ABSTRACT
This paper discusses the problem of information extraction from such web pages. Internet, especially the web has turned into a vast source of information. Most of the web content are currently generated from data stored in databases. From information provider view, the presentation of them tends to follow some predefined structures or fixed templates. On the other hand, some users want to consume such structured data to be processed further. Extracting such data is useful because it enable human to obtain and integrate data from multiple sources. Automatic pattern discovery method based on tree matching is used as structured data extraction method. The main advantage of the method is that it requires less human intervention. In this paper we will discuss the implemention of the extractor using that method and then the approach is evaluated in terms of correctness (recall) and precision. Experimental results show that almost all extraction target can be successfully extracted by the extractor developed. However, sometimes other structured data that are not being targetted are also extracted by the extractor. This lead to the provision of manual tuning or filter feature on the extractor developed.
Keywords
information extraction, structured data extraction, tree matching, web content mining
1.
INTRODUCTION
Structured data in web pages usually contain important information. Such data are often retrieved from underlying databases and displayed in web pages using fixed templates. These structured data are called data records [4]. Automatic data records extraction by computer can help human to gather information from web.
Structured data extraction from web pages has been studied by researchers. Existing methods addressing the problem can be classified into three categories [4]. Methods in the first category provide some languages to facilitate the construction of data extraction system. In this category the user must manually construct data record's pattern for the extraction target (manual extraction). Methods in the second category use machine learning techniques to learn and construct wrappers (data extractors) from human labeled examples. Manual labeling is time-consuming and is hard to scale to a large number of sites on the web. Methods in the second category also called wrapper induction. Methods in the third category are based on the idea of automatic pattern discovery. Methods in this category have some advantages over
other methods because these methods don't require separate training, validation, and application phases [2].
Methods in the third category can be divided into two category; string matching based and HTML tree matching based. It has been shown that automatic pattern discovery methods based on HTML tree matching are more efficient than the string matching approaches [3].
The rest of this paper is organized as follows: section 2. describe s shortly an example of web pages and data records, section 3. presents DEPTA, which is one of automatic pattern discovery methods based on tree matching. Section 4. describes the differences between the developed extractor and DEPTA. Section 5. describes the evaluation scheme used to evaluate the developed extractor. Experimental results are given in Section 6. and Section 7. concludes the paper and suggests the future works.
2.
WEB PAGES AND DATA RECORDS
Many web pages, especially those offering products, contain data records. The presentation of such web pages can be significantly different in look for human, but they can be classified into one of two classes : list pages and detail pages. A list page contains one or more objects while a detail page contains only information of one objects. Figure 1 shows an example of a list page. In the page, there are two data regions: horizontal (half upper part) and vertical (half lower part). A data region is a collection of similar data records (information of objects of similar type) that exist on contiguous part of a web page. In every data region data records are formatted uniformly using the same template. While Figure 2, on the other hand, is an example of a detail page.
Figure 1 Example of a list page containing horizontal and vertical data region
Information Extraction from Web Pages Using Automatic
Pattern Discovery Method Based on Tree Matching
Sigit Dewanto
Computer Science Departement
Gadjah Mada University
Yogyakarta
[email protected]
Khabib Mustofa
Computer Science Departement
This paper discuss an approach applicable to list pages only, not including detail pages.
3.
DATA EXTRACTION BASED ON
PARTIAL TREE ALIGNMENT (DEPTA)
Automatic pattern discovery methods has been studied by researchers because of the shortcomings of manual extraction and wrapper induction methods. Both methods are difficult to implement for a large number of sites. Moreover, if the encoding template used by a site changed, the existing wrapper for the site will become invalid.Figure 2 Example of a detail page containing information of an iPod
Automatic pattern extraction is possible because the data records in the web pages are usually encoded using a very small number of fixed templates. It is possible to find these templates by mining repeated patterns in multiple data records. Both string matching and tree matching based methods can be used to mine these patterns. Tree matching can be used because web pages are written in HyperText Markup Language (HTML) so they can be modeled as trees.
DEPTA is one of the automatic pattern discovery method based on tree matching developed by Zhai and Liu [4]. DEPTA is able to extract data records from a single list page. List page is page that contains one or more list of objects (for example, a page that displays a list of books including their authors, publishers, prices, etc.).
The general architecture of DEPTA illustrated in Fig. 3. The input to the system is a web page contains one or more data records (a page can have more than one area that contains regularly structured data records). The system is composed of the following main components:
1. DOM tree builder (or tag tree builder): The function of this component is to build a document object model (DOM) tree from an inputted page. In DEPTA this component implemented using MSHTML API, which returns the rendering information of each HTML element in the browser (also called visual information). Using the rendering information and the HTML opening tags, this component build the DOM tree of an input page.
2. Data regions identifier: This component traverse the DOM tree top down to identify each area or region in the inputted page that contains a list of similar data records. 3. Data records identifier: This component detects the
boundaries of individual data records in each data region (an area that contains data records describing similar objects). The output of this component is a list of data records (still in HTML) from each data region.
Figure 3 . The general architecture of the DEPTA system [4]
4. Data item extractor: This component aligns and extracts data items (analog to cell in a table) using partial tree alignment algorithm. The output of this component is one or more table (in accordance with the number of the identified data regions) that contains aligned data items. For an inputted page with multiple data regions, data from each region is put in a separate table.
The tree matching algorithm used in DEPTA is simple tree matching (STM). This algorithm used in data regions identifier, data records identifier, and data items extractor (used in partial tree alignment). In DEPTA, the number of tree matching computation is minimized by using visual information.
4.
DEVELOPMENT OF EXTRACTOR
The extractor created in this research, called Structured Data Extractor (SDE), is developed based on DEPTA and implemented using open source web scripting language PHP combined with JavaScript. There are some differences between SDE and DEPTA implementation. The differences are as follows:
1. In tag tree building, DEPTA uses HTML opening tags and visual information while SDE uses HTML DOM parser.
2. DEPTA uses visual information in tag tree building, tree matching, and gap between data records candidates detection while SDE doesn't.
3. In the scoring of similarity between data records candidates, DEPTA only considers tags that contain text while SDE considers all tags.
4.1
Tag Tree Building using HTML DOM
Parser
The first step done by SDE in data records extraction is building tag tree from an input web page. The HTML parser used in the tag tree building is an open source library, NekoHTMLParser, which is a DOM-based parser. A DOM-based parser builds a DOM tree from a web page. Nodes in a DOM tree have different types : Element, Text, Attribute, Comment, etc. Each HTML tag (or a pair of HTML tags) in a web page will be represented as an Element node. Each text within a pair of HTML tags will be represented as a Text node and will be a child of the Element node representing the pair of HTML tags. Each attribute in a HTML tag will be represented as an Attribute node and will be a child of the Element node representing the HTML tag. Each comment in HTML will be represented as a Comment node.
Because the thing needed in the structured data extraction method is the tag tree structure, not the entire DOM tree structure, we need to build tag tree based on the DOM tree. Each node in a tag tree represents each tag in a web page. In other words, there is only one type of node in a tag tree : the node representing HTML tag in a web page (the same as Element node in DOM tree). Each text within a pair of HTML tags in a web page will be represented as an innerText property of the node representing the pair of HTML tags.
5.
EVALUATION SCHEME
SDE is executed with web pages from 20 websites as inputs. From each website, two different web pages containing structured data are selected as samples. Fourteen of twenty websites are of job vacancies from Indonesia information provider. The other websites are international vacancies information provider.
The following parameters are recorded for each execution of SDE: 1. The numbers of target data records contained in the
input page. This parameter is called actual data records. 2. The numbers of correctly extracted actual data records 3. The numbers of incorrectly extracted actual data records.
For a data record, a wrongly extracted data record means that only part of the content of the data record is
7. The numbers of correctly aligned actual data items from the correctly extracted actual data records. By correctly aligned data items we mean that those data items aligned with other data items containing the same type of information.
8. The numbers of incorrectly aligned actual data items from the correctly extracted actual data records. By
incorrectly aligned data items we mean that those data items that contain the same type of information are not aligned in the same column. For example if there are five data items that should be aligned in the same column (because they contain same type of information), but in the actual alignment three data items are aligned in one columns and the other two data items are aligned in another different column. Another case of incorrectly aligned data items is some data items containing different types of information aligned in one column. 9. The numbers of unaligned (unidentified by SDE) actual
data items from the correctly extracted actual data records.
10. The numbers of aligned data items from the correctly extracted actual data records. Aligned data items are not always the same with the actual data items from correctly extracted data records.
After all parameters being recorded, precision and recall value of data records extraction and data items alignment for each input page. Precision and recall are widely used measures to evaluate information retrieval systems and have been adapted to evaluate information extraction system [1].
In the evaluation of SDE, precision of data records extraction divided into two kinds. The first is precision that consider irrelevant extracted data records. In this case the precision value of data records extraction is the number of correctly extracted actual data records divided by the number of extracted data records by SDE. The second is precision that doesn't consider irrelevant extracted actual data records. In this case the precision value of data records is the number of correctly extracted actual data records divided by the number of extracted data records, both correctly and incorrectly. The recall value of data records extraction is the number of correctly extracted actual data records divided by the number of actual data records in the input web page.
extracted because they are not in the contiguous area (separated). The used extraction method can only identify data records if there are two or more data records of the same type located in one contiguous area.
Table 1. Data Records Extraction Result
No. input Pages ACT COR WRG MISS FOU
1. datakarir.com 1 18 18 0 0 77 2. datakarir.com 2 18 18 0 0 27 3. lowongan-pekerjaan.net 1 30 30 0 0 156 4. lowongan-pekerjaan.net 2 30 30 0 0 32 5. jobitcom.com 1 14 14 0 0 149 6. jobitcom.com 2 14 14 0 0 51 7. gkarir.com 1 12 12 0 0 99 8. gkarir.com 2 7 5 2 0 97 9. jobindo.com 1 10 10 0 0 52 10. jobindo.com 2 20 20 0 0 28 11. ww.jobsdb.com 1 50 50 0 0 152 12. ww.jobsdb.com 2 50 50 0 0 140 13. bursa-kerja.ptkpt.net 1 238 0 238 0 49 14. bursa-kerja.ptkpt.net 2 230 0 230 0 51 15. duniakarir.com 1 10 10 0 0 12 16. duniakarir.com 2 10 10 0 0 12 17. jobstreet.com 1 50 50 0 0 71 18. jobstreet.com 2 50 50 0 0 69 19. klikkarir.com 1 18 18 0 0 54 20. klikkarir.com 2 10 10 0 0 58 21. lowongankerja.com 1 5 5 0 0 23 22. lowongankerja.com 2 5 5 0 0 23 23. karir.tv 1 20 20 0 0 61 24. karir.tv 2 20 20 0 0 61 25. karir.com 1 34 34 0 0 46 26. karir.com 2 109 109 0 0 121 27. lowongan-kerja.terbaru.com 1 9 9 0 0 36 28. lowongan-kerja.terbaru.com 2 9 9 0 0 38 29. yahoo.com 1 30 30 0 0 103 30. yahoo.com 2 30 30 0 0 96 31. jobs.com 1 25 24 0 1 34 32. jobs.com 2 50 50 0 0 55 33. indeed.com 1 10 10 0 0 49 34. indeed.com 2 10 10 0 0 49 35. efinancialcareers.sg 1 30 30 0 0 105 36. efinancialcareers.sg 2 30 30 0 0 105 37. careerone.com.au 1 10 10 0 0 44 38. careerone.com.au 2 15 15 0 0 56 39. careerbuilder.com 1 10 10 0 0 79 40. careerbuilder.com 2 4 4 0 0 39
There is only one unidentified actual data records by SDE, that is an actual data record in the first of the selected pages from jobs.com. This actual data record is not extracted because it's too different with the other data records in the same data region (i.e., similarity threshold is not reached).
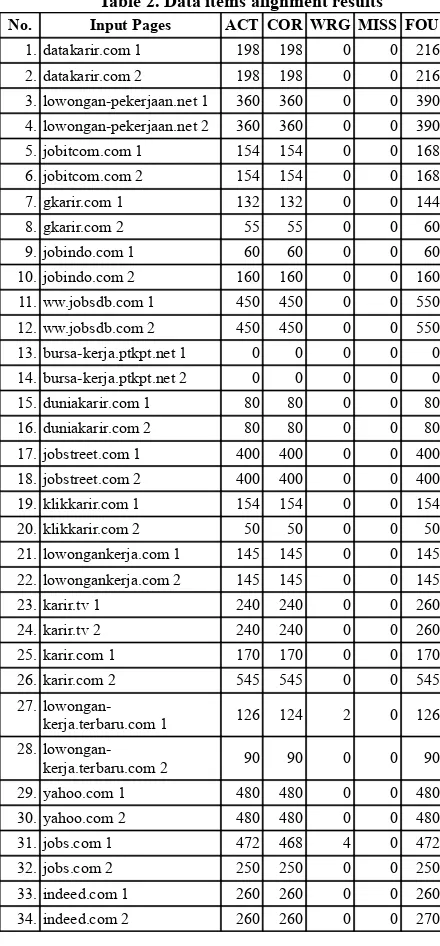
Table 2 shows the experimental results of the data items alignment from correctly extracted actual data records from each input web page. The “ACT” column shows the numbers of actual data items in the correctly extracted actual data records (actual data items). The “COR” column shows the numbers of correctly aligned actual data items. The “WRG” column shows the numbers of incorrectly aligned actual data items. The “MISS” column shows the numbers of unaligned (unidentified by SDE) actual data items. The “FOU” column shows the numbers of aligned data items from the correctly extracted actual data records.
Table 2. Data items alignment results
No. Input Pages ACT COR WRG MISS FOU
1. datakarir.com 1 198 198 0 0 216 2. datakarir.com 2 198 198 0 0 216 3. lowongan-pekerjaan.net 1 360 360 0 0 390 4. lowongan-pekerjaan.net 2 360 360 0 0 390 5. jobitcom.com 1 154 154 0 0 168 6. jobitcom.com 2 154 154 0 0 168 7. gkarir.com 1 132 132 0 0 144 8. gkarir.com 2 55 55 0 0 60 9. jobindo.com 1 60 60 0 0 60 10. jobindo.com 2 160 160 0 0 160 11. ww.jobsdb.com 1 450 450 0 0 550 12. ww.jobsdb.com 2 450 450 0 0 550 13. bursa-kerja.ptkpt.net 1 0 0 0 0 0 14. bursa-kerja.ptkpt.net 2 0 0 0 0 0 15. duniakarir.com 1 80 80 0 0 80 16. duniakarir.com 2 80 80 0 0 80 17. jobstreet.com 1 400 400 0 0 400 18. jobstreet.com 2 400 400 0 0 400 19. klikkarir.com 1 154 154 0 0 154 20. klikkarir.com 2 50 50 0 0 50 21. lowongankerja.com 1 145 145 0 0 145 22. lowongankerja.com 2 145 145 0 0 145 23. karir.tv 1 240 240 0 0 260 24. karir.tv 2 240 240 0 0 260 25. karir.com 1 170 170 0 0 170 26. karir.com 2 545 545 0 0 545 27.
lowongan-kerja.terbaru.com 1 126 124 2 0 126 28.
35. efinancialcareers.sg 1 210 210 0 0 210 36. efinancialcareers.sg 2 210 210 0 0 210 37. careerone.com.au 1 60 60 0 0 60 38. careerone.com.au 2 135 135 0 0 135 39. careerbuilder.com 1 40 40 0 0 40 40. careerbuilder.com 2 16 16 0 0 16
Tabel 3 describes the value of precision and recall of the data records extraction and data items alignment resulting from the extraction of the 40 web sites. Column “A” shows the precision score (in percent) of extracting data records considering irrelevant data records. Column “B” shows the precision score (in percent) of extracting data records without considering irrelevant data records. Column “C” indicates the recall (in percent) of extracting data records. Column “D” shows the precision (in percent) of aligning the data items. Column “E” demonstrates the recall (in percent) of aligning data items.
The table 3 shows that the arithmetic mean of the precisions of the data records extraction that consider irrelevant data records is low (below 50%). This shows the shortcoming of the extraction method using automatic pattern discovery: there are many irrelevant data records in the extraction results. It is also shown that the arithmetic mean of the recalls of the data items alignment is below 100% despite there are no unaligned data items. It is because of the data items that contain only non-printed characters (e.g. space, tab) or formatting tags (like BR).
Table 3. Precisions and recalls of the data records extractions and data items alignments
No. Input Pages A B C D E
1. datakarir.com 1 23.38 100 100 91.67 100 2. datakarir.com 2 66.67 100 100 91.67 100 3. lowongan-pekerjaan.net 1 19.23 100 100 92.31 100 4. lowongan-pekerjaan.net 2 93.75 100 100 92.31 100 5. jobitcom.com 1 9.4 100 100 91.67 100 6. jobitcom.com 2 27.45 100 100 91.67 100 7. gkarir.com 1 12.12 100 100 91.67 100 8. gkarir.com 2 5.15 71.43 71.43 91.67 100 9. jobindo.com 1 19.23 100 100 100 100 10. jobindo.com 2 71.43 100 100 100 100 11. ww.jobsdb.com 1 32.89 100 100 81.82 100 12. ww.jobsdb.com 2 35.71 100 100 81.82 100 13. bursa-kerja.ptkpt.net 1 0 0 0 100 100 14. bursa-kerja.ptkpt.net 2 0 0 0 100 100 15. duniakarir.com 1 83.33 100 100 100 100 16. duniakarir.com 2 83.33 100 100 100 100 17. jobstreet.com 1 70.42 100 100 100 100 18. jobstreet.com 2 72.46 100 100 100 100 19. klikkarir.com 1 33.33 100 100 100 100 20. klikkarir.com 2 17.24 100 100 100 100 21. lowongankerja.com 1 21.74 100 100 100 100 22. lowongankerja.com 2 21.74 100 100 100 100 23. karir.tv 1 32.79 100 100 92.31 100 24. karir.tv 2 32.79 100 100 92.31 100
25. karir.com 1 73.91 100 100 100 100 26. karir.com 2 90.08 100 100 100 100 27. lowongan-kerja.terbaru.com 1 25 100 100 98.41 98.41 28. lowongan-kerja.terbaru.com 2 23.68 100 100 100 100 29. yahoo.com 1 29.13 100 100 100 100 30. yahoo.com 2 31.25 100 100 100 100 31. jobs.com 1 70.59 100 96 99.15 99.15 32. jobs.com 2 90.91 100 100 100 100 33. indeed.com 1 20.41 100 100 100 100 34. indeed.com 2 20.41 100 100 96.3 100 35. efinancialcareers.sg 1 28.57 100 100 100 100 36. efinancialcareers.sg 2 28.57 100 100 100 100 37. careerone.com.au 1 22.73 100 100 100 100 38. careerone.com.au 2 26.79 100 100 100 100 39. careerbuilder.com 1 12.66 100 100 100 100 40. careerbuilder.com 2 10.26 100 100 100 100
Rata-rata 37.26 94.29 94.19 96.92 99.94
7.
CONCLUSION AND FUTURE
WORKS
Structured data extractor using automatic pattern discovery method based on tree matching has been successfully developed and evaluated. The method being used is based on DEPTA with several differences in the implementation. Experimental results show that almost all structured data being targeted can be successfully extracted (the average of the recall values for data records extraction and data items alignment are above 90%). However, the extractor also extract other structured data that not being targeted , i.e. irrelevant data, showed by the average precision values of the data records extraction with irrelevant data records being considered. Because of this, the users must manually filter the extraction results. It can be happen because the extraction used method only consider the tree structure pattern and it doesn't able to understand the information contained in data records.
Actual data records are incorrectly extracted by SDE because the actual data records structures are different with the assumptions used by the extraction method or there is only one actual data record in a contiguous area (separated from other data records of similar type).
Actual data records are not extracted (unidentified) by SDE because the similarity threshold is not satisfied. Actual data items are incorrectly aligned because the used extraction method only match the tag tree structure and string in the data items without understanding the meaning of the data items.
The followings could be considered some steps worth examining as the future works:
2. Integrating the developed system with information extraction tools based on natural language processing to improve the precisions of data records extraction and data items alignment. It can be used to overcome the shortcoming of the extraction method that cannot understand the information contained in data items so the irrelevant data records will be extracted.
8.
REFERENCES
[1] Benchalli, S S., Hiremath, P.S., Algur, S.P. , dan Udapudi, V.R., "Mining Data Regions from Web Pages" , 2005
[2] Breuel, T.M.,"Information Extraction from HTML Documents by Structural Matching" , Proceedings of the 2nd International Workshop on Web Document Analysis (WDA2003) PARC, Inc., Palo Alto, CA, USA, 2003, [online]:
http://www.csc.liv.ac.uk/~wda2003/Papers/Section_I/Paper_3.pdf access date 12 Feb 2010
[3] Yeonjung, K., Jeahyun, P., Taehwan, K., dan Joongmin, C.,,"Web Information Extraction by HTML Tree Edit Distance Matching" , Proceedings of the International Conference on Convergence Information Technology (ICCIT.2007) Washington, DC, US, 2007, [online]:
http://dx.doi.org/10.1109/ICCIT.2007.398 access date 13 Feb 2010

![Figure 3 . The general architecture of the DEPTA system [4]](https://thumb-ap.123doks.com/thumbv2/123dok/3987636.1931056/2.612.55.296.205.364/figure-general-architecture-depta.webp)