KLASIFIKASI REKRUITMENT KARYAWAN BARU DI PT OMRON MENGGUNAKAN ALGORITMA NAIVE BAYES
SKRIPSI
Oleh : AGUS PRIANTO
311410027
PROGRAM STUDI TEKNIK INFORMATIKA SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI 2018
KLASIFIKASI REKRUITMENT KARYAWAN BARU DI PT OMRON MENGGUNAKAN ALGORITMA NAIVE BAYES
SKRIPSI
Diajukan sebagai salah satu syarat untuk menyelesaikan Program Strata Satu (S1) pada Program Studi Tenik Informatika
Oleh : AGUS PRIANTO
311410027
PROGRAM STUDI TEKNIK INFORMATIKA SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI 2018
iv
SURAT PERNYATAAN PUBLIKASI KARYA ILMIAH
Dengan ini saya yang bertandatangan di bawah ini,
Nama : AGUS PRIANTO
NIM : 311410027
Perrguruan Tinggi : STT Pelita Bangsa Program Studi : Teknik Informatika
Dengan ini memberikan ijin kepada pihak Sekolah Tinggi Teknologi Pelita Bangsa Hak Bebas Royalti Non-Ekslusif atas karya ilmiah penulis.
Pihak Sekolah Tinggi Teknologi Pelita Bangsa berhak menyimpan, mengelola, mendistibusikan atau mempublikasikan di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari penulis selama tetap mencantumkan nama penulis sebagai penulis atau pencipta karya ilmiah.
Cikarang, 28 Oktober 2018 Yang Menyatakan,
v ABSTRAK
Salah satu kunci utama dalam menciptakan Sumber Daya Manusia (SDM) yang profesional adalah terletak pada proses rekrutmen, seleksi, training and
development calon tenaga kerja. Salah satu kewajiban dalam sebuah organisasi dan
perusahaan-perusahaan yaitu harus melakukan penyaringan untuk anggota atau para pekerja yang baru, maka dari itu penelitian ini menentukan calon karyawan baru yang layak diterima di PT Omron Manufacturing of Indonesia dengan menerapkan metode naive bayes dalam seleksi calon karyawan baru. Pada penelitian ini menerapkan metode naive bayes untuk menentukan nilai kepastian yang dihasilkan dengan metode naive bayes. Pengujian yang dilakukan dengan menggunakan metode algoritma naive bayes dalam seleksi perekrutan karyawan baru yang layak diterima dan tidak layak diterima. Hasil pengujian dengan menggunakan metode confusion matrix diperoleh akurasi dengan perbandingan data 90 : 10 adalah menghasilkan akurasi 90,91%.
vi ABSTRACT
One of the main keys in creating professional human resources (HR) lies in the process of recruitment, selection, training and development of prospective workers. One of the obligations in an organization and companies is that they have to do screening for new members or workers, therefore this study determines prospective new employees who are eligible to be accepted at PT Omron Manufacturing of Indonesia by applying the Naive Bayes method in the selection of new prospective employees . In this study applying the Naive Bayes method to determine the certainty value produced by the Naive Bayes method. Naive bayes is a simple probabilistic based prediction technique based on the application of Theorema Bayes with a strong assumption. The test results using the confusion matrix method obtained accuracy with a 90: 10 data comparison is to produce an accuracy of 90.91%.
vii
KATA PENGANTAR
Dengan memanjatkan puji dan syukur kehadirat Allah SWT atas segala Rahmat, Taufiq, serta Hidayah-Nya sehingga penulis dapat menyelesaikan Skripsi ini dengan judul “Klasifikasi Rekruitment Karyawan Baru PT Omron Menggunakan Algoritma Naive Bayes”. Yang merupakan syarat dalam menyelesaikan Program Studi Sl pada Program Studi Teknik Informatika, Sekolah Tinggi Teknologi Pelita Bangsa.
Selama penulisan skripsi ini penulis mendapat banyak bantuan dan bimbingan dari berbagai pihak, untuk itu pada kesempatan ini penulis mengucapkan terima kasih yang sebesar-besarnya. pada :
1. Aswan Supriyadi Sunge, S.E, M.Kom., selaku Ketua Program Studi Teknik Informatika Sekolah Tinggi Teknologi Pelita Bangsa.
2. Dr. Ir. Supriyanto, M.P., selaku Ketua Sekolah Tinggi Teknologi Pelita Bangsa. 3. Bapak Yoga Religia, S.Kom, M.Kom selaku Dosen Pembimbing I.
4. Bapak Ir. Nanang Tedi, MT. selaku Dosen Pembimbing II.
5. Ayah dan Ibu saya telah banyak memberikan dukungan maupun do'a kepada saya sehingga semua dapat berjalan dengan lancar.
6. Seluruh Dosen Teknik Informatika.
7. Teman-teman STT Pelita Bangsa angkatan 2014.
8. Semua pihak yang telah menbantu penulis dalam menyelesaikan Skripsi. Penulis sadar bahwa tentunya dalam penulisan skripsi ini masih banyak terdapat kekurangan untuk itu saran dan kritik dari pembaca yang sifatnya membangun sangat diharapkan, demi pengembangan kemampuan penulis ke depan.
viii DAFTAR ISI
LEMBAR PERSETUJUAN ... Error! Bookmark not defined.
LEMBAR PENGESAHAN ... i
SURAT PERNYATAAN KEASLIAN SKRIPSI .. Error! Bookmark not defined. SURAT PERNYATAAN PUBLIKASI KARYA ILMIAH ... iv
ABSTRAK ... v
KATA PENGANTAR ... vii
DAFTAR ISI ... viii
DAFTAR GAMBAR ... x DAFTAR TABEL ... xi BAB 1 PENDAHULUAN ... 1 1.1 Latar belakang ... 1 1.2 Identifikasi Masalah ... 3 1.3 Batasan Masalah ... 3 1.4 Rumusan Masalah ... 3 1.5 Tujuan Penelitian ... 4 1.6 Manfaat Penelitian ... 4 1.7 Sistematika Penulisan ... 5
BAB II PENELITIAN TERDAHULU DAN TINJAUAN PUSTAKA .... 6
2.1 Penelitian Terdahulu ... 6
2.1.1 Kajian jurnal pertama ... 6
2.1.2 Kajian jurnal kedua ... 7
2.1.3 Kajian jurnal ketiga ... 7
2.1.4 Kajian jurnal keempat ... 8
2.1.5 Kajian jurnal kelima ... 8
2.1.6 Kajian jurnal keenam ... 9
2.1.7 Kajian jurnal ketujuh ... 10
2.2 Tinjauan Pustaka ... 11
2.2.1 Perekrutan karyawan di PT Omron ... 11
ix 2.2.3 Klasifikasi ... 14 2.2.4 Naive Bayes ... 15 2.2.5 Confusion matrix ... 18 2.2.6 Split validation ... 20 2.3 Kerangka Pemikiran ... 22
BAB III METODE PENELITIAN ... 24
3.1 Instrumental Data ... 24
3.1.1 Perangkat Lunak (Software) ... 24
3.1.2 Perangkat Keras (Hardware) ... 24
3.2 Jenis Data ... 25
3.3 Metode Pengumpulan Data ... 26
3.4 Model yang diusulkan ... 26
3.5 Evaluasi dan Validasi ... 27
BAB IV HASIL DAN PEMBAHASAN ... 29
4.1 Langkah Perhitungan ... 29
4.1.1 Model dan Metode yang diusulkan ... 29
4.2 Contoh perhitungan ... 30
4.3 Hasil Pengujian ... 37
4.4 Analisa Hasil Pengujian ... 38
BAB V KESIMPULAN DAN SARAN ... 39
5.1 Kesimpulan ... 39
5.2 Saran ... 39
DAFTAR PUSTAKA ... i
x
DAFTAR GAMBAR
Gambar 2.1 Tahapan Knowledge Discovery in Database ... 12 Gambar 2.2 Kerangka Pemikiran ... 22 Gambar 3.1 Model pengujian ... 26
xi
DAFTAR TABEL
Tabel 2.1 Tabel Confusion matrix ... 19
Tabel 2.2 Tabel Split Validation ... 21
Tabel 3.1 Pembagian Data ... 27
Tabel 3.2 Evaluasi Pengujian Akurasi Naive Bayes ... 28
Tabel 4.1 Tabel Data Training ... 30
Tabel 4.2 Tabel Data Testing ... 31
Tabel 4.3 Nilai pengujian manual ... 35
1 1 BAB I PENDAHULUAN
1.1 Latar belakang
Era globalisasi ini penuh dengan tantangan dan kesulitan-kesulitan di masa yang akan datang yang harus dihadapi oleh masyarakat dan negara berkembang ini. Namun, suatu perusahaan tetap dituntut untuk efektif dalam pengelolaan perusahaannya, agar perusahaan itu dapat bersaing dengan perusahaan lain atau mengikuti perubahan yang terjadi, serta guna mencapai tujuan perusahaan itu sendiri. Dalam aset perusahaan yang paling berharga adalah sumber daya manusianya. Salah satu upaya yang dapat dilakukan perusahaan adalah melakukan seleksi terhadap calon karyawannya. Seleksi dilakukan untuk memilih calon karyawan yang paling memenuhi kriteria yang dicari ditetapkan perusahaan dari sekian banyak pelamar yang ada untuk menempati suatu posisi tertentu dalam perusahaan guna mencapai tujuan perusahaan.[1]
Saat ini persaingan untuk mendapatkan pekerjaan semakin ketat, dimana lapangan kerja yang tersedia semakin sedikit dan proses perekrutan dan seleksi karyawan semakin ketat, sehingga kesempatan orang untuk memperoleh pekerjaan semakin sulit. Kemudian dapat dikatakan lebih lanjut bahwa tujuan utama dari proses rekruitmen dan seleksi pegawai adalah untuk mendapatkan orang yang tepat bagi suatu jabatan tertentu, sehingga orang tersebut mampu bekerja secara optimal dan dapat bertahan di perusahaan dalam jangka waktu yang lama. Meskipun
2
tujuannya terdengar sangat sederhana, proses rekruitmen tersebut sangatlah kompleks, memakan waktu yang lama dan sangat terbuka peluang untuk melakukan kesalahan dalam menentukan orang yang tepat.[2]
Pada akhirnya, strategi seleksi yang turut mempertimbangkan kecocokan antara individu dengan perusahaan, disamping faktor pengetahuan, keterampilan, dan kemampuan yang dimiliki oleh calon karyawan akan memberikan hasil yang positif bagi perusahaan. Semakin efektif proses seleksi, semakin besar kemungkinan untuk mendapatkan pegawai yang tepat bagi perusahaan. Selain itu, seleksi yang efektif akan berpengaruh langsung pada prestasi kerja karyawan dan kinerja finansial perusahaan. Dengan demikian maka pengembangan dan perencanaan system seleksi merupakan hal penting untuk dilaksanakan setiap perusahaan supaya proses yang berlangsung cukup lama dan memakan biaya tersebut tidak sia-sia.[3]
Pada penelitian ini digunakan metode Naive Bayes Calssifier yang sering disebut sebagai Naive Bayes Classifier. Naive Bayes Calssifier menggunakan teori probabiliti sebagai dasar teori. Metode Naive Bayes Classifier juga memiliki kinerja yang baik terhadap pengklasifikasian data dokumen yang mengandung angka maupun teks. Penelitian ini diharapkan mampu menghasilkan klasifikasi yang akurat agar dapat di jadikan bahan penelitian lebih lanjut karena tingkat keakurasi yang tinggi.[4]
3
Dengan permasalahan yang terjadi, maka perlu melakukan uji kelayakan perekrutan karyawan baru di PT Omron dengan mengunakan metode naive bayes untuk mendapatkan karyawan yang tepat bagi perusahaan.
1.2 Identifikasi Masalah
Berdasarkan latar belakang diatas maka identifikasi masalah yang pada di penelitian ini adalah belum adanya pemodelan yang digunakan untuk klasifikasi proses perekrutan calon karyawan di PT Omron menggunakan metode naive bayes. 1.3 Batasan Masalah
Batasan masalah ini berfungsi untuk membatasi persoalan yang dihadapi agar tidak menyimpang dari yang diinginkan. Adapun batasan masalahnya sebagai berikut : klasifikasi perekrutan menggunakan algoritma naive bayes ini di buat hanya untuk perekrutan calon karyawan baru PT Omron untuk memperoleh
accuracy,precission dan recall.
1.4 Rumusan Masalah
Berdasarkan latar belakang dan identifikasi masalah yang telah disampaikan, maka perlu di rumuskan suatu masalah yang akan di diselesaikan pada penelitian ini : Bagaimana membuat model klasifikasi perekrutan calon karyawan di PT Omron sesuai kebutuhan dan kriteria perusahaan menggunakan algoritma naive
4
1.5 Tujuan Penelitian
Dari rumusan masalah yang diatas, maka tujuan penelitian ini adalah membuat model klasifikasi perekrutan calon karyawan di PT Omron Manufacturing of Indonesia dengan metode naive bayes untuk memperoleh accuracy ,precission dan recall.
1.6 Manfaat Penelitian
Dari penelitian ini diharapkan dapat diambil manfaatnya bagi pihak tertentu, yaitu :
1. Bagi Mahasiswa
Dapat memberikan solusi dalam perekrutan karyawan di PT Omron, supaya dalam perekrutan karyawan lebih baik dan lebih tepat dengan kriteria yang dibutuhkan.
2. Bagi Prodi Teknik Informatika
Sebagai acuan untuk melakukan penelitian dengan topik yang serupa maupun sebagai bahan acuan untuk melakukan penelitian lebih lanjut. 3. Bagi Perusahaan
Menambah pengetahuan dan pengalaman yang didapat selama di bangku perkuliahan
5
1.7 Sistematika Penulisan
Sistematika dalam penulisan skripsi ini, disusun dengan urutan sebagai berikut :
BAB 1 PENDAHULUAN
Bab satu berisi penjelasan mengenai latar belakang masalah, identifikasi masalah, rumusan masalah, batasan masalah, tujuan dan manfaat, serta sistematika penulisan yang di maksudkan agar dapat memberikan gambaran tentang urutan pemahaman dalam menyajikan laporan ini.
BAB 2 PENELITIAN TERDAHULU DAN TINJAUAN PUSTAKA Bab dua membahas mengenai landasan teori yang digunakan untuk menganalisis masalah dan teori yang dipakai dalam mengolah data penelitian yaitu teori mengenai klasifikasi naive bayes dan data mining dan lain-lain.
BAB 3 METODE PENELITIAN
Tahapan penelitian terdiri dari pengumpulan data dari perusahaan , membuat fungsi klasifikasi, dan evaluasi hasil.
BAB 4 HASIL DAN PEMBAHASAN
Pada tahap ini membahas tentang pembahasan langkah perhitungan dari data, jenis data, metode pengumpulan data, model yang diusulkan, dan evaluasi dari hasil perhitungan.
BAB 5 KESIMPULAN DAN SARAN
Bab ini menjelaskan tentang kesimpulan yang diperoleh dari hasil analisis metode naive bayes dan kesimpulan dari hasil perhitungan.
6 2 BAB II
PENELITIAN TERDAHULU DAN TINJAUAN PUSTAKA
2.1 Penelitian Terdahulu
Pada penelitian terdahulu terdapat 7 kajian jurnal yang di bahas adalah sebagai berikut :
2.1.1 Kajian Jurnal Pertama
Pada jurnal Burham Af,Noor Akhmad S,Teguh Bharata A. Pada tahun 2015 dengan judul Analisis perbandingan tingkat akurasi algoritma naive bayes classifier dengan tingkat correlated-naive bayes classifier. Penelitian ini Membahas Metode yang digunakan untuk membandingkan tingkat akurasi algoritma Naïve Bayes
Classifier dengan Correlated-Naïve Bayes Classifier adalah dengan melakukan
pengujian akurasi beberapa data set. Pada paper ini, data set yang digunakan diambil dari uji repository yaitu : data set iris, data set balance-scale, data set haberman, dan data set servo. Pengujian algoritma Naïve Bayes Classifier dan
Correlated-Naïve Bayes Classifier terhadap data set menggunakan metode
stage-fold. Adapun kesimpulan yang diperoleh Hasil dari pengujian membuktikan bahwa
yang dilakukan terhadap data pengujian hasil yang didapatkan bahwa tingkat akurasi algoritma Correlated-Naive bayes classifier adalah 94.22 dan hasil akurasi
Naive bayes classifier adalah 91.77. Jadi membuktikan bahwa algoritma
Correlated-Naive bayes classifier lebih tinggi akurasi nya di bandingkan dengan
7
2.1.2 Kajian Jurnal Kedua
Penelitian Niken Puji A,Kusrini,M Rudyanto A. Pada tahun 2015 dengan judul “Analisis prediksi tingkat ketidakdisiplinan siswa menggunakan algoritma
Naive bayes classifier “. Penelitian ini membahas tentang memprediksi siswa yang
berpotensi melakukan kedisiplinan dengan menggunakan algoritma Naive bayes
classifier(NBC). Penelitian yang akan dilakukan pemilihan atribut menggunakan
metode information gain. Adapun Kesimpulan yang diperoleh dari pengujian pada data siswa berjuamlah 895 record dengan konduksi reduki atribut sebesar 75% diurutkan dari nilai information gain(IG) yang terendah dengan perbandingan data training sebesar 75% dan data testing 25% menghasilkan akurasi sebesar 79,01% [5].
2.1.3 Kajian Jurnal Ketiga
Penelitian Novia B,Lian Aga A, Albertus Yoki A. Pada tahun 2016 dengan judul Penerapan Algoritma Naive bayes dan Natural language processing untuk mengklasifikasi jenis berita pada arsip pemberitaan. Penelitian ini membahas tentang mengklasifikasi tentang berita yang memudahkan dan membantu mengarsipkan berita /artikel yang telah di terbitkan . Dari percobaan yang dilakukan ,penentuan sebuah kategori pengarsipan didapat dari inputan teks yang dimasukan kedalam form inputan. Kemudian system akan mengolah data yang dimasukan pengguna dan memberikan solusi kategori dengan nilai akurasi lebih dari 82% sehingga pengguna dapat dengan mudah mengarsipkan dokumen(file) tepat dengan kategorinya[6].
8
2.1.4 Kajian Jurnal Keempat
Penelitian Erfan Karyadiputra pada tahun 2016 dengan judul analisis Algoritma Naive bayes klasifikasi status kesejahteraan rumah tangga keluarga binaan sosial. Penelitian ini membahas tentang mengklasifikasi status kesejahteraan rumah tangga miskin yaitu rumah tangga sangat miskin (RTSM) dan rumah tangga miskin (RTM) dengan metode confusion matrix maka dari hasil penelitian yang dilakukan dari tahap awal hingga pengujian, dan hasil perbandingan dapat disimpulkan bahwa model yang terbentuk dengan menggunakan algoritma Naive
bayes menghasilkan akurasi yang cukup baik yaitu sebesar 85,80 % berdasarkan
kehandalan dalam klasifikasi berupa nilai AUC yang didapat dari algoritma Naive
bayes adalah 0.930 sehingga tergolong sebagai Excellent Classification sehingga dapat disimpulkan algoritma Naïve Bayes dapat diterapkan untuk melakukan klasifikasi status kesejahteraan rumah tangga.[4]
2.1.5 Kajian Jurnal Kelima
Penelitian Lailatul M. C,Nurul Hidayat,Inu L.wibowo,Imam Muklas pada tahun 2016 yang berjudul Pemilihan jenis asuransi berdasarkan demografi calon pemegang polis dengan metode Naive bayes classifier. Penelitian ini membahas tentang bagaimana menentukan jenis asuransi yang tepat menggunakan task dalam data mining untuk menggali informasi yang berkaitan dengan kebutuhan produk asuransi bagi calon nasabah .Metode yang digunakan untuk klasifikasi adalah Naive
bayes Dari hasil pengujian memperlihatkan hasil eksperimen dengan perbagai
9
Bayes Classifier diperoleh ketika menggunakan 90% data latih dan 10% data uji
dengan rata-rata tingkat presisi sebesar 94.81% dan akurasi sebesar 94.12%. Dari hasil percobaan di atas, dapat disimpulkan bahwa Naïve Bayes Classifier dapat mampu membantu merekomendasikan produk asuransi yang tepat kepada calon nasabah berdasarkan ciri demografinya.[7]
2.1.6 Kajian Jurnal Keenam
Pada penelitian sebelumnya yang dilakukan oleh Ulfa Pauziah yang berjudul analisis penentuan karyawan terbaik menggunakan metode algoritma
naive bayes pada tahun 2017 . Penelitian ini membahas tentang mengukur tingkat
akurasi dari kajian algoritma naive bayes dalam penentuan karyawan terbaik di PT. XYZ. Pengujian dilakukan dengan mengukur kinerja algoritma tersebut menggunakan bantuan aplikasi weka, dimana dilakukannya dua pengujian. Pertama pengujian dengan Cross Validation dan yang kedua dengan Confusion Matrix serta Kurva ROC.Adapun kesimpulan yang diperoleh dari hasil perhitungan algoritma
naive bayes dengan menggunakan bantuan tool weka didapatkan hasil bahwa 98,57
% algoritma naïve bayes dapat membantu dalam pengambilan keputusan pada penentuan karyawan terbaik, sedangkan 1,4286% tidak dapat membantu untuk pengambilan keputusan. Model yang telah dibentuk diuji tingkat akurasinya dengan memasukan data uji yang berasal dari data training. Karena data yang didapat dalam penelitian ini setelah proses preprocessing hanya 70 data maka digunakan metode cross validation untuk menguji tingkat akurasi. Untuk nilai akurasi model
10
untuk metode naïve bayes sebesar 98,57 %, Selain itu dalam penelitian ini diuji juga dengan menggunakan confution matrix dan kurva ROC.[1]
2.1.7 Kajian Jurnal Ketujuh
Pada penelitian yang dilakukan oleh Mihuandayani,Eko feriyanto,Syahham dan Kusrini yang berjudul “Opinion Mining pada komentar twitter E-KTP menggunakan Naive bayes Classifier“ pada tahun 2018. Penelitian ini membahas tentang twitter menjadi salah satu media sosial yang digunakan untuk mengutarakan opini tentang berbagai isu atau topik yang sedang tren melalui kolom tweet. Isu terkait dengan Electronic Kartu Tanda Penduduk (E-KTP) sempat menjadi topik yang banyak dikomentari oleh pengguna akun twitter. Adapun metode yang digunakan untuk melakukan opinion mining yaitu Naïve Bayes
Classifier. Penelitian ini menjelaskan tahapan yang dilakukan dalam opinion
mining yaitu text processing, feature extraction dan klasifikasi menggunakan Naïve Bayes. Hasil klasifikasi yang diperoleh melalui data training, dilakukan pengujian dengan data testing. Penelitian ini dalam melakukan opinion mining menerapkan algoritma Naïve Bayes Classifier yang digunakan dalam melakukan klasifikasi untuk topik E-KTP. Klasifikasi dengan naïve Bayes dibagi dalam tiga target fitur yaitu kelas positif, kelas negatif dan kelas netral. Hasil yang diperoleh melalui pengujian sistem pada empat kelompok tweet menghasilkan tingkat akurasi sebesar 89,67 %[8]
11
2.2 Tinjauan Pustaka
Kajian pustaka adalah proses umum yang kita lalui untuk mendapatkan teoriter dahulu. Berikut beberapa tinjauan pustaka dan teori yang terdahulu.
2.2.1 Perekrutan Karyawan di PT Omron
PT. Omron Manufacturing of Indonesia adalah salah satu perusahaan Omron Corporation Japan yang terdepan dan terkemuka dalam Industri sistem kontrol otomasi yang berlokasi di EJIP Industrial Park, Cikarang, Bekasi, Jawab Barat. PT. Omron Manufacturing of Indonesia telah lebih dari 25 tahun beroperasi di Indonesia sebagai produsen global untuk relay dan Switch dan terus tumbuh dan berkembang dengan mendirikan pabrik otomasi yang memproduksi Sensor, Timer dan Counter serta memberikan solusi bisnis menyeluruh untuk otomasi Industri. PT. Omron Manufacturing of Indonesia juga dikenal sebagai perusahaan yang mempelopori dan mempekerjakan penyandang disabilitas sebagai bagian dari komitmen untuk menghormati semua orang. Dalam menghasilkan produk yang berkualitas dan bermutu tinggi tentunya diperlukan desain perencanaan, organisasi dan manajemen yang lebih baik. Selain itu fasilitas kerja menjadi faktor terpenting didalam menunjang keberhasilan.
2.2.2 Data mining
Data Mining disebut juga Knowledge Discovery in Database (KDD)
didefenisikan sebagai ekstraksi informasi potensial, implisit dan tidak dikenal dari sekumpulan data. Proses Knowlegde Discovery in Database melibatkan hasil proses data mining (proses pengekstrak kecenderungan suatu pola data), kemudian mengubah hasilnya secara akurat menjadi informasi yang mudah dipahami (Sri
12
Andayani,2010). Pemanfaatan dari data mining sendiri bisa dilihat dari dua sudut pandang, baik sudut pandang komersial dan sudut pandang keilmuan. Dari sudut pandang komersial, data mining bisa digunakan untuk menangani adanya peledakan dari volume data. Dengan melihat bagaimana menyimpannnya, mengekstraknya dan memanfaatkannya. Tentunya berbagai ilmu komputasi dapat untuk menghasilkan informasi yang dibutuhkan.[9]
Gambar 2.1 Tahapan Knowledge Discovery in Database
Gambar 2.1 Menjelaskan tentang proses atau tahapan Knowledge Discovery
in Database ( KDD) mempresentasikan pengetahuan dalam bentuk yang mudah di
pahami pengguna. Data Data Target ... ... Pengetahuan Pilihan Pemrosesan Merubah Data Mining Evaluasi Pre-pemrosesan
Data yang diubah Pola Data
13
Tahapan-tahapan proses KDD
1. Data Selection
Menciptakan himpunan data target , pemilihan himpunan data, atau memfokuskan pada subset variabel atau sampel data, dimana penemuan (discovery) akan dilakukan. Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/ Cleaning
Pemprosesan pendahuluan dan pembersihan data merupakan operasi dasar seperti penghapusan noise dilakukan. Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Pencarian fitur-fitur yang berguna untuk mempresentasikan data bergantung kepada goal yang ingin dicapai. Merupakan proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data
mining. Proses ini merupakan proses kreatif dan sangat tergantung pada jenis
14
4. Data mining
Pemilihan tugas data mining; pemilihan goal dari proses KDD misalnya klasifikasi, regresi, clustering, dan lain-lain. Pemilihan algoritma data mining untuk pencarian (searching). Proses data mining yaitu proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/ Evaluation
Penerjemahan pola-pola yang dihasilkan dari data mining. Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya.
2.2.3 Klasifikasi
Klasifikasi merupakan bagian dari algoritma data mining, klasifikasi ini adalah algoritma yang menggunakan data dengan target (class/label) yang berupa nilai kategorikal/nominal. Proses klasifikasi didasarkan pada empat komponen mendasar, yaitu Kelas (Class), Prediktor (Predictor), Pelatihan dataset (Training
dataset),Dataset Pengujian (Testing Dataset).Knowledge Discovery in Database
(KDD) merupakan sebuah proses dengan beberapa tingkatan, tidak sepele, interaktif dan berulang untuk identifikasi pola yang dipahami, sah, baru dan secara
15
potensial berguna mulai dari sekumpulan data yang sangat besar . KDD dikarakteristikkan sebagai sebuah proses yang terdiri dari beberapa tahap operasional : Preprocessing, Data Mining dan Post Processing(Kardianawati, Studi, Informasi, Dian, & Bayes, 2018).
2.2.4 Naive Bayes
Naive bayesian klasifikasi adalah suatu klasifikasi berpeluang sederhana
berdasarkan aplikasi teorema Bayes dengan asumsi antar variabel penjelas saling bebas (independen). Dalam hal ini, diasumsikan bahwa kehadiran atau ketiadaan dari suatu kejadian tertentu dari suatu kelompok tidak berhubungan dengan kehadiran atau ketiadaan dari kejadian lainnya. Naive Bayesian dapat digunakan untuk berbagai macam keperluan antara lain untuk klasifikasi dokumen, deteksi spam atau filtering spam, dan masalah klasifikasi lainnya. Dalam hal ini lebih disorot mengenai penggunaan teorema Naive Bayesian untuk spam filtering[2].
Teorema bayes diformulasikan sebagai berikut (Han, et, al, 2012):
P(H|X)=𝑃(𝐻)𝑃(𝐻)
𝑃(𝑋) (2.1)
Dimana :
X : Data dengan class yang belum diketahui atau Evidence. Digambarkan dengan
ukuran yang dibuat dari sejumlah n atribut
H : Hipotesis data tuple X yang termasuk didalam class tertentu.
16
P(X|H) : Probabilitas hipotesis X berdasarakan kondisi hipotesis H.
P(H) : Probalitas hipotesis H(Prior Probality).
P(X) : Probabilitas dari X
Untuk menjelaskan teorema Naïve Bayes, perlu diketahui bahwa proses dari klasifikasi membutuhkan sejumlah petunjuk untuk menetukan kelas yang sesuai dengan sampel yang dianalisis, sehinga teorema bayes diatas disesuaikan dengan :
P(Ci| X) = 𝑃(𝐶𝑖)𝑃(𝐶𝑖)
𝑃(𝑋) (2.2)
Disini X mempresentasikan vector masukan yang berisi fitur, sedangkan Ci mempresentasikan kelas label, dengan asumsi bahwa nilai variable dalam kelas saling independen yang kuat (naïve) satu dengan yang lainya maka :
P(X|Ci)= ∏𝑛𝑘=1𝑃(𝑋𝑘|𝐶𝑖)
=Ci XCiX … X PCi (2.3)
Dikarenakan nilai P(X) dalam setiap kelas bernilai konstan, maka model persamaan Naïve Bayes untuk klasifikasi dapat disederhanakan menjadi :
17
Laplation Correction digunakan agar kemungkinan probalitas yang dimaksud tidak ada yang bernilai 0. Rumus Laplacion correction dalam kasus ini adalah sebgai berikut :
P(Ci)= 𝑁 𝑖𝑘+𝑃
𝑁𝑖+𝑝.𝑁𝑘 (2.5)
Dimana Nik merupakan jumlah kejadian yang muncul didalam kolom k dari baris
i pada data training, Ni adalah jumlah kemunculan kejadian pada data training
dari kelas Ci, sedangkan Nk adalah jumlah kejadian yang muncul pada kolom k yang terdapat dalam data training, dan p merupakan Arbitrary Probality, disini nilai p =1.
Langkah Penyelesaian Naïve Bayes
Adapun alur dari metode Naive Bayes adalah sebagai berikut : 1. Mulai.
2. Baca data training.
a. Hitung P(Ci) untuk setiap class
b. Hitung P(X|Ci) untuk setiap kriteria dan setiap kelas c. Cari P(X|Ci) yang paling besar untuk menjadi kesimpulan 3. Tampilkan hasil prediksi.
18
Kelebihan Naïve Bayes /Teori Bayesian mempunyai beberapa kelebihan, yaitu: 1. Mudah untuk dipahami.
2. Hanya memerlukan pengkodean yang sederhana. 3. Lebih cepat dalam penghitungan.
4. Cepat dan efesiensi ruang.
2.2.5 Confusion Matrix
Confusion matrix merupakan salah satu metode yang dapat digunakan untuk
mengukur kinerja suatu metode klasifikasi. Pada dasarnya confusion matrix mengandung informasi yang membandingkan hasil klasifikasi yang dilakukan oleh sistem dengan hasil klasifikasi yang seharusnya. Pada pengukuran kinerja menggunakan confusion matrix, terdapat 4 (empat) istilah sebagai representasi hasil proses klasifikasi. Keempat istilah tersebut adalah True Positive (TP), True
Negative (TN), False Positive (FP) dan False Negative (FN). Nilai True Negative
(TN) merupakan jumlah data negatif yang terdeteksi dengan benar, sedangkan
False Positive (FP) merupakan data negatif namun terdeteksi sebagai data positif.
Sementara itu, True Positive (TP) merupakan data positif yang terdeteksi benar.
False Negative (FN) merupakan kebalikan dari True Positive, sehingga data positif,
namun terdeteksi sebagai data negatif.[10]
Pada jenis klasifikasi binary yang hanya memiliki 2 keluaran kelas, confusion matrix dapat disajikan seperti pada Tabel 2.1.
19
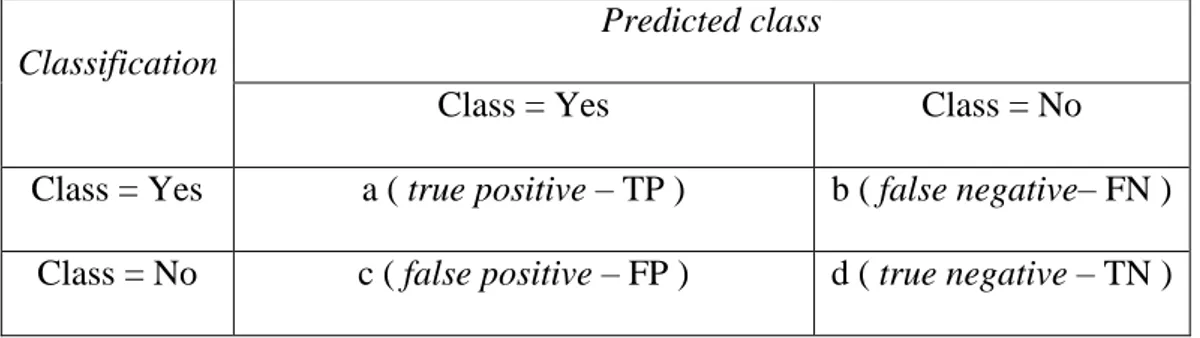
Tabel 2.1 Tabel Confusion matrix
Classification
Predicted class
Class = Yes Class = No
Class = Yes a ( true positive – TP ) b ( false negative– FN ) Class = No c ( false positive – FP ) d ( true negative – TN )
Pada tabel 2.1 berdasarkan nilai d (true negative –TN),c (false positive – FP),b (false negative – FN),a (True positive – TP) dapat diperoleh nilai akuras,presisi dan recall. Nilai akurasi menggambarkan seberapa akurasi sistem dapat mengklasifikasi data secara benar. Dengan kata lain, nilai akurasi merupakan perbandingan antara data yang terklasifikasi benar dengan keseluruhan data. Nilai akurasi dapat diperoleh dengan persamaan. Nilai presisi menggambarkan jumlah data kategori positif yang diklasifikasikan secara benar dibagi dengan total data yang diklasifikasi positif. Presisi dapat diperoleh dengan Persamaan. Sementara itu, recall menunjukkan berapa persen data kategori positif yang terklasifikasikan dengan benar oleh sistem. Nilai recall diperoleh dengan Persamaan.
Akurasi = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁
*100%
(2.6) Presisi = 𝑇𝑃 𝐹𝑃+𝑇𝑃*100%
(2.7) Recall = 𝑇𝑃 𝐹𝑁+𝑇𝑃*100%
(2.8) dimana:20
TP adalah True Positive, yaitu jumlah data positif yang terklasifikasi dengan benar oleh sistem.
TN adalah True Negative, yaitu jumlah data negatif yang terklasifikasi dengan benar oleh sistem.
FN adalah False Negative, yaitu jumlah data negatif namun terklasifikasi salah oleh sistem.
FP adalah False Positive, yaitu jumlah data positif namun terklasifikasi salah oleh sistem.
Sementara itu, pada klasifikasi dengan jumlah keluaran kelas yang lebih dari dua (multi-class), cara menghitung akurasi, presisi dan recall dapat dilakukan dengan menghitung rata-rata dari nilai akurasi, presisi dan recall pada setiap kelas.
2.2.6 Split validation
Split Validation adalah teknik validasi yang membagi data menjadi dua
bagian secara acak, sebagian sebagai data training dan sebagian lainnya sebagai
data testing. Dengan menggunakan Split Validation akan dilakukan percobaan
training berdasarkan split ratio yang telah ditentukan sebelumnya, untuk kemudian
sisa dari split ratio data training akan dianggap sebagai data testing. Data training adalah data yang akan dipakai dalam melakukan pembelajaran sedangkan data
testing adalah data yang belum pernah dipakai sebagai pembelajaran dan akan
berfungsi sebagai data pengujian kebenaran atau keakurasian hasil pembelajaran [10]
21
Tabel 2.2 Tabel Split Validation
Training 90 % Test 10 % Training 80 % Test 20 % Training 70 % Test 30 % Training 60 % Test 40 % Training 50 % Test 50 % Training 40 % Test 60 % Training 30 % Test 70 % Training 20 % Test 80 % Training 10 % Test 90 %
Dari tabel 2.2 tabel split validation digunakan untuk presentase data yang akan diuji dari keseluruhan data.
22
2.3 Kerangka Pemikiran
Kerangka pemikiran merupakan garis besar dari langkah - langkah penelitian yang sedang dilakukan, kerangka pemikiran dijadikan acuan untuk melakukan tahap – tahap yang sedang dilakukan dalam penelitian
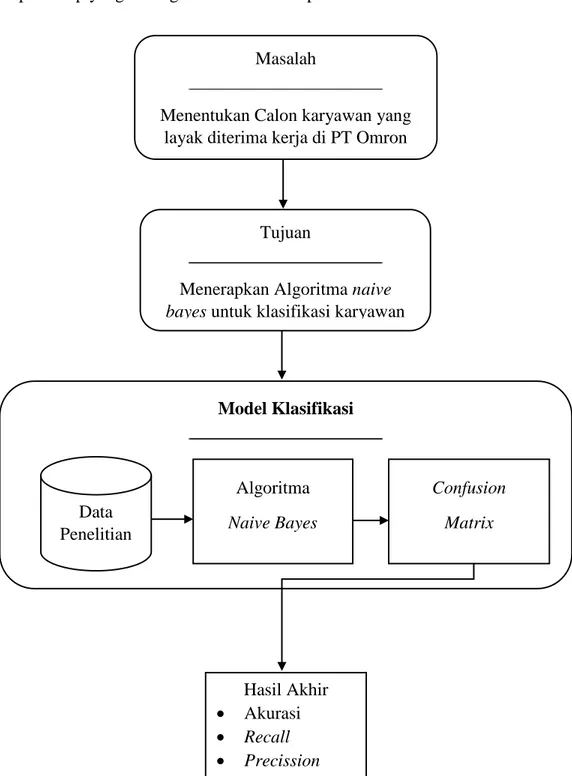
Gambar 2.2 Kerangka Pemikiran
Masalah
Menentukan Calon karyawan yang layak diterima kerja di PT Omron
Tujuan
Menerapkan Algoritma naive
bayes untuk klasifikasi karyawan
PT Omron Model Klasifikasi Hasil Akhir Akurasi Recall Precission Data Penelitian Confusion Matrix Algoritma Naive Bayes
23
Pada gambar 2.2 Menunjukan permasalahan pada penelitian ini adalah untuk melakukan klasifikasi pada data set PT Omron. Data set PT Omron ini diambil dari data perekrutan calon karyawan yang memiliki 10 atribut data. Teori-teori yang digunakan adalah algoritma naive bayes dan menggunakan metode
confusion matrix. Pengujian yang akan dilakukan dengan menggunakan software
Rapidminer untuk memperoleh akurasi dari model klasifikasi yang dibuat. Hasil pengujian berupa perbandingan antara hasil dari klasifikasi calon karyawan yang menggunakan algoritma naive bayes saja.
24 3 BAB III
METODE PENELITIAN
3.1 Instrumental Data
Pada penelitian ini akan menggunakan instrumental peralatan yang meliputi peralatan perangkat lunak dan peralatan perangkat keras. Adapun masing-masing kebutuhan dari setiap peralatan adalah sebagai berikut :
3.1.1 Perangkat Lunak (Software) 1. Sistem Operasi Windows 8
Untuk mendukung penelitian, minimal dapat menggunakan sitem operasi windows 8 dengan versi 64 bit, dikarenakan pada versi ini sistem operasi dapat menjalankan software Rapidminer.
2. Rapidminer
Dalam mengimplementasikan metode yang digunakan, maka akan digunakan software Rapidminer untuk membuat model klasifikasi. 3.1.2 Perangkat Keras (Hardware)
Selain membutuhkan perangkat lunak, ada pula perangkat keras yang dibutuhkan untuk implementasi. Adapun spesifikasi perangkat keras yang dibutuhkan yaitu :
Personal komputer dengan spesifikasi minimal CPU : Core™ i3
RAM dengan ukuran 6 GB Hardisk dengan ukuran 500 GB Layar monitor 14”
25
3.2 Jenis Data
Data yang digunakan dalam penelitian ini merupakan data sekunder. Data sekunder ini merupakan data perekrutan calon karyawan yang diperoleh dari PT Omron yang berjumlah 212 data. Data perekrutan calon karyawan yang diambil 9 atribut. Berikut atribut-atributnya adalah :
1. Nama : merupakan atribut yang berisikan nama calon karyawan. 2. Umur : merupakan data usia dalam bentuk numeric.
3. Jenis kelamin : merupakan atribut yang berisikan jenis orang. Atribut ini memiliki kategori “ laki-laki dan perempuan”.
4. Pendidikan : merupakan atribut yang memiliki kategori “sma dan smk”. 5. Tes tertulis : merupakan atribut yang berisikan hasil dari tes. Atribut ini
dalam bentuk numeric.
6. Psikotes : merupakan atribut yang berisikan hasil dari tes. Atribut ini dalam bentuk numeric.
7. Wawancara : merupakan atribut yang berisikan hasil tes dari pertanyaan.atribut ini dalam bentuk numeric.
8. Kesehatan : merupakan atribut yang berisikan keadaan fisik. Atribut ini meiliki kategori “sehat dan tidak sehat “.
9. Keterangan : merupakan atribut yang berisikan hasil dari penilaian dari hasil semua tes. Atribut ini memiliki kategori “diterima dan tidak diterima”.
Dari 9 atribut ini yang dimiliki akan digunakan untuk menentukan 1 class yaitu class “ Y”. Class “Y” ini merupakan keterangan apakah diterima atau tidak diterima di PT Omron.
26
3.3 Metode Pengumpulan Data
Data yang digunakan dalam penelitian ini merupakan data kualitatif dalam bentuk dokumentasi. Dalam pengumpulan data-data yang dibutuhkan dalam penelitian dengan menggunakan metode studi literature (Library Research). Metode studi literature ini dilakukan dengan cara mencari informasi mengenai permasalahn yang diteliti berdasarkan buku-buku, jurnal, paper atau sumber lain yang berkaitan.
3.4 Model yang diusulkan
Model yang diusulkan untuk klasifikasi menggunakan algoritma Naïve bayes adalah menggunakan model split validation. Split validation membagi data menjadi dua subset data yaitu data trainning dan data testing. Data trainning merupakan data yang digunakan untuk pelatihan, sedangkan data testing akan digunakan untuk pengujian. Adapaun untuk melihat secara lebih jelas dari model split validation dapat dilihat pada gambar 3.1
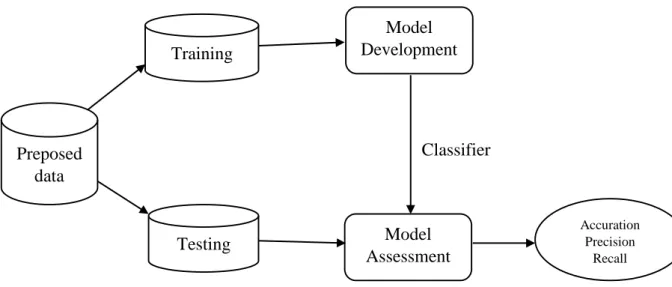
Gambar 3.1 Model pengujian
Preposed data Testing Data Training Data Model Development Model Assessment Accuration Precision Recall Classifier
27
Pada gambar 3.1 akan digunakan untuk melakukan pengujian sebanyak sepuluh kali yang masing-masing proporsi pembagian datanya dapat dilihat tabel 3.1.
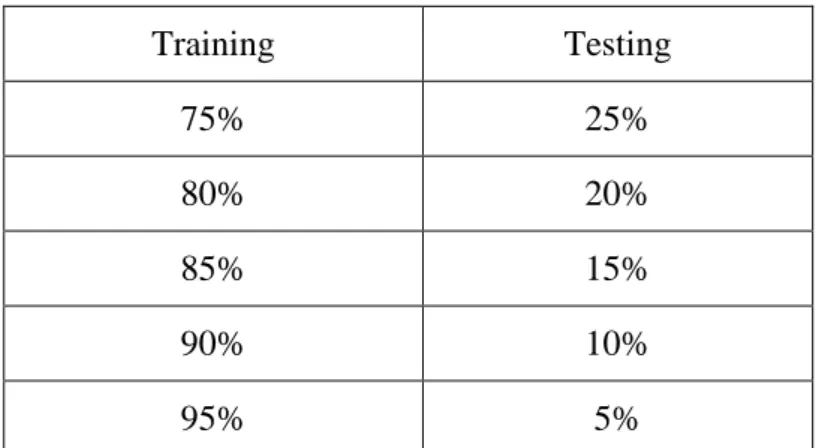
Tabel 3.1 Pembagian Data
Training Testing 75% 25% 80% 20% 85% 15% 90% 10% 95% 5%
Dari delapan kali percobaan yang dilakukan berdasarkan proporsi dari tabel 3.1 setiap hasil yang diperoleh akan ditentukan jumlahnya untuk diambil nilai rata-rata.
3.5 Evaluasi dan Validasi
Tahapan evaluasi yang dilakukan dalam penelitian ini adalah untuk memberikan penilaian dari hasil penggunaan algoritma naive bayes saja dan naive
bayes yang disertai dengan confusion matrix untuk mengklasifikasi data perekrutan
calon karyawan di PT Omron. Bagian yang akan dievaluasi adalah presentase data, jumlah data training, jumlah data testing , dan nilai akurasi yang dihasilkan. Adapaun secara keseluruhan dapat dilihat pada tabel 3.2.
28
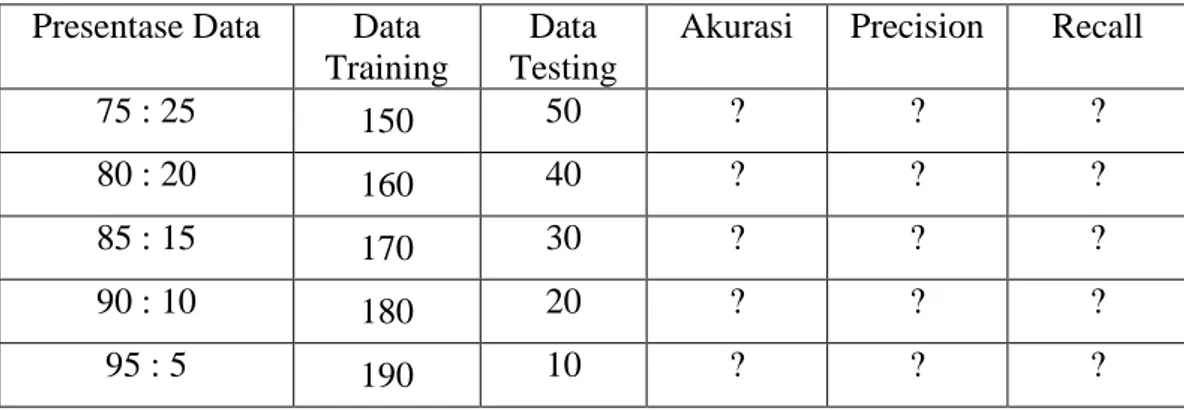
Tabel 3.2 Evaluasi Pengujian Akurasi Naive Bayes
Presentase Data Data Training
Data Testing
Akurasi Precision Recall
75 : 25 150 50 ? ? ?
80 : 20 160 40 ? ? ?
85 : 15 170 30 ? ? ?
90 : 10 180 20 ? ? ?
95 : 5 190 10 ? ? ?
Dari tabel 3.2 akan digunakan untuk validasi nilai akurasi dari algoritma
naive bayes saja. Dari nilai akurasi yang dihasilkan akan ditentukan rata-rata
akurasi pada algoritma. Kemudian akan dibandingkan dengan model yang dimiliki akurasi yang lebih tinggi untuk mengklasrifikasi data perekrutan calon karyawan di PT Omron.
29 4 BAB IV
HASIL DAN PEMBAHASAN
4.1 Langkah Perhitungan
Pada tahap ini metode yang digunakan dalam perhitungan tingkat akurasi adalah algoritma naive bayes dengan melakukan pengujian akurasi data set dan perhitungan manual. Berikut langkah metode algoritma naive bayes :
1. Membagi data set kedalam data testing dan data training.
2. Menghitung jumlah class dari klasifikasi yang sudah terbentuk yaitu class diterima dan tidak diterima untuk setiap class.
3. Menghitung jumlah kasus yang sama dari kelas yang sama X, dalam kasus
data set pada penelitian ini terdiri dari 2 class yaitu diterima dan tidak
diterima.
4. Hitung untuk setiap kelas atau atribut.
5. Setelah itu bandingkan, jika class diterima dan calss tidak diterima yang sudah dihitung lebih besar dari tidak diterima, maka hasilnya diterima dan jika class yang diterima kecil dari class tidak diterima ,maka hasilnya tidak diterima.
4.1.1 Model dan Metode yang diusulkan
Metode yang akan digunakan dalam penelitian ini adalah algoritma naive
bayes. Dalam pemodelan ini algoritma naive bayes akan dicari performance
30
Gambar 4.2 Model untuk menemukan performance algoritma
4.2 Contoh perhitungan
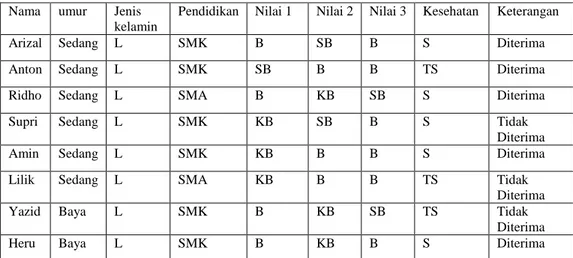
Contoh perhitungan dalam penelitian ini menggunakan sepuluh data sampel terdiri dari 9 atribut untuk menentukan sebuah class, yang mana dari sepuluh data tersebut akan digunakan untuk melakukan perhitungan algoritma Naive bayes. Adapun data kasus tersebut dapat dilihat pada tabel 4.1.
Tabel 4.1 Tabel Data Training
Nama umur Jenis kelamin
Pendidikan Nilai 1 Nilai 2 Nilai 3 Kesehatan Keterangan
Arizal Sedang L SMK B SB B S Diterima
Anton Sedang L SMK SB B B TS Diterima
Ridho Sedang L SMA B KB SB S Diterima
Supri Sedang L SMK KB SB B S Tidak
Diterima
Amin Sedang L SMK KB B B S Diterima
Lilik Sedang L SMA KB B B TS Tidak
Diterima
Yazid Baya L SMK B KB SB TS Tidak
Diterima
Heru Baya L SMK B KB B S Diterima
Data Set Processing Data Cleanning Model Naive Bayes Validation Apply Model Performance
Hasil Akurasi dan confusion matrix
31
Fitri Sedang P SMA SB B KB TS Tidak
Diterima
Yuli Sedang P SMK SB B SB S Diterima
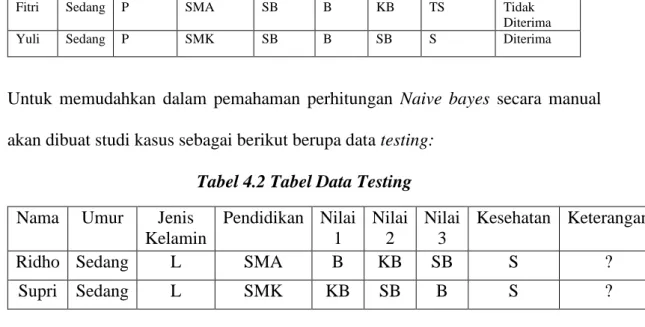
Untuk memudahkan dalam pemahaman perhitungan Naive bayes secara manual akan dibuat studi kasus sebagai berikut berupa data testing:
Tabel 4.2 Tabel Data Testing
Nama Umur Jenis Kelamin Pendidikan Nilai 1 Nilai 2 Nilai 3 Kesehatan Keterangan
Ridho Sedang L SMA B KB SB S ?
Supri Sedang L SMK KB SB B S ?
Data testing 1 : X = (Nama=Ridho, Umur=Sedang, Jenis kelamin=”L”, Pendidikan= “SMA”, Nilai 1=”B”, Nilai= “KB”, Nilai= “SB”, Kesehatan=”S”) Data testing 2 : X = (Nama=Supri, Umur= Sedang, Jenis kelamin=”L”, Pendidikan= “SMK”, Nilai 1=”KB”, Nilai= “SB”, Nilai= “B”, Kesehatan=”S”)
Berikut perhitungan manual dengan metode naive bayes dengan beberapa tahap : 1. Tahap 1 menghitung jumlah kelas atau prediksi data testing yang pertama P(Ci)
P(Diterima) = 105
212 = 0,4952
P(Tidak Diterima) = 107
212 = 0,5047
Tahap 2 menghitung jumlah kasus yang sama dengan kelas yang sama. P(X | Ci)
P(Sedang | Diterima) = 99
32
P(Sedang | Tidak Diterima) = 99
107 = 0,9252
P(Laki-laki | Diterima) = 55
105 = 0,5238
P(Laki-laki | Tidak Diterima) = 67
107 = 0,6261
P(SMA | Diterima) = 28
105 = 0,2666
P(SMA | Tidak Diterima) = 23
107 = 0,2149 P(B | Diterima) = 66 105 = 0,6285 P(B | Tidak Diterima) = 51 107 = 0,4766 P(KB | Diterima) = 16 105 = 0,1523 P(KB | Tidak Diterima) = 34 107 = 0,3177 P(SB | Diterima) = 43 105 = 0,4095 P(SB | Tidak Diterima) = 14 107 = 0,1308
33
Tahap 3 mengkalikan semua hasil dari atribut Diterima dan Tidak Diterima. P(X |Diterima)= 0,9428 * 0,5238 * 0,2666 * 0,6285 * 0,1523 * 0,4095 = 0,005160 P(X | Tidak Diterima) = 0,9252 * 0,6261 * 0,2149 * 0,4766 * 0,3177 * 0,1308
= 0,002465
Tahap 4 membandingkan nilai kelas Diterima dengan Tidak Diterima P(X | Ci * P(Ci)
P(X | Diterima) * P(Diterima) = 0,005160 * 0,4952 = 0,002555
P(X | Tidak Diterima) * P(Tidak Diterima) = 0,002465 * 0,5047 = 0,001244
2. Perhitungan dengan data testing yang kedua P(Ci)
P(Diterima) = 105
212 = 0,495
P(Tidak Diterima) = 107
212 = 0,504
Tahap 2 menghitung jumlah kasus yang sama dengan kelas yang sama. P(X | Ci)
P(Sedang | Diterima) = 99
105 = 0,9428
P(Sedang | Tidak Diterima) = 99
107 = 0,9252
P(Laki-laki | Diterima) = 55
34
P(Laki-laki | Tidak Diterima) = 67
107 = 0,6261 P(SMK | Diterima) = 77 105 = 0,7333 P(SMK | Tidak Diterima) = 84 107 = 0,7850 P(KB | Diterima) = 12 105 = 0,1142 P(KB | Tidak Diterima) = 24 107 = 0,2242 P(SB | Diterima) = 38 105 = 0,3619 P(SB | Tidak Diterima) = 25 107 = 0,2336 P(B | Diterima) = 56 105 = 0,5333 P(B | Tidak Diterima) = 40 107 = 0,3738
Tahap 3 mengkalikan semua hasil dari atribut Diterima dan Tidak Diterima pada data testing yang kedua.
P(X |Diterima) = 0,9428 * 0,5238 * 0,7333* 0,1142 * 0,3619 * 0,5333 = 0,007981
P(X | Tidak Diterima) = 0,9252 * 0,6261 * 0,7850 * 0,2242 * 0,2336 * 0,3738 = 0,008902
35
Tahap 4 membandingkan nilai kelas Diterima dengan Tidak Diterima. P(X | Ci * P(Ci)
P(X | Diterima) * P(Diterima) = 0,007981 * 0,4952 = 0,003952
P(X | Tidak Diterima) * P(Tidak Diterima) = 0,008902 * 0,5047 = 0,004492
Jadi data yang dihitung untuk nama=”Ridho”, Umur= “Sedang”, Jenis kelamin=”L”, Pendidikan = “SMA”, Nilai 1 =”B”, Nilai 2 = “KB”, Nilai 3 = “SB”, Kesehatan=”S”, hasilnya “Diterima” dengan hasil perhitngannya 0,002555.
Data testing yang kedua dengan nama = “Supri”, Umur = “Sedang”, Jenis Kelamin = “L”, Pendidikan = “SMK”, Nilai 1 =”KB”, Nilai 2 = “SB”, Nilai 3 = “B”, Kesehatan = “S”, hasilnya Tidak Diterima dengan hasil perhitungannya 0,004492. Pada tahap pertama pengujian model yang dilakukan dengan data original yang sebagian masih memiliki data kosong. Kemudian dilakukanpengujian dilakukan menggunkan algoritma naive bayes dengan validasi model klasifikasi dilakukan terhadap data testing.
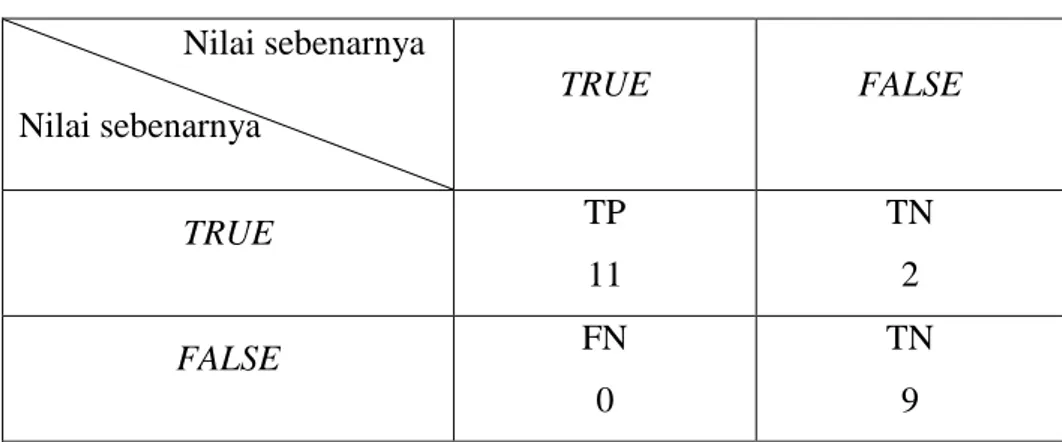
Tabel 4.3 Nilai pengujian manual Nilai sebenarnya Nilai sebenarnya TRUE FALSE TRUE TP 11 TN 2 FALSE FN 0 TN 9
36
Perhitungan manual confusion matrix : Akurasi = (𝑇𝑃+𝑇𝑁) (𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁)∗ 100% = (11+9) (11+9+2+0)∗ 100% = 20 22∗ 100% = 0,9091 *100% = 90,91% Precision = 𝑇𝑃 (𝑇𝑃+𝐹𝑃)∗ 100% = 11 11+2∗ 100% = 11 13∗ 100% = 0,8462 * 100% = 84,62% Recall = 𝑇𝑃 (𝑇𝑃+𝐹𝑁)∗ 100% = 11 (11+0)∗ 100% = 11 11∗ 100% = 1 * 100% = 100% Recall = 𝑇𝑁 (𝑇𝑁+𝐹𝑃)100% = 9 (9+2)∗ 100% = 9 11∗ 100% = 0,8182 * 100% = 81,82%
37
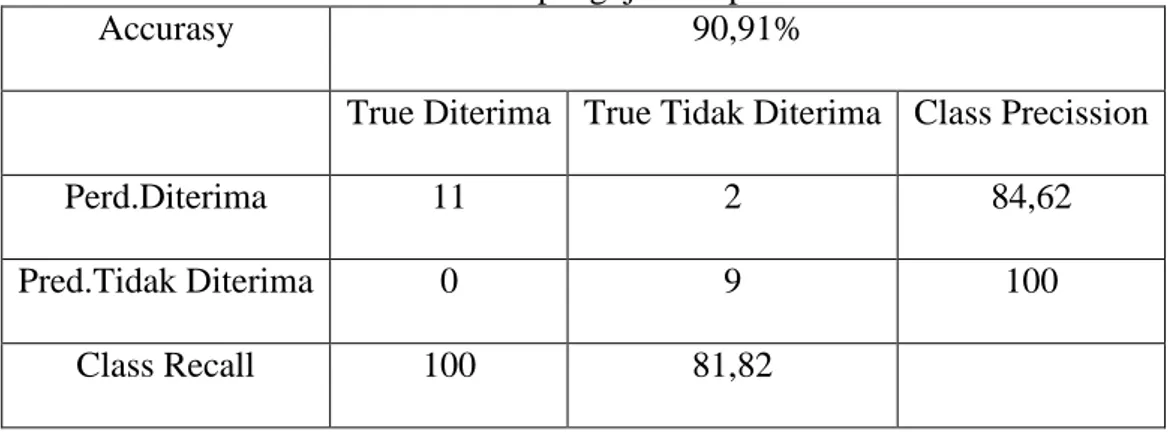
4.3 Hasil Pengujian
Uji coba dilakukan untuk mengetahui apakah perhitungan yang telah dilakukan diatas sesuai klasifikasi calon karyawan dengan metode naive bayes. Dalam uji coba yang dilakukan dengan menentukan sepuluh data testing yang telah dipilih dengan kasus yang di hitung manual yaitu dua data.
Tabel 4.4 Hasil pengujian Rapidminer
Accurasy 90,91%
True Diterima True Tidak Diterima Class Precission
Perd.Diterima 11 2 84,62
Pred.Tidak Diterima 0 9 100
Class Recall 100 81,82
Dari hasil pengujian tersebut didapatkan akurasi yang sudah cukup baik sekitar 90,91%. Pada tahap evaluasi dan validasi model klasifikasi pengujian yang dilakukan terhadap data testing dengan metode tersebut dan dilakukan dengan teknik split validation sehingga dapat dievaluasi hasilnya dengan mengukur seberapa keakuratan akurasi yang dilakukan dari beberapa percobaan tersebut menggunakan metode naive bayes. Namun sebelum melakukan percobaan tersebut ,terlebih dahulu akan dilakukan percobaan dengan mengganti split ratio. Proses akurasi dengan Rapidminer menggunakan metode naive bayes yang digunakan untuk mengklasifikasi data perekrutan calon karyawan pada penelitian ini. Pada penelitian ini untuk mengetahui nilai akurasi dari algoritma naive bayes yang digunakan untuk mengklasifikasi yang diterapkan yaitu naive bayes. Sedangkan di
38
dalam kolom testing terdapat Apply Model untuk menjalankan model naive bayes dan performance untuk mengukur performa dari model naive bayes tersebut. 4.4 Analisa Hasil Pengujian
Berdasarkan penelitian yang dilakukan, telah dihasilkan suatu pola, informasi, dan pengetahuan baru dalam proses data mining untuk klasifikasi perekrutan karyawan. Dari penelitian tersebut dihasilkan suatu pola, informasi, dan pengetahuan baru sesuai dengan tujuan data mining yaitu pola perhitungan data mining yang berisi data training dan data testing serta mencari probabilitas dari setiap atribut berdasarkan data training dan data testing untuk menghasilkan suatu informasi baru, apakah pada data perekrutan karyawan lebih banyak yang diterima atau tidak diterima. Kemudian untuk menguji tingkat keakurasiannya maka digunakan Rapidminer sebagai alat bantu dalam proses pengujian tingkat akurasi dari klasifikasi tersebut.
Dari hasil pengujian dapat diketahui tingkat akurasi dari algoritma naive
bayes menggunakan confusion matrix dengan jumlah data 80 menunjukkan bahwa
tingkat akurasinya 50%, yang terdiri dari 50% untuk data training dan 50% untuk data testing. Sedangkan untuk hasil pengujian dengan jumlah data 212 dengan perbandingan 90 : 10 menunjukkan bahwa tingkat akurasinya sebesar 90,91%. Dimana jumlah data sangat berpengaruh dalam proses pembentukan model dan proses pengujian model. Jadi semakin data training yang diuji, maka semakin besar pula hasil akurasinya.
39
5 BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan mengenai klasifikasi perekrutan karyawan di PT Omron Manufacturing of Indonesia dengan metode
naive bayes maka dapat diambil beberapa kesimpulan sebagai berikut :
1. Metode Naive Bayes yang digunakan memberikan proses penyeleksian yang cepat dan algoritma yang mudah dipahami dengan tingkat akurasi tinggi.
2. Pada penelitian ini dengan menggunakan algoritma Naive Bayes yang di lakukan sudah dilihat baik dari data yang diperoleh dengan perbandingan 90 : 10 hasil akurasinya 90,91%.
5.2 Saran
Berdasarkan hasil penelitian yang telah dilakukan mengenai klasifikasi perekrutan karyawan di PT Omron Manufacturing of Indonesia dengan metode
Naive Bayes , maka terdapat beberapa saran yang perlu diperhatikan :
1. Peneliti telah membahas penggunaan metode Naïve Bayes dalam penelitian klasifikasi perekrutan karyawan, diharapkan dalam penelitian selanjutnya dapat dibandingkan dengan memanfaatkan metode klasifikasi lainnya seperti metode C.4.5, metode nearest neighbor guna menentukan kelas berdasarkan atribut-atribut yang telah ditentukan sehingga dengan
40
menggunakan banyak metode dapat mengetahui kelebihan masing-masing metode dan metode mana yang menghasilkan nilai akurasi yang lebih baik.
i
6 DAFTAR PUSTAKA
[1] U. Fauziah, “ANALISIS PENENTUAN KARYAWAN TERBAIK MENGGUNAKAN METODE ALGORITMA NAIVE BAYES ( STUDI KASUS PT . XYZ ) Ulfa Pauziah,” no. April, pp. 94–102, 2017.
[2] A. Jamaluddin, “SISTEM PENDUKUNG KEPUTUSAN SELEKSI KARYAWAN PT . JAPFA COMFEED INDONESIA TBK CABANG KEDIRI MENGGUNKAN METODE NAIVE BAYES BERBASIS WEB Oleh : Dibimbing oleh :,” vol. 2, no. 4, pp. 1–13, 2018.
[3] B. A. Muktamar, N. A. Setiawan, T. B. Adji, J. G. No, K. Ugm, and D. I. Yogyakarta, “ANALISIS PERBANDINGAN TINGKAT AKURASI ALGORITMA NAÏVE BAYES CLASSIFIER DENGAN
CORRELATED-NAÏVE BAYES CLASSIFIER,” pp. 6–8, 2015. [4] E. Karyadiputra, S. Kom, and M. Kom, “ANALISIS ALGORITMA
NAIVE BAYES UNTUK KLASIFIKASI STATUS KESEJAHTERAAN RUMAH TANGGA KELUARGA BINAAN SOSIAL,” vol. 7, no. 4, pp. 199–208, 2016.
[5] N. P. Astuti and M. R. Arief, “ANALISIS PREDIKSI TINGKAT
KETIDAKDIPLINAN SISWA MENGGUNAKAN ALGORITMA NAÏVE BAYES CLASSIFIER ( STUDI KASUS : SMK NEGERI 1 PACITAN ),” pp. 6–8, 2015.
[6] N. Busiarli, L. A. Aditya, and A. Y. Andika, “PENERAPAN ALGORITMA NAÏVE BAYES & NATURAL LANGUAGE
PROCESSING UNTUK MENGKLASIFIKASI JENIS BERITA,” pp. 6–7, 2016.
[7] L. M. Chaira, N. Hidayat, and I. L. Wibowo, “PEMILIHAN JENIS ASURANSI,” vol. 13, pp. 11–20, 2016.
[8] E. Feriyanto, “OPINION MINING PADA KOMENTAR TWITTER E-KTP MENGGUNAKAN NAIVE BAYES CLASSIFIER,” pp. 25–30, 2018.
[9] K. A. Heryono, “Implementasi Metode Naive Bayes Untuk Klasifikasi Kredit Motor,” vol. x, no. x, pp. 10–21, 2018.
[10] D. Untari, “DATA MINING UNTUK MENGANALISA PREDIKSI MAHASISWA BERPOTENSI NON-AKTIF MENGGUNAKAN,” 2010.
1