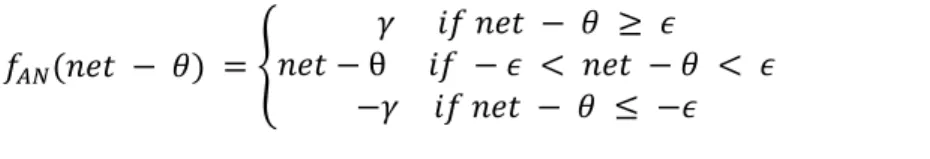BAB II
LANDASAN TEORI
BAB 2 LANDASAN TEORI
2.1 Kesesuaian Lahan
Pemanfaatan sumber daya lahan secara efisien memerlukan kesesuaian lahan. Kesesuaian lahan merupakan tingkat kecocokan lahan untuk penggunaan tertentu. FAO menyatakan bahwa sangat disarankan adanya kesesuaian lahan untuk negara-negara berkembang. Kesesuaian lahan aktual adalah kesesuaian lahan berdasarkan data tanah atau sumber daya lahan sebelum lahan tersebut digunakan. Data lahan tersebut berupa karakteristik tanah dan iklim yang berhubungan dengan persyaratan tumbuh suatu tanaman. FAO juga menyatakan bahwa evaluasi lahan diperlukan untuk mencocokkan / matching antara kualitas suatu lahan dengan syarat yang diperlukan untuk suatu penggunaan tertentu (FAO, 1976).
Evaluasi lahan yang bersifat kuantitatif berkaitan dengan tingkap produksi yang dicapai untuk suatu penggunaan lahan tertentu. Hal tersebut sangat diperlukan dalam perencanaan penggunaan lahan (land use planning) untuk mengurangi resiko kegagalan, meningkatkan produktivitas, serta memperoleh nilai ekonomi penggunaan lahan yang terbaik (Hermantoro, Rudiyanto, & Suprayogi, 2008).
Salah satu cara untuk mengevaluasi dan menentukan kesesuaian lahan untuk tanaman pangan adalah dengan menganalisis kesesuaian lahan yang didasarkan atas data lahan dan mendapatkan prediksi hasil produksi untuk setiap daerah.
Prediksi hasil produksi tersebut pada akhirnya dapat menjadi penentu dimanakah lahan yang sesuai untuk digunakan (Vargahan, Shahbazi, & Hajrasouli, 2011).
2.2 Padi Sawah
Pangan dapat diartikan sebagai segala sesuatu yang bersumber dari sumber hayati dan air, baik yang telah diolah maupun yang tidak diolah. Pangan diperuntukan untuk konsumsi manusia sebagai makanan atau minuman. Tanaman pangan merupakan kelompok tanaman yang merupakan sumber karbohidrat dan protein.
Padi adalah salah satu contoh tanaman pangan yang berupa rumput berumputan. Tanaman pangan ini berasal dari dua benua yakni benua Asia dan benua Afrika barat tropis dan subtropis. Penanaman padi sudah dilakukan pada tahun 3000 tahun SM di Zhejiang, China (Purnomo & Purnamawati, 2007).
Padi dapat beradaptasi pada lingkungan tergenang karena pada akarnya terdapat saluran seperti pipa memanjang hingga ujung daun yang disebut aerenchyma. Walaupun padi dapat beradaptasi pada lingkungan tergenang, padi juga dapat dibudidayakan pada lahan yang kering atau lading (lahan tidak tergenang) yang kondisinya aerob(Purnomo & Purnamawati, 2007).
Di Indonesia, sistem pembudidayaan tanaman padi secara garis besar dikelompokan menjadi 2 yaitu padi sawah dan padi gogo. Pada sistem sawah, padi sepanjang hidupnya selalu dalam keadaan tergenang oleh air. Sebaliknya, pada sistem gogo, padi tumbuh pada kondisi tidak tergenang air. Hasil kombinasi antara kedua sistem tersebut disebut juga dengan gogo rancah. Pada sistem gogo rancah, padi ditanam pada saat awal musim hujan pada petakan sawah yang
kemudian akan tergenangi oleh air hujan seiring dengan bertambahnya curah hujan ditempat tersebut(Purnomo & Purnamawati, 2007).
Gambar 2.1 Tanaman Padi (Purnomo & Purnamawati, 2007)
Terdapat beberapa varietas unggul untuk tanaman padi. Beberapa diantaranya ialah IR 48, IR 64, IR 65, IR 74, Fatmawati, Sintanur, Batang Kampar (KL 76), Hibrindo R-2, Batang Samo (KL 77), Yuwono, Rojolele, Tukad Balian, Citarum, Cisadane, Cisantana, dan Winongo(Purnomo & Purnamawati, 2007).
2.3 Artificial Neural Network
Artificial Neural Network merupakan sebuah sistem pemrosesan informasi yang meniru cara kerja dari neuron otak manusia. Neuron-neuron tersebut terhubung satu sama lain dengan connection link. Pemodelan dengan Artificial
Neural Network terdiri dari dua tugas utama yaitu design dan training network. Fase training atau yang biasa disebut dengan learning
phasemelibatkanpenyesuaianbobot/weightsertabias valuedari satu setcontohtraining(Mitra & Samanta, 2013).
Artificial Neural Network atau yang sering hanyadisebut sebagaiNeural Network merupakan sebuah modelmatematik yangterinspirasi olehjaringan sarafbiologisyang saling terhubung olehneuronbuatandanmemproses informasi
dengan menggunakan pendekatankoneksionisuntukperhitungan. Dalamkebanyakan kasus, neural networkadalah sistemadaptifyang mengubahstrukturselama fasepembelajaran/learning phase. Neural networkdigunakan untuk modelhubungan yang kompleks antarainput dan outputatauuntuk menemukanpola dalamdata(Dutta, Roy, & Choudhury, 2013).
2.3.1 Arsitektur Neural Network
Secara umum berdasarkan arsitektur jaringannya, terdapat beberapa jenis neural network yang sering digunakan. Beberapa jenis arsitektur yang sering digunakan adalah single-layer neural network dan multiple-layer neural network(Engelbrecht, 2007).
1. Single-Layer Neural Network
Neural Network jenis ini, memiliki koneksi input yang berhubungan langsung dengan output. Neural Network jenis ini hanya dapat menyelesaikan permasalahan sederhana seperti AND/OR problem.
Gambar 2.2AND & OR Perceptron (Engelbrecht, 2007)
2. Multiple-Layer Neural Network
Neural Network jenis ini memiliki layer tambahan yang disebut dengan hidden layer. Arsitektur ini dapat menyelesaikan permasalahan yang lebih kompleks dibandingkan dengan Single-Layer Neural Network.
Gambar 2.3Multiple Layer Neural Network(Engelbrecht, 2007)
Berikut merupakan beberapa aturan yang biasa digunakan untuk menentukan jumlah neuron dalam hidden layer(Karsoliya, 2012):
a. Jumlah hidden neuron dalam suatu hidden layer adalah 2/3 (atau 70% sampai 90%) dari jumlah input layer. Namun dapat disesuaikan dikemudian hari.
b. Jumlah hidden neurondalam suatu hidden layerbiasanya kurang dari dua kali jumlah input layer.
c. Jumlah hidden neurondalam suatu hidden layerberada diantara jumlah input layer dan jumlah output layer.
Metode trial and error terstruktur biasanya digunakan oleh beberapa pengembang untuk menciptakan jaringan saraf yang paling mendekati.
2.3.2 Learning pada Neural Network
Berdasarkan tipe learning/training, Neural Network dibedakan menjadi:
1. SupervisedLearning
SupervisedLearning membutuhkan data set yang terdiri dari vektor input dan target/output yang berkaitan dengan setiap input vektor. Data set ini disebut dengan trainingset. Tujuan dari training ini adalah untuk menyesuaikan weight sehingga kesalahan (error) mendekati nol. Salah satu Neural Network yang termasuk dalam Supervised Learning adalah Feed ForwardNeural Network(Engelbrecht, 2007).
Feed Forward Neural Network (FFNN) dapat memiliki koneksi langsung antara input layer dan output layer. Namun, FFNN standar terdiri dari tiga layer yaitu input layer, hidden layer, dan output layer.
Pengembangan Feed Forward Neural Network adalah menggunakan Backpropagation. Backpropagation diperkenalkan oleh G.E. Hinton, E. Rumelhart dan R.J. Williams pada tahun 1986. Backpropagation dapat menyelesaikan masalah-masalah yang sulit yang tidak dapat diselesaikan oleh Perceptron. Perbedaan antara Backpropagation dengan Perceptron adalah Backpropagation memiliki
layer tambahan atau yang biasa disebut dengan hidden layer. Backpropagation merupakan suatu Perceptron yang output-nya dijadikan input value dari perceptron lainnya(Dutta, Roy, & Choudhury, 2013).
Backpropagation melakukan optimasi Gradient Decent untuk mengurangi kesalahan/error. Gradient Decentmelakukan pembaharuan pola untuk menyesuaikan parameter Neural Network (bobot/weight) untuk meminimalkan kesalahan(Sehgal, Gupta, & Kumar, 2012).
Backpropagation yang diperkenalkan oleh Werbos ini terdiri dari dua tahap(Engelbrecht, 2007):
a. Feed Forward Pass
Tahap ini adalah tahapan dimana Neural Network menghitung nilai output untuk setiap pola pelatihan.
b. Backward Propagation
Tahap ini adalah tahapan dimana Neural Netwok memberikan sinyal kesalahan dari output layer ke input layer. Bobot/weight akan disesuaikan pada tahap ini.
Secara umum, berikut merupakan langkah-langkah algoritmaBackpropagation (Kusumadewi & Hartati, 2010):
Step1 : Memberikan initial weight secara random untuk setiap
weight.
Step2 : Menentukan parameter seperti maksimum epoch, target
error, learning ratedan momentum.
melakukan perulangan. Kondisi berhenti dapat meliputi mencapai jumlah epoch atau sudah mencapai Mean Squared Error (MSE) yang diinginkan.
Feed Forward:
Step4 : Setiap input unit ( dimana =1,…,) akan menerima
sinyal kemudian menyebarkan sinyal tersebut ke hidden unit.
Step5 : Untuk setiap hidden unit, ( dimana j = 1,…, ),
jumlahkan sinyal input yang sudah berbobot (termasuk bias) dengan rumus sebagai berikut:
_ = + ∑ Dimana:
= bias pada hidden unit ke j = nilai input ke i
= weight dari input unit i ke hidden unit j
Kemudian hitung sinyal ouput dari hidden unit sesuai dengan fungsi aktivasi yang telah ditentukan:
= ( _ )
Kemudian sinyal tersebut akan dikirimkan ke semua unit di layer selanjutnya yaitu output unit.
Step6 : Untuk setiap output unit, ( dimana k=1,…,m) akan
melakukan perhitungan: _ = + ∑
Dimana:
= nilai biasoutput unit ke k
= nilai input ke i(hasil perhitungan step 5) = weight dari hidden unit j ke output unit k Kemudian hitung sinyal ouput dari hidden unit sesuai dengan fungsi aktivasi yang telah ditentukan:
= ( _ )
Sinyal output ini selanjutnya dikirim ke seluruh unit pada output.
Backpropagation of Error:
Step7 : Untuk setiap output unit, ( dimana k=1,…,m) akan
dihitung kesalahan diantara nilai output yang dihasilkan oleh jaringan dengan target dengan rumus sebagai berikut:
= ( − ) ′( _ )
Kemudian hitung koreksi error (∆ jk) yang nantinya
akan dipakai untuk memperbaiki jk dengan rumus
sebagai berikut: ∆ jk = k j
Kemudian akan dihitung koreksi bias(∆ 0k yang
nantinya akan dipakai untuk memperbaiki 0k
menggunakan rumus sebagai berikut: ∆ 0k = k
pada tahap selanjutnya.
Step8 : Setiap unit tersembunyi ( , = 1, … , ) menerima
inputdelta. Hitung _inj menggunakan rumus:
_inj= ∑ δ
Hasil _injdikalikan dengan turunan dari fungsi
aktivasiyang digunakan untuk mendapatkan kesalahanerror j, dimana:
= _ ′( _ )
Setelah itu akan dihitung koreksi bobot (untuk memperbaiki vij)
∆ =
Selanjutnya akan dihitung juga koreksi bias (digunakan untuk memperbaiki v0j)
∆ 0 = j
Adjustment :
Step9 : Setiap output unit( dimana 1,…, ) memperbaiki
bobot dan biasdari setiap hidden unit dimana 0,…,
Δ
Demikian juga untuk setiap hidden unit( dimana 1,…, ) akan memperbaharui bobot dan bias dari setiap
input unit ( 0,…, )
Δ
maximumepoch atau target error), maka neural network training dapat dihentikan.
Pengujian dapat dilakukan melalui Feed Forward dengan langkah-langkah sebagai berikut:
Step1 : Memberikan initial weight berdasarkan hasil pelatihan.
Step2 : Untuk setiap vektor input, kerjakan step 3,4,5 dibawah
ini.
Step3 : Untuk i=1,…,n:
set aktivasi unit yang dipilih untuk input xi
Step4 : Untuk j=1,…,p:
_ = + ∑ Dimana:
= bias pada hidden unit ke j = nilai input ke i
= weight dari input unit i ke hidden unit j Kemudian hitung:
= ( _ )
Step5 : Untuk k=1,…,m:
Untuk setiap output unit, ( dimana k=1,…,m) akan melakukan perhitungan:
_ = + ∑ Dimana:
= nilai input ke i (hasil perhitungan tahap 4)
= weight dari hidden unit j ke output unit k
Kemudian hitung output: = ( _ )
2. UnsupervisedLearning
Dalam Unsupervised Learning, pattern/pola ditemukan melalui data input tanpa bantuan dari sumber external. Unsupervised Learning biasanya melakukan pengelompokan pola. Contohnya adalah menggunakan algoritma Learning Vector Quantizer untuk melakukan clustering(Engelbrecht, 2007).
3. ReinforcementLearning
Reinforcement Learning terinspirasi dari cara pembelajaran hewan. Ide dasar dari Reinforcement Learning adalah memberikan award kepada agent yang benar, dan menghukum yang salah. Reinforcement Learning adalah proses trial and error dan dikombinasikan dengan pembelajaran (Engelbrecht, 2007).
2.3.3 Fungsi Aktivasi pada Neural Network
Salah satu hal yang penting dalam struktur jaringan syaraf (neural network) adalah penggunaan activation function atau threshold function atau transferfunction. Fungsi aktivasi digunakan untuk mengubah atau
mentrasformasikan suatu inputan/aktivasi unit menjadi suatu output tertentu (Karlik & Vehbi, 2010).
Walaupun pemilihan fungsi aktivasi merupakan hal yang penting dalam neural network, ada faktor lain yang juga penting dalam neural networksepertialgoritma training dan arsitekurnetwork(Sibi, Jones, & Siddarth, 2013).
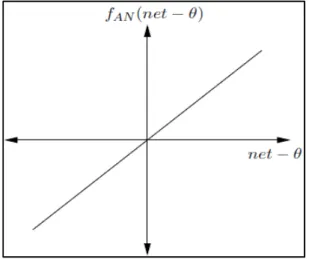
Terdapat beberapa fungsi aktivasi yang dapat digunakan. Berikut merupakan beberapa fungsi aktivasi pada neuralnetwork yang sering digunakan(Engelbrecht, 2007): Dimana: ∞ 0 atau ∞ 1 dan ∞ 1 1. Linear Function θ λ net θ
dimana θ = 0 dan λ adalah kemiringan fungsi. Fungsi linear menghasilkan output linear termodulasi, di mana λ adalah konstanta. Fungsi aktivasi linear hanya akan menghasilkan angka positif atas seluruh rentang bilangan real.
Gambar 2.4Linear Function
2. StepFunction
Dimana θ > 0. Step function menghasilkan salah satu dari dua nilai
outputskalar. Biasanya untuk binaryoutput akan menghasilkan = 1 dan
= 0. Bipolaroutput juga biasanya digunakan, dimana = 1 dan = -1.
Gambar 2.5Step Function
θ
Dimana θ > 0. Ramp function merupakan kombinasi dari Linear Function dan StepFunction.
Gambar 2.6Ramp Function
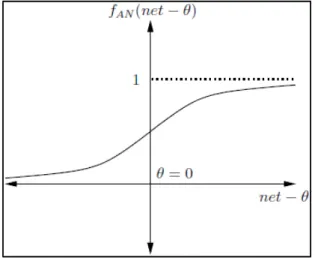
4. SigmoidFunction
SigmoidFunctionmerupakan salah satu fungsi yang paling sering digunakan. Fungsi ini akan menghasilkan angka positif antara 0 sampai 1. SigmoidFunctionakan berguna untuk data training antara 0 dan 1 (Sibi, Jones, & Siddarth, 2013).
1
1
Dimana θ = 0 dan λ adalah kemiringan fungsi, biasanya λ = 1. SigmoidFunctionadalah versi kontinu dari Step Function.
Gambar 2.7Sigmoid Function 5. HyperbolicTangentFunction atau 2 1 1
Dimana θ = 0. Keluaran dari Hyperbolic Tangent Functionadalah didalam range (−1, 1).
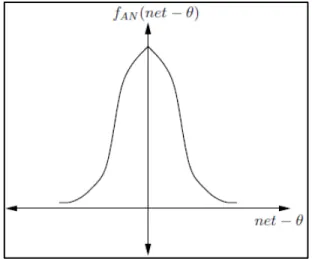
6. Gaussian Function
/
Dimana θ = 0, − θ adalah rata-rata dan σ adalah standar deviasi dari distribusi Gaussian.
Gambar 2.9Gaussian Function
2.3.4 Performance Factor pada Neural Network
Terdapat beberapa faktor yang mempengaruhi performa dari Supervised Neural Network. Faktor tersebut meliputi data preparation, weight initialization, learning rate, momentum, metode optimasi, pemilihan arsitektur, adaptive activation function, dan active learning(Engelbrecht, 2007).
Performa dari Artificial Neural Networks bergantung kepada beberapa faktor seperti arsitektur Neural Network, jumlah neuron pada hidden layer, neuronactivation function, dan pemilihan initial network parameters (connection weights). Biasanya trial & error dilakukan untuk menentukan network parameter dan initial connection weight. Particle
Swarm Optimation dapat digunakan pada tahap pre-training, network training, validation, dan testing performance untuk peningkatan secara signifikan (Nikelshpur & Tappert, 2013).
Learning rate merupakan faktor yang mengontrol langkah untuk menuju fungsi tujuan. Jika learning rate terlalu kecil, maka penyesuaian bobot/weight akan kecil. Jika learning rate besar, maka perubahan weight juga besar sehingga akan cepat konvergen dan terisolasi tanpa mencapai nilai minimumnya (Engelbrecht, 2007).
Istilah untuk momentum adalah rata-rata perubahan bobot/weight. Dengan momentum, perubahan bobot/weight sebelumnya mempengaruhi perubahan bobot. Jika momentum yang digunakan adalah nila 0, maka perubahan bobot/weight tidak dipengaruhi oleh perubahan bobot/weight di masa lalu (Engelbrecht, 2007).
2.4 Swarm Intelligence
Swarm intelligence/ Swarm Optimization Algorithmadalah metode optimasi berdasarkan agen terdistribusi yang memiliki kemampuan untuk bersama sama menyelesaikan permasalahan yang rumit. Swarm Intelligence mempelajari perilaku kawanan organisme sosial(Purnomo, 2014). Berikut merupakan beberapa algoritma optimasi yang termasuk ke dalam keluarga Swarm Intelligence:
2.4.1 Particle Swarm Optimization (PSO)
Particle Swarm Optimization(PSO) adalah metodeoptimasiyang termasuk dalam keluargaSwarmIntelligence.Particle Swarm Optimization
(PSO) adalah suatu teknik optimasi yang terinspirasi oleh perilaku sosial berkelompok burung dan ikan yang mencari makanan. Teknik ini awalnya dirancang dan dikembangkan oleh Eberhart dan Kennedy(Kennedy & Eberhart, 1995).
Particle Swarm Optimization merupakanmodel sederhanadari teori evolusi yang didasarkan padaprinsip-prinsip yangkawanan burung, ikan, atausegerombolanlebahyang mencari sumbermakanan di manapada awalnya lokasi sumbertidak diketahui. Namun, merekaakhirnyaakan mencapailokasi terbaikdarisumber makanandengan caraberkomunikasi satu sama lain (Dutta, Roy, & Choudhury, 2013).
Algoritma Particle Swarm Optimization merupakan algoritma optimasi yang berdasarkan konsep interaksi sosial dari sekumpulan burung yang akan mensimulasikan pergerakan sekumpulan burung yang tidak terprediksi. Simulasi algoritma ini bertujuan untuk mengetahui pola/pattern dari pergerakan burung yang dapat berubah secara tiba–tiba kemudian membuat formasi yang optimal (Engelbrecht, 2007).
Particleakandigunakanuntukmenyelesaikan problem ditentukan.
Setiap particle memilikiposisi, velocity dan solusi terbaik. Kemudian prosesdaripengubahanvelocity, perhitung pergerakan particle, jika solusi
yang didapatkanlebihbaikdarimaka solusi terbaik digantidengansolusitersebut. Jikatidaklebihbaik,makatidakadaperubahan
untuksolusiglobal best.Ulangilangkahsampaikondisiberhentiterpenuhi (Chu & Chen, 2006).
Dalam Particle Swarm Optimization, terdapat tiga bagian tahapan/langkah utama yakni:
1. Mengevaluasi nilai fitness dari setiap particle
2. Mengupdate nilai fitness dan posisi individu terbaik/yang biasa disebut global best.
3. Mengupadate kecepatan dan posisi dari setiap particle(Purnomo, 2014). Berikut merupakan langkah-langkah original dari Particle Swarm Optimization(Chu & Chen, 2006):
Step1 : Tentukan banyaknyaparticle yang akan digunakan untuk
menyelesaikan problem. Setiap particle mempunyai posisi, velocity dan solusi terbaik
Step2 : Proses dari pengubahan velocity dapat dilihat berdasarkan
perhitungan:
. . .
Step3 : Pergerakan particle dapat dilihat berdasarkan perhitungan:
, 0,1, … , 1, Dimana:
M adalah particle size
(Vmax adalah maximum velocity)
r1 dan r2 adalah random variable contohnya 0 , 1
Step4 : Jika solusi yang didapatkan lebih baik dari Gi, maka Gi
akan diganti dengan solusi tersebut. Jika tidak lebih baik, maka tidak ada perubahan untuk solusi global best.
Step 5 : Ulangi step 1 sampai 4, sampai kondisi berhenti terpenuhi. Ada
beberapakondisiterminasiyangdapatdipakaidalamParticleSwarm Optimizationyaitu (Engelbrecht, 2007):
1. Berhenti ketika jumlah iterasi telah mencapai jumlah iterasi maksimum yang diperbolehkan.
2. Berhenti ketika solusi yang dapat diterima telah ditemukan. 3. Berhenti ketika tidak ada perkembangan setelah beberapa iterasi.
Selanjutnya, konsep Inersia Weight dikembangkan oleh Shi dan Eberhart pada tahun 1998 untuk eksplorasi dan eksploitasi kontrol yang lebih baik dengan menggunakan persamaan V w V C . r P X C . r . G X (Shi & Eberhart, A Modified Particle Swarm Optimizer, 1998).
Terdapat beberapa rule yang digunakan untuk menentukan nilai dan . Kennedy & Eberhart menyarankan penggunaan nilai fix 2.0 untuk dan (Kennedy & Eberhart, 1995). Namun pada tahun 2000, Eberhart and Shi menyarankan penggunaan nilai 1.49618 untuk dan (Eberhart & Shi, 2000).
Dikatakan bahwa swarm size tidak mempengaruhi kinerja dari Particle Swarm Optimization(Shi & Eberhart, A Modified Particle Swarm Optimizer, 1998). Kemudian, dikatakan juga bahwa dengan menggunakan jumlah particle yang lebih sedikit kecil, akan mengurangi evaluasi fitness functionsehingga berpengaruh pada waktu/biaya komputasi (Escalante, Montes, & Sucar, 2009).(Shi & Eberhart, Parameter selection in particle swarm optimizatio n. In Evolutionary Programming VII, 1998)
2.4.2 Cat Swarm Optimization (CSO)
Cat Swarm Optimization (CSO) merupakan algoritma baru dalam teknik optimasi yang meniru perilaku kucing (cat) yang diusulkan oleh Chu & Tsai. Cat Swarm Optimization memiliki kelebihan dalam penyelesaikan masalah optimasi jika dibandingan dengan algoritma sebelumnya yaitu Particle Swarm Optimization.Cat Swarm Optimization dapat memberikan performance yang lebih baik jika dibandingkan dengan Particle Swarm Optimization (Chu & Tsai, 2007).
Berdasarkan hasil pengamatan perilaku kucing, terdapat dua perilaku besar yang dapat dimodelkan yaitu seeking mode dan tracking mode. Penggabungan antara dua mode tersebut dapat memberikan performa yang lebih baik(Chu & Chen, 2006). Berikut merupakan pembahasan dari algoritma optimasi Cat Swarm Optimization:
a. The Presentation of Solution Set
Pada algoritma optimasi, solution set (hasil) ditampilkan dengan cara tertentu misalnya chromosome yang digunakan untuk merepresentasikan solution set dari Genetic Algorithm. Contoh lainnya adalah dalam Ant Colony Optimization (ACO), semut (ant) disimulasikan sebagai Agent dan jalur yang dibentuk oleh semut merepresentasikan solution set. Cat Swarm Optimization akan menggunakan kucing (cat) dan pemodelan dari perilaku kucing (model of cat behavior) untuk menyelesaikan masalah optimasi.
Pada Cat Swarm Optimization, pertama-tama akan ditentukan berapa banyak cat yang akan digunakan dalam iterasi, kemudian cat akan diterapkan pada Cat Swarm Optimization untuk menyelesaikan masalah. Setiap cat akan memiliki posisinya sendiri yang tersusun dari dimensi M, kecepatan (velocities) untuk masing-masing dimensi, nilai kecocokan (fitness value) serta flag yang menandakan apakah cat sedang berada pada seeking mode atau tracking mode. Solusi akhirnya adalah posisi yang terbaik dari salah satu cat. Cat Swarm Optimization akan menyimpan solusi terbaik sampai iterasi berakhir.
b. Rest and Alert - Seeking Mode
Tahap ini memodelkan situasi cat ketika berada dalam keadaan istirahat, melihat sekeliling, dan mencari posisi selanjutnya untuk bergerak. Pada tahap ini, terdapat empat variable/faktor penting yang didefinisikan yakni:
1. SMP : seeking memory pool
SMP adalah variabel yang digunakan untuk mendefinisikan ukuran memori pencarian untuk masing-masing Cat yang mengindikasikan titik-titik yang telah dilalui oleh Cat. Cat kemudian akan memilih titik dari kelompok memori berdasarkan aturan tertentu.
2. SRD : seekingrange of the selected dimension
SRD merupakan variable yang menyatakan perpindahan dalam dimensi yang terpilih. Dalam seeking mode, jika dimensi diputuskan untuk berpindah, selisih antara nilai baru dengan yang lama tidak melebihi rentang yang didefinisikan oleh SRD.
3. CDC : counts of dimension to change
CDC adalah variabel yang memperlihatkan berapa besar dimensi yang akan berubah.
4. SPC : self-position considering
SPC merupakan variabel Boolean (true/false), untuk menandakan apakah suatu titik yang pernah menjadi posisi Cat akan menjadi kandidat posisi untuk bergerak.
Berikut merupakan tahapan - tahapan dalam Seeking Mode(Yusiong, 2013):
Step 1 : Buatlah salinan posisi cat sebanyak j, dimana j=SMP. Jika SPC bernilai true, maka j=(SMP − 1), kemudian, pertahankan posisi saat ini menjadi salah satu kandidat. Step2 : Untuk setiap salinan posisi cat, tambahkan atau kurangkan
SRD persen dari nilai saat ini secara acak dan ubah nilainya. Perubahan ini berdasarkan dengan CDC.
Step3 : Hitung fitness value (FS) untuk semua kandidat.
Step4 : Jika semua fitness valuetidak sama, maka dilakukan perhitungan probabilitas terpilih untuk masing-masingtitik kandidat dengan menggunakan persamaan
| |
, 0
Namun sebaliknya, jika sama maka atur probabilitas terpilih untuk semua titik menjadi 1.
dan pindahkanposisi
| |
, 0
Jika tujuan dari fungsi kecocokan adalah untuk menemukan solusi minimal maka: = .
Namun sebaliknya jika tujuan fungsi adalah menemukan solusi maksimum maka: = .
c. Tracking Mode
Tracing modemerupakankondisi yang menggambarkan keadaan ketika cat sedangmengikuti jejak targetnya. Ketika cat berada pada tracking mode,maka cat tersebut akanbergerak sesuai dengan velocities untuk tiap- tiap dimensi.Berikut merupakan tahapan pada tracking mode:
Step 1 : Perbaharuivelocities untuk setiap dimensi (vk,d) berdasarkan
persamaan berikut ini:
, , . . , ,
dimana d = 1,2,…,M
Step 2 : Periksa apakah velocities berada dalam range maksimum
velocities. Jika velocities baru tersebut melebihi
rentang,maka tetapkan nilainya menjadi nilaibatas/limit.
Step 3 : Perbaharui posisi sesuai dengan persamaan berikut ini:
, , ,
d. Core description of cat swarm optimization
Cat Swarm Optimization merupakan algoritma yang didasarkan pada perilaku kucing. Jika mengamati perilaku kucing, dapat diketahui
bahwa kucing menghabiskan sebagian besar waktunya untuk beristirahat dan mengubah posisinya secara perlahan dan berhati-hati dan kadang tepat di tempatnya. Perilaku kucing yang satu ini disebut dengan seeking mode, sedangkan perilaku kucing untuk mengejar target disebut dengan tracking mode.
Pengkombinasian kedua mode tersebut di dalam satu algoritma memerlukan pendefinisian mixture ratio (MR).MR harus bernilai kecil untuk memastikan Cat menghabiskan sebagian besar waktunya didalam seeking mode.Proses umum dalam Cat Swarm Optimization dijabarkan daam 6 langkah berikut:
Step 1 : Bangkitkan Cat sebanyak N
Step 2 : Sebarkan Cat secara acak didalam ruang yang berdimensi
D kemudian pilih nilai kecepatan secara acak yang berada didalam rentang untuk dijadikan kecepatan Cat. Pilih Cat secara acak, dan masukan Cat ke dalam tracking mode sesuai MR. Sedangkan sisanya, dimasukan kedalam seeking mode.
Step 3 : Hitung fitness value untuk masing-masing Cat dengan memasukkan nilai posisi Cat ke dalam fungsi kecocokan kemudian simpan Cat terbaik dalam memori.
Step 4 : Perlakukan sesuai dengan flag. Jika berada pada
seeking mode, maka jalankan proses seeking mode. Namun jika berada pada tracking mode, maka jalankan proses tracking mode.
Step 5 : Pilih kembali sejumlah Cat sejumlah MR untuk dimasukan kedalam tracking mode. Sedangkan sisanya, dimasukan kedalam seeking mode.
Step 6 : Perhatikan kondisi berhenti. Jika kondisi berhenti telah tercapai, maka program selesai. Namun jika kondisi berhenti belum terpenuhi, maka ulangi langkah 3 hingga langkah 5.
Berikut merupakan tahapan Cat Swarm Optimization dalam bentuk diagram proses :
2.5 Tinjauan Literatur
Tinjauan literatur meliputi tinjauan literatur kesesesuaian lahan dan tinjauan literatur NeuralNetwork&SwarmIntelligence.
2.5.1 Tinjauan Literatur Kesesuaian Lahan
Penelitian-penelitian sebelumnya mengenai penentuan kesesuaian lahan pernah dilakukan dengan menggunakan Fuzzy Logic untuk menentukan kesesuaian lahan berdasarkan faktor penghambat terbesar untuk tanaman pangan pada provinsi Jawa Timur. Pada penelitian ini, metode yang digunakan adalah Fuzzy Inference Systems (FIS). Beberapa contoh parameter yang digunakan dalam penelitian ini adalah data fuzzy seperti suhu, tekstur, drainase, dan lereng serta data non-fuzzy seperti curah hujan dan tinggi air tanah (Sevani, Marimin, & Sukoco, 2009).
Selain itu, teori himpunan fuzzy juga pernah digunakan untuk evaluasi kesesuaian lahan untuk tanaman gandum di wilayah Ziaran di provinsi Qazvin, Iran. Beberapa contoh parameter tanah yang diukur dalam penelitian ini adalah tekstur, Organic Carbon (OC), Bulkdensity (Bd), moisturecontents, watersaturationpercentage (SP), dan pH (Keshavarzi, Sarmadian, Heidari, & Omid, 2010).
Penelitian lainnya pernah dilakukan oleh Susanti & Winiarti yang membuat sistem pakar kesesuaian lahan pertanian untuk budidaya buah-buahan dengan menggunakan metode penelusuran fakta ForwardChaining yang merupakan sebuah metode yang akan mencari kesimpulan berdasarkan fakta-fakta yang ada dan kemudian akan diuji kebenaranya dalam bentuk hipotesis. Data masukan yang digunakan dalam penelitian ini adalah data
tanaman buah, fakta lahan, penyakit, serta cara penanaman (Susanti & Winiarti, 2013).
Selanjutnya pada tahun 2009, Neural Network juga pernah dipakai untuk memprediksi produksi kelapa sawit berdasarkan parameter lahan untuk menentukan kesesuaian lahan kelapa sawit. Dalam penelitian ini, digunakan Backpropagation untuk memprediksi jumlah produksi kelapa sawit dengan menggunakan input data yang berupa parameter lahan seperti curah hujan, lereng, dan keasaman tanah. Dari penelitian ini, dikatakan bahwa NeuralNetwork mempermudah dan memperinci penyajian hasil prediksi produksi kelapa sawit dan memberikan proses yang akurat, cepat dan meminimalkan kesalahan(Hermantoro & Purnawan, 2009).
Pada tahun 2010, penelitian lainnya mengenai kesesuaian lahan pernah dilakukan dengan menggunakan Back PropagationNeural Network untuk mengevaluasi kesesuaian penggunaan lahan konstruksi. Input layer yang digunakan adalah input yang berhubungan dengan opography, engineering geology, hydro-geology, dan geo-hazard yang akan ditentukan berdasarkan analisis kondisi penggunaan lahan di Hangzhou. Dalam penelitian tersebut dikatakan bahwa model Back PropagationNeural Network cocok dandapat memberikan solusi untuk masalah kesesuaian lahan di Hangzhou (Zhang, et al., 2010).
Kemudian, pada tahun 2013, dua jenis Neural Network yaitu RBF (Radial Basis Function) dan MLP (Multi-Layer Perceptron Networks), digunakan untuk forcasting kesesuaian lahan di dataran Eghlid, Iran. Dari hasil penelitian tersebut, didapat bahwa RBF dan MLP mampu memprediksi
kelas kesesuaian lahan dengan perkiraan yang baik, namun akurasi Neural Network menggunakan MLP lebih besar daripada Neural Network yang menggunakan RBF(Vali, Ramesht, & Mokarram, 2013)
2.5.2 Tinjauan Literatur Neural Network& Swarm
Intelligence
Pada tahun 2008, Neural Network pernah dibandingkan dengan metode konvensional lainnya seperti LinearReggression, dan didapat bahwa model Neural Network menghasilkan kebenaran yang lebih baik (Abdou, Pointon, & El-Masry, 2008).
Beberapa penelitian terkait Particle Swarm Algorithm telah diimplementasikan untuk menyelesaikan beberapa permasalahan dengan hasil yang lebih baik jika dibandingkan dengan algoritma optimasi lainnya. Contohnya ialah penelitian yang dilakukan untuk forecasting dalam indeks saham (Singh & Borah, 2013).
Pada tahun 2007, pernah dibandingkan antara algoritma Backpropagation (BP), algoritma Particle Swarm Optimization (PSO) dan pengabungan keduanya (BP-PSO) untuk data Iris. Dari hasil penelitian tersebut, didapatkan bahwa algoritma PSO dan BP-PSO mendapatkan hasil yang lebih baik daripada algoritma BP. Namun jika PSO dan BP-PSO dibandingkan, BP-PSO menghasilkan hasil yang lebih baik daripada PSO (Zhang, Zhang, Lok, & Lyu, 2007).
Selain itu, pada tahun 2011, penelitian Neural Network dan Particle Swarm Optimizationdilakukan untuk dataCardiotocography. Penelitian
tersebutmembandingkan antara metode Neural Network Back Propagation (NNBP) dengan Neural Network Particle Swarm Optimization (NNPSO) (Khalid, Rintyarna, & Arifin, 2011).
Pada tahun 2013, Particle Swarm Optimization diusulkan untuk digunakan untuk meningkatkan kinerja dari Neural Network. Pada penelitian tersebut digunakan data Iris. Disebutkan bahwa algoritma Particle Swarm Optimization memiliki kemampuan yang kuat untuk menemukan global optimum. Sebaliknya, algoritma Backpropagation memiliki kemampuan yang kuat untuk menemukan hasil local optimum namun lemah untuk menentukan global optimum. Dari situ, PSO diusulkan untuk digunakan untuk meningkatkan kinerja Neural Network(Dutta, Roy, & Choudhury, 2013).
Di tahun yang sama, Particle Swarm Optimization pernah diterapkan untuk memilih bobot awal pada BackpropagationNeural Network pada kasus pattern recognition untuk mendapatkan performa yang lebih baik jika dibandingkan dengan Backpropagation tanpa optimasi (Nikelshpur & Tappert, 2013). Kemudian pada tahun 2014, penelitian serupa juga dilakukan untuk memprediksi laju inflasi dengan menggunakan Particle Swarm Optimization untuk memilih bobot awal BackpropagationNeuralNetwork. (Nugraha & SN, 2014)
Selain itu, disebutkan bahwa Neural Network dapat dioptimasi dengan algoritma optimasi seperti Cat Optimization Algorithm. Neural Network menggunakan algoritma Cat swarm Optimization (CSO) pernah dilakukan menggunakan Optimal Brain Damage (OBD) pruning methods
yang dilakukan untuk mendapatkan algoritma traning yang efektif untuk artificial neural network(Yusiong, 2013). Berikut merupakan algoritma Cat swarm Optimization (CSO) yang diterapkan pada Neural Network oleh Yusiong:
1. Buatlah sebuah hidden layer feed forward neural network yang sepenuhnya terkoneksi
2. Training NN menggunakan CSO untuk mengevaluasi NN (cat) dengan menggunakan MSE sampai mendapatkan kriteria stop yang diinginkan
3. Mengaplikasikan OBD pada cat yang terbaik 4. Melakukan re-train pada pruned NN
5. Jika kriteria stop yang diinginkan belum didapatkan, kembali ke langkah 3. Sebaliknya, jika sudah didapatkan, maka jalankan langkah ke 6.
6. Output dari pruned NN yang terbaik.
Berikut merupakan detail pseudocode yang menunjukan bagaimana menggunakan CSONN-OBD:
Read dataset
Determine the Number of Hidden Neurons and Maximum Cycles Determine the Dimension of the Cat
Initialize the Cats (ANNs)
While Maximum Cycle is not reached Train ANNs
Output the Best Cat
While the termination condition is not satisfied Prune the Best Cat using OBD
Retrain the Best Cat and prune using OBD Output the Pruned ANN
Gambar 2.11Neural NetworksTraining Menggunakan CSONN-OBD (Yusiong, 2013)
Berikut merupakan rangkuman dari tinjauan literatur dalam bentuk tabel:
Tabel 2.1 TinjauanLiteratur
Publication Problem Method
Kesesuaian Lahan
(Sevani, Marimin, & Sukoco, 2009)
Menentukan kesesuaian lahan untuk tanaman pangan pada provinsi Jawa Timur
Fuzzy Logic
(Keshavarzi,
Sarmadian, Heidari, &
Evaluasi kesesuaian lahan untuk tanaman gandum di wilayah Ziaran di
Publication Problem Method
Omid, 2010) provinsi Qazvin, Iran (Susanti & Winiarti,
2013)
Sistem pakar kesesuaian lahan pertanian untuk budidaya buah-buahan
Forward Chaining
(Hermantoro & Purnawan, 2009)
Menentukan kesesuaian lahan kelapa sawit
Neural Network
(Zhang, et al., 2010) Mengevaluasi kesesuaian penggunaan lahan konstruksi
Neural Network
(Vali, Ramesht, & Mokarram, 2013)
Forcasting kesesuaian lahan di
dataran Eghlid, Iran Neural Network
Neural Network & Swarm Optimization
(Abdou, Pointon, & El-Masry, 2008)
Membandingkan Neural Network dengan teknik konvensional seperti Linear Reggression
Neural Network Versus
Conventional Techniques (Singh & Borah, 2013) Forecasting dalam indeks saham PSO
(Zhang, Zhang, Lok, & Lyu, 2007)
Perbandingan Backpropagation (BP) dan Particle Swarm Optimization (PSO) serta BP-PSO
Neural Network PSO
(Khalid, Rintyarna, & Arifin, 2011)
Perbandingan Neural Network Back Propagation (NNBP) dengan NeuralNetwork Particle Swarm Optimization (NNPSO)pada data Cardiotocography
Neural Network PSO
Publication Problem Method
(Dutta, Roy, & Choudhury, 2013)
Training Neural Network dengan Particle Swarm Optimization pada data Iris Neural Network PSO (Nikelshpur & Tappert, 2013) Perbandingan Backpropagation (BP) dan Backpropagation-Particle Swarm Optimization (BP-PSO) untuk pattern recognition
Neural Network PSO
(Nugraha & SN, 2014)
Training Neural Network dengan Particle Swarm Optimization untuk memprediksi laju inflasi
Neural Network PSO
(Yusiong, 2013)
Neural Network&Cat Optimization Algorithm pada masalah klasifikasi
Neural Network CSO
Kesesuaian Lahan Menggunakan Neural Network&Swarm Optimization
(Layona, 2015)
Optimalisasi Penentuan Kesesuaian Lahan untuk Tanaman Pangan dengan Menggunakan Neural Network dan Swarm Optimization Algorithm
Neural Network PSO