BAB II
LANDASAN TEORI
2.1. Algoritma
Istilah algoritma (algorithm) berasal dari kata “algoris” dan “ritmis”, yang pertama kali diungkapkan oleh Abu Ja’far Mohammed Ibn Musa al Khowarizmi (825 M) dalam buku Al-Jabr Wa-al Muqabla. Dalam bidang pemrograman algoritma didefenisikan sebagai suatu metode khusus yang tepat dan terdiri dari serangkaian langkah yang terstruktur dan dituliskan secara matematis yang akan dikerjakan untuk menyelesaikan suatu masalah dengan bantuan komputer (Jogiyanto, 2005).
Algoritma juga dapat didefinisikan sebagai proses komputasi yang mengambil beberapa nilai atau menetapkan nilai sebagai input dan menghasilkan atau menetapkan beberapa nilai sebagai output. Algoritma adalah urutan langkah–langkah komputasi yang mengubah input menjadi output (Cormen, et al. 2001).
2.2. Algoritma Pencocokan String (String Matching Algorithm)
Algoritma pencocokan string atau string matching algorithm adalah algoritma untuk melakukan pencarian semua kemunculan string pendek P[0..n-1] yang disebut pattern di string yang lebih panjang T[0..m-1] yang disebut teks. (Kamara, 2008).
Proses string matching membutuhkan 2 jenis data, yaitu:
1. Teks atau keseluruhan kata, yaitu string yang panjangnya n karakter
Setelah itu, dicari lokasi pertama di dalam teks yang bersesuaian dengan pattern. Secara umum, algoritma pencocokan string diklasifikasikan menjadi 2 bagian, yaitu:
1. Inexact string matching atau Fuzzy string matching, adalah pencocokan string secara samar, yaitu pencocokan string dimana string yang dicocokkan memiliki kemiripan namun keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya) tetapi string tersebut memiliki kemiripan, baik kemiripan tekstual/penulisan atau kemiripan ucapan (Rochmawati, 2015).
2. Exact string matching, merupakan pencocokan string secara tepat dengan susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama (Syaroni, 2005).
Selain dari dua pengklasifikasian tersebut, algoritma pencocokan string memiliki pendekatan-pendekatan yang membuat algoritma efisien dalam kasus tertentu, tergantung pada ukuran dari pola dan banyaknya karakter dalam suatu string. Ada 3 pola (Navarro, 2002), yaitu:
1. Prefix Searching adalah pencocokan string atau pencarian string kedalam teks pencarian, membaca setiap karakter pada string satu demi satu karakter. Untuk setiap posisi dalam teks, mencari string yang dicari pada setiap awalan dari teks pencarian yang juga merupakan awalan dari pattern yang dicari. Beberapa algortima string matching yang menggunakan metode pendekatan ini antara lain: Morris-Pratt , Knuth Morris Pratt, Or, Shift-And, dan Brute Force.
2. Suffix Searching adalah metode pencarian atau pencocokan string satu demi satu karakter, yang merupakan kebalikan dari prefix searching. Suffix searching melakukan pencocokan secara mundur atau dimulai dari akhir pattern, yang dilakukan dalam teks pencarian. Beberapa algortima string
3. Factor Searching adalah metode pencocokan string yang dilakukan serupa dengan suffix searching, mencari akhiran terpanjang yang juga merupakan faktor dari pattern yang dicari. Beberapa algortima string matching yang menggunakan metode pendekatan ini antara lain : BDM (Backward Dawg Matching), BNDM (Backward Nondeterministic Dawg Matching), dan Backward Oracle Dawg Matching.
2.3Algoritma Shift-And
Algoritma Shift-And adalah algoritma yang menggunakan teknik bit-parallelism. Bit-parrallelism adalah penggunaan bit yang adalah representasi dari sebuah karakter dalam komputer untuk meng-update set untuk setiap karakter baru (Navarro, 2002).
Kompleksitas pada algoritma ini adalah O(n), berasumsi bahwa operasi yang berada dalam formula dapat diselesaikan dalam waktu yang konstan, dalam kegunaannya ketika pattern cocok dalam beberapa kata yang ada (Navarro, 2002).
2.3.1 Fase Preprocessing
Pada fase ini pattern yang akan dicari urutkan berdasarka abjad dan menggunakan bit dari setiap karakter yang akan dicari, setiap karakter diubah menjadi bit dan menggunakan bit mask. Panjang jumlah bit ditentukan seberapa banyak karakter pattern yang akan dicocokan pada teks. Dengan D hasil dari And proses.
Misalkan :
Mencari kata “SINAGA” dalam “AGUSTIN SINAGA” :
B
A 1 0 1 0 0 0
G 0 1 0 0 0 0
I 0 0 0 0 1 0
S 0 0 0 0 0 1
* 0 0 0 0 0 0
D = 0 0 0 0 0 0
Keterangan: ubah pattern yang dicari menjadi UPPERCASE
2.3.2 Fase Pencarian
Pada fase pencarian akan dilakukan penyisipan atau shift pada bit mask sebagai parameter kecocokan suatu karakter pada pattern. Bila suatu karakter pattern cocok maka bit mask akan berubah dari yang semula, tapi ketika suatu karakter tidak cocok maka bit mask akan seperti pointer atau bit mask semula.
Misalkan :
D disisipkan 1 pada akhir bit Fase 1
(reading A)
0 0 0 0 0 1
1 0 1 0 0 0
D 0 0 0 0 0 0
Hasil And dari Fase 1: D= 000000, ini berarti bahwa karakter yang ditemukan tidak sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 2 (reading G)
0 0 0 0 0 1
0 1 0 0 0 0
D 0 0 0 0 0 0
Hasil And dari Fase 2: D= 000000, ini berarti bahwa karakter yang ditemukan tidak sesuai dengan pattern.
Fase 3 (reading U)
0 0 0 0 0 1
0 0 0 0 0 0
D 0 0 0 0 0 0
Hasil And dari Fase 3: D= 000000, ini berarti bahwa karakter yang ditemukan tidak sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 4 (reading S)
0 0 0 0 0 1
0 0 0 0 0 1
D 0 0 0 0 0 1
Hasil And dari Fase 4: D= 000001, ini berarti bahwa karakter yang ditemukan sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 5 (reading T)
0 0 0 0 1 1
0 0 0 0 0 0
D 0 0 0 0 0 0
Hasil And dari Fase 5: D= 000000, ini berarti bahwa karakter yang ditemukan tidak sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 6 (reading I)
0 0 0 0 0 1
0 0 0 0 1 0
Hasil And dari Fase 6: D= 000000, ini berarti bahwa karakter yang ditemukan tidak sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 7 (reading N)
0 0 0 0 0 1
0 0 0 1 0 0
D 0 0 0 0 0 0
Hasil And dari Fase 7: D= 000000, ini berarti bahwa karakter yang ditemukan tidak sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 8
Hasil And dari Fase 8: D= 000000, ini berarti bahwa karakter yang ditemukan tidak sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 9 (reading S)
0 0 0 0 0 1
0 0 0 0 0 1
D 0 0 0 0 0 1
Hasil And dari Fase 9: D= 000001, ini berarti bahwa karakter yang ditemukan sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 10 (reading I)
0 0 0 0 1 1
D 0 0 0 0 1 0
Hasil And dari Fase 10: D= 000010, ini berarti bahwa karakter yang ditemukan sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 11 (reading N)
0 0 0 1 0 1
0 0 0 1 0 0
D 0 0 0 1 0 0
Hasil And dari Fase 11: D= 000100, ini berarti bahwa karakter yang ditemukan sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 12 (reading A)
0 0 1 0 0 1
1 0 1 0 0 0
D 0 0 1 0 0 0
Hasil And dari Fase 12: D= 001000, ini berarti bahwa karakter yang ditemukan sesuai dengan pattern.
D disisipkan 1 pada akhir bit
Fase 13 (reading G)
0 1 0 0 0 1
0 1 0 0 0 0
D 0 1 0 0 0 0
Hasil And dari Fase 13: D= 010000, ini berarti bahwa karakter yang ditemukan sesuai dengan pattern.
Fase 14 (reading A)
1 0 0 0 0 1
1 0 1 0 0 0
D 1 0 0 0 0 0
Pattern ditemukan pada bit mask mencapai keseluruhan karakter pada pattern yang dicari. Pattern ditemukan dalam 14 fase pencarian
2.4 Algoritma Morris-Pratt
Algoritma Morris-Pratt dicetuskan oleh James H. Morris bersama Vaughan R. Pratt pada tahun 1966. Algoritma Morris-Pratt terdiri dari dua fase, yaitu fase preprocessing dan fase pencarian string.
Pada fase preprocessing dilakukan fungsi pinggiran untuk menentukan jumlah langkah pergeseran pattern terbesar dengan menggunakan perbAndingan sebelum pencarian string. Fungsi pinggiran ini bergantung pada karakter-karakter yang terdapat dalam pattern, bukan dalam teks. PerbAndingan karakter dilakukan dengan mencocokkan pattern ke dalam teks yang dicari dari kiri ke kanan (Hussain, 2010).
2.4.1 Fase Preprocessing
Pada fase preprocessing dilakukan perhitungan jumlah langkah pergeseran pattern terbesar yang mungkin terjadi dengan menggunakan perbAndingan
yang dibentuk sebelum fase pencarian string. Fase ini menggunakan tabel pergeseran mpNext.
Berikut adalah contoh perhitungan tabel pergeseran mpNext untuk pattern SINAGA pada teks AGUSTIN SINAGA.
*mengubah pattern yang dicari menjadi uppercase.
Tabel 2.1 Nilai mpNext[i] untuk pattern SINAGA
I 0 1 2 3 4 5 6
x[i] S I N A G A *
mpNext[i] -1 0 0 0 0 0 1
Keterangan :
i : indeks untuk setiap karakter pada pattern x : pattern
mpNext[i] : nilai mpNext[i] untuk setiap karakter pada pattern ubah pattern yang dicari menjadi UPPERCASE
2.4.2 Fase Pencarian
Selama fase pencarian, dimulai dari posisi j didalam y, ditentukan dimana : Jendela karakter diposisikan pada teks y[j..j + m– 1]
x[i] = y[i + j] dan 0 ≤ i ≤ m
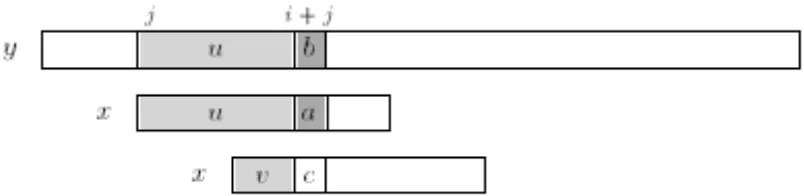
Gambar 2.1 Pergeseran pada algoritma Morris-Pratt : v adalah batasan dari u
Berikut adalah contoh proses pencarian pattern SINAGA pada teks AGUSTIN SINAGA.
I 0 1 2 3 4 5 6
x[i] S I N A G A *
mpNext[i] -1 0 0 0 0 0 1
Tahap 1 :
A G U S T I N S I N A G A
0 1
S I N A G A
Shift = 0 – mpNext[0] = 0 ––1 = 1 Tahap 2 :
A G U S T I N S I N A G A
0 1
S I N A G A
Tahap 3 :
A G U S T I N S I N A G A
0 1
S I N A G A
Shift = 0 – mpNext[0] = 0 – -1 = 1
Tahap 4 :
A G U S T I N S I N A G A
0 1
S I N A G A
Shift = 1 – mpNext[1] = 1 – 0 = 1
Tahap 5 :
A G U S T I N S I N A G A
0 1
S I N A G A
Shift = 0 – mpNext[0] = 0 – -1 = 1
Tahap 5 :
A G U S T I N S I N A G A
0 1
S I N A G A
Tahap 6 :
Pada percobaan kedelapan, pattern sudah sesuai dengan karakter pada teks. Algoritma Morris-Pratt akan terus bergerak ke kanan hingga karakter pada teks berakhir. Pada contoh ini, algoritma Morris-Pratt melakukan 14 kali perbandingan karakter dengan teks.
2.5 Analisis Algoritma
Istilah ‟analisis algoritma‟ sudah digunakan untuk menjelaskan dua pendekatan umum yang sedikit berbeda untuk menempatkan studi kinerja program komputer pada dasar ilmiah.
Pertama, dipopulerkan oleh Aho, Hopcroft, Ullman, Cormen, Leiserson, Rivest, dan Stein, analisis dipusatkan pada penentuan pertumbuhan kinerja algoritma 19 pada kasus terburuk (disebut upper bound). Tujuan utama dari analisis ini adalah untuk menentukan algoritma mana yang optimal, dalam arti bahwa ”lower bound” bisa dibuktikan pada kasus terburuk dari algoritma apa saja untuk masalah yang sama.
Pendekatan kedua pada analisis algoritma, yang dipopulerkan oleh Knuth, dipusatkan pada karakterisasi yang tepat dari kinerja algoritma untuk kasus terbaik, kasus terburuk, dan kasus rata-rata, menggunakan metode yang bisa dimurnikan untuk menghasilkan jawaban yang tepat secara meningkat ketika diinginkan. Tujuan utama dari analisis ini adalah bisa memprediksi secara akurat karakteristik kinerja dari berbagai algoritma ketika dijalankan pada berbagai komputer, guna memprediksi penggunaan sumber daya, menentukan parameter, dan membAndingkan algoritma (Sedgewick, 2013).
2.6 Notasi Asimptotik
Untuk membAndingkan dan menyusun urutan dari pertumbuhan, ilmuwan komputer menggunakan tiga notasi: O (big oh), Ω (big omega), dan Ө (big theta). Dalam penelitian ini, penulis akan membandingkan O (big oh) dan Ө (big theta) dari algoritma Shift-And dan Morris Pratt.
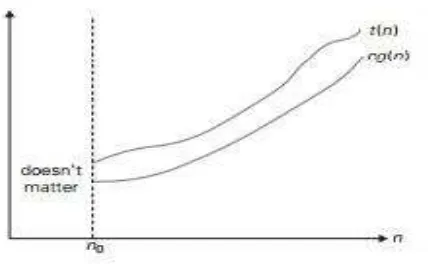
2.6.1 Notasi O
Gambar 2.2 Notasi Big-Oh (Levitin 2012)
2.6.2 Notasi Ω
Fungsi t(n) dikatakan berada dalam Ω(g(n)), dilambangkan dengan t(n) ϵΩ(g(n)), jika t(n) diberi batas bawah oleh beberapa pengali konstan dari g(n) untuk semua n bernilai besar, contohnya, jika ada beberapa konstan c bernilai positif dan n0 integer bukan negatif seperti t(n) ≥ cg(n) untuk semua n ≥ n0 (Levitin, 2012).
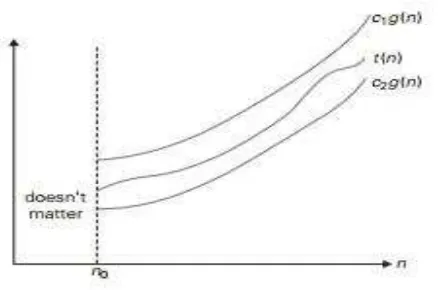
2.6.3 Notasi Ө
Fungsi t(n) dikatakan berada dalam Ө(g(n)), dilambangkan dengan t(n) ϵӨ(g(n)), jika t(n) diberi batas atas dan batas bawah oleh beberapa pengali konstan dari g(n) untuk semua n bernilai besar, contohnya, jika ada beberapa konstan c1 dan c2 bernilai positif dan n0 integer bukan negatif seperti c2g(n) ≤ t(n) ≤ c2g(n) untuk semua n ≥ n0 (Levitin, 2012).
![Tabel 2.1 Nilai mpNext[i] untuk pattern SINAGA](https://thumb-ap.123doks.com/thumbv2/123dok/2692720.1308306/9.595.148.465.273.355/tabel-nilai-mpnext-i-untuk-pattern-sinaga.webp)