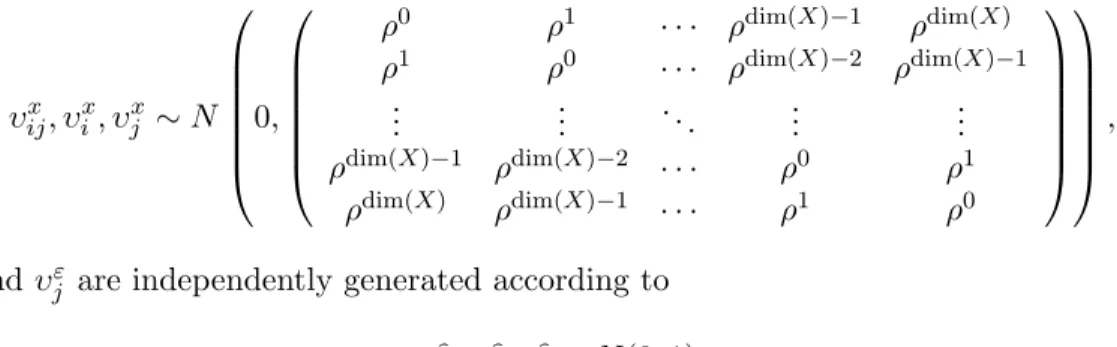We illustrate the proposed method with a number of empirical applications in development and growth economics. By applying the proposed method to market share data for demand analysis, we obtain larger robust two-way cluster standard errors for the price coefficient than non-robust standard errors in the demand model.

Introduction
Motivation: Text Analysis and Gendered Language on the Internet
Using a text regression model, Wu18 examines how women and men are discussed and portrayed in the anonymous Economics Job Market Rumors forum. For text regression models with binary attributes, a penalized logistic model is recommended by GKT19; see their section 3.1.1 for more details.
Background and Literature Review
- Contributions
- Relations to the Literature
- Notations
- Outline
Each WgG = {WigG : 1 ≤ i ≤ ng}, is a random vector that is independent over g, but not necessarily identically distributed. In Section 3.5, we apply the proposed method to perform simultaneous tests to verify a statement about gender language in Wu18.
An Overview
Estimation and Inference Procedures
We now summarize the estimation, inference, and construction of simultaneous confidence interval procedures based on the theoretical results to be presented in the following sections 1.5 and 1.6. The post-double selection estimator is theoretically related to the post-double selection estimators for linear models in BCH14 and for Logit regression coefficients in BCW16 and BCCW18.
Main Theoretical Results
However, to deal with APEs, we need additional conditions for the growth of some moments, which are listed below in the statement of Theorem 1.1. That is, the algorithms in Section 3.2 asymptotically provide valid simultaneous inferences and confidence intervals.
Nuisance Parameters
- Post-Lasso Logit and Estimation of β 0
- Weighted Post-Lasso with Estimated Weights
- Nodewise Post-Lasso and Estimation of θ k
- Weighted Post-Lasso and Estimation of ζ k
We now establish asymptotic theory for weighted post-lasso with estimated weights that will be essential for Sections 1.6.3 and 1.6.4. Now we provide estimators for θk built on the cluster nodewise post-lasso estimator method for approximating the inversion of a singular matrix.
Simulation Studies
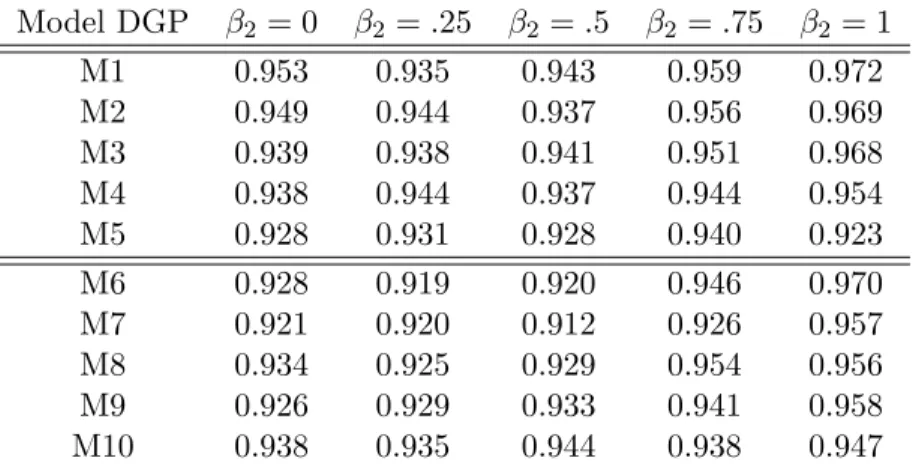
Finally, we investigate the asymptotic behaviors of case A10, one of the worst performing cases in the above simulations for simultaneous confidence intervals, to examine whether the performance improves with increasing sample size. In all three sets of simulations, the coverage probabilities are mostly close to the nominal coverage rate when ρ is not too high.

Application: Testing Gendered Language on the Internet
Conclusion
Inference in high-dimensional panel models with an application to arms control. Journal of Business and Economic Statistics. Oracle inequalities, variable selection, and uniform inference in high-dimensional correlated panel data models with random effects. ”Journal of Econometrics.
Appendix
Orthogonalization of the Score
Main Results under High-level Assumptions
One can use sample splitting to eliminate the dependence between the orthogonal result and the disturbance parameters. First, we do not assume that each group is identically distributed as it is not appropriate for the sampling method used in the motivating example in Section 1.2.
Proofs for Results in Section 1.10.2
This is due to the fact that Lemma A.1 of BCFH17 implies that it suffices to show that these results hold for any sequence PG∈ PG, which is satisfied since all bounds in this paper are set independently by DGP. It allows us to apply the maximum inequality of Corollary 1.3 to obtain the desired bound.
Proofs for Results in Section 1.5
For the further binding of the right-hand side, the binding of the matrix`2 norm for each of the production expressions is sufficient. Note that all these classes are uniformly bounded with the exceptions of G3ikT and G7ik.
Proofs for Results in Section 1.6
Since Assumption 13 implies that there exists a`G→ ∞ such that φmax(`Gs).1 with probability 1−C(logG)−1, it follows from Lemma 1.4 that kbγjk0.s with probability 1−C(logG)− 1 uniformly over j ∈ [p]. Expanding the mean and applying H¨older's inequality gives this with probability at least 1− C(logG)−1,. G with probability at least 1−C(logG)−1 can be determined by similar arguments and the fact that maxk∈[p]kΘkk1.
Supplementary Appendix
Additional Theoretical Results
Consider a data-generating process with an outcome variable Yigk and p-dimensional covariants Xigk, both indexed by k∈ UG for some UG ⊂[p]. Boundedness of minimum and maximum sparse eigenvalues with probability goes to 1 implies that bounded eigenvalue is bounded away from 0 with probability goes to 1. In addition to conditions of Lemma 1.3, suppose that with probability 1−∆eG, for some random variable LG such that for allδ ∈Rp, this holds.
Proof for Additional Results
To demonstrate the first statement, let us suppose that the events of Assumption 8 hold with probability 1−∆eG.
Technical Lemmas
Now E[σ2n] is bound by the contraction principle (Corollary 3.2.2 of GN16) and the Cauchy-Schwarz inequality,. Let F denote a class of measurable functions :W →Rwith a measurable envelope F. 1) Let F be a VC subgraph class with a finite VC index k or any other class whose entropy is bounded above by that of such A VC subgraph class, then obeys the uniform entropy numbers of F.
Introduction
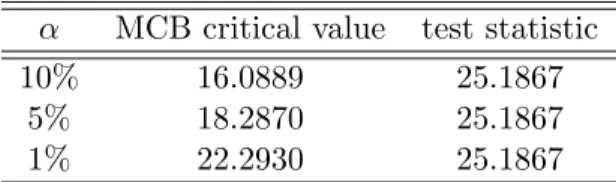
To the best of our knowledge, this paper is the first in this multi-way clustering literature to consider high-dimensional models.
The Model
Overview of the Method
Asymptotic Theory
- Independentization via H´ ajek Projection
- Convergence Rates of Lasso and Post-Lasso under Multiway Clustering
- Post-Selection-Inference with Post-Lasso under Multiway Clustering
- Variance Estimation
In this section, we show that an empirical process in multi-way clustered samples can be represented as a sum of independent variables via the H´ajek projection. The first part of the lemma shows that an empirical process GCf under multiway cluster sampling can be represented as a sum of unobserved independent variables via the H´ajek Hnf projection. While Ui0 and U0j are unobserved, the second part of this lemma shows that the variance of the H´ajek projection can be approximated by the covariance of the observed variables.
Extension: Heterogeneous Cluster Sizes
This result provides a theoretical justification for the asymptotic variance proposed in the overview in section 3.2. With these component estimators, we suggest that the asymptotic varianceσ2 =Q−1ΓQ−1 is estimated byσb2 =Qb−1bΓQb−1. We now formally state assumptions for the extended theory to support the asymptotic validity of this procedure.
Simulation Studies
Simulation Setup
Alternative Variance Estimators
Results
Both the 0-Way and 1-Way variance estimators significantly underestimate the variances of the lasso estimate α after double selection. On the other hand, the coverage frequency based on our 2-way variance estimator approaches the nominal probability (95%) as the sample size increases. These results show that when the real sampling process involves multi-way clustering, traditional variance estimators can bias the inference and that our multi-way cluster-robust variance estimator performs robustly well.
Empirical Illustrations
Slave Trade and Mistrust in Africa
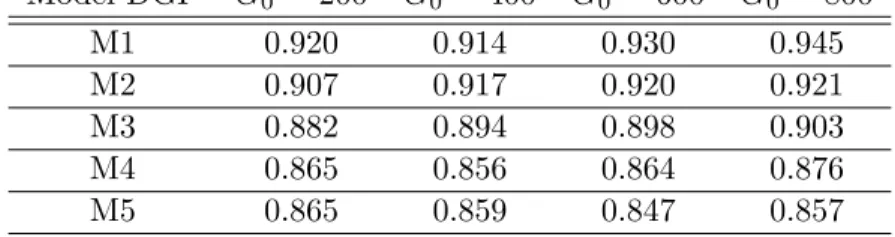
In view of the statistics columns, note that the lasso estimator after double selection is well behaved at larger sample sizes (eg, N, M ≥20) in terms of both bias and variance. In all measures of slave exports, the original estimates and our lasso estimates are similar with similar levels of statistical significance. These results demonstrate that, even for flexible model specifications involving high-dimensional covariates, the proposed method allows producing qualitatively similar results without extensive loss of significance, and thus we can further confirm the robustness of key empirical findings by NunnWantchekon11 .
Pre-Colonial Institutions and Regional Developments in Africa
Conclusion
We demonstrate that our method can enrich the flexibility of regression models and the robustness of empirical results with some empirical applications in growth and development economics. Indeed, both multivariate clustering and high dimensionality are two important issues that concern applied research. To the best of our knowledge, the literature does not seem to offer a solution to both questions simultaneously.
Appendix
Mathematical Proofs
Using Cauchy-Schwartz's inequality with assumptions 18 (1) and 11 (1), the first term in the variance can be bounded as Under Assumptions 18 (1) and 11 (1) similar calculations can be performed to the square root of the second term to obtain Similarly, using Cauchy-Schwartz's inequality, Theorem 2.1, Assumptions and 12 (2), and the addition rate conditions in the statement of the theorem, we obtain.
Auxiliary Lemmas
Confidence Intervals for Low-Dimensional Parameters in High-Dimensional Linear Models.” Journal of the Royal Statistical Society: Series B (Statistical Methodology), 76, no. To the best of our knowledge, this paper is the first to discuss generic DML methods in multi-way cluster sampling. Another branch of literature, following the seminal work of CGM11, proposes robust inference methods for multidirectional clusters.
Relations to the Literature
DDG18 develops empirical process theory under multi-way cluster sampling applicable to a large class of models. We advance this practically important literature by developing a multi-way cluster robust inference method based on DML. To our knowledge, there are no general machine learning-based procedures with known validity under multi-path cluster sampling environments.
Overview
Setup
On the other hand, coping with cross-sectional dependence using a robust multivariate group variance estimator is a relatively recent phenomenon. We say that Neyman's orthogonality condition holds on (θ0, η0) with respect to a realization set of the perturbation Tn⊂T if the result ψ satisfies (3.2.1), the path derivativeDr[η−η0] exists for all r ∈[0, 1) and η∈ Tn, and the orthogonality equation. Moreover, we also say that the condition λn Neyman close to orthogonality holds in (θ0, η0) with respect to a set of perturbation realizations Tn ⊂ T if the result ψ satisfies (3.2.1), there exists the path derivativeDr[η −η0]. for allr ∈[0,1) and η∈ Tn, and the orthogonality equation.
The Multiway Double/Debiased Machine Learning
In this setup, the true value of the low-dimensional target parameter, denoted by θ0 ∈Θ, is the object of interest. Throughout, we will consider structural models that satisfy the moment constraint (3.2.1) and either form of the Neyman orthogonality conditions (3.2.2) or (3.2.3). That said, we focus on this current estimator following their simulation finding that DML2 outperforms their DML1 in most situational settings due to the stability of the scoring function.
Example: Partially Linear IV Model with Multiway Cluster Sample
Note that for each (k, `)∈[K]2 , the estimate of the nuisance parameter ηbk` is calculated using a subsample of these observations with polynomial indices (i, j)∈ ([N]\Ik)×([M] \J `), and then the resulting term En,k`[ψ(W;·,ηbk`)] is calculated using a subsample of these observations with polynomial indices (i, j) ∈Ik×J`. Since Dij usually consists of the endogenous price of product i in market j, researchers often instrument Zij such that E[ij|Xij, Zij] = 0. Specifically, for each product i, {Wij}Mj=1 is likely to depend on supply shock from the product manufacturer i.
Theory of the Multiway DML
It imposes some high-level conditions on the quality of the gene parameter estimator as well as the non-degeneracy of the asymptotic variance. The following result presents the main theorem of this paper that establishes the linear representation and asymptotic normality of the multiway DML estimator. As in Section 3.4 of CCDDHNR (CCDDHNR18), we can also repeatedly calculate multiway DML estimates and variance estimates S times for some fixedS ∈N and consider the mean or median of the estimates as the new estimate.
Simulation Studies
Simulation Setup
Results
Empirical Illustration: Demand Analysis with Market Share Data
Therefore, we apply Algorithm 3.2.1 in Section 3.2.3 for the two-way cluster robust DML estimate of θ0 with a robust standard error. For each of the zero, one-way, and two-way cluster robust DML, both the point estimates and standard errors are the same across all choices of instrument. Furthermore, the point estimates are also similar across all the null, one-way, and two-way clustering robust DML.
Conclusion
To highlight the effect of cluster assumptions, we report estimates and standard errors under the zero-way cluster-robust DML (based on the i.i.d. assumption) and the one-way cluster-robust DML (based on clustering along each of the product and market dimensions), as well as the two-way cluster-robust DML (along both product and market dimensions). The number K= 4 folds of cross-matching is used for the robust DML with zero and one-way cluster, while the number K2 = 4 folds of two-way cross-fitting is used for the robust DML with two-way clusters, according to the recommendations of section 3.4 and those of CCDDHNR ( CCDDHNR18, note 3.1). In other words, the zero-way cluster robust DML reports the smallest standard error, while the two-way cluster robust DML reports the largest standard error.
Appendix
Proofs of the Main Results
Remember that q ≥4, the third moments of both summands of Hnψ¯ are bounded above under assumptions 19(v) and 20 (ii) (iv). An application of Lyapunov's CLT and Cramer-Wold unit yields Hnψ¯ N(0, Idθ), and an application of Theorem 2.7 ofvdV98 completes the proof. Note that all singular values of J0 are bounded from above by c1 under Assumption 19 (v), and all eigenvalues of Γ are bounded from below by c0 under Assumption 20 (iv).
Useful Lemmas
Inference in high-dimensional panel models with an application to arms control. Journal of Business and Economic Statistics, 34, no. Oracle Inequalities, Variable Selection, and Uniform Inference in High-Dimensional Correlated Random Effects Panel Data Models.” Journal of Econometrics, 195, no. Uniform Inference in Dynamic High-Dimensional Panel Data Models with Approximate Sparse Fixed Effects.” Econometric Theory 35, no.