BAB II
LANDASAN TEORI
2.1 Algoritma Mars
Pada tahun 1997, National Institute of Standard and Technology (NIST) mengadakan program untuk menentukan algoritma standar untuk enkripsi data yang dikenal dengan Advanced Encryption Standard (AES) sebagai pengganti
Data Encryption Standard (DES) yang sebelumnya digunakan sebagai algoritma
standar untuk enkripsi data. Hal ini dilakukan karena kunci yang digunakan pada algoritma DES terlalu pendek sehingga tidak dapat menjamin keamanan data tingkat tinggi yang dibutuhkan saat ini. Triple-DES muncul sebagai altematif solusi untuk masalah-masalah yang membutuhkan kemanan data tingkat tinggi seperti perbankan, tetapi terlalu lambat pada beberapa penggunaan. NIST bertugas untuk menilai algoritma-algoritma yang sudah masuk sebagai kandidat untuk AES dengan kriteria kunci yang digunakan harus panjang, ukuran blok yang digunakan harus lebih besar, lebih cepat, dan fleksibel. Pada tahun 1999, terpilih 5 buah algoritma sebagai kandidat final untuk AES yaitu MARS, RC6, RIJNDAEL,
SERPENT dan TWOFISH. Pada tahun 2000, tepatnya bulan oktober algoritma RIJNDAEL terpilih sebagai algoritma standar untuk enkripsi yang dikenal dengan
AES. Meskipun algoritma Mars tidak terpilih sebagai algoritma AES, tetapi algoritma Mars dapat dijadikan sebagai salah satu allematif untuk enkripsi data dalarn berbagai aplikasi. Mars adalah algoritma kriptografi block cipher kunci simetris dengan ukuran blok 128 bit dan ukuran variabel kunci berkisar pada 128 sampai 448 bit [DAV99]. Mars didesain untuk memenuhi kebutuhan enkripsi saat ini dan masa yang akan datang.
Mars merupakan salah satu algoritma yang digunakan Untuk mengenkripsi dan mendekripsi data, kriptografi menggunakan suatu algoritma (cipher) dan kunci (key). Cipher adalah fungsi matematika yang digunakan untuk mengenkripsi dan mendekripsi. Sedangkan kunci merupakan sederetan bit yang diperlukan untuk mengenkripsi dan mendekripsi data. Kriptografi modern dapat memecahkan masalah algoritma tersebut diatas yaitu dengan algoritma kunci. Kunci ini dapat berupa sembarang nilai dari sejumlah angka. Dengan demikian tingkat keamanan dari algoritma yang menggunakan kunci adalah berdasarkan kerahasiaan kuncinya, tidak berdasarkan detail dari algoritma itu sendiri (Encyclopedia of cryptography and security, 2005:368)
2.1.1 Elemen Pembangun Algoritma Mars 1. Tipe-3 Feistal Network
Mars memiliki panjang blok 128 bit dengan ukuran word 32 bit. Hal ini menunjukkan bahwa setiap blok terdiri dari 4 word. Dalam berbagai struktur
network, yang mempunyai kemampuan untuk menangani 4 word dalam satu blok
adalah tipe-3 Feistal network.
Tipe-3 Feistal network terdiri dari banyak iterasi, dimana pada setiap iterasi terdapat satu word data (dan beberapa sub kunci) yang digunakan untuk memodifikasi ketiga word data yang lain. Hal ini berbeda dengan tipe-1 Feistal
network yang pada setiap iterasinya terdapat satu word data yang digunakan untuk
memodifikasi satu word data yang lain. (Encyclopedia of cryptography and security, 2005:369)
2. Operasi yang digunakan algoritma Mars
Mars cipher menggunakan berbagai macam operasi pada 32-bit word yaitu
Penjumlahan, pengurangan, perkalian dan XOR, ini merupakan operasi yang sangat sederhana, yang digunakan untuk menggabungkan nilai data dan nilai kunci
Fixed Rotation, Rotasi berdasarkan nilai tertentu yang sudah ditetapkan. Dalam hal ini nilai rotasi untuk transformasi kunci adalah 13 posisi dengan pergerakan rotasi ke kiri. Untuk r-function adalah 5 dan 13 posisi dengan pergerakan rotasi ke kiri, 24 posisi untuk forward mixing dengan pergerakan rotasi ke kanan dan 24 posisi untuk backward mixing dengan pergerakan rotasi ke kiri.
Data Dependent Rotation, Rotasi berdasarkan nilai yang ditentukan berdasarkan 5 bit terendah (berkisar antara 0 dan 31) dari word data, misalkan nilai rotasi r = 5 bit terendah dari M maka nilai rotasi r akan sangat tergantung dengan nilai 5 bit terendah dari M.
3. S-Box
S-box merupakan suatu tabel substitusi yang digunakan pada kebanyakan Block cipher lainnya seperti Mars. S-box memiliki ukuran input dan output yang bervariasi, dan dapat disusun secara random atau menurut algoritma tertentu.
Mars menggunakan tabel tunggal yang terdiri dari 512 word yang mengandung 32-bit, yang disebut dengan S-box (Encyclopedia of cryptography and security, 2005:368)
2.1.2 Algoritma Enkripsi Dan Dekripsi Mars
Jumlah blok untuk input yang digunakan dalam enkripsi data pada algoritma Mars adalah 128 bit. Sebelum enkripsi blok dimulai, satu blok masukan dibagi menjadi empat word data dimana setiap word data terdiri dari 32-bit data. Untuk selanjutnya keseluruhan operasi internal dilakukan pada 32-bit data atau satu word data. Proses enkripsi dapat dilakukan terhadap semua jenis file dengan mengoperasikannya ke dalam bit-bit biner terlebih dahulu. Proses enkripsi dari algoritma Mars dilakukan dalam 3 tahap yang merupakan bagian struktur cipher dari algoritma Mars yaitu : forward mixing, cryptographic core (transformasi kunci utama), dan backward mixing. Proses dekripsi Mars dilakukan kebalikan dari proses enkripsinya (Encyclopedia of cryptography and security, 2005:375)
2.1.3 Struktur Cipher Algoritma Mars
Struktur cipher pada Mars dibagi dalam 3 tahap yakni : (Encyclopedia of cryptography and security, 2005:369):
1. Tahap pertama adalah forward mixing, berfungsi untuk mencegah serangan terhadap chosen plaintext. Terdiri dari penambahan sub kunci pada setiap
word data, diikuti dengan delapan iterasi dari S-box. Dalam tahap ini,
pertama-tama sebuah sub kunci ditambahkan pada setiap word data dari
plaintext, dan kemudian dilakukan delapan iterasi tipe-3 feistel mixing,
dikombinasikan dengan operasi mixing tambahan. Dalam setiap iterasi digunakan sebuah word data (disebut source word) untuk memodifikasi tiga
word data (disebut target word). Keempat byte dari source word digunakan
mengandung 256 word 32 bit kemudian nilai S-box entri akan di-XOR-kan, atau ditambahkan pada ketiga word data yang lain. Keempat byte dari source
word dinotasikan dengan b0, b1, b2, b3 (dimana b0 adalah byte terendah dan
b3 adalah byte tertinggi). b0,b2 digunakan sebagai indeks untuk S-box S0 dan b1,b3 sebagai indeks untuk S-box S1. S0[b0] di-XOR-kan dengan target word pertama, lalu S1[b1] ditambahkan dengan target word yang sama. S0[b2] ditambahkan dengan target word kedua dan S1[b3] di-XOR-kan dengan target
word ketiga. Terakhir source word dirotasikan sebanyak 24 posisi ke kanan.
Untuk iterasi berikutnya keempat word data dirotasikan, sehingga target
word pertama saat ini menjadi source word berikutnya, target word kedua saat
ini menjadi target word pertama berikutnya, target word ketiga saat ini menjadi target word kedua berikutnya dan source word saat ini menjadi target
word ketiga berikutnya.
2. Tahap kedua adalah "cryptographic core". Untuk menjamin bahwa proses enkripsi dan dekripsi mempunyai kekuatan yang sama, delapan iterasi pertama ditunjukkan dalam “forward mode" dan delapan iterasi terakhir ditunjukkan dalam " backward mode”. Cryptographic core pada Mars cipher menggunakan tipe-3 feistal network yang terdiri dari enam belas iterasi. Dalam setiap iterasi digunakan E-function (E adalah notasi dari expansion) yang mengkombinasikan perkalian, data dependent rotation dan S box lookup. Fungsi ini menerima input satu word data dan menghasilkan tiga word data sebagai output dengan notasi L, M dan R. Dalam setiap iterasi digunakan satu
word data sebagai input untuk function dan ketiga output word data dari E-function ditambahkan atau di-XOR-kan ke ketiga word data yang lama.
Kemudian source word dirotasikan sebanyak 13 posisi ke kiri. Ketiga output dari E-function digunakan dengan cara yang berbeda dalam delapan iterasi pertama dibandingkan dengan delapan iterasi terakhir. Dalam delapan iterasi pertama, output pertama dan kedua dari E-function ditambahkan dengan target
word pertama dan kedua, output ketiga di-XOR-kan dengan target word
ketiga. Dalam delapan iterasi terakhir, output pertama dan kedua dari
E-function ditambahkan dengan target word ketiga dan kedua, output ketiga
di-XOR-kan dengan target word pertama.
E-function menerima input satu word data (32 bit) dan menggunakan dua atau
lebih sub kunci untuk menghasilkan tiga word data sebagai output. Dalam fungsi ini digunakan tiga variabel sementara, yang dinotasikan dengan L, M dan R (left, middle, dan right). R berfungsi untuk menampung nilai source
word yang dirotasikan sebanyak 13 posisi ke kiri. M berfungsi untuk
menampung nilai source word yang dijumlahkan dengan sub kunci pertama. Sembilan bit terendah dari M digunakan sebagai indeks untuk 512 entry S-box. L berfungsi untuk menampung nilai yang sesuai dengan S box entry. Sub kunci kedua (mengandung integer) akan dikalikan dengan R dan kemudian R dirotasikan sebanyak 5 posisi ke kiri (5 bit tertinggi menjadi 5 bit terendah dari R setelah rotasi). Lalu L di-XOR-kan dengan R dan lima bit terendah dari R digunakan untuk nilai rotasi r dengan nilai antara 0 dan 31, dan M dirotasikan ke kiri sebanyak r posisi. R dirotasikan sebanyak 5 posisi ke kiri dan di-XOR-kan dengan L. Terakhir, lima bit terendah dari R diambil sebagai nilai rotasi r dan L dirotasikan kekiri sebanyak r posisi. Output word pertama dari E-function adalah L, kedua adalah M dan ketiga adalah R.
3. Tahap terakhir adalah backward mixing, berfungsi untuk melindungi
serangan kembali terhadap chosen chipertext. Tahap ini terdiri dari delapan iterasi tipe-3 Feistel mixing (dalam backward mode) dengan berbasis S-box, diikuti dengan pengurangan sub kunci dari word data. Hasil pengurangan inilah yang disebut dengan ciphertext
Tahap ini merupakan invers dari tahap forward mixing, word data diproses dalam urutan yang berbeda dalam backward mode. Seperti halnya pada forward mixing, di setiap iterasi pada backward mixing juga digunakan sebuah source word untuk memodifikasi tiga target word. Keempat byte dari source word dinotasikan dengan b0, bl, b2, b3 sebelumnya (dimana b0 adalah byte terendah dan b3 adalah byte tertinggi). b0, b2 digunakan sebagai index ke dalam S-box S1 dan b1, b3 sebagai index ke dalam S-box S0. S1[b0] di-XOR-kan dengan target word pertama, dan S0[b3] dikurangdi-XOR-kan dengan target word kedua. S1 [b2] dikurangkan dengan target word ketiga dan S0[b1] di-XOR-kan dengan target word ketiga juga. Terakhir source word dirotasidi-XOR-kan sebanyak 24 posisi ke kiri. Untuk iterasi berikutnya keempat word data dirotasikan sehingga target word pertama saat ini menjadi source word berikutnya, target word kedua saat ini menjadi target word pertama berikutnya, target word ketiga saat ini menjadi target word kedua berikutnya dan source word saat ini menjadi target word ketiga berikutnya.
Notasi yang digunakan dalam cipher :
1. D[ ] adalah sebuah array untuk 4 word 32-bit data. Inisial D berisi plaintext dan pada akhir proses enkripsi berisi ciphertext.
3. S[ ] adalah sebuah S-box, terdiri dari 512 word 32-bit
2.1.4 Perluasan Kunci
Perluasan kunci berfungsi untuk membangkitkan sub kunci dari kunci yang diberikan oleh pemakai yaitu array k[ ] yang terdiri dari n 32-bit word (dimana n adalah jumlah words dari 4 sampai 14) ke dalam array K[] sebanyak 40
words.
Mars menerima satu blok key awal sebesar 128 bit untuk mendapatkan key lain yang digunakan dalam proses enkripsi dan dekripsi. Untuk panjang kunci yang kurang dari 128, maka dilakukan padding bits yaitu proses penambahan untuk menambahkan satu dan sisanya ditambahkan dengan nol sampai mencapai panjang kunci yang seharusnya.
Key expansion menyediakan 40 words key (K[0],...,K[39]) yang terdiri
dari 32-bit. Empat kunci pertama digunakan untuk proses forward mixing dan empat kunci terakhir digunakan pada proses backwards mixing
2.2 Metode Huffman 2.2.1 Kompresi Huffman
Metode Huffman merupakan salah satu teknik kompresi dengan cara melakukan pengkodean dalam bentuk bit untuk mewakili data karakter. Cara kerja atau algoritma metode ini adalah sebagai berikut (Pengolahan Citra Digital, 2005:279) :
a. Menghitung banyaknya jenis karakter dan jumlah dari masing-masing karakter yang terdapat dalam sebuah file.
b. Menyusun setiap jenis karakter dengan urutan jenis karakter yang jumlahnya paling sedikit ke yang jumlahnya paling banyak.
c. Membuat pohon biner berdasarkan urutan karakter dari yang jumlahnya terkecil ke yang terbesar, dan memberi kode untuk tiap karakter.
d. Mengganti data yang ada dengan kode bit berdasarkan pohon biner.
e. Menyimpan jumlah bit untuk kode bit yang terbesar, jenis karakter yang diurutkan dari frekuensi keluarnya terbesar ke terkecil beserta data yang sudah berubah menjadi kode bit sebagai data hasil kompresi.
Contoh teknik kompresi dengan menggunakan metode Huffman pada file teks. Misalkan sebuah file teks yang isinya “AAAABBBCCCCCD”. File ini memiliki
ukuran 13 byte atau satu karakter sama dengan 1 byte. Berdasarkan pada cara kerja di
atas, dapat dilakukan kompresi sebagai berikut :
a. Mencatat karakter yang ada dan jumlah tiap karakter. A = 4, B = 3, C = 5, D = 1
b. Mengurutkan karakter dari yang jumlahnya paling sedikit ke yang paling banyak yaitu : D, B, A, C
c. Membuat pohon biner berdasarkan urutan karakter yang memiliki frekuensi terkecil hingga yang paling besar. Lihat Gambar.2.1
Gambar.2.1 Pohon Biner
d. Mengganti data yang ada dengan kode bit berdasarkan pohon biner yang dibuat.
Penggantian karakter menjadi kode biner, dilihat dari node yang paling atas atau
disebut node akar :
A = 01, B = 001, C = 1, D = 000.
Selanjutnya berdasarkan pada kode biner masing-masing karakter ini, semua karakter dalam file dapat diganti menjadi :
01010101001001001111110001111111
Karena angka 0 dan angka 1 mewakili 1 bit, sehingga data bit di atas terdiri dari
32 bit atau 4 byte (1 byte = 8 bit)
e. Menyimpan kode bit dari karakter yang frekuensinya terbesar, jenis karakter yang
terdapat di dalam file dan data file teks yang sudah dikodekan. Cara menyimpan data jenis karakter adalah dengan mengurutkan data jenis karakter dari yang frekuensinya paling banyak sampai ke yang paling sedikit, menjadi : [C,A,B,D] File teks di atas, setelah mengalami kompresi, memiliki ukuran sebesar 1 + 4 + 4 = 9 byte. Jumlah ini terdiri dari 1 byte kode karakter yang memiliki frekuensi terendah, 4 jenis karakter = 4 byte dan 4 byte data kode semua karakter.
2.2.2 Dekompresi Huffman
Setiap data yang telah mengalami kompresi, tentu harus dapat merekonstruksi kembali data tersebut sesuai dengan aslinya. Merekonstruksi data lebih dikenal sebagai metode dekompresi data. Metode dekompresi Huffman dapat digunakan untuk mengembalikan data kode biner menjadi file teks. Metode atau algoritma untuk mengembalikan data hasil kompresi menjadi data semula adalah sebagai berikut :
a. Membaca data pertama yang merupakan kode bit dari data karakter terakhir. Data pertama ini memiliki jumlah bit yang bervariasi (dalam contoh di atas data ini sama dengan 1 byte) dan digunakan sebagai pembanding untuk mengetahui apakah data karakter yang direkonstruksi merupakan data karakter terakhir atau bukan. Data ini selalu memiliki nilai sama dengan nol. b. Membaca data kode biner bit per bit hasil kompresi, bila nilai bit pertama
sama dengan “0” maka dilanjutkan pada bit kedua. Bila bit kedua juga memilik nilai “0”, maka terus dilakukan pembacaan bit hingga ditemukan nilai bit sama dengan “1”. Setelah ditemukan nilai bit “1”, berarti semua bit yang terbaca adalah merupakan kode sebuah karakter.
c. Mengubah kode biner menjadi sebuah karakter dengan cara menghitung banyaknya bit dalam kode tersebut. Misalkan banyaknya bit tersebut adalah n, maka kode biner di atas mewakili karakter pada urutan ke n dalam listing karakter.
d. Ulangi langkah b dan c hingga kode bit biner terakhir. Untuk menentukan apakah kode biner yang sedang dibaca mewakili karakter yang paling akhir dalam listing karakter atau tidak adalah dengan cara membandingkan semua bit “0” yang terbaca dengan kode biner dari karakter yang terakhir.
2.3 Metodologi Rekayasa Perangkat Lunak
Metodologi perangkat lunak yang digunakan dalam pembuatan sistem aplikasi ini adalah sebagai berikut :
Unified Modelling Language (selanjutnya disebut UML) adalah keluarga
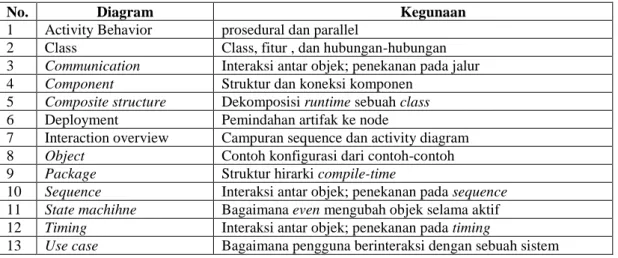
notasi grafis yang didukung oleh meta-model tunggal, yang membantu pendeskripsian dan desain sistem perangkat lunak, khususnya sistem yang dibangun menggunakan pemrograman berorientasi objek (Fowler, 2005:1). UML terdiri atas 13 jenis diagram resmi seperti tertulis dalam Tabel 2.
Tabel 2.1 Jenis diagram resmi UML
No. Diagram Kegunaan
1 Activity Behavior prosedural dan parallel
2 Class Class, fitur , dan hubungan-hubungan
3 Communication Interaksi antar objek; penekanan pada jalur
4 Component Struktur dan koneksi komponen
5 Composite structure Dekomposisi runtime sebuah class
6 Deployment Pemindahan artifak ke node
7 Interaction overview Campuran sequence dan activity diagram
8 Object Contoh konfigurasi dari contoh-contoh
9 Package Struktur hirarki compile-time
10 Sequence Interaksi antar objek; penekanan pada sequence
11 State machihne Bagaimana even mengubah objek selama aktif
12 Timing Interaksi antar objek; penekanan pada timing
Diagram UML yang akan dibahas pada bab ini adalah diagram use case (use case diagram), diagram aktifitas (activity diagram), dan diagram sekuensial (sequence diagram)
2.3.1 Diagram Use Case
Diagram use case adalah teknik untuk merekam persyaratan fungsional sebuah sistem. Diagram use case mendeskripsikan interaksi tipikal antara para pengguna sistem dengan sistem itu sendiri, dengan memberi sebuah narasi tentang bagaimana sistem tersebut digunakan (Fowler, 2005:141). Diagram use case menggambarkan fungsionalitas yang diharapkan dari sebuah sistem. Yang ditekankan adalah apa yang diperbuat sistem, dan bukan bagaimana (Dharwiyanti
dan Wahono, 2003:4).
Menurut Munawar (2005:63) use case adalah deskripsi fungsi dari sebuah sistem dari perspektif pengguna. Use case bekerja dengan cara mendeskripsikan tipikal interaksi antara pengguna sebuah sistem dengan sistemnya sendiri melalui sebuah cerita bagaimana sebuah sistem dipakai. Urutan langkah-langkah yang menerangkan antara pengguna dan sistem disebut skenario. Setiap skenario mendeskripsikan urutan kejadian. Setiap urutan diinisialisasi oleh orang, sistem yang lain, perangkat keras atau urutan waktu. Dengan demikian secara singkat bisa dikatakan use case adalah serangkaian skenario yang digabungkan bersama-sama oleh tujuan umum pengguna.
Dalam pembicaraan tentang use case, pengguna biasanya disebut dengan aktor. Aktor adalah sebuah peran yang bisa dimainkan oleh pengguna dalam interaksinya dengan sistem. Aktor mewakili peran orang, sistem yang lain, atau
alat ketika berkomunikasi dengan use case. Di dalam use case terdapat Stereotype yaitu sebuah model khusus yang terbatas untuk kondisi tertentu. Untuk menunjukkan Stereotype digunakan simbol ”<<” diawalnya dan ditutup ”>>” diakhirnya. <<include>> digunakan untuk menggambarkan bahwa suatu use case 15 seluruhnya merupakan fungsionalitas dari use case lainnya. Biasanya
<<include>> digunakan untuk menghindari penggandaan suatu use case karena
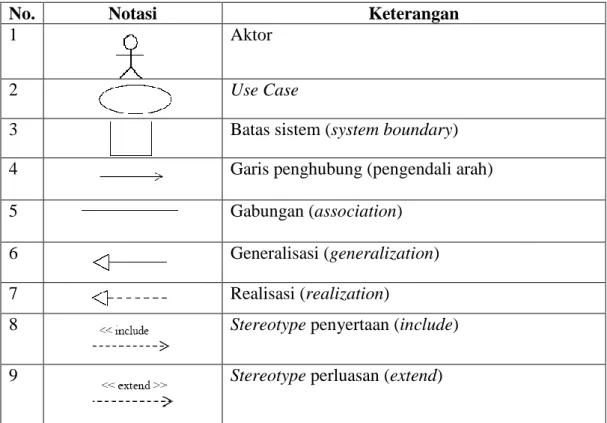
sering dipakai. <<extend>> digunakan untuk menunjukkan bahwa suatu use case merupakan tambahan fungsional dari use case yang lain jika kondisi atau syarat tertentu dipenuhi. Di dalam use case juga terdapat generalisasi. Tabel 2.2 menampilkan notasi-notasi dalam pemodelan diagram use case menurut Booch,
Rumbaugh, dan Jacobson (1998:187).
Tabel 2.2. Notasi pemodelan diagram use case
No. Notasi Keterangan
1 Aktor
2 Use Case
3 Batas sistem (system boundary)
4 Garis penghubung (pengendali arah)
5 Gabungan (association)
6 Generalisasi (generalization)
7 Realisasi (realization)
8 Stereotype penyertaan (include)
9 Stereotype perluasan (extend)
Menurut Munawar (2005:179) setiap use case harus dideskripsikan dalam dokumen yang disebut dengan dokumen aliran kejadian (flow of event).
Dokumen ini mendefinisikan apa yang harus dilakukan oleh sistem ketika aktor mengaktifkan use case. Struktur dari dokumen use case ini bisa macam-macam, tetapi umumnya deskripsi ini paling tidak harus mengandung :
1. Deskripsi singkat (brief description). 2. Aktor yang terlibat.
3. Kondisi awal (precondition) yang penting bagi use case untuk memulai. 4. Deskripsi rinci dari aliran kejadian yang mencakup:
a. Aliran utama (main flow) dari kejadian yang bisa dirinci lagi. b. Aliran bagian (sub flow) dari kejadian.
c. Aliran alternatif untuk mendefinisikan situasi perkecualian.
5. Kondisi akhir yang menjelaskan state dari sistem setelah use case berakhir. Dokumen use case ini berkembang selama masa pengembangan. Di awal-awal penentuan kebutuhan sistem, hanya deskripsi singkat saja yang ditulis. Bagian bagian lain dari dokumen ini ditulis secara gradual dan iteratif. Akhirnya sebuah dokumen lengkap bisa didapatkan di akhir fase spesifikasi. Biasanya pada fase spesifikasi ini sebuah prototipe yang dilengkapi dengan tampilan layar bisa ditambahkan. Pada tahap berikutnya, dokumen use case ini bisa digunakan untuk membuat dokumentasi untuk implementasi sistem.
2.3.2 Diagram Aktifitas
Menurut Munawar (2005:109) diagram aktifitas adalah teknik untuk mendeskripsikan logika prosedural, proses bisnis dan aliran kerja dalam banyak kasus. Diagram aktifitas mempunyai peran seperti halnya diagram alur
(flowchart), akan tetapi perbedaannya dengan flowchart adalah diagram aktifitas
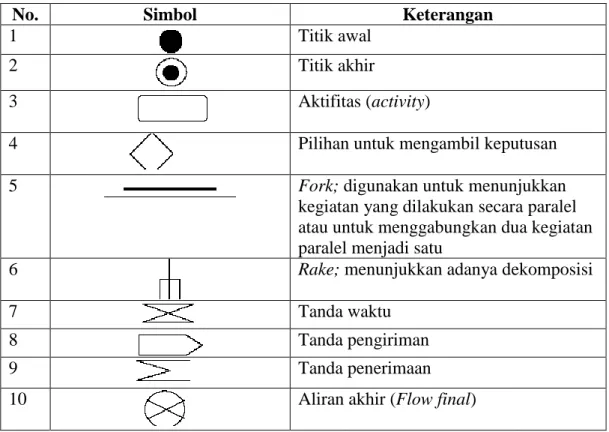
Tabel 2.3 adalah simbol-simbol yang sering digunakan pada saat pembuatan diagram aktifitas.
Tabel 2.3. Simbol-simbol pada diagram aktifitas
No. Simbol Keterangan
1 Titik awal
2 Titik akhir
3 Aktifitas (activity)
4 Pilihan untuk mengambil keputusan
5 Fork; digunakan untuk menunjukkan
kegiatan yang dilakukan secara paralel atau untuk menggabungkan dua kegiatan paralel menjadi satu
6 Rake; menunjukkan adanya dekomposisi
7 Tanda waktu
8 Tanda pengiriman
9 Tanda penerimaan
10 Aliran akhir (Flow final)
2.3.3 Diagram Sekuensial
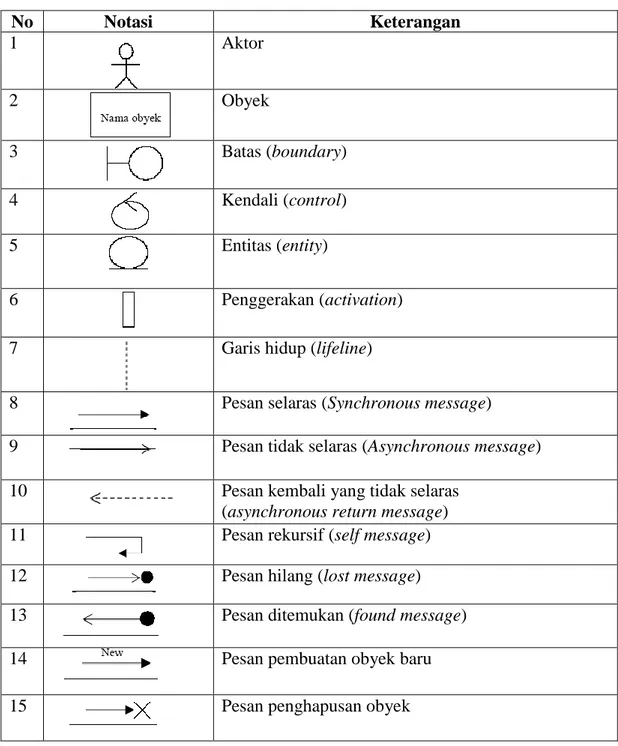
Menurut Munawar (2005:87) diagram sekuensial digunakan untuk menggambarkan perilaku pada sebuah skenario. Komponen utama diagram sekuensial terdiri atas objek atau disebut juga peserta (participant), pesan diwakili oleh garis dengan tanda panah dan waktu yang ditunjukkan dengan garis tegak lurus. Tabel 2.4 memperlihatkan notasi-notasi dalam pemodelan diagram sekuensial.
Tabel 2.4. Notasi pemodelan diagram sekuensial No Notasi Keterangan 1 Aktor 2 Obyek 3 Batas (boundary) 4 Kendali (control) 5 Entitas (entity) 6 Penggerakan (activation)
7 Garis hidup (lifeline)
8 Pesan selaras (Synchronous message)
9 Pesan tidak selaras (Asynchronous message)
10 Pesan kembali yang tidak selaras
(asynchronous return message)
11 Pesan rekursif (self message)
12 Pesan hilang (lost message)
13 Pesan ditemukan (found message)
14 Pesan pembuatan obyek baru
15 Pesan penghapusan obyek
Algoritma berisi langkah-langkah penyelesaian suatu masalah. Langkah langkah tersebut dapat berupa runtunan aksi (sequence), pemilihan aksi
(selection), pengulangan aksi (iteration) atau kombinasi dari ketiganya. Jadi
1. Struktur Runtunan
Digunakan untuk program yang pernyataannya sequential atau urutan. 2. Struktur Pemilihan
Digunakan untuk program yang menggunakan pemilihan atau penyeleksian kondisi.
3. Struktur Perulangan
Digunakan untuk program yang pernyataannya akan dieksekusi berulang-ulang.
Penyajian algoritma secara garis besar bisa dalam 2 bentuk penyajian yaitu tulisan dan gambar. Algoritma yang disajikan dengan tulisan yaitu dengan struktur bahasa tertentu (misalnya bahasa Indonesia atau bahasa Inggris) dan
pseudocode. Pseudocode adalah kode yang mirip dengan kode pemrograman yang
sebenarnya seperti Pascal, atau C, sehingga lebih tepat digunakan untuk menggambarkan algoritma yang akan dikomunikasikan kepada pemrogram.
Sedangkan algoritma disajikan dengan gambar, misalnya dengan
flowchart. Secara umum, pseudocode mengekspresikan ide-ide secara informal
dalam proses penyusunan algoritma. Salah satu cara untuk menghasilkan kode
pseudo adalah dengan meregangkan aturan-aturan bahasa formal yang dengannya
versi akhir dari algoritma akan diekspresikan. Pendekatan ini umumnya digunakan ketika bahasa pemrograman yang akan digunakan telah diketahui sejak awal.
2.4 Pengujian
Pengujian perangkat lunak adalah elemen kritis dari jaminan kualitas perangkat lunak dan merepresentasikan kajian pokok dari spesifikasi, desain, dan pengkodean. (Pressman, 2002:525)
2.4.1 Pengujian Black Box
Salah satu bentuk pengujian black box adalah metode partisi ekivalensi yaitu metode pengujian black box yang membagi domain input dari suatu program ke dalam kelas data dari mana test case dapat dilakukan (Pressman, 2002:526) Pengujian black box berusaha menemukan kesalahan diantaranya fungsi-fungsi yang hilang atau tidak benar, kesalahan interface, kesalahan dalam struktur data atau akses basis data eksternal, kesalahan kinerja, inisialisasi dan kesalahan terminasi. Pengujian black box ini dilakukan untuk memperlihatkan bahwa fungsi-fungsi bekerja dengan baik dalam arti masukan yang diterima dengan benar dan keluaran yang dihasilkan benar-benar tepat, pengintegrasian dari eksternal data berjalan dengan baik (file/data). Walaupun sulit untuk menelusuri kesalahan yang mungkin didapat, teknik pengujian black box lebih sering dipilih untuk menguji perangkat lunak karena kemudahan dalam pelaksanaannya. Proses yang terdapat dalam pengujian Black-Box :
1. Pembagian kelas data untuk pengujian setiap kasus pada pengujian White-Box. 2. Analisis batasan nilai yang berlaku untuk setiap data
2.4.2 Pengujian White Box
Pengujian White box ditujukan untuk mengetahui fungsi yang ditentukan dimana produk dirancang untuk melakukannya pengujian dapat dilakukan untuk memperlihatkan bahwa masing-masing fungsi beroperasi sepenuhnya, pada waktu yang sama untuk mencari kesalahan-kesalahan pada setiap fungsi. Dengan metode ini perekayasa sistem dapat melakukan pengujian jalur yang memberikan jaminan bahwa semua jalur independen path atau lintasan pada suatu modul telah digunakan paling tidak satu kali, menggunakan semua keputusan logis pada sisi benar (true) dan salah (false) program akan diuji serta eksekusi semua loop dalam batasan kondisi dan batasan operasionalnya selain itu juga meliputi pengujian validasi struktur data internal. Pelaksanaan pengujian White box :
1. Menjamin seluruh independent path dieksekusi paling sedikit satu kali.
Independent path adalah jalur dalam program yang menunjukkan paling sedikit
satu kumpulan proses ataupun kondisi baru. 2. Semua titik keputusan akan teruji.
3. Semua konstruksi pengulangan (loop) akan dieksekusi hingga batas akhir pengulangannya.
4. Struktur data internal dapat diuji untuk menjamin validitasnya. Analisa siklomatis adalah metrik perangkat lunak yang memberikan pengukuran kuantitatif terhadap kompleksitas logis suatu program. Nilainya memberikan jumlah dari independent path dalam basis set dan upper bound dari jumlah test untuk memastikan bahwa setiap statement dieksekusi paling tidak satu kali.