NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 40 ISSN 2303-0135
Penggalian Data dalam Penentuan
Keterkaitan Topik pada Terjemahan
Ayat-ayat Al-Qur’an
Lailil Muflikhah1, Marji2, Dewi Yanti L.3
1,2,3Program Studi Ilmu Komputer, Fakultas MIPA, Universitas Brawijaya, Malang, Indonesia
Abstrak— Dalam mempelajari isi kandungan Al-Qur’an, seringkali kita hanya membaca dan memahami suatu ayat yang berada dalam satu topik tertentu saja tanpa menyadari adanya ketersinggungan dengan ayat lain dengan topik yang berbeda. Padahal, isi dari suatu ayat seringkali diperjelas pada ayat dan bahkan surat yang berbeda. Oleh karena itu, pada penelitian ini bertujuan melakukan penggalian data dengan cara mengetahui adanya keterkaitan antar topik dalam terjemahan ayat-ayat Al-Qur’an.Adapun metode yang digunakan dalam penelitian ini dengan memadukan dua metode yakni Weighted K-Nearest Neighbour (WKNN) dengan Multiple Direct Hashing and Prunning (M-DHP). WKNN merupakan salah satu dari algoritma klasifikasi yang berfungsi sebagai preprocessing data untuk menentukan topik dalam suatu terjemahan ayat. Sedangkan M-DHP berfungsi sebagai pencarian keterkaitan topik-topik dalam terjemahan ayat Al-Qur’an. Pengujian kinerja penelitian ini dilakukan terhadap penentuan topik dengan mencari nilai precision, recall dan f-measure. Dari hasil pengujian didapatkan nilai rata-rata precision=0.810, recall=0.699 dan f-measure=0.750. Selanjutnya uji coba dilakukan terhadap tingkat kekuatan rule yang dihasilkan. Rule-rule yang dihasilkan memiliki keakuratan tertinggi dengan nilai confidence mencapai 100% dan nilai confiction tak berhingga.
Kata Kunci— penggalian data, klasifikasi, keterkaitan topik, ayat-ayat al-Qur’an.
1 P
ENDAHULUANPada Al-Qur’an terjemahan baik yang dalam bentuk fisik ataupun digital telah dikelompokkan berdasarkan topik dari ayat tersebut, namun belum ada yang menampilkan suatu bentuk keterkaitan atau asosiasi antar topik, padahal berbagai topik yang terkandung di dalam Al-Qur’an akan saling terkait satu sama lain. Beberapa penelitian tentang pencarian ayat-ayat Al-Qur’an berdasarkan content menggunakan text mining telah dilakukan dengan menggunakan metode korelasi. M. Syaiful Rizal dalam Tugas Akhirnya membahas tentang permasalahan aqidah berdasarkan content menggunakan text mining. Kemudian dikembangkan lagi permasalahannya yang bukan hanya membahas tentang permasalahan aqidah saja oleh Aditya Herdianto dengan semua pemasalahan dengan topik pencarian ayat-ayat al-qur’an berdasarkan konten menggunakan text
mining berbasis aplikasi desktop.
Adapun pencarian topik dalam terjemahan yang merupakan salah satu penerapan dari metode klasifikasi erat kaitannya dengan permasalahan dengan pengkategorisasian teks yang merupakan proses secara otomatis menempatkan dokumen teks ke dalam suatu kategori berdasarkan isi dari teks tersebut (Zhang, dkk., 2009). Pada kebanyakan penelitian dengan metode-metode klasifikasi standar mengasumsikan bahwa dokumen training di distribusikan secara rata. Padahal pada kenyataannya kumpulan data yang tidak seimbang sering kali muncul (Japkowicz, 2000). Pada kumpulan data yang tidak seimbang, kelas mayoritas digambarkan oleh banyaknya data training, sementara kelas minoritas hanya memiliki sedikit data training. Sehingga diperkenalkan oleh Tan (2005) untuk mengatasi permasalahan tersebut dengan memberikan bobot yang kecil pada kelas mayoritas dan bobot yang besar pada kelas minoritas yang dikenal dengan metode
Neighbor-weighted K-Nearest Neighbor (NWKNN). Melihat dari pola data yang terdapat ayat Al-Qur’an yang tersebar di
berbagai surat dalam jumlah yang tidak seimbang, maka dalam penelitian ini akan digunakan metode tersebut. Selain itu, dalam upaya mencari hubungan antar topik dalam suatu surat sangatlah menarik untuk dikaji juga. Beberapa penelitian yang telah dilakukan dalam upaya mencari keterkaitan antar item dalam suatu dataset menggunakan metode association rule mining (Han dan Kamber, 2000). Algoritma yang telah digunakan mulai dari Apriori, kemudian dikembangkan dengan meminimisasi pembentukan kandidat seperti FP-Growth, Fold
Growth sampai dengan Hash Table Apriori, Hasil yang didapatkan berupa rule yang kuat berisi keterkaitan
- – –
-2
! "### $ - % ! &' "##( 1. 2. 3. 4. ! &' "##( ) 2.1 ! * & ) "#++ ! ' ) "##" ! ( , "##-2.1.1 -- !.. ' $ !.. ' -) / -$ + " (1) %• KNN(q) : dokumen latih dj yang berada pada kumpulan tetangga terdekat (nearest neighbor)
dari dokumen uji q.
• : similarity antara dokumen uji q dengan dokumen latih dj
! (2)
% /
- – – -2.1.2 - -0 !.. - - ) 1 "##2 0 "#$ #% & # '( ! ( ) *+, $ - . /012345 6 378. /01204 59 0:; & <'=> ;?@ABC7@7D (3) %
• EF # merupakan banyaknya dokumen latih d pada kategori i
• EF #G merupakan banyaknya dokumen latih d pada kategori m, dimana kategori m merupakan
kategori-kategori yang terdapat dalam K. • exponent merupakan bilangan lebih dari 1
-%
) *+, (4)
%
• Weighti : bobot kategori i
• KNN(q) : dokumen latih dj yang berada pada kumpulan tetangga terdekat (nearest neighbor) dari
dokumen uji q.
• : similarity antara dokumen uji q dengan dokumen latih dj, ! %
• Seperti halnya algoritma KNN, dokumen uji q masuk ke dalam kelas dengan nilai skor yang paling tinggi. 2.2 ' ! "### 0 "##" % ' 1. 2. 3 4 2 ) 4 5
HIJJKLM N OG PQR STQUVQWV G XUYQU OUY Z
S[SQPSTQUVQWV (5)
\K]^_`a]ba c d9N OG PQR STQUVQWV G XUYQU OUY Z QU e
OG PQR STQUVQWV G XUYQU OUY Z (6)
2.2.1 - !" ! "
- $ *
- – – -! " # $- 6+ ' 1 -- $ % -1. $- 6+ $ $- $+ $" 7 $ 2. , $ -3. ' $ $-+ 7 $+ ! $ $ ! $-+ $-+ $ $-+ $ $-+ $ $+ 2.2.2 # 4 % 1 % % 8 % fg h i j $kVOl e $km[Un Zie (7) % 4 % ) 4 % 4 9 i j % i j . % #2 + : % fo h i j + ) & % + & ; "##5
3
$ ' -- .< !.. - $ ! " #$ , + - -= > % ! ' - ) $ -;& & $ &
NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 44 ISSN 2303-0135
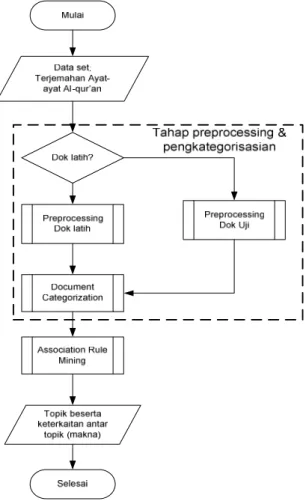
Gambar 1 Diagram Alir Sistem
Seperti halnya preprocessing dokumen latih, preprocessing dokumen uji bertujuan untuk mengubah dokumen uji menjadi representasi vektor. Perbedaan preprocessing pada dokumen latih dan dokumen uji adalah tidak adanya proses feature selection pada preprocessing dokumen uji karena term yang dipakai di dokumen uji mengacu pada term yang ada pada kamus yang telah dibentuk pada preprocessing dokumen latih.
Untuk proses perhitungan bobot term dokumen juga menggunakan metode TF-IDF. Nilai TF yang digunakan adalah nilai TF untuk term pada dokumen uji. Sedangkan nilai IDF dari term merupakan nilai IDF yang sudah dihitung pada preprocessing dokumen latih.
3.1 Classifier Construction
Classifier construction atau pembentukan classifier dibagi menjadi dua sub proses, yaitu proses
perhitungan kemiripan menggunakan Cossine Similarity dan proses pembentukan classifier dengan menggunakan metode Neighbor-weighted K-Nearest Neighbor (NWKNN). Hasil dari cossine similarity tiap dokumen latih dengan dokumen uji diurutkan berdasarkan nilai terbesar. Kemudian dipilih nilai similarity sebanyak k terbesar. K merupakan inputan berupa bilangan bulat lebih dari 0. Pada himpunan k dapat berisi beberapa dokumen latih yang berasal dari satu atau lebih kategori. Langkah selanjutnya adalah menghitung bobot kategori dengan menggunakan Persamaan 3. Pada persamaan tersebut terdapat parameter exponent.
Exponent merupakan inputan berupa bilangan lebih dari 1. Bobot kategori yang telah dihitung kemudian
digunakan untuk menghitung skor antara dokumen uji dengan masing-masing kategori, dimana rumus untuk menghitung skor tersebut ditunjukkan pada Persamaan 4.
3.2 Document Categorization
Proses yang terakhir adalah proses document categorization atau klasifikasi dokumen. Pengklasifikasian dokumen menggunakan model classifier yang telah dibuat pada classifier constrction. Berdasarkan nilai skor
NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 45 ISSN 2303-0135
dokumen uji terhadap masing-masing kategori, kategori yang memiliki skor paling tinggi dianggap sebagai kategori dari dokumen uji. Flowchart document categorization dapat dilihat pada Gambar 1.
3.3 Pencarian Keterkaitan Antar Topik
Untuk menerapkan metode M-DHP pada sistem pencarian asosiasi topik dari ayat-ayat surat yang terkandung di dalam Al-Qur’ an, terdapat beberapa langkah proses yang harus dilakukan agar menghasilkan suatu rule yang baik dan terpercaya. Adapun lingkungan implementasi yang dikembangkan dibagi menjadi dua, yakni klasifikasi untuk penentuan topik dan pencarian pola keterkaitan antar topik dalam Al-Qur’ an.
4 U
JIC
OBAPada bagian ini menjelaskan implementasi dari rancangan uji coba yang telah dibuat pada bagian sebelumnya. Adapun macam topik dan jumlah dokumen dalam setiap topik terlihat pada Tabel 1.
Uji coba dilakukan terhadap ketepatan penentuan topik, dengan menggunakan metode WKNN. Beberapa parameter yang terlibat dalam metode ini diujikan untuk mengetahui pengaruhnya terhadap keakuratan.
Pada uji coba pertama digunakan untuk mengetahui pengaruh nilai exponent terhadap nilai akurasi, yakni
precision (P), recall (R) dan F measure (F1) sebagaimana ditunjukkan pada Tabel 2. Adapun variabel threshold
dan jumlah tetangga terdekat (k) =1.
Sedangkan pada uji coba kedua dilakukan untuk mengetahui pengaruh nilai k terhadap akurasi untuk penentuan topik dan hasilnya terlihat pada Tabel 3.
Hasil akurasi menunjukkan angka kemiripan, hal ini berarti perubahan nilai tidak menimbulkan perbedaan yang signifikan dan juga tidak adanya pola kecenderungan semakin besar nilai k terhadap tingkat akurasi. Namun demikian, pada k=5 mencapai nilai akurasi (precission, recall, dan f-measure) yang paling tinggi.
Setelah dilakukan penentuan topik di setiap terjemahan ayat, maka dilakukan tahap awal dari metode keterkaitan antar topik. Pada Tabel 4 terlihat untuk membentuk data transaksi dengan memetakan pokok bahasan (topik) sebagaimana terlihat pada Tabel 5.
TABEL 1 TOPIK BESERTA JUMLAH DOKUMEN
Pokok Bahasan (Topik) Jumlah Dokumen
Akhlaq mulia 86 Al-Qur’ an 122 Bangsa-bangsa 56 Hukum Pidana 26 Iman 42 Ilmu 54 Ibadah 48 Hukum privat 43
Makanan dan minuman 36
Jihad 54
Muamalat 16
Pakaian dan Perhiasan 12
Peradilan 22
NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 46 ISSN 2303-0135
TABEL 2.EVALUASI UJI COBA TERHADAP BERBAGAI NILAI EXPONENT
TABEL 3.EVALUASI UJI COBA TERHADAP BERBAGAI MACAM NILAI K
Exponent P R F1 1 0.818 0.671 0.715 1.5 0.810 0.662 0.706 2 0.810 0.662 0.706 2.5 0.810 0.662 0.706 3 0.810 0.662 0.706 3.5 0.810 0.662 0.706 4 0.810 0.662 0.706 4.5 0.810 0.662 0.706 5 0.810 0.662 0.706 5.5 0.810 0.662 0.706 6 0.810 0.662 0.706 6.5 0.810 0.662 0.706 7 0.810 0.662 0.706 k P R F1 1 0.818 0.671 0.737 2 0.843 0.723 0.778 3 0.843 0.724 0.779 4 0.825 0.715 0.766 5 0.825 0.715 0.766 6 0.824 0.715 0.766 10 0.810 0.659 0.727 15 0.805 0.703 0.751 20 0.805 0.703 0.751 30 0.797 0.699 0.745 40 0.795 0.696 0.742 50 0.796 0.695 0.742 100 0.792 0.693 0.739 150 0.789 0.692 0.737 200 0.792 0.693 0.739 300 0.795 0.694 0.741
NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 47 ISSN 2303-0135
TABEL 4.DAFTAR TOPIK DALAM AL-QUR’AN (ITEM)
TABEL 5.DATA KEMUNCULAN TOPIK DI TIAP-TIAP SURAT
Keterangan:
Tid : nomor transaksi yang menunjukkan nomor surat dalam Al-qur’ an Itemset : nomor topik dari surat Al-Qur’ an yang diperoleh dari Al-qur’ an digital
Setelah dibentuk data transaksi, maka diimplementasikan metode M-DHP untuk membentuk pola keterkaitan antar topik dalam surat al-Qur’ an (association rule). Pembentukan rule diperoleh berdasarkan kemunculan topik dari suatu ayat dalam setiap surat. Kemudian dilakukan beberapa uji coba dengan memasukkan berbagai nilai dari variabel input, yakni: minimum confidence, minimum support, dan jumlah partisi sebagaimana tercantum dalam skenario uji coba sehingga dihasilkan rule, nilai support, confidence dan nilai confiction sebagaimana pada Tabel 6.
Kode Item Item
1 Al Qur’ an
2 Iman
3 Ilmu
4 Ibadah
5 Akhlaq dan Adab 6 Hikum Privat
7 Makanan dan minuman 8 Pakaian dan perhiasan 9 Muamalat
10 Peradilan dan Hakim 11 Hukum pidana (jinayah) 12 Bangsa-bangsa terdahulu 13 Sejarah 14 Jihad Tid Itemset 1 1 12 4 2 2 5 1 12 0 6 4 3 2 14 7 9 8 10 13 3 5 1 12 6 4 3 2 14 7 9 10 13 4 5 1 12 0 6 4 3 2 14 7 9 8 10 13 5 5 1 12 0 6 4 3 2 14 7 9 8 10 13 6 5 1 12 0 6 4 3 2 14 7 9 10 13 7 5 1 12 6 4 3 2 7 8 10 13 8 5 1 12 6 4 3 2 14 9 10 13 9 5 1 12 0 6 4 3 2 14 9 10 13 10 5 1 12 4 3 2 7 13 11 5 1 12 6 4 2 10 13 12 5 1 12 6 4 3 2 9 10 13 13 5 1 12 6 4 2 7 9 13 113 5 4 3 2 114 4 2
NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 48 ISSN 2303-0135
TABEL 6.HASIL RULE YANG TERBENTUK DENGAN NILAI AKURASI YANG TERTINGGI
RULE Support Confidence Conviction
Ilmu=>Akhlaq_dan_Adab 49.12 100.00 Inf Ilmu=>Iman 49.12 100.00 Inf Sejarah=>Iman 78.07 100.00 Inf Bangsa_Terdahulu=>Iman 81.58 100.00 Inf Akhlaq_dan_Adab=>Iman 86.84 100.00 Inf Ibadah=>Iman 88.60 100.00 Inf Al_Qur'an=>Iman 94.74 100.00 Inf
Ilmu=>Iman Akhlaq_dan_Adab 49.12 100.00 Inf
Ilmu Sejarah=>Iman Akhlaq_dan_Adab 44.74 100.00 Inf
Ilmu=>Iman Akhlaq_dan_Adab 47.37 100.00 Inf
Ilmu Ibadah=>Iman Akhlaq_dan_Adab 46.49 100.00 Inf Al_Qur'an Ilmu=>Iman Akhlaq_dan_Adab 47.37 100.00 Inf
Ibadah=>Al_Qur'an Iman 74.56 100.00 Inf
Ilmu Sejarah=>Iman Akhlaq_dan_Adab 43.86 100.00 Inf Ilmu Ibadah Sejarah=>Al_Qur'an Akhlaq_dan_Adab 42.98 100.00 Inf Ilmu Ibadah Sejarah=>Iman Akhlaq_dan_Adab 42.98 100.00 Inf Al_Qur'an Ilmu Sejarah=>Iman Akhlaq_dan_Adab 43.86 100.00 Inf Ilmu Ibadah Sejarah=>Al_Qur'an Iman 42.98 100.00 Inf Ilmu Ibadah=>Al_Qur'an Akhlaq_dan_Adab 44.74 100.00 Inf Ilmu Ibadah=>Iman Akhlaq_dan_Adab 44.74 100.00 Inf Al_Qur'an Ilmu=>Iman Akhlaq_dan_Adab 46.49 100.00 Inf
Ilmu Ibadah=>Al_Qur'an Iman 44.74 100.00 Inf
Al_Qur'an Ilmu Ibadah=>Iman Akhlaq_dan_Adab 45.61 100.00 Inf Ibadah Sejarah=>Al_Qur'an Iman 66.67 100.00 Inf Ibadah Akhlaq_dan_Adab=>Al_Qur'an Iman 71.05 100.00 Inf Ilmu Ibadah Sejarah=>Al_Qur'an Akhlaq_dan_Adab 42.11 100.00 Inf Ilmu Ibadah Sejarah=>Iman Akhlaq_dan_Adab 42.11 100.00 Inf Al_Qur'an Ilmu Sejarah=>Iman Akhlaq_dan_Adab 42.98 100.00 Inf Ilmu Ibadah Sejarah=>Al_Qur'an Iman 42.11 100.00 Inf Ilmu Ibadah Akhlaq_dan_Adab Sejarah=>Al_Qur'an Iman 42.98 100.00 Inf Iman Ilmu Ibadah Sejarah=>Al_Qur'an Akhlaq_dan_Adab 42.98 100.00 Inf Al_Qur'an Ilmu Ibadah Sejarah=>Iman Akhlaq_dan_Adab 42.98 100.00 Inf Ilmu Ibadah Sejarah=>Al_Qur'an Iman Akhlaq_dan_Adab 42.98 100.00 Inf Ilmu Ibadah Akhlaq_dan_Adab=>Al_Qur'an Iman 44.74 100.00 Inf Iman Ilmu Ibadah=>Al_Qur'an Akhlaq_dan_Adab 44.74 100.00 Inf Al_Qur'an Ilmu Ibadah=>Iman Akhlaq_dan_Adab 44.74 100.00 Inf Ilmu Ibadah=>Al_Qur'an Iman Akhlaq_dan_Adab 44.74 100.00 Inf Ibadah Akhlaq_dan_Adab Sejarah=>Al_Qur'an Iman 65.79 100.00 Inf Ilmu Ibadah Akhlaq_dan_Adab Sejarah=>Al_Qur'an Iman 42.11 100.00 Inf Iman Ilmu Ibadah Sejarah=>Al_Qur'an Akhlaq_dan_Adab 42.11 100.00 Inf Al_Qur'an Ilmu Ibadah Sejarah=>Iman Akhlaq_dan_Adab 42.11 100.00 Inf Ilmu Ibadah Sejarah=>Al_Qur'an Iman Akhlaq_dan_Adab 42.11 100.00 Inf
NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 49 ISSN 2303-0135
5 A
NALISAAnalisa yang dilakukan adalah untuk mengetahui pengaruh beberapa parameter dalam pembentukan rule, yang meliputi jumlah partisi dan minimum support dan confidence terhadap akurasi dari rule yang terbentuk.
5.1 Pengaruh jumlah partisi terhadap akurasi rule yang terbentuk
Uji coba pertama terhadap jumlah partisi dalam upaya mencari rule keterkaitan antar topik dalam Al-Qur’ an, dimana mulai dari 2 partisi sampai dengan 14 partisi (=maksimal jumlah topik yang diujikan). Hasil uji coba terlihat pada Table 7, Tabel 8, dan Tabel 9.
TABEL 7.AKURASI HASIL UJICOBA PEMBENTUKAN RULE (MINSUP MINCONF=30)
Jumlah partisi Support Confidence Conviction
2 51.06 76.58 2.43 3 70.03 86.71 2.02 4 75.45 88.41 1.67 5 81.37 90.56 1.27 6 87.28 95.28 1.22 7 94.74 100.00 Inf 8 73.29 83.55 1.42 9 77.19 85.83 1.24 10 77.19 85.83 1.24
TABEL 8.AKURASI HASIL UJICOBA PEMBENTUKAN RULE (MINSUP MINCONF=50) Jumlah partisi Support Confidence Conviction
2 75.45 88.41 1.67
3 81.37 90.56 1.27
4 87.28 95.28 1.22
5 94.74 100.00 Inf
6 77.19 85.83 1.24
TABEL 9.AKURASI HASIL UJICOBA PEMBENTUKAN RULE (MINSUP MINCONF=60)
Jumlah partisi Support Confidence Conviction
2 75.45 88.41 1.67
3 81.37 90.56 1.27
4 87.28 95.28 1.22
5 94.74 100.00 Inf
6 77.19 85.83 1.24
Dari ketiga tabel di atas menunjukkan bahwasannya dengan pada partisi 7 dan 5 telah menghasilkan rule yang memiliki performansi yang paling tinggi.
5.2 Pengaruh minimum support dan minimum confidence terhadap akurasi rule yang terbentuk
Setelah dilakukan uji coba terhadap berbagai macam jumlah partisi, kemudian dilakukan uji coba dilakukan untuk mengetahui pengaruh minimum support dan confidence terhadap tingkat akurasi rule yang
- – – -1 +# ! " # $ ! % $ ) & % ;
6
% $ - -1. < !.. 4 % % ? ) - $ 2. $ . 3. 0 ' @ < !.. 0 ' A+ A+ +A#B+B A#58+ (- A#8(8 ! '
A( A #B-( A #8"- (- A#88C
) ' - A#B+# A#5CC (- A#82#
) 4. % 0 ' - $ $ ' 2 8 A C-8-D A +##D % ) ' +# (# 2+ #5 852B "-( +# 2# 82-2 BB-+ + 58 +# 5# 82-2 BB-+ + 58 +2 (# 2+ #5 852B "-( +2 2# 82-2 BB-+ + 58 +2 5# 82-2 BB-+ + 58 "# (# 2+ #5 852B "-( "# 2# 82-2 BB-+ + 58 "# 5# 82-2 BB-+ + 58 "2 (# 2+ #5 852B "-( "2 2# 82-2 BB-+ + 58 "2 5# 82-2 BB-+ + 58 (# (# 2+ #5 852B "-( (# 2# 82-2 BB-+ + 58 (# 5# 82-2 BB-+ + 58
NATURAL-A – Journal of Scientific Modeling & Computation, Volume 1 No.1 – 2013 51 ISSN 2303-0135
menunjukkan besarnya minimum confidence mempengaruhi tingkat kekuatan rule yang dihasilkan. Semakin tinggi nilai minimum confidence semakin tinggi pula nilai kekuatan rule yang dihasilkan yang ditunjukkan besarnya nilai confidence dan conviction.
7 D
AFTARP
USTAKA[1] Cavallo, “Oil Price and Inflation”, FRBSF Economic Letter, no. 2008-31(October), 2008.
[2] Edy, S, "Analisis Kausalitas Inflasi Dan Pengangguran Di Indonesia Tahun 1986-2005 (Pendekatan Error Correction Model (ECM))", Tesis, Universitas Muhammadiyah Surakarta, 2008.
[3] Erawati, N dan R, Llewelyn, "Analisa Pergerakan Suku Bunga dan Laju Ekspektasi Inflasi Untuk Menentukan Kebijakan Moneter di Indonesia", Jurnal Manajemen & Kewirausahaan, Vol, 4, no, 2, 98 – 107, 2002. [4] Gujarati, D, N, "Basic Econometric", Fourth Edition, McGraw – Hill, New York, 2003.
[5] http://www.eia.gov/dnav/pet/pet_pri_spt_s1_m.htm [6] http://www.bps.go.id
[7] Hooker, M, A, "Are Oil Shocks Inflationary? Asymmetric and Nonlinear Specifications versus Changes in Regime." Journal of Money, Credit and Banking 34 (May), pp, 540-561, 2002.
[8] Hutagalung, E, "Analisis kenaikan harga minyak dunia, jumlah uang beredar dan nilai tukar(kurs) terhadap inflasi di Indonesia", Skripsi, Fakultas Ekonomi, Universitas Sumatera Utara, 2006.
[9] Leblanc, M dan M, D, Chinn, "Do High Oil Prices Presage Inflation?", http://www.sciie.ucsc.edu/workingpaper/2004/0404.pdf, 2011.
[10] Liviatan, N, "Consistent Estimation of Dsitributed Lag", International Economic Review 4 (January), pp 45-52, 1963. [11] Mulyati, S, "Analisis Hubungan Inflasi Dan Pengangguran Di Indonesia Periode 1985-2008: Pendekatan Kurva
Philips", Skripsi, Fakultas Ekonomi dan Manajemen, Institut Pertanian Bogor, 2009.