Dosen Pembina:
Dr. Gatot Sugeng Purwono, M.S.
UNIVERSITAS MUHAMMADIYAH JEMBER
FAKULTAS KEGURUAN DAN ILMU PENDIDIKAN
PROGRAM STUDI PENDIDIKAN BIOLOGI
Juni, 2014
1. Dasar–Dasar SPSS
SPSS merupakan salah satu sekian banyak software statistika yang telah dikenal luas dikalangan penggunaannya. Disamping masih banyak lagi software statistika lainnya seperti Minitab, Syastas, Microstat dan masih banyak lagi. SPSS sebagai sebuah tools mempunyai banyak kelebihan, terutama untuk aplikasi di bidang ilmu sosial.
Menu Bar kumpulan perintah-perintah dasar untuk meng-operasikan SPSS. Menu yang terdapat pada SPSS adalah :
a. File
Untuk operasi file dokumen SPSS yang telah dibuat, baik untuk perbaikan pencetakan dan sebagainya. Ada 5 macam data yang digunakan dalam SPSS, yaitu :
(1). Data : dokumen SPSS berupa data (2). Systax : dokumen berisi file syntax SPSS
(3). Output : dokumen yang berisi hasil running out SPSS (4). Script : dokumen yang berisi running out SPSS (5). Database
(a). New : membuat lembar kerja baru SPSS
(b). Open : membuka dokumen SPSS yang telah ada
Secara umum ada 3 macam ekstensi dalam lembar kerja SPSS, yaitu; (1). *.spo, yaitu file data yang dihasilkan pada lembar data editor, (2). *.sav, yaitu file text/obyek yang dihasilkan oleh lembar output, dan (3). *.cht, file obyek gambar/chart yang dihasilkan oleh chart window.
(a). Read Text Data, membuka dokumen dari file text (yang berekstensi txt), yang bisa dimasukkan/dikonversi dalam lembar data SPSS
(b). Save, menyimpan dokumen/hasil kerja yang telah dibuat.
(c). Save As, menyimpan ulang dokumen dengan nama/tempat/type dokumen yang berbeda
(d). Page Setup, mengatur halaman kerja SPSS Toolba
r
(e). Print, mencetak hasil output/data/syntaq lembar SPSS. Ada 2 option/pilihan cara mencetak, yaitu :
o All visible output, mencetak lembar kerja secara keseluruhan o Selection, mencetak sesuai keinginan yang kita sorot/blok
(f). Print Preview, melihat contoh hasil cetakan yang nantinya diperoleh (g). Recently used data, berisi list file data yang pernah dibuka sebelumnya. (h). Recently used file, berisi list file secara keseluruhan yang pernah dikerjakan
b. Edit
Untuk melakukan pengeditan pada operasi SPSS baik data, serta pengaturan/ option untuk konfigurasi SPSS secara keseluruhan.
(1). Undo, pembatalan perintah yang dilakukan sebelumnya
(2). Redo, perintah pembatalan perintah redo yang dilakukan sebelumnya
(3). Cut, penghapusan sebual sel/text/obyek, bisa dicopy untuk keperluan tertentu dengan perintah dari menu paste
(4). Paste, mempilkan sebua sel/text/obyek hasil dari perintah copy atau cut (5). Paste after, mengulangi perintah paste sebelumya
(6). Paste spesial, perintah paste spesial, yaitu bisa konvesri ke gambar, word, dll (7). Clear, menghapusan sebuah sel/text/obyek
(8). Find, mencari suatu text
(9). Options, mengatur konfigurasi tampilan lembar SPSS secara umum
c. View
Untuk pengaturan tambilan di layar kerja SPSS, serta mengetahui proses-proses yang sedang terjadi pada operasi SPSS.
(1). Status Bar, mengetahui proses yang sedang berlangsung (2). Toolbar, mengatur tampilan toolbar
(3). Fonts, ukuran font pada data editor SPSS
(a). Outline size, ukuran font lembar output SPSS (b). Outline font, jenis font lembar output SPSS (4). Gridlines, mengatur garis sel pada editor SPSS
(5). Value labels, mengatur tampilan pada editor untuk mengetahui value label
d. Data
Menu data digunakan untuk melakukan pemrosesan data.
(1). Define Dates, mendefinisikan sebuah waktu untuk variable yang meliputi jam, tanggal, tahun, dan sebagainya
(2). Insert Variable, menyisipkan kolom variable (3). Insert case, menyisipkan baris
(4). Go to case, memindahkan cursor pada baris tertentu (5). Sort case, mengurutkan nilai dari suatu kolom variable
(6). Transpose, operasi transpose pada sebuah kolom variable menjadi baris
(7). Merge files, menggabungkan beberapa file dokumen SPSS, yang dilakukan dengan penggabungan kolom-kolom variablenya
(8). Split file, memecahkan file berdasarkan kolom variablenya
Menu transform dipergunakan untuk melakukan perubahan-perubahan atau penambahan data.
(1). Compute, operasi aritmatika dan logika untuk
(2). Count, untuk mengetahui jumlah sebuah ukuran data tertentu pada suatu baris tertentu (3). Recode, untuk mengganti nilai pada kolom variable tertentu, sifatnya menggantikan
(into same variable) atau merubah (into different variable) pada variable baru
(4). Categorize variable, merubah angka rasional menjadi diskrit (5). Rank case, mengurutkan nilai data sebuah variable
f. Analyse
Menu analyse digunakan untuk melakukan analisis data yang telah kita masukkan ke dalam komputer. Menu ini merupakan menu yang terpenting karena semua pemrosesan dan analisis data dilakukan dengan menggunakan menu correlate, compare mens, regresion.
g. Graph
Menu graph digunakan untuk membuat grafik, diantaranya ialah bar, line, pie, dll h. Utilities
Menu utilities dipergunakan untuk mengetahui informasi variabel, informasi file, dll
i. Ad-Ons
Menu ad-ons digunakan untuk memberikan perintah kepada SPSS jika ingin menggunakan aplikasi tambahan, misalnya menggunakan alikasi Amos, SPSS data entry, text analysis, dsb
j. Windows
Menu windows digunakan untuk melakukan perpindahan (switch) dari satu file ke file lainnya
k. Help
Menu help digunakan untuk membantu pengguna dalam memahami perintah-perintah SPSS jika menemui kesulitan
2. Memulai SPSS Data Editor
Sebelum melakukan analisis data statistik, perlu memasukkan data terlebih dulu. Bila file data belum ada, maka anda harus ketik file data pada lembar SPSS Data Editor. Untuk membuat file data yang baru, klik file, kemudian klik New dan selanjutnya klik Data. Halaman SPSS data editor yang aktif, terdiri dari dua lembar. Lembar pertama adalah Data View, yaitu tempat untuk memasukkan data (gambar 1). Sedangkan lembar kedua adalah Variable View, yaitu tempat memberi nama variabel dan mendefinisikan karakteristik lain dari variabel tersebut (gambar 2).
Gambar 1. Lembar data editor pertama “Data View”
Gambar 2. Lembar data editor kedua “Variabel View” Pada lembar variabel view:
1. Memberi nama variabel (variable name) dengan panjang maksimal “8 karakter” pada kolom name. Kalau anda tidak memberi nama variabel, maka SPSS akan menggunakan nama variabel; VAR00001, VAR00002, VAR00003, dan seterusnya.
Gambar 3. Menentukan type variabel
3. Menentukan lebar data atau banyaknya angka/karakter data pada kolom “Width”. 4. Menentukan banyaknya angka dibelakang koma pada kolom “Decimals”.
5. Memberi penjelasan nama variabel pada kolom “Label”, karena nama variabel pada kolom “Name” hanya mempunyai panjang maksimal 8 karakter, maka untuk menjelaskan nama variabel yang panjang, penjelasannya dapat diberikan pada kolom Label.
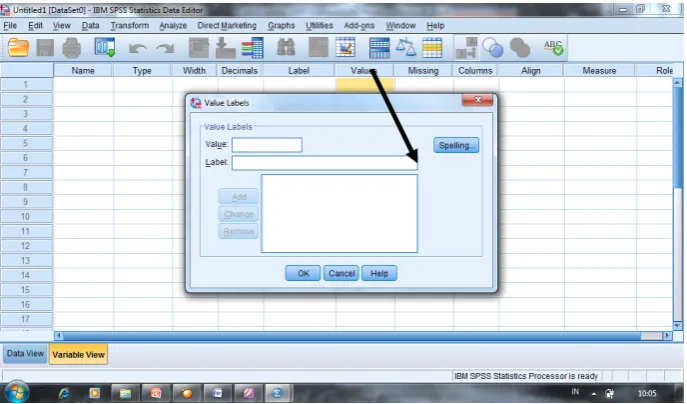
6. Memberi penjelasan nilai data pada kolom “Values”. Misalkan untuk variabel jenis kelamin dapat diberi penjelasan nilai data ‘1=pria’ dan ‘2=perempuan’.
Gambar 4. Memberi nilai data pada “Values”
Perhatikan bahwa anda bebas memilih kode untuk misssing values, selama kode yang anda pilih berbeda dari nilai data.
8. Menentukan lebar kolom display pada kolom “Columns”.
9. Menentukan alignment pada kolom “Align”: untuk rata kanan pilih right, untuk rata kiri pilih left atau untuk posisi di tengah pilih center. Default untuk data numeric adalah rata kanan (right) dan default untuk data string adalah rata kiri (left).
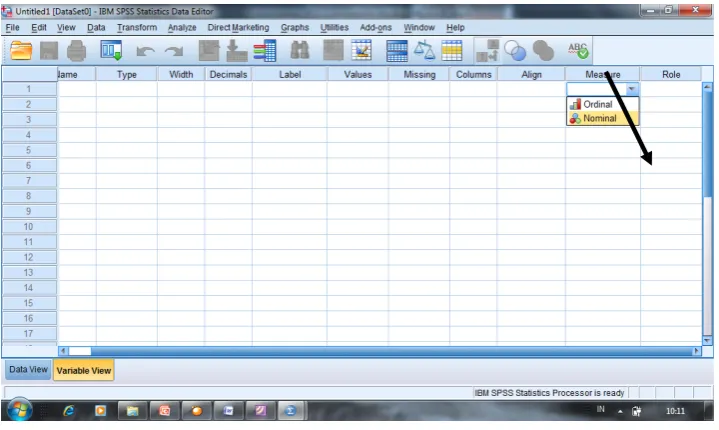
10. Menentukan skala data (nominal, ordinal, interval, ratio) pada kolom Measure. SPSS selalu mengansumsikan tipe data numeric memiliki skala interval atau skala ratio (scale). Untuk data skala nominal atau skala ordinal anda harus menentukan sendiri pada kolom Measure ini.
Gambar 5. Menentukan skala data
3. Menyusun Tabel Frekuensi Bergolong dengan SPSS
Tabel Frekuensi yang dihasilkan oleh SPSS berbeda dengan cara manual yang menggunakan kelas interval. Bila menggunakan yang kelas interval di SPPS dihitung dahulu jumlah kelas interval dan isi kelasnya secara manual. Tabel Frekuensi secara otomatis akan disusun oleh program SPSS.
Langkah menyusun tabel frekuensi dengan program SPSS:
Gambar 6. Langkah menyusun tabel
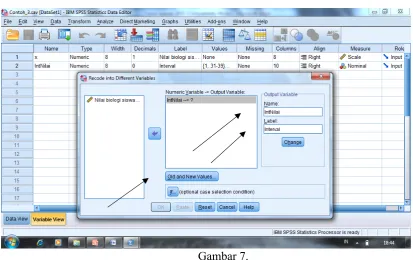
Pada variabel nilai dipindah ke kanan, Name pada Output Variable diberi nama = intNilai dan Label diisi = Interval. Sampai langkah ini klik Tombol Old and New Values.
Gambar 7.
Klik Range, pada Range diisi 31, pada through diis 39, pada Value diisi angka 1, kemudian klik Add. Langkah ini dijalankan sampai 7 kali, karena tabel frekuensi yang kita coba ada 7
Gambar 7.
Masuk menu Analyze > Descriptive Statistics > Frekuencies. Langkah berikutnya sama dengan sebelumnya, hanya bedanya pada variabel nilai yang masih berada pada sebalah kanan, dikembalikan ke kiri dan digandi dengan variabel intnilai (jadi yang dibuat tabel frekuensi adalah variabel intnilai) seperti terlihat pada tabel berikut:
A. UJI NORMALITAS DENGAN SPSS
Uji normalitas data adalah hal yang lazim dilakukan sebelum sebuah metode statistik. Tujuan uji normalitas adalah untuk mengetahui apakah distribusi sebuah data mengikuti atau mendekati distribusi normal, yakni distribusi data yang mampunyai pola seperti distribusi normal (distribusi data tersebut tidak menceng ke kiri atau ke kanan). Misalkan dalam sebuah penelitian pendidikan ingin diketahui apakah data dalam penelitian tersebut berdistribusi normal, data penelitian adalah sebagai berikut:
No.
Responden Sex Nilai harian Nilai Rapot 1 Keterangan sex: 1=laki-laki, 2=perempuan
2. Buat semua keterangan variabel di variable view seperti gambar berikut:
4. Lakukan analisis dengan cara: memilih menu Analyze, lalu submenu Nonparametriks Test. Dari serangkaian pilihan yang ada, pilih 1-Sample K-S, akan muncul kotak dialog sebagai berikut:
6. Klik Options sehingga muncul kotak dialog sebagai berikut, kemudian centang Descriptive lalu klik Continue.
8. Klik OK sehingga akan muncul Output sebagai berikut:
Nilai Harian 15 70,267 14,7864 40,0 95,0
Nilai Rapor 15 77,933 8,7788 60,0 90,0
One-Sample Kolmogorov-Smirnov Test
Normal Parametersa,b Mean 1,40 70,267 77,933
Std. Deviation ,507 14,7864 8,7788
Most Extreme
Differences AbsolutePositive ,385,385 ,147,077 ,123,085
Negative -,282 -,147 -,123
Kolmogorov-Smirnov Z 1,491 ,568 ,476
Asymp. Sig. (2-tailed) ,023 ,904 ,977
a. Test distribution is Normal. b. Calculated from data. 9. Cara membaca Output tersebut adalah sebagai berikut:
a. Deskriptif
Catatan: pada sex tidak diperbolehkan menggunakan mean, sebab sex adalah data nominal
b. Kolmogorov smirnov (1). Analisis:
Ho : Populasi berdistribusi normal Ha : Populasi tidak berdistribusi normal (2). Dasar pengambilan keputusan adalah berdasarkan probabilitas
Jika nilai probabilitas > 0,05 maka Ho diterima Jikan nilai probabilitas ≤ 0,05 maka Ho ditolak (3). Keputusan
(a). Sex: Terlihat bahwa pada kolom signifikan (Asymp. Sig (2-tailed)) adalah 0,023 atau probabilitas kurang dari 0,05 maka Ho ditolak yang berarti populasi tidak berdistribusi normal.
(b). Terlihat bahwa pada kolom signifikan (Asymp. Sig (2-tailed) adalah 0,904 atau probabilitas lebih dari 0,05 maka Ho diterima yang berarti populasi berdistribusi normal.
(c). Terlihat bahwa pada kolom signifikan (Asymp. Sig (2-tailed)) adalah 0,977 atau probabilitas lebih dari 0,05 maka Ho diterima yang berarti populasi berdistribusi normal.
B. UJI VALIDITAS DENGAN SPSS
Sumber data sebuah penelitian ada kalanya menggunakan data dari hasil kuesioner. Tentunya dalam penyusunan kuesioner harus benar-benar bisa menggambarkan tujuan dari penelitian (valid). Uji validitas untuk mengukur kelayakan butir-butir pertanyaan dalam kuesioner tersebut dapat mendefinisikan suatu variabel. Daftar pertanyaan pada umumnya untuk mendukung suatu kelompok variabel tertentu. Uji validitas dilakukan pada setiap butir pertanyaan. Hasilnya dibandingkan dengan r tabel | df=n-k dengan tingkat kesalahan 5%. Jika r tabel Jika r tabel < r hitung, maka butir soal disebut valid.
5 2 2 3 7
6 4 2 4 10
7 4 4 3 11
8 1 1 1 3
9 2 2 1 5
10 3 5 5 13
11 3 4 4 11
12 2 4 5 11
13 5 2 4 11
14 2 4 2 8
15 4 4 4 12
16 1 4 2 7
17 1 4 1 6
18 2 2 4 8
19 1 2 1 4
21 4 4 5 13
22 2 2 2 6
23 2 2 2 6
24 2 1 1 4
25 5 4 5 14
26 4 3 5 12
27 5 5 5 15
28 2 4 4 10
29 3 3 5 11
30 5 5 4 14
31 1 3 3 7
32 2 4 3 9
33 2 2 4 8
34 5 1 3 9
37 2 4 3 9
38 1 1 3 5
39 2 3 3 8
40 2 3 2 7
41 2 4 5 11
42 3 3 3 9
43 3 5 3 11
44 2 2 3 7
45 3 4 5 12
46 1 2 3 6
47 1 3 3 7
48 2 4 4 10
49 1 2 2 5
50 5 4 3 12
Keterangan:
x12 (jenis pekerjaan) : 1. Petani, 2. Pedagang, 3. Pegawai Swasta, 4. PNS, 5 TNI-POLRI
x13 (status Sosial Ekonomi : 1. Miskin sekali, 2. Miskin, 3. Cukup, 4. Kaya, 5. Kaya sekali Langkah 1 : Masukkan data ke dalam data editor SPSS. Untuk memberikan
nama/label variabel klik Variable view (x11, x12, x13 dan total_x)
Langkah 4 : Selanjutnya pindahkan masing-masing indikator x11, x12, x13 dan total_x ke sebelah kanan pada kolom variables dengan cara memblok masing-masing indikator kemudian klik tanda panah tengah.
Langkah 5 : Klik OK. Setelah itu akan tampak kota seperti berikut Correlations
*. Correlation is significant at the 0.05 level (2-tailed). **. Correlation is significant at the 0.01 level (2-tailed).
Catatan: ada beberapa buku yang menggunakan nilai korelasi diatas 0,3. Tetapi ada juga yang menentukan nilai korelasi diatas 0,5. Batas keduanya diakui dan bisa diterima.
C. UJI RELIABILITAS DENGAN SPSS
Selain harus valid, kuesioner sebagai alat ukur harus konsisten bila pertanyaan tersebut dijawab dalam waktu yang berbeda (reliabel). Untuk menilai kestabilan ukuran dan konsistensi responden dalam menjawab kuesioner. Kuesioner tersebut mencerminkan konstruk sebagai dimensi suatu variabel yang disusun dalam bentuk pertanyaan. Uji reliabilitas dilakukan secara bersama-sama terhadap seluruh pertanyaan. Jika nilai alpha>0.60, disebut reliable. Dengan menggunakan data yang sama, langkah uji reliabilitas adalah sebagai berikut:
Langkah 1 : Dari layar Data editor klik analyze Scale Reliability Analysis
Langkah 2
Langkah 3 : Klik Statistics pada sebelah kanan atas
Langkah 4 : Pada kotak Reliability Analysis: Statistics tandai (√) kolom scale if item deleted lalu Continue.
lalu Continue OK.
Reliability Statistics
Hasil perhitungan menunjukkan nilai Cronbach’s Alpha = 0,683 yang lebih besar dari 0,60 berarti instrumen penelitian dikatakan reliabel
Catatan: ada beberapa buku yang menggunakan batas nilai reliabilitas di atas 0,6. Tetapi ada juga yang menentukan nilai reliabilitas diatas 0,7. Batas keduanya diakui dan bisa
Uji T Satu Sampel (One Sample T-Test)
Uji ini digunakan untuk mengetahui perbedaan mean (rerata) populasi atau penelitian
terdahulu dengan mean data sampel penelitian sekarang.
Misalnya Seorang Kepala Puskesmas menyatakan bahwa rata-rata perhari jumlah kunjungan pasien adalah 20 orang. Untuk membuktikan pernyatan tsb, kemudian di ambil sampel random sebanyak 20 hari kerja dan diperoleh rata-rata 23 orang dengan standar deviasi 6 orang.
Sekarang kita akan menguji apakah rata-rata jumlah kunjungan pasien sebelumnya berbeda
secara statistik dengan yang saat ini.
Langkah-langkah pengujian.
Ha ≠ 20 ( ada perbedaan kunjungan pasien tahun lalu dengan saat ini )
2. STATISTIK UJI
Uji t satu sampel
KETERANGAN : x = rata-rata sampel
µ = rata-rata populasi/penelitian terdahulu S = Standar Deviasi
n = jumlah (banyaknya) sampel Perhitungan :
DF = n – 1 → 20 -1 = 19, di tabel T, p value terletak antara 0,025 dan 0,001. 3. KEPUTUSAN STATISTIK
Karena nilai P pada tabel (< 0,025) yang berarti kurang dari nilai α = 0,05, maka Ho dapat kita ditolak
4. KESIMPULAN
Uji T Satu Sampel dengan SPSS
Written By Malonda Gaib on Senin, 21 Maret 2011 | 21.3.11
Sudah tau kan uji T satu sampel, kalau belum baca dulu postingan yang ini, kalau yang dulu hitungannya manual, sekarang kita akan apikasikan di SPSS :
1. Buka SPSS anda.
2. Misalkan saya memiliki datanya seperti di bawah ini :
5. Setelah itu akan muncul jendela seperti ini :
6. Pilih variabel "kunjungan pasien", lalu klik tanda 'segitiga' untuk memindahkan variabel tersebut ke kotak 'Test Variables'.
7. Isi kotak 'Test Value' dengan angka "20"(angka 20 merupakan rata-rata kunjungan pasien tahun lalu), kemudian klik OK. Hasilnya :
8. Kesimpulan
ternyata pada uji statistik dua sisi (2-tailed) pada taraf nyata α = 0,05, menunjukan ada perbedaan yang bermakna antara kunjungan pasien tahun lalu dengan tahun ini.
Uji T Independen
Uji ini untuk mengetahui perbedaan rata-rata dua populasi/kelompok data yang independen. Contoh kasus suatu penelitian ingin mengetahui hubungan status merokok ibu hamil dengan berat badan bayi yang dilahirkan. Respondan terbagi dalam dua kelompok, yauti mereka yang
merokok dan yang tidak merokok.
Uji T independen ini memiliki asumsi/syarat yang mesti dipenuhi, yaitu : 1. Datanya berdistribusi normal.
2. Kedua kelompok data independen (bebas)
3. variabel yang dihubungkan berbentuk numerik dan kategorik (dengan hanya 2 kelompok)
Secara perhitungan manual ada dua formula (rumus) uji T independen, yaitu uji T yang variannya sama dan uji T yang variannya tidak sama.
Untuk varian sama gunakan formulasi berikut :
nb = banyaknya sampel di kelompok b DF = na + nb -2
Sedangkan untuk varian yang tidak sama gunakan formulasi berikut :
Untuk DF (degrre of freedom) uji T independen yang variannya tidak sama itu berbeda dengan yang di atas (DF= Na + Nb -2), tetapi menggunakan rumus :
Nah... untuk menentukan apakah varian sama atau beda, maka menggunaka rumus :
Bila nilai P > α , maka variannya sama, namun bila nilai P <= α, berati variannya berbeda. Contoh perhitungan secara manual, saya tidak akan berikan disini...capek...hehe. Mungkin
Uji T Independen dengan SPSS
Kesempatan ini akan saya gunakan untuk memberikan contoh penerapan Uji T (T-test) independen di SPSS. Sebagaimana diketahui bahwa uji ini digunakan, bila kita memiliki data kategorik dan numerik.
Sebagai contoh misalnya kita ingin mengetahui apakah ada pengaruh ibu yang merokok dan ibu yang tidak merokok (status merokok merupakan data kateorik) terhadap berat bayi yang dilahirkan (berat bayi lahir merupakan data numerik).Kebetulan saya memiliki filenya, jadi file ini akan saya gunakan untuk tutorial kali ini.
Langkahnya sebagi berikut :
Buka/aktifkan SPSS anda. Kemudian pada menu utama klik File --> Open --> Data, sampai muncul layar seperti di bawah ini :
Pilih file "bbay.sav" dan klik open, akan muncul layar di bawah ini :
Selanjutnya klik pada menu utama SPSS anda Analyze --> Compare Means-->Independent-Samples-T Test :
Lalu akan muncul layar seperti ini :
Pilih variabel "bbayi" dengan cara mengklik variabel tersebut.
Kemudian klik tanda segitiga paling atas untuk memasukan variabel tersebut ke kotak Test variable(s).
Klik variabel "rokok' dan masukan ke kotak Grouping variable.
Klik OK untuk menjalankan prosedur. Pada layar output akan nampak hasil seperti berikut :
Dari tabel Group Statistics, terlihat bahwa rata-rata berat bayi yang dilahirkan oleh ibu yang tidak merokok adalah 3054,96 gram, sedangkan berat bayi yang dilahirkan oleh ibu yang perokok sebesar 2773,24 gram. Namun apakah perbedaan ini berbeda juga secara statistik ? Untuk melihat perbedaan ini kita lihat pada tabel Independent Samples Test. Pada tabel tersebut ada dua baris (sel), sel pertama dengan asumsi bahwa varian kedua kelompok tersebut sama, sedangkan pada sel kedua dengan asumsi bahwa varians kedua kelompok tersebut tidak sama. Untuk memilih sel mana yang akan kita gunakan sebagai uji, maka kita lihat pada kolom uji F, jika Signifikansinya > 0,05 maka asumsinya varian sama sebaliknya jika Sig. <=0,05 maka variannya tidak sama. Dari uji F menunjukan kalau varian kedua kelompok tersebut sama (P-value = 0,221), sehingga sel akan dibaca adlah sel pertama. Dari kolom uji T menunjukan bahwa nilai P = 0,009 untuk uji 2-sisi . Karena P-value lebih kecil dari
α = 0,05 yang berarti Ho ditolak, sehingga dapat kita simpulkan bahwa secara statistik ada perbedaan yang bermakna rata-rata berat bayi yang dilahirkan oleh ibu yang merokok dengan ibu yang tidak merokok dengan kata lain ada pengaruh merokok terhadap berat bayi lahir. Uji tersebut di atas adalah uji 2-sisi, bagaimana kalau uji 1-sisi ? Bila uji yang kita lakukan adalah uji 1-sisi maka nilai P harus dibagi 2 sehingga menjadi P-value = 0,0045.
Uji T Dependen (Berpasangan)
Uji ini untuk menguji perbedaan rata-rata antara dua kelompok data yang dependen. Misalnya untuk mengetahui apakah ada perbedaan berat badan sebelum mengikuti proram
1. Datanya berdistribusi normal.
2. Kedua kelompok data dependen (berpasangan)
3. variabel yang dihubungkan berbentuk numerik dan kategorik (dengan hanya 2 kelompok).
Rumus yang digunakan, sebagai berikut :
KETERANGAN :
δ = rata-rata deviasi (selisih sampel sebelum dan sampel sesudah) SDδ = Standar deviasi dari δ (selisih sampel sebelum dan sampel sesudah)
n = banyaknya sampel DF = n-1
Contoh :
Data sampel terdiri atas 10 pasien pria mendapat obat captoril dengan dosis 6,25 mg. Pasien diukur
tekanan darah sistolik sebelum pemberian obat dan 60 menit sesudah pemberian obat. Peneliti ingin mengetahui apakah pengobatan tersebut efektif untuk menurunkan tekanan darah pasien-pasien tersebut dengan alpha 5%. Adapun data hasil pengukuran adalah sebagai
berikut.
Sebelum : 175 179 165 170 162 180 177 178 140 176 Sesudah : 140 143 135 133 162 150 182 150 175
1. HIPOTESIS :
Ho : δ = 0 (Tidak ada perbedaan tekanan darah sistolik pria antara sebelum dibandingkan sesudah dengan pemberian Catopril)
Ha : δ ≠ 0 (Ada perbedaan tekanan darah sistolik setelah diberikan Catopril dibanding sebelum diberikan obat)
2. STATISTIK UJI
Uji T dua sampel berpasangan (Uji T Dependen) Perhitungan :
δ : -35 -36 -30 - 37 0 -30 5 - 28 35 -16 δrata-rata = -17,2
S = 23,62 n = 10
t = δ = - 17,2 = - 17,2 = -17,2 S/√n 23,62/√10 23,62/3,162 7,469
= -2,302
Df = n - 1 = 10-1 = 9
Dilihat pada tabel t pada df = 19, t = 2,302 diperoleh Pvalue < 0,0253. 3. KEPUTUSAN
Dengan α = 0,05, maka Pvalue < α, sehingga Ho ditolak 4. KESIMPULAN
Uji T Dependen (Berpasangan) dengan SPSS
Uji-t untuk data berpasangan berarti setiap subjek diukur dua kali. Misalnya sebelum dan sesudah dilakukannya suatu intervensi atau pengukuran yang dilakukan terhadap pasangan orang kembar. Dalam contoh ini akan membandingkan data sebelum dengan sesudah intervensi.
Contoh Kasus :
Suatu studi ingin mengetahui pengaruh suatu metode diet, lalu diambil 28 ibu sebagai sampel untuk menjalani program diet tersebut. Pengukuran berat badan yang pertama (BBIBU_1) dilakukan sebelum kegiatan penyesuaian diet dilakukan, dan pengukuran berat badan yang kedua (BBIBU_2) dilakukan setelah dua bulan menjalani penyesuaian diet. Buka SPSS, dan masukan datanya seperti ini :
Dari menu utama, pilihlah: Analyze-->Compare Mean-->Paired-Sample T-test….
Pilih variabel BBIBU_1 dan BBIBU_2 dengan cara mengklik masing-masing variable tersebut.
Kemudian klik tanda ‘segitiga’ untuk memasukkannya ke dalam kotak Paired-Variables. Seperti nampak di bawah ini :
Dari 28 subjek yang diamati terlihat bahwa rata-rata (mean) berat badan dari ibu sebelum intervensi (BBIBU_1) adalah 57.54, dan rata-rata berat badan sesudah intervensi (BBIBU_2) adalah 56,21. Uji ‘t’ yang dilakukan terlihat pada tabel berikut:
Dari hasil uji-t berpasangan tersebut terlihat bahwa rata-rata perbedaan antara BBIBU_1 dengan BBIBU_2 adalah sebesar 1.321. Artinya ada penurunan berat badan sesudah
intervensi dengan rata-rata penurunan sebesar 1.32 kg.
Hasil perhitungan nilai “t” adalah sebesar 5,133 dengan p-value 0.000 dapat ditulis 0,001 (uji 2-arah). Hal ini berarti kita menolak Ho dan menyimpulkan bahwa secara statistik ada perbedaan yang bermakna antara rata-rata berat badan sebelum dengan sudah intervensi. Dari hasil di atas kita bisa menilai bahwa program diet tersebut berhasil.
Uji One Way Anova
ANOVA merupakan lanjutan dari uji-t independen dimana kita memiliki dua kelompok percobaan atau lebih. ANOVA biasa digunakan untuk membandingkan mean dari dua kelompok sampel independen (bebas). Uji ANOVA ini juga biasa disebut sebagai One Way
Analysis of Variance.
Asumsi yang digunakan adalah subjek diambil secara acak menjadi satu kelompok n. Distribusi mean berdasarkan kelompok normal dengan keragaman yang sama. Ukuran sampel antara masing-masing kelompok sampel tidak harus sama, tetapi perbedaan ukuran kelompok sampel yang besar dapat mempengaruhi hasil uji perbandingan keragaman.
Hipotesis yang digunakan adalah:
H0: µ1 = µ2 … = µk (mean dari semua kelompok sama)
Ha: µi <> µj (terdapat mean dari dua atau lebih kelompok tidak sama)
mengindikasikan penolakan terhadap hipotesis nol, dengan kata lain terdapat bukti bahwa
setidaknya satu pasangan mean tidak sama.
Sebaran perbandingan grafis memungkinkan kita melihat distribusi kelompok. Terdapat beberapa pilihan tersedia pada grafik perbandingan yang memungkinkan kita menjelaskan kelompok. Termasuk box plot, mean, median, dan error bar.
Contoh Kasus.
Evaluasi pada metode pengajaran oleh pengawas untuk anak-anak sekolah Paket C adalah sebagai berikut:
Sebelum diinput ke dalam SPSS susunan data harus dirubah dahulu karena data diatas berbentuk matriks, untuk yang datanya tidak dalam bentuk matriks tabel, tidak perlu dirubah. Tabelnya adalah seperti tabel berikut:
Data ini kemudian dapat dimasukkan ke dalam worksheet
SPSS agar dapat dilakukan analisis.
Hipotesis yang digunakan adalah:
H0 : µ1 = µ2 = µ3 = µ4 = µ5 (mean dari
masing-masing kelompok metode adalah sama)
H1: µ1 <> µ2 <> µ3 <> µ4 <> µ5 (terdapat mean
dari dua atau lebih kelompok metode tidak sama)
Langkah-langkah pengujian One Way ANOVA dengan
software SPSS adalah sebagai berikut:
1. Input data ke dalam worksheet SPSS, tampilannya akan
seperti berikut ini:
Sedangkan Variabel view:
2. Kemudian jalankan analisis dengan memilih ANALYZE – COMPARE MEANS – ONE WAY ANOVA, seperti berikut ini:
4. Setelah variabel dependen dimasukkan pilih OPTION, kemudian checklist Descriptive dan Homogeneity-of-Variance box, seperti gambar berikut kemudian klik continue.
7. Sedangkan Output Post Hoc Test akan berupa tabel MULTIPLE COMPARRISON seperti berikut ini:
8. Interpretasi:
Hasil uji Homogeneity-of-Variance box menunjukkan nilai sig. (p-value) sebesar 0,848, ini mengindikasikan bahwa kita gagal menolak H0, berarti tidak cukup bukti untuk menyatakan bahwa mean dari dua atau lebih kelompok metode tidak sama. Hasil uji one way ANOVA yang telah dilakukan mengindikasikan bahwa nilai uji-F signifikan pada kelompok uji, ini ditunjukkan oleh nilai Fhitung sebesar 11,6 yang lebih besar daripada F(3,9) sebesar 3,86 (Fhitung > Ftabel), diperkuat dengan nilai p = 0.003
lebih kecil daripada nilai kritik α=0,05.
UjI Lanjut BNT (LSD)
Tulisan kali ini adalah lanjutan dari artikel beberapa waktu yang lalu, yaitu “One Way ANOVA”, so it’s strongly recommended untuk membaca artikel tersebut sebelum
melanjutkan artikel ini.
Uji ANOVA hanya memberikan indikasi tentang ada tidaknya beda antar rata-rata dari keseluruhan perlakuan, namun belum memberikan informasi tentang ada tidaknya perbedaan antara individu perlakuan yang satu dengan individu perlakuan lainnya.
Sederhananya bila ada 5 perlakuan yang ingin diuji, misalnya perlakuan A, B, C, D, dan E. Maka bila uji ANOVA menginformasikan adanya perbedaan yang signifikan, maka dapat disimpulkan bahwa secara keseluruhan terdapat perbedaan yang signifikan antar rata-rata perlakuan, namun belum tentu rata-rata perlakuan A berbeda dengan rata-rata perlakuan B, dan seterusnya…
Untuk uji yang lebih mendalam maka mesti dilakukan uji lanjut (Post hoc test). Ada berbagai macam jenis uji lanjut, namun pada artikel kali ini kita coba bahas uji BNt.
Uji BNt (Beda Nyata terkecil) atau yang lebih dikenal sebagai uji LSD (Least Significance Different) adalah metode yang diperkenalkan oleh Ronald Fisher. Metode ini menjadikan nilai BNt atau nilai LSD sebagai acuan dalam menentukan apakah rata-rata dua perlakuan berbeda secara statistik atau tidak.
Untuk menghitung nilai BNt atau LSD, kita membutuhkan beberapa data yang berasal dari perhitungan sidik ragam (ANOVA) yang telah dilakukan sebelumnya, data tersebut berupa MSE dan dfE. Selain itu juga butuh tabel t-student. Secara lengkap rumusnya adalah sbb:
Kasus:
Setelah dilakukan uji ANOVA (sidik ragam) pada taraf kepercayaan 5% , hasilnya menunjukkan bahwa perlakuan memberikan pengaruh signifikan terhadap produktivitas tanaman padi.
Karena uji ANOVA menunjukkan adanya perbedaan yang nyata secara statistik, maka dilakukan uji lanjut BNt untuk mengetahui ada tidaknya perbedaan antar tiap individu perlakuan.
Prosedur pengerjaannya tidak disediakan secara default oleh program Microsoft excel, namun kita bisa melakukannya secara semi manual. Silahkan tonton video berikut:
Nilai BNt pada contoh kasus ini adalah:
Nilai BNt (LSD) inilah yang menjadi pembeda antar rata dua populasi sampel, bila rata-rata dua populasi sampel lebih kecil atau sama dengan nilai LSD, maka dinyatakan tidak berbeda signifikan. Atau dapat ditulis dengan persamaan berikut:
Kesimpulan yang terlihat pada tabel tersebut, tampilannya terkesan agak rumit, terutama bila kita harus menguji perlakuan yang sangat banyak. Bisa dibayangkan, misalnya ada 15 perlakuan, maka paling tidak terdapat 105 kombinasi perlakuan yang akan diuji.
Untuk itu, dibuat sebuah sistem notasi, gunanya untuk menyederhanakan tampilah hasil uji BNt (LSD), yang caranyanya sudah diuraikan pada video diatas. Pada contoh kasus ini, tampilan uji LSD0.05 dengan sistem notasi adalah sebagai berikut:
Cara interpretasinya adalah dengan metihat notasi huruf yang berada didepan nilai rata-rata tiap perlakuan. Nilai rata-rata perlakuan yang diikuti oleh huruf yang sama dinyatakan tidak berbeda signifikan, misalnya:
(a) Nilai rata-rata Varietas A tidak berbeda signifikan dengan Varietas B, karena sama-sama diberi simbol notasi “a”,
Uji Beda Nyata Terkecil (BNT)
a. Oke, kali ini saya akan menjelaskan bagaimana cara menggunakan uji Beda Nyata Terkecil atau sering disebut uji BNT. Seperti pada uji BNJ, Uji BNT sebenarnya juga sangat simpel. Untuk menggunakan uji ini, atribut yang kita perlukan adalah 1) data rata-rata perlakuan, 2) taraf nyata, 3) derajad bebas (db) galat, dan 4) tabel t-student untuk menentukan nilai kritis uji perbandingan.
Perlu anda ketahui bahwa uji BNT ini dilakukan hanya apabila hasil analisis ragam minimal berpengaruh nyata. Tapi bagaimana kalau hasil analisis ragam tidak berpengaruh nyata apakah bisa dilanjutkan dengan uji BNT? Jawabnya bisa. Tapi yang menjadi pertanyaan selanjutnya adalah apakah perlu menguji perbedaan
pengaruh perlakuan jika ternyata perlakuan yang dicobakan sudah tidak memberikan pengaruh yang nyata? Bukankah apabila perlakuan tidak berpengaruh berarti
perlakuan t1 = t2 = t3 = tn, yang berarti pengaruh perlakuannya sama. Jadi sebenarnya pengujian rata-rata perlakuan pada perlakuan-perlakuan yang tidak berpengaruh nyata tidak banyak memberikan manfaat apa-apa.
Baiklah, sebagai contoh saya ambil data berikut ini yang merupakan data hasil pengamatan pengaruh pemupukan P terhadap bobot polong isi (gram) kedelai varitas Slamet. Percobaan dilakukan dengan rancangan acak kelompok dengan tujuan untuk mengetahui pengaruh pemupukan P terhadap bobot polong isi kedelai. Data hasil pengamatan adalah sebagai berikut :
Hasil analisis ragam (anova) dari data di atas adalah berikut ini :
Nah, selanjutnya kita akan menghitung nilai kritis atau nilai baku dari BNJ dengan rumus berikut :
untuk mencari nilai t(α, v) anda dapat melihatnya pada tabel Sebaran t-student pada taraf nyata α dengan derajad bebas v. Untuk menentukan nilai t(α, v), harus
nilai derajad bebas (db) galat (dalam contoh ini db galat = 12, lihat angka 12 yang berwarna kuning pada tabel analisis ragam).
Setelah semua nilai sudah anda tentukan, maka langkah selanjutnya adalah anda menuju tabel Sebaran t-student. Berikut saya lampirkan sebagian dari tabel tersebut :
Pada tabel Sebaran t-student di atas, panah yang vertikal berasal dari angka 0,050 yang menunjukkan α = 5%. Sedangkan panah horizontal berasal dari angka 12 yang menunjukkan nilai derajad bebas (db) galat = 12. Dari pertemuan kedua panah tersebut didapatkanlah nilai t (0,05; 12) = 2,179.
Langkah selanjutnya anda menghitung nilai kritis BNT dengan menggunakan rumus di atas berikut ini :
Anda perhatikan KT galat = 14,97 dan r (kelompok) = 3 (lihat pada tabel analisis ragam)
Langkah selanjutnya adalah menentukan huruf pada nilai rata-rata tersebut. Perlu anda ketahui cara menentukan huruf ini agak sedikit rumit, tapi anda jangan khawatir asalkan anda mengikuti petunjuk saya pelan-pelan tahap demi tahap. Dan saya yakin apabila anda menguasai cara ini, saya jamin anda hanya butuh waktu paling lama 5 menit untuk menyelesaikan pengkodifikasian huruf pada nilai rata-rata perlakuan. Baik kita mulai saja. Pertama-tama anda jumlahkan nilai kritis BNT5% = 6,88 dengan nilai rata-rata perlakuan terkecil pertama, yaitu 17,33 + 6,88 = 24,21 dan beri huruf “a” dari nilai rata-rata perlakuan terkecil pertama (17,33) hingga nilai rata-rata perlakuan berikutnya yang kurang dari atau sama dengan nilai 24,21. Dalam contoh ini huruf “a” diberi dari nilai rata-rata perlakuan 17,33 hingga 22,67. Lebih jelasnya lihat pada tabel berikut :
Selanjutnya jumlahkan lagi nilai kritis BNT5% = 6,88 dengan nilai rata-rata perlakuan terkecil ketiga, yaitu 22,67 + 6,88 = 29,55 dan beri huruf “c” dari nilai rata-rata perlakuan terkecil ketiga (22,67) hingga nilai rata-rata perlakuan berikutnya yang kurang dari atau sama dengan nilai 29,55. Dalam contoh ini huruf “c” diberi dari nilai rata-rata perlakuan 22,67 hingga 26,00. Lebih jelasnya lihat pada tabel berikut :
Sampai disini anda perhatikan huruf "c" pada tabel di atas. Huruf "c" tersebut harus anda abaikan (batalkan) karena sebenarnya huruf c sudah terwakili oleh huruf b (karena pemberian huruf "c" tidak melewati huruf "b"). Berbeda dengan pemberian huruf "b" sebelumnya. Pemberian huruf "b" melewati huruf "a" sehingga huruf "b" tidak diabaikan/dibatalkan.
Anda perhatikan huruf “c” di atas. Karena pemberian huruf “c” melewati huruf “b” sebelumnya, maka pemberian huruf “c” ini tidak dibaikan/dibatalkan.
Langkah selanjutnya jumlahkan lagi nilai kritis BNT5% = 6,88 dengan nilai rata-rata perlakuan terkecil kelima, yaitu 30,67 + 6,88 = 37,55 dan beri huruf “d” dari nilai rata-rata perlakuan terkecil kelima (30,67) hingga nilai rata-rata perlakuan berikutnya yang kurang dari atau sama dengan nilai 37,55. Dalam contoh ini huruf “d” diberi dari nilai rata-rata perlakuan 30,67 hingga 36,00. Lebih jelasnya lihat pada tabel berikut :
Anda perhatikan huruf “d” di atas. Karena pemberian huruf “d” juga melewati huruf “c” sebelumnya, maka pemberian huruf d ini tidak dibaikan/dibatalkan.
Perlu anda ketahui, apabila pemberian huruf ini telah sampai pada nilai rata-rata perlakuan yang terbesar, walaupun perhitungan penjumlahan belum selesai, maka perhitungan penambahan nilai BNT selanjutnya dihentikan/tidak dilanjutkan. Dan pemberian huruf dianggap selesai.
Terakhir anda susun kembali nilai rata-rata perlakuan tersebut sesuai dengan perlakuannya, seperti tabel berikut:
Nah, sekarang bagaimana cara menjelaskan arti huruf-huruf pada tabel diatas? Prinsip yang harus anda pegang adalah bahwa “perlakuan yang diikuti oleh huruf yang sama berarti tidak berbeda nyata pengaruhnya menurut BNT5%”. Dari hasil pengujian di atas, perlakuan P2 dan P3 sama-sama diikuti huruf “e” artinya perlakuan P2 dan P3 tidak berbeda nyata pengaruhnya menurut BNT 5%. Dan kedua perlakuan tersebut berbeda nyata dengan perlakuan lainnya
Menentukan Perlakuan Terbaik
Untuk menentukan perlakuan mana yang terbaik, langkah-langkahnya adalah berikut ini:
3. Langkah ketiga anda lihat rata-rata perlakuan mana saja yang diikuti oleh huruf “e”. Dalam contoh ini rata-rata perlakuan yang diikuti oleh huruf “e” adalah P2 itu sendiri, dan P3.
4. Langkah keempat anda perhatikan kembali perlakuan P2 dan P3. Dalam contoh ini perlakuan P2=45,00 kg/ha dan P3=67,50 kg/ha. Sampai di sini anda harus bisa mempertimbangkan secara logis perlakuan mana yang terbaik. Logikanya seperti ini, apabila perlakuan dengan dosis lebih rendah tetapi mempunyai pengaruh yang sama dengan perlakuan dengan dosis yang lebih tinggi dalam meningkatkan hasil, maka perlakuan dosis yang lebih rendah tersebut lebih baik daripada perlakuan dosis yang lebih tinggi di atasnya. Dalam contoh ini perlakuan P2 lebih baik daripada perlakuan P3. Jadi dapat disimpulkan perlakuan P2-lah yang terbaik.
Contoh Soal dan Pembahasan RAL
A. PENDAHULUAN
Latar Belakang
Diversivikasi atau penganekaragaman produk susu selain sebagai upaya dalam meningkatkan konsumsi gizi masyarakat dengan daya tarik keragaman produknya, juga bertujuan untuk meningkatkan daya tahan produk sehingga dapat mengatasi masalah keterbatasan ruang dan waktu. Dangke adalah salah satu produk tradisional yang berasal dari Kabupaten Enrekang, merupakan bentuk diversifikasi produk olahan susu. Produk ini sangat mengemuka dan diminati oleh masyarakat khususnya di Sulawesi Selatan.
Sebagai produk tradisional, dangke pada mulanya hanya menjadi konsumsi masyarakat setempat, namun dengan pertumbuhan populasi dan kemajuan informasi, area pemasaran produk ini mengalami perluasan hingga keluar daerah. Dangke sebagai produk olahan susu, sangat rentan mengalami kerusakan dan penurunan kualitas, sehingga dangke yang dipasarkan untuk tujuan ke laur daerah harus melalui proses pengawetan terlebih dahulu.
karena itu, diperlukan suatu bahan pengawet alternatif yang aman dan murah untuk mengatasi masalah tersebut.
Permasalahan
Pennggunaan bahan pengawet alternatif selain garam pada produk Dangke pernah di uji cobakan, yakni dengan menggunakan asam sorbat. Hanya saja asam sorbat dapat mempengaruhi kandungan vitamin B1, dan dapat meninggalkan residu dalam produk, sehingga dianggap berpengaruh negatif terhadap kualitas nutrisi dalam produk. Salah satu bahan pengawet lain yang lebih aman dan bisa digunakan untuk pengawetan pangan adalah “asam askorbat” (Vitamin C) yang diaplikasikan dalam bentuk garam-garaman seperti Na-Askorbat akat K-Na-Askorbat. Namun demikian sejauh mana efektifitas penggunaan asam askorbat dalam produk dangke belum pernah dilakuakan.
Tujuan dan Kegunaan
1. Penelitian ini bertujuan untuk mengetahui sejauhmana efektifitas penggunaan asam askorbat dalam pengawetan dangke berdasarkan tingkat “ketengikan” yang terjadi yang diukur berdasarkan nilai “TBA dangke” yang telah disimpan selama 7 hari pada suhu chilling (5oC).
2. Hasil penelitian ini diharapkan dapat menjadi informasi ilmiah bagi kalangan akademik dalam pengembangan proses pengawetan; dan dapat menjadi rekomendasi bagi pengrajin dangke dalam penggunaan bahan pengawet alternatif selain garam.
Hipotesis
Diduga dalam konsentrasi tertentu, asam askorbat dapat menekan nilai TBA (Tirobarbituric Acid) dangke hingga penyimpanan selama 7 hari.
Ho : Tidak ada pengaruh penggunaan asam askorbat terhadap tingkat “ketengikan” yang telah disimpan selama 7 hari pada suhu chilling (5oC)
H1 : Ada pengaruh penggunaan asam askorbat terhadap tingkat “ketengikan” yang telah
disimpan selama 7 hari pada suhu chilling (5oC)
Variabel bebas adalah perlakuan yang diberikan dalam penelitian, yaitu level pemberian Na-Askorbat:
P1: perlakuan dengan konsentrasi asam askorbat 0% P2: perlakuan dengan konsentrasi asam askorbat 1% P3: perlakuan dengan konsentrasi asam askorbat 2% P4: perlakuan dengan konsentrasi asam askorbat 3%
Variabel Tak Bebas (Independent)
Merupakan variable yang diukur atau parameter yang diukur, yaitu tingkat ketengikan yang diukur berdasarkan nilai “TBA dangke” yang telah disimpan selama 7 hari pada suhu chilling (5oC)
10 4.27 5.80 6.50 6.78 23.35
Total 54.12 53.60 63.13 62.55 233.40
= (49,00 + 36,00 + 36,00 + ….. + 46,00) – 1361,85
D. KESIMPULAN
Analisis Variannsi: Fhitung (5,07) lebih besar dari Ftabel 1% (4,06), maka perlakuan pemberian