BAB II
LANDASAN TEORI
2.1 Tinjauan Pustaka
Dalam penelitian ini akan menggunakan sepuluh tinjauana studi yang nantinya dapat mendukung penelitian. Berikut ini merupakan tinjauan studi yang digunakan sebagai berikut :
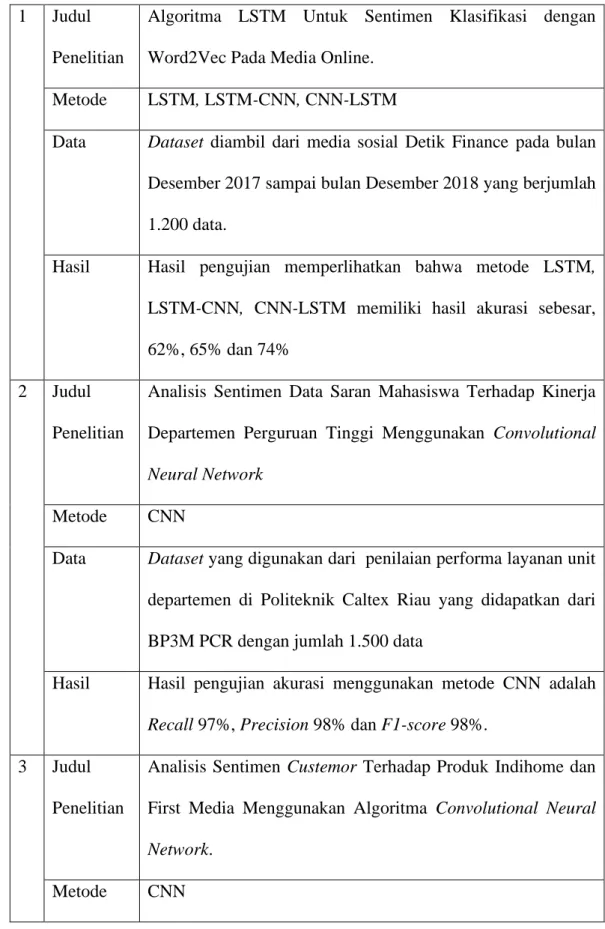
1. Dedi Tri Hermanto, Arief Setyanto, Emha Taufiq Luthfi (2021) melakukan penelitian tentang Algoritma LSTM Untuk Sentimen Klasifikasi dengan Word2Vec pada Media Online. Penelitian ini bertujuan untuk melakukan pengklasifikasian judul berita berbahasa Indonesia berdasarkan sentimen positif, negatif pada topik ekonomi dengan menggunakan metode LSTM, LSTM-CNN, CNN-LSTM.
Dataset diambil dari media sosial Detik Finance pada bulan Desember 2017 sampai bulan Desember 2018 data yang diambil adalah judul dari artikel yang ada dilaman Detik Finance berjumlah 1200 data. Data training sebesar 900 data dan data testing sebesar 300 data dengan proses pelabelan secara manual. Hasil pengujian memperlihatkan bahwa metode LSTM, LSTM-CNN, CNN-LSTM memiliki hasil akurasi sebesar, 62%, 65% dan 74%.
2. Yuliska, Dini Hidayatul Qudsi, Juanda Hakim Lubis, Khairul Umam Syaliman, Nina Fadilah Najwa (2021). Melakukan sebuah penelitian tentang Analisis Sentimen Data Saran Mahasiswa Terhadap Kinerja Departemen Perguruan Tinggi Menggunakan Convolutional Neural Network. Penelitian ini dilakukan bertujuan agar data saran mahasiswa
dapat digunakan untuk pengambilan keputusan dan perbaikan kualitas pelayanan. Data yang digunakan pada penelitian ini adalah data hasil Quality Assurance (QA) penilaian performa layanan unit kerja atau departemen di Politeknik Caltex Riau di semester genap Tahun Ajaran 2018/2019 yang didapatkan dari BP3M PCR, dengan jumlah data saran di masing-masing unit adalah mulai dari 1.470 hingga 1.500, namun hanya 1.200 data saran saja yang akan digunakan. Terdapat 7 departemen dengan proses pelabelan secara otomatis didapat 3 label yaitu positif, negatif, netral. Hasil pengujian yang telah dilakukan bahwa DoubleMax CNN dengan filter ukuran 5 memiliki hasil terbaik pada klasifikasi 2 dan tiga kelas sentimen. Pada klasifikasi dua kelas sentimen, DoubleMax CNN mendapatkan akurasi dan F1-score sebesar 98%. Pada klasifikasi 3 kelas sentimen, DoubleMax CNN mendapatkan akurasi dan F1-score sebesar 91% dan 90%. Dibandingkan dengan metode klasik machine learning seperti SVM, Logistic Regression dan Naïve Bayes, DoubleMax CNN bekerja rata-rata 17% lebih baik dalam melakukan klasifikasi sentimen data saran. Hal ini menunjukkan bahwa CNN dengan arsitektur yang lebih kompleks memiliki performa yang lebih baik dalam menganalisis sentimen data saran mahasiswa, bahkan untuk kalimat yang panjang.
3. Saleh Hasan Badjrie, Oktariani Nurul Pratiwi, Hilman Dwi Anggana (2021) meneliti tentang Analisis Sentimen Custemor Terhadap Produk Indihome dan First Media Menggunakan Algoritma Convolutional Neural Network. Penelitian ini bertujuan untuk melakukan penilaian
sebagai bentuk masukkan untuk perusahaan dapat mengevaluasi tingkat kepuasan pelanggan terhadap produk dan memperbaiki kualitas pelayanan. Jumlah data 13.689 diambil dari Twitter dengan tiga label yaitu positif, negatif, dan netral. Pada penelitian ini hasil akurasi yang dimiliki dari tiap label provider dan mencapai nilai akurasi tertinggi 98%
untuk provider IndiHome dan 91% provider First Media, dan hasil menunjukkan bahwa algoritma Convolutional Neural Network bekerja sangat dalam melakukan proses klasifikasi data.
4. Mohammad Farid Naufal, Selvia Ferdiana Kusuma (2022) melakukan penelitian Analisis Sentimen pada Media Sosial Twitter Terhadap Kebijakan Pemberlakuan Pembatasan Kegiatan Masyarakat Berbasis Deep Learning. Penelitian ini bertujuan untuk mendeteksi respon masyarakat terhadap kebijakan pemerintah dan membuat Tindakan yang diperlukan untuk menekan laju persebaran Covid-19. Dataset yang digunakan adalah data Twitter mulai tanggal 15 Agustus 2021 sampai dengan 24 September 2021. Total data yang digunakan berjumlah 37.756 tweet dengan dua label. Jumlah data yang digunakan untuk training model sebanyak 80% dari keseluruhan data, sedangkan jumlah data yang digunakan untuk testing sebanyak 20% dari keseluruhan data. Hasil penelitian ini dengan algoritma LSTM dapat digunakan untuk membentuk model klasifikasi sentimen terhadap kebijakan PPKM yang dibuat oleh pemerintah dengan akurasi 87%.
5. Faiza R Irawan, Ahmad Jazuli, Tutik Khotimah (2022) melakukan penelitian tentang Analisis Sentimen Terhadap Pengguna Gojek
menggunakan Metode K-Nearset Neighbors. Penelitian ini diharapkan mampu memberikan informasi tentang respon pengguna Gojek terhadap layanan yang sudah diberikan oleh Gojek yang dapat digunakan untuk mengevaluasi tingkat kepuasan pelanggan dan memperbaiki kualitas layanan pada Gojek. Penelitian ini mengambil data sebanyak 1409 di media sosial Twitter dengan tiga label. Hasil pengujian metode K-Nearest Neighbor menggunakan confusion matrix dengan data sebanyak 1409 mendapatkan tingkat akurasi sebesar 79,43% dengan nilai k=15.
6. Faiz Adil Khatami, Budhi Irawan, S.Si., M.T., Casi Setianingsih, S.T., M.T. (2020). Meneliti tentang Analisis Sentimen Terhadap Review Aplikasi Layanan E-Commerce menggunakan Metode Convolutional Neural Network. Penelitian ini mengklasifikasikan opini yang diberikan masyarakat, sangat baik dalam menentukan kebijakan yang diambil untuk memperbaiki layanan tersebut. Objek sentimen analisis yang diteliti adalah review tentang aplikasi Shopee yang ada di Google Play. Proses klasifikasi dapat menganalisa sentimen ke dalam tiga kategori yaitu positif, negatif, dan netral dengan akurasi yang dicapai paling tinggi sebesar 86,6%. Akurasi tersebut didapatkan dengan cara mengubah beberapa konfigurasi sistem seperti mengubah persentase partisi data, mengubah nilai learning rate, batch size, dan epoch.
7. Made Dwi Dharma Sreya, Erwin Budi Setiawan (2022). Meneliti tentang Penggunaan Metode GloVe Untuk Ekspansi Fitur pada Analisis Sentimen Twitter dengan Naïve Bayes dan Support Vector Machine. Dataset didapat dengan menggunakan API Twitter yang sudah tersedia dengan
sebanyak 16.597 tweet. Setelah data di preprocessing dan diberi label ke dalam kelas positif dan negatif. Hasil pengujian dengan Metode GloVe berhasil diimplementasikan sehingga menghasilkan 3 korpus yang digunakan saat ekspansi fitur. Sehingga Peningkatan performa terbaik diperoleh pada Top 5 similarity dengan menggunakan korpus Indonews+Tweet dengan akurasi 83.23% untuk SVM dan 77.86% untuk Naïve Bayes.
8. Erwin Yudi Hidayat, Raindy Wicaksana Hardiansyah, Affandy (2021).
Meneliti tentang Analisis Sentimen Twitter Menilai Opini Terhadap Perusahaan Publik menggunakan Algoritma Deep Neural Network.
Penelitian ini bertujuan melakukan analisis sentimen opini publik terhadap reputasi atau citra perusahaan publik yang ada di masyarakat.
Sehingga, perusahaan dapat mendapatkan umpan balik untuk menentukan langkah strategis dan kebijakan yang akan ditempuh selanjutnya.
Pengumpulan data dari Twitter dilakukan antara bulan Juni 2020 sampai November 2020 dan didapatkan 5.504 data. Data tersebut kemudian dilakukan preprocessing, selanjutnya pelabelan diselesaikan menggunakan Sentiment Strength Detection terdapat 3 label yaitu positif, negatif dan netral sehingga mendapat 3.902 data. Tahap pelatihan model dilakukan menggunakan algoritma DNN dengan variasi jumlah hidden layer, susunan node, dan nilai learning rate. Eksperimen dengan proporsi data training dan testing sebesar 90:10 memberikan hasil performa terbaik. Model tersusun dengan 3 hidden layer dengan susunan node tiap layer pada model tersebut yaitu 128, 256, 128 node dan menggunakan
learning rate sebesar 0.005, model mampu menghasilkan nilai akurasi mencapai 88.72%.
9. Ainun Rizki, Yuliant Sibaroni (2021). Melakukan penelitian Analisis Sentimen untuk Pengukuran Tingkat Depresi Pengguna Twitter menggunakan Deep Learning. Penelitian ini dilakukan untuk mengetahui analisis sentimen terhadap tingkat depresi pengguna Twitter dengan menggunakan CNN dan untuk memperoleh performansi klasifikasi model CNN terhadap tingkat depresi pengguna Twitter dengan menggunakan parameter drop out. Dataset pada penelitian ini adalah hasil dari web crawling akan dilakukan pelabelan yang dilakukan oleh beberapa mahasiswa dengan jumlah data yang didapat sebanyak 3.069 tweet.
Proses klasifikasi menggunakan 80% data training dan 20% data testing.
Sistem mengklasifikasikan teks tweet pada model CNN dengan membangun tiga skenario pengujian dengan menggunakan parameter drop out memperoleh hasil yang cukup baik. Skenario kedua merupakan model CNN terbaik dengan drop out 50% menghasilkan nilai akurasi 82.90%.
10. Sukma Nindi Listyarini, Dimas Aryo Anggoro (2021). Meneliti tentang Analisis Sentimen Pilkada Di Tengah Pandemi Covid-19 menggunakan Convolutional Neural Network. tujuan dari penelitian ini adalah mengevaluasi efektivitas metode analisis sentimen menggunakan CNN untuk mempelajari sentimen publik tentang Pilkada di tengah pandemi COVID-19. Penelitian ini menggunakan teknik pembelajaran mesin dengan menerapkan 4 layer Convolutional Neural Network untuk
mengamati dan mengklasifikasikan sentimen dari data teks yang diambil dari media sosial. Hasil penelitian menunjukkan bahwa CNN memiliki akurasi yang lebih tinggi sebesar 90% dan akurasi cenderung meningkat dibandingkan metode analisis sentimen lainnya.
11. Budi M Mulyo & Dwi H Widyantoro (2018). Melakukan penelitian tentang Aspect-Based Sentiment Analysis Approach with CNN.
Menunjukkan bagaimana pendekatan analisis sentimen berdasarkan aspek dapat diterapkan dengan menggunakan Convolutional Neural Network (CNN). Studi ini mengevaluasi efektivitas metode ini dalam mempelajari dan mengklasifikasikan sentimen pada data teks, dengan fokus pada aspek tertentu dari produk atau layanan. Hasil penelitian menunjukkan bahwa pendekatan analisis sentimen berdasarkan aspek dengan menggunakan CNN memberikan hasil yang lebih baik dibandingkan metode analisis sentimen lainnya. Karya ini memberikan kontribusi penting bagi bidang analisis sentimen dan membantu pembuat kebijakan dalam memahami opini dan sentimen publik terkait produk atau layanan.
12. Shiyang Liao, Junbo Wang, Ruiyun Yu, Koichi Sato, Zixue Cheng (2016). Meneliti tentang CNN For Situations Understanding Based On Sentiment Analysis Of Twitter Data. Bertujuan untuk memahami situasi berdasarkan analisis sentimen dari data Twitter. Penelitian ini menggunakan dua dataset yaitu MR yang terdiri dari 10.662 tweet dan STS Gold 2.034 tweet. Dataset tersebut kemudian dilakukan preprocessing dan labeling sentimen menjadi tiga kategori yaitu positif,
negatif, dan netral. CNN digunakan untuk melakukan analisis sentimen pada tweet dengan memanfaatkan representasi vektor kata menggunakan model word embedding Word2Vec. Selain itu, penelitian ini juga mengembangkan metode yang disebut dengan "situation classification"
untuk mengklasifikasikan situasi yang terkait dengan sentimen yang ada pada tweet. Hasil penelitian menunjukkan bahwa CNN berhasil mencapai akurasi klasifikasi sebesar 75%. Dengan 74,5% untuk pengembangan hasil pelatihan MR dan 68% untuk akurasi pengembangan pelatihan dataset STS Gold.
13. Nadhifa Ayu Shafirra dan Irhamah (2020). Penelitian tentang Klasifikasi Sentimen Ulasan Film Indonesia dengan Konversi Speech To Text (Stt) Menggunakan Metode Convolutional Neural Network. Dataset yang digunakan dalam penelitian ini adalah data ulasan film Indonesia yang dikumpulkan dari situs web IMDb. Metode CNN merupakan algoritma Deep Learning yang banyak digunakan dalam pengolahan data gambar dan suara. CNN digunakan untuk mengklasifikasikan sentimen dari ulasan film yang dikonversi dari suara ke teks. Hasil penelitian menunjukkan bahwa metode CNN yang digunakan dalam klasifikasi sentimen ulasan film dengan konversi STT menghasilkan akurasi sebesar 83%.
14. Mohammad Farid Naufal (2021). Meneliti tentang Analisis Perbandingan Algoritma SVM, KNN, dan CNN untuk Klasifikasi Citra Cuaca.
Penelitian ini dilakukan untuk membandingkan kinerja tiga algoritma tersebut dalam mengklasifikasikan citra cuaca menjadi empat kategori,
yaitu cerah, berawan, hujan, dan petir. Dalam analisis perbandingan algoritma SVM, KNN, dan CNN menggunakan dataset yang didapatkan dari Multi-class Weather dataset for image classification pada repositori Mendeley. Dataset ini dibagi menjadi data latih (80%) dan data uji (20%).
Selanjutnya, dilakukan ekstraksi fitur citra menggunakan metode Local Binary Pattern (LBP) dan reduksi dimensi menggunakan metode Principal Component Analysis (PCA). Hasil analisis menunjukkan bahwa algoritma CNN memiliki kinerja yang lebih baik dibandingkan dengan algoritma SVM dan KNN dalam klasifikasi citra cuaca. CNN berhasil menghasilkan akurasi sebesar 0,94. Sementara SVM dan KNN masing- masing menghasilkan akurasi sebesar 0,86 dan 0,76.
15. Fany Alifian Irawan, Dwi Anindyani Rochmah (2022). Peneliti tentang Penerapan Algoritma CNN untuk Mengetahui Sentimen Masyarakat Terhadap Kebijakan Vaksin Covid-19. Penelitian ini dilakukan bertujuan untuk mengetahui sebagian respon masyarakat Indonesia mengenai kebijakan vaksin sehingga dapat menjadi bahan pertimbangan pihak terkait dalam mengevaluasi kebijakan sehingga menjadi lebih baik. Data didapat dari media sosial diambil pada rentang waktu 2021 hingga 2022 dengan jumlah sebesar 2.148 tweet, namun setelah data dilakukan proses seleksi dan cleansing data menjadi 1.295 data. Penelitian ini menbandingkan metode CNN dengan Naive Bayes dengan hasil perbandingan yaitu algoritma CNN dengan Global Max Pooling layer mendapatkan nilai rata-rata akurasi sebesar 98.66% Sedangkan algoritma Naïve Bayes mempunyai nilai rata-rata akurasi sebesar 94.66%.
16. Putri Lannidya Parameswari, Prihandoko (2022). melakukan penelitian tentang Penggunaan Convolutional Neural Network untuk Analisis Sentimen Opini Lingkungan Hidup Kota Depok Di Twitter. Tujuan dari penelitian ini untuk melakukan analisis sentimen pada opini terkait lingkungan hidup di Kota Depok yang diambil dari platform Twitter.
Dataset diambil dari Twitter sebanyak 19.856 tweet yang diambil dari akun Twitter resmi Pemerintah Kota Depok. Setiap tweet diberi label sentimen positif, negatif, atau netral, dan kemudian dilakukan preprocessing. Setelah itu, tweet tersebut diubah menjadi matriks dengan menggunakan metode word embedding. Hasil penelitian menunjukkan bahwa metode CNN yang digunakan mampu menghasilkan akurasi sebesar 86%.
17. Hans Juwiantho, Esther Irawati Setiawan, Joan Santoso, Mauridhi Hery Purnomo (2020). Melakukan penelitian tentang Sentiment Analysis Twitter Bahasa Indonesia Berbasis Word2Vec menggunakan Deep Convolutional Neural Network. Tujuan dari penelitian untuk Perusahaan dapat secara langsung mengetahui tingkat kepuasan pelanggan dan digunakan untuk meningkatkan kualitas pelayanan hingga menaikan brand perusahaan (Gojek dan Grab). menggunakan dataset dari total 3.219 tweet yang telah didapatkan, hanya 999 tweet yang digunakan pada proses berdasarkan Bahasa Indonesia sebagai acuan. Setelah dilakukan pelabelan terhadap data ditemukan label positif 419 data, negatif 453 data, dan netral 127 data. Hasil percobaan yang telah dilakukan dengan
algoritma Deep Convolutional Neural Network memiliki nilai akurasi terbaik sebesar 76,40%.
18. Tajinder Singh, Madhu Kumar (2016) jurnal internasional. meneliti Role of Text Pre-Processing in Twitter Sentiment Analysis. Penelitian ini fokus melakukan klasifikasi sentimen pada data Twitter melalui tahapan preprocessing. Terdapat beberapan tahap preprocessing seperti case folding, tokenization, stopword removal, dan stemming pada data Twitter sebelum dilakukan analisis sentimen. Penelitian ini menggunakan dataset Twitter yang sudah dianotasikan secara manual dengan label positif, negatif, dan netral. Hasil penelitian menunjukkan bahwa tahapan preprocessing memiliki pengaruh yang signifikan pada performa analisis sentimen pada data Twitter. Dari beberapa tahap preprocessing yang dilakukan, tahap stopword removal dan stemming memberikan pengaruh paling signifikan dalam meningkatkan akurasi klasifikasi sentimen.
Penelitian ini memiliki nilai penting pada bidang analisis sentimen pada data sosial media, khususnya Twitter. Namun, penelitian ini memiliki keterbatasan pada ukuran dataset yang digunakan yang relatif kecil dan hanya terbatas pada bahasa Inggris.
19. Arvanchrist Charlie Wijaya, I Gede Arta Wibawa (2022). melakukan penelitian Deteksi Sarkasme dan Ironi pada Twitter dengan Mengunakan Metode CNN. pengambilan data dari kaggle. dataset yang digunakan dataset "Tweets with Sarcasm and Irony” yang diupload oleh Nikhil John.
Dataset terdiri atas file train.csv dan test.csv. File train.csv terdiri atas 67.997 buah data sedangkan file test.csv terdiri atas 7.994 buah data. Hasil
penelitian ini ditemukan bahwa metode Convolutional Neural Network dapat digunakan dalam pemrosesan bahasa alami yakni dalam hal deteksi sarkasme. Dari hasil latih model didapatkan akurasi 73,8% untuk data latih dan 74,6% untuk data validasi.
20. Erlyna Nour Arrofiqoh, Harintaka (2018). Melakukan penelitian Implementasi Metode Convolutional Neural Network Untuk Klasifikasi Tanaman pada Citra Resolusi Tinggi. Tujuan penelitian ini adalah untuk melakukan klasifikasi tanaman pada citra resolusi tinggi. Penelitian ini sangat menarik karena memberikan kontribusi pada bidang pertanian dan teknologi pengolahan citra. Dalam penelitian ini, data yang digunakan menggunakan foto udara hasil perekaman dengan menggunakan teknologi UAV dengan jenis kamera Canon PowerShot S100. Data diambil dari satu scene citra RGB dengan koreksi geometrik 4,64 mm seluas 311 ha dan resolusi spasial 6,5 cm. Lokasi penelitian berada di daerah Kretek, Daerah Istimewa Yogyakarta. Data meliputi foto dari 5 jenis tanaman berbeda. Data tersebut dibagi menjadi dua bagian yaitu data pelatihan dan data pengujian. CNN dilatih dengan berbagai variasi parameter seperti jumlah layer, ukuran filter, dan jumlah filter. Hasil penelitian menunjukkan bahwa CNN mampu menghasilkan akurasi klasifikasi yang tinggi dengan akurasi sebesar 93% pada data pelatihan dan 82% pada data pengujian. Selain itu, penelitian juga menunjukkan bahwa penambahan layer pada CNN dapat meningkatkan performa klasifikasi, dan menggunakan filter berukuran 5x5 dapat menghasilkan akurasi yang lebih tinggi daripada menggunakan filter berukuran 3x3.
Tabel 2. 1 Ringkasan Tinjauan Pustaka 1 Judul
Penelitian
Algoritma LSTM Untuk Sentimen Klasifikasi dengan Word2Vec Pada Media Online.
Metode LSTM, LSTM-CNN, CNN-LSTM
Data Dataset diambil dari media sosial Detik Finance pada bulan Desember 2017 sampai bulan Desember 2018 yang berjumlah 1.200 data.
Hasil Hasil pengujian memperlihatkan bahwa metode LSTM, LSTM-CNN, CNN-LSTM memiliki hasil akurasi sebesar, 62%, 65% dan 74%
2 Judul Penelitian
Analisis Sentimen Data Saran Mahasiswa Terhadap Kinerja Departemen Perguruan Tinggi Menggunakan Convolutional Neural Network
Metode CNN
Data Dataset yang digunakan dari penilaian performa layanan unit departemen di Politeknik Caltex Riau yang didapatkan dari BP3M PCR dengan jumlah 1.500 data
Hasil Hasil pengujian akurasi menggunakan metode CNN adalah Recall 97%, Precision 98% dan F1-score 98%.
3 Judul Penelitian
Analisis Sentimen Custemor Terhadap Produk Indihome dan First Media Menggunakan Algoritma Convolutional Neural Network.
Metode CNN
Data Jumlah data 13.689 diambil dari Twitter dengan tiga label yaitu positif, negatif, dan netral.
Hasil Hasil akurasi yang didapatkan, memperoleh akurasi tertinggi sebesar 98% untuk provider IndiHome dan 91% untuk provider First Media.
4 Judul Penelitian
Analisis Sentimen Pada Media Sosial Twitter Terhadap Kebijakan Pemberlakuan Pembatasan Kegiatan Masyarakat Berbasis Deep Learning.
Metode LSTM
Data data Twitter mulai tanggal 15 Agustus 2021 sampai dengan 24 September 2021 dengan data berjumlah 37.756 tweet
Hasil Hasil penelitian ini dengan algoritma LSTM memperoleh akurasi 87%.
5 Judul Penelitian
Analisis Sentimen Terhadap Pengguna Gojek Menggunakan Metode K-Nearset Neighbors.
Metode KNN
Data Dataset diambil dari Twitter berjumlah 1.409 tweet
Hasil Hasil pengujian metode KNN menggunakan confusion matrix mendapatkan tingkat akurasi sebesar 79,43% dengan nilai k=15.
6 Judul Penelitian
Analisis Sentimen Terhadap Review Aplikasi Layanan E- Commerce Menggunakan Metode Convolutional Neural Network
Metode CNN
Data Objek sentimen analisis yang diteliti tentang aplikasi Shopee yang ada di Google Play
Hasil Hasil menganalisa sentimen kedalam tiga kategori yaitu positif, negatif, dan netral dengan akurasi yang dicapai paling tinggi sebesar 86,6%.
7 Judul Penelitian
Penggunaan Metode GloVe untuk Ekspansi Fitur pada Analisis Sentimen Twitter dengan Naïve Bayes dan Support Vector Machine
Metode SVM, Naïve Bayes
Data Dataset didapat dengan menggunakan API Twitter yang sudah tersedia dengan sebanyak 16.597 tweet
Hasil Hasil pengujian dengan Metode GloVe berhasil diimplementasikan sehingga menghasilkan 3 korpus yang digunakan saat ekspansi fitur. Sehingga Peningkatan performa terbaik diperoleh pada Top 5 similarity dengan menggunakan korpus Indonews+Tweet dengan akurasi 83.23% untuk SVM dan 77.86% untuk Naïve Bayes.
8 Judul Penelitian
Analisis Sentimen Twitter Menilai Opini Terhadap Perusahaan Publik Menggunakan Algoritma Deep Neural Network.
Metode DNN
Data Dataset diambil dari Twitter dengan jumlah 5.504 tweet Hasil Model tersusun dengan 3 hidden layer dengan susunan node
tiap layer pada model tersebut yaitu 128, 256, 128 node dan
menggunakan learning rate sebesar 0.005, model mampu menghasilkan nilai akurasi mencapai 88.72%.
9 Judul Penelitian
Analisis Sentimen untuk Pengukuran Tingkat Depresi Pengguna Twitter Menggunakan Deep Learning
Metode CNN
Data Dataset diambil dari Twitter dengan jumlah 3.069 tweet Hasil Hasil pengujian menggunakan metode CNN memperoleh nilai
akurasi 82.90%
10 Judul Penelitian
Analisis Sentimen Pilkada Di Tengah Pandemi Covid-19 Menggunakan Convolutional Neural Network
Metode CNN
Data 500 tweet diperoleh dari Twitter API menggunakan library tweepy, lalu diberi label ke dalam dua kelas
Hasil Hasil dari penelitian menunjukkan bahwa, metode CNN dengan dataset pilkada ditengah pandemi mendapatkan akurasi tertinggi sebesar 90% dengan4 layer convolutional dan 100 epoch. Didapatkan pula bahwa, semakin banyak epoch yang digunakan dalam model, akurasi cenderung meningkat 11 Judul
Penelitian
Aspect-Based Sentiment Analysis Approach with CNN
Metode CNN
Data -
Hasil Hasil dari penelitian menunjukan bawah metode CNN menghasilkan akurasi sebesar 80%.
12 Judul Penelitian
CNN For Situations Understanding Based On Sentiment Analysis Of Twitter Data.
Metode CNN
Data Terdapat dua dataset diambil dari Twitter yaitu MR yang terdiri dari 10662 tweet dan STS Gold 2034 tweet
Hasil Hasil penelitian menunjukkan bahwa CNN berhasil mencapai akurasi klasifikasi sebesar 75%. Dengan 74,5% untuk pengembangan hasil pelatihan MR dan 68% untuk akurasi pengembangan pelatihan dataset STS Gold.
13 Judul Penelitian
Klasifikasi Sentimen Ulasan Film Indonesia dengan Konversi Speech to Text (Stt) Menggunakan Metode Convolutional Neural Network
Metode CNN
Data Data dikumpulkan dari web IMDb, dataset berupa suara Hasil Hasil penelitian menunjukkan bahwa metode CNN yang
digunakan dalam klasifikasi sentimen ulasan film dengan konversi STT menghasilkan akurasi sebesar 83%.
14 Judul Penelitian
Analisis Perbandingan Algoritma SVM, KNN, dan CNN untuk Klasifikasi Citra Cuaca
Metode SVM, KNN, dan CNN
Data dataset yang didapatkan dari Multi-class Weather dataset for image classification pada repositori Mendeley.
Hasil Hasil penelitian menunjukan bahwa metode CNN lebih baik dalam mengenali pola data citra. CNN berhasil menghasilkan
akurasi sebesar 0,94. Sementara SVM dan KNN masing- masing menghasilkan akurasi sebesar 0,86 dan 0,76.
15 Judul Penelitian
Penerapan Algoritma CNN untuk Mengetahui Sentimen Masyarakat Terhadap Kebijakan Vaksin Covid-19
Metode CNN dan Naïve Bayes
Data Data didapat dari Twitter dengan jumlah 2.148 tweet
Hasil Penelitian ini membandingkan metode CNN dengan nilai rata- rata akurasi sebesar 98,66%. Sedangkan metode Naïve Bayes dengan nilai akurasi sebesar 94,66%
16 Judul Penelitian
Penggunaan Convolutional Neural Network untuk Analisis Sentimen Opini Lingkungan Hidup Kota Depok Di Twitter Metode CNN
Data Dataset diambil dari Twitter sebanyak 19.856 tweet
Hasil Hasil penelitian menunjukkan bahwa metode CNN yang digunakan mampu menghasilkan akurasi sebesar 86%.
17 Judul Penelitian
Sentiment Analysis Twitter Bahasa Indonesia Berbasis Word2Vec Menggunakan Deep Convolutional Neural Network
Metode Naïve Bayes, SVM, dan CNN
Data Data yang dikumpulkan dari Twitter sebanyak 3.219 tweet, lalu dilakukan proses preprocessing sehingga menghasilkan 999 tweet yang bisa dipakai karena terdapat banyak tweet tidak pakai Bahasa Indonesia.
Hasil Setelah proses preprocessing dan pelabelan, ditemukan label positif 419 data, negatif 453 data, dan netral 127 data. Hasil percobaan yang telah dilakukan dengan metode CNN memiliki nilai akurasi terbaik sebesar 76,40%.
18 Judul Penelitian
Role of Text Pre-Processing in Twitter Sentiment Analysis.
Metode - Data Twitter
Hasil Hasil penelitian menunjukkan bahwa tahapan preprocessing memiliki pengaruh yang signifikan dalam meningkatkan akurasi pada performa analisis sentimen pada data Twitter 19 Judul
Penelitian
Deteksi Sarkasme dan Ironi pada Twitter dengan Mengunakan Metode CNN
Metode CNN
Data pengambilan data dari Kaggle. dataset yang digunakan dataset
"Tweets with Sarcasm and Irony” yang diupload oleh Nikhil John
Hasil Hasil penelitian ini menggunakan metode CNN didapatkan akurasi 73,8% untuk data latih dan 74,6% untuk data validasi.
20 Judul Penelitian
Implementasi Metode Convolutional Neural Network Untuk Klasifikasi Tanaman Pada Citra Resolusi Tinggi
Metode CNN
Data Data diambil dari satu scene citra RGB dengan koreksi geometrik 4,64 mm seluas 311 ha dan resolusi spasial 6,5 cm
Hasil Proses learning jaringan menghasilkan akurasi 100% terhadap data training. Pengujian terhadap data validasi menghasilkan akurasi 93% dan akurasi terhadap data tes 82%.
Berdasarkan hasil literatur yang ada, penulis mengambil kesimpulan yaitu:
1. Preprocessing memiliki peran sangat penting dalam klasifikasi data berupa teks sebelum ke model.
2. CNN dapat mengklasifikasi data berupa gambar, teks, dan audio.
3. CNN dapat menghasilkan akurasi cukup baik dengan jumlah data yang besar.
4. CNN menunjukkan bekerja sangat dalam melakukan proses klasifikasi data berupa teks.
5. Parameter pada model CNN dengan drop out dapat mempengaruhi akurasi dan Loss, selain itu dapat mencegah terjadinya overfitting.
2.2 Twitter
Twitter adalah sebuah media sosial dan layanan microblogging yang mengizinkan penggunanya untuk mengirimkan pesan realtime. Pesan yang berupa teks, gambar dan video ini populer dengan sebutan tweet. Twitter memberikan akses kepada penggunanya untuk mengirimkan pesan singkat (tweet) dengan maksimal 140 karakter menjadi 280 karakter (Irawan, Jazuli and Khotimah, 2022).
Dikarenakan keterbatasan jumlah karakter yang dapat ditulis, tweet sering mengandung singkatan, bahasa gaul atau kesalahan tata Bahasa (Hasan Badjrie, Pratiwi and Anggana, 2021).
2.3 Analisis Sentimen
Analisis sentimen adalah proses menganalisis teks dari berbagai sumber data dengan tujuan untuk memperoleh informasi emosional pada suatu kalimat opini (Agsar Dwi Anggoro et al., 2021). Informasi yang dikumpulkan dapat berupa pendapat umum tentang produk, layanan, kebijakan, dan lainnya. Analisis sentimen adalah cabang dari text mining yang bertujuan untuk menganalisis, memahami, mengolah dan mengekstrak data tekstual berupa opini yang menganalisis pendapat, penilaian, evaluasi, sikap, dan perasaan orang tentang objek seperti produk, layanan, organisasi, individu, topik, peristiwa, topik tertentu (Khatami et al., 2020).
Setelah itu akan dilakukan evaluasi terhadap opini tersebut, yaitu positif, netral, dan negatif.
2.4 Preprocessing
Text Preprocessing merupakan proses pengolahan teks yang bertujuan untuk mengurangi noise pada dataset serta mengubah dataset menjadi bentuk yang lebih terstuktur(Hidayat, Hardiansyah and Affandy, 2021). Preprocessing merupakan salah satu langkah penting dalam analisis sentimen. Maka dari itu perlu proses Preprocessing untuk menseleksi data yang berguna untuk mengoptimalkan data agar dapat diproses dan mendapatkan hasil yang lebih baik dalam meningkatkan kinerja klasifikasi (Listyarini and Anggoro, 2021). Pemrosesan data mencakup 6 tahapan sebagai berikut :
1. Cleansing
Cleansing membersihkan data tweet yang bertujuan untuk menghapus simbol, username, angka, kata ‘RT’, hashtag (#), Uniform Resource Locator (URL), emoji, dan ruang kosong atau white space.
2. Case folding
Case Folding adalah proses merubah setiap katakter huruf pada seluruh data tweet menjadi huruf kecil atau non-kapital. Hanya huruf "a" sampai "z" saja yang diterima, selain itu kata akan hilang.
3. Tokenizing
Tokenizing adalah Proses pemecahan sebuah string data menjadi token.
Token adalah memisahkan kalimat yang ada pada dataset menjadi sebuah kata. Proses ini memanfaatkan fungsi dari pustaka Natural Language Toolkit (NLTK). Proses tokenisasi bisa dilakukan berdasarkan adanya spasi di sebuah kalimat, bisa juga dilakukan berdasarkan parameter tertentu (Parameswari and Prihandoko, 2022).
4. Stopword removal
Stopword removal adalah proses menghilangkan kata yang tidak merepresentasikan data. pada proses ini kata yang tidak memiliki makna penting untuk melakukan klasifikasi akan dihilangkan (Rizki and Sibaroni, 2021).
5. Stemming
Stemming adalah proses yang dilakukan untuk menghapus kata imbuhan atau mengubah kata ke bentuk dasar. Proses ini memanfaatkan pustaka Sastrawi menggunakan library nltk dengan fungsi StemmerFactory() (Parameswari and Prihandoko, 2022).
Selain melakukan pembersihan data maka dilakukan balancing dataset.
Salah satu masalah umum yang ditemukan dalam kumpulan data untuk klasifikasi adalah persebaran data yang tidak seimbang. Persebaran data yang tidak seimbang
dapat menyebabkan kurang tepatnya model yang dibuat pada saat training data serta algoritma klasifikasi memiliki kinerja yang buruk (Sonak and Patankar, 2015).
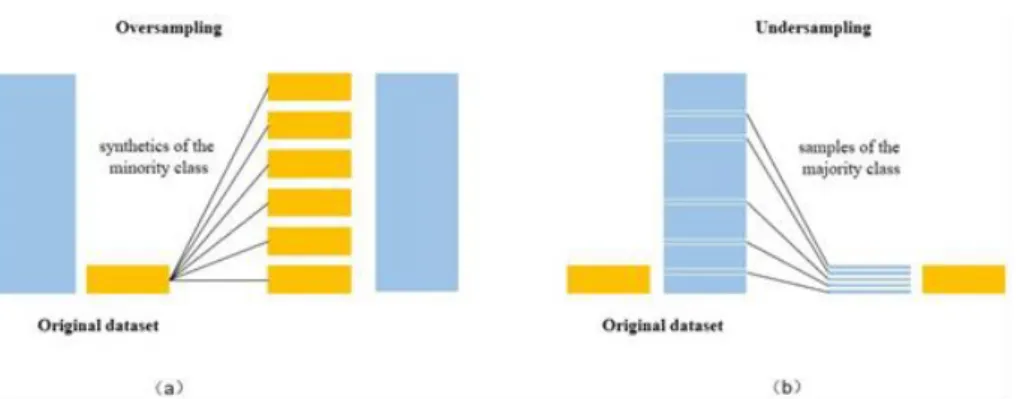
Untuk menangani masalah ketidakseimbangan data dapat dilakukan dengan teknik resampling seperti oversampling dan undersampling (Ganganwar, 2012) seperti yang disajikan pada gambar 2.1.
1. Oversampling
Oversampling adalah teknik pengambilan sampel yang menyeimbangkan kumpulan data dengan mereplikasi kelas minoritas. Keuntungan dari metode ini adalah tidak ada kehilangan data sedangkan kerugian dari teknik ini dapat menyebabkan pemasangan yang berlebihan dan dapat menyebabkan overhead komputasi tambahan.
2. Undersampling
Metode undersampling dilakukan menggunakan subset dari kelas mayoritas untuk melatih classifier dengan menghapus kelas mayoritas.
Gambar 2.1 Ilustrasi (a) Oversampling dan (b) Undersampling Sumber : (Xia et al., 2019)
2.5 Deep Learning
Deep Learning adalah sebuah penerapan jaringan syaraf tiruan yang meniru cara kerja dari kortex manusia yang memiliki banyak layer tersembunyi (hidden layer) dan termasuk kedalam kajian dari Machine Learning di dalam bidang
kecerdasan buatan. Dalam implementasinya pada permasalahan dataset yang besar Deep Learning memberikan ketepatan pada berbagai penelitian seperti deteksi suatu objek, pengenalan suara, terjemahan bahasa, dan lain-lain. Berbeda dengan teknik pada machine learning yang masih tradisional harus mengenali masukan terlebih dahulu (LeCun, Bengio and Hinton, 2015), Deep Learning mampu menganalisa jutaan kemungkinan berdasarkan data latih sebelumnya dan dilakukan dalam waktu singkat. Deep Learning di klaim mampu beradaptasi dengan data dalam jumlah besar serta mampu menyelesaikan masalah yang sulit diselesaikan oleh machine learning lainnya. Sistem Deep Learning juga dapat mempelajari dari fungsi pemetaan yang kompleks dari mulai input hingga output tanpa konsep dari buatan manusia. Deep Learning memiliki beberapa jenis algoritma diantaranya Convolutional Neural Network, Recurrent Neural Network, Long Short TermMemory, dan Self Organizing Map.
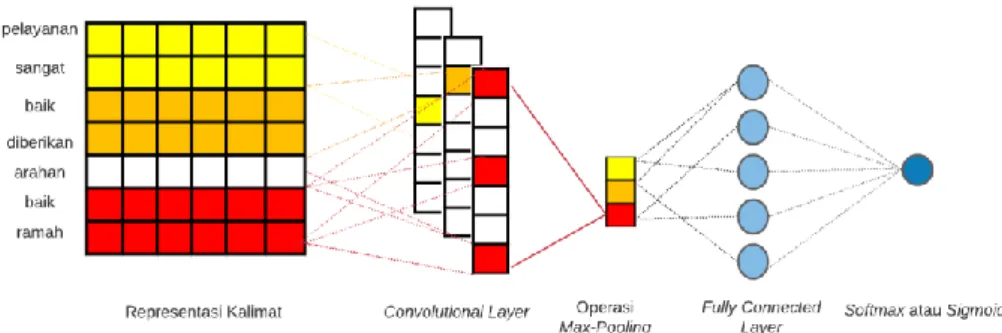
2.6 Convolutional Neural Network
Convolutional Neural Network adalah salah satu metode algoritma Deep Learning. CNN juga didefinisikan sebagai algoritma yang biasa digunakan untuk pemproses data gambar dan teks (Hasan Badjrie, Pratiwi and Anggana, 2021).
Konvolusi didefinisikan sebagai matriks yang berfungsi melakukan klasifikasi dan filter untuk gambar dan teks. Tujuan utama dari konvolusi adalah untuk mengekstrak fitur input, dan pooling adalah untuk mengambil sampel matriks konvolusi (Khatami et al., 2020). Convolutional Neural Network memiliki beberapa layer yang digunakan untuk melakukan filter dalam setiap proses. Proses ini dikenal sebagai proses training. Pada proses training terdapat 3 tahapan yaitu Convolutional layer, Pooling layer, dan Fully connected layer (Hasan Badjrie,
Pratiwi and Anggana, 2021). Arsitektur proses training Convolutional Neural Netwok dapat di lihat pada gambar 2.2.
Sumber: (Hidayatul Qudsi et al., 2019) 2.7 Word2Vec
Word2Vec adalah salah satu metode embedding word yang berguna untuk merepresentasikan kata menjadi sebuah vector (Hidayatul Qudsi et al., 2019).
Word2Vec dapat memiliki 50 sampai dengan 300 dimensi. Word2Vec mulai ramai digunakan dalam bidang natural language processing di tahun 2013, karena Word2Vec merupakan dense vectors yang dapat merepresentasikan hubungan antar kata dengan lebih baik (dibandingkan dengan TF-IDF), secara semantik maupun sintaksis (Hidayatul Qudsi et al., 2019). Word2Vec memiliki dua model arsitektur yaitu Skip-Gram dan Continous Bag of Words (CBOW) (Mikolov, Yih and Zweig, 2013). Kedua metode ini menggunakan konsep jaringan saraf tiruan yang memetakan kata ke variabel target yang merupakan sebuah kata. Tujuan dalam arsitektur skip-gram adalah untuk memprediksi kata yang ada di sekitar current word. Sedangkan arsitektur CBOW digunakan untuk memprediksi kata yang ada pada sekitar kata tersebut.
Gambar 2.2 Arsitektur Convolutional Neural Network
2.8 Confussion Matrix
Confusion Matrix adalah ringkasan hasil prediksi pada masalah klasifikasi.
Jumlah prediksi yang benar dan salah dirangkum dengan nilai hitungan hasil akurasi pada konsep data mining dan dipecah oleh masing – masing kelas. Terdapat empat istilah dari hasil klasifikasi dalam I, antara lain:
1. TP (True Positive) merupakan data yang bersifat positif dan terdeteksi benar.
2. TN (True Negative) merupakan data yang bersifat negatif dan terdeteksi benar.
3. FP (False Positive) merupakan data yang bersifat negatif namun terdeteksi sebagai data positif.
4. FN (False Negative) merupakan data yang bersifat positif namun terdeteksi sebagai data negatif.
Confusion Matrix juga berguna untuk menilai bagaimana kinerja suatu model dibangun. Hasil klasifikasi tidak dapat dilihat hanya dengan satu angka, sehingga keempat istilah TP, FP, TN, dan FN sama pentingnya dalam memberikan informasi dari temuan. Secara umum, perhitungan yang biasa digunakan dalam confusion matrix meliputi precision, recall, F1-score dan accurary.
Precision adalah perhitungan untuk menghasilkan tingkat akurasi antara data yang diminta dengan hasil prediksi sistem. oleh karena itu, precision membandingkan prediksi data benar positif dengan hasil prediksi positif keseluruhan. Dapat dilihat pada persamaan berikut:
Precision = TP
FP+TP (2.1)
Recall merupakan tingkat dari keberhasilan suatu sistem dalam menemukan sebuah informasi kembali yang dapat dilihat dari persamaan berikut :
Recall = TP
TP+FN (2.2)
F1-score adalah perbandingan berbobot dari rata-rata presisi dan recall. F1- score dihitung sebagai berikut:
F1 = 2𝑋𝑝𝑟𝑒𝑐𝑖𝑠𝑠𝑖𝑜𝑛 𝑥 𝑟𝑒𝑐𝑎𝑙𝑙
𝑝𝑟𝑒𝑐𝑖𝑠𝑠𝑖𝑜𝑛+𝑟𝑒𝑐𝑎𝑙𝑙 (2.3)
Accuracy adalah rasio prediksi yang benar (positif dan negatif) terhadap keseluruhan data. Accuracy dapat dihitung sebagai berikut
Accuracy = 100 𝑋 𝑇otal Klasifikasi Benar
Total Klasifikasi (2.4)