Power System Operation
Thesis by
Yujie Tang
In Partial Fulfillment of the Requirements for the Degree of
Doctor of Philosophy
CALIFORNIA INSTITUTE OF TECHNOLOGY Pasadena, California
2019
Defended January 4, 2019
© 2019 Yujie Tang
ORCID: 0000-0002-4921-8372 All rights reserved
ACKNOWLEDGEMENTS
My years at Caltech have truly been a precious experience and have shaped my research style. Foremost, I would like to express my sincere gratitude to my advisor, Professor Steven Low, for his generous support and invaluable guidance through my studies and research. Steven has always inspired me by his passion, intelligence, pa- tience, and hardworking attitude. His philosophy of research has greatly influenced my thoughts and is something I will always admire and try to emulate in my future career.
I would also like to thank Professor Adam Wierman, Professor Venkat Chan- drasekaran, and Professor Babak Hassibi for being my thesis committee members and providing brilliant comments and suggestions.
My sincere thanks also go to Professor Emiliano Dall’Anese at University of Col- orado Boulder and Andrey Bernstein at National Renewable Energy Laboratory for their strong support of my research. It has always been a great pleasure to work with them.
I greatly appreciate the support from current and previous members of Netlab. My early years at Caltech would not have been smooth without the help from Lingwen Gan, Changhong Zhao, Qiuyu Peng, and Niangjun Chen. Discussions with Daniel Guo and John Pang have always been enlightening and valuable. It is also pleasing to see younger generations of Netlab making great contributions to state-of-the-art research, stimulating me to gain more confidence and diligence.
Finally, I would like to thank my parents Yongcheng Tang and Diqiu Yu for their unconditional love and support throughout my life.
ABSTRACT
The main topic of this thesis is time-varying optimization, which studies algorithms that can track optimal trajectories of optimization problems that evolve with time. A typical time-varying optimization algorithm is implemented in a running fashion in the sense that the underlying optimization problem is updated during the iterations of the algorithm, and is especially suitable for optimizing large-scale fast varying systems. Motivated by applications in power system operation, we propose and analyze first-order and second-order running algorithms for time-varying nonconvex optimization problems.
The first-order algorithm we propose is the regularized proximal primal-dual gradi- ent algorithm, and we develop a comprehensive theory on its tracking performance.
Specifically, we provide analytical results in terms of tracking a KKT point, and derive bounds for the tracking error defined as the distance between the algorithmic iterates and a KKT trajectory. We then provide sufficient conditions under which there exists a set of algorithmic parameters that guarantee that the tracking error bound holds. Qualitatively, the sufficient conditions for the existence of feasible parameters suggest that the problem should be “sufficiently convex” around a KKT trajectory to overcome the nonlinearity of the nonconvex constraints. The study of feasible algorithmic parameters motivates us to analyze the continuous-time limit of the discrete-time algorithm, which we formulate as a system of differential inclu- sions; results on its tracking performance as well as feasible and optimal algorithmic parameters are also derived. Finally, we derive conditions under which the KKT points for a given time instant will always be isolated so that bifurcations or merging of KKT trajectories do not happen.
The second-order algorithms we develop are approximate Newton methods that incorporate second-order information. We first propose the approximate Newton method for a special case where there are no explicit inequality or equality con- straints. It is shown that good estimation of second-order information is important for achieving satisfactory tracking performance. We also propose a specific version of the approximate Newton method based on L-BFGS-B that handles box con- straints. Then, we propose two variants of the approximate Newton method that handle explicit inequality and equality constraints. The first variant employs penalty functions to obtain a modified version of the original problem, so that the approx- imate Newton method for the special case can be applied. The second variant can
be viewed as an extension of the sequential quadratic program in the time-varying setting.
Finally, we discuss application of the proposed algorithms to power system operation.
We formulate the time-varying optimal power flow problem, and introduce partition of the decision variables that enables us to model the power system by an implicit power flow map. The implicit power flow map allows us to incorporate real-time feedback measurements naturally in the algorithm. The use of real-time feedback measurement is a central idea in real-time optimal power flow algorithms, as it helps reduce the computation burden and potentially improve robustness against model mismatch. We then present in detail two real-time optimal power flow algorithms, one based on the regularized proximal primal-dual gradient algorithm, and the other based on the approximate Newton method with the penalty approach.
PUBLISHED CONTENT AND CONTRIBUTIONS
[1] Y. Tang, E. Dall’Anese, A. Berstein, and S. Low. Running primal-dual gradient method for time-varying nonconvex problems, 2018, arXiv:1812.00613. URL https://arxiv.org/abs/1812.00613.
Y. Tang participated in formulating the problem and proposing the algorithm, derived the theorerical results, prepared the simulation, and participated in the writing of the manuscript.
[2] Y. Tang, E. Dall’Anese, A. Berstein, and S. H. Low. A feedback-based regularized primal-dual gradient method for time-varying nonconvex opti- mization. In Proceedings of the 57th IEEE Conference on Decision and Control (CDC), pages 3244–3250, Miami Beach, FL, USA, Dec. 2018.
doi:10.1109/CDC.2018.8619225.
Y. Tang participated in formulating the problem, proposing the algorithm, and deriving the theoretical results, prepared the simulation, and participated in the writing of the manuscript.
[3] Y. Tang, K. Dvijotham, and S. Low. Real-time optimal power flow. IEEE Transactions on Smart Grid, 8(6):2963–2973, 2017.
doi:10.1109/TSG.2017.2704922.
Y. Tang participated in formulating the problem, proposed and analyzed the algo- rithm, prepared the simulation, and participated in the writing of the manuscript.
[4] Y. Tang and S. Low. Distributed algorithm for time-varying optimal power flow. In Proceedings of the 56th IEEE Conference on Decision and Control (CDC), pages 3264–3270, Melbourne, VIC, Australia, Dec. 2017.
doi:10.1109/CDC.2017.8264138.
Y. Tang participated in formulating the problem, proposed the distributed algo- rithm, prepared the simulation, and participated in the writing of the manuscript.
TABLE OF CONTENTS
Acknowledgements . . . iii
Abstract . . . iv
Published Content and Contributions . . . vi
Bibliography . . . vi
Table of Contents . . . vii
List of Illustrations . . . viii
List of Tables . . . ix
Chapter I: Introduction . . . 1
1.1 Overview of Time-Varying Optimization . . . 1
1.2 Review of Existing Works . . . 8
1.3 Organization of the Thesis . . . 14
1.4 Notations and Terminologies . . . 17
Chapter II: First-Order Algorithms for Time-Varying Optimization . . . 22
2.1 Problem Formulation . . . 22
2.2 Regularized Proximal Primal-Dual Gradient Algorithm . . . 26
2.3 Tracking Performance . . . 27
2.4 Continuous-Time Limit . . . 38
2.5 Summary . . . 53
2.A Proofs . . . 54
Chapter III: Second-Order Algorithms for Time-Varying Optimization . . . . 82
3.1 Problem Formulation . . . 82
3.2 Approximate Newton Method: A Special Case . . . 82
3.3 Approximate Newton Method: The General Case . . . 89
3.4 Comparison of First-Order and Second-Order Methods . . . 101
3.5 Summary . . . 103
3.A Proofs . . . 103
Chapter IV: Applications in Power System Operation . . . 109
4.1 The Time-Varying Optimal Power Flow Problem . . . 109
4.2 A First-Order Real-Time Optimal Power Flow Algorithm . . . 119
4.3 A Second-Order Real-Time Optimal Power Flow Algorithm . . . 131
4.4 Summary . . . 145
Chapter V: Concluding Remarks on Future Directions . . . 147
Bibliography . . . 151
LIST OF ILLUSTRATIONS
Number Page
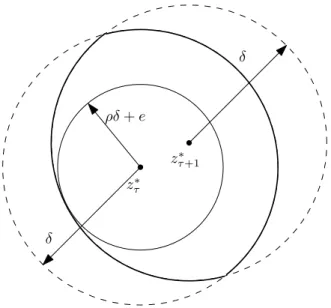
1.1 The distances to the optimal trajectory kxb(t) − x∗(t)k and kxr(t) − x∗(t)k, and the objective value differencesc(xb(t),t) −c(x∗(t),t)and c(xr(t),t) −c(x∗(t),t)of the two optimization schemes. . . 6 2.1 Illustration of condition (2.25). This condition is essentially on: (i)
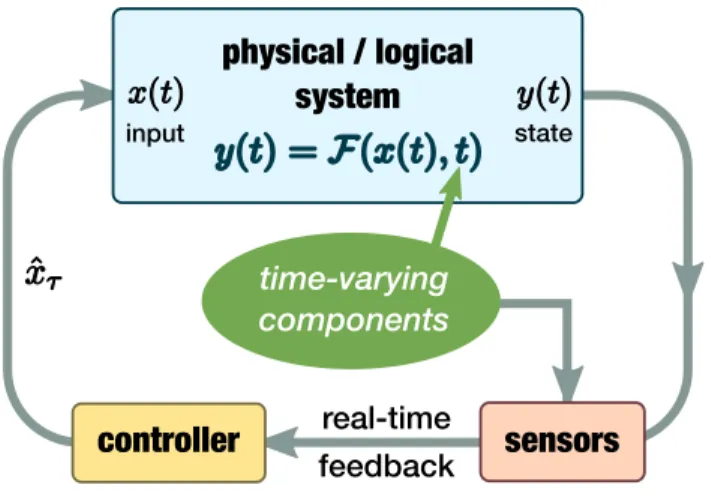
time-variability of a KKT point, (ii) extent of the contraction, and (iii) maximum error in each iteration. Note that in the error-less static case (i.e.,ση =e= 0), this condition is trivially satisfied. . . 31 4.1 Diagram of the control of a time-varying system. The system’s input-
state relation is given byF, which is influenced by some time-varying components. . . 116 4.2 Topology of the distribution test feeder. . . 127 4.3 Profiles of individual loads pLτ,i,i ∈ N, total loadÍ
i∈N pLτ,i and total photovoltaic (PV) generationÍ
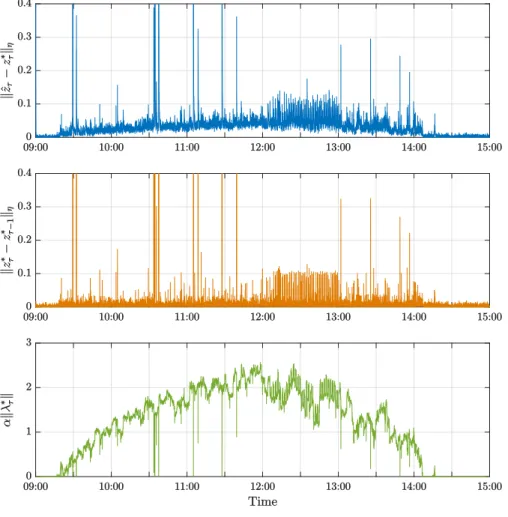
i∈NPVpPVτ,i. . . 128 4.4 Illustrations of
zˆτ −z∗τ η,
zτ∗−z∗τ−1
ηandα λτ∗
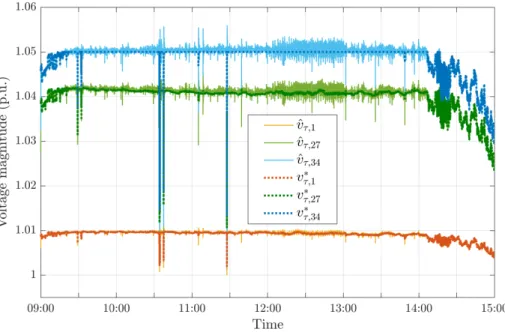
. . . 129 4.5 The voltage profiles ˆvτ,iandv∗τ,ifori =1, 27 and 34. . . 130 4.6 Load profiles used for simulation. . . 143 4.7 Illustrations ofkxˆτ−x∗,pτ k, kx∗,pτ −xτ−1∗,p k,(Fτ(xτ∗,p) −Fτ(xˆτ))/Fτ(xτ∗,p)
andFτ(x∗,pτ ). . . 144 4.8 Voltage profiles of the buses whose voltages have ever violated the
constraints 0.94 ≤ vi ≤ 1.06 for some t. . . 145
LIST OF TABLES
Number Page
3.1 Averaged tracking errors of the first-order method and the second- order method applied to the problem (3.34). . . 102 4.1 The locations and normalized areas of the PV panels, and the rated
apparent power of their inverters. . . 127
C h a p t e r 1
INTRODUCTION
1.1 Overview of Time-Varying Optimization
Suppose we are given a physical or logical system, and for each time t ∈ [0,T], the optimal operation of the system can be modeled as the following optimization problem:
minx c(x,t)
s.t. f(x,t) ≤ 0. (1.1)
Here x ∈ Rn is the decision variable that will be applied for operating the system, c(x,t)is the objective function, and f(x,t)gives the constraints at timet. It can be seen that (1.1) gives an optimization problem that evolves with time. We focus on the situations where the maps x 7→ c(x,t) and x 7→ f(x,t) will only be revealed at timet and their prior predictions are not available. This is a typical setting of a time-varying optimization problem.
In most situations where digital computers are used to solve this problem, we discretize the period[0,T]by a sequence(tτ)Kτ=1satisfying 0 < t1 < . . . < tK ≤ T, and obtain the following sequence of sampled problems:
minx cτ(x)
s.t. fτ(x) ≤0, (1.2)
where τ ∈ {1, . . . ,K} labels the discrete time index, and cτ and fτ denote the sampled versionsc(·,tτ)and f(·,tτ). Traditionally, each instance of (1.2) is solved in thebatchscheme abstracted as follows:
For eachτ= 1,2, . . . ,K,
1. Collect problem dataD(tτ)att =tτ, and construct the initial iteratezτ0. 2. Repeat
zτk =T zτk−1;D(tτ)
(1.3) for eachk =1,2, . . .untilzτk convergences to somez∞τ .
3. Letxτ∗ = Πz∞τ , and apply x∗τ to the system of interest.
Here the operator T represents a single iteration of some iterative optimization algorithm, zk denotes the intermediate iterate, D(t) denotes the problem data (ob- jective function and constraints) at time t, and Π is a canonical projection map that extracts an applicable solution from the intermediate iterate. In order for the batch scheme to work smoothly, the iterations (1.3) for each τ should converge before the next sampling instanttτ+1arrives. However, when each sampling interval tτ+1−tτneeds to be very small to fully capture fast-varying costs and constraints and closely approximate the continuous-time optimal trajectory, the batch scheme may not be appropriate as the iterations (1.3) may fail to converge within the interval (tτ,tτ+1). The batch scheme may also break down if each instance of (1.2) is a large-scale problem or the optimization procedure requires heavy communication over a network in a distributed setting, as limited computation resources or high computational complexity may prevent the iterations (1.3) from converging within the interval(tτ,tτ+1).
The operation and control of smart grids is one such example. Technological advances have continuously reduced the cost of sustainable energy, and it is antici- pated that future smart grids will incorporate a large number of distributed energy resources, including renewable generations such as solar panels and wind turbines, as well as small-scale, distributed devices with controllable power injections such as smart inverters, smart appliances, electric vehicles, and distributed energy storage to name a few. On the one hand, renewable generations introduce hard-to-predict fluctuations and uncertainties into the power network, making the operation and control of smart grids challenging. On the other hand, the increasing penetration of distributed controllable devices can provide diverse control capabilities that can be potentially utilized to overcome these challenges. In addition, extensive real-time measurement data will become available through the installation of smart meters and other advanced measurement equipment.
The optimal operation of smart grids can be formulated as a time-varying optimal power flow (OPF) problem, which is generally nonconvex. There is extensive literature on traditional OPF algorithms that solve each instance of (1.2) in the batch scheme; see the survey papers [45, 46] and the tutorial papers [65, 66].
However, these traditional algorithms are computationally burdensome if one needs to handle the fast fluctuations and uncertainties introduced by renewable generations, considering that the number of distributed controllable devices will be large in future smart grids. This motivates us to develop novel technologies for the operation and
control of smart grids.
The operation of smart grids is not the only case where batch solutions can be difficult to obtain or inappropriate for application due to the time-varying nature of the problems. Similar situations can also occur in communication networks [29, 67], robotic networks [25], social networks [8], sparse signal recovery [6, 9], online learning [68, 96], economics [39], etc.
In time-varying optimization, this issue is resolved by designing algorithms that can be implemented in arunningfashion, in the sense that the underlying optimization problem changes during the iterations of the algorithm. In other words, the problem data will be constantly updated regardless of whether the iterations converge to an optimal solution, and a sub-optimal solution can be extracted from the iterations at any time when necessary.
Throughout the thesis we consider the situation where each sampling instant tτ is equal to τ∆ for some ∆ > 0; in other words, we discretize [0,T] by a uniform sampling interval ∆. Then, a running time-varying optimization algorithm for solving (1.1) can be described by the following procedure:
For eachτ= 1,2, . . . ,bT/∆c,
1. Collect problem dataD(τ∆)att = τ∆.
2. Compute
ˆ
zτ =T(zˆτ−1;D(τ∆)), ˆ
xτ = Πzˆτ. (1.4)
3. Apply ˆxτ to the system of interest.
Here ˆzτ ∈ Rd denotes the intermediate iterate, D(t) ∈ Rp represents the problem data (parameters that describe the time-varying objective function, constraints, etc.) at timet. The mapT :Rd×Rp → Rd computes the new iterate from the previous iterate and the problem data, and Π : Rd → Rnis a canonical projection map that extracts an applicable solution from the intermediate iterate. The operatorThas the following features:
1. The computation ofTis relatively inexpensive so that (1.4) can be finished within the interval(τ∆,(τ+1)∆).
2. Suppose X∗(t)is the set of global optimal solutions to (1.1) at time t which is nonempty. Let Tt denote the map x 7→ T(x;D(t)). Then there exist an open
subsetUt ⊆ Rd withX∗(t) ⊂ Π[Ut]and a setKt ⊇ X∗(t)with sup
x∈Kt
inf
x0∈X∗(t)kx−x0k < +∞, such that for any z∈Ut,
Π◦Ttk(z) ∈ Kt
eventually ask → ∞, where
Ttk := Tt◦ · · · ◦Tt
| {z }
ktimes
.
Roughly speaking, this feature ensures that, if we fixt and run the iteration Tt in the batch scheme from a sufficiently good initial point, then in the long run we will get a good sub-optimal solution to (1.1) at timet. In other words, the iteration (1.4) is able to at least properly handle static problems.
In applications, the iteration (1.4) is carried out immediately after the problem data D(τ∆)has been collected, and once a single iteration (1.4) is finished, the solution
ˆ
xτ will be immediately applied to the real world, and one prepares to collect the new problem data at time t = (τ+1)∆. While the solution ˆxτ is in general only sub-optimal, the problem data is updated frequently to keep pace with the time- varying problem, so that the resulting solutions ˆxτ will be able totrackthe optimal trajectory.
The simplest time-varying optimization algorithm is perhaps the running gradient descent algorithm for unconstrained time-varying optimization problems, whose iterations are given by
xˆτ = xˆτ−1−α∇cτ(xˆτ−1).
One can readily recognize that this is exactly a single iteration of the gradient descent algorithm for static optimization problems. In fact, many time-varying optimization algorithms are developed in a similar way, where the operatorTresembles a single iteration of some existing iterative algorithm for static optimization, as the operator Tconstructed in such manner will be very likely to possess the aforementioned two features.
Let’s look at a toy example that illustrates the advantages of employing running time-varying algorithms over batch solutions. Consider the following time-varying optimization problem
min
x∈R2
c(x,t)= 1 2
"
x1−cost x2−sint
#T "
3−2 cos 2t 2 sin 2t 2 sin 2t 3+2 cos 2t
# "
x1−cost x2−sint
#
for t ∈ [0,2π], which models the optimization of some fictitious system that is time-varying. It is easy to recognize that the problem is quadratic and convex for eacht and the trajectory of optimal solution is given by
x∗(t)=
"
cost sint
# .
Let us consider two strategies for solving this problem:
1. The batch scheme: The gradient descent algorithm is employed. Computation of one gradient∇xc(x,t)takes a fixed amount of timeπ/200. Starting fromt = 0, we update the problem data, then run the gradient descent algorithm until the
`∞ norm of the gradient is less than 10−3. Immediately after the iteration has converged, we apply the resulting solution to the fictitious system, increaseτby 1, update the problem data, and restart the iterations with the initial point being the previous solution that has just been calculated. For the fictitious system, the applied setpoint does not change until the next solution arrives.
2. The running scheme: The running gradient descent algorithm is employed, and computation of one gradient∇xc(x,t)takes the same fixed amount of timeπ/200.
After one iteration has been carried out, we immediately apply the iterate to the fictitious system as a sub-optimal solution, increase τby 1, update the problem data, and compute the next iteration. For the fictitious system, the applied setpoint does not change until the next solution arrives.
The initial point att = 0 is(1.01,0), and the step size is 1/3 for both schemes. We assume that apart from the delays caused by the gradient computation, there are no other delays or time spent during the procedure. The two schemes will provide two solution trajectories; we denote the trajectory generated by the batch scheme by xb(t), and denote the trajectory generated by the running scheme by xr(t). They are step functions overt ∈ [0,2π]as can be seen from the setting.
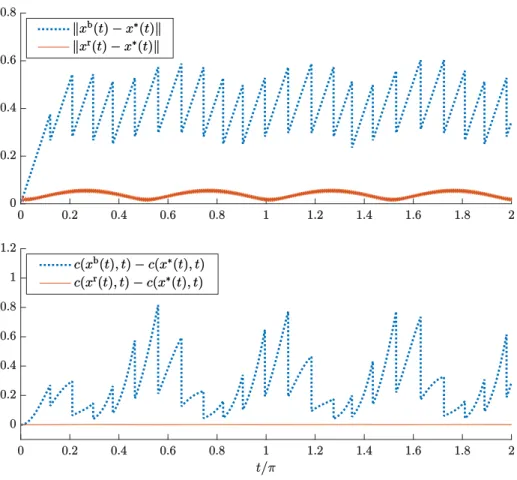
Figure 1.1 shows the curves of the distances to the optimal trajectorykxb(t) −x∗(t)k and kxr(t) − x∗(t)k, and the objective value differencesc(xb(t),t) −c(x∗(t),t) and c(xr(t),t) −c(x∗(t),t). It is apparent that the running scheme achieves much better performance in terms of tracking the time-varying optimal solution. In the batch scheme, it takes quite some time for the iterations to converge, and when a batch solution is applied to the system, the optimization problem has already changed considerably, meaning that the applied solution is not up-to-date. But in the running scheme, since we do not wait for the iterations to converge, we can update the
Figure 1.1: The distances to the optimal trajectorykxb(t)−x∗(t)kandkxr(t)−x∗(t)k, and the objective value differencesc(xb(t),t) −c(x∗(t),t)andc(xr(t),t) −c(x∗(t),t) of the two optimization schemes.
problem data much more frequently, and the resulting setpoints are able to keep track of the fast varying problem. While this toy example has a much simplified setting compared to practical scenarios, it demonstrates the benefits of time-varying optimization algorithms that can become significant in appropriate situations.
Performance Evaluation of Time-Varying Optimization Algorithms
As previously discussed, the solutions provided by time-varying optimization algo- rithms are in general not optimal; instead one focuses on whether and how accurately the solutions cantrackthe optimal solution trajectory. Tracking performanceis cen- tral in evaluating time-varying optimization algorithms.
Let us consider the sampled problem (1.2), and denote x∗τ
τ as a sequence of its (local) optimal solutions1. Suppose we run some time-varying optimization
1We choosexτ∗arbitrarily when there are multiple local optimal solutions to (1.2).
algorithm and obtain a sequence of solutions denoted by (xˆτ)τ. So far in existing literature, three types of quantities have been proposed as metrics for tracking performance with respect to xτ∗
τ. 1. The distance to the optimal solutionx∗τ
eτ :=
xˆτ− xτ∗ ,
where the norm can be arbitrary. When there are explicit equality or inequality constraints and the algorithm also generates dual iterates, we can also evaluate the distance between the primal-dual pairs. This metric has been analyzed in [64, 77, 84, 86–88, 95] for specific time-varying optimization algorithms and employed in [9, 29, 35, 36, 90] for specific applications.
2. The sub-optimality in terms of objective values. Comparison of objective values is standard for evaluating performance of online learning algorithms, and can be also employed in time-varying optimization. There can be two sub-categories in this type of metric:
a) The difference in objective values
eτ := cτ(xˆτ) −cτ(x∗τ).
The notion of dynamic regret in online learning is closely related to this metric [48, 56, 68, 96, 99].
b) The ratio of objective values rτ := cτ(xˆτ)
cτ(xτ∗) or r :=
Íτcτ(xˆτ) Íτcτ(xτ∗).
Competitive ratio in online convex optimization can be viewed as a variant of this metric [4, 30, 63]. This metric can be employed in situations where the relative gap to the optimal objective value is more relevant than the absolute gap. On the other hand, one usually needs strong assumptions on the objective function to achieve a bounded competitive ratio.
When the iterates ˆxτ generated by the algorithm do not strictly satisfy the con- straints fτ(xˆτ) ≤0, we can use some meric function
φτ(x)=cτ(x)+Õ
i
g [fτ,i(x)]+
instead of the objective function cτ, where [·]+ denotes the positive part of a scalar, andg :R→R+ is a non-decreasing function withg(x)=0 forx ≤0.
3. The fixed-point residual
eτ := kxˆτ−Gτ(xˆτ)k,
where Gτ : Rn → Rn is a continuous map such that any fixed point of Gτ is an optimal solution (local or global) to (1.2) at time τ. This metric has been introduced and analyzed in [84].
We mention that, in existing literature, researchers have also proposed to compare ˆ
xτ with an optimal solution of the problem instance at the next time stepτ+1; in other words, metrics based on
xˆτ− xτ∗+1
, cτ+1 xˆτ
−cτ+1 x∗τ+1, cτ+1(xˆτ)
cτ+1 xτ∗+1, kxˆτ−Gτ+1(xˆτ)k have also been proposed. It turns out that it doesn’t matter much whether we choose to compare ˆxτ withxτ∗ or x∗τ+1in the time-varying optimization setting2; results on either one of the choices can usually be transferred to results on the other choice under appropriate conditions.
The three types of metrics are all reasonable quantitative characterizations of the tracking performance mathematically, and depending on specific scenarios where the time-varying optimization algorithms are applied, one can choose different metrics that are more suitable for application. In this thesis, we mostly use the first metric, the distance to the optimal trajectory, as the metric for tracking performance.
1.2 Review of Existing Works
In this section we give a brief and non-exhaustive review of some existing works on time-varying optimization and related topics.
Reference [77] is one of the early papers that consider time-varying optimization problems with a similar setting to the one in this thesis. The paper derived a tracking error bound of the running gradient descent algorithm for unconstrained time-varying convex optimization. Specifically, the paper showed that
lim sup
τ→∞
xˆτ− x∗τ ≤ ρ
1− ρsup
τ
x∗τ− x∗τ−1
(1.5)
for the running gradient descent algorithm for time-varying unconstrained strongly convex problems, where
Λmin =inf
τ,x λmin
∇2cτ(x)
, Λmax =sup
τ,x λmax
∇2cτ(x) ,
2It does matter, however, in online learning where the actual loss incurred iscτ+1(xˆτ).
ρ=max{|1−αΛmin|,|1−αΛmax|},
andα∈ (0,2/Λmax)is the step size. The paper also considered a special case where the tracking errorkxˆτ−xτ∗ktends to zero asτ→ ∞. The tracking error bound (1.5) turns out to be one of the most fundamental results in time-varying optimization.
Recent years have witnessed considerable advances in the theory and algorithms of time-varying convex optimization. [64] proposed a decentralized algorithm based on Alternating Direction Method of Multipliers for time-varying unconstrained con- sensus problems, and also derived a tracking error bound that is similar to (1.5).
[86] proposed a running algorithm based on the consensus + innovations method for time-varying constrained consensus problems, and also showed a similar tracking error bound. [87] proposed and analyzed the double smoothing method based on the multiuser optimization algorithm in [60], which is one of the earliest time-varying optimization algorithms that treat explicit inequality constraints. [95] introduced auxiliary variables in the design of the running algorithm for time-varying uncon- strained consensus problems over directed networks, and showed convergence to a bounded tracking error. [84] proposed a unified framework for time-varying convex optimization using averaged operators, and derived tracking error bounds for sev- eral running algorithms. [16] proposed and analyzed a feedback-based time-varying optimization algorithm based on the primal-dual gradient method, which applies to logical or physical systems with feedback measurements. [34] proposed and analyzed a feedback-based method to regulate the output of a linear time-invariant dynamical system to the optimal solution of a time-varying convex optimization problem. [54] proposed a formulation of time-varying projected gradient dynamics by introducing the notion of temporal tangent cones, and showed existence of solu- tion to the resulting differential equations. [15] developed an algorithmic framework for tracking fixed points of time-varying contraction mappings, and derived tracking error results in the situations where communication delays and packet drops lead to asynchronous algorithmic updates.
We would like to further expand on the results of [84] and [87]. In [84], the author considered the case where the time-varying optimization algorithm can be abstracted as
ˆ
xτ =Tτ xˆτ−1
, where for eachτ,Tτ :Rn→Rncan be represented as
Tτ(x)= (1−aτ)x+aτGτ(x), x ∈Rn
for someaτ > 0 and some nonexpansive operatorGτ(i.e.,kGτ(x1)−Gτ(x2)k ≤ kx1− x2k), and the fixed point of the operatorTτ gives the optimal solutionx∗τ. The paper showed that, ifσ := supτkx∗τ − x∗τ−1k < +∞ and X := supτsupx∈RnTτ(x) < +∞, then the sequence(xˆτ)τ satisfies
1 K
K
Õ
τ=1
1−aτ
aτ kTτ(xˆτ−1) −xˆτ−1k2 ≤ 1 K
xˆ0−x1∗
2+σ(4X +σ).
In addition, in the special case whereTτ is a contraction mapping with a uniform contraction coefficientρ ∈ (0,1), it was shown that
xˆτ−1−xτ∗
≤ ρτ−1kxˆ0− x∗1k+ 1− ρτ−1 1−ρ σ.
The paper then applied this bound to several time-varying optimization algorithms.
Especially, a bound on the fixed-point residual was established for the running projected gradient descent method that solves
x∈X(t)min c(x,t),
where X(t) ⊂ Rn is compact and uniformly bounded, and c(·,t) is convex and uniformly strongly smooth for eacht.
In [87], the authors considered the time-varying convex problem minx∈X cτ(x)
s.t. fτ(x) ≤0,
wherecτ :Rn→Ris convex, fτ :Rn →Rmhas convex components, andX ⊆Rnis convex and closed. The paper proposed a running version of the double smoothing algorithm [60] given by
ˆ
xτ = PX ˆ
xτ−1−α∇xLν,τ (xˆτ−1,λˆτ−1), λˆτ = PRm λˆτ−1+α∇λLτν,(xˆτ−1,λˆτ−1) , where the regularized LagrangianLν,τ is defined by
Lτν,(x, λ):= cτ(x)+λT fτ(x)+ ν
2kxk2− 2kλk2.
The paper showed that, when the step sizeαis sufficiently small, there exists some ρ <1 such that
lim sup
k→∞
zˆτ−z?τ+1 ≤ 1
1−ρsup
τ
z?τ+1−z?τ ,
where ˆzτ = xˆτ,λˆτ
, and z?τ = x?τ, λ?τ
denotes the saddle point of the regularized Lagrangian Lν,τ (x, λ). The authors also considered how to implement the algo- rithm in a distribution manner when the cost and constraint functions have special structures.
Time-varying optimization is closely related to parametric optimizationthat has a long history [49, 73, 81]. The formulation of one-parametric optimization problems is almost the same as (1.1), wheretis regarded as a one-dimensional parameter that may or may not represent time. Path-following methods (also called continuation methods or homotopy methods) and their varients have been developed to solve these problems [3, 39, 43, 80, 85, 97]. A typical parametric optimization algorithm discretizes the parameter set [0,T] by 0 < t1 < . . . < tK ≤ T, and generates approximate solutions ˆxτ such that
e :=sup
τ kxˆτ− x∗(tτ)k =O(∆max), as ∆max→0,
where ∆max = maxτ|tτ+1−tτ|. The theory of parametric optimization generally focuses on the convergence rate of the approximation erroreas∆max →0. In addi- tion, many parametric optimization algorithms consist of a predictor and a corrector:
for eachτ = 1, . . . ,K, the corrector utilizes the problem data att = tτ to move the prediction produced by the previous iteration towards the optimal trajectory, and the predictor then estimates the tangent vectordz∗(t)/dtatt = tτto provide a prediction of the optimal solution at the subsequent parameter value. This predictor-corrector procedure assumes knowledge of how the cost and constraint functions evolve with time, which is different from the time-varying optimization setting discussed in this thesis. The theory and algorithms of parametric optimization provide important insights on and tools for the study of time-varying optimization.
We would also like to mention that, in online learning, theories on dynamic regret have been developed, which are closely related to time-varying optimization [21, 48, 51, 56, 62, 68, 96, 99]. In online learning, for each time step τ, a player chooses a strategy ˆxτfrom some feasible setXby an online learning algorithm, and suffers some loss cτ+1(xˆτ) 3. To evaluate the performance of the online learning algorithm in the time-varying setting, the dynamic regret is proposed that compares the cumulative losses of the online player with the losses of the best possible
3We label the time indices in a fashion that is different from online learning literature but similar to the time-varying optimization setting.
responses
K
Õ
τ=1
cτ xˆτ−1
−cτ x∗τ.
Particularly, researchers are interested in bounding the growth rate of the dynamic regret asK → ∞ over a specific class of loss functions, and usually focus on the situations where the dynamic regret achieves sublinear growth.
For example, the pioneering paper [99] formulated the online convex programming problem in whichX ⊆ Rnis convex and compact andcτis convex and differentiable for allτ. The paper proposed the online projected gradient descent algorithm whose iterations are given by
ˆ
xτ =PX[xˆτ−1−α∇cτ(xˆτ−1)].
The paper showed that, for the online projected gradient descent algorithm, the dynamic regret can be upper bounded by
K
Õ
τ=1
cτ xˆτ−1
−cτ xτ∗
≤ 7R2 4α + R
α
K−1
Õ
τ=1
x∗τ+1−x∗τ + Gα
2 K, where
R:= sup
x1,x2∈X
kx2−x1k, G:=sup
τ sup
x∈X
k∇cτ(x)k.
In [68], the authors considered an online learning problem whereX ⊆Rnis convex and compact and the loss functioncτ is uniformly strongly convex, i.e., there exists µ > 0 such that
cτ(x2) ≥cτ(x1)+∇cτ(x1)T(x2− x1)+ µ
2kx2−x1k2, ∀x1,x2 ∈ X. It was shown that an improved bound on the dynamic regret can be derived for the online projected gradient descent algorithm when the step sizeαis sufficiently small:
K
Õ
τ=1
cτ xˆτ−1
−cτ xτ∗
≤ G 1
1−ρ
K−1
Õ
τ=1
xτ∗+1− xτ∗
+ kxˆ0−x1∗k 1− ρ
! ,
where
ρ=p
1−αµ, G= sup
τ sup
x∈X
k∇cτ(x)k.
A recent paper [48] considered an online learning problem where the loss function could be nonconvex. Specifically, whileX ⊆Rnwas still assumed to be convex and
compact, each loss functioncτ :X → Rwas assumed to beweakly pseudo-convex: there exists M > 0 such that
cτ x
−cτ xτ∗
≤
M∇cτ(x)T x−xτ∗
k∇cτ(x)k , ∇cτ(x),0,
0, ∇cτ(x)=0
for anyx ∈ Xand anyxτ∗ ∈arg minu∈Xcτ(u). The paper showed that, if the strategies xˆτ are generated by theonline normalized gradient descentalgorithm
ˆ
xτ = PX[xˆτ−1−ηgτ], gτ :=
∇cτ(xˆτ−1)
k∇cτ(xˆτ−1)k, ∇cτ(xˆτ−1), 0, 0, ∇cτ(xˆτ−1)= 0,
whereηis some positive constant, then the following bound on the dynamic regret holds under certain conditions:
K
Õ
τ=1
cτ(xˆτ−1) −cτ(xτ∗) ≤ M
2η 4R2+η2K +6R
K−1
Õ
τ=1
xτ∗+1− x∗τ
! ,
where R := supx∈Xkxk. Further investigation of these examples and other related works suggests that, although time-varying optimization and online learning have different perspectives and settings, the mathematics behind the theories of dynamic regret can be very relevant for the research on time-varying optimization.
Time-varying optimization has also found its place in various applications. While the original formulation was for static problems, the network flow control algorithm in [67] is essentially implemented in a running fashion and can be easily extended to time-varying situations. In [29], the primal-dual saddle point dynamics was applied in time-varying wireless systems, with theoretical analysis on the tracking performance. In [9], the running version of the iterative soft-thresholding algorithm and its continuous-time counterpart for sparse signal recovery were analyzed under the time-varying setting. In [8], the authors proposed a running stochastic gradient descent method for topology tracking in social networks, though no theoretical guarantee on tracking performance has been provided.
With the technological advances in sustainable energy and smart grids, recent re- search has found it necessary to consider power system operation in the time-varying setting. Reference [24] proposed an online algorithm based on the dual subgradient ascent method, and [17, 47] proposed online algorithms based on the projected gradient descent method for the operation of distribution networks, though no the- oretical results were developed for the time-varying setting. [35, 36] employed the
double smoothing method [87] and a linearized power flow model for real-time oper- ation of distribution networks, and [14] presented a more comprehensive framework that can handle a wider range of controllable power devices. [52, 55] proposed continuous-time online algorithms that employ projected gradient dynamics on the power flow manifold.
1.3 Organization of the Thesis
Chapter 2: First-Order Algorithms for Time-Varying Optimization
In Chapter 2, we propose a first-order time-varying optmization algorithm, which we call the regularized proximal primal-dual gradient algorithm. The regulariza- tion comes in the form of a strongly concave term in the dual vector variable that is added to the Lagrangian function [50, 58, 60]. The strongly concave regular- ization term plays a critical role in establishing contraction-like behavior of the proposed algorithm. However, as an artifact of this regularization, existing works for time-invariant convex programs [60], time-varying convex programs [16], and for static nonconvex problems [50] could prove that gradient-based iterative methods approach an approximate KKT point. On the other hand, in Chapter 2 we provide analytical results in terms of tracking a KKT point (as opposed to an approximate KKT point) of (1.2) and provide bounds for the distance of the algorithmic iterates from a KKT trajectory. The bounds are obtained by finding conditions under which the regularized proximal primal-dual gradient step exhibits a contraction-like be- havior. The bounds are directly related to the maximum temporal variability of a KKT trajectory, and also depend on pertinent algorithmic parameters such as the step size and the regularization coefficient.
We then provide sufficient conditions for the existence of algorithmic parameters that guarantee bounded tracking error for sufficiently small sampling interval. From a qualitative standpoint, the sufficient conditions for the existence of feasible pa- rameters suggest that the problem should be “sufficiently convex” around a KKT trajectory to overcome the nonlinearity of the nonconvex constraints.
The study of feasible algorithmic parameters suggests analyzing the continuous- time limit of the proposed regularized proximal primal-dual gradient algorithm;
see, e.g., [31, 32, 78, 79, 93] and pertinent references therein for continuous-time algorithmic platforms. We show that the continuous-time counterpart of the discrete- time algorithm is given by a system of differential inclusions that can be viewed as a generalization ofperturbed sweeping processes[2, 28]. The tracking performance
of the system of differential inclusions is analytically established; the continuous- time tracking error bound shares a similar form with the discrete-time tracking error bound. Then, we provide sufficient conditions for the existence of feasible algorithmic parameters, and also analyze the existence and properties of the optimal algorithmic parameters that minimize the tracking error bound.
Finally, we derive conditions under which the KKT points for a given time will always be isolated; that is, bifurcations or merging of KKT trajectories do not happen.
While most existing works on time-varying optimization focus on problems that are globally convex, our study does not assume global convexity of the objective and constraint functions, which can be particularly useful for time-varying nonconvex problems such as the time-varying optimal power flow problem. Part of these results have been reported in [88, 89].
Chapter 3: Second-Order Algorithms for Time-Varying Optimization
In Chapter 3, we consider second-order algorithms for time-varying optimization.
By “second-order” algorithms, we mean that for eachτ, not only the current function value and gradient information is used, but also the exact or approximate curvature information is employed, which is similar to Newton and quasi-Newton methods in static optimization.
We first propose the approximate Newton method for a special case where the constraints in (1.2) appear in the form x ∈ Xτ for some closed and convexXτ. The approximate Newton method is a natural extension of (quasi-)Newton method to the time-varying setting. It is shown that the tracking error is directly affected by how well we can approximate the curvature of the objective function cτ. We also propose a specific version of the approximate Newton method based on L-BFGS-B [26, 69] that handles box constraints.
Then, we propose two variants of the approximate Newton method that can handle nonlinear constraints that are formulated as explicit equalities and inequalities. The first variant employs penalty functions [19, 72] to obtain a modified version of the original problem, so that the approximate Newton method for the special case dis- cussed above can be applied. We investigate the relationship between the penalty functions and regularization on the dual variables, and derive bounds on the differ- ence between optimal solutions of the penalized problem and the original problem.
The second variant can be viewed as an extension of sequential quadratic program-
ming [23] in the time-varying setting, with regularization on the dual variable just like the regularized proximal primal-dual gradient algorithm. We perform a direct analysis of the tracking error with respect to the optimal trajectory and discuss its implications.
Finally, we use a toy example to compare first-order and second-order methods, in order to have a better understanding of how to appropriately choose between these two types of methods in practical scenarios.
As mentioned in Section 1.2, parametric optimization is closely related to time- varying optimization, and many path-following algorithms utilize curvature infor- mation in a very similar fashion to the approximate Newton methods [39, 43, 49, 97].
On the other hand, parametric optimization generally focuses on whether and how fast the trajectory generated by path-following algorithms will converge to the opti- mal trajectory as the sampling interval goes to zero. This is different from our setting where we assume a given and fixed sampling interval, considering that the delays caused by computation, communication, etc. will prevent the sampling interval from being arbitrarily small in practice.
Similar to Chapter 2, we do not explicitly assume global convexity for the time- varying optimization problem in our study. Part of these results have been reported in [90, 91].
Chapter 4: Applications in Power System Operation
In Chapter 4, we discuss the application of time-varying optimization algorithms to power system operation, motivated by the consideration that batch solutions are inappropriate when one needs to optimize over a large number of distributed con- trollable devices to handle fast-timescale fluctuations and uncertainties introduced by distributed energy resources in future smart grids.
We formulate the time-varying optimal power flow problem, where the decision variables are subject to the power flow equations. We partition the decision variables into two groups, and replace the power flow equations by an implicit power flow map between the two groups of variables. We present sufficient conditions for the existence of the implicit power flow map, and discuss the advantages of introducing implicit power flow map to utilize real-time feedback measurements. The use of real-time feedback measurements is a central idea in real-time optimal power flow algorithms [35, 36, 90, 91] (also see [47] for static optimization), which not only greatly reduces the computation burden, but also improves robustness against model
mismatch.
Then we present two real-time optimal power flow algorithms in detail. The first algorithm applies the regularized primal-dual gradient algorithm to the real-time operation of a distribution feeder. Specifically, we show how real-time measurement data can be naturally incorporated in the computation, and analyze the effect of employing approximate Jacobian of the implicit power flow map in the algorithm theoretically. The second algorithm applies the approximate Newton method with penalty functions to the time-varying optimal power flow problem. Second-order real-time optimal power flow method was first proposed by [90] and here we present the distributed implementation proposed in [91].
Chapter 5: Concluding Remarks on Future Directions
We conclude the thesis by remarks on some future directions that are worth explo- ration.
1.4 Notations and Terminologies Sets and Functions
For any set A, its power set will be denoted by 2A, and the Cartesian product A× · · · × A
| {z }
ntimes
will be denoted by An. Let(Ai)in=
1be a finite sequence of sets, and letSbe a nonempty subset ofA1×· · ·×An. A mapπ :S →Ðn
i=1Aiis called a canonical projection if there existsj ∈ {1, . . . ,n}
such that
π(x1, . . . ,xn)= xj, ∀(x1, . . . ,xn) ∈S.
We denoteR+ = [0,+∞)andR++= (0,+∞).
Suppose f : X →Y where X andY are any sets. For any subset A ⊆ Y, f−1[A]
denotes the preimage{x ∈ X : f(x) ∈ A}.
For a real-valued function f defined on an interval D ⊆ R, we say that it is nondecreasing if∀x1,x2 ∈ D, x1 < x2⇒ f(x1) ≤ f(x2), and say that it is (strictly) increasing if the inequality is strict. The notion of nonincreasing and (strictly) decreasing functions are defined similarly. We say that f is unimodal if there exists x0 ∈ D such that f is strictly decreasing onD∩ (−∞,x0]and is strictly increasing onD∩ [x0,+∞).
For f :Rn →Rm, the inequality f(x) ≤0 means−f(x) ∈ Rm+.
For any x ∈ R, bxc denotes the largest integernsuch thatn ≤ x, and dxe denotes the smallest integernsuch thatn ≥ x.
Linear Algebra We use
x = (x1, . . . ,xn)=
x1
...
xn
to denote vectorx inRn. The Euclidean norm onRnwill be simply denoted by kxk :=
vt n Õ
i=1
xi2, x ∈Rn.
The identity matrix will be denoted byI, orIn∈Rn×nwhen the dimension needs to be specified to avoid confusion.
For any matrixM = Mi j
∈Rm×n. kMkdenotes the operator norm kMk :=sup
x,0
kM xk kxk .
WhenM is a square matrix, we useλmax(M)andλmin(M)to denote the largest and the smallest eigenvalues ofM respectively.
For two real symmetric matrix A and B, the expression A B means B− A is positive semidefinite, and A≺ BmeansB−Ais positive definite.
Real Analysis
For a topological space X and a subset A⊆ X, the interior of Awill be denoted by intA, and the closure of Awill be denoted by clA.
The closed unit ball inRncentered at the origin will be denoted byBn. For any two subsets A,BofRnand anyα, β ∈R, we define
αA+βB :={αx+ βy : x ∈ A,y ∈ B}.
As an example,{x}+rBnis the closed ball inRnof radiusrcentered at x.
Suppose f : X → R∪ {+∞} where X is a topological space. We say that f is lower semicontinuous if lim infn→∞ f(xn) ≥ f(x)for any x ∈ X and any sequence (xn) ⊂ X that converges to x. Equivalently, f is lower semicontinuous if {x ∈ X : f(x) > a} is an open subset of X for alla ∈ R. A function f : X → R∪ {−∞}
is upper semicontinuous if −f is lower semicontinuous. A function f : X → R is continuous if and only if it is both lower and upper semicontinuous. See [57, Section 12] for more details.
Let f :I →Rbe a function defined on an interval I ofR. The essential supremum of f(t)overt ∈ I is defined by
ess sup
t∈I
f(t):=inf
M ∈R: Leb f−1[(M,+∞)]
=0 , where Leb denotes the Lebesgue measure onR.
Let f :[a,b] →Rm be a vector-valued function whose components are absolutely continuous. Then there exists a Lebegue integrable function from [a,b] to Rm, which we denote byD f, such that
f(t) − f(a)=
∫ t a
D f(s)ds
for allt ∈ [a,b], andD f is unique up to a Lebesgue null set. We will also denote
d
dt f(t):= D f(t). Furthermore, f is Lipschitz continuous on[a,b]if and only if ess sup
t∈[0,T]
kD f(t)k < +∞, or in other words,D f ∈ L∞([a,b]), and in this case,
sup
t1,t2∈[a,b], t1,t2
kf(t2) − f(t1)k
|t2−t1| = ess sup
t∈[a,b] kD f(t)k.
See [44, Section 3.5] for more details.
Differential Calculus
Let f :Rn→Rbe differentiable onRn. The gradient of f atx ∈Rnwill be denoted by∇f(x)which is ann-dimensional column vector. If f is twice differentiable, the Hessian of f at x ∈Rnwill be denoted by∇2f(x).
Let f(x,y)be a function fromRn×Y toRwhereY is any set, and for some y0 ∈Y, f(x,y0) is differentiable with respect to x. The (partial) gradient of f(x,y) with respect to xat(x0,y0) ∈Rn×Y will be denoted by∇xf(x0,y0). If f(x,y0)is twice differentiable with respect to x, the (partial) Hessian of f(x,y)with respect to x at (x0,y0) ∈Rn×Y will be denoted by∇2x xf(x0,y0).
Let f : Rn → Rm be a differentiable vector-valued function. We will denote its components by f1, . . . , fm. The Jacobian of f at x ∈Rnwill be denoted by
Jf(x):=
∇f1(x)T ...
∇fn(x)T
∈Rm×n.
Let f(x,y) be a vector-valued function from Rn ×Y to Rm where Y is any set.
Suppose for somey0 ∈Y, f(x,y0)is differentiable with respect to x. The (partial) Jacobian of f(x,y)with respect tox at(x0,y0) ∈Rn×Y will be denoted by
Jf,x(x0,y0):=
∇xf1(x0,y0)T ...
∇xfm(x0,y0)T
∈Rm×n.
The following equalities can be shown by straightforward calculations.
Lemma 1.1. 1. Suppose f :Rn→ Rm is continuously differentiable. Then for any x,y ∈Rn,
f(y)= f(x)+ ∫ 1 0
Jf(x+θ(y− x))dθ
(y− x). (1.6)
2. Suppose f :Rn →Ris twice continuously differentiable. Then for anyx,y ∈Rn, f(y)= f(x)+∇f(x)T(y− x)
+ 1
2(y−x)T
∫ 1 0
2(1−θ)∇2f(x+θ(y− x))dθ
(y− x). (1.7) Convex Analysis
LetC ⊆ Rnbe a convex set. The indicator function ofCwill be defined and denoted by
IC(x)=
(0, x ∈C, +∞, x<C.
The relative interior ofCwill be denoted by relintC. The normal cone ofCatx ∈C is defined by
NC(x):= {y ∈Rn : yT(z− x) ≤ 0, ∀z ∈C}.
When C is closed, for any x ∈ Rn, it is known [20, Proposition 2.2.1] that there exists a unique vector that minimizesky−xkover ally ∈C. We call this vector the
projection of xintoC, and denote it by PC(x):=arg min
y∈C
ky− xk. Furthermore, we have the following proposition.
Proposition 1.1([20, Proposition 2.2.1]). SupposeC ⊆ Rnis convex and closed.
1. For anyx ∈Rn,
y = PC(x) ⇐⇒ (x− y)T(z− y) ≤ 0, ∀z ∈C ⇐⇒ x−y ∈ NC(y). 2. PC is nonexpansive, i.e.,kPC(x) − PC(y)k ≤ kx− yk for anyx,y ∈Rn. For a convex coneC ⊆ Rn, its polar cone is defined by
C◦:= {y ∈Rn: yTz ≤ 0, ∀z ∈C}.
For any subsetAofRn, its convex hull will be denoted by convA, and its affine hull will be denoted by affA.
Let f :Rn→R∪ {+∞}be a convex function. The domain of f is defined by dom(f):= {x ∈Rn : f(x)< +∞}.
We say that f is proper if dom(f) is nonempty. We say that f is closed if the epigraph
epi(f):={(x,y) ∈Rn×R: y ≥ f(x)}
is closed.
Proposition 1.2([82, Theorem 7.1]). A proper convex function f :Rn →R∪ {+∞}
is lower semicontinuous if and only if it is closed.
The subdifferential of f at x0∈dom(f)is defined by
∂f(x0):=
u ∈Rn: f(x) − f(x0) ≥ uT(x− x0), ∀x ∈Rn .
The definition indicates that ∂f(x0) is the intersection of a collection of closed half-spaces inRn, and therefore is convex and closed.
Supposeg(x,y)is a function fromRn×Y toR∪ {+∞} whereY is any set, and for some fixed y0 ∈Y,g(x,y0)is a proper convex function of x. We denote the partial subdifferential ofg(x,y)with respect tox at(x0,y0) ∈Rn×Y by
∂xg(x0,y0):=
u ∈Rn:g(x,y0) −g(x0,y0) ≥ uT(x− x0), ∀x ∈Rn .

![1. graph t (g) is κ 1 -Lipschitz in t , and for each fixed t ∈ [0, T ] , g(·, t) is a proper convex function,](https://thumb-ap.123doks.com/thumbv2/123dok/11848398.0/77.918.156.739.244.682/graph-κ-lipschitz-fixed-t-proper-convex-function.webp)