KOMBINASI INTEGRASI METODE SAMPLING DENGAN
NAIVE
BAYES
UNTUK KETIDAKSEIMBANGAN KELAS PADA
PREDIKSI CACAT PERANGKAT LUNAK
Sukmawati Anggraeni PutriSistem Informasi, STMIK Nusa Mandiri
Jl. Damai No. 8, Warung Jati Barat (Margasatwa), Jakarta Selatan email:[email protected]
ABSTRAKSI
Distribution of the dataset class software engineering experienced imbalance class. This research will analyze the data class is counterbalanced by the sampling technique Naive Bayes algorithm uses four general dataset from NASA repository MDP to find the defect module. Results of this research, sampling techniques consisting of Random Under Sampling, SMOTE (Synthetic Minority Over-sampling Technique) and Resampling shows increase in the percentage of the size of the AUC. Of the three proposed sampling technique, that SMOTE technique gives better results than the other two techniques.
Keywords: Sampling Technique, Software Engineering, Naive Bayes, Defect Prediction
PENDAHULUAN
Pendistribusian kelas memiliki kejadian pada masing-masing kelas dalam data set yang memainkan peran penting dalam klasifikasi. Ketidak seimbangan dataset terjadi ketika satu kelas, umumnya salah satu yang mengacu pada konsep mengenai tujuan (kelas positif atau monoritas), yang kurang terwakili dalam dataset. Dengan kata lain, jumlah kelas negatif (mayoritas) lebih banyak dibandingkan dengan jumlah kelas positif.
Selain itu kriteria evaluasi yang mengarahkan prosedur pembelajaran, dapat menyebabkan mengabaikan contoh kelas minoritas (yang diketahui sebagai noise) dan karenanya,
classifier mungkin memiliki kesulitan untuk mengklasifikasi dalam kasus ini. Sebagai contoh, dapat dipertimbangkan dataset yang memiliki ketidakseimbangan rasio 1:100 (yaitu untuk nilai 1 sebagai contoh dari kelas positif, dan nilai 100 sebagai contoh kelas negatif). Sebuah classifier yang mencoba memaksimalkan akurasi, dapat memperoleh akurasi 99% hanya dengan tidak menggunakan contoh positif, dengan klasifikasi semua kasus yang negatif. Akibatnya, mesin pembelajaran cenderung salah mengklasifikasikan contoh kelas minoritas sebagai mayoritas, dan menyebabkan tingginya tingkat kelas negatif yang palsu [1]. Untuk mengatasi masalah ini, terdapat pendekatan sampling yang diusulkan. Umumnya, teknik sampling termasuk metode over sampling
yaitu, metodeRandom Over Sampling[2], sedangkan metode under sampling yaitu Random Under Sampling[3] dan Resample[4]. Pendekatan berbasis algoritma bertujuan untuk meningkatkan kinerja dari classifier berdasarkan pada karakteristik pada classifier tersebut. Contohnya, metode yang khusus
disesuaikan untuk Decision Trees, Neural Networks, Naive Bayes dan lain sebagainya.
Pada tulisan ini berkaitan dengan meningkatkan kinerja dari classifier Naive Bayes
pada dataset yang tidak seimbang. Classifier Naive Bayes merupakan komputasi yang efesien [5] dan memiliki reputasi yang baik pada akurasi prediksinya [6].
Pertama, penelitian yang kami lakukan menujukkan bahwa menggunakan under sample
seperti yang diusulkan pada penelitian sebelumnya [3] dapat mengurangi noise yang berlebihan dan menyebabkan kerancuan untuk menentukan keputusan. Pada penelitian ini mengusulkan untuk mengintegrasikan dua jenis strategi pengambilan sampel dengan SMOTE [7] pada kelas minoritas, dan teknik resample[4].
KAJIAN LITERATUR 1. Dataset Tidak Seimbangan
Masalah ketidakseimbangan kelas merupakan topik yang menarik dalam pembahasan menggunakan pembelajaran mesin. Pendekatan untuk mengatasi masalah ini dapat dibagi menjadi dua arah utama. Pertama, menggunakan pendekatan sampel dan pendekatan berbasis algoritma.
2. Teknik Sampling
Sampling merupakan strategi yang populer untuk menangani noise yang dilakukan untuk menyeimbangkan data pada tahap pra proses data. Oleh karena itu teknik sampling dapat digunakan pada pendekatan klasifikasi yang ada [7][3][4]. Meskipun teknik sampling memiliki kelebihan, namun pendekatan sampling memiliki kekurangan yaitu pada under-sampling, contoh kelas mayoritas mungkin kehilangan informasi yang berguna.
Sedangkan over-sampling pada kelas positif akan menyebabkan duplikasi berlebihan yang menyebabkan over-fitting. Selain itu, over-sampling
dapat meningkatkan jumlah dataset pelatihan, sehingga menyebabkan biaya komputasi yang berlebihan.
Meskipun demikian [7] menemukan proses yang dapat mengatasi masalah teknik over-sampling, yaitu algoritma Synthetic Minority Over-sampling Technique (SMOTE) yang menghasilkan artifisial interpolasi data pada proses over-sampling pada kelas minoritas. Algoritma dimulasi dengan mencari
k tentang terdekat untuk setiap contoh minoritas, dan kemudian untuk setiap tetangga, secara acak memilih titik dari garis yang menghubungkan tetangga dan contoh itu sendiri. Akhirnya, data pada titik tersebut dimasukan sebagai contoh minoritas baru. Dengan menambahkan contoh minoritas baru menjadi data pelatihan, diharapkan over-fitting dapat teratasi [7].
3. Metode Klasifikasi
Ada banyak metode klasifikasi untuk menganalisa efektivitas teknik penyeimbang, sedangkan pada penelitian ini hanya menggunakan satu jenis klasfikasi yaitu klasifikasi probabilistik (Naive Bayes). Algoritma Naive Bayes menggunakan teorema Bayes untuk memprediksi kelas untuk setiap kasus, dengan asumsi atribut independen.Jumlah frekuensi sederhana digunakan untuk memperkirakan probabilitas atribut diskrit. Untuk atribut numerik pada umumnya menggunakan fungsi probabilitas untuk distribusi normal[6], yaitu dengan rumus: 𝑔 𝑥, µ, σ = 1 2𝜋𝜎 𝜖 − (𝑥−𝜇 )2 2𝜎2 ... (1) Dimana: µ = mean σ = standar deviasi 𝑥 = nilai 𝜖 = nilai eksponen 4. TeknikEvaluasidanValidasi
Model validasi yang digunakan pada penelitian ini adalah 10 fold cross validation. Kinerja algoritma pembelajaran mesin biasanya dievaluasi oleh confusion matrix seperti yang diilustrasikan pada tabel 1. Kolom merupakan kelas yang diprediksi, sedangkan baris merupakan kelas yang sebenarnya [7]. Pada cofusion marix, TN merupakan contoh negatif yang benar diklasifikasikan (true negative). FP merupakan sejumlah contoh negatif yang tidak benar diklasifikasikan sebagai positif (false positive). FN merupakan jumlah contoh positif yang tidak benar diklasifikasikan sebagai negatif (false negative) dan TP merupakan jumlah contoh positif diklasifikasikan dengan benar (true positive).
Tabel1. Confusion Matrix
Rumus yang digunakan untuk melakukan penghitungan adalah sebagai berikut:
Akurasi= 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁𝑇𝑃+𝑇𝑁 ... (2)
Kurva ROC (Receiver Operating Characteristics) telah diperkenalkan untuk mengevaluasi kinerja dari algoritma pengklasifikasi. Area Under the ROC (AUC) memberikan sejumlah “ringkasan” untuk kinerja algoritma pengklasifikasi.
Area Under the ROC (Receive Operating Characteristic) (AUC) adalah pengukuran nilai tunggal yang berasal dari deteksi sinyal. Nilai AUC berkisar dari 0 sampai 1. Kurva ROC digunakan untuk mengkarakterisasi trade-off antara true positive rate (TPR) dan false positive rate (FPR). Sebuah classifier yang menyediakan area yang luas di bawah kurva adalah lebih dari classifier dengan area yang lebih kecil di bawah kurva [8].
a. TeknikAnalisis
Pada statistik menyediakan prosedur khusus yang lebih baik untuk menguji signifikan perbedaan antara lebih dari dua klasifikasi yaitu uji friedman untuk uji non parametrik [9].
Uji Friedman merupakan uji non parametrik yang setara dengan ANOVA pada uji parametik. Pada uji Friedman peringkat algoritma untuk setiap data diatur secara terpisah, kinerja algoritma yang baik mendapat peringkat 1 sedangkan untuk yang terbaik diberi peringkat dua.
Berikut akan ditampilkan formula dari uji
friedman: 𝑋𝑟2= 12 𝑛𝑥𝑘 (𝑘+1)𝑥 (𝑅𝑗) 2 𝑘 𝑗 =1 − [ 3𝑛 𝑘 + 1 ](3) Dimana:
𝑋𝑟2 = nilai khai – kuadrat jenjeng dua arah
friedman
N = jumlah sampel
K = banyaknya kelompok sampel 1, 3, 12 = konstanta
Perbandingan statistik dari pengklasifikasi yang baik adalah menggunakan tes non parametrik yang terdiri dari uji Wilcoxon signed ranked untuk perbadingan dari dua pengklasifikasi dan uji Friedman dengan uji Post Hoc yang sesuai untuk perbandingan lebih dari satu pengklasifikasi dengan beberapa dataset [9].
Kelas Nilai Awal
Benar Salah
Nilai Prediksi
Benar TP FP
PEMBAHASAN 1. Kerangka Pemikiran
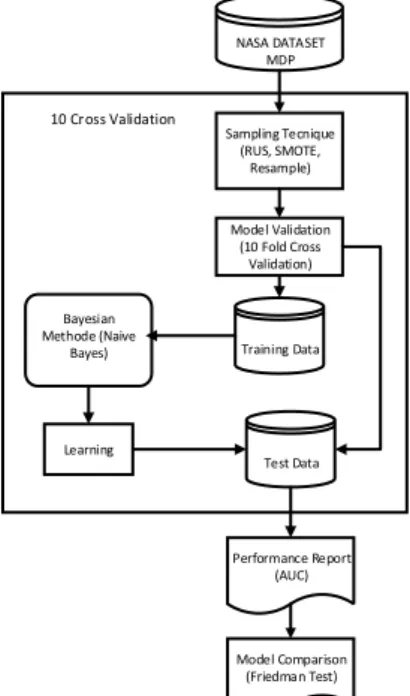
Kerangka pemikiran yang digunakan pada penelitian ini terdiri dari beberapa tahap seperti dijelaskan pada gambar . Permasalahan yang akan dibahas pada penelitian ini mengenai dataset cacat perangkat lunak yang memiliki distribusi kelas yang tidak seimbang. Dimana dataset yang tidak seimbang tersebut dapat mempengaruhi kinerja dari classifier Naive Bayes. Penggunaan teknik sampling yang terdiri dari Random Under Sampling, SMOTE dan Resample dapat mengurangi pengaruh ketidak seimbangan tersebut. Kemudian pada tahap akhir untuk mengevaluasi hasil klasifikasi, maka digunakan pengukuran (measurement) dengan Area Under the ROC (Receiver Operating Characteristic) Curve (AUC). Sehingga diperoleh lah kerangka pemikiran yang akan dijelaskan pada gambar 1. DATASET NASA MDP RUS SMOTE Teknik Sampling Al goritma Klasifikasi Naive Bayes 10 Cross Validation Jumlah Nearest Neighbors Jumlah Sintesis Perulangan Performa Model Prediksi Perangkat Lunak AUC Tes Friedman Model Pengukuran Penanganan Ketidakseimbangan Kelas Parameter Yang Disesuaikan
FAKTOR METODE YANG
DIUSULKAN VALIDASI TUJUAN PENGUKURAN
Resample
Gambar 1. Kerangka Pemikiran 2. Metode Yang Diusulkan
Metode yang diusulkan dengan melakukan penerapan teknik sampling (RUS, SMOTE dan Resample) Naive Bayes untuk prediksi cacat perangkat lunak. Tahap pertama dengan melakukan pra proses pada data yang tidak seimbangan menggunakan teknik sampling, kemudian dataset dibagi menggunakan metode 10 cross validation yaitu menjadi data training dan data testing, kemudian data training yang telah dilakukan penyeimbangan diproses dengan menggunakan Naive Bayes, sehinga menghasilkan model evaluasi yang diukur dengan nilai Root Mean Square Error (RMSE) dan Area Under the ROC Curve (AUC) yang dijelaskan pada gambar 2.
NASA DATASET MDP Sampling Tecnique (RUS, SMOTE, Resample) Training Data Test Data Learning Performance Report (AUC) Model Comparison (Friedman Test) Bayesian Methode (Naive Bayes) Model Validation (10 Fold Cross Validation) 10 Cross Validation
Gambar 2. Metode Yang Diusulkan 3. Datasets
Pada penelitian ini menggunakan data publik yang biasa digunakan oleh para peneliti sebelumnya, yaitu software metrics dari NASA (National Aeronautics and Space Administration) MDP repository. Dataset tersebut terdiri dari CM1, MW1, PC1, dan PC4. Dataset NASA MDP yang dapat diakses bebas oleh umum dan dapat diperoleh melalui halaman website wikispaces (
http://nasa-softwaredefectdatasets.wikispaces.com/).
Tabel 2. Dataset Yang digunakan Pada Penelitian
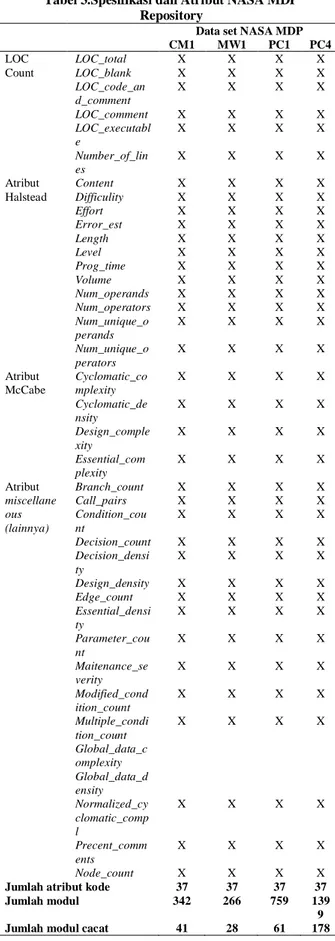
Setiap dataset yang terdiri dari beberapa modul perangkat lunak, bersama dengan jumlah kesalahan dan atribut kode karakteristik. Pemrosesan awal dataset NASA MDP memiliki 38 atribut ditambah satu atribut cacat atau tidak cacat (defective?). Atribut tersebut terdiri dari jenis atribut Halstead, McCabe, Line of Code (LOC) dan atribut
miscellaneous [5].
Sistem Bahasa Datas
et Total LOC Instrumen pesawat ruang angkasa C CM1 17K Database C MW1 8K Software penerbangan
untuk satelit yang
mengorbit bumi
C PC1 26K
Tabel 3.Spesifikasi dan Atribut NASA MDP Repository
Data set NASA MDP
CM1 MW1 PC1 PC4 LOC Count LOC_total X X X X LOC_blank X X X X LOC_code_an d_comment X X X X LOC_comment X X X X LOC_executabl e X X X X Number_of_lin es X X X X Atribut Halstead Content X X X X Difficulity X X X X Effort X X X X Error_est X X X X Length X X X X Level X X X X Prog_time X X X X Volume X X X X Num_operands X X X X Num_operators X X X X Num_unique_o perands X X X X Num_unique_o perators X X X X Atribut McCabe Cyclomatic_co mplexity X X X X Cyclomatic_de nsity X X X X Design_comple xity X X X X Essential_com plexity X X X X Atribut miscellane ous (lainnya) Branch_count X X X X Call_pairs X X X X Condition_cou nt X X X X Decision_count X X X X Decision_densi ty X X X X Design_density X X X X Edge_count X X X X Essential_densi ty X X X X Parameter_cou nt X X X X Maitenance_se verity X X X X Modified_cond ition_count X X X X Multiple_condi tion_count X X X X Global_data_c omplexity Global_data_d ensity Normalized_cy clomatic_comp l X X X X Precent_comm ents X X X X Node_count X X X X
Jumlah atribut kode 37 37 37 37
Jumlah modul 342 266 759 139
9
Jumlah modul cacat 41 28 61 178
4. Pelaksanaan Dan HasilEksperimen
Pengukuran model digunakan dengan menggunakan 4 dataset NASA MDP (CM1, MW1, PC1, PC4). Model yang diuji menggunakan model
pengklasifikasi Naive Bayes, Naive Bayes dengan SMOTE, Naive Bayes dengan Random Under Sampling, dan yang terakhir Naive Bayes dengan SMOTE dan Resample.
Langkah-langkah
initelahdigunakanuntukmembandingkankeakuratanp engklasifikasidengandantanpateknikpenyeimbang. Hasilpercobaandapatdilihatpadatabel.Presentasepada klasifkasikasitidakmeningkat, tetapi AUC meningkatketikamenggunakanteknik sampling terutamapadateknik SMOTE.
Tabel 4.NilaiAkurasi
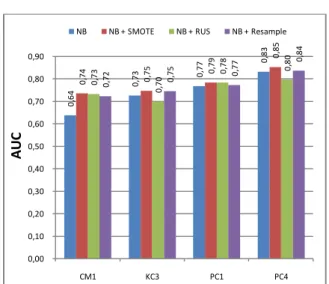
Pada tabel 4 menujukkan hasil nilai akurasi yang terbaik pada penggunaan model Naive Bayes, dimana pada keempat dataset yang digunakan (CM1, MW1, PC1, PC4) menujukkan nilai akurasi yang terbaik. Tabel5.Nilai AUC Klasifikasi CM1 MW1 PC1 PC4 Naive Bayes 0,64 0,73 0,77 0,83 Naive Bayes + SMOTE 0,74 0,75 0,79 0,85 Naive Bayes + RUS 0,73 0,7 0,78 0,8 Naive Bayes + Resample 0,72 0,75 0,77 0,84
Pada tabel 5 menujukkan hasil nilai AUC yang baik pada penggunaan model Naive + SMOTE, dimana terdapat pada semua dataset (CM1, MW1, PC1, PC4) yang digunakan.
5. Perbandingan Kinerja Model Naive Bayes
Langkah awal dalam menganalisa data adalah mempelajari karakteristik dari data tersebut. Untuk itu diperlukannya mengetahui pemusatan dan penyebaran data dari nilai tengahnya, nilai ekstrem atau outliernya. Oleh karenanya nantinya dapat diketahui peningkatan kinerja pengklasifikasi (Naive Bayes) untuk memperbaiki model prediksi cacat perangkat lunak.
Untuk mengetahui perbandingan kinerja model pengklasifikasi (Naive Bayes) dengan model yang telah dioptimasi, maka akan digambarkan dengan diagram box and whisker
plotspadaperbandingan AUC yang
dijelaskanpadaGambar Klasifikasi CM1 MW1 PC1 PC4 Naive Bayes 0,79 0,81 0,88 0,87 Naive Bayes + SMOTE 0,76 0,77 0,84 0,82 Naive Bayes + RUS 0,62 0,67 0,62 0,64 Naive Bayes + Resample 0,64 0,72 0,65 0,67
Gambar 3. Diagram Perbandingan AUC Model Prediksi Cacat Perangkat Lunak
Pada gambar 3 menampilkan penyebaran data padasetiapmodelnyauntukperbandingan AUC. Pada model NB penyebarandatanyatidaksimetris,
whiskerbagianbawahboxplot yang lebih, sehinggamenunjukkandistribusi data cenderungmenjulurkearah kiri (negative skewness). Model NB + SMOTEpenyebaran data tidaksimetris,
whiskerbagianatasboxplot yang lebihpanjang, sehinggamenunjukkandistribusi data cenderungmenjulurkearah kanan (positive
skewness). Pada model NB +
RUSpenyebarandatanyatidak
simetrisdanwhiskerbagianbawahboxplot yang lebihpanjang, sehinggamenunjukkandistribusi data cenderungmenjulurkearah kiri (negative skewness). Dan pada model NB + Resamplepenyebaran data tidaksimetrisdanwhiskerbagianatas boxplot yang lebihpanjang, sehinggamenunjukkandistribusi data cenderungmenjulurkearahkanan (positive skewness).
6. Perbandingan Antar Metode
Sebagai bukti bahwa metode yang diusulkan (NB + SMOTE) lebih baik, maka dilakukanlah antara metode yang diusulkan dengan metode yang telah diusulkan pada penelitian sebelumnya.
Tabel 6. AUC Perbandingan Antara Metode
Klasifikasi CM1 MW1 PC1 PC4 Naive Bayes (Lessmann, et al) 0,64 0,73 0,77 0,83 Naive Bayes + RUS 0,73 0,70 0,78 0,8 Naive Bayes + Resample (Requelme, et al) 0,72 0,75 0,77 0,84 Naive Bayes + SMOTE (MetodeUsulan) 0,74 0,75 0,79 0,85 Hasilpercobaanditampilkanpadatabel 6. Model klasifikasiterbaikpadasetiap dataset akanditampilkandengancetaktebal. Padagambar 4 menampilkanperbandingan AUC padaempatmetode yang berbedadariempat dataset NASA MDP.
Gambar 4. GrafikAUC Perbandingan Antara Metode Usulan dengan Metode Lain
Sebagai perbandingan untuk mengetahui perbedaan setiap model yang diusulkan, maka dilakukanlah penghitungan statistik menggunakan uji statistik yang dapat digunakan terdiri dari uji parametrik dan uji non parametrik. Pada penelitian ini menggunakan uji non parametrik yang terdiri dari uji peringkat bertanda wilcoxon dan uji friedman.
Nilai AUC model NB, NB + SMOTE, NB + RUS dan NB + Resample dibandingkan menggunakan uji peringkat bertanda wilcoxon yang akan ditampilkan pada tabel 7.
Tabel 7. Nilai P dari AUC Perbandingan Menggunakan Uji Peringkat Bertanda Wilcoxon
Seperti yang ditampilkan pada tabel 7
meskipun NB + RUS dengan NB, tidak memiliki perbedaan yang signifikan dengan nilai p adalah 1 lebih besar dari alpha (0,05), hasil memperlihatkan bahwa NB + SMOTE dan NB + Resample memiliki perbedaan yang signifikan dengan NB. Nilai p dari NB + SMOTE dengan NB uji friedman adalah 0,04 kurang dari alpha (0,05). Sedangkan nilai p dari NB + Resample dengan NB uji peringkat bertanda
wilcoxon adalah 0,04 kurang dari alpha (0,05). Sehingga dapat disimpulkan bahwa NB + SMOTE dan NB + Resample dapat meningkatkan kinerja NB, sedangkan NB + RUS tidak dapat melakukan perbaikan dari kinerja NB pada prediksi cacat perangkat lunak. 0 ,6 4 0 ,7 3 0,7 7 0,8 3 0 ,7 4 0 ,7 5 0,79 0 ,8 5 0 ,7 3 0 ,7 0 0 ,7 8 0 ,8 0 0 ,7 2 0 ,7 5 0,77 0 ,8 4 0,00 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 CM1 KC3 PC1 PC4 AUC
NB NB + SMOTE NB + RUS NB + Resample
Model NB + SMO TE NB + RUS NB + Resa mple NB NB + SMOTE 0,06 0,06 0,04 NB + RUS 0,06 0,461 1 NB + Resample 0,06 0,461 0,04 NB 0,04 1 0,04
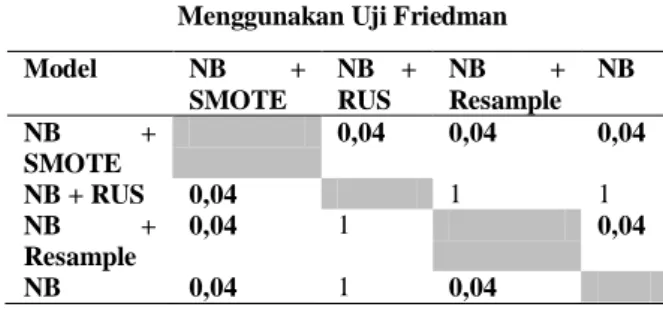
Nilai AUC model NB, NB + SMOTE, NB + RUS dan NB + Resample dibandingkan menggunakan uji Friedman yang akan ditampilkan pada tabel 8.
Tabel 8. Nilai P dari AUC Perbandingan Menggunakan Uji Friedman
Seperti yang ditampilkan pada tabel 8 meskipun NB + RUS dengan NB tidak memiliki perbedaan yang signifikan dengan nilai p adalah 1 lebih besar dari alpha (0,05), hasil memperlihatkan bahwa NB + SMOTE dan NB + Resample memiliki perbedaan yang signifikan dengan NB. Nilai p dari NB + SMOTE dengan NB uji friedman adalah 0,04 kurang dari alpha (0,05). Sedangkan nilai p dari NB + Resample dengan NB uji friedman adalah 0,04 kurang dari alpha (0,05). Sehingga dapat disimpulkan bahwa NB + SMOTE dan NB + Resample dapat meningkatkan kinerja NB, sedangkan NB + RUS tidak dapat melakukan perbaikan dari kinerja NB pada prediksi cacat perangkat lunak.
Nilai AUC model NB, NB + SMOTE, NB + RUS dan NB + Resample dibandingkan menggunakan uji friedman. Untuk hasil rata-rata peringkat dari masing-masing model berdasarkan AUC ditampilkan pada tabel 9 dan untuk hasil pengujian friedman ditampilkan pada tabel 10.
Tabel 9. Rata-rata Peringkat Model Uji Friedman Berdasarkan Nilai AUC
Mean Rank
NB 1.50
NB_SMOTE 4.00
NB_RUS 2.00
NB_RESAMPLE 2.50
Pada tabel yang memperlihatkan hasil rata-rata peringkat diketahui bahwa model NB + SMOTE mendapat respon paling tinggi yaitu 4. Sehingga model NB + SMOTE lebih baik dari model NB murni dengan rata-rata peringkat yaitu 1.50, model NB + RUS dengan nilai rata-rata peringkat yaitu 2,00 maupun model NB + Resample dengan nilai rata-rata peringkat yaitu 2,50.
Tabel 10. Uji Friedman nilai AUC
N 4
Chi-Square 8.400
df 3
Asymp. Sig. .038
Kesimpulan hasil hipotesa dari pengujian
friedman pada tabel 4.63 terlihat bahwa asymp sig 0,038, dimana nilai asymp sig mewakili nilai p. Hasil uji memperlihatkan bahwa sig < 0,05, sehingga dapat disimpulkan bahwa empat model yang dilakukan pengujian terdapat perbedaan yang signifikan.
UCAPAN TERIMAKASIH
Penulis mengucapkan terima kasih kepada kedua orang tuayang selalu mendukung,baik dukungan berupa moril maupun materil. Ucapan terimakasih pula penulis ucapkan kepada para dosen Pascasarjana STMIK Nusa Mandiri yang telah memberikan ilmu yang bermanfaat, sehingga membuka wawasan bagi penulis pada bidang penelitian. Dan tak lupa penulis ucapkan terimakasih kepada para teman yang aktif dalam melakukan penelitian atas ilmu dan diskusi ilmiahnya dalam pengembangan penelitian.
KESIMPULAN
Penerapan tekning sampling terutama pada teknik SMOTE dan Resample terbukti dapat meningkatkan kinerja pengklasifikasi Naive Bayes. Namun ada beberapa saran terkait hasil dari penelitian ini dan penelitian lanjutan untuk menangani ketidak seimbangan kelas pada model prediksi cacat perangkat lunak antara lain:
a). Pada penelitian ini menggunakan pengklasifikasi Naive Bayes, namun pada penelitian lanjutan dapat menggunakan pengklasifikasi lainnya seperti Logistic Regression, Neural Network dan SVM.
b). Pada penelitian ini, menggunakan teknik sampling. Pada penelitian di masa depat dapat menggunakan penggabungan teknik sampling
dan ensemble untuk meningkatkan kinerja pada prediksi cacat perangkat lunak.
DAFTAR PUSTAKA
[1] Y. Liu, X. Yu, J. X. Huang, and A. An, “Combining integrated sampling with SVM ensembles for learning from imbalanced datasets,” Inf. Process. Manag., vol. 47, no. 4, pp. 617–631, Jul. 2011.
[2] I. H. Laradji, M. Alshayeb, and L. Ghouti, “Software defect prediction using ensemble learning on selected features,” Inf. Softw. Technol., 2014. Model NB + SMOTE NB + RUS NB + Resample NB NB + SMOTE 0,04 0,04 0,04 NB + RUS 0,04 1 1 NB + Resample 0,04 1 0,04 NB 0,04 1 0,04
[3] K. Gao and T. M. Khoshgoftaar, “Software Defect Prediction for High-Dimensional and Class-Imbalanced Data,” Conf. Proc. 23rd Int. Conf. Softw. Eng. Knowl. Eng., no. 2, 2011.
[4] J. C. Riquelme, R. Ruiz, and J. Moreno, “Finding Defective Modules from Highly Unbalanced Datasets,” Engineering, vol. 2, no. 1, pp. 67–74, 2008.
[5] S. Lessmann, S. Member, B. Baesens, C. Mues, and S. Pietsch, “Benchmarking Classification Models for Software Defect Prediction : A Proposed Framework and Novel Findings,” IEEE Trans. Softw. Eng., vol. 34, no. 4, pp. 485–496, 2008.
[6] T. Menzies, J. Greenwald, and A. Frank, “Data Mining Static Code Attributes to Learn Defect Predictors,” IEEE Trans.
Softw. Eng., vol. 33, no. 1, pp. 2–13, Jan. 2007.
[7] N. V Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE : Synthetic Minority Over-sampling Technique,” vol. 16, pp. 321–357, 2002.
[8] T. M. Khoshgoftaar and K. Gao, “Feature Selection with Imbalanced Data for
Software Defect Prediction,” 2009 Int. Conf. Mach. Learn. Appl., pp. 235–240, Dec. 2009.
[9] J. Demsar, “Statistical Comparisons of Classifiers over Multiple Data Sets,” J. Mach. Learn. Res., vol. 7, pp. 1–30, 2006.