PENDEKATAN TEKNIK DATA MINING PADA PUSAT DATA KESEHATAN NASIONAL MENGGUNAKAN MAP VISUALISATION
DATA MINING TECHNIQUE APPROACH FOR DATA CENTER OF NATIONAL HEALTH USING MAP VISUALISATION
M. Adnan Nur1, Adnan2, Armin Lawi2
1STMIK Handayanai Makassar,
2Bagian Teknik Informatika Fakultas Teknik, Universitas Hasanuddin
Alamat Korespondensi :
M. Adnan Nur
Jl. Alamat Rumah : Jl. Beruang No. 60 Makassar HP : 082348530538
Abstrak
Keberadaan sistem Bank Data Kesehatan Nasional Kementrian Kesehatan RI telah memberikan kemudahan bagi masyarakat dalam memperoleh informasi kesehatan yang mencakup hingga tingkat Kabupaten/Kota tetapi informasi yang disajikan masih berupa informasi kuantitatif dimana seluruh data disajikan dalam tabulasi angka dan belum disediakan penggalian informasi lebih dalam. Penelitian ini bertujuan untuk menerapkan dan mengkombinasikan beberapa teknik data mining untuk menyajikan penggalian informasi kualitatif secara dinamis dengan mengkategorikan sistem yang sedang berjalan sebagai sebuah data warehouse. Metode penelitian yang dilakukan dalam penelitian ini meliputi studi lapang untuk mengidentifikasi permasalahan dan kebutuhan informasi kesehatan , penelusuran literatur yang menyangkut pengembangan sistem, perancangan dengan menggunakan Unified Modeling Language dan implementasi menggunakan bahasa pemprograman PHP. Hasil penelitian berupa penerapan teknik data mining yang meliputi klasterisasi (clustering)menggunakan algoritma k-means, klasifikasi (classification) menggunakan algoritma naive bayes dan pola asosiasi (association rules) menggunakan algoritma FP-Growth yang bekerja secara dinamis untuk menjawab kebutuhan pengetahuan informasi kesehatan yang lebih cepat dan mendalam secara kualitatif. Hasil dari olahan data mining selanjutnya divisualisasi dalam sebuah Sistem Informasi Geografis (SIG) yang dalam penelitian ini disebut sebagai Map Visulisation untuk memudahkan dalam memetakan informasi kesehatan berdasarkan provinsi dan kabupaten/kota. Dari hasil penelitian tersebut dapat disimpulkan bahwa data yang diperoleh dari website bank data kesehatan nasional mempunyai attribut atau indikator kuantitatif yang seragam sehingga memudahkan dalam melakukan pengolahan data lebih lanjut.
Kata Kunci : bank data kesehatan, data warehouse,data mining, map visualization.
Abstrack
The existence of the National Health Data Bank system the Ministry of Health has made it easier for people to obtain health information that includes up to district / city level but the information presented is a quantitative information where all the data presented in the tabulation of numbers and not provided more information on excavations. This study aims to apply and combine several data mining techniques to present dynamically extracting qualitative information to categorize the current system as a data warehouse. Methods of research conducted in this research include field studies to identify the problems and information needs of health, literature searches related to systems development, design using Unified Modeling Language and implementations using the programming language PHP. The results of the application of data mining techniques, including clustering (clustering) using the k-means algorithm, classification (classification) using Naive Bayes algorithm and association patterns (association rules) using FP-Growth algorithm that dynamically works to address the needs of knowledge of health information more rapid and in-depth qualitative. The results of the processed data mining subsequently visualized in a Geographic Information System (GIS) which in this study is referred to as Map Visulisation to facilitate the mapping of health information by province and district / city. From these results it can be concluded that the data obtained from national health data bank website has attributes or quantitative indicators to facilitate the uniform conduct further data processing.
PENDAHULUAN
Keberadaan teknologi sebagai media dalam pendistribusian informasi dalam bidang kesehatan belakangan ini semakin dibutuhkan. Jumlah data kesehatan yang terus meningkat dan kebutuhan penyajian informasi yang cepat dan akurat mendorong penerapan teknologi diberbagai aspek bidang kesehatan. Di Indonesia, terbitnya UU Nomor 36 Tahun 2009 Pasal 169 yang menyatakan bahwa “Pemerintah memberikan kemudahan kepada masyarakat untuk memperoleh akses terhadap informasi kesehatan dalam upaya meningkatkan derajat kesehatan masyarakat” menjadi dasar dalam penerapan teknologi untuk penyajian informasi kesehatan tersebut. Penerapan teknologi ini tentunya membutuhkan metode-metode baru dalam pengolahan dan penyajian informasinya agar dapat dimanfaatkan oleh berbagai kalangan seperti akademisi, pemerintahan dan masyarakat umum.
Saat ini, Departemen Kesehatan RI telah memiliki sebuah sistem yang disebut Bank Data Kesehatan Nasional yang dapat diakses melalui websitenya http://www.bankdata.depkes.go.id. Sistem menyediakan informasi kuantitatif berdasarkan indikator kependudukan, pendidikan, penyakit, upaya kesehatan, kesehatan lingkungan, tenaga kesehatan dan sarana kesehatan. Dimana setiap informasi tersebut dapat disajikan menurut wilayah provinsi dan kabupaten/kota untuk setiap tahunnya. Dari segi ketersediaan informasi yang ada, sistem tersebut masih dikategorikan sebagai sebuah data warehouse
dan belum menyajikan fasilitas penggalian informasi tertentu untuk kebutuhan pengambilan kebijakan sehingga membutuhkan pengolahan data lebih lanjut yang tentunya membutuhkan waktu. (Architect Dkk, 2011). Sebelumnya, telah terdapat sebuah penelitian yang menyangkut penggalian informasi data kesehatan. Penelitian tersebut menyajikan sebuah survey tentang teknik dalam knowledge discovery in database (KDD). Namun, hasil penelitian hanya fokus pada tahap analisis dan deskripsi penerapannya . Tahap perancangan dan implementasi belum dilakukan pada penelitian tersebut. (Canlas, 2009).
a. Pengelompokan tingkat penderita penyakit tertentu berdasarkan indikator jumlah penderita penyakit untuk setiap wilayah provinsi maupun kota/kabupaten.
b. Mencari keterkaitan antara indikator kesehatan lingkungan dan indikator sarana kesehatan terhadap tingkat penderita penyakit tertentu pada suatu wilayah.
c. Mencari keterkaitan antara indikator tenaga kesehatan dan indikator sarana kesehatan terhadap data upaya kesehatan.
Dari segi visualisasi, pendekatan geografis lebih memudahkan dalam penyajian informasi menurut penyebaran lokasi atau wilayah. Pemetaan informasi kesehatan berdasarkan provinsi maupun kabupaten/kota secara mendalam dapat dilakukan dengan cepat melalui penyajian peta/map yang interaktif. (Bill, 2005).
Dari beberapa permasalahan tersebut, penelitian ini bertujuan untuk mengimplementasikan beberapa teknik data mining secara fleksibel berdasarkan Bank Data Kesehatan yang tersedia dan selanjutnya hasil olahan divisualisasikan melalui peta (map) interaktif , grafik dan tabel yang diharapkan mampu memenuhi kebutuhan informasi kesehatan bagi semua kalangan dan sebagai pendukung keputusan yang akurat bagi penentu kebijakan.
BAHAN DAN METODE
Lokasi dan Rancangan Penelitian
Penelitian dilaksanakan selama bulan Februari 2013 sampai dengan bulan Juli 2013. Penelitian ini dilakukan di Kampus Universitas Hasanudin dan Website Pusat Data Kesehatan Departemen Kesehatan Nasional.
Penelitian ini diawali dari ketersediaan informasi kesehatan nasional yang saat ini masih terbatas pada penyajian data kuantitaif berupa data kontinu. Ketersediaan informasi meliputi nilai indikator kesehatan untuk provinsi dan kabupaten setiap tahunnya yang disajikan melalui tabulasi dan grafik. Informasi kesehatan tersebut dapat diakses melalui sebuah sistem yang disebut website pusat data kesehatan nasional.
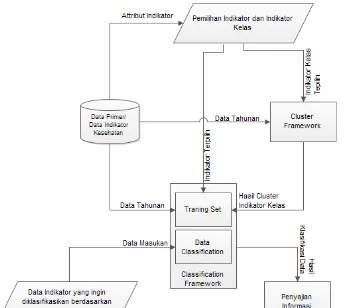
sesuai dengan ketersediaan data yaitu berupa data kontinu. Oleh karena itu, tidak dibutuhkan lagi preprocessing dan data tersebut dapat langsung digunakan sebagai masukan/input pada sistem. Diagram analisis data untuk metode klasterisasi dapat dilihat pada gambar 1.
Untuk metode klasifikasi (classification), data masukan yang dibutuhkan berupa sekumpulan record (training set) dimana setiap record meliputi himpunan attributes yang salah satu attributnya merupakan kelas/class label. Attribute kelas/class label merupakan data kategorikal sehingga data kuntitatif yang tersedia harus melalui preprocessing terlebih dahulu. Transformasi data kontinu ke dalam bentuk kategorikal dilakukan dengan proses klaterisasi/clustering menggunakan algoritma K-mean. Preprocessing ini diterapkan pada data yang ingin dijadikan sebagai data kelas/classlabel. Selanjutnya, estimasi terhadap hasil klasifikasi menggunakan fungsi densitas gauss karena data yang ingin diklasifikasikan merupakan data kontinu. Diagram analisis data untuk metode klasifikasi dapat dilihat pada gambar 2.
Metode pola asosiasi (association rules) dengan algoritma Fp-Growth memerlukan data dengan attribut biner, sehingga diperlukan preprocessing untuk tranformasi data primer
yang berupa attribut kontinu ke bentuk attribut biner. Transformasi ini dapat dilakukan dengan menerapkan clustering/klasterisasi dengan jumlah klaster dua. Dimana data dengan
centroid tertinggi akan bernilai 1 dan centroid terendah bernilai 0. Hasil klaster inilah yang dijadikan masukan untuk algoritma Fp-Growth dalam penerapan metode pola asosiasi. Diagram analisis data untuk metode pola dapat dilihat pada gambar 2.
Populasi dan Sampel
Analisis Data
Pada penelitian ini, analisis data dilakukan menggunakan metode Black Box dalam pengujian data terhadap metode yang diterapkan serta menghitung waktu eksekusi proses sistem untuk sisi server dan sisi client.
HASIL
Berdasarkan hasil analisis data sebelumnya, metode klasterisasi, klasifikasi dan pola asosiasi yang diterapkan pada sistem yang dikembangkan dapat berjalan dengan baik. Untuk sisi server, waktu eksekusi cukup cepat dibandingkan waktu eksekusi pada sisi client. Akumulasi waktu eksekusi tersebut relatif bergantung pada instrumen penelitian yang digunakan.
Metode Pendekatan
Penelitian dimulai dengan penelusuran literatur (library research) yang terkait dengan pengembangan sistem dan studi lapangan (field research) terhadap sistem pusat data kesehatan nasional yang tersedia untuk mengidentifikasi masalah dan bagaimana pengembangan sistem yang dibutuhkan. Untuk tahap perancangan dan desain sistem digunakan pendekatan Unified Modeling Language yaitu menggambarkan bagaiamana keterlibatan pengguna dengan sistem, interaksi antarmuka sistem dan alur kerja sistem. Untuk pengujian dan evaluasi sistem digunakan beberapa tahapan pengujian, yaitu pengujian fungsional sistem dan menghitung waktu eksekusi proses sistem.
Tahapan Penelitian
Studi lapangan (field research) terlebih dahulu dilakukan untuk mengidentifikasi masalah dan kubutuhan pengembangan sistem. Selanjutnya penelusuran literatur yang terkait dengan pengembangan sistem yang ingin dilakukan. Perancangan sistem di implementasi berdasarkan penerapan metode pada proses kerja sistem.
Adapun tahapan penelitian adalah sebagai berikut: Tahap Analisis Masalah dan Kebutuhan, Tahap Penelusuran Literatur, Tahap Desain dan Perancangan Sistem, Tahap Implementasi serta Tahap Pengujian dan Evaluasi Sistem
Perancangan Sistem
(UML) yang merupakan metode pemodelan berbasis objek. Perancangan diawali dengan merancang use case Publik dan Use Case Administrator. Use Case Publik diperuntukkan untuk pengunjung atau pengguna sedangkan Use Case Administrator untuk pengelola.
Perancangan selanjutnya dilakukan melalui desain Class diagram yang mendeskripsikan jenis-jenis objek dalam sistem dan berbagai hubungan statis diantara objek tersebut. Diagram ini mendefinisikan kelas-kelas yang akan dibuat untuk membangun sistem. Mengacu pada Use Case, pada tahap ini penelitian merancang dua jenis Class Diagram yaitu
Class Diagram Publik dan Class Diagram Administrator. Tahap berikutnya melakukan desian untuk sequence diagram dan activity diagram yang mengambar secara detail bagaimana interaksi antaramuka sistem yang dikembangkan.
PEMBAHASAN
Penelitian ini menunjukkan bahwa impementasi dari metode data mining yang diterapkan pada sistem digunakan untuk menggali informasi berupa pengelompokan data indikator kesehatan tertentu yang tersedia melalui klasterisasi, melakukan klasifikasi data untuk memprediksi kategori dari suatu data baru dan mencari tingkat keterkaitan antar indikator melalui pola asosiasi. Berikut penjelasan dari implementasi metode-metode data mining tersebut.
Klasterisasi (Clustering) Data
Klasterisasi (Clustering) Data bertujuan untuk memisahkan nilai-nilai dari indikator kesehatan ke dalam beberapa kelompok yang mempunyai perbedaan jarak nilai signifikan antar kelompok yang satu dengan yang lainnya. (Wu, 2012). Nilai-nilai indikator tersebut diperoleh berdasarkan wilayah dan tahun tertentu sesuai pilihan pengguna sistem.
Impelementasi klasterisasi pada penelitian ini menggunakan algoritma K-Mean
dengan memanfaatkan bahasa pemprograman PHP. Algoritma K-Mean dinilai cukup efisien yang ditunjukkan dengan kompleksitasnya, dengan catatan banyaknya objek data harus jauh lebih besar dari jumlah klaster yang dibentuk dan banyaknya iterasi.. Selain itu, algoritma ini akan terhenti dalam kondisi optimum lokal dan bekerja pada attribut numerik. (Andayani, 2007)
Proses dari algoritma K-Mean diimplementasikan dengan membuat dua class yang disesuaikan dengan perancangan sebelumnya. Class tersebut antara lain class Objek KMean
dari sekumpulan record yang ingin diklaster sedangkan classKMean merupakan class utama dari proses klasterisasi.
Klasifikasi (Classification) Data
Klasifikasi ini bertujuan untuk menentukan suatu nilai indikator kesehatan kesalah satu kategori indikator kesehatan lainnya yang telah didefinisikan. Kemudian indikator-indikator tersebut menjadi acuan untuk memprediksi kategori indikator-indikator dari nilai indikator-indikator baru yang ingin dimasukkan. Impementasi dari metode klasifikasi menggunakan algoritma
Naive Bayes. Naive Bayes merupakan salah satu algoritma klasifikasi pembelajaran induktif yang paling efektif dan efisien untuk machine learning dan data mining. Performa naive bayes yang kompetitif dalam proses klasifikasi walaupun menggunakan asumsi keindependen
attribute (tidak ada kaitan antar attribute). (Shadiq, 2009) .
Terkait dengan analisis data sebelumnya, proses klasifikasi membutuhkan menemukan aturan asosiatif antara suatu kombinasi indikator kesehatan. Penting tidaknya suatu aturan asosiatif dapat diketahui melalui dua parameter antara lain support (nilai penunjang) yaitu persentase kombinasi indikator dalam sekumpulan record dan confidence
(nilai kepastian) yaitu kuatnya hubungan antar indikator dalam aturan asosiatif.(Astuti, 2013). Pola asosiasi data ini diimplementasikan menggunakan algoritma Fp-Grotwh dengan membuat lima class antaralain Class Fp-Growth, Class Fp-Tree, Class Node, Class Path dan
Class Asosiasi Indikator.
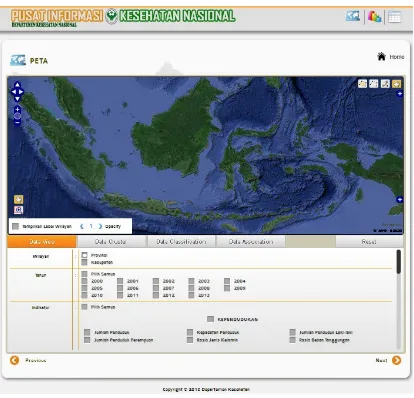
Implementasi arsitektur sistem dari ketiga metode tersebut dapat dilihat pada gambar 4 dan antaramuka sistem pada gambar 5.
KESIMPULAN DAN SARAN
untuk klasterisasi, klasifikasi dan asosiasi tentunya memberikan banyak alternatif terhadap pengembangan sistem. Namun untuk efektifitas pengolahan data, ada baiknya untuk pengembangan sistem selanjutnya dilakukan observasi terlebih dahulu terhadap setiap algoritma yang ada dengan menyesuaikan jenis dan karakteristik data pada data warehouse. Menyangkut data warehouse, sebaiknya pengembangan sistem nantinya juga menyediakan fasilitas web service untuk layanan pembaharuan data yang diperuntukkan pada wilayah kabupaten. Sehingga pemasukan data tidak terpusat lagi.
DAFTAR PUSTAKA
Andayani, Sri. (2007). Pembentukan Cluster dalam Knowledge Discovery In Database denganAlgoritma K-Means. Yogyakarta: Jurnal Universitas Negeri Yogyakarta.
Architect, Chieft; Guerra, Joseph; President Vice. (2011). Why You Need a Data Warehouse. Chesire: Journal of Andrews Consulting Groups.
Canlas Jr, Ruben D. (2009). Data Mining In Healthcare : Current Application And Issues.
Australia: Journal of Carniege Mellon University.
Hermawati Fajar, Astuti. (2013). Data Mining. Yoyakarta: Andi Publiser. Kropla, Bill. (2005) .Beginning MapServer. USA: Apress.
Shadiq, M.Ammar. (2009). Keoptimalan Naïve Bayes Dalam Klasifikasi. Bandung: Jurnal Universitas Pendidikan Indonesia.
Gambar 1 Analisis Data Untuk Metode Klasterisasi
Gambar 2 Analisis Data Untuk Metode Klasifikasi
Gambar 3 Analisis Data Untuk Metode Pola Asosiasi