An OpenCL Implementation of Sketch-based Network Traffic Change Detection
on GPU
Theophilus Wellem Department of Information Systems Satya Wacana Christian University
Salatiga, Indonesia
Email: [email protected]
Yu-Kuen Lai
Department of Electrical Engineering Chung Yuan Christian University
Chungli, Taiwan Email: [email protected]
Abstract—GPU and other SIMD stream architecture have been used for accelerating packet processing applications. This paper explores the design space on GPU for sketch-based network traffic change detection application by using OpenCL parallel programming framework. Due to the parallel nature of sketch data structure, the computations can be mapped to OpenCL execution model on GPU efficiently. The sketch data structure is mapped to buffer object in device’s global memory, and work-items are executed on the sketch in parallel. Compared to the sequential CPU implementation, the experiment results on Radeon HD 5870 GPU show that the hash computation and ESTIMATE operation achieved about 15 times and 9 times speedup, respectively.
Keywords-Sketch, Change detection, OpenCL, GPU
I. INTRODUCTION
Anomalies in network traffic are common in today’s network due to flash crowds, worm, and denial of service (DoS) attack. These anomalies often result in significant changes on traffic volume. Therefore, traffic monitoring and measurement for detecting these changes are important for anomaly detection. The problem of finding flows with significant changes in traffic volume has been addressed in several works. There are several methods for detecting these flows such as, sliding window based on nonparametric cumulative sum (CUSUM) [1], sketch-based methods [2], [3], and Combinatorial Group Testing approach [4].
Sketch-based methods are interesting due to its small memory footprint and proven to have high accuracy for detecting flows with large traffic volume changes in network. Krishnamurty et al. [2] proposed a sketch-based method for change detection in network traffic. The scheme is implemented in software using C and work offline. Later, Lai et al. [5] implemented the on-line sketch-based scheme for change detection based on [2] on NetFPGA [6] platform. The computations on sketch data structure are inherently parallel, make it suitable for parallel processing on multi-core CPU or Graphics Processing Unit (GPU). Recently, GPU is increasingly being used for general purpose compu-tation because of its parallel processing capability, memory bandwidth, and computational power. For example, ATI
Radeon HD 5870 GPU has 20 cores and total of 320 stream processors (with 154 GB/s peak memory bandwidth) or NVIDIA Tesla C2050 GPU which has 448 CUDA cores (with 144 GB/s peak memory bandwidth) to process data in parallel. The other advantage is that GPUs are available at low cost together with the commodity CPUs compared to another accelerator, such as FPGAs or ASICs. Therefore, we proposed a parallel implementation of these sketch computations on GPU to offload it from CPU.
The remainder of this paper is organized as follows. Section 2 provides background on data stream and sketch al-gorithms. Section 3 describes the sketch-based change detec-tion scheme. OpenCL programming and GPU are described in Section 4. The implementation of sketch-based change detection scheme using OpenCL programming model is explained in Section 5. Section 6 discusses experimental results. Finally, Section 7 concludes the paper.
II. DATA STREAM ANDSKETCH
Figure 1. Sketch-based change detection scheme
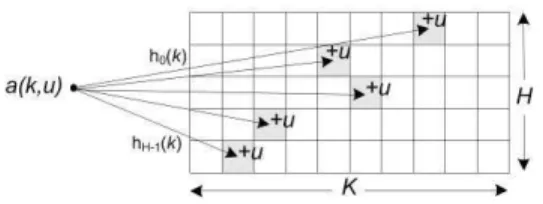
Figure 2. Illustration ofk-arysketch
III. PREVIOUSWORK
Change detection in network traffic can be viewed as pro-cess of detecting and identifying flows that have significant differences in their attributes (e.g., volume) between obser-vation intervals. We provide a brief review of the sketch-based change detection scheme proposed by Krishnamurty et al. in this section. Details of the scheme can be found in [2].
The sketch-based change detection scheme is shown in Figure 1. It consists of three modules: sketch module, forecasting module, and change detection module.
Sketch Module: This module usesk-arysketch to summa-rize the input data stream (network traffic) for each time in-terval,t. The output from this module is the observed sketch, So(t)for each time interval. Thek-arysketch data structure
is anH×K array of counters: T[i] [j], i∈[H], j∈[K]. Each row H is associated with a hash function, hi to
map items in data stream to the counters. Universal hash function [18] is used to provide probabilistic guarantees of reconstruction (of the forecast error for a given key, k) accuracy in ESTIMATE operation (query operation). This sketch also can be viewed as array of hash tables, whereH represents the number of hash tables in the sketch andK is the number of entries in each hash table. These entries are the counters to count the packets or flows. Figure 2 shows the illustration ofk-arysketch. Initially, all hash table’s entries (counters) are set to zero. When a packet arrives, the key is hashed using the H hash functions to get the counters’ index. These counters are then incremented. The key can be a field or several fields from the packet header (e.g., source IP address, destination IP address, source port, destination port, etc.) and the update can be the packet length.
Four operations are defined fork-arysketch: 1) UPDATE, 2) ESTIMATE, 3) ESTIMATEF2, and 4) COMBINE. Given
Figure 3. Sketch update operation
a sketch S, a key k, and an update u, the operations are defined below. For each keyk,vk=Pi∈Akui whereAk=
{i|ki=k}. In other words, vk is the sum of updates for
a given key k. For each observation interval, the second moment,F2 is defined asF2=P
Forecasting Module: This module uses a forecasting model to create a forecast sketch,Sf(t)from the observed
sketches in past intervals. Forecasting models, such as Moving Average (MA), S-shaped Moving Average (SMA) or Exponential Weighted Moving Average (EMWA) can be used to create the forecast sketch,Sf(t). This module also
computes the forecast error sketch, Se(t)as the difference
between the observed sketch and forecast sketch,
Se(t) =So(t)−Sf(t) (7)
Moving Average (MA): Using MA forecasting model, the forecast sketch computation is shown below.
Sf(t) = PW
i=1So(t−i)
W , W ≥1 (8)
whereW is the window size, which is an integer parameter indicates how many past time interval used for computing the forecast sketch. For example, using W = 3, the first forecast sketch is computed at the beginning of fourth interval (t = 4) as Sf(4) = S
o(3)+So(2)+So(1)
3 . At the end
of t4, So(4) is available, so at beginning of next interval
(t= 5),Se(4)can be computed asSe(4) =So(4)−Sf(4).
Exponential Weighted Moving Average (EWMA): Forecast sketch computation using EWMA is shown below.
Sf(t) = (
α·So(t−1) + (1−α)·Sf(t−1), t >2
So(1), t= 2
(9) For example, computation of forecast sketch at t= 3 with α= 0.5 isSf(3) = 0.5So(2) + 0.5Sf(2).
Change Detection Module: This module uses the forecast error sketchSe(t)to find the significant changes by looking
for flows with large forecast errors (above a predefined threshold). After the computation of Se(t), for each time
interval, the alarm threshold TA is chosen by the change
detection module as
whereT is a parameter determined by the application. The change detection process is as follows. For a given key k, the change detection module can query the Se(t) using
EST IM AT E(Se(t), k). If this estimated forecast error
value is above TA, then the key k is the key (flow) with
significant change. Alarm is raised and the key is recorded. In the sketch-based change detection scheme described above, important parameters that will affect the performance and accuracy of the change detection are the number of hash functionsH, the sketch widthK, the window sizeW, and the observation interval ∆t.
As shown, the UPDATE operation is computationally in-tensive. It is executed for each incoming packet and requires several hash computations and memory accesses for counter update. The sketch update process can be the bottleneck
if the rate of update is not fast enough due to latency of hash computations. This update process is inherently parallel because the hash computation and counter update for each row of the sketch is independent each other. Therefore, it is suitable for implementation on multi-core processor to accelerate the operation [9], [19].
The ESTIMATE operation is also computationally inten-sive because it is executed for each incoming key (if all incoming key is saved). According to [2], the incoming keys can be sampled, so the ESTIMATE operation can be done only on samples of incoming keys. By executing only on sampled incoming keys, the overhead of this operation can be reduced. However, if the incoming keys are sampled, some keys that have significant change maybe loss and cannot be detected. Finally, although the computation of forecast and forecast error sketches is not the bottleneck, the computation is similar to vector or matrix processing, which is also fit to multi-core architecture for parallel processing. We took these statistical computations and implemented them on GPU to show that the parallel processing capability offered by these multi-core devices can speed up the com-putations.
IV. OPENCLANDGPU
Open Computing Language (OpenCL) [20] is an open in-dustry standard parallel programming framework that allows developers to program heterogeneous collection of CPUs, GPUs, and other computing devices or accelerators (e.g., IBM Cell B.E). It supports data-parallel and task-parallel programming model. In OpenCL platform, GPU is treated as a device consisting of compute units. A compute unit contains several stream cores, and a stream core consists of several processing elements.
Platform model: OpenCL platform model consists of a host and one or more OpenCL devices. An OpenCL device is comprised of one or more compute units, and a compute unit is divided into one or more processing elements. There are three types of OpenCL device: CPU, GPU, and accelerator. SPEs of IBM Cell processor is the example of OpenCL accelerator device.
Execution model: OpenCL application consists of two parts:host application(written in C/C++), which is executed on the host, andkernels, which are executed on the device. OpenCL supports two types of kernel: OpenCL kernel which is written in OpenCL C programming language and compiled using OpenCL C compiler, andnative kernelsuch as, functions defined in application code. The capability of executing native kernel is depend on the device.
the command for kernel execution in the command queue) the kernel to the device for execution.
Kernel instances (calledwork-items) are executed for each point in the NDRange. The work-items are organized into work-groups, and work-items in a work-group are executed in parallel on the processing elements of a compute unit. The OpenCL runtime is responsible for scheduling and manage the execution of work-items. The maximum work-group size and work-item size are depend on the device and the resources required for kernel execution.
Memory model: During execution, kernel can access its own memory (device memory), which is divided into four distinct regions: global memory, constant memory, local memory, and private memory.Global memoryis the memory region that accessible (read/write) from all work-items in all work-groups. Constant memory is the region of global memory that remains constant during the execution of a ker-nel. This region is read-only for all items in all work-groups.Local memoryis the memory region that accessible from a work-group. All work-items in the corresponding work-group can access this memory region.Private memory is the memory region private to a work-item.
Programming model: OpenCL execution model supports data parallel programming model and task parallel program-ming model. In OpenCL task parallel programprogram-ming model, each task is mapped onto a compute unit. This is equal to executing a kernel on a compute unit where a work-group only has a single work item. The parallelism is expressed by using vector data types in kernel code or enqueuing multiple tasks for execution. In OpenCL data parallel programming model, kernel is executed on different data from a mem-ory object in parallel (using the SIMD/SPMD processing model), and the NDRange is used to define the kernel execution. Application should use maximum work group size if possible, to fully saturate the compute unit. The parallelism is achieved by parallel work-items execution and depends on the auto vectorization by the OpenCL compiler (implicit vectorization). Vector data types also can be used directly in kernel code (explicit vectorization) to maximize the utilization of the vector units on the device.
V. ARCHITECTURALDESIGN ANDIMPLEMENTATION We implemented the sketch-based change detection ap-plication using OpenCL data-parallel programming model. Using OpenCL parallel programming framework, we can develop parallel program to run on heterogeneous platform, such as multi-core CPU, GPU, and Cell processor’s SPE (accelerator). Based on OpenCL programming model, the sketch-based change detection scheme has five main com-putation kernels: 1) Forecast kernel, 2) Forecast error kernel, 3) EstimateF2 kernel, 4) Hash kernel, and 5) Estimate kernel. Mapping the sketch data structure and its operations is straightforward because each row can be processed inde-pendently, also the operations on each element in the sketch
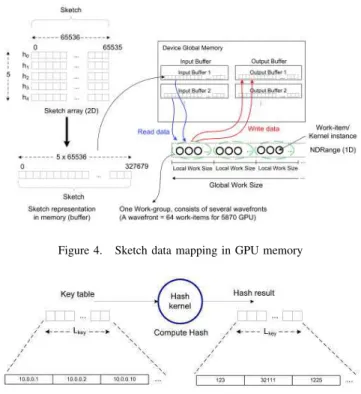
Figure 4. Sketch data mapping in GPU memory
Figure 5. Hash kernel
can be done in parallel. The sketch data mapping in GPU memory is shown in Figure 4.
The host application first initializes all host variables and OpenCL environment (create buffers, command queue, etc.). Then, it reads the observed sketch data,So(t) for each
in-terval and the key table used for ESTIMATE operation from host memory, and put it to device’s global memory. When the sketches and key tables are ready, the host application executes the kernel to compute the forecast sketch, forecast error sketch, EstimateF2 and Estimate. This process is then repeated. The key and update used in this application are the source IP address (32-bit) and the packet length (16-bit), respectively.
A. Hash kernel
This kernel implements the 4-universal hash function based on [21]. It receives the key table as its input and outputs the hash results. Figure 5 shows the hash kernel. Several keys can be hashed at once, therefore, it can speed up the hash computation. This kernel is executedH times using 1D NDRange and the number of key in key table,Lkey
is the global work size. As shown in the figure, the length of the resulting hash result table is depend on theLkey. The
Figure 6. Moving Average forecast kernel
Figure 7. Forecast error kernel
B. Forecast kernel
The forecast sketch computation can be parallelized since each element of the sketch can be processed independently. The data-level parallelism (DLP) is exploited by executing the kernel on each sketch’s element in parallel. The forecast kernel takes observed sketches as its input and outputs the forecast sketch. It reads the observed sketches from global memory, computes the forecast sketch, and stores the result back to global memory. The resulting forecast sketch is then used for forecast error computation at the next interval.
We implemented the MA forecast method. Therefore, the kernel takes the observed sketch of the first W observing time intervals from the buffer, and computes the moving average value according to Equation 8. The window sizeW is fixed to 3. Figure 6 shows the MA forecast kernel.
C. Forecast Error kernel
This kernel computes the forecast error sketch (see Equa-tion 7). It takes the observed sketch, So(t) and forecast
sketch,Sf(t)as its main arguments, and outputs the forecast
error sketch,Se(t). As in the forecast kernel, this kernel is
executed using 1D NDRange with global work size equal to H×K. Each work-item executes the kernel on each sketch’s element in parallel. The forecast error kernel is shown in Figure 7.
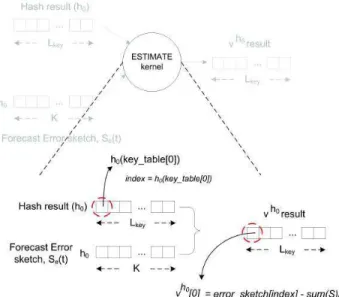
Figure 8. Estimate kernel
D. Estimate kernel
The ESTIMATE operation needs the hash results of the key as shown in Equation 3. For this operation, the key is obtained from the key table sent in each interval. Because it is not practical to save each incoming key in one interval to the key table, the key table is limited to save up to 65536 keys in each interval. The key used is the source IP address, so the maximum key table size is 65536×4 bytes = 256
KB.
Using keys from the key table, the index hi(k) is
com-puted first using the hash kernel, then the output hash results are used as the input to the ESTIMATE kernel. Thesum(S)
part of Equation 3 is only computed once in host (CPU) and passed as one of the arguments to the kernel. This kernel implementation takes the forecast error sketch and hash result table as its main arguments besides the other additional arguments. The output of this kernel is the variance value for hash table hi. Figure 8 shows how the ESTIMATE kernel
computes vhi
k for each key kin key table. Each work-item
executes this kernel on each key in parallel.
This kernel is executed for each hash table hi (i.e., it is
executed H times) using 1D NDRange with global work size of Lkey. The results from this kernel are sent back to
host. Using the results, the host then does the sorting and gets the median values to derive the estimated value for each key in the key table.
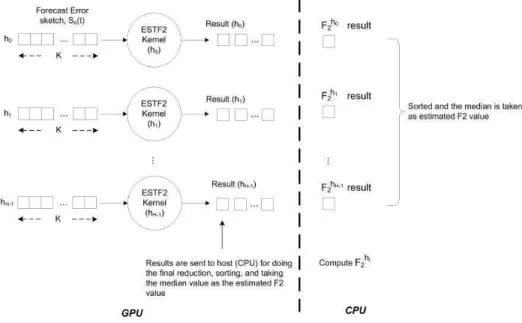
E. EstimateF2 kernel
The ESTIMATEF2 computation is not fully fit for parallel computation. Therefore, we choose to compute only the P
j∈[K](T[i] [j]) 2
part of Equation 5. The
P
j∈[K](T[i] [j]) 2
Table I
OPENCL DEVICE PARAMETER
Parameters GPU CPU
CL MAX COMPUTE UNITS 20 2
CL DEVICE GLOBAL MEM SIZE 512 MB 2 GB
CL DEVICE LOCAL MEM SIZE 32 KB 32 KB
CL DEVICE MAX WORK GROUP SIZE 256 1024
CL DEVICE MAX WORK ITEM SIZES 256 1024
method, which is suitable for computation on GPU espe-cially ifK is large. Two stages reduction is used. The first reduction stage is done in GPU and final reduction stage is done in host. The sum(S) part, as in the ESTIMATE kernel, is only computed once in host (CPU) and passed as one of the arguments to the kernel.
This kernel’s input is the hash table of the forecast error sketch and outputs the partial reduction sum of the hash table’s entries. Using these results, the host (CPU) then does the final reduction, sorting, and gets the median value as the estimated second moment (F2) value of the forecast error sketch.
As in ESTIMATE kernel case, this kernel is executed for each hash table hi. The NDRange used is the sketch entry,
K. The ESTIMATEF2 computation process and its kernel are shown in Figure 9 and Figure 10, respectively.
VI. EXPERIMENTALSETUP ANDRESULTS The application has been executed on a computer with 2GHz AMD Athlon64x2 Dual Core CPU with Radeon HD 5870 GPU attached to the PCIe slot. Some of the OpenCL devices’ parameters are shown in Table I. Our sequential CPU implementation is also executed on the same machine. We evaluated each operation on GPU, then compared their execution speed to the sequential CPU implementation. For the experiments, we set the value of H to5. TheK value and number of key are set to 216 (64K). The sketch data and keys are internally generated by the application. The internal data generator is set, such that the data generated can resemble real sketch data and key (source IP address). For measuring the total execution time, before an operation is called, a timer is started. This timer is stopped when the operation is complete. We use the timer function provided in AMD APP SDK for OpenCL host and CPU codes.
The experiment results for all operations are summarized in Table II. Here, we only showed the result forH = 5,K= 216and number of key = 64K. Note that for all experiments, H value is fixed to5.
The execution time of hash operation largely depends on the number of key in the key table. As shown from the table, we can achieve about 15times speedup on GPU compared to serial CPU implementation. For small number of key (e.g., 1K), we found that the hash execution time on CPU is
Table II
TOTAL EXECUTION TIME IN MS(H= 5,K= 216,Lkey= 64K)
Operations Exec. time (GPU) Exec. time (CPU)
Hash 15.71 241.93
Forecast 1.28 9.0
Forecast Error 3.62 9.0
Estimate 62.01 465.74
EstimateF2 19.91 29.35
faster because there is no big enough data (key) for GPU to process, to get the advantage of parallel processing on GPU. The implementation of forecast and forecast error operations achieve about7 times and2.5 times speedup, respectively. We found that the execution time these two operations are influenced by the K paramater value. Generally, on our experiments showed that, as K grows from 1K to 64K, the execution time will growth exponentially.
The ESTIMATE operation execution time is depend on number of key and K parameters. Value of K influenced the sorting time process. On the experiments, we also experimented with different number of key and Kvalue for ESTIMATE operation. The results show that the ESTIMATE operation execution time grows as the number of key and K value increase. For H = 5,K= 216 and number of key = 64K, the ESTIMATE operation achieves about 9 times speedup. Finally, for ESTIMATEF2 operation’s execution time which is influenced by theK value, it achieves about 1.5 times speedup.
VII. CONCLUSION ANDFUTUREWORKS
This paper presents a parallel implementation of sketch operations for network traffic change detection system on GPU using OpenCL. Due to parallel nature of sketch data structure, the sketch computations can be mapped to the OpenCL execution model on GPU. Our experiment results on Radeon HD 5870 GPU show that the parallel implementation of these sketch operations can speed up the computation time compared to the original sequential implementation in CPU. The kernel for hash operation can achieve15times speedup, the forecast operation gets about7
times speedup, and the forecast error operation has about2.5
times speedup. The other operations such as ESTIMATEF2 and ESTIMATE, have about1.5times and9times speedup, respectively.
Figure 9. ESTIMATEF2 computation process
Figure 10. ESTIMATEF2 kernel
versa. Host application implemented in this paper uses the memory copy functions (clEnqueueWriteBuffer() and clEnqueueReadBuffer()). These functions can be replaced by using the memory mapping function (clEnqueueMap-Buffer()) to map the memory buffer.
For future works, there are some improvements can be done such as, kernel and application optimizations, imple-menting parallel sorting for the ESTIMATE operation on GPU, and using the device fission OpenCL extension to split an OpenCL device into multiple sub-devices. For example, a four cores x86 CPU is divided into four devices. The sketch computations can be divided to these sub-devices, implementing a pipeline processing model. OpenCL also
supports kernel execution on multi-device. Our implemen-tation in this paper only uses one device to execute the kernels (i.e., the kernels are executed only on GPU or CPU). Improvement can be made by using all devices available to execute the kernels. Other configuration, such as multi-GPU or implementation on FPGA is also possible.
ACKNOWLEDGMENT
REFERENCES
[1] E. Ahmed, A. Clark, and G. Mohay, “A novel sliding window based change detection algorithm for asymmetric traffic,” in IFIP International Conference on Network and Parallel Computing, 2008. NPC 2008, 2008, pp. 168–175.
[2] B. Krishnamurthy, S. Sen, Y. Zhang, and Y. Chen, “Sketch-based change detection: Methods, evaluation, and applica-tions,” inProceedings of the 3rd ACM SIGCOMM Conference on Internet Measurement, IMC ’03. ACM, October 2003, pp. 234–247.
[3] R. Schweller, A. Gupta, E. Parsons, and Y. Chen, “Reverse hashing for sketch-based change detection on high-speed networks,” inProceedings of the ACM/USENIX Internet Mea-surement Conference, IMC ’04. ACM, October 2004.
[4] G. Cormode and S. Muthukrishnan, “What’s new: Finding significant differences in network data streams,”Proceedings of 23rd Annual Joint Conference of the IEEE Computer and Communications Societies, INFOCOM 2004, vol. 3, pp. 1534–1545, 2004.
[5] Y.-K. Lai, N.-C.Wang, T.-Y. Chou, C.-C. Lee, T. Wellem, and H. Nugroho, “Implementing on-line sketch-based change detection on a NetFPGA platform,” inProceedings of the 1st Asia NetFPGA Developers Workshop, Daejeon, South Korea, 2010.
[6] NetFPGA project website, http://netfpga.org.
[7] S. Muthukrishnan, Data Streams: Algorithms and Appli-cations (Foundations and Trends in Theoretical Computer Science). Now Publishers, Inc., 2005.
[8] A. Gilbert, Y. Kotidis, S. Muthukrishnan, and M. Strauss, “QuickSAND: Quick summary and analysis of network data,” DIMACS, Center for Discrete Mathematics and Theoretical Computer Science, Tech. Rep. 2001-43, November 2001.
[9] G. Cormode, “Count-min sketch,” in Encyclopedia of Database Systems, L. Liu and M. T. Ozsu, Eds. Springer, 2009, pp. 511–516.
[10] X. Li, F. Bian, M. Crovella, C. Diot, R. Govindan, G. Ian-naccone, and A. Lakhina, “Detection and identification of network anomalies using sketch subspaces,” inProceedings of the 6th ACM SIGCOMM conference on Internet measurement. ACM, 2006, pp. 147–152.
[11] D. Barman, P. Satapathy, and G. Ciardo, “Detecting attacks in router using sketches,” inWorkshop on High Performance Switching and Routing, HSPR ’07, June 2007.
[12] Y. Gao, Z. Li, and Y. Chen, “A DoS resilient flow-level intrusion detection approach for high-speed networks,” in Proceedings of the 26th IEEE International Conference on Distributed Computing Systems, 2006, ICDCS 2006, 2006, p. 39.
[13] J. Tang, Y. Cheng, and C. Zhou, “Sketch-Based SIP flooding detection using hellinger distance,” inIEEE Global Telecom-munications Conference, 2009. GLOBECOM 2009., 2009, pp. 1–6.
[14] R. Schweller, A. Gupta, E. Parsons, and Y. Chen, “Reversible sketches for efficient and accurate change detection over network data streams,” inProceedings of the 4th ACM SIG-COMM conference on Internet measurement. Taormina, Sicily, Italy: ACM, 2004, pp. 207–212.
[15] G. Cormode, F. Korn, S. Muthukrishnan, and D. Srivastava, “Diamond in the rough: Finding hierarchical heavy hitters in multi-dimensional data,” inProceedings of the 2004 ACM SIGMOD International Conference on Management of Data. ACM, 2004, pp. 155–166.
[16] Y. Liu, L. Zhang, and Y. Guan, “A distributed data stream-ing algorithm for network-wide traffic anomaly detection,” SIGMETRICS Perform. Eval. Rev., vol. 37, no. 2, pp. 81–82, 2009.
[17] A. Lakhina, M. Crovella, and C. Diot, “Diagnosing network-wide traffic anomalies,” inProceedings of the 2004 Confer-ence on Applications, technologies, architectures, and proto-cols for computer communications. Portland, Oregon, USA: ACM, 2004, pp. 219–230.
[18] J. Carter and M. Wegman, “Universal classes of hash func-tions,” Journal of Computer and System Sciences, vol. 18, no. 2, pp. 143–154, 1979.
[19] G. Cormode and S. Muthukrishnan, “Summarizing and min-ing skewed data streams,” inProceedings of the SIAM Con-ference on Data Mining, 2005.
[20] A. Munshi (Editor), “The OpenCL Specification, Version 1.1 Rev. 44,” in http://www.khronos.org/registry/cl/specs/opencl-1.1.pdf, Khronos OpenCL Working Group, 2011.