See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/384448552
Aplikasi Jamovi Untuk Statistisi Pemula
Book · September 2024
CITATIONS
0
READS
121
4 authors:
Pardomuan Robinson Sihombing Statistics Indonesia
190PUBLICATIONS 254CITATIONS SEE PROFILE
Ade Marsinta Arsani Statistics Indonesia 61PUBLICATIONS 113CITATIONS
SEE PROFILE
Dyah Purwanti
Polytechnic of state finance stan 29PUBLICATIONS 32CITATIONS
SEE PROFILE
Masruri Muchtar
Polytechnic of State Finance STAN 58PUBLICATIONS 61CITATIONS
SEE PROFILE
All content following this page was uploaded by Pardomuan Robinson Sihombing on 30 September 2024.
APLIKASI JAMOVI UNTUK
STATISTISI PEMULA
Sanksi Pelanggaran Pasal 113
Undang-Undang Nomor 28 Tahun 2014 tentang Hak Cipta
1. Setiap Orang yang dengan tanpa hak melakukan pelanggaran hak ekonomi sebagaimana dimaksud dalam Pasal 9 ayat (1) huruf i untuk Penggunaan Secara Komersial dipidana dengan pidana penjara paling lama 1 (satu) tahun dan/atau pidana denda paling banyak Rp 100.000.000 (seratus juta rupiah).
2. Setiap Orang yang dengan tanpa hak dan/atau tanpa izin Pencipta atau pemegang Hak Cipta melakukan pelanggaran hak ekonomi Pencipta sebagaimana dimaksud dalam Pasal 9 ayat (1) huruf c, huruf d, huruf f, dan/atau huruf h untuk Penggunaan Secara Komersial dipidana dengan pidana penjara paling lama 3 (tiga) tahun dan/atau pidana denda paling banyak Rp500.000.000,00 (lima ratus juta rupiah).
3. Setiap Orang yang dengan tanpa hak dan/atau tanpa izin Pencipta atau pemegang Hak Cipta melakukan pelanggaran hak ekonomi Pencipta sebagaimana dimaksud dalam Pasal 9 ayat (1) huruf a, huruf b, huruf e, dan/atau huruf g untuk Penggunaan Secara Komersial dipidana dengan pidana penjara paling lama 4 (empat) tahun dan/atau pidana denda paling banyak Rp 1.000.000.000,00 (satu miliar rupiah).
4. Setiap Orang yang memenuhi unsur sebagaimana dimaksud pada ayat (3) yang dilakukan dalam bentuk pembajakan, dipidana dengan pidana penjara paling lama 10 (sepuluh) tahun dan/atau pidana denda paling banyak Rp 4.000.000.000,00 (empat miliar rupiah).
Pardomuan Robinson Sihombing, SST, M.Stat Ade Marsinta Arsani, SST, MPMA, ME
Dr. Dyah Purwanti, SST, Ak., M.Si.
Masruri Muchtar, S.E., S.S.T., M.Ebm., M.Sc.
APLIKASI JAMOVI UNTUK
STATISTISI PEMULA
APLIKASI JAMOVI UNTUK STATISTISI PEMULA Copyright © September 2024
Penulis :Pardomuan Robinson Sihombing, SST, M.Stat Ade Marsinta Arsani, SST, MPMA, ME Dr. Dyah Purwanti, SST, Ak., M.Si.
Masruri Muchtar, S.E., S.S.T., M.Ebm., M.Sc.
Editor : Dr. Lukmanul Hakim, M.Pd.I Setting dan layout : Rafika Aisyah Rahman Desain cover : Team Minhaj Pustaka Hak Penerbitan ada pada © Minhaj Pustaka 2024 Hak Cipta © 2024 pada penulis
Ukuran: 14,8 x 21 cm (A5) Halaman: x, 146 hal
Hak cipta dilindungi Undang-undang
Dilarang mengutip, memperbanyak dan menerjemahkan sebagian atau seluruh isi buku ini tanpa izin tertulis dari penerbit Minhaj Pustaka
Cetakan I, September 2024 ISBN: 978-623-89417-4-2 (PDF)
Jl. Pandawa II, DB 2, No. 97, Gelam Jaya, Pasar Kemis, Tangerang Banten – Indonesia
Telp. 085717079887
E-mail : [email protected]
Website: www.minhajpustaka.id
KATA PENGANTAR
Puji dan syukur Penulis panjatkan kepada Tuhan Yang Maha Esa, buku Aplikasi JAMOVI Untuk Statistisi Pemula dapat diterbitkan.
Buku ini merupakan pelengkap dari Buku Corat Coret Catatan Statistisi Pemula. Buku ini berisikan langkah-langkah pengolahan statistika dengan aplikasi software Jamovi. Adapun metode yang dibahas dalam buku ini adalah model-model standard yang biasa digunakan peneliti mulai dari analisis deskriptif dan analisis inferensia. Analisis inferensia mencakup penggunaan statistik untuk tujuan komparasi/ uji beda, menguji arah dan kekuatan hubungan antar variabel dan pembentukan model sebab akibat.
Jamovi merupakan salah satu software statistik yang dianggap powerfull karena dapat digunakan untuk data primer maupun data sekunder. Untuk data primer dapat digunakan untuk model SEM.
Dalam jamovi juga dapat digunakan untuk model-model univariat maupun multivariat. Keunikan JAMOVI ialah software ini bersifat free, opensource dan berbasis menu/ GUI serta terintegrasi dengan R.
Untuk edisi terbaru Jamovi juga dilengkapi dengan model-model statistika yang menggunakan berbagai metode estimasi seperti metode least square, maximum likelihood, method of moment dan Bayesian. Dalam JAMOVI juga pada menganalisi model panel dengan keluarga eksponensial dapat ditambahkan efek korelasi dengan menggunakan model Generalized Estimating Equation (GEE) dan efek acak/ random dengan model Generalized LinearMixed Model (GLMM).
Penulis berharap dengan hadirnya buku ini dapat menambah khasanah ilmu pengetahuan. Semoga dengan hadirnya buku ini, statistika yang sering dianggap sebagai suatu ilmu yang kompleks
dan rumit dapat menjadi mudah dipahami dan menjadi sesuatu yang menarik serta menyenangkan bagi khalayak umum. Penulis menyadari bahwa buku ini masih jauh dari kata sempurna. Sehingga penulis, sangat mengharapkan kritik dan saran dari pembaca demi penyempurnaan buku ini ke depan. Akhir kata penulis berharap, buku ini dapat menambah referensi dan pemahaman pembaca akan metode statistika.
Penulis
DAFTAR ISI
KATA PENGANTAR ... v
DAFTAR ISI ... vii
Pengenalan JAMOVI ... 1
Statistik Deskriptif ... 5
Untuk Data Kuantitatif/Metrik/Numerik ... 5
Untuk Data Kualitatif/Nonmetric/Label/Atribut ... 8
Kombinasi Data Kuantitatif dan Kualitatif ... 10
Kombinasi Data Kualitatif/ Kategorik dengan Tabulasi Silang (CossTab) ... 11
Scatter Plot ... 13
Diagram Pareto ... 14
Analisis Cluster ... 15
Cluster Hirarki ... 16
Cluster Non Hirarki ... 17
Statistik Inferensia ... 19
Uji Komparasi ... 21
Uji Rata-rata/Mean Aritmatik dan Uji Median ... 21
Uji Rata-Rata 1 Populasi Univariat ... 22
Uji Rata-Rata 2 Populasi Independen Univariat ... 24
Uji Rata 2 Populasi Dependen Univariat ... 27
Uji Rata-Rata K Populasi Independen Univariat / Analysis of Variance (ANOVA) One Way ... 29
Uji Rata-Rata K Populasi Independen Univariat / Analysis of Variance (ANOVA) Two-Way ... 35
Uji Rata-Rata K Populasi Dependen/Paired/Repeated
Univariat/Repeated Analysis of Variance (ANOVA) ... 37
Uji Proporsi ... 39
Uji Proporsi 1 Populasi ... 39
Uji Proporsi 2 Populasi Berpasangan Mac Nemar ... 40
Uji Proporsi K Populasi ... 42
Uji Korelasi ... 45
Korelasi Pearson ... 45
Korelasi Spearman ... 46
Korelasi Kendall ... 47
Korelasi Tetachoric ... 48
Korelasi Phi ... 49
Korelasi Cramer V ... 51
Regresi Binary Logistik pada Data Cross Section ... 59
Regresi Ordinal Logistik pada Data Cross Section ... 65
Regresi Multinomial Logistik pada Data Cross Section ... 69
Regresi Poisson pada Data Cross Section ... 73
Regresi Beta pada Data Cross Section ... 77
Regresi Model Mediasi/ Intervening pada Data Cross Section81 Langkah-Langkah dalam Pengujian Mediasi ... 82
Regresi Model Moderasi Pada Data Cross Section ... 85
Analisis Regresi Log Linier ... 91
Model Difference in Difference (DiD) ... 93
Uji Validitas dan Reabilitas ... 97
Analisis Faktor ... 101
Analisis Faktor EFA ... 101
Analisis Faktor CFA ... 104
Model SEM (Structural Equation Modeling) ... 109
Model Endogenitas dengan Instrument Variabel ... 117
Meta Analisis ... 121
Analisis Butir dengan Model Rasch ... 131
DAFTAR PUSTAKA ... 139
PROFIL PENULIS ... 143
Pengenalan JAMOVI
Jamovi adalah salah satu aplikasi statistik yang bersifat free, opensource dan berbasis GUI/ menu. Versi terbaru Jamovi saat ini adalah Jamovi 2.6.2 (https://www.jamovi.org/download.html). Jamovi dapat diaplikasikan baik pada OS Windows, Mac dan Linux. Berikut tampilan dari Jamovi:
Untuk memasukkan data pada Jamovi dapat menginput langsung pada spreadsheet yang ada atau menpaste (rekatkan) dari file aplikasi lain yang di copy (salin), missal menyalin data dari M.Excel. Selain
B A B
1
itu dapat menggunakan menu: File > Open, lalu pilih This PC dan browse data yang akan ditampilkan. Pilih format data yang akan dimasukkan dalam jamovi misalkan data berasal dari spss (.sav), dari excel (.xls), stata (.dta), SAS dan lainnya.
Untuk menambah package aplikasi metode yang akan digunakan dapat mengklik menu modul (+) di pojok kanan atas, lalu pilih jamovi library, dan pilih menu available, maka akan tampil package tambahan yang dapat diinstall sesuai kebutuhan analisis yang akan digunakan.
Statistik Deskriptif
Menurut Walpole (2012), statistika deskriptif dapat diartikan sebagai metode yang berkaitan dengan pengumpulan dan penyajian suatu data sehingga memberikan informasi yang berguna. Sedangkan menurut Sugiono (2017) statistik deskriptif berfungsi untuk mendeskripsikan atau memberi gambaran terhadap objek yang diteliti melalui data sampel atau populasi. Gambaran dapat berupa ukuran pemusatan/tendency (rata-rata, median, modus, proporsi), ukuran letak/posisi (kuartil, desil, persentil) maupun ukuran dispersi/keragaman data (jangkauan/range, standar deviasi dan varian/ragam).
Untuk Data Kuantitatif/Metrik/Numerik
Data kuantitatif merupakan data yang berbentuk angka/ metrik.
Data kuantitatif dapat dibagi atas data interval yang memiliki nilai nol mutlak seperti data suhu dan data tahun. Selain itu juga dapat berupa data rasio yang tidak memiliki nilai nol mutlak seperti data berat, volume, luas dan lainnya. Selain itu data kuantitatif berdasarkan cara memperoleh dan sifat datanya dapat berupa data diskrit dan data kontinu. Data diskrit didapat berdasarkan hasil cacahan (count), dimana nilainya berupa bilangan bulat tanpa desimal misalnya jumlah orang, jumlah kursi dan lainnya. Data
B A B
2
kontinu didapat berdasarkan hasil pengukuran (measurement), dimana nilainya dapat berupa bilangan bulat dengan desimal misalnya berat badan, tinggi badan dan lainnya. Adapun langkah pengujian, dengan menggunakan menu analyses → exploration → descriptive:
Lalu masukkan variable yang akan ditampilkan descriptivenya misal variabel pendapatan dan pengeluaran ke kolom “Variables”. Untuk menampikan ukuran statistik yang lebih lengkap dapat mengklik menu statistics dan plot.
Berikut hasilnya:
Descriptives
pendapatan pengeluaran
N 10 10
Missing 0 0
Mean 2.98 1.63
Median 2.90 1.25
Standard deviation 1.10 1.09
Minimum 1.60 0.400
Maximum 5.20 3.60
Untuk Data Kualitatif/Nonmetric/Label/Atribut Data kualitatif merupakan data yang tidak berbentuk angka, biasanya datanya berupa data kategorik dimana atribut/labelnya diberikan kode. Data kuantitatif dapat dibagi atas data nominal yang berfungsi sebagai label atau pembeda tanpa dapat memberikan peringkat misalnya data gender/jenis kelamin, warna pupil mata dan lainnya. Selain itu juga dapat berupa data ordinal yang tidak hanya dapat membedakan tetapi juga dapat diurutkan/diberi peringkat, hanya saja jarak antar kategori tidak selalu sama, misalnya tingkatan sekolah, tingkatan jabatan dan lainnya. Adapun langkah pengujian, dengan menggunakan menu analyses → exploration → descriptive:
Lalu masukkan variable yang akan ditampilkkan descriptive-nya misal variabel gender dan pendidikan ke kolom “Variables”. Dan centang opsi frequency table. Berikut hasilnya:
Frequencies of gender
gender Counts % of Total Cumulative %
Perempuan 5 50.0% 50.0%
Laki-laki 5 50.0% 100.0%
Frequencies of Pendidikan
pendidikan Counts % of Total Cumulative %
SD dan SMP 4 40.0% 40.0%
SMA 3 30.0% 70.0%
PT 3 30.0% 100.0%
Kombinasi Data Kuantitatif dan Kualitatif
Terkadang peneliti juga menggabungkan deskriptif antara data kuantitatif dengan data kualitatif. Hal ini dilakukan untuk membandingkan nilai-nilai dari variabel kuantitatif berdasarkan kategori tertentu. Adapun langkah pengujian, dengan menggunakan menu analyses →exploration → descriptive:
Lalu masukkan variable yang akan ditampilkkan descriptive-nya misal variabel pendapatan dan pengeluaran ke kolom “Variables”. Lalu pada kolom split by masukkan variabel kategorinya misal gender.
Berikut outputnya:
Descriptives
gender pendapatan pengeluaran
N Perempuan 5 5
Laki-laki 5 5
Mean Perempuan 3.02 1.60
Laki-laki 2.94 1.66
Median Perempuan 3.20 1.30
Laki-laki 2.60 1.20
Descriptives
gender pendapatan pengeluaran Standard deviation Perempuan 1.47 0.843
Laki-laki 0.730 1.40
Minimum Perempuan 1.60 1.10
Laki-laki 2.30 0.400
Maximum Perempuan 5.20 3.10
Laki-laki 4.10 3.60
Kombinasi Data Kualitatif/ Kategorik dengan Tabulasi Silang (CossTab)
Ketika seorang peneliti memiliki banyak data kualitatif maka dapat dilakukan tabulasi silang/cross tab sehingga dapat dilihat pola hubungan antar data kategorik tersebut. Adapun langkah pengujian, dengan menggunakan menu jamovi: Klik menu analyses→ frequenties → contingency table → independent sample
Jika ingin melakukan tabulasi dua arah masukkan variabel kategori pada rows dan coloums missal gender dan pendidikan, tetapi jika ingin lebih dari dua arah masukkan variabel kategori ke-3 dan seterusnya pada kolom layers.
Lalu klik menu cell
Tentukan tampilan tambahan misal persentase dari setiap frekuensi terhadap total data. Berikut outputya:
Contingency Tables
pendidikan
gender SD dan SMP SMA PT Total
Perempuan Observed 0 2 3 5
% of total 0.0% 20.0% 30.0% 50.0%
Laki-laki Observed 4 1 0 5
Contingency Tables
pendidikan
gender SD dan SMP SMA PT Total
% of total 40.0% 10.0% 0.0% 50.0%
Total Observed 4 3 3 10
% of total 40.0% 30.0% 30.0% 100.0%
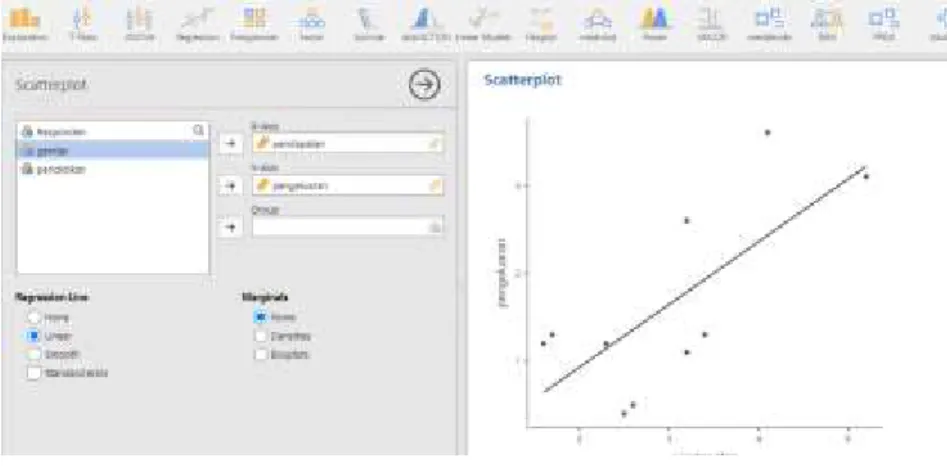
Scatter Plot
Scatter Plot atau diagram pencar adalah salah satu alat visualisasi data yang digunakan untuk menunjukkan hubungan antara dua variabel kuantitatif. Dalam scatter plot, setiap titik (atau plot) merepresentasikan satu observasi dari pasangan data (X, Y), di mana sumbu horizontal (X-axis) mewakili satu variabel, dan sumbu vertikal (Y-axis) mewakili variabel lainnya.
Misalkan kita akan melihat pola hubungan pendapatan dan pengeluaran dari 10 responden. Adapun Langkah yang digunakan adalah klik menu analyses → exploration → scatter plot, pada kolom X-axis masukkan variabel pendapatan dan pada y-axis masukkan varianel pengeluaran. Pada regression line centang linier. Berikut hasilnya:
Diagram Pareto
Diagram Pareto adalah alat manajemen yang digunakan untuk menganalisis data yang terkait dengan penyebab atau masalah dalam suatu proses, berdasarkan prinsip Pareto atau hukum 80/20. Prinsip Pareto menyatakan bahwa sekitar 80% dari efek disebabkan oleh 20% dari penyebab. Dalam konteks diagram Pareto, artinya sebagian besar masalah (sekitar 80%) berasal dari sebagian kecil penyebab (sekitar 20%).
Misalkan sebuah program studi Manajemen Universitas swasta meneliti, faktor-faktor yang menyebabkan menurunya prestasi mahasiswa, dilakukan observasi terhadap 100 mahasiswa didapakan hasil sebagai berikut:
Alasan Frekuensi
Malas 25
Kurang berminat 20
Kurang efektif Pembagian Waktu 28
Perlengkapan pribadi 17
Jarak 10
JUMLAH 100
Adapun Langkah yang digunakan adalah klik menu analyses → exploration → pareto chart, pada kolom X-axis masuknya variabel alasan dan pada count masukkan variabel frekuensi. Berikut hasilnya
Analisis Cluster
Analisis cluster (klaster/gerombol) adalah salah satu metode dalam analysis multivariat. Analisis ini terkadang dimasukan ke dalam analisis deskriptif karena tidak mengandung unsur hipotesis dan hasilnya tidak unik. Analisis cluster bertujuan mengelompokkkan unit-unit/ subjek berdasarkan kemiripan, baik kedekatan jarak maupun kemiripan korelasi antar variabel. Ada berbagai teknik pengelompokan data berdasarkan kedekatan jarak seperti jarak cartesian, jarak mahalanobis, jarak Blok Mahakam, blok chebychev dan lainnya. Pada umumnya analisis klaster dibagi dua metode yaitu metode hierarki dan metode non hierarki (Johnson & Wichern, 1998). Metode hierarki (metode single linkage, average linkage, complete linkage dan lainnya) akan membentuk klaster maksimal sebanyak jumlah objek sedangkan pada metode non hierarki (k- means dan k-median) berdasarkan jumlah yang diinginkan peneliti (dalam hal ini berdasarkan teori yang ada atau lanjutan dari uji
hirarki). Hal yang perlu diperhatikan dalam analisis klaster adalah satuan, jika satuan satuan antar variabel terlalu berbeda maka sebaiknya gunakan nilai standar dari data yang ada. Dalam analisis klaster pada umumnya data yang digunakan adalah data numerik/
kuantitatif, jika terdapat daoa kategorik/ kualitatif maka sebaiknya menggunakan teknik two step klaster. Misalkan kita akan mengelompokkkan kabupaten kota di Bali dengan indiaktor sosial ekonomi seperti ipm, gini, kemiskinan, pdrb dan tpt.
Cluster Hirarki
Adapun langkahnya klik menu analyses → snowcluster→ Hierachical Clustering
• Pada menu variable: Masukkan variabel yang dijadikan dasar pengelompokan dalam hal ini ipm, kemiskinan, gini_rasi, pdrb dan tpt
• Pada option pilih standardize data
• Pada distance measure pilih jenis jarak yang digunkan missal Euclidian
• Pada clustering method pilih jenis clustering misal ward02
• Pada by number of cluster pilih isian cluster misal 3
• Pada plot klik dendogram
Terlihat hasil dendogram, missal untuk 3 kluster Kabupaten Badung dan Kota Denpasar masuk dalam 1 cluster, Kabupaten Klungkung masuk dalam 1 cluster tersendiri dan sisanya masuk kluster ke-3.
Cluster Non Hirarki
Adapun langkahnya klik menu analyses → snowcluster→ K-Means Clustering
• Pada menu variable: Masukkan variabel yang dijadikan dasar pengelompokan dalam hal ini ipm, kemiskinan, gini_rasi, pdrb dan tpt
• Pada option pilih standardize data
• Pada alogoritma pilih salah satu
• Pada by number of cluster pilih isian cluster misal 3
• Pada plot pilih plot of means accross of cluster
Terlihat masing-masing jumlah anggota tiap cluster. Pada cluster 1 terdapat 5 kabkot, cluster 2 (klungkung dan Karangasem) serta cluster 3 (Badung dan Denpasar) masing-masing terdapat 2 kabkot. Untuk melihat anggota tiap cluster pada menu save centang cluster number.
Nilai centroid cluster dapat bernilai positif dan negatif. Nilai positif menunjukkan nilai di atas rata-rata dan nilai negative menunjukkan nilai di bawah rata-rata. Pada cluster 3, memiliki IPM di atas rata- rata sekaligus tertinggi di banding dua klaster lainnya, sebaliknya kluster ini memiliki nilai kemiskinan terendah.
.
Statistik Inferensia
Statistik inferensia adalah suatu metode yang digunakan untuk menarik kesimpulan/ generalisasi terhadap populasi dari data sampel yang ada (Walpole, 2012). Sutau data dapat dilakukan metode inferensua jika data yang digunakan merupakan data yang bersifat acak/ random dan diambil dengan menggunakan teknik probability sampling.
Ada tiga tujuan utama dalam statistik inferensia yaitu analisis komparasi/ perbandingan, analisis arah dan keeratan hubungan antar variabel serta analisi model sebab akibat/ pengaruh. Baik untuk ketiga tujuan tersebut, analisis statistik inferensia dapat dibagai atas statistic parametrik dan statistic nonparametrik.
Perbedaan utama dalam statistik parametrik dan statistik nonparametrik untuk kasus uji komparasi adalah berdasarkan distribusi data yang digunakan, skala data dan jumlah data. Jika data didasarkan pada asumsi distribusi tertentu (umumnya distribusi normal), skala data interval atau rasio serta jumlah data yang besar maka digunakan statistik parametrik. Sebaliknya jika data tidak didasarkan pada asumsi distribusi tertentu, skala data nominal atau ordinal serta jumlah data yang kecil maka digunakan statistik nonparametrik.
B A B
3
Perbedaan utama dalam statistik parametrik dan statistik nonparametrik untuk kasus analisis arah dan keeratan hubungan adalah berdasarkan distribusi data yang digunakan, skala data serta pola hubungan yang terbentuk. Jika data didasarkan pada asumsi distribusi tertentu (umumnya distribusi normal), skala data interval atau rasio serta pola hubungannya linier maka digunakan statistik parametrik. Sebaliknya jika data tidak didasarkan pada asumsi distribusi tertentu, skala data nominal atau ordinal serta pola hubungan yang tidak linier maka digunakan statistik nonparametrik.
Perbedaan utama dalam statistik parametrik dan statistik nonparametrik untuk kasus analisis pembentukan model adalah berdasarkan distribusi data yang digunakan, pola hubungan yang terbentuk serta spesifikasi model yang digunakan. Jika data didasarkan pada asumsi distribusi tertentu (umumnya distribusi normal dan keluarga eksponensial, pola hubungannya linier dan spesifikasi modelnya finit (terbatas) maka digunakan statistik parametrik. Sebaliknya jika data tidak didasarkan pada asumsi distribusi tertentu, pola hubungan yang tidak linier serta spesifikasi model tidak finit maka digunakan statistik nonparametrik.
Uji Komparasi
Dalam statistik untuk tujuan pengujian komparasi pada umumnya dilakukan pada ukuran data yaitu ragam/varian, rata-rata, median dan proporsi. Pengujian ini dapat dilakukan pada satu populasi, dua populasi dan lebih dari dua populasi. Pengujian terhadap satu populasi biasa dibandingkan dengan suatu nilai sebagai acuan/
standar. Pengujian terhadap dua atau lebih dua populasi dapat dibagi lagi menjadi dua atau lebih populasi dependen/
berpasangan/paired/related dan dua populasi atau lebih yang independen. Populasi dependen/related/paired didasarkan pada pengujian suatu populasi terhadap suatu treatment atau kebijakan yang dilakukan pada suatu populasi. Pada umumnya adanya efek pre dan post atau before dan after. Sedangkan pada populasi independen dilakukan pada populasi yang saling bebas, dimana kejadian atau peluang sutau populasi tidak mempengaruhi kejadian atau peluang populasi lainnya, umumnya dapat didasarkan pada populasi treatment dan populasi control/placebo. Untuk data contoh pada pengujian komparasi dapat didownload di link berikut:
shorturl.at/muAEP
Uji Rata-rata/Mean Aritmatik dan Uji Median
Pengujian komparasi rata-rata dapat dilakukan pada satu populasi dengan membandingkan terhadap suatu nilai, dua populasi yang
B A B
4
berbeda maupun lebih dari dua populasi. Jika datanya mengikuti distribusi normal maka dapat menggunakan uji t untuk uji 1 dan 2 populasi (Welch, 1947). Jika data tidak normal dapat menggunakan uji komparasi median dengan uji Wilcoxon (Siegel, 1997).
Uji Rata-Rata 1 Populasi Univariat
Misalkan akan diteliti apakah rata-rata nilai gini rasio 34 Provinsi di Indonesia tahun 2021 kurang dari 0.40
• Klik menu analyses →t-test→ one sample t test
• Pada dependen variables: pilih gini2021
• Pada test: pilih Student
• Pada hypothesis:
• Test value: ketik angka 0.4
• Lalu pada arah test pilih: < test value
• Pada additional statistics centang mean difference, effect size dan descriptive
• Pada assumption check: centang normality test.
Berikut contoh tampilan dan outputnya:
Dari hasil di atas terlihat bahwa data berdistriusi normal karena prob=0.710 > alpha=-0.05. Berdasarkan hasil uji t test nilai prob=
0.001 sehingga disimpulkan gini rasio Indonesia < 0.4 tahun 2021.
Selanjutnya, misalkan akan diteliti apakah median nilai persentase kemiskinan 34 Provinsi di Indonesia tahun 2021 lebih besar dari 8 persen.
• Klik menu analyses →t-test→ one sample t test
• Pada dependen variables: pilih miskin2021
• Pada test: pilih wilcoxon
• Pada Test value: ketik angka 8
• Lalu pada arah test pilih: > test value
• Pada additional statistics centang mean difference, effect size dan descriptive
• Pada assumption check: centang normality test.
Berikut vontoh tampilan dan outputnya:
Dari hasil di atas terlihat bahwa data tidak berdistribusi normal karena prob=0.001 < alpha=0.05
Berdasarkan hasil uji Wilcoxon nilai prob=0.017 sehingga disimpulkan kemiskinan Indonesia > 8.0 persen tahun 2021
Uji Rata-Rata 2 Populasi Independen Univariat
Misalkan akan diteliti apakah rata-rata IPM tahun 2021 pada daerah Sumatera Jawa lebih besar daripada daerah selain Sumatera Jawa
• Klik menu analyses →t-test→ independent sample t test
• Pada test: pilih Student t
• Pada dependen variables: pilih ipm2021
• Pada grouping variables: pilih kode
• Pada hypothesis: pilih group 1 > group 2
• Pada additional statistics centang mean difference, effect size dan descriptive
• Pada assumption check: centang normality test dan homogenity test.
Berikut tampilan dan outputnya:
Dari hasil di atas terlihat bahwa data berdistribusi normal karena prob=0.055 > alpha=0.05 dan varian data homogen (equal varian) karena prob=0.578 > alpha=0.05. Berdasarkan hasil uji student t nilai prob=<0.001 sehingga disimpulkan IPM di Sumatera Jawa lebih besar dari daerah lainnya pada tahun 2021. Selanjutnya, misalkan akan diteliti apakah rata-rata kemiskinan tahun 2020 pada daerah Sumatera Jawa lebih kecil daripada daerah selain Sumatera Jawa
• Klik menu analyses → t-test→ independent sample t test
• Pada dependen variables: pilih miskin2020
• Pada grouping variable: pilih kode
• Pada test: pilih welch
• Pada hypothesis: pilih group 1 < group 2
• Pada additional statistics centang mean difference, effect size dan descriptive
• Pada assumption check: centang normality test dan homogenity test Berikut tampilan dan outputnya
Dari hasil di atas terlihat bahwa data berdistribusi normal karena prob=0.063 > alpha=0.05 dan varian data heterogen (unequal varian) karena prob=0.042 < alpha=0.05. Berdasarkan hasil uji Welch’s nilai prob=0.057 > sehingga disimpulkan kemiskinan di Sumatera Jawa tidak berbeda dengan daerah lainnya pada tahun 2020. Selanjutnya, misalkan akan diteliti apakah median pengangguran tahun 2020 pada daerah Sumatera Jawa lebih besar daripada daerah selain Sumatera Jawa.
• Klik menu analyses →t-test→ independent sample t test
• Pada dependen variables: pilih tpt2020
• Pada grouping variable: pilih kode
• Pada test: pilih u mann whitney
• Pada hypothesis: pilih group 1 > group 2
• Pada additional statistics centang mean difference, effect size dan descriptive
• Pada assumption check: centang normality test dan homogenity test.
Berikut tampilan dan outputnya:
Dari hasil di atas terlihat bahwa data tidak berdistribusi normal karena prob=0.020 < alpha=0.05 dan varian data homogen (equal varian) karena prob=0.303 > alpha=0.05. Berdasarkan hasil uji u mann whitney nilai prob=0.015 < 0.05 sehingga disimpulkan pengangguran di Sumatera Jawa lebih besar dari daerah lainnya pada tahun 2020
Uji Rata 2 Populasi Dependen Univariat
Misalkan akan diteliti apakah rata-rata nilai persentase kemiskinan tahun 2021 lebih kecil dari tahun 2020 pada 34 Provinsi di Indonesia sama
• Klik menu analyses → t-test→ paired sample t test
• Pada paired variables: masukkan variabel miskin2021 dan miskin2020
• Pada test: pilih student’s
• Pada hypothesis: pilih measure 1 < measure 2
• Pada additional statistics centang mean difference, effect size dan descriptive
• Pada assumption check: centang normality test.
Dari hasil di atas terlihat bahwa data berdistribusi normal karena prob=0.741 > alpha=0.05. Berdasarkan hasil uji Student t nilai prob=0.001 < 0.05 sehingga disimpulkan persentase Tingkat kemiskinan tahun 2021 lebih kecil/ berkurang dari tahun 2020.
Selanjutnya, misalkan akan diteliti apakah median nilai IPM tahun 2021 pada daerah Sumatera Jawa lebih besar dari pada tahun 2020.
• Klik menu t-test→ paired sample t test
• Pada paired variables: masukkan variabel ipm2021 dan ipm2020
• Pada test: pilih wilcoxon
• Pada hypothesis: pilih measure 1 > measure 2
• Pada additional statistics centang mean difference, effect size dan descriptive
• Pada assumption check: centang normality test
Dari hasil di atas terlihat bahwa data tidak berdistribusi normal karena prob=0.001 < alpha=0.05. Berdasarkan hasil uji wilcoxon nilai prob=0.001 < 0.05 sehingga disimpulkan IPM tahun 2021 lebih besar/ meningkat dari tahun 2020.
Uji Rata-Rata K Populasi Independen Univariat / Analysis of Variance (ANOVA) One Way
Uji ANOVA digunakan untuk menguji apakah nilai rata-rata populasi untuk k populasi sama atau berbeda. Adapun asumsi dalam ANOVA adalah data harus berdistribusi normal dan nilai varian antar populasi yang homogen (Walpole, 2012). Jika data tidak berdistribusi normal dapat menggunakan alternatif uji nonparametric k populasi speri uji Kruskal Wallis (Siegel, 1997).
Misalkan akan diteliti apakah rata-rata nilai ipm2020 pada daerah Sumatera, Jawa-Bali dan selain Sumatera-Jawa-Bali sama atau berbeda
• Klik menu analyses →anova→ anova one way
• Pada dependen variables: masukkan variabel ipm2020
• Pada grouping variable: masukkan type
• Pada variance: centang assume equal (fisher)
• Pada assumption check: centang homogeneity test dan normality test
• Pada post hoc: pilih Tukey (equal variance)
Dari hasil di atas terlihat bahwa data berdistribusi normal karena prob=0.606> alpha=0.05 dan varian data homogen (equal varian) karena prob=0.055> alpha=0.05. Berdasarkan hasil uji ANOVA nilai prob=0.001 < alpha=0.05 sehingga disimpulkan ipm2020 pada ketiga wilayah ada yang berbeda. karena data berdistibusi normal serta variam data homogen maka uji post hoc menggunakan Tukey dari hasil uji post hoc terlihat yang berbeda ada pada wilayah daerah Jawa-bali dengan lainnya, sementara daerah Sumatera dan lainnya dianggap tidak berbeda.
Tukey Post-Hoc Test – ipm2020
Sumatera Jawa dan Bali Lainnya
Sumatera Mean difference — -3.08 2.77
p-value — 0.147 0.098
Jawa dan Bali Mean difference — 5.84***
p-value — <.001
Lainnya Mean difference —
p-value —
Note. * p < .05, ** p < .01, *** p < .001
Selanjutnya, misalkan akan diteliti apakah rata-rata nilai gini 2019 pada daerah Sumatera, Jawa-Bali dan selain Sumatera-Jawa-Bali sama atau berbeda:
• Klik menu analyses → anova→ anova one way
• Pada dependen variables: masukkan variabel gini2019
• Pada grouping variable: masukkan type
• Pada variance: centang don’t assume equal (welch)
• Pada assumption check: centang homogeneity test dan normality test
• Pada post hoc: pilih games Howell (unequal variance)
Dari hasil di atas terlihat bahwa data berdistribusi normal karena prob=0.780> alpha=0.05 dan varian data tidak homogen (unequal varian) karena prob=0.009< alpha=0.05. Berdasarkan hasil uji ANOVA nilai prob=0.001 < alpha=0.05 sehingga disimpulkan gini2019 pada ketiga wilayah ada yang berbeda. Karena data berdistibusi normal serta tetapi varian data homogen maka uji post hoc menggunakan Games-Howell dari hasil uji post hoc terlihat yang berbeda ada pada wilayah daerah Sumatera dengan daerah Jawa-Bali dan lainnya, sementara daerah Jawa-Bali dan lainnya dianggap tidak berbeda.
Games-Howell Post-Hoc Test – gini2019
Sumatera Jawa dan Bali Lainnya
Sumatera Mean difference — -0.0619 -0.0349
p-value — <.001 0.007
Jawa dan Bali Mean difference — 0.0270
p-value — 0.078
Lainnya Mean difference —
p-value —
Misalkan akan diteliti apakah rata-rata nilai tpt201 pada daerah Sumatera, Jawa-Bali dan selain Sumatera-Jawa-Bali sama atau berbeda
• Klik menu analyses →anova→ anova one way
• Pada dependen variables: masukkan variabel tpt2021
• Pada grouping variable: masukkan type
• Pada assumption check: centang homogeneity test dan normality test.
Dari hasil di atas terlihat bahwa data tidak berdistribusi normal karena prob=0.020 < alpha=0.05 dan varian data homogen (equal varian) karena prob=0.303 < alpha=0.05. Sehingga digunakan uji alternatif ANOVA yaitu Kruskal Wallis dan uji post hoc dengan uji pairwise Dunn.
• Klik menu analyses → anova→ nonparametric→ one-way anova
→ Kuskall Wallis
• Pada dependen variables: masukkan variabel tpt2021
• Pada grouping variable: masukkan type
• Centang DSCFpairwise comparasion
Dari hasil terlihat nilai p Kuskall Wallis 0.182 > alpha=0.05 sehingga dikatakan tidak ada perbedaan nilai tpt2021 antar ketiga wilayah.
Uji Rata-Rata K Populasi Independen Univariat / Analysis of Variance (ANOVA) Two-Way
Uji two-way ANOVA digunakan untuk menguji apakah nilai rata- rata populasi untuk k populasi sama atau berbeda untuk dua faktor.
Misalkan akan diuji tinggi tanaman berdasarkan ype lokasi (A, B, C dan D) serta varietas (X, Y, dan Z).
• Klik menu analyses →anova→ anova
• Pada dependen variables: tinggi tanaman
• Pada fixed factor: masukkan lokasi dan variets
• Pada variance: centang assume equal (fisher)
• Pada assumption check: centang homogeneity test dan normality test
• Pada post hoc: pilih Tukey (equal variance)
Dari hasil di atas terlihat bahwa data tidak berdistribusi normal karena prob=0.002< alpha=0.05 dan varian data homogen (equal varian) karena prob=0.99> alpha=0.05. Berdasarkan hasil uji ANOVA nilai prob=0.001 < alpha=0.05 untuk varietas dan loaksi sehingga disimpulkan masing-masng wilyah dan varietas nilainya ada yang berbeda. sedangkan untuk interasksinya tidak signifikan, artinya tidak ada interaksi antara wilayah dan varietas.
Untuk uji lanjutan terlihat masing-masing varietas dan lokasi yang berbeda yang nilai prob < alpha.
Uji Rata-Rata K Populasi Dependen/Paired/Repeated Univariat/Repeated Analysis of Variance (ANOVA) Uji repeated ANOVA digunakan untuk menguji apakah nilai rata- rata populasi untuk k populasi dependen sama atau berbeda. Adapun asumsi dalam ANOVA adalah data harus berdistribusi normal dan nilai varian antar populasi yang homogen (Walpole, 2012). Jika data tidak berdistribusi normal dapat menggunakan alternatif uji nonparametrik k populasi seperti uji Friedman (Siegel, 1997).
Misalkan akan diteliti apakah rata-rata nilai gini pada tahun 2019, 2020 dan 2021 sama atau berbeda
• Klik menu analyses →anova→ repeated measure anova
• Pada kolom repeated measure factors:
• Ketik gini dan kategori periode missal 2019, 2020 dan 2021
• Lalu pada kolom repated measurement cell:
• Masukkan variabel gini 2019, 2020 dan 2021
Dari hasil di atas terlihat nilai prob=0.153 > alpha=0.05; artinya tidak tolak Ho dan dianggap ketiga periode nilai gini dianggap sama.
Untuk melanjutkan analisis dapat menggunakan menu pada post hoc.
Lalu masukkan variabel gini dan pilih salah satu analisis post hoc misal Tukey.
Pada hasil di atas terlihat perbandingan antar tahun semua nilai p.value tukey > alpha=0.05. Selanjutnya, misalkan akan diteliti apakah rata-rata nilai kemiskinan pada tahun 2019, 2020 dan 2021 sama atau berbeda
• Klik menu analyses →anova→ nonparametric → repeated measure anova → Friedman
• Pada dependen variables: masukkan variabel miskin2019;
miskin2020 dan miski2021
• Centang opsi Pairwose comparisons (Durbin-Conover)
Berdasarkan hasil uji Friedman nilai prob=0.001 < alha=0.05 sehingga disimpulkan kemiskinan pada ketiga wilayah ada yang berbeda. Selanjutnya dari uji post hoc terlihat semua periode dianggap berbeda.
Uji Proporsi
Pengujian proporsi digunakan untuk membandingkan apakah proporsi suatu kategori sama terhadap nilai yang dihipotiskan (untuk uji 1 populasi) maupun apakah proporsi suatu kategori sama terhadap dua populasi yang berbeda. Uji proporsi menggunakan ui z (Walpole, 2012).
Uji Proporsi 1 Populasi
Misalkan akan diteliti apakah data 19 data yang ada proporsi laki- laki (kode=1) =0.5
Pilih menu analyses → frequency → one sample proportion test → 2 outcome → binomial test, masukkan variabel yang akan diuji dan ketikkan nilai proposi yang akan diuji serta arah uji hipotesisnya.
Terlihat bahwa p.value =0.064 > alpha=0.05 dapat diartika proporsi kedua populasi masih dianggap sama.
Uji Proporsi 2 Populasi Berpasangan Mac Nemar
Uji McNemar adalah uji non-parametrik yang digunakan untuk menganalisis data berpasangan atau berulang yang berskala nominal, khususnya pada situasi di mana kita ingin melihat perubahan dalam variabel kategori biner pada dua waktu atau kondisi yang berbeda.
Uji ini sering digunakan untuk mengevaluasi apakah ada perubahan yang signifikan dalam proporsi hasil biner setelah perlakuan atau intervensi. Uji McNemar membandingkan dua pengukuran yang dilakukan pada sampel yang sama (berpasangan), misalnya sebelum dan sesudah intervensi. Uji ini digunakan untuk menentukan apakah ada perbedaan signifikan antara dua kondisi yang diukur, dengan fokus pada pasangan yang hasilnya berubah.
Uji McNemar hanya memperhitungkan subjek yang berubah antara dua kondisi (misalnya, dari hasil 1 ke 0 atau 0 ke 1). Jika tidak ada perubahan (hasil tetap sama), subjek tersebut tidak mempengaruhi hasil uji. Misalkan sebuah penelitian ingin mengevaluasi apakah ada perbedaan yang signifikan dalam proporsi siswa yang lulus ujian setelah mengikuti program bimbingan belajar. Data dikumpulkan sebelum dan sesudah program bimbingan dari 50 siswa. Hasilnya dikategorikan sebagai "lulus" (1) atau "tidak lulus" (0).
Setelah Bimbingan Lulus (1)
Setelah Bimbingan Tidak Lulus (0) Sebelum Lulus
(1) 12 3
Sebelum Tidak
Lulus (0) 16 19
Pilih menu analyses → frequency → contingency table → paired sample
→ mac nemar test masukkan variabel sebelum apda row dan setelah apda colouns serta nilai pada count.
Dari hasil di atas dapat disimpulkan tidak terjadi perubahan yang signifikan jumlah kelulusan sebelum dan sesudah bimbangan karen aprob 0.209 > alpha=0.05.
Uji Proporsi K Populasi
Selanjutnya adalah melakukan uji komparasi terhadap k populasi. Statistik yang digunakan adalah uji chi square (Breiman, 1973). Misalkan akan diteliti apakah dari 100 data responden yang terdiri atas 4 katgeori Pendidikan (SD, SMP, SMA dan PT) apakah proporsinya sama jika yang terkumpul masing-masing sebanyak 25, 20, 15, 40
Pilih menu analyses →frequency → one sample proportion test → n outcome → x2 goodness of fit, masukkan variabel yang akan diuji pada kolom variables.
Terlihat p.value=0.705 > alpha=0.05 artinya proposi ketiga kategori masih dianggap sama.
Uji Korelasi
Pengujian korelasi digunakan untuk melihat arah dan kuat/ besaran hubungan antar variabel. Jika koefisien korelasi bertanda positif artinya hubungannya searah, dimana kenaikan nilai satu variabel juga diikuti kenaikan variabel lainnya, sebaliknya penurunan nilai suatu variabel diikuti penurunan variabel lainnya. Jika koefisien korelasi bertanda negative artinya hubungannya berlawanan arah, dimana kenaikan nilai satu variabel juga diikuti penurunan variabel lainnya, sebaliknya penurunan nilai suatu variabel diikuti kenaikan variabel lainnya. Nilai korelasi berkisar antara -1 sampai 1. Nilai absolut korelasi 0-0.5 besaran korelasinya dianggap lemah, jika nilai absolutnya diantara 0.51-0.70 besaran korelasinya dianggap moderat sedangkan jika nilai absolut nya 0.71-0.99 besaran korelasinya dianggap kuat. Korelasi hanya menyatakan ada tidaknya serta besaran hubungan antar variabel, tidak menjelaskan hubungan sebab akibat.
Korelasi Pearson
Korelasi pearson adalah metode hubungan antar variabel kuantitatif.
Syarat data dalam korelasi pearson adalah data berdistribusi normal dengan pola hubungan linier (Walpole, 2012). Untuk data contoh pada pengujian korelasi pearson dapat didownload di link berikut:
shorturl.at/muAEP
B A B
5
Misalkan akan diteliti apakah ada hubungan antara ipm dan gini tahun 2021
Klik menu analyses →regression→ correlation matrix.
Masukkan variabel yang akan diuji misal gini dan ipm, lalu pilih Pearson pada opsi correlation coefisien dan pilih arah hypothesis.
Terlihat bahwa kedua data berdistribusi normal karena prob >
alpha=0.05. Dilihat dari korelasinya sebesar 0.158, tetapi tidak signifikan karena prob=0.372 > alpha=0.05
Korelasi Spearman
Korelasi pearson adalah metode hubungan antar variabel kuantitatif, dimana datanya tidak harus berdistribusi normal (Siegel, 1997).
Untuk data contoh pada pengujian korelasi spearman dapat didownload di link berikut: shorturl.at/muAEP
Misalkan akan diteliti apakah ada hubungan antara kemiskinan dan tpt tahun 2021
Klik menu analyses →regression→ correlation matrix.
Masukkan variabel yang akan diuji missal gini dan ipm, lalu pilih Spearman pada opsi correlation coefisien dan pilih arah hypothesis
Terlihat bahwa kedua data tidak berdistribusi normal karena prob <
alpha=0.05. Dilihat dari korelasinya sebesar -0.408, dan signifikan karena prob=0.016 < alpha=0.05
Korelasi Kendall
Misalkan akan diteliti apakah ada hubungan displin dan kinerja yang dikukur dengan skla ordinal likert.
Klik menu analyses →regression→ correlation matrix
Masukkan variabel yang akan diuji missal kinerja dan disiplin, lalu pilih Kendall tau-b pada opsi correlation coefisien dan pilih arah hypothesis.
Terlihat bahwa kedua data tidak berdistribusi normal karena prob <
alpha=0.05. Dilihat dari korelasinya sebesar -0.526, dan signifikan karena prob=0.025 < alpha=0.05
Korelasi Tetachoric
Korelasi Tetachoric adalah metode hubungan antar variabel kategori (dikotomos/ binary) yang berskala ordinal (Edwards & Edwards, 1984). Misalkan akan diteliti apakah ada hubungan antara status pekerjaan (karyawan dan manajer/ direktur) dengan status perumahan yang ditempati (kontrakan dan perumahan)
Klik menu analyses →seolmatrix→ ordinal correlation.
Masukkan variabel yang akan diuji missal status dan perumahan, lalu pilih tetachoric pada opsi correlation coefisien dan pilih arah hypothesis.
Terlihat nilai korelasinya sebesar 0.302 Korelasi Phi
Korelasi Phi adalah metode hubungan antar variabel berskala nominal dikothomus/ binary (Garson, 2013). Misalkan akan diteliti apakah ada hubungan antara gender (laki-laki dan perempuan) dengan jenis tontonan (sinetron dan berita).
• Klik menu analyses → frequenties → contingency table → independent sample → X2 test of association. Pada rows masukan variabel gender dan pada coloum masukkan variabel tontonan
• Klik menu test pilih X2
• Lalu pada hyphotesis test pilih phi and cramer phi
• Pada cell pilih percentage total.
Pada hasil terlihat nilai korelasi sebsar 0.491 dengan nilai p.value 0.057.
Korelasi Cramer V
Korelasi Cramer V adalah metode hubungan antar variabel berskala nominal yang berukuran mxm (Garson, 2013). Misalkan akan diteliti apakah ada hubungan antara kepemilikin TV (mnc, bakery dan CT) dengan acara (sinetron, berita dan olah raga)
Klik menu analyses → frequenties → contingency table → independent sample → X2 test of association. Pada rows masukan variabel TV dan pada coloum masukkan variabel acata. Klik menu test pilih X2
Lalu pada hyphotesis test pilih phi and cramer phi Pada cell pilih percentage total.
Pada hasil terlihat nilai korelasi sebsar 0.365 dan tidak signifikan dengan nilai p.value 0.406 > alpha=0.05
Regresi Linier Berganda pada Data Cross Section Gaussian
Salah satu pemodelan sebab akibat yang sering digunakan adalah model regresi. Jika data yang digunakan merupakan data cross section (satu periode), dengan jumlah variabel independen lebih dari 1 dan data diasumsikan berdistibusi normal maka model regresi dengan teknik estimasi ordinary least square (OLS) tepat digunakan. Model regresi ini sering disebut model regresi gaussian, yang memiliki asumsi klasik yaitu normalitas, multikol, heterokedastisitas dan linearitas (Gujarati, 2004). Adapun langkah pengujian, dengan menggunakan menu Jamovi:
Untuk data contoh pada pengujian regresilinier berganda pada data cross section dapat didownload di link berikut: shorturl.at/muAEP.
Misalkan akan diteliti pengaruh gini rasio dan IPM di 34 Provinsi di Indonesia Tahun 2021
B A B
6
• Klik menu analyses → regression → linier regression
• Pada dependen Variable: masukkan variabel miskin2021
• Pada covariates: masukkan variabel independent yang kuantitatif missal ipm2021 dan gini2021
• Pada factors: masukkan variabel independent yang kualitatif
Pada assumption Check
Tentang autocorrelation test, collinearity test dan normality test
Pada Menu Model Fit centang adjusted r square dan overall model test F test
Model R R² Adjusted R²
1 0.792 0.627 0.603
Overall Model Test F df1 df2 p 26.1 2 31 <.001
Model Coefficients - miskin2021
Predictor Estimate SE t p Intercept 63.28 11.236 5.63 <.001 ipm2021 -1.01 0.153 -6.61 <.001 gini2021 55.53 14.218 3.91 <.001
Nilai r adj-0.6271 artinya variasi kemiskinan tahun 2021 mampu dijelaskan oleh gini dan ipm sebesar 60.30 persen sisanya 39.70 oleh variabel lain di luar model.
Ho: variabel independen ke-i tidak berpengaruh H1: variabel independen ke-i berpengaruh
Karena nilai sign.prob value t =0.000 < alpha (0.05) maka tolak Ho dan disimpulkan variabel independent berpengaruh signifikan.
=63.28-1.009 ipm+55.53 gini
• Nilai koefisien ipm negatif artinya kenaikan IPM akan menurunkan persentase kemiskinan dengan asumsi variabel lain konstan
• Nilai koefisien gini positif artinya kenaikan gini akan menaikkan persentase kemiskinan dengan asumsi variabel lain konstan.
Normality Tests
Statistic p
Shapiro-Wilk 0.964 0.322 Kolmogorov-Smirnov 0.113 0.735 Anderson-Darling 0.362 0.424
Note. Additional results provided by moretests
Ho: data berdistribusi normal H1: data tidak berdistribusi normal
Karena nilai sign.prob value =0.3223 > alpha (0.05) maka tidak tolak Ho dan disimpulkan bahwa datanya sudah berdistribusi normal
Heteroskedasticity Tests
Statistic p
Breusch-Pagan 0.505 0.777 Goldfeld-Quandt 1.19 0.374 Harrison-McCabe 0.453 0.344 Note. Additional results provided by moretests Ho: varian data homogen (non heterokedastis)
H1: varian data heterokedastis
Karena nilai sign.prob value =0.777 > alpha (0.05) maka tidak tolak Ho dan disimpulkan bahwa varian datanya homogen, bebas asumsi heterokedastisitas
Collinearity Statistics
VIF Tolerance ipm2021 1.03 0.975 gini2021 1.03 0.975
Ho: tidak ada multikolinearitas yang tinggi antar variabel independen
H1: ada multikolinearitas yang tinggi antar variabel independen
Karena nilai VIF < 10 maka tidak tolak Ho dan disimpulkan modelnya bebas asumsi multikolinearitas.
Regresi Binary Logistik pada Data Cross Section
Jika seorang peneliti melakukan pemodelan sebab akibat dengan variabel dependen berupa data kategorik dengan dua kriteria baik berupa data nominal maupun ordinal maka model regresi yang tepat adalah model regresi binary (Gujarati, 2004). Model regresi binary masuk ke dalam model Generalized Linear Model (GLM). Di dalam model GLM terdapat tiga komponen utama yaitu komponen distribusi acak, yaitu y berdistribusi keluarga eksponensial;
komponen prediktor linier, yaitu ; dan fungsi link yaitu fungsi monoton dan diferensiabel sehingga . Fungsi link dapat berupa fungsi logit, probit dan complementari log-log (Agresti, 2002). Dalam regresi binary logistic perlu diperhatikan komposisi antar kategori variabel dependennya, jika proporsinya tidak seimbang (imbalanced), maka dapat menggunakan imbalanced model untuk data binary, atau dapat menggunakan model quasy binary logistic maupun skew binary logistic
Untuk data contoh pada pengujian regresi binary logistik dapat didownload di link berikut: shorturl.at/rwAD5.
B A B
7
• Klik menu analyses → regression → logistic regression → 2 outcome
→ binomial
• Pada dependen Variable: masukkan status
• Pada covariates: masukkan variabel independent yang kuantitatif
• Pada factors: masukkan variabel independent yang kualitatif missal kelahiran kembar dan jarak kelahiran
• Pada Fit measures: centang overall model test, dan Negelkerke R2,
• Pada Model Coefficient: centang likelihood ratio test dan odds ratio Pada Prediction: centang classification matrix, accuracy, specificity dan sensitivity
Predictive Measures
Accuracy Specificity Sensitivity
0.928 0.996 0.0701
Note. The cut-off value is set to 0.5 Model R²McF RN
1 0.0315 0.0401
Overall Model Test χ² df p 270 2 <.001
Model mampu memprediksi dengan tepat sebesar 92.82 persen koefisien determinasi (pseudo r square).
Nilai pseudo r2 0.0401 artinya variasi kejadian bayi lahir rendah mampu dijelaskan oleh kelahiran kembar dan jarak kelahiran sebesar 4.01 persen sisanya variabel lain di luar model.
Ho: tidak ada variabel yang berpengaruh
H1: minimal 1 variabel independen yang berpengaruh
Karena nilai sign.prob value chi2 =0.000 < alpha (0.05) maka tolak Ho dan disimpulkan minimal 1 variabel yang berpengaruh
Model Coefficients - status
Predictor Estimate SE Z p Odds
ratio
Intercept -2.689 0.0408 -
65.85 <.001 0.0680
Kelahiran kembar:
lahir kembar – lahir tidak kembar
2.994 0.1733 17.28 <.001 19.9679
Jarak kelahiran:
< 2 tahun – > 2
tahun 0.204 0.0620 3.28 0.001 1.2258
Note. Estimates represent the log odds of "status = berat bayi lahir rendah" vs.
"status = berat bayi normal"
Ho: variabel independen ke-i tidak berpengaruh H1: variabel independen ke-i berpengaruh
Karena nilai sign.prob value z =0.000 < alpha (0.05) maka tolak Ho dan disimpulkan variabel independent berpengaruh signifikan persamaan regresi
=-5.88+0.2036 jarak lahir+ 2.99 kembar
• Nilai koefisien jarak lahir positif artinya peluang BBLR lebih tinggi pada bayi yang lahir kembar dibanding yang tidak kembar dengan odds sebesar exp (2.99) =19,96 kali, dengan asumsi variabel lain konstan.
• Nilai jarak lahir positif artinya peluang BBLR lebih tinggi pada kelahiran dengan jarak < 2 tahun dibanding jarak kelahiran > 2 tahun, dengan odds sebesar exp (0.2036) =1.22 kali, dengan asumsi variabel lain konstan.
Untuk data contoh pada pengujian regresi ordinal sampai dengan regresi beta dapat didownload di link berikut: shorturl.at/axzS7.
Regresi Ordinal Logistik pada Data Cross Section
Jika seorang peneliti melakukan pemodelan sebab akibat dengan variabel dependen berupa data kategorik dengan lebih dari dua kriteria yang dapat diurutkan (ordinal) maka model regresi yang tepat adalah model regresi ordinal (Gujarati, 2004). Model regresi ordinal juga masuk ke dalam model Generalized Linear Model (GLM). Fungsi link dapat berupa fungsi logit, probit dan complementari log-log (Agresti, 2002). Dalam model ordinal regression hal yang perlu diperhatikan adalah asumsi/asas pararel line/proportional odss, jika asumsi ini tidak terpenuhi maka dapat menggunakan model penalized/regulazation ordinal regression.
Misalkan akan diteliti pengaruh sosial score dan jenis kelamin terhadap kemampuan TPA/ SES (1=rendah, 2=sedang, 3=tinggi).
B A B
8
• Klik menu analyses → regression → logistic regression → ordinal regression
• Pada dependen Variable: masukkan SES
• Pada covariates: masukkan variabel independent yang kuantitatif seperti socr
• Pada factors: masukkan variabel independent yang kualitatif misal female
Pada Model Coefficient: centang likelihood ratio test dan odds ratio.
Model Fit Measures
Model Deviance AIC R²McF
1 393 401 0.0671
Note. The dependent variable 'ses' has the following order: low | middle | high Note. Models estimated using sample size of N=200
Overall Model Test χ² df p 28.3 2 <.001
Nilai pseudo r2 0.0671 artinya variasi SES mampu dijelaskan oleh female dan soct sebesar 6.71 persen sisanya variabel lain di luar model.
Ho: tidak ada variabel yang berpengaruh
H1: minimal 1 variabel independen yang berpengaruh
Karena nilai sign.prob value chi2 =0.000 < alpha (0.05) maka tolak Ho dan disimpulkan minimal 1 variabel yang berpengaruh.
Model Coefficients - ses
Predictor Estimate SE Z p Odds
ratio
female:
female – male
-0.5802 0.2740 -2.12 0.034 0.560
socst 0.0662 0.0137 4.84 <.001 1.068
Uji parsial/ uji z/ uji wald
Ho: variabel independen ke-i tidak berpengaruh H1: variabel independen ke-i berpengaruh
Karena nilai sign.prob value z =0.000 < alpha (0.05) maka tolak Ho dan disimpulkan variabel independen berpengaruh signifikan iv.
persamaan regresi.
=1.84-0.58 female+ 0.066 socst
=4.16-0.58 female+ 0.066 socst
• Nilai koefisien female negatif artinya peluang nilai SES tinggi pada Wanita lebih rendah dibandingkan laki-laki, dengan asumsi variabel lain konstan
• Nilai koefisien socst positif artinya semakin tinggi nlai sosst maka peluang nilai SES juga meningkat, dengan asumsi variabel lain konstan.
Regresi Multinomial Logistik pada Data Cross Section
Jika seorang peneliti melakukan pemodelan sebab akibat dengan variabel dependen berupa data kategorik dengan lebih dari dua kriteria yang tidak dapat diurutkan/ dibandingkan (nominal) maka model regresi yang tepat adalah model regresi multinomial (Agresti, 2002). Model regresi multinominal juga masuk ke dalam model Generalized Linear Model (GLM). Fungsi link dapat berupa fungsi logit, probit dan complementari log-log (Agresti, 2002). Misalkan akan diteliti pengaruh math dan science score terhadap pemilihan program perkuliahan (1=general, 2=vocational, 3=academic).
B A B
9
• Klik menu analyses→regression →logistic regression →n-outcome→ multinomial regression
• Pada dependen Variable: masukkan variabel prog
• Pada covariates: masukkan variabel independent yang kuantitatif seperti math dan science
• Pada factors: masukkan variabel independent yang kualitatif
• Pada reference level tentukan baseline kategorinya
Pada Model Coefficient: centang likelihood ratio test dan odds ratio Model Deviance AIC R²McF
1 350 362 0.142
Overall Model Test χ² df p 58.0 4 <.001
Nilai pseudo r2 0.1422 artinya variasi jenis