Misalnya data suatu objek berwarna merah, maka data yang dikumpulkan peneliti juga berwarna merah. Cleaning (pembersihan data) merupakan kegiatan memeriksa data yang telah dimasukkan kembali apakah ada kesalahan atau tidak.
ENTRY DATA
File: Digunakan untuk membuat file data baru, membuka file data tersimpan (ekstensi SAV) atau membaca file data dari program lain seperti dbase, excel, dll. Analisis: digunakan untuk memilih prosedur statistik yang berbeda, dari statistik sederhana (deskriptif) hingga analisis statistik kompleks (multivariat).
Langkah pertama : Memberi/membuat nama variabel
- Geser kekanan ke kolom Value, isikan koding 0=tdk eksklusive 1=eksklusive
- Geser kekanan ke kolom Decimal, untuk variabel HB1 sesuai dengan datanya, ada satu desimal, maka isikan angka 1
- Geser kekanan ke kolom Decimal, untuk variabel HB2 sesuai dengan datanya, ada satu desimal, maka isikan angka 1
4. Tarik ke kanan pada kolom Nilai, masukkan enkripsi 0=berfungsi 1=tidak berfungsi Proses pembuatan variabel job selesai. 2. Geser ke kanan pada kolom Desimal, masukkan 0. 3. Geser ke kolom Label, masukkan: Berat Badan Bayi 4. Abaikan kolom Nilai.
Memasukkan/entry Data
- Menghapus isi sel satu kolom (menghapus variabel)
- Menghapus baris (menghapus case/responden)
- Mengcopy isi sel
- Mengcopy isi satu kolom (mengcopy variabel)
- Menyisipkan Kolom
- Menyisipkan Baris
Untuk menghapus isi sel beberapa kolom sekaligus, pilih beberapa kolom dengan cara drag (menyorot dan memblokir) dengan mouse pada bagian judul. Klik nomor kasus yang ingin dituju atau pindahkan penunjuk sel ke kolom Klik nomor kasus yang ingin disalin.
SPSS menambahkan ekstensi ".sav" sehingga Anda hanya perlu mengetikkan nama file dan bukan ekstensinya.
TRANSFORMASI / MODIFIKASI DATA
Dari uraian di atas terlihat jelas bahwa seringkali kita tidak bisa melakukan analisis secara langsung, kita harus mengubah/mentransformasi datanya. Dari contoh definisi operasional di atas terlihat bahwa variabel 'Masa Kerja' dapat langsung dianalisis, sedangkan variabel usia dan sikap masih perlu dimodifikasi/ditransformasikan dengan SPSS.
Mengelompokkan data
Membuat variabel baru hasil perhitungan matematik
Membuat variabel baru dengan kondisi
Memilih sebagian data (SUBSET)
MENGGABUNG FILE DATA
Menyimpan hasil olahan/hasil analisis
Hasil analisis akan disimpan pada jendela keluaran seperti terlihat pada gambar di bawah ini. Di jendela keluaran ini, Anda juga dapat menggunakan operasi pengeditan teks yang umum digunakan seperti Potong, Salin, dan Tempel.
Frequencies
3 UJI INSTRUMEN
Uji validitas dan Reliabilitas Kuesioner
Sebaliknya, pengukuran yang dilakukan dengan kaki kemungkinan besar akan memberikan hasil yang berbeda jika pengukuran diulang dua kali atau lebih. Umumnya pengukuran dilakukan dengan menggunakan One Shot dengan beberapa pertanyaan.Pengujian reliabilitas diawali dengan terlebih dahulu memeriksa validitas.
KASUS
Uji Interrater Reliability
Dalam melakukan penelitian dengan metode observasi, seringkali terdapat perbedaan persepsi antara peneliti dan enumerator (pengumpul data) terhadap peristiwa yang diamati. Uji reliabilitas antar penilai merupakan jenis tes yang digunakan untuk menyamakan persepsi antara peneliti dan petugas pengumpulan data.
4 ANALISIS DATA PENGANTAR
Pertanyaan penelitiannya adalah “Adakah perbedaan kinerja tenaga kesehatan sebelum dan sesudah mendapat pelatihan manajemen?”. Dalam penelitian ini kelompok sampel tenaga kesehatan bersifat dependen, karena kelompok (orang) yang sama diukur dua kali yaitu sebelum pelatihan (pre-test) dan setelah pelatihan (post-test).
Sedangkan uji yang digunakan untuk penelitian eksperimen yang bersifat pre dan post alam (sebelum dan sesudah dilakukan pengukuran perlakuan tertentu) adalah uji statistik terhadap data dependen.
ANALISIS UNIVARIAT
DESKTIPTIF)
Peringkasan Data Untuk Data Jenis Numerik a. Ukuran Tengah
Namun kelemahan mean adalah sangat dipengaruhi oleh nilai-nilai ekstrim, baik ekstrim tinggi maupun rendah. Oleh karena itu, pada kelompok data yang mempunyai nilai ekstrim (sering disebut dengan 'distribusi data miring'), mean tidak dapat mewakili rata-rata dari kumpulan nilai yang diamati. Oleh karena itu tidak tepat menggunakan mean untuk data yang mempunyai nilai ekstrim (data yang distribusinya miring).
Bentuk Distribusi Data
Peringkasan Data Katagorik
Di kelas B, jenis kelamin siswanya tidak berbeda-beda (homogen untuk laki-laki), karena 90% laki-laki dan hanya 10% perempuan.
Bentuk Penyajian Data
Eksplorasi data juga dapat mendeteksi outlier/pencilan, jika ada outlier justru menentukan apakah nilainya akan menurun pada analisis selanjutnya (bivariat).
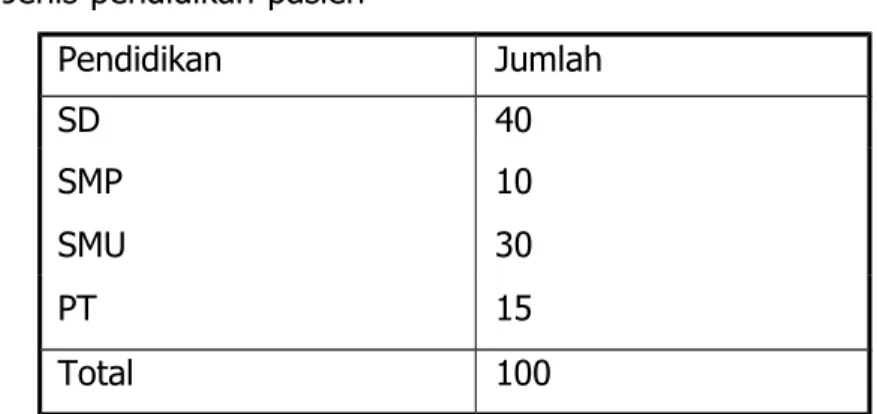
Pada contoh di atas jumlah responden sebanyak 50 orang, dari jumlah tersebut 10 ibu berpendidikan SD, proporsinya dapat dilihat pada kolom 'Persen', pada contoh di atas terdapat 20% ibu yang berpendidikan SD. pendidikan sekolah. Kolom 'Persen Valid' memberikan hasil yang sama karena tidak ada 'kasus yang hilang' dalam data ini.
Penyajian dan Interpretasi di Laporan Penelitian
Frekuensinya sangat lengkap (seperti mean, median, variance, dll), selain itu perintah ini juga dapat menampilkan grafik histogram dan kurva normal. Klik 'OK', dan di layar Anda akan melihat distribusi frekuensi beserta pengukuran statistik yang diminta dan di bawahnya Anda akan melihat grafik histogram beserta kurva normal. Dari hasil diatas, nilai mean dapat dilihat pada baris mean, sedangkan nilai standar deviasi dapat dilihat pada baris standar.
Explore
Dilihat dari grafik histogram dan kurva normalnya, jika bentuknya menyerupai bentuk lonceng berarti distribusinya normal. Berdasarkan kelemahan tersebut, disarankan untuk menggunakan angka skewness atau melihat grafik histogram dan kurva normal untuk mengetahui normalitas data. Dilihat dari histogram dan kurva normalnya, terlihat bahwa variabel umur diatas berbentuk normal. Selain itu, hasil perbandingan skewness dan standard error menunjukkan hasil masih dibawah 2 artinya distribusinya normal.
ANALISIS BIVARIAT
Perbedaan Substansi/Klinis dan perbedaan Statistik
Misalnya, ada penelitian eksperimental di mana dua obat (misalnya obat A dan obat B) diuji untuk mengetahui pengaruhnya terhadap penurunan tekanan darah. Secara statistik terdapat perbedaan yang signifikan, namun secara substantif tidak terdapat perbedaan yang signifikan, karena perbedaan rata-rata penurunan tekanan darah antara obat A dan B hanya 1 mmHg. Dengan hasil tersebut dapat disimpulkan bahwa sebenarnya tidak ada perbedaan (sama) khasiat antara obat A dan B.
UJI HIPOTESIS
- Hipotesis
- Arah dan bentuk hipotesis
- Menentukan Tingkat Kemaknaan ( Level of Significance )
- Pemilihan Jenis Uji Parametrik atau Non Parametrik
Bentuk hipotesis alternatif akan menentukan arah uji statistik apakah satu arah (one tail) atau dua arah (two tail). Dari hipotesis alternatif tersebut akan diketahui apakah uji statistiknya menggunakan satu arah (one tail) atau dua arah (two tail). Berikut beberapa uji statistik yang dapat digunakan untuk analisis bivariat. Variabel I Variabel II Jenis uji statistik.
7 ANALISIS BIVARIAT HUBUNGAN KATAGORIK DENGAN NUMERIK
Uji t
Uji beda dua mean independen
Oleh karena itu, pengujian ini memerlukan informasi apakah varians kedua kelompok yang diuji sama atau tidak. Bentuk varians kedua kelompok data akan mempengaruhi nilai standar error yang pada akhirnya akan membedakan rumus pengujian. Tujuan pengujian ini adalah untuk mengetahui apakah varians antara kelompok data pertama sama dengan kelompok data kedua.
Uji beda dua mean dependen (Paired sample)
Pada perhitungan uji F, varian yang lebih besar adalah pembilangnya dan varian yang lebih kecil adalah penyebutnya.
UJI t INDEPENDEN DAN UJI t DEPENDEN
Test
- Uji T Dependen
Pada tabel pertama, Anda dapat melihat statistik deskriptif berupa mean dan deviasi standar kadar Hb antara pengukuran pertama dan pengukuran kedua. Pada pengukuran kedua (Hb2), rata-rata kadar Hb sebesar 10,860 gr% dengan standar deviasi 1,05 gr%. Pada contoh di atas diperoleh p-value = 0,001 sehingga dapat disimpulkan terdapat perbedaan kadar HB yang signifikan antara pengukuran pertama dan pengukuran kedua.
8 ANALISIS HUBUNGAN
KATEGORIK DENGAN NUMERIK
ANOVA
Analisis varians (ANOVA) mempunyai dua jenis analisis varians: satu hala (sehala) dan analisis faktor (dua hala).
Kasus
Oneway
Post Hoc Tests
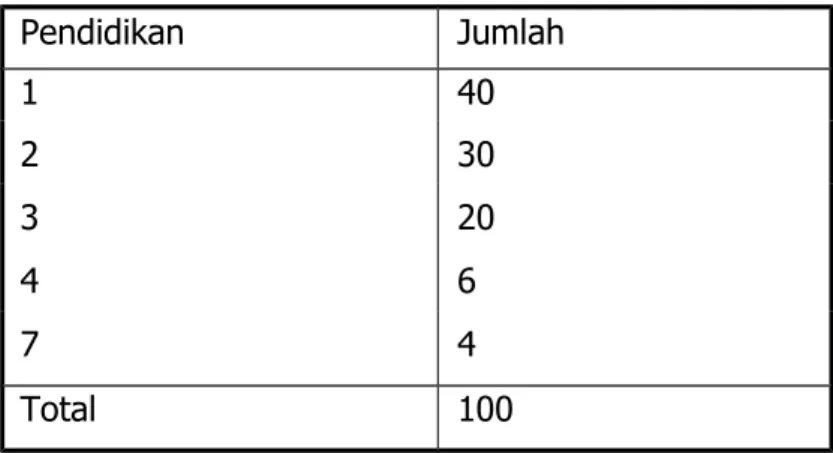
Pada hasil diatas, nilai p uji ANOVA terlihat pada kolom “F” dan “Sig”, terlihat p = 0,000 (jika koma desimal 0 ditulis p = 0,0005), yang mana artinya dengan alpha sebesar 5% dapat disimpulkan terdapat perbedaan berat badan bayi antara keempat jenjang pendidikan. Ternyata kelompok signifikan tersebut adalah jenjang pendidikan SD dengan SMP, SD dengan PT, SMP dengan SMA, SMP dengan PT, dan SMA dengan PT.
Pada yang mendapat pelatihan PT, rerata berat badan bayi adalah 3761,5 gram dengan standar deviasi 386,3 gram. Hasil uji statistik diperoleh nilai p=0,0005 yang berarti pada alpha 5% dapat disimpulkan terdapat perbedaan berat badan bayi antara keempat jenjang pendidikan. Analisis lebih lanjut membuktikan bahwa kelompok yang berbeda secara signifikan adalah SD dan SMA, SD dan SMA, SMP dan SMA, SMP dan SMA, serta SMA dan SMA.
9 ANALISIS HUBUNGAN
KATAGORIK DENGAN KATAGORIK
Tujuan penggunaan uji chi-square adalah untuk menguji perbedaan proporsi/persentase antara beberapa kelompok data. Sedangkan khusus untuk tabel 2 x 2 (df = 1) sebaiknya menggunakan uji chi-kuadrat terkoreksi (Yate Corrected atau Yate's Correction). Sebagaimana kita ketahui, uji chi-square mensyaratkan frekuensi harapan/ekspektasi (E) pada setiap selnya tidak boleh terlalu kecil.
ODDS RATIO (OR) dan RISIKO RELATIF (RR)
Contoh di atas merupakan jenis penelitian cross sectional, variabel pendidikan sebagai variabel bebas dan pengetahuan sebagai variabel terikat. Sementara itu, pada kelompok yang tidak menderita kanker paru-paru, jumlah laki-laki yang disurvei sama banyaknya (30%). Pada menu tab silang terdapat dua kolom yang harus diisi, masukkan variabel bebas pada kolom "Baris". Dalam hal ini, variabel tugas masuk ke kolom "Baris".
Crosstabs
Untuk mengetahui apakah ada nilai E yang kurang dari 5, dapat dilihat pada footnote b di bawah kotak Uji Chi-Square dan tertulis di atas nilainya adalah 0 sel (0%), yang berarti pada crosstab di atas tidak ada nilai E < Ditemukan 5. Beginilah cara kita menggunakan uji Chi, Kotak yang telah dikoreksi (Koreksi Kontinuitas) dengan nilai p dapat dilihat pada kolom. Uji chi-square hanya dapat digunakan untuk mengetahui ada tidaknya hubungan antara dua variabel, sehingga uji ini tidak dapat mengetahui derajat/kuatnya hubungan antara dua variabel.
ANALISIS HUBUNGAN
NUMERIK DENGAN NUMERIK
Korelasi
Korelasi positif terjadi bila peningkatan suatu variabel diikuti dengan peningkatan variabel lainnya, misalnya semakin banyak berat badan (semakin gemuk), maka tekanan darah pun semakin tinggi. Untuk lebih mengetahui secara pasti besaran/derajat korelasi dua variabel digunakan Koefisien Korelasi Pearson Product Moment. Koefisien korelasi yang dihasilkan merupakan langkah awal dalam menjelaskan derajat hubungan linier antara dua variabel.
Regresi Linier Sederhana
Besar kecilnya kesalahan baku penduga (Se) menunjukkan keakuratan persamaan penduga dalam menjelaskan nilai sebenarnya dari variabel terikat. Semakin kecil nilai Se maka semakin tinggi keakuratan persamaan estimasi yang dihasilkan dalam menjelaskan nilai sebenarnya dari variabel terikat. Dan sebaliknya, semakin besar nilai Se maka semakin rendah keakuratan persamaan penduga yang dihasilkan dalam menjelaskan nilai sebenarnya dari variabel terikat.
Korelasi
Correlations
Regresi Linier Sederhana
Regression
Nilai koefisien determinasi dilihat dari nilai R Square (dapat dilihat pada tabel 'Model Summary') yaitu sebesar 0,468 yang berarti persamaan garis regresi yang kita peroleh dapat menjelaskan 46,8% variasi berat badan bayi atau garis Persamaan yang diperoleh cukup baik untuk menjelaskan variabel berat badan bayi. Dengan persamaan tersebut maka berat badan anak dapat diperkirakan jika kita mengetahui nilai berat badan ibu. Nilai b = 44,38 artinya variabel berat badan anak akan bertambah sebesar 44,38 gram jika berat badan ibu bertambah setiap kilogramnya.
Memprediksi variabel Dependen
Membuat Grafik Prediksi Langkahnya
ANALISIS MULTIVARIAT
12 REGRESI LINIER GANDA ANALISIS
- Asumsi Regresi Linier
- Kegunaan Analisis Regresi Ganda
- Pemodelan
- Melakukan diagnostik regresi linier,
Misalnya, kami melakukan analisis terhadap variabel independen usia, berat badan, dan jenis kelamin dalam kaitannya dengan variabel dependen tekanan darah. Pasalnya, dengan memasukkan sebanyak mungkin variabel independen ke dalam model, maka variabel dependen diharapkan dapat diprediksi dengan sempurna. HAPUS, menghapus semua variabel independen secara bertahap, tanpa memenuhi kriteria signifikansi statistik tertentu.
- Merokok
- Riwayat Hipertensi
Uji Korelasi Bivariat: Lakukan analisis bivariat untuk variabel independen numerik: berat badan ibu, usia ibu, angka prematuritas, angka ANC. Pada kotak Variables, isikan semua variabel numerik baik untuk variabel independen (usia, lwt, ptl, ftv) maupun variabel dependen (bwt). Dengan demikian pemilihan seluruh variabel independen selesai, keenam variabel independen tersebut lanjut ke proses selanjutnya yaitu ke analisis multivariat.
Pada kotak Independen masih terdapat 6 variabel lengkap, namun sekarang Anda perlu menghilangkan variabel 'tidak ada dokter' dan memasukkannya ke dalam kotak Variabel di sebelah kiri. Dari perhitungan perubahan nilai koefisien B tiap variabel terlihat tidak ada perubahan lebih dari 10%, sehingga variabel frekuensi ANC kami keluarkan dari model. Hasil perhitungan setelah dikeluarkan variabel prematuritas, ternyata koefisien B variabel berat badan (bbt) ibu mengalami perubahan sebesar 12,3%, sehingga variabel riwayat mengalami prematuritas tidak dikeluarkan dan tetap dipertahankan dalam model multivariat.
Dari hasil uji hipotesis dan uji kolinearitas ternyata semua asumsi terpenuhi sehingga model dapat digunakan untuk memprediksi berat badan bayi. Dengan model persamaan ini kita dapat memperkirakan berat badan bayi dengan menggunakan variabel berat badan ibu, kebiasaan merokok dan hipertensi. Ibu dengan hipertensi akan mempunyai berat badan lahir lebih rendah sebesar 582,5 gram setelah dilakukan kontrol terhadap variabel berat badan ibu, kebiasaan merokok, dan prematuritas.
REGRESI LOGISTIK
REGRESI LOGISTIK SEDERHANA 1. Pendahuluan
Regresi logistik juga dapat mengatasi hal ini, namun terdapat sedikit perbedaan saat menghitung mean variabel dependen (Y). Model regresi logistik dapat digunakan pada data yang dikumpulkan melalui desain kohort, kasus-kontrol, atau cross-sectional. Dalam desain kohort prospektif, regresi logistik dapat digunakan untuk memprediksi/memperkirakan kemungkinan seseorang untuk sakit (atau meninggal) berdasarkan nilai sejumlah variabel yang diukur dalam dirinya.
Method = Enter
- Analisis bivariat antara “ras” dengan “bblr”
- Analisis bivariat antara “hipertensi” dengan “bblr”
- Analisis bivariat antara “kelainan uterus” dengan “bblr”
- Analisis bivariat antara “periksa hamil” dengan “bblr”
- Analisis bivariat antara “merokok” dengan “bblr”
- Analisis bivariat antara “prematur” dengan “bblr”
Pada kotak Dependent masih berisi “layer” dan pada kotak Covariate variabel “usia” dihilangkan dan diganti dengan memasukkan variabel “ras”. Hasil pengujiannya adalah p-value = 0,379 (p-value > 0,25) sehingga secara statistik tidak bisa terus bersifat multivariat, namun karena variabel pengendalian kehamilan pada hakikatnya sangat penting maka variabel ini dapat dianalisis secara multivariat. Hasil analisis menunjukkan p-value sebesar 0,009 yang berarti < 0,25 sehingga variabel riwayat prematuritas dapat dimasukkan ke dalam multivariat.
Logistic Regression
Setelah variabel umur dihilangkan, kita periksa kembali perubahan OR untuk variabel yang masih aktif dalam model. Ternyata setelah PTL dihilangkan, OR variabel merokok dan kelainan rahim berubah >10%, sehingga variabel PTL dimasukkan kembali ke dalam model. Setelah melakukan perbandingan OR, ternyata variabel ht berubah >10%, sehingga variabel ui masuk kembali ke dalam model.
Method = Enter