Penulis mengucapkan terima kasih kepada semua pihak yang telah membantu hingga terselesaikannya buku ini. Karena bersifat lintas platform, pengguna yang menggunakan sistem operasi (OS) Linux, Mac, dan Windows dapat bekerja sama.
Kode R pada Gambar 2.6 baris 2 dapat diartikan sebagai mempresentasikan atau menampilkan nilai data yang disimpan pada variabel penyimpanan. Pada Gambar 2.8, keluaran eksekusi kode R pada Gambar 2.6 dapat berformat HTML, PDF, dan MS Word.

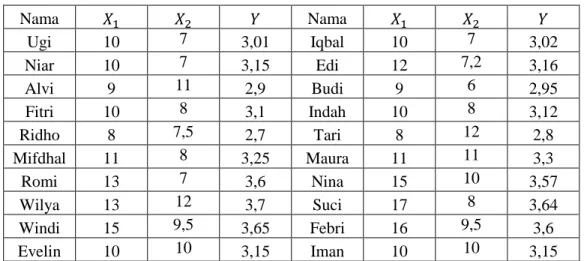
Pada Gambar 3.6, kode R pada baris keenam yaitu Pendapatan=tabungan$pendapatan berarti variabel Pendapatan ditugaskan untuk menyimpan data tentang variabel pendapatan, pada variabel tabungan. Dari data Gambar 3.48 diketahui 90 responden laki-laki mempunyai hobi olah raga, 10 responden laki-laki mempunyai hobi memasak dan sebagainya. 65 Berdasarkan data pada Tabel 4.1, berikut ini akan dihitung jumlah nilai (jumlah), mean aritmatika, modus dan median.
Pada Gambar 4.1 (1) kurvanya miring ke kanan atau disebut kurva positif dan pada Gambar 4.1 (2) kurvanya simetris. Di bawah ini adalah kode R (Gambar 4.6) untuk memperoleh hasil perhitungan ukuran pusat gejala, lokasi, penyebaran, kemiringan dan ketajaman berdasarkan data pada Tabel 4.1 (data1 lihat Gambar 4.5), Tabel 4.3 (data2 lihat Gambar 4.5 ) dan Tabel 4.9 (data3, lihat Gambar 4.5).
Rata-rata distribusi sampling 𝑋̅ (rata-rata distribusi sampling 𝑋̅) atau rata-rata 𝑋̅ dilambangkan dengan 𝜇𝑋̅. Setelah diubah menjadi numerik, nilai mean dapat dihitung dari distribusi sampling mean sampel (kode R pada baris 11). Simpangan baku distribusi sampel mean 𝑋̅ dilambangkan dengan simbol 𝜎𝑋̅, sedangkan simpangan baku populasi dilambangkan dengan simbol 𝜎.
Pada pembahasan sebelumnya diketahui bahwa mean distribusi sampling 𝑋̅ sama dengan mean populasi 𝜇, yaitu. Namun simpangan baku distribusi sampel, mean 𝑋̅ tidak sama dengan simpangan baku populasi (kecuali 𝑛 = 1). Nilai simpangan baku mean distribusi sampel 𝑋̅ lebih kecil dari nilai simpangan baku populasi, yaitu 𝜎𝑋̅ < 𝜎 apabila 𝑛 lebih besar dari 1.
Nilai simpangan baku distribusi mean sampling 𝑋̅ akan semakin kecil seiring dengan semakin besarnya ukuran sampel 𝑛. Perhatikan bahwa semakin besar ukuran sampel, semakin kecil nilai deviasi standar mean distribusi sampling 𝑋̅. Semakin besar ukuran sampel maka bentuk distribusi mean sampling (𝑋̅) akan semakin mendekati normal.
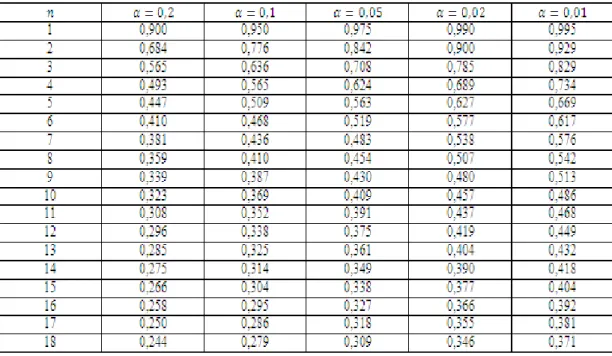
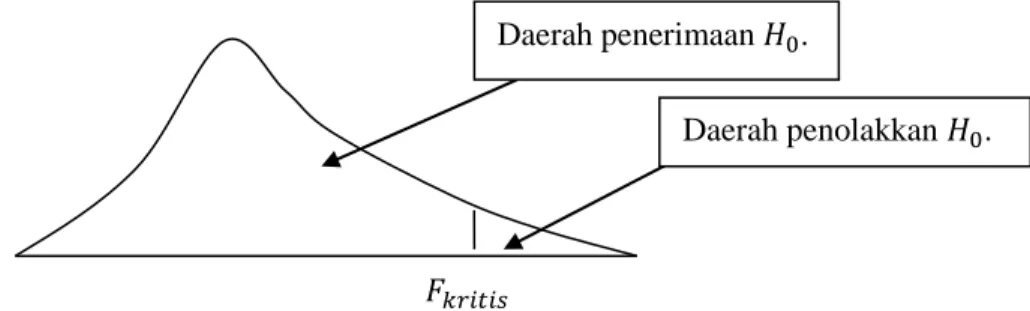
Di bawah ini akan digunakan pendekatan uji Kolmogorov-Smirnov untuk menguji hipotesis apakah data diambil dari populasi yang berdistribusi normal atau tidak (misalnya tingkat signifikansi yang digunakan adalah 𝛼 = 5%). Nilai kritis Kolmogorov-Smirnov pada taraf signifikansi 5% dan jumlah elemen sampel sebanyak 16 berdasarkan tabel distribusi Kolmogorov-Smirnov adalah sebesar 0,327. Perlu diketahui bahwa karena nilai statistik uji Kolmogorov-Smirnov (0,125) lebih kecil dari nilai kritis Kolmogorov-Smirnov (0,327), maka hipotesis nol diterima dan hipotesis alternatif ditolak, sehingga asumsi tentang data hasil Tes matematika kelas 6 SD diambil dari populasi yang berdistribusi normal, dapat diterima pada tingkat signifikansi 5%.
Data pertama kali dibuat di Microsoft Excel (Gambar 6.1) dan disimpan dalam format tipe .csv (Gambar 6.2 dan Gambar 6.3). Pada Gambar 6.6 terlihat nilai statistik uji Kolmogorov-Smirnov (D) sebesar 0,125 lebih kecil dari nilai kritis Kolmogorov-Smirnov sebesar 0,327 maka hipotesis nol diterima dan hipotesis alternatif ditolak sehingga asumsinya mengenai data nilai ujian matematika SD kelas 6 diambil dari populasi yang berdistribusi normal, dapat diterima pada taraf signifikansi 5%. Pengambilan keputusan mengenai hipotesis dapat dilakukan dengan membandingkan nilai statistik uji Jarque-Bera dengan nilai kritis chi-square 𝜒𝑘𝑟𝑖𝑡𝑖𝑠2.
Statistik uji Jarque-Bera mempunyai distribusi sampling chi-kuadrat dengan derajat kebebasan 2 untuk ukuran sampel besar. Karena nilai statistik uji Jarque-Bera yaitu 0,308 lebih kecil dari nilai kritis chi-square yaitu 5,991 maka hipotesis nol diterima dan hipotesis alternatif ditolak, sehingga asumsi tentang ujian matematika kelas 6 SD. Data hasil yang diambil dari populasi yang berdistribusi normal dapat diterima pada tingkat signifikansi 5%. Berdasarkan Gambar 6.11 titik-titik menyebar cukup dekat dengan garis diagonal sehingga asumsi normalitas terpenuhi.
Di bawah ini akan digunakan pendekatan uji Levene untuk menguji apakah asumsi populasi 𝑋, 𝑌 dan 𝑍 mempunyai varian yang sama (secara statistik) dapat diterima atau tidak, pada tingkat signifikansi 5%. Diketahui taraf signifikansi yang digunakan adalah 5%, sehingga nilai kritis 𝐹 dengan derajat kebebasan pada pembilang, derajat kebebasan pada penyebut, dan taraf signifikansi 5% adalah sebesar 3,68. Perlu diketahui bahwa karena nilai statistik uji Levene yaitu 0,649 lebih kecil dari nilai kritis 𝐹 yaitu 3,68, maka hipotesis nol diterima dan hipotesis alternatif ditolak. Oleh karena itu, asumsinya adalah bahwa sampel 𝑋, 𝑌 dan 𝑍 berasal dari populasi dengan varians populasi yang sama, dapat diterima pada tingkat signifikansi 5%.
Data pertama kali dibuat di Microsoft Excel (Gambar 7.5) dan disimpan dalam format .csv (Gambar 7.6). Namun nilai statistik uji Levene dengan pendekatan Location=”mean” adalah 0,649, sama dengan hasil SPSS. Diketahui juga bahwa dari Gambar 7.10 nilai probabilitas (p-value) sebesar 0,5366 lebih besar dari taraf signifikansi 0,05 maka hipotesis nol diterima dan hipotesis alternatif ditolak, sehingga asumsi sampelnya adalah 𝑋, 𝑌 dan 𝑍 berasal dari populasi. populasi yang mempunyai varian populasi yang sama, dapat diterima pada tingkat signifikansi 5%.
Di bawah ini, kita akan menggunakan pendekatan uji Levene untuk menguji apakah asumsi populasi 𝑋, 𝑌, dan 𝑍 mempunyai varians yang sama, dapat diterima atau tidak, pada tingkat signifikansi 5%. Perlu diketahui bahwa karena statistik uji Levene yaitu 0 lebih kecil dari nilai kritis 𝐹 sebesar 4,747 maka hipotesis nol diterima dan hipotesis alternatif ditolak, sehingga asumsinya sampel 𝑋 dan sampel 𝑌 berasal dari populasi yang memiliki populasi yang sama. varians populasi dapat diterima pada tingkat signifikansi 5%. Diketahui juga bahwa berdasarkan Gambar 7.14, nilai probabilitas (p-value) adalah 1 lebih besar dari tingkat signifikansi 0,05, maka hipotesis nol diterima dan hipotesis alternatif ditolak, sehingga asumsinya adalah sampel 𝑋 dan sampel 𝑌 berasal dari populasi yang mempunyai varians populasi yang sama dan dapat diterima pada tingkat signifikansi 5%.
Data pertama kali dibuat di Microsoft Excel (Gambar 8.1) dan disimpan dalam format tipe .csv (Gambar 8.2). Berdasarkan Gambar 8.8 diketahui bahwa titik-titik yang letaknya sangat dekat pada garis diagonal, disimpulkan bahwa asumsi normalitas data dari selisih berpasangan pengamatan terpenuhi. Diketahui juga bahwa berdasarkan Gambar 8.9, nilai probabilitas (p-value) uji Kolmogorov-Smirnov sebesar 0,6544, sedangkan berdasarkan Gambar 8.10, nilai probabilitas (p-value) uji Jarque-Bera sebesar 0,4982.
Data pertama kali dibuat di Microsoft Excel (Gambar 9.5) dan disimpan dalam format .csv (Gambar 9.6). Gambar 9.10 menyajikan kode R untuk menguji asumsi bahwa sampel 𝑋 dan sampel 𝑌 diambil dari populasi yang berdistribusi normal. 153 Diketahui berdasarkan Gambar 9.12, nilai probabilitas uji Kolmogorov-Smirn untuk sampel 𝑋 (p-value) adalah 0,9469, sedangkan untuk sampel 𝑌 adalah 0,356.
Berdasarkan Gambar 9.14, nilai probabilitas uji Jarque-Bera untuk sampel 𝑋 (p-value) sebesar 0,6284, sedangkan untuk sampel sebesar 0,5552. Data pertama kali dibuat di Microsoft Excel (Gambar 9.15) dan disimpan dalam format tipe .csv (Gambar 9.16). Diketahui pula berdasarkan Gambar 9.20 nilai probabilitas (p-value) sebesar 0,438 lebih besar dari taraf signifikansi 0,05 maka hipotesis nol diterima dan hipotesis alternatif ditolak sehingga asumsi populasi 𝑋 dan populasi 𝑌 mempunyai varian yang sama dapat diterima pada taraf signifikansi 5%.
Untuk mengambil keputusan suatu hipotesis, nilai probabilitas dari uji Kolmogorov-Smirnov atau uji Jarque-Bera dapat dibandingkan dengan tingkat signifikansi yang diterapkan (𝛼). Contoh kasus uji persamaan mean dari dua populasi yang tidak berhubungan (independen) dengan asumsi varians yang berbeda (contoh perhitungan). Data pertama kali dibuat di Microsoft Excel (Gambar 10.2) dan disimpan dalam format .csv (Gambar 10.3).
Karena nilai probabilitas (p-value) lebih kecil dari tingkat signifikansi 𝛼 = 0,05 maka hipotesis nol ditolak dan hipotesis alternatif diterima. Gambar 10.7 menyajikan kode R untuk menguji asumsi bahwa sampel 𝑋 dan sampel 𝑌 diambil dari populasi yang berdistribusi normal. Berdasarkan Gambar 10.9, nilai probabilitas uji Kolmogorov-Smirnov untuk sampel 𝑋 (p-value) adalah 0,57, sedangkan untuk sampel 𝑌 adalah 0,999.
Berdasarkan Gambar 10.11, nilai probabilitas uji Jarque-Bera untuk sampel 𝑋 (p-value) sebesar 0,5976, sedangkan untuk sampel 𝑌 sebesar 0,9013. Data pertama kali dibuat di Microsoft Excel (Gambar 10.12) dan disimpan dalam format .csv (Gambar 10.13). Diketahui juga bahwa berdasarkan Gambar 10.17, nilai probabilitas (p-value) sebesar 0,004853 (lokasi=”mean”) kurang dari tingkat signifikansi 0,05, sehingga hipotesis nol diterima dan hipotesis alternatif ditolak. jadi asumsinya populasi 𝑋 dan populasi 𝑌 mempunyai varians yang berbeda (inequality of variance) yang dapat diterima pada taraf signifikansi 5%.
Hubungan linier yang terjadi dapat bernilai positif yang ditunjukkan dengan nilai koefisien korelasi Pearson yang positif, atau dapat pula negatif yang ditunjukkan dengan nilai koefisien korelasi Pearson yang negatif. Sebaran data pada Gambar 11.2(b) cenderung acak (tidak beraturan), sehingga hubungan linier yang muncul antara X2 dan Y2 lemah. Misalnya diberikan data seperti pada Gambar 11.3 dengan nama file exampledata.csv, dan Gambar 11.4 dengan nama file exampledata2.csv.
Artinya sebaran datanya positif dan linier sempurna (positif artinya sebaran data cenderung berpindah dari kiri bawah ke kanan atas). Artinya hubungan linier yang terjadi antara X2 dan Y2 lemah (perhatikan penyebaran datanya cenderung acak, Gambar 11.2(b)). Artinya sebaran datanya negatif dan linier sempurna (negatif artinya sebaran data cenderung berpindah dari kiri atas ke kanan bawah).
Pada R, perhitungan nilai koefisien korelasi linier Pearson dapat dilakukan secara bersamaan dengan terlebih dahulu menggunakan perintah data.frame. Berdasarkan Gambar 11.12, nilai koefisien korelasi linier Pearson antara Ca dan HCO3 adalah nilai koefisien korelasi linier Pearson antara Ca dan Mg adalah nilai koefisien korelasi linier Pearson antara Ca dan SO4 dan seterusnya.

Persamaan regresi linier berganda yang telah dihasilkan sebelumnya dapat digunakan untuk memprediksi atau memperkirakan nilai variabel terikat, berdasarkan nilai masukan dari variabel bebas. Pada Gambar 12.14, garis persamaan regresi linier lebih baik dalam fitting data dibandingkan garis persamaan regresi linier pada Gambar 12.15. Koefisien determinasi sebesar 1 berarti persamaan regresi linier sangat sesuai dengan data (Gambar 12.16).
Koefisien determinasi semakin mendekati 0 yang berarti kekuatan persamaan regresi linier semakin buruk seiring dengan penyesuaian data. Dengan kata lain, kekuatan variabel independen yang digunakan secara bersamaan atau bersamaan dalam persamaan regresi linier kurang mampu menjelaskan variasi variabel dependen (Gambar 12.15). Semakin tinggi nilai koefisien determinasi (mendekati 1), maka persamaan regresi linier tersebut semakin sesuai dengan data.
Dengan kata lain kemampuan variabel-variabel independen yang digunakan dalam persamaan regresi linier secara bersamaan atau simultan semakin baik dalam menjelaskan variasi variabel dependen (Gujarati, 2993:87). Uji 𝐹 digunakan untuk memeriksa apakah persamaan regresi linier yang dihasilkan benar-benar bermakna atau signifikan secara statistik ditinjau dari kesesuaian data. Artinya persamaan regresi linier yang dihasilkan signifikan secara statistik ditinjau dari kesesuaian data.