vii ABSTRACT
Sanjaya, Albertus Agung. 2015. The Phonological Analysis of a Japanese Singer in Producing the Tense Vowels, Diphthongs, and Liquids in Live Performance Music Videos. Yogyakarta: Sanata Dharma University.
The study deals with the phonological analysis of a Japanese singer in producing tense vowels and liquids in live performance music videos. This study has two objectives. Firstly, it analyzes and describes the pronunciation process of Japanese singer in producing tense vowels, diphthongs, and liquids. Secondly, this study describes the strategies used by the Japanese singer when he produced the non-exist sounds in his first language.
The method used in this study is document analysis. The documents are from live performance videos of Japanese singer. The researcher watched and listened to the videos. After that, the researcher listed the words in the lyrics of the songs containing tense vowels, diphthongs, and liquids. The words were transcribed into standard phonetic transcription. Then, the researcher also transcribed the words into the phonetic transcription according to the pronunciation of the singer. After that, the data was classified into three parts which were the words containing tense vowels, diphthongs, and liquids.
After the researcher analyzed the videos, the results of this study showed that the Japanese singer as an EFL speaker had different pronunciation process in producing tense vowels, diphthongs, and liquids sounds. The differences were caused by the non-existence of some sounds in their first language phonological system. In producing those non-exist sounds, the results also showed that the singer frequently used two linguistic strategies. The singer used sound substitution strategy when he produced the tense vowel /i/ and liquids /r/ or /l/. Moreover, the singer used sounds simplification strategy when he produced diphthongs such as /eɪ/ and /oʊ/.
viii ABSTRAK
Sanjaya, Albertus Agung. 2015. The Phonological Analysis of a Japanese Singer in Producing the Tense Vowels, Diphthongs, and Liquids in Live Performance Music Video. Yogyakarta: Universitas Sanata Dharma.
Penelitian ini berkaitan dengan analisis fonologi dari penyanyi Jepang dalam memproduksi bunyi-bunyi vokal tegang, diftong, dan liquid dalam video-video penampilan langsung. Penelitian ini memiliki dua tujuan. Pertama, menganalisis dan menjelaskan proses pengucapan penyanyi Jepang dalam memproduksi bunyi-bunyi vokal, diftong, dan konsonan likuida. Kedua, penelitian ini menggambarkan dan mendeskripsikan strategi yang digunakan oleh penyanyi Jepang ketika ia menghasilkan bunyi-bunyi yang tidak ada dalam sistem fonologi di bahasa pertamanya.
Metode yang digunakan dalam penelitian ini adalah studi dokumen. Data-data yang digunakan adalah dari video-video penampilan langsung dari penyanyi Jepang. Peneliti mengamati dan mendengarkan video-video yang didapat. Setelah itu, peneliti menyantumkan kata-kata dalam lirik lagu yang mengandung bunyi-bunyi vokal, diftong, dan konsonan likuida. Kata-kata tersebut ditranskripsi menjadi fonetik transkripsi standar. Kemudian, peneliti juga mentranskripsi kata-kata ke dalam fonetik transkripsi sesuai dengan pengucapan penyanyi. Setelah itu, data diklasifikasikan menjadi tiga bagian yang merupakan kata-kata yang mengandung bunyi-bunyi vokal, diftong, dan konsonan likuida.
Setelah peneliti menganalisa video-video, hasil penelitian ini menunjukkan bahwa penutur Jepang yang diwakili oleh penyanyi Jepang memiliki proses pengucapan yang berbeda dalam memproduksi bunyi-bunyi vokal, diftong, dan konsonan likuida. Perbedaan tersebut disebabkan oleh tidak adanya beberapa suara dalam sistem fonologis bahasa pertama mereka. Dalam memproduksi bunyi-bunyi yang tidak ada, hasil menunjukkan bahwa penyanyi sering menggunakan dua strategi linguistik. Penyanyi menggunakan strategi pergantian bunyi ketika ia menghasilkan bunyi vokal / i / dan konsonan likuida / r / atau / l /. Selain itu, penyanyi menggunakan strategi penyederhanaan bunyi ketika ia memproduksi diftong seperti / eɪ / dan / oʊ /.
THE PHONOLOGICAL ANALYSIS OF A JAPANESE SINGER IN PRODUCING THE TENSE VOWELS, DIPHTHONGS, AND LIQUIDS
IN LIVE PERFORMANCE MUSIC VIDEOS
A SARJANA PENDIDIKAN THESIS
Presented as Partial Fulfillment of the Requirements to Obtain the Sarjana Pendidikan Degree
in English Language Education
By
Albertus Agung Sanjaya Student Number: 111214037
ENGLISH LANGUAGE EDUCATION STUDY PROGRAM DEPARTMENT OF LANGUAGE AND ARTS EDUCATION FACULTY OF TEACHERS TRAINING AND EDUCATION
SANATA DHARMA UNIVERSITY YOGYAKARTA
i
THE PHONOLOGICAL ANALYSIS OF A JAPANESE SINGER IN PRODUCING THE TENSE VOWELS, DIPHTHONGS, AND LIQUIDS
IN LIVE PERFORMANCE MUSIC VIDEOS
A SARJANA PENDIDIKAN THESIS
Presented as Partial Fulfillment of the Requirements to Obtain the Sarjana Pendidikan Degree
in English Language Education
By
Albertus Agung Sanjaya Student Number: 111214037
ENGLISH LANGUAGE EDUCATION STUDY PROGRAM DEPARTMENT OF LANGUAGE AND ARTS EDUCATION FACULTY OF TEACHERS TRAINING AND EDUCATION
SANATA DHARMA UNIVERSITY YOGYAKARTA
iv
DEDICATION PAGE
Don’t hurt others if you don’t want to be hurt (Albertus Agung Sanjaya)
Ora et labora (St. Benedict’s Rule)
Ask, and it shall be given you. Seek, and ye shall find. Knock, and it shall be opened unto you. For every one that asketh receiveth; and he that seeketh
findeth; and to him that knocketh it shall be opened. (Matthew 7: 7-8)
v
STATEMENT OF WORK’S ORIGINALITY
I honestly declare that this thesis, which I have written, does not contain the work or parts of the works of other people, except those which were cited in the quotations and the references, as a scientific paper should.
Yogyakarta, 31 July 2015
The writer
vi
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama : Albertus Agung Sanjaya Nomor Mahasiswa : 111214037
Demi pengembangan ilmu pengetahuan saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
THE PHONOLOGICAL ANALYSIS OF A JAPANESE SINGER IN PRODUCING THE TENSE VOWELS, DIPHTHONGS, AND LIQUIDS
IN LIVE PERFORMANCE MUSIC VIDEOS
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin kepada saya atau memberikan royalti kepada saya selama tetap mencatumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya,
Dibuat di Yogyakarta Pada tanggal: 26 Juni 2015
Yang menyatakan
vii ABSTRACT
Sanjaya, Albertus Agung. 2015. The Phonological Analysis of a Japanese Singer in Producing the Tense Vowels, Diphthongs, and Liquids in Live Performance Music Videos. Yogyakarta: Sanata Dharma University.
The study deals with the phonological analysis of a Japanese singer in producing tense vowels and liquids in live performance music videos. This study has two objectives. Firstly, it analyzes and describes the pronunciation process of Japanese singer in producing tense vowels, diphthongs, and liquids. Secondly, this study describes the strategies used by the Japanese singer when he produced the non-exist sounds in his first language.
The method used in this study is document analysis. The documents are from live performance videos of Japanese singer. The researcher watched and listened to the videos. After that, the researcher listed the words in the lyrics of the songs containing tense vowels, diphthongs, and liquids. The words were transcribed into standard phonetic transcription. Then, the researcher also transcribed the words into the phonetic transcription according to the pronunciation of the singer. After that, the data was classified into three parts which were the words containing tense vowels, diphthongs, and liquids.
After the researcher analyzed the videos, the results of this study showed that the Japanese singer as an EFL speaker had different pronunciation process in producing tense vowels, diphthongs, and liquids sounds. The differences were caused by the non-existence of some sounds in their first language phonological system. In producing those non-exist sounds, the results also showed that the singer frequently used two linguistic strategies. The singer used sound substitution strategy when he produced the tense vowel /i/ and liquids /r/ or /l/. Moreover, the singer used sounds simplification strategy when he produced diphthongs such as /eɪ/ and /oʊ/.
viii ABSTRAK
Sanjaya, Albertus Agung. 2015. The Phonological Analysis of a Japanese Singer in Producing the Tense Vowels, Diphthongs, and Liquids in Live Performance Music Video. Yogyakarta: Universitas Sanata Dharma.
Penelitian ini berkaitan dengan analisis fonologi dari penyanyi Jepang dalam memproduksi bunyi-bunyi vokal tegang, diftong, dan liquid dalam video-video penampilan langsung. Penelitian ini memiliki dua tujuan. Pertama, menganalisis dan menjelaskan proses pengucapan penyanyi Jepang dalam memproduksi bunyi-bunyi vokal, diftong, dan konsonan likuida. Kedua, penelitian ini menggambarkan dan mendeskripsikan strategi yang digunakan oleh penyanyi Jepang ketika ia menghasilkan bunyi-bunyi yang tidak ada dalam sistem fonologi di bahasa pertamanya.
Metode yang digunakan dalam penelitian ini adalah studi dokumen. Data-data yang digunakan adalah dari video-video penampilan langsung dari penyanyi Jepang. Peneliti mengamati dan mendengarkan video-video yang didapat. Setelah itu, peneliti menyantumkan kata-kata dalam lirik lagu yang mengandung bunyi-bunyi vokal, diftong, dan konsonan likuida. Kata-kata tersebut ditranskripsi menjadi fonetik transkripsi standar. Kemudian, peneliti juga mentranskripsi kata-kata ke dalam fonetik transkripsi sesuai dengan pengucapan penyanyi. Setelah itu, data diklasifikasikan menjadi tiga bagian yang merupakan kata-kata yang mengandung bunyi-bunyi vokal, diftong, dan konsonan likuida.
Setelah peneliti menganalisa video-video, hasil penelitian ini menunjukkan bahwa penutur Jepang yang diwakili oleh penyanyi Jepang memiliki proses pengucapan yang berbeda dalam memproduksi bunyi-bunyi vokal, diftong, dan konsonan likuida. Perbedaan tersebut disebabkan oleh tidak adanya beberapa suara dalam sistem fonologis bahasa pertama mereka. Dalam memproduksi bunyi-bunyi yang tidak ada, hasil menunjukkan bahwa penyanyi sering menggunakan dua strategi linguistik. Penyanyi menggunakan strategi pergantian bunyi ketika ia menghasilkan bunyi vokal / i / dan konsonan likuida / r / atau / l /. Selain itu, penyanyi menggunakan strategi penyederhanaan bunyi ketika ia memproduksi diftong seperti / eɪ / dan / oʊ /.
ix
ACKNOWLEDGMENTS
I thank our God and Savior Jesus Christ because of His blessing and grace, I
was allowed to write and accomplish my thesis. I also thank Him for His guidance
when I underwent the process of making the thesis.
Special thanks go to my beloved parents Veronika Noer Harijanti or Mamah
and Michael Wisnu Brata or Papah who have allowed and facilitated me to study in
this wonderful study program. I also thank them for the motivation and advices given
to me when I am down and in difficult situation.
I would also like to give my gratitude to my advisor Yuseva Ariyani Iswandari, S.Pd., M.Ed. for being so patient and meticulous in guiding and giving feedback during the process of making and finishing this thesis. I also thank Christina
Lhaksmita Anandari, S.Pd., Ed.M. as my academic advisor for eight semesters. Without her guidance and advice, I cannot finish all of the courses in this study
program. I give my gratitude to my board of examiners Agustinus Hardi Prasetyo,
S.Pd., M.A.and C. Tutyandari, S.Pd., M.Pd. for giving the useful suggestions to my thesis. In addition, I thank Drs. Barli Bram, M.Ed., Ph.D. for being meticulous in correcting my thesis. Without him my thesis would be so full of mistakes and errors.I
also thank Pak Pras for being my inspiring English teacher in my senior high school. Because of him, I am now in English Language Education Study Program.
I thank my two best senior high school friends Billy and Edo. They have
x
Gerard, Albert, Yanu, Ginong, Theo, and Malik for being my best friends in English Language Education Study Program. Besides, I thank Puzzle Group members Monic,
Angel, Nike, Yanu, and Arin. We had done our very best in the process of SPD class, so I could complete the course well and finish my study in this study program. They
also had encouraged me in doing my thesis.
Lastly, I extend my gratitude to all people who cannot be mentioned one by
one. God bless us.
xi
TABLE OF CONTENTS
TITLE PAGE ... i
APPROVAL PAGES ... ii
DEDICATION PAGE ... iv
STATEMENT OF WORK’S ORIGINALITY ... v
PERNYATAAN PERSETUJUAN PUBLIKASI ... vi
ABSTRACT ... vii
ABSTRAK ... viii
ACKNOWLEDGEMENTS ... ix
TABLE OF CONTENTS ... xi
LIST OF TABLES ... xiv
LIST OF APPENDICES ... xv
CHAPTER I. INTRODUCTION ... 1
A. Research Background ... 1
B. Research Problems ... 4
C. Problem Limitation ... 4
D. Research Objectives ... 5
E. Research Benefits ... 5
F. Definition of Terms ... 6
CHAPTER II. REVIEW OF RELATED LITERATURE ... 9
A. Theoretical Description ... 9
1. Phonological Analysis ... 9
a. Sound Substitution ... 11
b. Sound Deletion ... 11
c. Sound Simplification ... 12
xii
e. Insertion ... 13
2. Vowels ... 13
a. Diphthongs ... 14
b. Tense ... 14
c. Lax ... 14
3. Liquids ... 14
a. Trill ... 15
b. Flap ... 15
4. EFL Speakers ... 15
5. Japanese Phonology ... 17
a. Vowels ... 18
b. Consonants ... 18
B. Theoretical Framework ... 19
CHAPTER III. RESEARCH METHODOLOGY ... 22
A. Research Method ... 22
B. Research Setting ... 24
C. Research Subject ... 24
D. Instruments and Data Gathering Techniques ... 25
1. Human Instrument ... 25
2. The Videos of Japanese Singer Performing English Songs ... 26
E. Data Analysis Techniques ... 27
F. Research Procedure ... 29
1. Formulating Problem ... 29
2. Specifying The Phenomenon ... 29
3. Selecting The Media ... 30
4. Gathering The Data ... 30
xiii
CHAPTER IV. RESEARCH RESULTS AND DISCUSSION ... 32
A. Pronunciation Process of Tense Vowels, Diphthongs, and Liquids Produced By Japanese Singer ... 32
1. Tense Vowels ... 32
2. Diphthongs ... 35
3. Liquids ... 37
B. The Linguistic Strategies Done By Japanese Singer in Producing Tense Vowels, Diphthongs, and Liquids ... 39
1. Sound Substitution ... 39
2. Sound Simplification ... 40
CHAPTER V. CONCLUSIONS AND RECOMMENDATIONS ... 42
A. Conclusions ... 42
B. Recommendations ... 44
xiv
LIST OF TABLES
Tables ... Page
2.1. Japanese Vowels System ... 18
2.2. Japanese Consonantal System ... 19
3.1. Sounds Production ... 27
4.1. Tense Vowels Production ... 33
4.2. Diphthongs Production ... 35
xv
LIST OF APPENDICES
Appendices ... Page
A. Chase Lyrics ... 48
B. XXX (Kiss Kiss Kiss) Lyrics ... 50
C. The Words Containing Tense Vowels In Chase Lyrics ... 51
D. The Words Containing Diphthongs In Chase Lyrics ... 52
E. The Words Containing Liquids In Chase Lyrics ... 53
F. The Words Containing Tense Vowels In XXX Lyrics ... 55
G. The Words Containing Diphthongs In XXX Lyrics ... 56
H. The Words Containing Liquids In XXX Lyrics ... 57
1
CHAPTER I INTRODUCTION
This study discusses the phonological analysis of a Japanese singer in
producing tense vowels and liquid in live performance music videos. This chapter
consists of six sections. The first section is about the background of the research
which discusses the general explanation of the difference between phonological
systems in English and Japanese and the significance of the study. The second
section is research problems in which the researcher raises two problems from the
topic. The third section is problem limitation which determines the focus of the
study. The fourth section is research objectives. This section presents the expected
outcomes of the research according to the research questions. The fifth and the sixth
part are research benefits and definition of terms.
A. Research Background
As an international language, English has been learned by many people around
the world. It is in accordance with Crystal’s statement (2003) that English becomes
the language which is most widely taught as a foreign language so that the number
of second language speakers increases vastly. In this case, there will appear a lot of
accents, Chinese accents, Korean accents, Spanish accents and so on. It is a clear
sign that the sound patterns or structure of their native languages influence the
speech or production of their second language. In short, it is very equitable to say
that the nature of a foreign accent is determined to a large extent by a learner’s native
language (Avery & Ehrlich, 1992).
The sound patterns of language or usually called as phonology of a certain
language raises some problems for the foreign speakers in pronouncing English
words since the phonology of a certain language is different from the phonology of
English. The difference can appear from the absence of sounds in a certain language
but they are present in English. One example of the language is Japanese. As
Kenworthy (1987) said, Japanese has only five vowels in its vowel inventory namely
/i/, /e/, /a/, /u/, and /o/. A system is quite common among many natural languages
in the world. It is different from English which has fifteen vowels namely /i/, /ɪ/, /e/,
/ᴈ/, /ᴂ/, /ə/, /ʌ/, /u/, /ʊ/, /o/, /ɔ/, and /a/. The difference of Japanese and English vowel
systems is also indicated from the existence of lax and tense in those two vowel
systems. The difference between tense and lax vowels is made according to how
much muscle tension or movement in the mouth is involved in producing vowels
(Ladefoged, 1982). Some of English vowel systems are tense such as /a/, /i/, /u/, /e/,
/o/ and all of Japanese vowel systems are lax.
Besides the difference in the vowel systems, there are also differences in
consonantal distribution between Japanese and English. According to Avery and
Japanese. Japanese does not have fricatives and affricates which are much more widely distributed in English such as /f/, /v/, /θ /, /ð/, / ʃ /, / ʒ /, /ʧ/, and /ʤ/. In
addition, Japanese has a liquid /r/ which is different from the /r/ or /l/ sound of
English. The exact of articulation point of /r/ sound in Japanese is not specific.
In addition, the researcher chooses the topic because of his interest in English
sounds production of foreign speakers. The researcher often listens to Japanese
songs in which there are some English words in the lyrics. Then the singer
pronounces the English words in a unique way. As a result, the researcher is
interested in analyzing the pronunciation process of the singer in producing English
words.
This study is quite significant because it gives the insights of the diversity in
English accent especially Japanese accent for the English Language Education
Study Program students. When they are working as an English teacher in Japan or
English as a foreign language teacher at Lembaga Bahasa Sanata Dharma
University, they will face the natives of Japanese in which they have to be able to
understand the English words uttered by the Japanese students.
Thus, this thesis discusses the phonological systems in Japanese which
influence the Japanese singer in pronouncing the English words. The study describes
the process of Japanese singer in making the sounds of tense vowels and liquids.
Finally, the study shows the linguistic strategies used by the Japanese singer to solve
In conducting this study, the researcher is inspired by the previous study
written by Aprilia Kristiana Tri Wahyuni, one of English Language Education Study
Program students 2012. She used Korean singers as her subjects and analyzing the
production of labiodental fricatives of Korean singers in live performance music
videos.
The Japanese singer who is used as the subject of the study is the singer of a band namely L’Arc-en-Ciel. The researcher uses the band because the members
have been considered as the band which is popular in Japan and other countries.
They also have debuted internationally.
B. Research Problems
From the research background, the study raises two research questions in
order to make this study more organized. Those two questions are as follows.
1. How does the Japanese singer pronounce tense vowels, diphthongs, and
liquids in English?
2. What are the linguistic strategies used by the Japanese singer when he faces
tense vowels, diphthongs, and liquids in English?
C. Problem Limitation
The study focuses on the sound production of the foreign speakers of English
who are represented by the Japanese singer since he has debuted internationally.
analyzes the live performance music videos of the singer and the other members
because they are considered as the authentic data in which the singer produces the
sound without any manipulation.
The subjects discussed in the study are the tense vowels, diphthongs, and
liquids produced by the Japanese singer when he sings English songs in each word
and phrase. Then, as the first objective, the study describes the pronunciation
process of the Japanese singer in producing the tense vowels, diphthongs, and
liquid in words and phrases. Secondly, it shows the linguistics strategies used by
the Japanese singer when he faces the tense vowels, diphthongs, and liquids.
D. Research Objectives
The study has two objectives. Those two objectives are as follows.
1. The study aims to describe the pronunciation process of the Japanese singer
when producing the tense vowels, diphthongs and liquid in each word.
2. The study aims to show the linguistic strategies used by the Japanese singer to
solve the absence of tense vowels, diphthongs, and the unspecified liquids.
E. Research Benefits
The results of the study are expected to give benefits to the teachers of English
1. English as Foreign Language Teachers
The results of the study give the insights of the diversity in English accent so
that the teachers can understand the learners especially Japanese learners. They
help the teachers not to misunderstand the English words uttered by Japanese
learners.
2. The English Language Education Study Program Students
This study is expected to be a source of reference for ELESP students to
improve their awareness of phonological phenomena occurred in another
country. It expands the phonological knowledge of ELESP students when they
are learning phonetic and phonology.
3. Linguistics Lecturers
This study is expected to be a source of knowledge for linguistics lecturers in
ELESP Sanata Dharma University especially phonetic and phonology lecturers.
It can be a media for students to make an observation of phonological
phenomena in other countries.
F. Definition of Terms
In order to avoid misunderstanding in the study, the researcher provides
some definition of terms.
1. Phonological Analysis
As Veen and Mve (2010) stated, phonological analysis can be defined as the
are produced by foreign speakers in this case Japanese singer. In this study, the
analysis describes the process of Japanese singer in pronouncing tense vowels,
diphthongs, and liquids in English words.
2. Tense Vowels
Tense vowels are vowels produced with extra muscle tension. For example, /i/ as in English /it/ “eat” is categorized as a tense vowel as the lips are spread
(muscular tension in the mouth) and the tongue moves toward the root of the
mouth (Ladefoged, 1982). Although Japanese has similar vowels system to
English which are /i/, /e/, /a/, /u/, and /o/, Japanese pronounces them in lax.
Thus, this study is going to analyze the pronunciation process of Japanese singer
when they are producing those tense vowels.
3. Diphthongs
Diphthongs are other types of vowels. They refer to a sequence of two sounds,
vowel plus glide (Fromkin, Rodman, and Hyams, 2007). There are several examples of diphthongs, such as /aɪ/, /əʊ/, and /oʊ/. In this research, the
researcher analyzes the pronunciation process of the Japanese singer when he
produces English word containing diphthongs.
4. Liquids
Liquids are the sounds produced by some obstruction of the airstream in the
mouth, but not enough to cause a real constriction or friction (Fromkin,
Rodman, and Hyams, 2007). There are two liquids: /r/ and /l/. Even though
the English liquid /r/ or /l/, but rather it is considered to be an in-between sound
of English /r/ and /l/. The exact articulation point is not specified for the
Japanese /r/ sound. In this study, the researcher analyzes the pronunciation
9 CHAPTER II
REVIEW OF RELATED LITERATURE
This chapter presents the review of literatures, theoretical writings and
researches which are related to the study. This chapter includes two sections. The first
section is theoretical description which includes the theories which are relevant to the
study being discussed. The theories are about the phonological analysis, tense vowels,
liquids, Japanese phonology, and Japanese singer who is considered as EFL (English
as Foreign Language) speakers. The second section is theoretical framework. It
summarizes all major relevant theories which will help the researcher conduct the study
to solve the research problems.
A. Theoretical Description
In this section, the researcher uses four theories which are directly related to the
study matter. This section describes the definitions, kinds and some important
information of the phonological analysis, tense vowels, liquids and Japanese singer who
is considered as EFL (English as Foreign Language) speakers.
1. Phonological Analysis
Phonological has meaning as relating to the nature of sounds of certain language,
in this case is English (Fromkin, Rodman, & Hyams, 2007). Therefore, phonological
analysis can be defined as the theoretical and practical steps in analyzing the sound
speakers and the strategies they use to solve the problems in producing the English
sounds.
Steps of phonological analysis can be divided into three major steps. As Veen
and Mve (2010) said, the first step of phonological analysis is carrying out preliminary
inquiries in which the researcher has to determine the clear goals of the research and the
sound representations. The second step is performing phonetic transcription. This is the
necessary step yet it consumes a plenty of time to work on. The final step is analysis.
Veen and Mve (2010) also stated that in working on phonological analysis, there
are some important things to consider. Being rigorous, meticulous and accurate are must
in working on phonological analysis, especially in terms of transcription, data
management and storage, analysis, and description. They are very important since doing
a phonological analysis is a task that combines specific analytical skills, techniques and
reasoning (describing problems and giving solutions). The ability to manage the time
and being patient are also important since when the researcher does the phonetic
transcription it will take a plenty of time. It requires careful observation in watching and
listening. In addition, it requires repetition in identifying the exact pronunciation of the
subjects.
Besides, phonological analysis is going to identify the acts of the subjects in
solving their problems in producing English sounds which are usually called as
a. Sound Substitution
In producing English words, there will be a lot of problems faced by English
non-native speakers. They often find some sounds in English which do not exist in their
language. For example, as Ohata (1994) said, Japanese has a liquid sound which is
similar to both English /r/ and /l/. However the liquid does not exactly correspond to
either of the English liquids and they are often pronounced as a kind of in-between
sound of the English /r/ and /l/. In this case, Japanese students often change the English
/r/ and /l/ sounds (Suski, 1931). Therefore they usually change /l/ into /r/ at one time
and /r/ into /l/ at another. Because of this interchangeable use of both /l/ and /r/, the
words such as light and arrive may sound like right and alive to English native speakers.
Thus, that is usually called as a sound substitution strategy. That is the strategy
used by non-native English speakers in labeling the non-existing sound with the sound
which is present in their language and has the closest quality with the English sound.
b. Sound Deletion
Sound deletion refers to the phonological process in which one sound with a
syllable is omitted (Jenkins, 2000). Jenkins (2000) said that there are three kinds of
sound deletion, namely aphesis or apheresis, syncope, and apocope. Aphesis or
apheresis is the type of deletion which occurs in the initial vowel of a word. As the
Meanwhile, syncope is a very common deletion which occurs in the middle
vowel of a word, for example the word family [fæmli]. Finally, apocope is the deletion
of the consonant. The final sound of a word is omitted which is usually placed within
consonant cluster.
c. Sound simplification
Sound simplification is a variation in which the certain sound within one syllable
is simplified into simple sound. It usually occurs within short and long vowels or
minimal pair (McMahon, 2002). As the example, the long vowel in a word snake which
is pronounced as [sneɪk]. The long vowel [eɪ] is usually simplified into [e] which
becomes [snek].
d. Sound Assimilation
Sound assimilation refers to the linguistic process when one sound becomes more
like its neighbor (Nathan, 2008). There are two types of assimilation which are
anticipatory assimilation or regressive assimilation, or simply leftforward assimilation
and perseveratory assimilation, or progressive assimilation, or rightforward
assimilation. The first type of assimilation, anticipatory assimilation, happens when the
sound in the preceding syllable is assimilated to the next sound. Meanwhile,
perseveratory assimilation happens when the direction goes forward from the causing
e. Insertion
Insertion refers to the addition of a sound in the initial, middle or final of a word.
According to Nathan (2008), there are two reasons of the insertion application. The
first reason is to prevent consonant cluster that violate syllable structure. Secondly,
insertion is done to ease transition between segments that have multiple incompatible.
As stated on the definition of insertion, there are three types of insertion based
on the sound placed on a word. The first type is prothesis. Prothesis refers to the
insertion of a sound which precedes the initial letter of a word, for example the word
special becomes [espesial] (Nathan, 2008). The second one is epenthesis. It refers to the insertion of a sound in the middle of a word (Nathan, 2008). As the example, the
word film is pronounced as [fıləm]. The last one is paragoge. It refers to the insertion
of a sound in the final of a word, for example the word pride is pronounced as [puraido]
(Nathan, 2008). Those three types of insertion often occur when Japanese try to say
English words. They do those insertions to avoid the consonant clusters since they have
predominantly open syllables which means the word is finalized with a vowel.
Therefore, when they say the word pride, they will pronounce it as [puraido] instead
of [praid] in which epenthesis and paragoge inertions are applied.
2. Vowels
McMahon (2002) said that vowels refer to the sounds which are produced on a
pulmonic aggressive airstream, with central airflow. Vowels can also refer to an
out through the lips (Roach, 2009, p. 10). Vowels have some types, three of which are
diphthongs, tense and lax.
a. Diphthongs
A diphthong is a sequence of two sounds, vowel plus glide. For example: bite
[bajt]; there are [a] vowel and glide of [j]. Another example is bout [bawt]; there are
vowel of [a] and [w] glide (Fromkin, Rodman, & Hyams, 2007). This kind of vowels
do not exist in Japanese since as Kenworthy (1987) said, Japanese has only five vowels.
b. Tense
Tense vowels are the vowels which are produced with greater tension of the
tongue muscle than its counterpart, and they are often a little longer in duration
(Fromkin, Rodman, & Hyams, 2007). [a], [e], [i], [o], [u] and diphthongs are tense in
English, while in Japanese, there is no tense or lax differentiation. In his journal, Ohata
said that the tense/lax vowels pairs of English such as /i/ vs. /ɪ/, /e/ vs. /ε /, /u/ vs. /ʊ/, do
not exist in the five-vowel system of Japanese.
c. Lax
According to Fromkin, Rodman, and Hyams (2007), lax vowels refer to the
vowels which are produced with smaller tension of the tongue muscle than its
counterpart, and they are shorter in duration. Some examples of lax vowels are /ʌ/, /ɪ/,
/ʊ/, /ᴈ/, and /ɔ/.
3. Liquids
Liquids refer to the sounds produced by some obstruction of the airstream in the
Hyams, 2007). There are two liquids in English: [l] and [r]. In Japanese liquids are not
exactly the same as in English. This issue stems from the lack of a separate /r/ and /l/
sound and the difference in place of articulation between Japanese and English /r/
sounds.
a. Trill
A trilled “r” can be found in the word “perro” which means dog in Spanish. They
produce the /r/ very clear. Therefore, according to Fromkin, Rodman, and Hyams (2007), a trilled “r” is the sound produced by rapid vibrations of an articulator.
b. Flap
A flap is produced by a flick of the tongue against the alveolar ridge. It sounds like “a very fast d (Fromkin, Rodman, & Hyams, 2007).” This kind of sound can be
found when American pronounce the word “writer” in which it is almost the same as
pronouncing the word “rider”. A flapped “r” is symbolized as [ɾ], so the word “writer”
will be pronounced as [raiɾər]. It also happens when Japanese students say an English
word which has liquids. It is different from English in which /l/ is an alveolar lateral or
approximant and the /r/ is a post-alveolar approximant. Japanese students produce a
single liquid voiced consonant that combines the two sounds of /l/ and /r/ as it is produced by a very quick tap (also called a “flap”) of the tongue tip on the alveolar ridge
(Suski, 1931, p. 70).
4. EFL Speakers
In this part, there will be a general explanation of speaking and EFL. As it is
defined as a process of building and sharing meaning through the use of verbal or oral
form (Chaney & Burk, 1988, p.13 and Gebhard, 1996, p.169). Moreover, Nunan (2003,
p.48) defines that speaking consists of producing systematic verbal utterances to convey
meaning. In this context, the person who uses English (language) to convey the meaning
in verbal utterances is considered as an English speaker. An English speaker who has
learned and used English from early childhood refers to a native English speaker.
Meanwhile, an English speaker who is not born or raised in a place where a particular
language is spoken, in this case, English refers to a non-native English speaker
(Merriam-Webster).
In addition, EFL is the acronym of English as Foreign Language. This term is
usually used to describe the students learning English (their first language is not
English) in their own country. For example, the students in Indonesia learn English. In
his article at grammar.about.com, Nordquist also stated another meaning of EFL which
is a traditional term for the use or study of the English language by non-native speakers
in countries where English is generally not a local medium of communication. From
those statements, non-native English speakers are directly related to EFL since they do
not use English as the first language but as the foreign language. Therefore, in this
context, the Japanese singer can be considered as the EFL speakers.
From the usage of English by Japanese singers, it is closely related to the
purposes of speaking English for EFL speakers. They use English for the specific
purposes in which this situation can be called as English for Specific Purposes (ESP).
which all decisions as to content and method are based on the learner's reason for
learning" (p. 19). In brief, ESP is the use of a particular variety of English in a specific context of use and justified by the learners’ needs. In this study, the learner is a Japanese
singer who uses English for entertainment purposes since he has debuted
internationally.
As the EFL speakers, they face problems in speaking English one of which is
pronunciation. Pronunciation problems appear because as EFL speakers, they do not
use English as their first language in which they are not also accustomed to speak
English in their daily life. As a result, they cannot pronounce English words as perfect
as the words in their language. Nation and Newton (2009) also stated that the EFL
speakers often have pronunciation problems in speaking English. The pronunciation of
the speakers can be influenced by the first language of the speakers. As Nation & Newton (2009) stated that the research studies show many learners’ first language has
been the major influence when they produce English sounds. One evidence for this is where speakers of the same first language typically pronounce the second language in
the same way, making the same kinds of substitutions and patterns of pronunciation.
5. Japanese Phonology
In order to describe the pronunciation process of the Japanese singer in
producing vowels (including diphthongs) and liquids, this research discusses the
a. Vowels
Japanese language does not have many kinds of vowels like in English. It even
does not have the diphthongs. Ohata (1994) stated in his journal that Japanese language
has only five vowels in its vowel inventory which are very different from English
vowels containing fifteen different vowels, which include several diphthongs such as
[image:36.612.96.519.247.490.2]/aw/, /ay/, and /oy/. The Japanese vowels are presented in Table 2.1.
Table 2.1. Japanese Vowels System
Front Central Back
High i u
Mid e o
Low a
In Japanese Vowels System table adapted from Okada (1991), /a/ sounds like “cut” in English but with more slightly open mouth. /i/ in Japanese sounds like “feet”
in English. Meanwhile /u/ in Japanese, they pronounce it with the lips compressed
toward each other but neither rounded like [u] nor spread to the sides like [ɯ]. /e/ in Japanese has the same sound as “set” in English. Finally /o/ is somewhere between
“core” and “coke” in English.
b. Consonants
As in its vowels, Japanese consonants also have differences from English
/, / ʒ /, /ʧ/, and /ʤ/ do not exist in the Japanese consonantal system (Avery & Ehrlich,
[image:37.612.105.528.214.497.2]1992; Kenworthy, 1987). The Japanese consonantal system is presented in Table 2.2.
Table 2.2 Japanese Consonantal System
Place and Manner of Articulation
Bilabial Alveolar Alveopalatal Velar Glottal
Stops Voiceless p T k
Voiced b D g
Fricatives Voiceless S Ҫ h
Voiced Z
Nasals m n
Liquids (approximants)
r
Although Japanese has a liquid consonant as shown in Table 2.2, the liquid does
not exactly sound like the English liquid /r/ or /l/, but rather it is considered to be an
in-between sound of English /r/ and /l/. The exact articulation point is not specified for
the Japanese /r/ sound. As Akamatsu (1997) stated, /r/ is an apical postalveolar flap
undefined for laterality. Therefore, it is specified as neither a central nor a lateral flap,
but may vary between the two which is similar to Korean /r/.
B. Theoretical Framework
As the framework of the theories, it sums up that the researcher uses five theories.
linguistic strategies. The study provides the description of five linguistic strategies. The
first strategy is sound substitution. Sound substitution refers to the strategy in labeling
the non-existing sound with the sound which is present in their language and has the
closest quality with the English sound. Secondly, sound deletion is the strategy which
is simply used by omitting the sound from a word (Jenkins, 2000). The third strategy is
sound simplification which refers to a variation in which the certain sound within one
syllable is simplified into simple sound (McMahon, 2002). The fourth strategy is sound
assimilation. It is a linguistic process when one sound becomes similar to its neighbor
(Nathan, 2008). Lastly, insertion is the addition of a sound in the initial, middle or final
of a word (Nathan, 2008). The insertion of sound which preceding the initial of a word
is usually called as prosthesis (Nathan, 2008). The insertion of sound which occurs in
the middle of a word is called epenthesis (Nathan, 2008). Finally, paragoge is the
insertion of a sound in the final of a word (Nathan, 2008).
The second and the third theories are vowels and liquids in English phonological
system. In 2007, Fromkin, Rodman, and Hymas stated that English vowels consist of
tense vowels, lax, and diphthongs. The fourth theory is English as a Foreign Language
(EFL) speakers. The theory also describe the position of the Japanese singer when he
sings English song. In this case, he uses English to sing the song. As a result, he can be
considered as an English as foreign language speaker since it is similar to the definition
of EFL which is a traditional term for the use or study of the English language by
non-native speakers in countries where English is generally not a local medium of
The last theory is Japanese phonology theory. This theory describes the
phonological system in Japanese. There are some absences of sounds between English
and Japanese. In Japanese there are only five variants of vowel which are not specified
whether they are lax or tense while in English there are fifteen different vowels and they
contain diphthongs, tense and lax. The absence of an exact sounds of liquids also exists
in Japanese consonants. According to Kenworthy (1987), although Japanese has the
same liquids as in English, they do not pronounce them very clearly whether they should
22 CHAPTER III
RESEARCH METHODOLOGY
This chapter presents a rationale of the methods of research and analysis. It
contains six sections which are going to be defined and described each of them. The
first section is research method. It contains the explanation of the document analysis
as the research method used in this study. The second section is research setting.
Research setting describes where and when the research is done. In the third section,
this study elaborates on the participants/subjects of the research as well as the
methods of sampling. The fourth section is instruments and data gathering
technique. In this section, the researcher explains the research instruments used in
the study and the techniques in gathering the data. Then, from the data there are
some findings and the description of the way how to analyze the findings is
presented in data analysis technique as the fifth section of this chapter. Finally, the
steps taken in conducting the study are described in the section of research
procedure.
A. Research Method
This research was qualitative research since this study dealt with the
description of sound production analysis, which focused on the pronunciation
process when Japanese produced liquids and tense vowels. This study described how
In this study, the sources of data gathering can be specified into document analysis.
As Ary, Jacobs, and Razavieh (2002) said that document analysis refers to a method
of research utilized to written or visual materials in a purpose of identifying specified
characteristics of the material or a project that focuses on analyzing and interpreting
recorded materials within its own context. From the description of document
analysis, live performance videos from Japanese singer can be indicated as the visual
materials which are going to be identified and analyzed the errors.
As Ary, Jacobs, and Razavieh (2002) stated, there are six steps in document
analysis which should be done. The first step is specifying the phenomenon to be
investigated. In this step, the researcher specified the phenomenon of pronunciation
process of Japanese singer in producing tense vowels and liquids. Secondly, the
researcher selected the media to analyze which are the videos. The third step is
formulating exhaustive and mutually exclusive coding categories so that the verbal
or symbolic content can be counted. Then, the researcher specified the sample in this
case video based on the year or period when they performed. It aims to obtain a
representative sample of the documents. The next step is training the coders so that
they can consistently apply the coding scheme that has been developed and thus
contribute to the reliability of the content analysis. Finally, the data was analyzed
and it involved the descriptive accounts since this study used qualitative research.
The materials could be analyzed from the textbooks, newspapers, web pages,
speeches, television programs, advertisements, videos, musical compositions, or any
of a host of other types of documents. The reason why the researcher wanted to use
singer when he sang a song in English. The videos did not use the process of editing
and it was as real as it was. In addition, from that originality the researcher was able
to see the authentic process when the Japanese singer pronounced the English words.
The pronunciation of the Japanese singer was analyzed from the lip movement and
mouth so that the clearer sound transcription could be interpreted.
B. Research Setting
The researcher conducted the research starting from 6 March 2015 until 30
April 2015. On 6 March 2015, the research was conducted at the researcher’s
boarding house by downloading several live performance videos from youtube.
Then, the videos were watched and analyzed during two weeks, starting from 7
March 2015 until 21 March 2015. During two weeks, the researcher saw the process
of pronunciation when Japanese singer produced tense vowels and liquids. The next
five weeks, starting from 21 March 2015 until 30 April 2015, the researcher
described the results of the analysis from the videos by making the table and
comparing how Japanese singer made the sound of tense vowels and liquids to the
sounds in English. The researcher also did the revision from the results which had
been described.
C. Research Subject
In conducting the study, the researcher used the Japanese singer as the subject
of the research. The Japanese singer was a vocalist in a Japanese band named L’Arc
four members consisting of Hyde as the vocalist, Tetsuya as the bassist, Ken as the
guitarist and Yukihiro as the drummer. Those members are formed after several
changes occurred in their group. On 1 April 1993, the band released their debut
album Dune on the independent, but well-known, record label Danger Crue. This
was their first debut. Besides, they have debuted internationally in U.S. (2004) and
Europe (2006-2008). On 31 July 2004, L'Arc-en-Ciel made their North American
debut at the anime convention Otakon. Then, when they were in Europe, they did
their performance in Paris, France. The subject was going to be analyzed through
the live-performance videos of their concert in which there were not any
manipulation.
The study used L’Arc-en-Ciel’s singer as the subject because he has been
considered as the singer who was popular in Japan and other countries. The singer
and the members also have debuted internationally. Besides, they have songs in
English and from those songs, the researcher analyzed when the Japanese singer
sang those songs. This is one authentic example in which Japanese people use
English.
D. Instruments and Data Gathering Technique
There were two instruments used to gather the data. The two instruments were:
1. Human Instrument
In this research, the researcher used human as the instrument in gathering the
data. It was not the same as quantitative research, as Ary, Jacobs, and Razavieh
qualitative and quantitative research is the condition in which human can be used as
primary instrument for gathering data, or human as instrument. Qualitative research
in form of document analysis study which deals with human experiences and
situation need a flexible instrument to ensnare the complexity of both subject.
Therefore, this study which deals with the situation where Japanese people speak
English as international language employs the researcher himself as the instrument
to examine the phenomena happened in the subject.
2. The Videos of the Japanese Singer Performing English Songs
Since this study used document analysis, the documents which were obtained
during the observation was also called research instrument. The documents were in
form of videos and they were specified to live-performance videos of Japanese
singer. In the videos, the Japanese singer did live performance. There were no
editing process in their performance in which it will keep the authenticity of the
sample. The songs which the Japanese speaker sings were English songs.
In gathering the data, the researcher used the videos as the data or documents
to analyze. The researcher downloaded the videos in this case were live-performance
videos of Japanese singer from youtube. After that, the researcher tried to find the
lyrics of songs which were sung by the Japanese singer and matched them to the
video, which part should be omitted, which part was repeated. It aimed to make the
lyrics have exactly same part and sequence to the video. Then, the researcher found
the words containing tense vowels and liquids sounds. After that, the researcher
The researcher used the table as the tools to ease the work in gathering the
data. Then, the words or the word groups which contain tense vowels, diphthongs, and liquids were inserted in the words/word groups’ column. There were the other
columns to show the standard phonetic transcription and the variation phonetic
transcription which is produced by the Japanese singer. The standard phonetic
transcription refers to the phonetic transcription which is showed in the eighth
edition of the Oxford for Advanced Learners Dictionary. The following is the table
[image:45.595.103.520.258.567.2]used to collect the data.
Table 3.1. Sounds Production
No. Word / Word Group
Phonetic Transcription
Standard Variation
1.
2.
3.
…
The findings were single words or word groups. Word group in this research
refers to a kind of group which has random combination. It did not create fixed
phrase, such as adjective phrase, noun phrase, and so on. It contained various type
of words, such as combination of noun verb, verb article, and many others. These
E. Data Analysis Technique
There are two research problems in this research. Those two research
problems were answered by using document analysis. The first thing to do, the
researcher transcribed the word or word group from the lyrics of the song in the
standard phonetic transcription. Since the researcher only focused the sounds on
tense vowels and liquids, the words were grouped into three major groups which
were words or word groups with tense vowels, words or word groups with
diphthongs, and words and word groups with liquids. The phonetic transcriptions
then were inserted in the sounds production table.
The next step was analyzing the process of pronunciation done by the
Japanese singer when producing English words containing tense vowels and liquids.
The researcher watched and listened to the word or word groups containing tense
vowels and liquids sound produced by the Japanese singer in the live-performance
video. The researcher also asked one colleague who also understands the linguistic
to observe the videos. It aimed to confirm the findings of pronunciation process in
the videos. After that, those English words were transcribed in the phonetic
transcription as the words are produced by the singer and they were inserted in the
table of variation phonetic transcription. After inserting the phonetic transcription,
the researcher found the differences between the standard phonetic transcription and
the variation. From the differences, the researcher described the process of
pronunciation of the Japanese singer when producing tense vowels, diphthongs, and
liquids by relating the theories how the process of pronouncing the tense vowels,
From that analysis, it could be described what made the Japanese singer produce the
sounds of tense vowels, diphthongs, and liquids differently. Then, the strategies of
how they made the sounds could be indicated.
F. Research Procedure
In doing the study, the researcher underwent some procedures in formulating
the problems, gathering the data and analyzing the data. Since, the researcher used
document analysis, the steps were similar to it. The following is the steps how the
research done.
1. Formulating The Problem
This step was started by finding the topic which was going to be used for the
research. The researcher had made the topic of phonological analysis of a Japanese
singer in producing the tense vowels and liquids in live-performance music video.
From that topic, it raised research problems in form of two questions about the
process of Japanese singer in pronouncing the English words containing tense
vowels and liquids and the linguistic strategies used by the Japanese singer when
they are facing those words. Those two questions were answered descriptively.
2. Specifying The Phenomenon
In this step, the researcher had specified the phenomenon by employing the Japanese singer who is L’Arc-en-Ciel as the subject of the research. Since it is about
phonological analysis, it is all about the sound pattern. Therefore, the researcher also
specified the sounds which were going to be identified to the tense vowels and
3. Selecting The Media
A document analysis uses many kinds media to be analyzed, such as
textbooks, newspapers, web pages, speeches, television programs, advertisements,
videos, musical compositions, or any of a host of other types of documents. In this
study, the media to analyze was taken from the live-performance videos from the
Japanese singer when he is singing English songs.
4. Gathering The Data
In this step, the researcher started to find the live-performance videos of L’Arc-en-Ciel . The researcher downloaded the videos from youtube. After that, the
researcher found the song lyrics sung by those singer and transcribed the standard
phonetic transcription of the words and word group in the lyrics containing tense
[image:48.595.98.514.244.560.2]vowels and liquids. The standard phonetic transcriptions were inserted in the basic
table which had been made.
5. Analyzing The Data
In analyzing the data, there were some steps which should be undergone by
the researcher. The following is the steps in analyzing the data.
a. The first thing to do was listening to the video from YouTube.com.
b. Secondly, the researcher found the words containing tense vowels and liquids.
c. Next, the words found were transcribed into phonetic symbols.
d. After having written the phonetic transcription, the writer inserted them in the
table of variation of phonetic transcription so that the difference from the
e. Then, the next step was categorizing the findings into three major groups, which
were words or words group containing tense vowels, words or word groups
containing diphthongs, and words or word groups containing liquids.
f. After inserting the phonetic transcription, the researcher tried to find the
difference between the standard phonetic transcription and variation.
g. From the differences, the researcher described the process of pronunciation of
the Japanese singer when producing tense vowels and liquids by relating the
theories how the process of pronouncing the tense vowels and liquids were with
the pronunciation produced by the Japanese singer.
h. Describing what made the Japanese singer produce the sounds of tense vowels
and liquids differently in which the strategies of how they made the sound could
32 CHAPTER IV
RESEARCH RESULTS AND DISCUSSION
This chapter presents the results of the research. The results answered the
first research problem by describing the process of pronunciation of the Japanese
singer in producing tense vowels, diphthongs, and liquids. Then, the second
research problem was answered by indicating the linguistic strategies done by the
Japanese singer when he produces the tense vowels, diphthongs, and liquids from
the description of the pronunciation process.
A. The Pronunciation Process of Tense Vowels, Diphthongs and Liquids Produced by the Japanese Singer
This part discusses the pronunciation process of Japanese speakers which
are represented by the Japanese singer. This part has three sections of discussion
containing the pronunciation process when he produced tense vowels, diphthongs
and liquids.
1. Tense Vowels
In two videos, the researcher found thirty nine single words containing tense
vowels. From the videos, the researcher analyzed that the singer of the band L’Arc
-en-Ciel produced words containing tense vowels in a different way. Even though
pronunciation between tense and lax. It means that in English, there are specific
differences between tense and lax vowels, such as /i/ and /ɪ/, /u/ and /ʊ/, /e/ and /ᴈ/
and so on. However, although long vowels of Japanese are sometimes analyzed as
having the same quality as English tense vowels, this claim is difficult to support
because those vowels of Japanese are not always contrastive in nature as the English
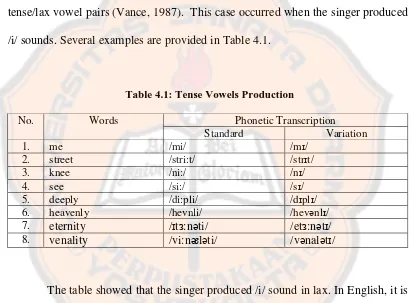
tense/lax vowel pairs (Vance, 1987). This case occurred when the singer produced
[image:51.595.102.513.246.549.2]/i/ sounds. Several examples are provided in Table 4.1.
Table 4.1: Tense Vowels Production
No. Words Phonetic Transcription
Standard Variation
1. me /mi/ /mɪ/
2. street /stri:t/ /strɪt/
3. knee /ni:/ /nɪ/
4. see /si:/ /sɪ/
5. deeply /di:pli/ /dɪplɪ/
6. heavenly /hevnli/ /hevənlɪ/
7. eternity /ɪtᴈ:nəti/ /etᴈ:nətɪ/
8. venality /vi:nᴂləti/ /vənalətɪ/
The table showed that the singer produced /i/ sound in lax. In English, it is
usually called short /i/ which is symbolized as /ɪ/. When the singer said the word me, he pronounced it as /mɪ/ instead of /mi/. It also happened when the singer pronounced street, knee, and see. He pronounced all of them as /strɪt/, /nɪ/, and /sɪ/
in which the /i/ sound which is supposed to be the tense vowel became /ɪ/. There were
also other examples such as the words eternity and venality. In English, eternity
singer produced /ɪ/ sound instead of /i/ especially in the final syllable from the other
words such as deeply and heavenly. In the videos, the researcher also watched the
vocalist did not totally do unrounded lips. In fact, Fromkin, Rodman, and Hyams
(2007) said that when someone produces /i/ sound he or she will have the lips in the shape of smile which is totally unrounded. Meanwhile, the vocalist’s teeth were still
not closed which means the lips were not in the shape of smile.
In addition, when the singer pronounced words me, knee, and see, he actually had produced impossible words in English. It means that lax vowels mostly
did not appear at the ends of English words. For example the words me, knee, and
see should be pronounced as /mi/, /ni:/, and /si:/ in English yet the singer which is a Japanese pronounced them as /mɪ/, /nɪ/, and /sɪ/ all of which have no meaning in
English words.It comes from Fromkin, Rodman, and Hyams (2007) who stated that lax vowels do not occur at the ends of words, so [sɪ], [sᴈ], [sᴂ], [sʊ], and [sʌ] are
impossible words in English.
From the data result, it can be concluded that the singer who is a Japanese
speaker did not pronounce the tense vowels clearly. The singer produced the tense
vowels in lax. It means that the singer did not spread the lips when he produced the
words me, knee, and see. In fact, Ladefoged (1982) stated that the difference
between tense and lax vowels is made according to how much muscle tension or
movement in the mouth is involved in producing vowels. In this case, the muscle
2. Diphthongs
The second section is diphthongs. In order to make the discussion clearer,
the meaning of diphthongs was explained concisely here. As Fromkin, Rodman, and
Hyams (2007) stated, diphthongs are the sounds produced by the English speakers
by adding the short /j/ and /w/ glides when they produce front and back vowels. For
example, English speakers pronounce survey as /sᴈveɪ/ in which the front vowel /e/
is followed by a short /j/ glide and they are symbolized as /eɪ/.
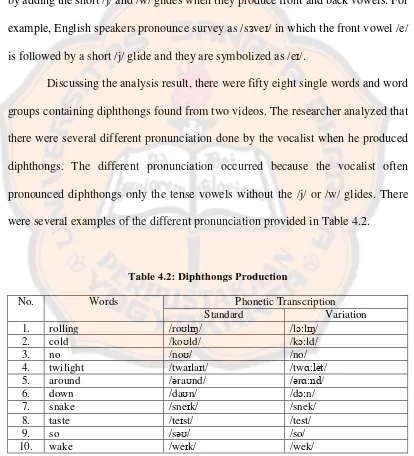
Discussing the analysis result, there were fifty eight single words and word
groups containing diphthongs found from two videos. The researcher analyzed that
there were several different pronunciation done by the vocalist when he produced
diphthongs. The different pronunciation occurred because the vocalist often
pronounced diphthongs only the tense vowels without the /j/ or /w/ glides. There
[image:53.595.102.516.230.686.2]were several examples of the different pronunciation provided in Table 4.2.
Table 4.2: Diphthongs Production
No. Words Phonetic Transcription
Standard Variation
1. rolling /roʊlɪŋ/ /lɔ:lɪŋ/
2. cold /koʊld/ /kɔ:ld/
3. no /noʊ/ /no/
4. twilight /twaɪlaɪt/ /tw :let/
5. around /əraʊnd/ /ər :nd/
6. down /daʊn/ /dɔ:n/
7. snake /sneɪk/ /snek/
8. taste /teɪst/ /test/
9. so /səʊ/ /so/
From the table, it could be seen that most of different pronunciation
occurred because the vocalist did not pronounce the glides /j/ or /w/ clearly. It
occurred because there are only five vowels in Japanese vowels inventory
(Kenworthy, 1987). He pronounced the words rolling, cold, and twilight as /lɔ:lɪŋ/, /kɔ:ld/, and /tw :let/ in which he only pronounced the vowels. One example came
from the word down. In the word down, /a/ becomes /aʊ/ since /a/ is added with /w/ glide so the word is pronounced as /daʊn/. However, the singer pronounced it as /dɔ:n/. The singer did not pronounce the glide clearly, so that the sound was like
/o/ in lax which becomes /ɔ/. Another example is snake. /e/ became /eɪ/ since /e/ is added with /j/ glide, so the word is pronounced as /sneɪk/. However, the singer only
pronounced the tense vowel [e] without the [j] glide and it became /snek/.
The different pronunciation also occured in the other words such as so and wake. The words should be pronounced as /səʊ/ and /weɪk/. Yet, the vocalist pronounce them differently and the words became /so/ and /wek/. It happened since
there are no vowels which are added with the glides in Japanese vowel system. It is supported by Okada’s statement (1991, p.94) which is showed in the vowel chart
that the vowels of standard Japanese are only [ä], [i], [ɯ], [e̞], and [o̞]. They only
have simple vowels usually called as monophthongs (Fromkin, Rodman, and
Hyams, 2007).
The data result indicated that the singer did not pronounce the diphthongs
clearly. In this case, the singer had produced the diphthongs only in one sound
which means that the glides were not produced directly after the vowels. For
instead of /daʊn/. Therefore, it is different from what Fromkin, Rodman, and Hyams
(2007) had stated in their book that diphthong is two sounds containing vowel and
glide which are produced in a sequence.
3. Liquids
From the two videos, the researcher found sixty four single words and
word groups containing liquids. Each word had the liquids which w