi = Jumlah prediksi benar Jumlah total prediksi
Error rate = Jumlah prediksi salah
Jumlah total prediksi
Algoritma klasifikasi berusaha untuk mencari model yang mempunyai akurasi yang tinggi atau error rate yang rendah ketika model diterapkan pada test set.
4.4 Teknik Klasifikasi
Didalam Klasifikasi sebagaimana telah dijelaskan, ada beberapa teknik klasifikasi yang digunakan, anataralain: pohon keputusan, rule based, neural network, support
vector machine, naive bayes, dan nearest neighbour. Dan pada praktikum ini akan
menggunakan teknik pohon keputusan, karena beberapa alasan:
1. Dibandingkan dengan classifier JST atau bayesian, sebuah pohon keputusan mudah diinterpretasi/ ditangani oleh manusia.
2. Sementara training JST dapat menghabiskan banyak waktu dan ribuan iterasi, pohon keputusan efisien dan sesuai untuk himpunan data besar.
3. Algoritma dengan pohon keputusan tidak memerlukan informasi tambahan selain yang terkandung dalam data training (yaitu, pengetahuan domain dari distribusi-distribusi pada data atau kelas-kelas).
4. Pohon keputusan menunjukkan akurasi klasifikasi yang baik dibandingkan dengan teknik-teknik yang lainnya.
4.5 Decision Tree
Salah satu metoda Data Mining yang umum digunakan adalah decision tree.
Decision tree adalah struktur flowchart yang menyerupai tree (pohon), dimana setiap
simpul internal menandakan suatu tes pada atribut, setiap cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision
tree di telusuri dari simpul akar ke simpul daun yang memegang prediksi kelas untuk
contoh tersebut. Decision tree mudah untuk dikonversi ke aturan klasifikasi (classification rules)(Zalilia, 2007).
Konsep Decision Tree
Mengubah data menjadi pohon keputusan (decision tree) dan aturan-aturan keputusan (rule) (Basuki dkk, 2003).
Gambar 3. Konsep Decision Tree
Tipe Simpul Pada Tree
Tree mempunyai 3 tipe simpul yaitu (Zalilia, 2007):
1. Simpul akar dimana tidak ada masukan edge dan 0 atau lebih keluaran edge (tepi), 2. Simpul internal , masing-masing 1 masukan edge dan 2 atau lebih edge keluaran, 3. Simpul daun atau simpul akhir, masing-masing 1 masukan edge dan tidak ada
edge keluaran.
Pada decision tree setiap simpul daun menandai label kelas. Simpul yang bukan simpul akhir terdiri dari akar dan simpul internal yang terdiri dari kondisi tes atribut pada sebagian record yang mempunyai karakteristik yang berbeda. Simpul akar dan simpul internal ditandai dengan bentuk oval dan simpul daun ditandai dengan bentuk segi empat (Han, 2001).
Gambar 4. Decision tree untuk masalah klasifikasi intrusion
Konsep Data Dalam Decision Tree
Ada beberapa konsep dalam decision tree, antara lain:
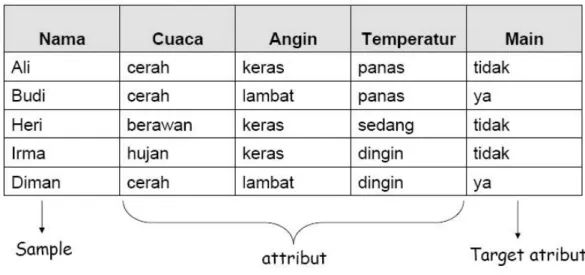
1. Data dinyatakan dalam bentuk tabel dengan atribut dan record.
2. Atribut menyatakan suatu parameter yang dibuat sebagai kriteria dalam pembentukan tree. Misalkan untuk menentukan main tenis, kriteria yang diperhatikan adalah cuaca, angin dan temperatur. Salah satu atribut merupakan atribut yang menyatakan data solusi per-item data yang disebut dengan target atribut.
3. Atribut memiliki nilai-nilai yang dinamakan dengan instance . Misalkan atribut cuaca mempunyai instance berupa cerah, berawan dan hujan.
Contoh pemakaian Decision Tree
1. Diagnosa penyakit tertentu, seperti hipertensi, kanker, stroke dan lain-lain. 2. Pemilihan produk seperti rumah, kendaraan, komputer dan lain-lain 3. Pemilihan pegawai teladan sesuai dengan kriteria tertentu
Proses Dalam Decision Tree (Basuki dkk, 2003)
Proses pembentukan Decision Tree adalah sbb:
1. Mengubah bentuk data (tabel) menjadi model tree.
Ukuran untuk Memilih Split Terbaik
Pemilihan atribut pada algoritma induksi decision tree menggunakan ukuran berdasarkan entropy yang dikenal dengan information gain sebagai sebuah
heuristic untuk memilih atribut yang merupakan bagian terbaik dari contoh ke
dalam kelas. Semua atribut adalah bersifat kategori yang bernilai diskrit. Atribut dengan nilai
continuous harus didiskritkan (Zalilia, 2007).
Ukuran information gain digunakan untuk memilih tes atribut pada setiap simpul dalam tree. Atribut dengan information gain tertinggi (atau nilai pengurangan entropy yang terbesar) dipilih sebagai tes atribut untuk simpul tersebut. Atribut ini meminimalkan informasi yang dibutuhkan untuk mengklasifikasikan contoh pada proses pembagian dan mencerminkan ketidakmurnian (impurity). Misalkan S adalah kumpulan dari s contoh data. Andaikan atribut label kelas mempunyai m nilai berbeda yang menjelaskan m nilai kelas yang berbeda, C (for i = 1, ..., m). Misalkan si i menjadi jumlah contoh S dalam kelasC . i
Informasi yang dibutuhkan untuk mengklasifikasikan diberikan contoh sebagai berikut.
∑
= − = m i i i S S S p p I m 1 2 ) ,..., , ( 1 2 log ( ) (1)dimana pi adalah kemungkinan sebuah contoh kepunyaan kelas C dan i
diperkirakan oleh si/s . Catatan bahwa fungsi log basis 2 digunakan semenjak
informasi dikodekan dalam bit-bit.
Misalkan atribut A mempunyai nilai v yang berbeda,
{
a1,a2,...,av}
AtributA dapat digunakan untuk membagi S kedalam v bagian (subset),
{
S1,S2,...,Sv}
,dimana S berisi contoh di S yang mempunyai nilai j a dari A . Jika A terpilih j
sebagai tes atribut (misal atribut untuk splitting), maka bagian ini akan sesuai dengan pertumbuhan cabang dari simpul yang berisi S . Misal S menjadi contoh ij
kelas C pada sebuah subset i S . Entropy atau informasi berdasarkan pembagian ke j
dalam bagian A sebagai berikut.
( )
(
j mj)
v j mj j I s s s s s A E ... . 1 ,..., 1 1∑
= + + = (2)Bentuk
s s sij + ...+ mj
adalah bobot dari bagian (subset) jth dan merupakan jumlah
contoh pada subbagian dibagi oleh total jumlah contoh dalam S . Nilai entropy terkecil adalah kemurnian (purity) terbesar pada pembagian subbagian. Catatan untuk subbagian s ,j
(
)
∑
( )
= − = m i ij ij mj j j s s p p s I 1 2 2 1 , ,..., log (3) Dimana j ij ij S sp = adalah probabilitas pada contoh s kepunyaan kelas j C . i
Pengkodean informasi yang akan diperoleh dari percabangan pada A adalah:
( ) (
A I s s s) ( )
E AGain = 1, 2,...., m − (4)
Dengan kata lain, Gain(A)adalah reduksi yang diharapkan dalam entropy yang disebabkan oleh pengetahuan nilai pada atribut A. Algoritma menghitung
information gain pada setiap atribut. Atribut dengan nilai gain terbesar dipilih
sebagai tes atribut (simpul akar). Simpul A dibuat dan dilabelkan dengan atribut, cabang dibuat untuk setiap nilai atribut.
a. Entropy
Definisi Entrophy (Basuki, 2003):
1. Entropy (S) adalah jumlah bit yang diperkirakan dibutuhkan untuk dapat mengekstrak suatu kelas (+ atau -) dari sejumlah data acak pada ruang sample S. 2. Entropy bisa dikatakan sebagai kebutuhan bit untuk menyatakan suatu kelas.
Semakin kecil nilai Entropy maka semakin baik untuk digunakan dalam mengekstraksi suatu kelas.
3. Panjang kode untuk menyatakan informasi secara optimal adalah − log2 pbits untuk messages yang mempunyai probabilitas p.
4. Sehingga jumlah bit yang diperkirakan untuk mengekstraksi S ke dalam kelas adalah: ) ( 2 ) ( ) ( 2 ) (+ log + − − log − − p p p p (5) ) ( 2 ) ( ) ( 2 ) ( log log ) (S = − p+ p+ − p− p− Entropy (6)
Keterangan :
S = ruang (data) sample yang digunakan untuk training.
P(+) = jumlah yang bersolusi positif (mendukung) pada data sample untuk kriteria tertentu.
P(-) = jumlah yang bersolusi negatif (tidak mendukung) pada data sample untuk kriteria tertentu.
2. Mengubah model tree menjadi rule.
Gambar 6. Mengubah Tree Menjadi Rules
3. Menyederhanakan Rule (“test of independency” dengan distribusi terpadu chi-square) Apabila individu-individu suatu populasi dapat diklasifikasikan dalam dua variable (kategori),tiap-tiap kategori dapat terdiri dari beberapa alternative. Kemudian kita ingin menguji Ho apakah kedua variable kedua variable itu independent. Untuk menguji Ho tersebut kemudian diambil suatu sample, individu-individu dalam sample tersebut diklasifikasikan dalam”two way classification”. Test yang demikian dinamakan test of independency (pengujian Independensi). Tabelnya dinamakan tabel kontingensi. Apabila variabel I terdiri dari k kategori dan variabel II terdiri dari r kategori, tabelnya dapat disusun seperti tabel dibawah ini.
Tabel kontingensi Variabel I A1 A2 A3 Ak Jumlah Variabel II B1 n11 n12 n13 ……… n1k n1 B2 n21 n22 n23 ……… n2k n2 . . . . ……… . . . . . . ……… . . . . . . ……… . . . . . . ……… . . Br nr1 nr2 nr3 ……….. nrk nr Jumlah n1 n2 n3 nk n Dimana;
nij = individu dari baris i kolom j
i = 1, 2, ………..r
j = 1, 2, 3, ………...k
Langkah-langkah dalam test of independensi:
1. Menentukan formulasi null hipotesis dengan alternative hipotesis: Ho: P11 = P12 = …………...= P1k
P21 = P22 = …………...= P2k
Pr1 = Pr2 = = Prk
H1 : tidak semua proporsi sama
3. Kriteria pengujian:
X 2 {α ; (r-1)(k-1)}
Ho diterima apabila : X 2 ≤ X 2 α ; (n-1) (k-1)
berarti kriteria independent (dapat dihilangkan) Ho ditolak apabila : X 2 > X 2 α ; (r-1) (k-1)
berarti kriteria dependent (tidak dapat dihilangkan) 4. Perhitungan: X 2 =
∑
∑
= = − k i j r j i eij eij nij )2 ( ……… (1) Dimana eij = n n ni.)( .j) ( ………. (2) ijn = frekuensi pengamatan (observasi) dari baris I dan kolom j
ij
e = frekuensi diharapkan (expected) dari baris I dan kolom j
5. Kesimpulan: Apakah Ho diterima (Variabel yang satu tidak mempengaruhi/independent dengan variabel yang lain) atau Ho ditolak (variabel I dependen dengan variabel II)
Contoh:
Kita ingin mengetahui apakah ada pengaruh (hubungan dependen) antara pendapatan individu dengan kualitas bahan makanan yang dikonsumir.
Untuk tujuan ini kemudian diadakan ujian penyelidikan terhadap 100 individu dan didapat kenyatan sebagai berikut:
Daerah tolak Daerah
terima
Pendapatan
Tinggi Sedang Rendah jumlah
Mutu bahan makan Baik 14 6 9 29 Cukup 10 16 10 36 Jelek 2 13 20 35 Jumlah 26 35 39 100 Penyelesaian: 1. Hipotesis Ho : P11 = P12 = P13 P21 = P22 = P23 P31 = P32 = P33
Atau mutu bahan makan dependen dengan tingkat dependen. Ho : Mutu bahan makan dependen dengan tingkat pendapatan 2. Dipilih level of significance 0,05
3. Kriteria Pengujian:
X 2 {0,05 ; (3-1)(3-1)}= 9,488
Ho diterima apabila X 2 ≤ 9,488
Ho ditolak apabila X 2 > 9,488
4. Perhitungan X 2 dari sample:
Dengan menggunakan persamaan (2), maka dapat kita cari eij
e11 = 100 ) 26 )( 29 ( = 7,54 e12 = 100 ) 35 )( 29 ( = 10,15 e13 = 100 ) 39 )( 29 ( = 11,31 e21 = 100 ) 26 )( 36 ( = 9,36 e22 = 100 ) 35 )( 36 ( = 12,60 e23 = 100 ) 39 )( 36 ( = 14,04 e31 = 100 ) 26 )( 35 ( = 9,10 e32 = 100 ) 35 )( 35 ( = 12,25 e33 = 100 ) 39 )( 35 ( = 13,65 Daerah terima Daerah tolak X 2
n
ij65 , 13 ) 65 , 13 20 ( 25 , 12 ) 25 , 12 13 ( 10 , 9 ) 10 , 9 2 ( 40 , 14 ) 40 , 14 10 ( 60 , 12 ) 60 , 12 16 ( 36 , 9 ) 36 , 9 10 ( 31 , 11 ) 31 , 11 9 ( 15 , 10 ) 15 , 10 6 ( 54 , 7 ) 54 , 7 14 ( 2 2 2 2 2 2 2 2 2 − ⊕ − ⊕ − ⊕ − ⊕ − ⊕ − ⊕ − ⊕ − ⊕ − Pendapatan
Tinggi Sedang Rendah jumlah
Mutu bahan makan Baik 7,54 10,15 11,31 29 Cukup 9,36 12,60 14,04 36 Jelek 9,10 12,25 13,65 35 Jumlah 26 35 39 100 X 2 = = 18,36 5. Kesimpulan:
Oleh karena 18,36 > 9,48 maka Ho kita tolak, berarti terdapat hubungan antara mutu bahan makan dengan tingkat pendapatan (kriteria dependent).
4.6 CONTOH KASUS
Contoh: Permasalahan Penentuan Seseorang Menderita Hipertensi Menggunakan
Decision Tree. Data diambil dengan 18 sample, dengan pemikiran bahwa yang
mempengaruhi seseorang menderita hipertensi atau tidak adalah usia, berat badan, dan jenis kelamin. Usia mempunyai instance: muda dan tua. Berat badan mempunyai
instance: underweight, average dan overweight. Jenis kelamin mempunyai instance:
pria dan wanita. Data sample yang digunakan untuk menentukan hipertensi adalah:
Nama Pasien Berat Badan Usia Jenis Kelamin Hipertensi?
Oki lukman Overweight Tua Perempuan Ya
Pasha ungu Overweight Tua Laki-laki Ya
Budi anduk Overweight Tua Laki-laki Ya
Indra bekti Overweight Tua Laki-laki Ya
Luna maya Overweight Muda Perempuan Ya
Tukul Overweight Muda Laki-laki Ya
Afgan Average Tua Laki-laki Ya
Desta Average Tua Laki-laki Ya
Ringgo Average Muda Laki-laki Tidak
Ruben Average Muda Laki-laki Tidak
Titi kamal Average Muda Perempuan Tidak
Aurakasih Average Tua Perempuan Tidak
Jengkelin Average Tua Perempuan Tidak
Ari untung Average Muda Laki-laki Tidak
Gita gutawa Underweight Muda Perempuan Tidak
Fedi nuril Underweight Muda Laki-laki Tidak
Dian sastro Underweight Tua Perempuan Tidak
Nicholas Underweight Tua Laki-laki Tidak
Langkah penyelesaian kasus: 1. Mengubah Data Menjadi Tree. 2. Mengubah tree menjadi rule.
3. Menyederhanakan dan menguji rule. 4. Menentukan rule akhir
Penyelesaian:
Langkah -1: Mengubah Data Menjadi Tree. a. Menentukan Node Terpilih.
Dari data sampel tentukan dulu node terpilih, yaitu dengan menghitung nilai information gain masing-masing atribut. (usia, berat badan, dan jenis kelamin).
Catatan:
• Untuk menentukan node terpilih, gunakan nilai information gain dari setiap kriteria dengan data sample yang ditentukan.
• Node terpilih adalah kriteria dengan information gain yang paling besar. Langkah – langkah menentukan node terpilih:
1. Menghitung nilai informasi (I) dari seluruh data training Dengan menggunakan persamaan:
) ( 2 ) ( ) ( 2 ) (+ log + − − log − − p p p p I = -8/18 log2 8/18 – 10/18 log2 10/18 = 0.99 2. Menghitung nilai informasi tiap atribut
Contoh: nilai informasi atribut berat badan
Dengan menggunakan persamaan: − p(+)log2 p(+) − p(−)log2 p(−)
BB Hiper? Jumlah Overweight Ya 6 Overweight Tidak 0 Average Ya 2 Average Tidak 6 Underweight Ya 4 Underweight Tidak 0 Total 18
3. Menghitung nilai entrophy tiap atribut Contoh: Entropy untuk berat badan:
4. Menghitung nilai information gain tiap atribut Contoh: atribut berat badan
( ) (
A I s s s) ( )
E A Gain = 1, 2,...., m − = 0.99 – 0.36 = 0.63 q1= -6/6 log2 6/6 – 0/6 log2 0/6 = 0 q2= -2/8 log2 2/8 – 6/8 log2 6/8 = 0.81 q1= -4/4 log2 4/4 – 0/4 log2 0/4 = 0 E = (6/18)q1 + (8/18)q2 + (4/18)q3 = 0.36Dengan menggunakan langkah – langkah yang sama kita hitung nilai information gain atribut usia dan jenis kelamin, sehingga didapat nilai information gain atribut usia sebesar 0.091 dan jenis kelamin sebesar 0.048.
Sehingga, terpilih atribut BERAT BADAN sebagai node awal karena memiliki
information gain terbesar.
b. Menyusun Tree Awal
Berat badan Afgan + Desta + Ringgo -Ruben -Titi kamal -Aurakasih -Jengkelin -Ari untung -Fedi nuril -Gita gutawa -Dian sastro -Nicholas -Oki lukman + Pasha ungu + Budi anduk + Indra bekti + Luna maya + Tukul + Underweight Average Overweight
Node berikutnya dapat dipilih pada bagian yang mempunyai nilai + dan -, pada
contoh di atas hanya berat = average yang mempunyai nilai + dan –, maka semuanya pasti mempunyai internal node. Untuk menyusun internal node lakukan satu-persatu.
Penentuan
Internal Node untuk berat = average
Nama Pasien Usia Jenis Kelamin Hipertensi?
Afgan Tua Laki-laki Ya
Desta Tua Laki-laki Ya
Ringgo Muda Laki-laki Tidak
Ruben Muda Laki-laki Tidak
Titi kamal Muda Perempuan Tidak
Aurakasih Tua Perempuan Tidak
Jengkelin Tua Perempuan Tidak
Nilai informasi (I) dari data training untuk berat average:
Dengan menggunakan persamaan: − p(+)log2 p(+)− p(−)log2 p(−)
I = -2/8 log2 2/8 – 6/8 log2 6/8 = 0.811
Kemudian kita menghitung nilai entrophy untuk masing – masing atribut yang tersisa:
Usia Hiper? Jumlah Jenis Kelamin Hiper? Jumlah
Tua Ya 2 Laki-laki Ya 2
Tua Tidak 2 Laki-laki Tidak 3
Muda Ya 0 Perempuan Ya 0
Muda Tidak 4 Perempuan Tidak 3
E = 0.5 E = 0.61
Setelah itu didapatkan nilai information gain untuk atribut usia sebesar 0.811 – 0.5 = 0.311, dan nilai information gain untuk atribut jenis kelamin sebesar 0.811 – 0.61 = 0.201, sehingga atribut usia dipilih sebagai node berikutnya. Begitu seterusnya sampai node terakhir dapat menentukan kelas dari data.
Menyusun Tree Lanjutan NO YES Average Overweight Berat badan Usia Afgan + Desta + Aurakasih -Jengkelin -Ringgo -Ruben -Titi kamal -Ari untung -Muda Tua Underweight
NO YES Average Overweight Berat badan Usia Muda Tua Underweight NO Jenis Kelamin Afgan + Desta + Aurakasih -Jengkelin -Perempuan Laki-laki Hasil Tree Akhir NO YES Average Overweight Berat badan Usia Muda Tua Underweight NO Jenis Kelamin Perempuan Laki-laki YES NO
Langkah -2 : Mengubah Tree menjadi rule NO YES Average Overweight Berat badan Usia Muda Tua Underweight NO Jenis Kelamin Perempuan Laki-laki YES NO
R1: IF berat = overweight THEN hipertensi = ya R2: IF berat = underweight THEN hipertensi = tidak
R3: IF berat = average^usia = muda^ THEN hipertensi = tidak
R4: IF berat = average^usia = tua^jenis kelamin=laki-laki^ THEN hipertensi = ya R5: IF berat = average^usia = tua^jenis kelamin=perempuan^ THEN hipertensi = tidak
Langkah -3 : Menyederhanakan dan Menguji Rule
Dalam langkah menyederhanakan dan menguji rule ini, kita dapat menjalankan langkah-langkah berikut:
1. Membuat table distribusi terpadu dengan menyatakan semua nilai kejadian pada setiap rule.
2. Menghitung tingkat independensi antara kriteria pada suatu rule, yaitu antara atribut dan target atribut (penghitungan tingkat independensi menggunakan “Test of Independency” Chi-square)
Untuk
Atribut Berat Badan
BB hiper? jumlah OW AV UW Jumlah
OW ya 6 Hipertensi 6 2 4 12 OW tidak 0 Tidak 0 6 0 6 AV ya 2 Jumlah 6 8 4 18 AV tidak 6 UW ya 4 UW tidak 0 Hipotesis:
H0 : tidak ada hubungan antara berat badan dengan seseorang menderita
hipotensi
H1 : ada hubungan antara berat badan dengan seseorang menderita hipotensi
Tingkat signifikansi : α = 0.05
Degree of freedom (DOF) = {α; (r – 1)*(k - 1)} = {0.05; (2– 1)*(3 - 1)} = {0.05; 2}
9915 . 5 2 = tabel X (lihat tabel) Daerah kritis: X 2 {0,05 ; (2-1)(3-1)}= 5.99 Ho diterima apabila X 2 ≤ 5.99 Ho ditolak apabila X 2 > 5.99
Uji Independensi dengan distribusi Chi-Square
OW AV UW Jumlah Hipertens i 6 2 4 12 Tidak 0 6 0 6 Jumlah 6 8 4 18
n
ij Daerah terima Daerah tolak X 2n
ij33 . 1 ) 33 . 1 0 ( 67 . 2 ) 67 . 2 6 ( 2 ) 2 0 ( 67 . 2 ) 67 . 2 4 ( 33 . 5 ) 33 . 5 2 ( 4 ) 4 6 ( 2 2 2 2 2 − 2 + − + − + − + − + − OW AV UW Hipertensi 4 5.33 2.67 12 Tidak 2 2.67 1.33 6 Jumlah 6 8 4 18 Perhitungan: e11 = 18 ) 6 )( 12 ( = 4 e12 = 18 ) 8 )( 12 ( = 5.33 e13 = 18 ) 4 )( 12 ( = 2.67 e21 = 18 ) 6 )( 6 ( = 2 e22 = 18 ) 8 )( 6 ( = 2.67 e23 = 18 ) 4 )( 6 ( = 1.33
Lalu, kita hitung nilai X2 dengan menggunakan persamaan:
X2 hitung =
∑
∑
= = − k i j ij j ij r j i e ei n )2 ( Dimana eij = n n ni.)( .j) ( X2hitung = = 1 + 2.08 + 0.67 +2 + 4.17 +1.33 = 11.25Karena nilai X2 hitung > X2 tabel yaitu 11.25 > 5.99, maka H0 ditolak, artinya atribut
berat badan mempengaruhi seseorang menderita hipertensi atau tidak (dependent), sehingga atribut ini tidak bisa dihilangkan.
Untuk
Atribut Usia
Dengan cara yang sama pada atribut berat badan, maka dapat diperoleh:
• {0,05 ; 1} 2 = 3.8415
tabel
X (lihat tabel)
• X2 hitung = 2.205
Kesimpulan: Karena nilai X2 hitung ≤ X2 tabel yaitu 2.205 yaitu 2.205 ≤ 3.8415, artinya
atribut usia tidak mempengaruhi seseorang menderita hipertensi atau tidak (independent), sehingga atribut ini bisa dihilangkan.
Untuk
Atribut Jenis kelamin
Dengan cara yang sama pada atribut berat badan, maka dapat diperoleh:
• {0,05 ; 1} 2 = 3.8415
tabel
X (lihat tabel)
• X2 hitung = 5.299
Kesimpulan: Karena nilai X2 hitung > X2 tabel yaitu 5.299> 3.8415, maka H0 ditolak,
artinya atribut berat badan mempengaruhi seseorang menderita hipertensi atau tidak (dependent), sehingga atribut ini tidak bisa dihilangkan.
Langkah -4 : Menentukan Rule Akhir
Berdasarkan hasil penyederhanaan rule dengan Chi-Square, maka rule akhir yang terbentuk adalah:
R1: IF berat = overweight THEN hipertensi = ya R2: IF berat = underweight THEN hipertensi = tidak
R4: IF berat = average ^jenis kelamin=laki-laki^ THEN hipertensi = ya R5: IF berat = average ^jenis kelamin=perempuan^ THEN hipertensi = tidak