4. METODOLOGI
Jenis dan Sumber Data Cakupan Data
Penelitian ini menggunakan data sekunder dari dua sumber utama yaitu Kementerian Keuangan Republik Indonesia (Kemenkeu RI) dan Badan Pusat Statistik (BPS) yang merupakan lembaga pemerintah yang menyediakan data-data resmi negara terkait keuangan dan perekonomian nasional dan daerah sebagai dasar penyusunan rencana dan evaluasi pembangunan nasional dan daerah. Data yang digunakan adalah data panel 23 provinsi tahun 2005-2011 mencakup aspek-aspek fiskal, perekonomian, dan kemiskinan. Menurut Hsiao (1995), data panel yang digunakan dalam penelitian ekonomi memiliki beberapa keunggulan, yaitu: (1) jumlah observasi yang lebih besar akan meningkatkan derajat bebas (degree of freedom) sehingga estimasinya lebih efisien; (2) mengurangi kolinearitas antar variabel penjelas; dan (3) mengatasi masalah yang timbul ketika ada variabel yang dihilangkan (ommited-variable). Meskipun selama periode penelitian sudah terbentuk 33 provinsi secara definitif namun 10 provinsi tidak digunakan yaitu DKI Jakarta, Maluku, Maluku Utara, Papua, Papua Barat, Gorontalo, Sulawesi Barat, Sulawesi Tenggara, Bengkulu, dan Kepulauan Bangka Belitung. Alasannya adalah ada perbedaan karakteristik data fiskal dan perekonomian yang cukup besar dibandingkan provinsi-provinsi lainnya, seperti DKI Jakarta. Selain itu, beberapa data tahun 2005 tidak tersedia terutama di provinsi-provinsi baru.
Data Fiskal
Data fiskal yang digunakan adalah data agregat realisasi APBD provinsi dan seluruh APBD kabupaten/kota di provinsi yang bersangkutan yang bersumber dari Kemenkeu RI meliputi pendapatan dan pengeluaran daerah. Data pendapatan daerah terdiri dari Pendapatan Asli Daerah (PAD), Dana Perimbangan, dan lain-lain Pendapatan. PAD bersumber dari Pajak Daerah, Retribusi Daerah, hasil pengelolaan kekayaan Daerah yang dipisahkan, dan lain-lain PAD yang sah. Dana perimbangan merupakan dana transfer fiskal dari APBN yang diperoleh melalui mekanisme transfer. Dana perimbangan terdiri dari Dana Alokasi Umum (DAU), Dana Alokasi Khusus (DAK), Dana Bagi Hasil Pajak, dan Dana Bagi Hasil Sumber Daya Alam. Dana Bagi Hasil Pajak bersumber dari pajak-pajak properti dan pajak-pajak penghasilan. Pajak-pajak properti yang dibagihasilkan berasal dari Pajak Bumi dan Bangunan (PBB), Bea Perolehan Hak atas Tanah dan Bangunan (BPHTB). Sedangkan, pajak-pajak penghasilan yang dibagi hasilkan bersumber dari Pajak Penghasilan (PPh) Pasal 25 dan 29 Wajib Pajak Orang Pribadi Dalam Negeri (WPOPDN) dan PPh Pasal 21. Struktur pengeluaran daerah mengacu pada UU No. 17 tahun 2003 tentang Keuangan Negara dan PP No. 58 tahun 2005 tentang Pengelolaan Keuangan Daerah dimana keduanya tidak lagi memisahkan pengeluaran rutin dan pengeluaran pembangunan tetapi menjadi belanja langsung dan belanja tidak langsung. Data pengeluaran daerah juga diklasifikasikan menurut sektor ekonomi sesuai Satuan Kerja Perangkat Daerah (SKPD) namun merupakan agregat belanja langsung dan belanja tidak langsung. Hasil kajian terhadap laporan data keuangan daerah menurut sektor ekonomi
menunjukkan ada perbedaan jenis belanja daerah selama periode 2005-2011. Belanja daerah pada tahun anggaran 2005 mencakup 21 bidang, sedangkan tahun anggaran 2006-2011 mencakup 35 urusan. Beberapa perbedaan untuk klasifikasi bidang dan urusan tersebut adalah: (1) belanja bidang kehutanan dan perkebunan didisagregasi menjadi belanja urusan kehutanan dan belanja urusan perkebunan, dimana belanja urusan perkebunan digabung ke dalam belanja urusan pertanian yang juga meliputi belanja tanaman pangan dan peternakan, (2) belanja bidang perindustrian dan perdagangan didisagregasi menjadi belanja urusan perindustrian dan belanja urusan perdagangan. Untuk keseragaman jenis belanja, data tahun 2005 dikonversi sesuai klasifikasi urusan1
Data pengeluaran per kapita adalah rata-rata pengeluaran penduduk untuk konsumsi makanan dan non-makanan per bulan yang diperoleh dari hasil Survei Sosial Ekonomi Nasional (SUSENAS) BPS yang dilakukan setiap tahun dengan . Selanjutnya, agar sesuai dengan tujuan maka klasifikasi belanja daerah yang digunakan adalah belanja menurut urutasn yang terdiri dari: (1) belanja pertanian, (2) belanja perindustrian, (3) belanja perdagangan, (4) belanja pekerjaan umum (belanja infrastruktur), dan (5) belanja-belanja lainnya.
Data Perekonomian
Data perekonomian meliputi PDRB sektoral, jumlah dan upah tenaga kerja sektoral, pengeluaran per kapita sektoral, dan panjang jalan aspal. Klasifikasi sektoral mengacu pada 9 lapangan usaha sesuai Klasifikas Baku Lapangan Usaha Indonesia (KBLI). Namun, untuk keperluan penelitian ini hanya digunakan tiga lapangan usaha (sektor) yaitu sektor pertanian, sektor industri pengolahan, dan sektor perdagangan, hotel, dan restoran. Sedangkan enam sektor lainnya digabung menjadi sektor lainnya. PDRB sektor pertanian terdiri dari dua subsektor yaitu: (1) subsektor tanaman pangan, perkebunan, dan peternakan; dan (2) subsektor lainnya (gabungan subsektor kehutanan dan perikanan). PDRB sektor industri pengolahan terdiri dari: (1) subsektor industri pertanian; dan (2) subsektor industri lainnya. Subsektor industri pertanian terdiri dari industri makanan, minuman, dan tembakau, dan industri pertanian lainnya (gabungan industri kayu, industri kertas, dan industri tekstil). Sedangkan subsektor industri lainnya merupakan gabungan industri migas dan lima jenis industri non-migas. Untuk efisiensi penulisan maka klasifikasi sektor industri pengolahan diganti menjadi sektor industri, klasifikasi subsektor industri makanan, minuman, dan tembakau diganti menjadi subsektor industri makanan jadi, dan klasifikasi sektor perdagangan, hotel, dan restoran diganti menjadi sektor perdagangan.
Data ketenagakerjaan meliputi jumlah dan upah tenaga kerja sektoral dari hasil Survei Angkatan Kerja Nasional (SAKERNAS) yang dilakukan BPS setiap tahun dengan pendekatan rumahtangga. Klasifikasi ketenagakerjaan sektoral pada penelitian ini disesuaikan dengan klasifikasi PDRB sektoral yang digunakan yaitu sektor pertanian, sektor industri, dan sektor perdagangan. Klasifikasi pekerjaan mengacu pada konsep SAKERNAS dimana pekerjaan utama adalah pekerjaan dengan jumlah jam kerja terbanyak yang dilakukan pada waktu referensi survei yaitu selama satu pekan sebelum survei. Sedangkan konsep tenaga kerja adalah penduduk usia 15 tahun ke atas yang sedang bekerja pada saat survei dilakukan.
pendekatan rumahtangga. Pada penelitian ini, data pengeluaran per kapita diklasifikasikan menurut sektor pekerjaan utama kepala rumahtangga yaitu sektor pertanian, sektor industri, dan sektor perdagangan. Namun, data pengeluaran per kapita sektoral tidak diolah dan dipublikasikan oleh BPS. Oleh karena itu, untuk keperluan penelitian ini data diolah sendiri2
Data kemiskinan meliputi ukuran ketimpangan pendapatan Indeks Gini dan tiga ukuran kemiskinan FGT terdiri dari Headcount index atau persentase penduduk miskin (P
dari SUSENAS Kor bulan Maret tahun 2005 sampai 2011. Selanjutnya, data pengeluaran per kapita sektoral per bulan menjadi data dasar dalam penghitungan indikator-indikator kemiskinan.
Data panjang jalan dengan permukaan aspal dianggap mewakili kondisi infrastruktur daerah. Data ini merupakan gabungan panjang jalan aspal untuk tiga tingkat kewenangan yaitu negara, provinsi, dan kabupaten/kota. Data tersebut bersumber dari Kementerian Pekerjaan Umum, Dinas Pekerjaan Umum Provinsi, dan Dinas Pekerjaan Umum Kabupaten/Kota.
Data Kemiskinan
0), Poverty Gap Index atau indeks kedalaman kemiskinan
(P1), dan Poverty Severity Index atau indeks keparahan kemiskinan (P2). Data
Indeks Gini bersumber dari BPS yang dihitung dari hasil SUSENAS. Sebagaimana data pengeluaran per kapita sektoral, data kemiskinan juga diklasifikasikan menurut sektor pekerjaan utama kepala rumahtangga, yaitu sektor pertanian, sektor industri, dan sektor perdagangan. Sebagaimana data pengeluaran per kapita sektoral, data kemiskinan sektoral juga tidak dihitung oleh BPS. Oleh karena itu, untuk keperluan penelitian ini maka data kemiskinan diolah2
Seluruh variabel dalam satuan nilai (rupiah) dalam penelitian ini adalah data nominal sehingga agar terbanding antar waktu maka terlebih dahulu dibagi Indeks Harga Konsumen (IHK) untuk memperoleh data riil. IHK adalah suatu indikator ekonomi yang menggambarkan rata-rata perubahan harga sekumpulan barang dan jasa yang dikonsumsi penduduk/rumahtangga dalam kurun waktu tertentu.
dari data SUSENAS Kor bulan Maret tahun 2005 sampai 2011 dengan batasan identifikasi penduduk miskin adalah garis kemiskinan kota dan desa di setiap provinsi.
Data Penunjang
Selain data utama, penelitian ini juga menggunakan data penunjang, antara lain: (1) penanaman modal dalam negeri (PMDN) dan penanaman modal asing (PMA) dari Badan Koordinasi Penanaman Modal (BKPM) untuk menggambarkan investasi swasta; (2) jumlah kendaraan bermotor dari Kepolisian R.I.; (3) luas wilayah dari Kementerian Dalam Negeri; (4) jumlah pegawai negeri sipil dari Badan Kepegawaian Nasional (BKN); dan (5) jumlah penduduk dari BPS.
Data Indeks Harga Konsumen Provinsi
IHK dihitung oleh BPS berdasarkan hasil Survei Biaya Hidup setiap bulan di b
2 Pengolahan data dilakukan dengan bantuan staf Direktorat Ketahanan Sosial BPS.
eberapa pasar tradisional dan pasar modern pada beberapa kota tepilih untuk mewakili harga-harga dalam kota tersebut. Data harga setiap komoditi diperoleh
dari tiga atau empat tempat penjualan yang didatangi oleh petugas pengumpul data dengan wawancara langsung. Sejak bulan Juni tahun 2008, IHK mencakup 66 kota di 33 provinsi yang terdiri dari 33 ibukota provinsi dan 33 kota besar lainnya di seluruh Indonesia dan menggunakan tahun dasar 2007 (2007=100). Sebelumnya, data IHK hanya mencakup 45 kota dan menggunakan tahun dasar 2002 (2002=100). IHK dihitung berdasarkan data harga konsumen (retail) dari 284 sampai 441 barang dan jasa yang mencakup tujuh kelompok pengeluaran yaitu: (1) bahan makanan; (2) makanan jadi, minuman, rokok, dan tembakau; (3) perumahan, air, listrik, gas, dan bahan bakar; (4) sandang; (5) kesehatan; (6) pendidikan, rekreasi, dan olah raga; dan (7) transportasi, komunikasi, dan jasa keuangan. Setiap kelompok terdiri dari beberapa sub kelompok dimana di setiap sub kelompok terdiri dari beberapa item dengan beberapa mutu atau spesifikasi.
Dalam penghitungan rata-rata harga barang dan jasa digunakan mean (rata-rata), tetapi untuk beberapa barang dan jasa musiman digunakan geometri.
x100 Q P Q P P P IHK 0 0 0 1 n 1 n n
∑
∑
− − = Rumus penghitungan IHK merupakan pengembangan formula Laspeyres yaitu :(4.1) dimana,
IHK : indeks harga konsumen Pn
P
: harga pada bulan ke-n
n-1
P
: harga pada bulan ke-(n-1)
0
Q
: harga pada tahun dasar
0
Meskipun data IHK dapat disajikan untuk tingkat kota tetapi tidak dapat disajikan untuk tingkat provinsi karena tidak mencakup seluruh wilayah di setiap provinsi. Oleh karena itu, pada penelitian ini data IHK provinsi diproksi dengan rata-rata IHK kota di setiap provinsi. Namun sebelumnya IHK tahun 2005 dan 2006 dengan tahun dasar 2002 terlebih dahulu dikonversi menjadi IHK dengan tahun dasar 2007, dan IHK tahun 2007 dikonversi menjadi 100 karena merupakan nilai dasar. Rumus yang digunakan adalah:
: kuantitas pada tahun dasar.
(4.2) dimana, i = 1, 2,…, 23 (jumlah provinsi) j = 1, 2, …, k (jumlah kota) t = 2005 dan 2006 IHKijt07 IHK
: IHK provinsi i kota j tahun t (2007=100)
ijt02
IHK
: IHK provinsi i kota j tahun t (2002=100)
ij07
Selanjutnya, data IHK provinsi dengan tahun dasar 2007 dihitung dengan rumus: : IHK provinsi i kota j tahun t tahun 2007
(4.3)
dimana,
i = 1,2, …, 23 (jumlah provinsi) j = 1, 2, …, k (jumlah kota)
t = 2005, 2006, …, 2011 IHKit07
IHK
: IHK provinsi i tahun t (2007=100)
ijt07
Rata-rata IHK provinsi juga digunakan untuk menghitung laju inflasi provinsi dengan rumus berikut:
: IHK provinsi i kota j tahun t (2007=100)
(4.4) dimana, i = 1,2, …, 23 (jumlah provinsi) j = 1, 2, …, k (jumlah kota) t = 2005, 2006, …, 2011 IFLit07 IHK
: Laju inflasi provinsi i tahun t (2007=100)
it07
IHK
: IHK provinsi i tahun t (2007=100)
ijt07
Data IHK provinsi dengan tahun dasar 2007 (2007=100) hasil penghitungan menggunakan rumus (4.3) secara lengkap disajikan pada Lampiran 1. Sedangkan data-data nominal yang digunakan pada penelitian ini disajikan pada Lampiran 2.
: IHK provinsi i kota j tahun t (2007=100)
Spesifikasi Model Ekonometrika
Metode penelitian ini menggunakan pendekatan ekonometrik dengan membangun model ekonometrik yang diawali dengan tahap spesifikasi model berupa kajian hubungan antar variabel untuk menganalisis fenomena ekonomi secara empiris. Model yang dibangun pada penelitian ini dinamai model Fiskal, Perekonomian, dan Kemiskinan Sektoral Daerah yang mencakup tiga aspek yaitu kebijakan fiskal daerah, kinerja perekonomian sektoral daerah, dan kemiskinan sektoral daerah. Model tersebut dibangun berdasarkan tujuan penelitian, tinjauan pustaka, kerangka teori, dan studi-studi empiris terdahulu. Model ekonometrik yang dibangun merupakan sistem persamaan simultan dengan alasan kerangka teori dan studi-studi empiris terdahulu menunjukkan keterkaitan antar variabel fiskal, perekonomian, dan kemiskinan. Menurut Koutsoyiannis (1977), sistem persamaan simultan adalah suatu sistem yang menjelaskan ketergantungan bersama antar variabel (a system describing the joint dependence of variables). Bahkan, sesuai sifat alami fenomena ekonomi maka setiap persamaan hampir pasti akan berada pada suatu sistem persamaan simultan yang lebih besar.
Dalam sistem persamaan simultan, sebuah variabel dapat berperan ganda yaitu sebagai variabel penjelas (independent variable) dan variabel dependen atau endogen (dependent variable). Dengan demikian, perubahan suatu variabel dapat mempengaruhi variabel lain dalam model. Oleh karena itu, penggunaan sistem persamaan simultan pada penelitian ini dianggap tepat karena dapat digunakan untuk simulasi kebijakan dengan mengubah variabel-variabel yang dianggap berdampak pada kemiskinan sektoral melalui transmisi perekonomian sektoral daerah. Model Fiskal, Perekonomian, dan Kemiskinan Sektoral Daerah mencakup 48 persamaan terdiri dari 28 persamaan struktural dan 20 persamaan identitas dalam tiga blok persamaan yang mewakili ketiga aspek penelitian yaitu blok fiskal, blok perekonomian sektoral, dan blok kemiskinan sektoral.
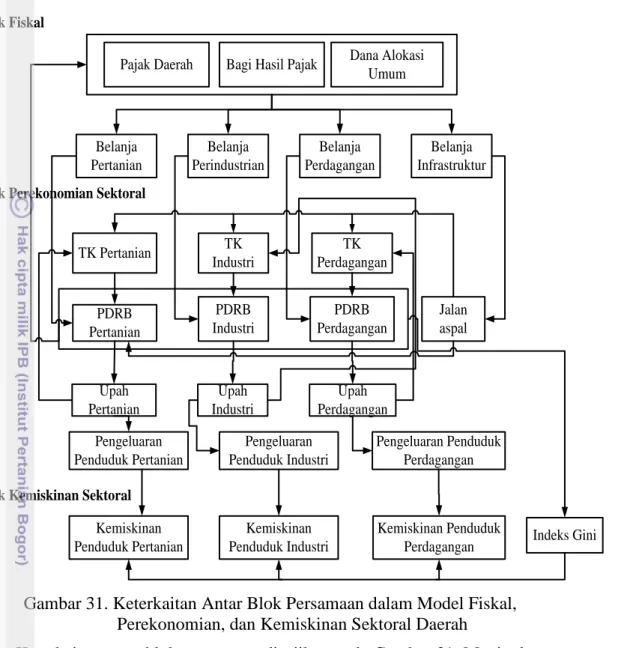
Pajak Daerah Bagi Hasil Pajak Dana Alokasi Umum Belanja Pertanian Belanja Perindustrian Belanja Perdagangan Belanja Infrastruktur PDRB Pertanian PDRB Industri PDRB Perdagangan Jalan aspal TK Pertanian TK Industri TK Perdagangan Upah Pertanian Upah Industri Upah Perdagangan Pengeluaran Penduduk Pertanian Pengeluaran Penduduk Industri Pengeluaran Penduduk Perdagangan Indeks Gini Kemiskinan Penduduk Pertanian Kemiskinan Penduduk Industri Kemiskinan Penduduk Perdagangan Blok Fiskal
Blok Perekonomian Sektoral
Blok Kemiskinan Sektoral
Gambar 31. Keterkaitan Antar Blok Persamaan dalam Model Fiskal, Perekonomian, dan Kemiskinan Sektoral Daerah
Keterkaitan antar blok persamaan disajikan pada Gambar 31. Meningkatnya pendapatan daerah baik dari kapasitas fiskal khususnya dari pajak daerah dan bagi hasil pajak maupun dari transfer fiskal khususnya DAU akan meningkatkan kemampuan keuangan daerah sehingga pengeluaran pemerintah daerah belanja pertanian, belanja perindustrian, belanja perdagangan, dan belanja infrastruktur meningkat. Sebagai bentuk investasi pemerintah maka pengeluaran pemerintah yang lebih besar akan mendorong produksi barang dan jasa sehingga output daerah meningkat. Dengan demikian, meningkatnya belanja-belanja sektoral dan belanja infrastruktur akan meningkatkan PDRB sektoral khususnya pertanian, industri, dan perdagangan. Di sisi lain, peningkatan belanja infrastruktur akan menambah panjang jalan aspal yang mempermudah akses kepada sumber daya tenaga kerja sehingga ketiga sektor ekonomi tersebut akan menyerap tenaga kerja lebih banyak. Sebagai faktor produksi yang penting maka jumlah tenaga kerja yang lebih besar akan meningkatkan output sektoral sehingga PDRB ketiga sektor meningkat. Dengan mengacu pada hasil penelitian Malik dan Ahmed (2000) yaitu ada hubungan pro-cyclical antara output dan upah riil sektoral maka kenaikan PDRB sektoral akan meningkatkan upah riil sektoral sehingga pendapatan rumahtangga meningkat. Hal ini akan meningkatkatkan daya beli penduduk yang
diukur dari pengeluaran per kapita untuk setiap kelompok rumahtangga sektoral. Sesuai formula indikator kemiskinan FGT dalam konsep kemiskinan pendapatan (income poverty) maka pengeluaran per kapita sektoral yang lebih besar akan menurunkan tingkat kemiskinan sektoral. Di sisi lain, laju pertumbuhan PDRB sektor riil yang lebih cepat terutama sektor pertanian mengurangi ketimpangan pendapatan karena kelompok penduduk miskin yang mayoritas hidup di sektor pertanian menikmati manfaat lebih besar dari pertumbuhan ekonomi tersebut. Ketimpangan pendapatan yang berkurang (Indeks Gini yang rendah) menambah peran pertumbuhan sektoral (pengeluaran per kapita yang lebih besar) dalam menurunkan kemiskinan sektoral. Keterkaitan antar variabel secara lengkap disajikan pada Lampiran 3.
Persamaan-persamaan struktural dalam model Fiskal, Perekonomian, dan Kemiskinan Sektoral Daerah merupakan model regresi data panel. Secara umum, model regresi data panel dapat dibuat dengan pendekatan common effect, fixed effect, dan random effect yang masing-masing diestimasi dengan metode pooled least squares, fixed effect, dan random effect (Gujarati, 2008). Pada penelitian ini, setiap persamaan struktural dibangun dengan pendekatan common effect dengan asumsi estimasi konstanta (intersep) dan estimasi parameter (slope) setiap variabel adalah sama untuk setiap provinsi. Bentuk umum persamaan tunggal untuk model regresi panel common effect adalah (Gujarati, 2008):
(4.5) dimana,
i : provinsi
k : variabel penjelas (explanatory variables) t : tahun
yit
β0 : variabel dependen provinsi i tahun t
β1: intercept , β2, …, βk
x
: slope atau koefisien parameter variabel penjelas
1it, x2it, …, xkit
u
: variabel penjelas di provinsi i tahun t
it
Model Fiskal, Perekonomian, dan Kemiskinan Sektoral Daerah merupakan sistem persamaan simultan dengan bentuk umum yang disajikan dalam notasi matriks sebagai berikut :
: komponen error provinsi i tahun t
(4.6)
dimana,
Yit
B
: vektor current endogenous variables provinsi i tahun t
0
B
: vektor koefisien intercept
1
: vektor current explanatory endogenous variables provinsi i tahun t : martriks koefisien current explanatory endogenous variables
B2
X
: martriks koefisien current exogenous variables
it
B
: vektor current exogenous variables provinsi i tahun t
3
Z
: martriks koefisien current policy variables
it
B
: vektor current policy variables provinsi i tahun t
4
Y
: martriks koefisien lagged endogenous variables
it-1
U
: vektor lagged endogenous variables provinsi i tahun t
Blok Fiskal
Blok fiskal terdiri dari beberapa persamaan yang menunjukkan sumber-sumber pendapatan daerah dan jenis-jenis pengeluaran daerah. Pendapatan daerah meliputi pajak daerah, bagi hasil pajak, dan DAU. Sementara, pengeluaran daerah meliputi belanja pertanian, belanja perindustrian, belanja perdagangan, belanja infrastruktur, dan belanja lainnya.
Pajak Daerah
Variabel-variabel yang diduga mempengaruhi jumlah penerimaan pajak daerah dipilih berdasarkan UU No. 34 tahun 2000 tentang Pajak Daerah dan Retribusi Daerah dimana pajak daerah yang terdiri dari pajak provinsi dan pajak kabupaten/kota antara lain bersumber dari pajak-pajak terkait kendaraan bermotor, pajak hotel, pajak restoran, pajak hiburan, dan pajak reklame. Sumber-sumber pajak tersebut terkait dengan kemampuan ekonomi penduduk. Berdasarkan hal itu maka pajak daerah diduga dipengaruhi oleh PDRB per kapita, jumlah kendaraan bermotor, dan penanaman modal. Persamaan pajak daerah provinsi-i tahun-t adalah:
PJKit = a0 + a1PDRBKAPit + a2PMit + a3MTRit + a4PJKit-1 + u1it
Hipotesis: a (4.7) 1, a2, a3 > 0; 0 < a4 dimana, < 1
PJK : pendapatan pajak daerah (juta Rp) PDRBKAP : PDRB per kapita (ribu Rp) MTR : jumlah kendaraan bermotor (ribu unit) PM : total penanaman modal (juta Rp)
Bagi Hasil Pajak
Sesuai UU No. 33 tahun 2004, bagi hasil pajak bersumber dari pajak-pajak properti (PBB dan BPHTB) dan pajak-pajak penghasilan (PPh Pasal 25 dan pasal 29 WPOPDN dan PPh Pasal 21). Berdasarkan kedua sumber tersebut maka bagi hasil pajak diduga dipengaruhi oleh luas wilayah dan PDRB non-pertanian. Variabel luas wilayah dianggap mewakili PBB dan BPHTB, sedangkan PDRB non-pertanian dianggap mewakili PPh karena sektor non-pertanian merupakan lapangan usaha mayoritas wajib pajak untuk ketiga jenis PPh tersebut. Persamaan bagi hasil pajak provinsi-i tahun-t adalah:
BHSPJKit = b0 + b1PDRBNONTANIit + b2WLYHit + b3BHSPJKit-1 + u2it
Hipotesis: b (4.8) 1, b2 > 0; 0 < b3 dimana, < 1 BHSPJK: bagi hasil pajak (juta Rp)
PDRBNONTANI: PDRB sektor-sektor non-pertanian (juta Rp) WLYH: luas wilayah (km2)
Dana Alokasi Umum
Persamaan DAU disusun sesuai formula alokasi DAU yang diatur dalam UU No. 33 tahun 2004 dan PP No. 55 tahun 2005 yang menggunakan pendekatan celah fiskal dan alokasi dasar. Celah fiskal adalah selisih kebutuhan fiskal dan kapasitas fiskal. Kebutuhan fiskal diproksi dari variabel-variabel PDRB, jumlah penduduk, dan luas wilayah. Sedangkan, alokasi dasar mencerminkan kebutuhan pembiayaan administrasi pemerintahan daerah diproksi dari jumlah PNS daerah. Persamaan DAU provinsi-i tahun-t adalah:
DAUit = c0 + c1PDRBit-1 + c2POPit + c3WLYHit + c4PNSit + c5DAUit-1 + u3it
Hipotesis: c (4.9) 1 < 0; c2, c3, c4 > 0; 0 < c5 dimana, < 1 DAU: dana alokasi umum (juta Rp) PDRB: PDRB total (juta Rp)
POP: jumlah penduduk (ribu orang) WLYH: luas wilayah (km2)
PNS: jumlah pegawai negeri sipil (orang)
Total Pendapatan Daerah
Pendapatan dari pajak daerah selanjutnya dijumlahkan dengan beberapa komponen pendapatan daerah lainnya untuk memperoleh PAD. Kemudian PAD, bagi hasil pajak, dan bagi hasil sumber daya alam dijumlahkan untuk memperoleh kapasitas fiskal. Selanjutnya, kapasitas fiskal, DAU, DAK, dan pendapatan daerah dari sumber-sumber lain dijumlahkan untuk memperoleh total pendapatan daerah. Karena ketiganya adalah hasil penjumlahan maka persamaan-persamaan yang dibangun merupakan persamaan identitas. Ketiga persamaan di provinsi-i tahun-t adalah:
PADit = PJKit + RETit + KKYDit + PADLNit
KAPFIS
(4.10)
it = PADit + BHSPJKit + BHSSDAit
DPT
(4.11)
it = KAPFISit + DAUit + DAKit + DPTLNit
dimana,
(4.12)
PAD : pendapatan asli daerah (juta Rp) KAPFIS: kapasitas fiskal (juta Rp)
DPT: total pendapatan daerah (juta Rp) RET: retribusi (juta Rp)
KKYD: hasil pengelolaan kekayaan daerah yang dipisahkan (juta Rp) PADLN: PAD lainnya (juta Rp)
BHSPJK: bagi hasil pajak (juta Rp)
BHSSDA: bagi hasil sumber daya alam (juta Rp) DAU: dana alokasi umum (juta Rp)
DAK: dana alokasi khusus (juta Rp) DPTLN: pendapatan lainnya (juta Rp)
Belanja Sektoral
Belanja sektoral diduga dipengaruhi oleh pendapatan daerah khususnya kapasitas fiskal dan DAU. Penggunaan kedua jenis pendapatan daerah ini juga bertujuan untuk mengetahui perilaku pemerintah dalam mengalokasikan dana dari bantuan pemerintah pusat dan pendapatan dari sumber daya sendiri melalui fenomena flypaper effect. Sedangkan, persamaan belanja daerah dibuat secara sektoral untuk mengetahui apakah fenomena flypaper effect terjadi pada jenis-jenis belanja tertentu. Sesuai klasifikasi data pengeluaran daerah dari Kemenkeu, blanja pertanian adalah belanja urusan tanaman pangan, hortikultura, perkebunan, dan peternakan. Selain dipengaruhi oleh kapasitas fiskal dan DAU, belanja pertanian diduga dipengaruhi juga DAK karena DAK disalurkan dari pemerintah pusat kepada pemerintah daerah salah satunya untuk pembangunan pertanian. Pada tahun 2011, rasio DAK bidang pertanian terhadap belanja pertanian rata-rata 15% per provinsi. Hal ini menunjukkan cukup besarnya peran DAK dalam total belanja pertanian di daerah. Persamaan belanja sektoral provinsi-i tahun-t adalah:
GPGNKBNTNKit = d0 + d1KAPFISit + d2DAUit + d3DAKit
d
+
4GPGNKBNTNKit-1 + u4it
GIND
(4.13)
it = e0 + e1KAPFISit + e2DAUit + e3GINDit-1 + u5it
GDG
(4.14)
it = f0 + f1KAPFISit + f2DAUit + f3GDGit-1 + u6it
GIFR
(4.15)
it = g0 + g1KAPFISit + g2DAUit + g3GIFRit-1 + u7it
GLN
(4.16)
it = h0 + h1KAPFISit + h2DAUit + h3GLNit-1 + u8it
Hipotesis: d (4.17) 1, d2, d3, e1, e2, f1, f2, g1, g2, h1, h2 > 0; 0 < d4, e3,f3, g3,h3 dimana, < 1 GPGNKBNTNK : belanja pertanian (juta Rp)
GIND : belanja perindustrian (juta Rp) GDG : belanja perdagangan (juta Rp) GIFR : belanja infrastruktur (juta Rp) GLN : belanja lainnya (juta Rp) KAPFIS: kapasitas fiskal (juta Rp) DAU: dana alokasi umum (juta Rp) DAK: dana alokasi khusus (juta Rp)
Kinerja Fiskal
Kinerja fiskal daerah dapat diukur dari indiaktor kesenjangan fiskal (fiscal gap) dan indikator kemandirian fiskal (fiscal autonomy). Sesuai konsep dalam UU No. 33 tahun 2004 kesenjangan fiskal dihitung dari selisih total belanja daerah dan kapasitas fiskal. Indikator tersebut dapat mencerminkan tingkat ketergantungan keuangan daerah pada DAU dimana semakin tinggi kesenjangan fiskal semakin tinggi ketergantungan pada DAU. Sedangkan, kemandirian fiskal dihitung dari rasio PAD terhadap total belanja daerah. Indikator ini mencerminkan kemampuan
daerah dalam membiayai pembangunan daerah dari sumber daya lokal khususnya PAD dimana semakin tinggi kemandirian fiskal semakin rendah ketergantungan pada DAU. Kinerja fiskal yang baik ditunjukkan oleh kesenjangan fiskal yang rendah dan kemandirian fiskal yang tinggi. Kedua indikator kinerja fiskal tersebut merupakan persamaan identitas dimana persamaan di provinsi-i tahun-t adalah:
GDGKAPit = GDGit/POPit G (4.18) it = GPGNKBNTNKit + GINDit + GDGit + GIFRit + GLNit FISGAP (4.19) it = Git - KAPFISit FISAUTO (4.20) it = (PADit/Git dimana, ) x 100 (4.21)
GDGKAP: belanja perdagangan per kapita (ribu Rp) G: total belanja daerah (juta Rp)
FISGAP: kesenjangan fiskal (juta Rp) FISAUTO: kemandirian fiskal (%)
GPGNKBNTNK : belanja pertanian (juta Rp) GIND : belanja perindustrian (juta Rp)
GDG : belanja perdagangan (juta Rp) GIFR : belanja infrastruktur (juta Rp) GLN : belanja lainnya (juta Rp) KAPFIS: kapasitas fiskal (juta Rp) PAD: pendapatan asli daerah (juta Rp)
Blok Perekonomian Sektoral
Kinerja perekonomian daerah meliputi infrastruktur jalan, PDRB sektoral, jumah dan upah tenaga kerja sektoral, dan pengeluaran per kapita sektoral.
Panjang Jalan Aspal
Infrastruktur jalan di daerah diproksi dari panjang jalan aspal. Jalan aspal yang merupakan sub-sektor transportasi darat berperan meningkatkan konektivitas antar wilayah baik di dalam provinsi maupun antar provinsi sehingga memperluas akses ekonomi. Artinya, infrastruktur jalan aspal memberi efek pengganda besar bagi perekonomian daerah. Panjang jalan aspal diduga dipengaruhi oleh belanja infrastruktur, jumlah kendaraan bermotor, dan penanaman modal. Belanja daerah untuk pembangunan infrastruktur yang semakin lebih besar akan menambah panjang jalan aspal. Selain itu, sektor swasta juga turut berperan serta membiayai pembangunan infrastruktur terutama di daerah-daerah yang memiliki keterbatasan pembiayaan pembangunan infrastruktur. Persamaan panjang jalan aspal provinsi-i tahun-t adalah:
ASPit = i0 + i1GIFRit + i2PMit + i3MTRit + u9it
Hipotesis: i
(4.22)
1, i2, dan i3
dimana,
> 0 ASP: panjang jalan aspal (km) GIFR: belanja infrastruktur (juta Rp) PM: total penanaman modal (juta Rp)
MTR: jumlah kendaraan bermotor (ribu unit)
PDRB Sektoral
Faktor-faktor yang diduga mempengaruhi PDRB sektoral adalah belanja sektoral dan tenaga kerja sektoral. Hal ini sesuai teori pertumbuhan ekonomi Solow (Solow Growth Model) yaitu output merupakan fungsi dari kapital dan tenaga kerja dimana belanja daerah merupakan bagian dari kapital. Selain itu, panjang jalan aspal juga diduga mempengaruhi PDRB sektoral terutama sektor pertanian yang mayoritas berada di pedesaan dan sektor perdagangan khususnya pada skala usaha kecil melalui perannya dalam meningkatkan aksesibilitas ke pasar output. Persamaan PDRB sektoral di provinsi-i tahun-t adalah:
PDRBPGNKBNTNKit = j0 + j1GPGNKBNTNKit + j2TKTANIit + j3*ASPit + u 10it PDRBMKN (4.23)
it = k0 + k1GINDit + k2TKINDit + u11it
PDRBDG
(4.24)
it = l0 + l1GDGKAPit + l2TKDGit + l3ASPit + u12it
Hipotesis: j
(4.25)
1, j2, j3, k1, k2, l1, l2, l3
dimana,
> 0
PDRBPGNKBNTNK: PDRB pangan, perkebunan, peternakan (juta Rp) PDRBMKN: PDRB industri makanan jadi (juta Rp)
PDRBDG: PDRB perdagangan per kapita (juta Rp) GPGNKBNTNK: belanja pertanian (juta Rp) GIND: belanja perindustrian (juta Rp)
GDG: belanja perdagangan (juta Rp)
TKTANI: jumlah tenaga kerja pertanian (ribu orang) TKIND: jumlah tenaga kerja industri (ribu orang) TKDG: jumlah tenaga kerja perdagangan (ribu orang) ASP: panjang jalan aspal (km)
Selain ketiga persamaan struktural di atas, PDRB sektoral juga dibuat dalam bentuk persamaan identitas yaitu jumlah komponen-komponen pembentuk PDRB pertanian, PDRB industri, PDRB perdagangan, dan PDRB total. Persamaan di provinsi-i tahun-t adalah:
PDRBTANIit = PDRBPGNKBNTNKit + PDRBHTNit + PDRBIKANit PDRBTANIKAP (4.26) it = PDRBTANIit/POPit PDRBINDTANI (4.27) it = PDRBMKNit + PDRBKYUit + PDRBINDTANILNit PDRBIND (4.28) it = PDRBINDTANIit + PDRBINDLNit PDRBINDKAP (4.29) it = PDRBINDit/POPit PDRBDGKAP (4.30) it = PDRBDGit/POPit PDRBNONTANI (4.31) it = PDRBINDit + PDRBDGit + PDRBLNit PDRB (4.32) it = PDRBTANIit + PDRBNONTANIit PDRBKAP (4.33) it = PDRBit/POPit (4.34)
SHPDRBTANIit = PDRBTANIit/PDRBit SHPDRBIND X 100 (4.35) it = PDRBINDit/PDRBit SHPDRBDG X 100 (4.36) it = PDRBDGit/PDRBit dimana, X 100 (4.37)
PDRBTANI: PDRB pertanian (juta Rp)
PDRBTANIKAP: PDRB pertanian per kapita (ribu Rp) PDRBINDTANI: PDRB industri pertanian (juta Rp) PDRBIND: PDRB industri (juta Rp)
PDRBINDKAP: PDRB industri per kapita (ribu Rp) PDRBDGKAP: PDRB perdagangan per kapita (ribu Rp) PDRBNONTANI: PDRB non-pertanian (juta Rp)
PDRB: PDRB total (juta Rp)
PDRBKAP: PDRB per kapita (juta Rp) SHPDRBTANI: Share PDRB pertanian (%) SHPDRBIND: Share PDRB industri (%) SHPDRBDG: Share PDRB perdagangan (%)
PDRBPGNKBNTNK: PDRB pangan, perkebunan, peternakan (juta Rp) PDRBHTN: PDRB kehutanan (juta Rp)
PDRBIKAN: PDRB perikanan (juta Rp)
PDRBMKN: PDRB industri makanan jadi (juta Rp) PDRBKYU: PDRB industri kayu (juta Rp)
PDRBINDTANILN: PDRB industri pertanian lainnya (juta Rp) PDRBINDLN: PDRB industri lainnya (juta Rp)
PDRBDG: PDRB perdagangan per kapita (juta Rp) PDRBLN: PDRB lainnya (juta Rp)
POP: jumlah penduduk (ribu orang)
Tenaga Kerja Sektoral
Jumlah tenaga kerja sektoral diduga dipengaruhi oleh PDRB sektoral, upah sektoral, dan infrastruktur jalan aspal. Meningkatnya PDRB sektoral diduga akan menyerap tenaga kerja sektoral. Demikian juga, panjang jalan aspal yang meningkat akan mempermudah aksesibilitas angkatan kerja ke pasar input tenaga kerja sehingga meningkatkan jumlah tenaga kerja sektoral. Sebaliknya, sesuai teori pasar tenaga kerja, upah riil yang lebih besar diduga menurunkan permintaan tenaga kerja. Persamaan jumlah tenaga kerja sektoral di provinsi-i tahun-t adalah:
TKTANIit = m0 + m1PDRBTANIit + m2UPHTANIit + m3ASPit + u13it
TKIND (4.38)
it = n0 + n1PDRBINDit + n2UPHINDit + n3ASPit + u14it
TKDG
(4.39)
it = o0 + o1PDRBDGit + o2UPHDGit + o3ASPit + u15it
TK (4.40) it = TKTANitI + TKINDit + TKDGit + TKLNit Hipotesis: m (4.41) 1, m3, n1, n3, o1, o3, > 0; m2, n2, o2 dimana, < 0 TKTANI: jumlah tenaga kerja pertanian (ribu orang) TKIND: jumlah tenaga kerja industri (ribu orang) TKDG: jumlah tenaga kerja perdagangan (ribu orang)
TK: jumlah tenaga kerja (ribu orang) PDRBTANI: PDRB pertanian (juta Rp) PDRBIND: PDRB industri (juta Rp) PDRBDG: PDRB perdagangan (juta Rp)
UPHTANI: upah tenaga kerja pertanian (ribu Rp) UPHIND: upah tenaga kerja industri (ribu Rp) UPHDG: upah tenaga kerja perdagangan (ribu Rp) ASP: panjang jalan aspal (km)
TKLN: jumlah tenaga kerja lainnya (ribu orang)
Upah Riil Sektoral
Sebagai salah satu faktor produksi, tenaga kerja mendapatkan balas jasa produksi dalam bentuk upah dimana upah riil adalah marginal product of labor (MPL) yaitu tambahan output yang dihasilkan untuk setiap tambahan tenaga kerja. Secara alami meningkatnya produksi akan meningkatkan penerimaan sehingga upah riil yang diterima tenaga kerja juga meningkat. Dengan demikian, pada penelitian ini upah riil sektoral diduga dipengaruhi oleh PDRB sektoral dalam hal ini PDRB per kapita sektoral. Persamaan di provinsi-i tahun-t adalah:
UPHTANIit = p0 + p1PDRBTANIKAPit + p2UPHTANIit-1 + u16it
UPHIND
(4.42)
it = q0 + q1PDRBINDKAPit + q2UPHINDit-1 + u17it
UPHDG
(4.43)
it = r0 + r1PDRBDGKAPit + r2UPHDGit-1 + u18it
Hipotesis: p
(4.44)
1, q1, r1 > 0; 0 < p2, q2, r2
dimana,
< 1
UPHTANI: upah tenaga kerja pertanian per bulan (ribu Rp) UPHIND: upah tenaga kerja industri per bulan (ribu Rp) UPHDG: upah tenaga kerja perdagangan per bulan (ribu Rp) PDRBTANIKAP: PDRB pertanian per kapita (ribu Rp) PDRBINDKAP: PDRB industri per kapita (ribu Rp) PDRBDGKAP: PDRB perdagangan per kapita (ribu Rp)
Pengeluaran per Kapita Sektoral
Konsep pertumbuhan pro-poor menunjukkan peran pertumbuhan ekonomi dan pemerataan pendapatan dalam menurunkan kemiskinan. Meskipun perubahan output merupakan ukuran pertumbuhan ekonomi yang umum, namun studi-studi empiris terdahulu terkait kemiskinan lebih banyak menggunakan pengeluaran per kapita dari hasil survey rumahtangga, antara lain Miranti (2010) dan Ravallion dan Chen (1997). Bahkan menurut Ravallion (1995) pengeluaran per kapita lebih mencerminkan kesejahteraan penduduk dibandingkan pendapatan walaupun keduanya berasal dari sumber data yang sama. Oleh karena itu, penelitian ini menggunakan pengeluaran penduduk yang diperoleh dari indikator pengeluaran per kapita rumahtangga sektoral berdasarkan pekerjaan utama kepala rumahtangga dari hasil SUSENAS. Pengeluaran per kapita diduga dipengaruhi oleh upah riil kepala rumahtangga dimana semakin besar upah riil maka semakin besar pengeluaran per kapita. Sebaliknya, inflasi diduga menurunkan pengeluaran
per kapita. Persamaan pengeluaran per kapita per bulan di provinsi-i tahun-t adalah:
EXPTANIit = s0 + s1UPHTANIit + s2IFLit + u19it
EXPIND
(4.45)
it = t0 + t1UPHINDit + t2IFLit + u20it
EXPDG
(4.46)
it = u0 + u1UPHDGit + u2IFLit + u21it
Hipotesis: s
(4.47)
1, t1, u1 > 0; s2, t2, u2
dimana,
< 0
EXPTANI: pengeluaran penduduk pertanian per bulan (ribu Rp) EXPIND: pengeluaran penduduk industri per bulan (ribu Rp) EXPDG: pengeluaran penduduk perdagangan per bulan (ribu Rp) UPHTANI: upah tenaga kerja pertanian per bulan (ribu Rp) UPHIND: upah tenaga kerja industri per bulan (ribu Rp) UPHDG: upah tenaga kerja perdagangan per bulan (ribu Rp) IFL: laju inflasi (%)
Blok Kemiskinan Sektoral
Dalam konsep pertumbuhan pro-poor, perubahan kemiskinan terjadi karena perubahan pertumbuhan dan perubahan ketimpangan pendapatan. Oleh karena itu, persamaan-persamaan pada blok kemiskinan sektoral daerah meliputi Indeks Gini sebagai ukuran ketimpangan pendapatan dan tiga indikator kemiskinan yaitu headcount index (P0), poverty gap index (P1), dan poverty severity index (P2
Indeks Gini
).
Indeks Gini yang merupakan ukuran ketimpangan pendapatan penduduk diduga dipengaruhi oeh kontribusi PDRB sektoral pada total PDRB berdasarkan asumsi hipotesis Kuznets (1955) yaitu sektor tradisional di pedesaan memiliki ketimpangan pendapatan rendah, sedangkan sektor modern di perkotaan memiliki ketimpangan pendapatan tinggi. Dengan demikian, jika share PDRB sektor pertanian sebagai sektor yang mendominasi struktur ekonomi di pedesaan lebih besar diduga menurunkan Indeks Gini yang berarti ketimpangan pendapatan lebih rendah. Namun, jika share PDRB perdagangan sebagai sektor yang mendominasi struktur ekonomi di perkotaan lebih besar diduga meningkatkan Indeks Gini yang berarti ketimpangan pendapatan semakin besar. Persamaan Indeks Gini provinsi-i tahun-t adalah:
GINIit = v0 + v1SHPDRBTANIit + v2SHPDRBINDit + v2SHPDRBDGit
+ v
3GINIit-1 + u22it
Hipotesis: v
(4.48)
1 < 0; v2≠ 0; v3 > 0; 0 < v4
dimana,
< 1 GINI: Indeks Gini
SHPDRBTANI: share PDRB pertanian (%) SHPDRBIND: share PDRB industri (%) SHPDRBDG: share PDRB perdagangan (%)
Tingkat kemiskinan umumnya dinyatakan dalam tiga indikator FGT yang dikembangkan oleh Foster, et al. (1984), yaitu Headcount index (P0), Poverty Gap
Index (P1), dan Poverty Severity Index (P2
POVTANIP0
). Ketiga indikator kemiskinan tersebut diduga dipengaruhi oleh pengeluaran per kapita, Indeks Gini, dan garis kemiskinan. Penggunaan ketiga variabel tersebut mengacu pada konsep Kakwani (1993) yang mendefinisikan indeks kemiskinan sebagai fungsi dari garis kemiskinan, rata-rata pendapatan per kapita, dan ketimpangan pendapatan. Studi-studi empiris terdahulu antara lain Nanga (2006) serta Laabas dan Limam (2004) juga menggunakan ketiga variabel tersebut dalam mengestimasi ketiga indikator kemiskinan FGT. Hipotesis hubungan ketiganya adalah pengeluaran per kapita yang lebih besar diduga menurunkan kemiskinan, sedangkan Indeks Gini dan garis kemiskinan yang lebih besar diduga meningkatkan kemiskinan. Pada penelitian ini, estimasi headcount index dilakukan untuk ketiga sektor, sedangkan estimasi poverty gap index dan poverty severity index hanya dilakukan pada sektor pertanian. Selain headcount index sektoral estimasi terhadap total headcount index juga dilakukan menggunakan ketiga headcount index sektoral. Meskipun total headcount index dapat dihitung dari dekomposisi headcount index sektoral tetapi karena headcount index sektoral pada penelitian ini hanya diestimasi untuk tiga sektor maka total headcount index tidak dihitung secara aditif melainkan diestimasi dari ketiga headcount index sektoral tersebut yaitu headcount index pertanian, headcount index industri, dan headcount index perdagangan. Persamaan ketiga indikator kemiskinan di provinsi-i tahun-t adalah:
it = w0 + w1EXPTANIit + w2GINIit + w3GKit + u23it
POVINDP0
(4.49)
it = x0 + x1EXPINDit + x2GINIit + x3GKit + u24it
POVDGP0
(4.50)
it = y0 + y1EXPDGit + y2GINIit + y3GKit + u25it
POVTANIP1
(4.51)
it = z0 + z1EXPTANIit + z2GINIit + z3GKit + u26it
POVTANIP2
(4.52)
it = aa0 + aa1EXPTANIit + aa2GINIit + aa3GKit + u27it
POVP0
(4.53)
it = ab0 + ab1POVTANIP0it + ab2POVINDP0it + ab3POVDGP0it
+ u 28it Hipotesis: (4.54) w1, x1, y1, z1, aa1 < 0; w2, w3, x2, x3, y2, y3, z2, z3, aa2, aa3, ab1, ab2, ab3 dimana, > 0 POVTANIP0: headcount index pertanian (%)
POVINDP0: headcount index industri (%) POVDGP0: headcount index perdagangan (%) POVTANIP1: poverty gap index pertanian POVTANIP2: poverty severity index pertanian POVP0: total headcount index (%)
EXPTANI: pengeluaran per kapita pertanian per bulan (ribu Rp) EXPIND: pengeluaran per kapita industri per bulan (ribu Rp) EXPDG: pengeluaran per kapita perdagangan per bulan (ribu Rp) GINI: Indeks Gini
GK: Garis Kemiskinan (ribu Rp)
Identifikasi dan Metode Estimasi Model
Identifikasi merupakan suatu permasalahan formulasi bukan estimasi atau penilaian (appraisal) model (Koutsoyiannis, 1977). Namun, identifikasi sangat terkait dengan estimasi, yaitu: (1) jika suatu persamaan tidak teridentifikasi maka estimasi seluruh parameter tidak mungkin dilakukan dengan teknik ekonometrik apapun; dan (2) jika suatu persamaan teridentifikasi maka secara umum koefisien parameternya dapat diestimasi secara statistik. Identifikasi dapat dilakukan dengan memeriksa spesifikasi model struktural atau dengan memeriksa model yang direduksi. Namun, pendekatan pertama lebih sederhana dan lebih berguna sehingga penelitian ini menggunakan pendekatan tersebut. Ada dua kondisi yang harus dipenuhi oleh suatu persamaan dalam identifikasi model yaitu order condition dan rank condition. Syarat order condition dilakukan berdasarkan jumlah variabel yang dimasukkan dan dikeluarkan dari suatu persamaan. Untuk memenuhi syarat order condition pada persamaan yang akan diidentifikasi maka jumlah variabel (endogen dan eksogen) yang dikeluarkan dari persamaan tersebut harus sama atau lebih besar dari jumlah variabel endogen dalam model dikurangi satu, atau:
(K – M) ≥ (G – 1) (4.55)
dimana:
G : jumlah persamaan (= jumlah variabel endogen) dalam model K : jumlah variabel dalam model (endogen dan predetermined)
M : jumlah variabel endogen dan eksogen dalam suatu persamaan struktural Dengan demikian, jika:
(K-M) > (G-1) maka persamaan teridentifikasi berlebih (over identified) (K-M) = (G-1) maka persamaan teridentifikasi tepat (exactly identified) (K-M) < (G-1) maka persamaan tidak teridentifikasi (unidentified)
Jjika persamaan teridentifikasi tepat (exactly identified) maka estimasi dapat dilakukan dengan metode Indirect Least Squares (ILS), namun jika teridentifikasi berlebih (over identified) dapat digunakan beberapa metode antara lain two-stage least squares (2SLS) dan maximum likelihood (Koutsoyiannis, 1997). Perbedaan mendasar dari kedua metode ini adalah metode Maximum Likelihood memerlukan sampel besar dan variabel-variabel berdistribusi multivariate normal. Sedangkan metode 2SLS tidak memerlukan asumsi distribusi apapun dan dapat digunakan untuk sampel kecil (Sulistiyawan, 2009). Selain itu, metode 2SLS menghasilkan estimasi konsisten dan efisien serta konsep dan komputasinya lebih sederhana (Koutsoyiannis, 1977).
Syarat order condition merupakan syarat perlu (necessary) namun tidak cukup karena meskipun syarat tersebut terpenuhi suatu persamaan namun hubungannya bisa saja tidak dapat diidentifikasi. Oleh karena itu, dalam proses identifikasi diperlukan rank condition yang merupakan syarat cukup (sufficient), yaitu dalam suatu sistem dengan G buah persamaan maka suatu persamaan akan teridentifikasi jika dan hanya jika dimungkinkan untuk membentuk minimal satu nilai determinan bukan nol (non-zero determinant) pada order (G-1) dari koefisien variabel yang dikeluarkan dari persamaan namun ada di persamaan-persamaan
lain dalam model (Koutsoyiannis, 1977). Artinya, rank condition ditentukan oleh determinan turunan pertama persamaan struktural yang nilainya tidak nol.
Model Fiskal, Perekonomian, dan Kemiskinan Sektoral Daerah terdiri dari 48 variabel endogen dan 37 variabel predetermined (14 variabel lag endogen dan 23 variabel eksogen) sehingga ada 85 variabel dalam model (K), 3 sampai 6 variabel endogen dan eksogen dalam suatu persamaan struktural, dan 48 variabel endogen atau jumlah persamaan dalam model. Berdasarkan kriteria identifikasi sesuai persamaan (4.55) diketahui jumlah variabel (endogen dan eksogen) yang dikeluarkan dari setiap persamaan (K-M) lebih besar dari jumlah variabel endogen dalam model dikurangi satu (G-1) yang berarti model teridentifikasi berlebih (over identified) sehingga dapat diestimasi dengan metode 2SLS. Program dan hasil estimasi model dengan metode 2SLS prosedur syslin pada software SAS/ETS 9.1.3 secara lengkap disajikan pada Lampiran 4 dan 5.
Evaluasi Model
Hasil estimasi selanjutnya digunakan untuk mengevaluasi model untuk mengetahui apakah sesuai dengan kriteria ekonomi dan kriteria statistik. Analisis kriteria ekonomi bertujuan untuk mengetahui apakah model sesuai dengan teori-teori ekonomi (theoretically meaningful). Hal ini dilakukan dengan menganalisis tanda setiap koefisien variabel. Sedangkan, analisis kriteria statistik bertujuan untuk mengetahui kesesuaian model (goodness of fit) yang dapat dilakukan dengan menganalisis koefisien determinasi (R2), uji F dan uji t. R2 merupakan ukuran proporsi variasi variabel dependen yang dijelaskan secara bersama-sama oleh seluruh variabel penjelas pada suatu persamaan regresi. Nilai R2 tersebut dapat menjadi petunjuk seberapa baik garis regresi mendekati nilai data aktualnya. Jika R2 bernilai satu maka garis regresi cocok dengan data secara sempurna, sedangkan jika R2 bernilai nol maka garis regresi tidak cocok dengan data secara sempurna. Nilai R2 2 i 2 i i Total Error Total Reg 2 ) y (y ) yˆ (y 1 SS SS 1 SS SS R
∑
∑
− − − = − = =dihitung dengan rumus berikut (Walpole dan Myers, 1978): (4.56) dimana,
SSReg
SS
: Sum squares of regression
Total
y
: Sum squares of total
i
i yˆ
: nilai aktual variabel dependen ke-i : nilai estimasi variabel dependen ke-i y : rata-rata nilai aktual variabel dependen
Analisis kriteria statistik juga dilakukan dengan uji F untuk mengetahui apakah variabel penjelas secara bersama-sama berpengaruh nyata (significant) secara statistik pada variabel dependen. Untuk mengujinya maka nilai F dibandingkan dengan nilai F pada tingkat signifikasi (α) tertentu. Jika lebih besar maka hipotesis nol H0: β1 = β2 = … = βk = 0 yang berarti semua variabel penjelas tidak
mempengaruhi variabel dependen ditolak. Artinya, seluruh variabel penjelas secara bersama-sama mempengaruhi variabel dependen secara nyata pada tingkat signifikansi α. Nilai F dihitung dengan rumus:
1) k )/(n R (1 /k) (R F 2 2 − − − = (4.57) dimana, R2
n = jumlah observasi (sampel) : koefisien determinasi k = jumlah variabel penjelas
Sedangkan, uji t untuk mengetahui pengaruh setiap variabel penjelas pada variabel dependen. Untuk itu, nilai t dibandingkan dengan t pada α tertentu. Jika lebih besar maka hipotesis nol H0: βi
SE βˆ t= i
= 0; i = 1, 2, …, k yang berarti suatu variabel penjelas tertentu tidak mempengaruhi variabel dependen ditolak. Artinya, suatu variabel penjelas mempengaruhi variabel dependen pada tingkat signifikansi α. Nilai t dihitung dengan rumus:
; i = 0, 1, 2, …, k (4.58)
dimana,
i
βˆ : koefisien parameter variabel ke-i SE = Standar error
Prosedur Simulasi Model Validasi Model
Validasi model dilakukan untuk mengetahui apakah model layak digunakan dalam menganalisis dampak suatu kebijakan melalui simulasi alternatif kebijakan. Untuk itu diperlukan suatu kriteria yang mengacu pada selisih nilai prediksi dan nilai aktual setiap variabel endogen. Jika hasil validasi menunjukkan perbedaan nilai prediksi dan nilai aktual kecil atau nilai prediksi relatif tidak menyimpang dari nilai aktual maka dapat dilakukan simulasi. Indikator statistik yang digunakan adalah rms (root-mean-squrae) simulation error (Pyndick dan Rubinfeld, 1991). Indikator rms simulation error yang sering digunakan adalah Root Mean Square Percentage Error (RMSPE) untuk mengukur sejauh mana nilai-nilai variabel endogen hasil simulasi relatif menyimpang dari nilai-nilai aktualny dimana semakin kecil RMSPE semakin baik estimasi model. Indikator dihitung dengan:
–
(4.59)
dimana,
: nilai prediksi (simulasi) dari Y : nilai aktual Y
t
T : jumlah periode simulasi
t
Namun, jika model dirancang untuk keperluan peramalan (forecasting) maka indikator statistik rms simulation error yang dapat digunakan adalah Theil Inequality Coefficient (U). Indikator ini diperoleh dengan rumus:
(4.60) dimana,
: nilai prediksi (simulasi) dari Y : nilai aktual Y
t
T : jumlah periode simulasi
t
Bagian numerator dari indikator ini adalah rms simulation error. Namun skala denominator menyebabkan U bernilai antara nol dan satu. Jika U bernilai nol atau untuk setiap t berarti cocok secara sempurna (perfect fit). Namun, jika U bernilai satu maka nilai-nilai prediksi selalu nol untuk nilai-nilai aktual yang tidak nol, atau nilai-nilai prediksi tidak bernilai nol untuk nilai-nilai aktual yang bernilai nol. Hal ini menunjukkan bahwa nilai-nilai simulasi akan positif (negatif) untuk nilai-nilai aktual yang negatif (positif). Dengan perkataan lain, model dapat digunakan untuk simulasi apabila nilai-nilai U semakin kecil. Theil Inequality Coefficient (U) dapat didekomposisi menjadi (Pyndick dan Rubinfeld, 1991) :
(4.61) dimana,
: rata-rata nilai prediksi : rata-rata nilai aktual
: standar deviasi untuk nilai prediksi : standar deviasi untuk nilai aktual : koefisien korelasi
dan
(4.62)
Proporsi dari U (proportion of inequality) dapat didefinisikan sebagai berikut : (4.63) (4.64) (4.65) dimana,
UM : proporsi bias digunakan untuk mengindikasikan error sistematik (systematic error) yang merupakan ukuran rata-rata deviasi nilai-nilai simulasi dari nilai-nilai aktualnya. Nilai UM diharapkan mendekati nol dimana nilai UM
U
yang besar (lebih dari 0.2) menunjukkan adanya bias sistematik sehingga model harus direvisi.
S
: proporsi variansi yang mengukur seberapa jauh variansi nilai-nilai prediksi menyimpang dari variansi nilai-nilai aktual. Nilai-nilai US mengindikasikan kemampuan model mereplikasi derajat variabilitas dari variabel-variabel tertentu. Nilai US yang baik adalah mendekati nol. Nilai US besar menunjukkan nilai-nilai aktual sangat berfluktuasi
sementara nilai-nilai simulasi kurang berfluktuasi, atau sebaliknya sehingga model harus direvisi.
UC : proporsi kovariansi yang merupakan ukuran error tidak sistematik (unsystematic error). Indikator ini juga merupakan sisa error. Namun, indikator ini tidak terlalu diperhatikan karena tidak beralasan untuk mengharapkan nilai-nilai prediksi yang berkorelasi sempurna dengan nilai-nilai aktualnya. Namun, untuk setiap U positif (U > 0) maka distribusi inequality yang ideal dari ketiga error ini adalah UM = US = 0 dan UC = 1 (Pindyck dan Rubinfeld, 1991). Distribusi U yang ideal atas ketiga proporsi tersebut adalah UM = US = 0 dan UC
Hubungan ketiganya dapat diperoleh dengan membagi persamaan (4.61) dengan sisi kiri, sehingga:
= 1.
UM + US + UC
Pada penelitian ini, validasi dilakukan dengan prosedur SIMNLIN metode solusi Newton pada software SAS/ETS 9.1.3. Program validasi dan hasilnya secara lengkap disajikan pada Lampiran 6 dan 7.
= 1 (4.66)
Simulasi Kebijakan
Simulasi seringkali digunakan dalam rancangan kebijakan publik. Istilah simulasi secara sederhana adalah solusi matematis dari sekumpulan persamaan simultan (Pyndick dan Rubinfeld, 1991). Secara teoritis, tujuan simulasi kebijakan adalah untuk menganalisis dampak dari berbagai alternatif atau skenario kebijakan dengan cara mengubah nilai variabel atau instrumen kebijakannya baik variabel eksogen maupun variabel endogen. Oleh karena itu, proses simulasi merupakan proses penentuan prediksi nilai-nilai variabel endogen dengan cara substitusi hasil estimasi koefisien regresi variabel penjelas dan nilai-nilai aktualnya ke dalam model regresi yang berkaitan dengan variabel endogen dalam simulasi.
Simulasi dapat dibedakan menurut horison waktu yaitu ex-post simulation dan ex-ante simulation. Ex-post simulation atau simulasi historis adalah simulasi pada periode data penelitian. Ex-ante simulation atau simulasi peramalan adalah simulasi pada periode di luar data penelitian. Untuk itu, terlebih dahulu harus dilakukan peramalan terhadap variabel-variabel eksogen. Pada penelitian ini simulasi dilakukan secara historis (ex-post simulation) dan peramalan (ex-ante simulation) untuk menganalisis dampak kebijakan yang mendorong peran kapasitas fiskal dalam menurunkan kemiskinan sektoral melalui perbaikan kinerja perekonomian dengan mempertimbangkan perbaikan kinerja fiskal. Hasil simulasi selanjutnya akan direkomendasikan jika berdampak positif dan memihak penduduk miskin terutama yang bekerja di sektor pertanian sehingga dapat mempercepat pengentasan kemiskinan nasional mengingat insiden kemiskinan paling tinggi di sektor pertanian.
Simulasi model yang menggunakan variabel lag dapat dilakukan secara statis, dinamis, dan kombinasi keduanya (Sitepu dan Sinaga, 2006). Simulasi statis (static simulation) menggunakan nilai aktual dari variabel lag, sedangkan simulasi dinamis (dynamic simulation) menggunakan solusi dari nilai-nilai variabel lag (SAS Institute Inc., 2004). Penelitian ini melakukan simulasi dinamis dimana pada beberapa persamaan struktural dalam model terdapat variabel lag
endogen. Proses simulasi diawali dengan mengklasifikasikan seluruh provinsi penelitian menjadi dua yaitu provinsi pertanian dan provinsi non-pertanian. Klasifikasi ini dilakukan dengan alasan ada perbedaan yang cukup besar terkait karakteristik fiskal, perekonomian, dan kemiskinan antara provinsi pertanian dan provinsi non-pertanian. Klasifikasi dilakukan dengan membandingkan share PDRB pertanian di suatu provinsi dengan rata-rata share PDRB pertanian seluruh provinsi periode 2006-2011. Jika share PDRB pertanian lebih besar dari rata-rata maka provinsi tersebut diklasifikasikan sebagai provinsi pertanian, sedangkan jika lebih kecil dari rata-rata diklasifikasikan sebagai provinsi non-pertanian. Rata-rata share PDRB pertanian di setiap provinsi penelitian dan klasifikasinya disajikan pada Tabel 8.
Tabel 8 Rata-rata Share PDRB Riil1
Provinsi Pertanian
Pertanian Tahun 2006-2011 (%)
Provinsi Non-Pertanian
1. Nanggroe Aceh Darussalam 27.0 1. Riau 20.1
2. Sumatera Utara 22.7 2. Sumatera Selatan 17.6
3. Sumatera Barat 24.3 3. Kepulauan Riau 4.9
4. Jambi 27.3 4. Jawa Barat 11.9
5. Lampung 37.5 5. Jawa Tengah 19.9
6. Nusa Tenggara Barat 22.0 6. Daerah Istimewa Yogyakarta 15.1
7. Nusa Tenggara Timur 39.4 7. Jawa Timur 16.3
8. Kalimantan Barat 25.8 8. Banten 7.8
9. Kalimantan Tengah 30.5 9. Bali 18.9
10. Kalimantan Selatan 22.0 10. Kalimantan Timur 5.6
11. Sulawesi Tengah 41.4 11. Sulawesi Utara 19.6
12. Sulawesi Selatan 28.2
Catatan: 1 Sumber: BPS
Nilai nominal dikonversi ke riil menggunakan IHK provinsi tahun dasar 2007
Skenario kebijakan terdiri dari kebijakan tunggal (single policy) dan kebijakan gabungan. Simulasi skenario kebijakan tunggal dilakukan pada periode periode 2006-2011 untuk masing-masing kelompok provinsi pertanian dan provinsi non-pertanian. Hasil simulasi selanjutnya menjadi acuan penyusunan skenario kebijakan gabungan periode historis 2006-2011 dan periode peramalan 2013-2015 dengan besaran perubahan instrumen kebijakan mengacu pada arah dan besaran perubahan variabel-variabel endogen yang menjadi fokus penelitian. Variabel-variabel skenario dipilih berdasarkan tujuan penelitian serta koefisien paramaeter dan koefisien elastisitas dari hasil estimasi model namun tetap berada pada kerangka peningkatan kapasitas fiskal untuk mengurangi ketergantungan keuangan daerah pada DAU dan berdampak menurunkan tingkat kemiskinan dan ketimpangan pendapatan melalui efek pertumbuhan pro-poor. Sebagai contoh, skenario peningkatan belanja pertanian dilakukan dengan alasan bahwa dari hasil estimasi diketahui pengaruh kapasitas fiskal pada belanja pertanian lebih kecil dibandingkan pengaruh DAU. Oleh karena itu, untuk mencapai pertumbuhan pro-poor melalui strategi pembangunan pertanian maka belanja pertanian harus ditingkatkan. Selain itu, variabel skenario terpilih merupakan
variabel-variabel yang berpotensi meningkatkan kapasitas fiskal, salah satunya bagi hasil pajak. Rincian setiap skenario serta penjelasan alasan yang menjadi pertimbangan dalam menentukan besaran perubahan varaibel-variabel yang menjadi instrumen kebijakan secara lengkap disajikan pada bagian analisis dampak setelah ulasan hasil estimasi karena terkait dengan hasil estimasi model.